
Вы открываете страницу GGUF популярной модели на Hugging Face, и на вас смотрят пятнадцать файлов: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, плюс отдельные папки для GPTQ, AWQ и EXL2 с полудюжиной битовых настроек. Вы прикидываете на салфетке для файла «4-бит»: 4 бита × 8 миллиардов параметров ÷ 8 = 4 ГБ. Но файл весит 4,6 ГБ. А после загрузки модель занимает ещё больше памяти.
Имена файлов, это не шум. Они кодируют реальную, полезную информацию о битовой ширине, среде выполнения, которая их загружает, и оборудовании, которое им требуется. Таблицы размеров, которые вы читали, говорят, что модели на 70B нужно примерно 40 ГБ, это полезно, но они никогда не расшифровывают сам формат и не объясняют, почему запущенная модель требует больше памяти, чем файл на диске.
Итак, вот план: расшифровать соглашение об именовании GGUF (с реальной битовой шириной, а не номинальной), разобраться, какой из четырёх форматов действительно может запускать ваше оборудование, и учесть единственные затраты памяти, невидимые в любом размере файла, KV cache. В итоге вы сможете читать репозиторий модели и предсказывать её поведение при загрузке.
Кратко (TL;DR)
- Уровни квантования GGUF, это эффективная битовая ширина, а не точное число в названии. Q4_K_M составляет около 4,89 бита на вес, поэтому «4-битный» файл на 8B получается около 4,6 ГиБ вместо наивной оценки в 4 бита.
- GGUF - самый переносимый вариант, потому что llama.cpp может запускать его на CPU, GPU или в гибридной конфигурации. GPTQ, AWQ и EXL2 более привязаны к GPU и среде выполнения, а EXL2 особенно завязан на рабочие процессы NVIDIA/CUDA.
- KV cache отделён от весов модели и растёт вместе с длиной контекста. Именно поэтому модель, которая нормально загружается, всё же может упасть с ошибкой нехватки памяти, когда разговор становится длинным.
- Выше диапазона 5 бит потеря качества обычно невелика. В районе Q4 компромисс всё ещё практичен для многих локальных сценариев использования. Ниже 4 бит потеря качества становится гораздо заметнее. Q4_K_M остаётся распространённым выбором по умолчанию в сообществе, тогда как Q5_K_M и Q6_K безопаснее, если у вас есть запас памяти.
Что означает Q4_K_M в имени файла GGUF?

Название квантования GGUF следует шаблону Q[биты]_[K]_[S/M/L]. Число, это целевое битов на вес, K означает, что это «K-quant», хранящий коэффициенты масштабирования для каждого небольшого блока весов, а завершающая S, M или L обозначает уровень размера/качества (small, medium, large). Поскольку K-quant-ы хранят масштаб и минимальное значение для каждого блока в дополнение к весам, эффективная оказывается выше заявленного числа. Q4_K_M получается около 4,89 бита на вес, а не 4.
Именно этот разрыв полностью объясняет вопрос «почему мой 4-битный файл весит 4,6 ГБ?». Наивная оценка предполагает, что каждый вес стоит ровно 4 бита. На деле K-quant-ы тратят дополнительные биты на блок на метаданные, которые делают низкобитное квантование точным, масштаб и минимум на блок, позволяющие среде выполнения восстанавливать каждый вес. Умножьте 4,89 бита на 8 миллиардов весов и получите около 4,58 ГиБ, именно столько реально весит файл.
Вот измеренные эффективные битовые ширины и размеры файлов, взятые из llama.cpp quantize documentation для Llama 3.1 8B в качестве эталонной модели, наряду с ценой в перплексии для каждого уровня, измеренной в статье оценки квантования llama.cpp (arXiv:2601.14277) на Llama-3.1-8B-Instruct:
| Уровень GGUF | Эффективный BPW | ~Размер файла (8B) | Перплексия относительно F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 ГиБ | +22% |
| Q3_K_M | 3.95 | ~3,7 ГиБ | +8.7% |
| Q3_K_L | 4.30 | ~4,0 ГиБ | +6.7% |
| Q4_K_S | 4.67 | ~4,4 ГиБ | +4.1% |
| Q4_K_M | 4.89 | ~4,6 ГиБ | +3.3% |
| Q5_K_M | 5.70 | ~5,3 ГиБ | +1.1% |
| Q6_K | 6.56 | ~6,1 ГиБ | +0.4% |
| Q8_0 | 8.50 | ~8,0 ГиБ | +0.1% |
| F16 | 16.00 | ~15,0 ГиБ | базовый уровень |
*Значения перплексии относятся конкретно к Llama-3.1-8B-Instruct из arXiv:2601.14277. Столбец BPW/размер файла и столбец перплексии взяты из двух разных источников, измеренных отдельно, поэтому воспринимайте таблицу как практическое сопоставление, а не как результат единого прогона бенчмарка. Деградация зависит от задачи, математические рассуждения обычно страдают сильнее, чем рассуждения на основе здравого смысла при низкой битовой ширине, но общая картина сохраняется: 5 бит и выше обычно безопаснее, Q4 - практическая зона сжатия, а 3 бита - тот уровень, где потерю качества становится гораздо труднее игнорировать.
На практике: Q4_K_M - выбор по умолчанию для большинства пользователей, Q5_K_M и Q6_K - варианты в пользу качества, если у вас есть запас памяти, а всё на уровне Q3_K_S и ниже, крайняя мера для оборудования, которое действительно не может вместить больше.
Какой формат квантования стоит скачать: GGUF, GPTQ, AWQ или EXL2?

GGUF - самый переносимый из четырёх: он работает на CPU, GPU или в гибриде обоих через llama.cpp, поэтому это самый безопасный выбор, если вы не уверены, что может поддерживать ваше оборудование. GPTQ, AWQ и EXL2 более привязаны к GPU и среде выполнения. На практике они чаще всего встречаются на конфигурациях NVIDIA/CUDA, но поддержка GPTQ и AWQ может отличаться в зависимости от загрузчика и стека обслуживания; vLLM, например, разделяет поддержку квантования по оборудованию и реализации. Если вы работаете локально на Mac, карте AMD или машине только с CPU, GGUF по-прежнему самый безопасный ответ. Если у вас есть GPU NVIDIA и вы хотите максимально быстрые токены, в игру вступают остальные три.
| Формат | Оборудование/среда выполнения | Скорость (относительная) | VRAM в сравнении с аналогами | Подходит для |
|---|---|---|---|---|
| GGUF Q4_K_M | Самый широкий охват, CPU, GPU или гибрид через llama.cpp | Умеренный | Самый низкий | Любое оборудование; локальный выбор по умолчанию |
| GPTQ 4-bit | Обычно ориентирован на CUDA/GPU; зависит от среды выполнения | Быстро (ExLlama) | Средняя | Ориентирован на GPU, устаревший инструментарий |
| AWQ 4-bit | Обычно ориентирован на CUDA/GPU; зависит от среды выполнения | Быстрее | Наивысший | Обслуживание через vLLM/TGI, быстрая загрузка |
| EXL2 ~4,9 bpw | Ориентирован на NVIDIA/CUDA | Самый быстрый | Низкий-средний | Максимальная скорость на NVIDIA |
Оговорка к этой таблице: рейтинги скорости и VRAM взяты из бенчмарка oobabooga, который проводился на оборудовании эпохи 2023-2024 годов. Воспринимайте относительный относительный порядок как устойчивый. EXL2 создан для скорости, AWQ жертвует VRAM ради быстрой загрузки, GGUF остаётся компактным и переносимым, но не воспринимайте исходные абсолютные значения токенов в секунду как актуальные. GPU 2026 года покажет совсем другую пропускную способность; сохраняется именно относительный порядок.
Итак, вот правило принятия решения, которое из этого следует: если у вас есть карта NVIDIA и скорость важнее всего, EXL2; если вам нужен самый безопасный локальный выбор по умолчанию для разного оборудования, GGUF. AWQ и GPTQ важны в основном тогда, когда конкретный стек обслуживания (vLLM, TGI) или существующий инструментарий подталкивает вас к ним.
Почему локальная LLM использует больше памяти, чем весит её файл?
Размер файла, это только веса модели. Во время работы вы также платите за KV cache (состояние внимания для каждого токена в вашем окне контекста), активации (промежуточные вычисления прямого прохода) и накладные расходы фреймворка и драйвера. Вместе элементы, не являющиеся весами, обычно добавляют 10-20% сверх весов для однопользовательской конфигурации, а сам по себе KV cache может затмить всё остальное, когда контекст становится длинным. Файлу на 4,6 ГБ может понадобиться для работы значительно больше 4,6 ГБ памяти.
Представьте память во время выполнения как четыре компонента, наложенных друг на друга:
- Веса модели. Файл, который вы скачали. Это единственный компонент, видимый до загрузки.
- KV cache. Состояние внимания для окна контекста. Небольшое при коротком контексте, огромное при длинном. Это тема следующего раздела, потому что именно она удивляет людей больше всего.
- Активации. Рабочая память прямого прохода. Для однопотокового локального инференса (размер батча 1) она невелика, обычно несколько сотен мегабайт.
- Накладные расходы фреймворка. Собственный след среды выполнения плюс контекст драйвера GPU. Для лёгкой локальной среды выполнения это может быть небольшим по сравнению с весами модели и KV cache; более тяжёлые фреймворки обслуживания могут резервировать гораздо больше. Собственное резервирование памяти вашей операционной системой находится за пределами этого и снова является отдельным.
Веса и накладные расходы фреймворка предсказуемы. KV cache - это переменная, превращающая модель, которая «помещается», в модель, которая падает, поэтому стоит проделать реальные расчёты.
Сколько памяти использует KV cache?
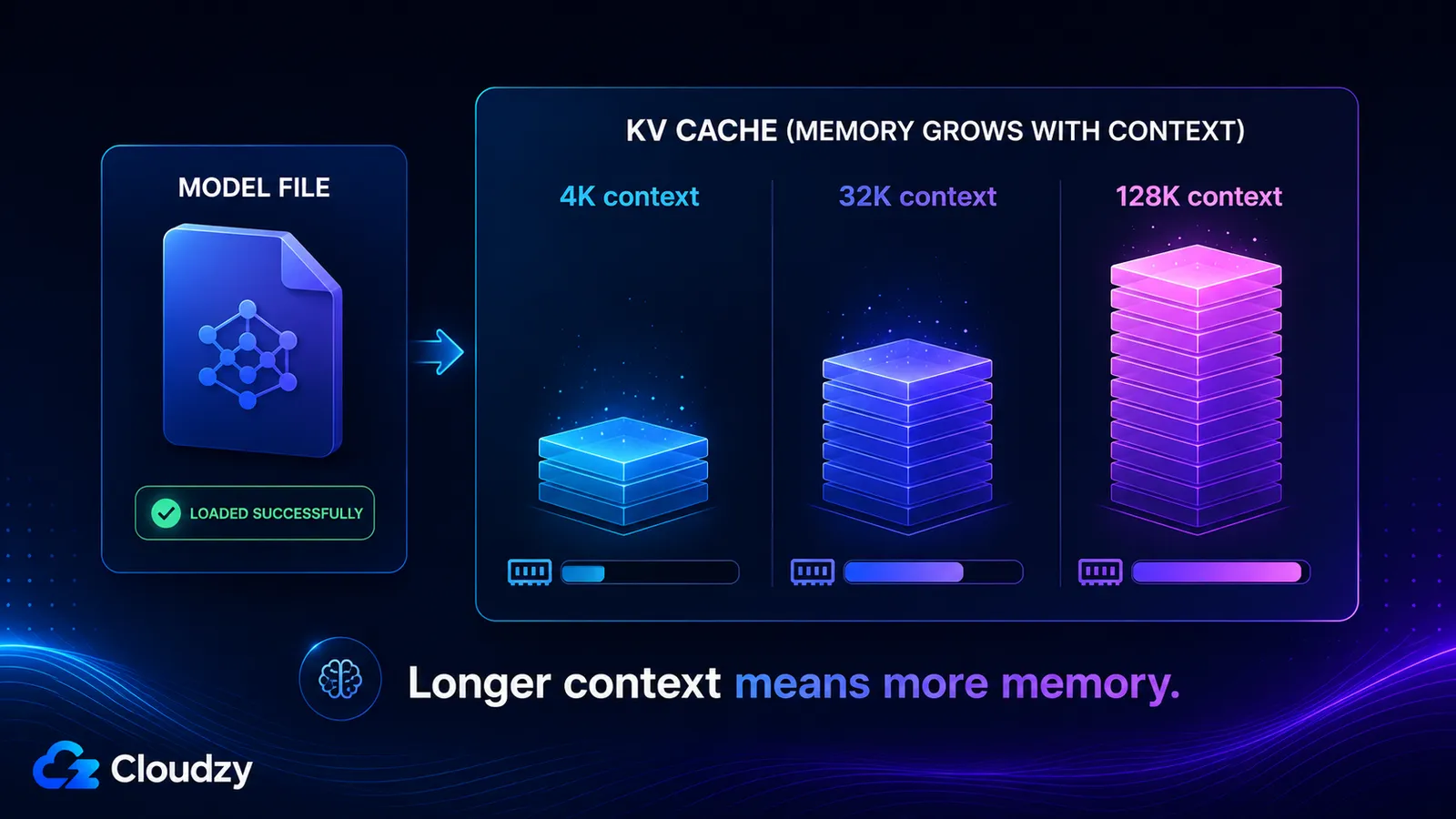
KV cache хранит векторы ключей и значений для каждого токена в вашем окне контекста, поэтому он растёт примерно линейно с длиной контекста и полностью отделён от весов модели. Его размер определяется количеством слоёв модели, числом KV-голов, размерностью головы, длиной контекста и точностью кэша. Включите длинный контекст, и вы можете добавить десятки гигабайт, о которых модель, прекрасно загружавшаяся, никогда вас не предупреждала.
Формула достаточно короткая, чтобы держать её в голове:
Байты KV cache = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Начальная 2 отражает два тензора, хранящихся на токен: один для ключей, один для значений. bytes_per_element равен 2 для кэша FP16. Остальное - архитектурные константы, которые можно найти в карточке модели.
Посчитаем для Llama 3.1 8B, у которой 32 слоя, 8 KV-голов и размерность головы 128. При контексте в 4096 токенов, размере батча 1, кэше FP16:
2 × 32 × 8 × 128 × 4096 × 2 байта ≈ 536 МБ
Увеличьте контекст, и число масштабируется вместе с ним, поскольку все члены, кроме context_tokens, фиксированы:
- Контекст 4K: ~536 МБ
- Контекст 32K: ~4,3 ГБ
- Контекст 128K: ~17 ГБ
Эти последние два числа объясняют, почему модель может заявлять окно контекста в 128K, спокойно загружаться, а затем исчерпывать память в тот момент, когда вы реально используете это окно. KV cache при полном контексте оказывается больше, чем сами квантованные веса.
А вот что вообще делает возможными современные модели с длинным контекстом: Llama 3.1 8B использует Grouped Query Attention (GQA)У неё 32 головы запросов, но только 8 KV-голов, кэш хранит векторы ключей/значений для 8 голов, а не 32. Примените ту же формулу с 32 KV-головами (более старая конструкция Multi-Head Attention, где KV-головы равны головам запросов), и каждое число выше умножается на 4. Те 17 ГБ при 128K превращаются в 68 ГБ. GQA - это архитектурная причина, по которой математика остаётся выносимой по мере роста окон контекста.
Размер файла - это не ваш бюджет памяти. Когда веса или KV cache перестают помещаться в быстрый путь памяти и среде выполнения приходится возвращаться к системной RAM через PCIe, пропускная способность не деградирует плавно. Она обрушивается, как только вы начинаете гонять данные через PCIe на каждый токен. Планируйте память так, чтобы поместились и веса, и KV cache при вашей реальной длине контекста, а не только веса.
Как выбрать квантование для вашего GPU или Mac?
Начните с вашего оборудования и среды выполнения. У владельцев GPU NVIDIA самый широкий выбор, стоит рассмотреть EXL2 ради чистой скорости или GGUF ради переносимости. Если у вас AMD, Apple Silicon, оборудование только с CPU или смешанная конфигурация, GGUF через llama.cpp обычно самая безопасная отправная точка. Далее выбирайте наивысший уровень квантования, который помещается после того, как вы заложили в бюджет KV cache при той длине контекста, которую реально используете, а не при максимуме модели.
Ловушка Apple Silicon, о которой стоит знать: GPU не получает всю вашу унифицированную память (см. нашу смежную статью о том, что такое унифицированная память на самом деле , для полной картины того, как работает этот общий пул). Сообщество self-hosting задокументировало ограничение около 75% от общей унифицированной памяти, доступной GPU (это не подтверждено официально Apple и может меняться с обновлениями macOS). Так что «64-гигабайтный Mac» реально даёт около 48 ГБ для модели плюс её KV cache, планируйте, исходя из меньшего числа.
Эта статья посвящена чтению формата и предсказанию его поведения во время выполнения: расшифровка названия квантования, выбор формата, поддерживаемого вашим оборудованием, и планирование бюджета KV cache отдельно от весов. Сопоставление конкретной модели с конкретным объёмом памяти, таблица соответствия размера и памяти, это связанный, но отдельный вопрос, который мы разберём в будущей смежной статье.
Читайте репозиторий
Теперь вы можете смотреть на страницу модели и понимать её, а не гадать. Расшифруйте название квантования до его эффективной битовой ширины, помните, что GGUF - самый универсальный локальный формат, тогда как GPTQ, AWQ и EXL2 более привязаны к среде выполнения, и не забывайте, что размер файла - это лишь нижняя граница, поверх неё наслаивается KV cache, растущий вместе с вашим контекстом. Откройте файлы нужной модели, выберите формат, который может запускать ваше оборудование, выберите наивысший уровень квантования, который помещается после того, как вы оставили запас для KV cache при вашей реальной длине контекста, и вы избежите сбоя нехватки памяти, с которого начался весь этот вопрос.
Часто задаваемые вопросы
Что означает Q4_K_M?
Q4_K_M - это уровень квантования GGUF: примерно 4 бита на вес (Q4), с использованием поблочного масштабирования K-quant (K), на среднем уровне размера/качества (M). Его эффективная эффективная битовая ширина составляет около 4,89 бита на вес, а не ровно 4, потому что K-quant-ы хранят масштаб и минимальное значение для каждого блока весов. Именно поэтому файл «4-битной» модели на 8B весит около 4,6 ГБ, а не 3,5 ГБ.
Снижает ли квантование качество LLM?
Да, но цена сильно зависит от того, насколько далеко вы заходите. На Llama-3.1-8B-Instruct, измеренной в arXiv:2601.14277, перплексия растёт лишь примерно на 0,4% при Q6_K и остаётся около 1% на всём диапазоне Q5. Опуститесь до Q4, и рост всё ещё умеренный (несколько процентов); ниже Q3_K_M он резко взлетает, достигая +22% при Q3_K_S. Для большинства применений Q4_K_M и выше практически без потерь; резкий штраф начинается на 3 битах и ниже.
В чём разница между GGUF, GPTQ, AWQ и EXL2?
GGUF (запускается через llama.cpp) - это переносимый формат, он работает на CPU, GPU или в гибридной конфигурации на широком спектре оборудования. GPTQ, AWQ и EXL2 более привязаны к GPU и среде выполнения. При 4 битах все четыре могут оказаться в узком диапазоне качества, поэтому практическая разница заключается в оборудовании, поддержке загрузчика, скорости и использовании VRAM: EXL2 - выбор, ориентированный на скорость для NVIDIA/CUDA, AWQ распространён в стеках обслуживания, GPTQ подходит для более старого GPU-инструментария и репозиториев моделей, а GGUF остаётся самым переносимым локальным вариантом.
Почему моя локальная LLM использует больше памяти, чем файл?
Размер файла - это только веса модели. Во время работы вы также платите за KV cache (состояние внимания для каждого токена в окне контекста), активации и накладные расходы фреймворка плюс драйвера. KV cache обычно виноват, когда разрыв велик, потому что он растёт вместе с длиной контекста и выделяется отдельно от весов; модель, файл которой весит несколько гигабайт, может потребовать намного больше памяти, как только вы зададите длинный контекст.
Как длина контекста влияет на использование памяти?
KV cache растёт примерно линейно с длиной контекста, поэтому удвоение контекста примерно удваивает кэш. Для Llama 3.1 8B кэш составляет около 536 МБ при 4K токенов, ~4,3 ГБ при 32K и ~17 ГБ при 128K (FP16, один поток). Этот рост полностью отделён от весов модели, поэтому заявление длинного окна контекста может привести модель к нехватке памяти, даже если она нормально загрузилась.


