
Быстрый запуск, оплата только за использованные ресурсы и снятие забот об обновлениях — звучит убедительно. Но эйфория проходит, когда приходят счета за неконтролируемое хранилище или забытая политика S3 оставляет бакет открытым для всех. На практике я снова и снова вижу одни и те же ключевые проблемы облачных вычислений в разных стеках и отраслях. Если разобраться с ними заранее, удастся избежать большей части боли и позволить команде сосредоточиться на выпуске фич, а не на тушении пожаров.
Почему эти проблемы никуда не Go
Сбои в облаке редко возникают из-за одной катастрофической ошибки. Они нарастают постепенно: небольшие упущения накапливаются в архитектуре, процессах и командах. Прежде чем разбирать каждую категорию, вот краткий список симптомов, указывающих на более глубокие проблемы:
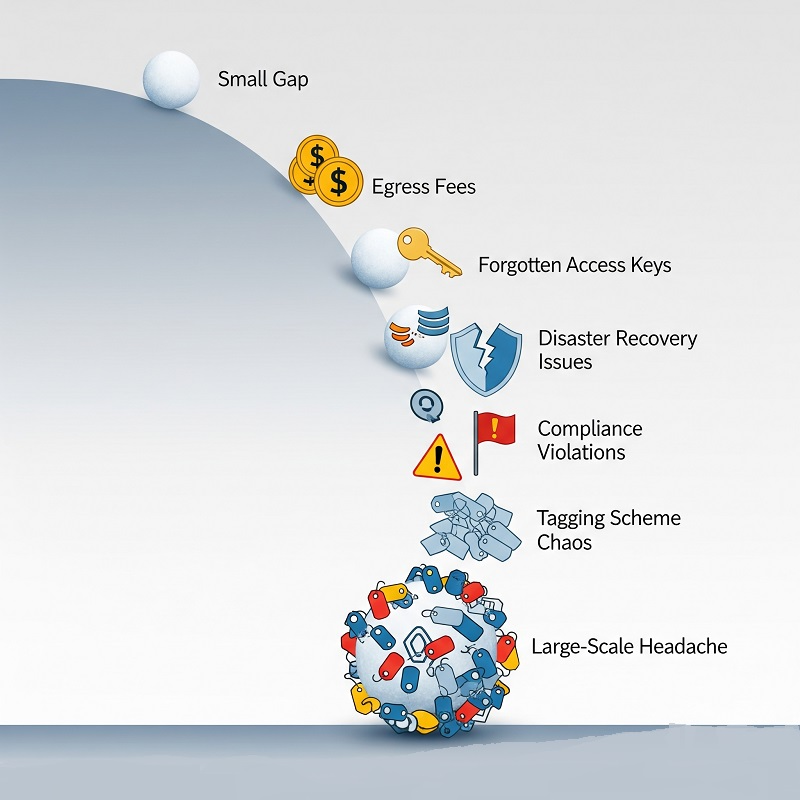
- Внезапный скачок платы за исходящий трафик съедает двухмесячную прибыль.
- Забытый ключ доступа запускает ночной майнинг криптовалюты.
- Сбой в целом регионе проверяет план аварийного восстановления, который никто не отрабатывал на практике.
- Аудит соответствия выявляет непомеченные чувствительные данные в объектном хранилище.
- Десять команд используют десять разных схем тегирования, и отчёты по распределению затрат превращаются в нечитаемый набор символов.
Каждый симптом связан с одной или несколькими ключевыми категориями рисков. Держите эту карту под рукой — она поможет на каждом этапе снижения рисков.
Риски облачных вычислений
Отраслевые исследования неизменно выделяют семь ключевых категорий рисков, которые охватывают большинство инцидентов во всех сферах. Хотя эти категории пересекаются между собой, вместе они описывают основные проблемы облачных вычислений с которыми команды сталкиваются ежедневно — от неконтролируемых расходов до утечки данных:
Неправильная настройка и избыточные привилегии
Даже опытные инженеры иногда ошибаются при настройке консоли. Слишком разрешительная группа безопасности или публичный бакет хранилища превращают внутренний инструмент в уязвимость, доступную из интернета.
Типичные ошибки
- Wildcard- 0.0.0.0/0 правила на административных портах.
- IAM-роли с полным доступом, которые никто не отозвал после завершения миграции.
Утечки и компрометация данных
Стоит появиться ошибке в настройках — и данные уходят. Утечки данных — постоянная проблема в облачной безопасности. Как правило, их причиной становятся не сложные zero-day атаки, а открытые эндпоинты или устаревшие учётные данные.
Внутренние угрозы и теневые администраторы
Не все риски приходят снаружи. Подрядчики с незакрытыми привилегиями или сотрудники, запускающие несогласованные сервисы, создают слепые зоны, которые стандартный мониторинг не замечает.
Небезопасные API и уязвимости цепочки поставок
Каждое облачное приложение опирается на сторонние SDK и API. Отсутствие ограничений на количество запросов или неисправленные библиотеки открывают путь для злоупотреблений, превращая безобидную функцию в вектор атаки.
Ограниченная видимость и пробелы в мониторинге
Если логи хранятся в одном аккаунте, а алерты настроены в другом, инциденты затягиваются, пока команды ищут нужный контекст. Слепые зоны скрывают как деградацию производительности, так и активные вторжения.
Проблемы безопасности, которые не дают командам спать по ночам
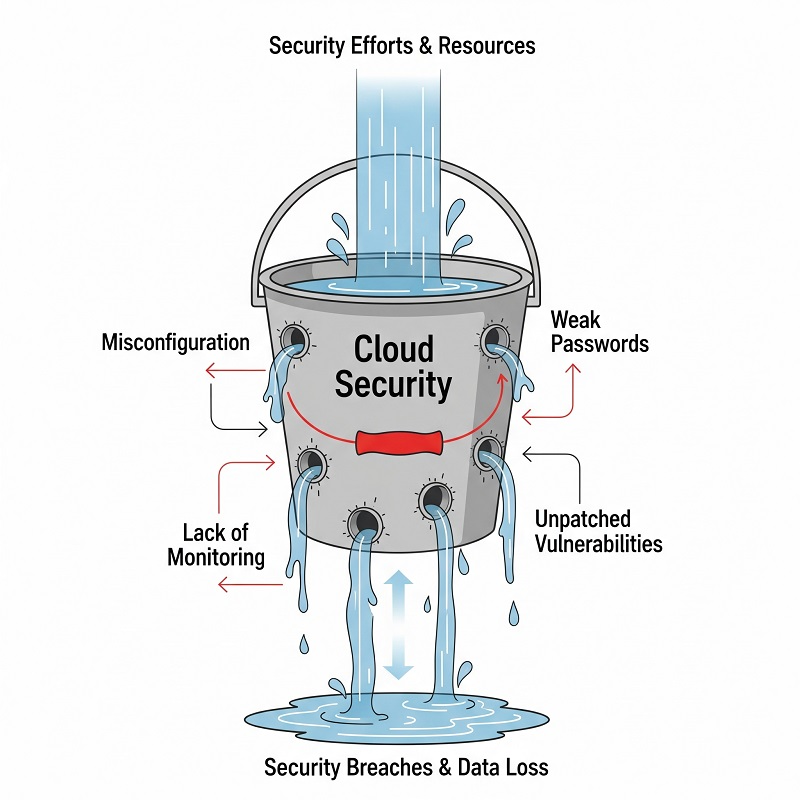
Принципы, изложенные в нашей статье о что такое облачная безопасность дают надёжную отправную точку, однако подготовленные злоумышленники всё равно находят лазейки — если компании не автоматизируют анализ логов, MFA и принцип минимальных привилегий. Без этих ограничений основные проблемы безопасности в облачных вычислениях перестают быть абстрактными и становятся срочными. Современные Инструменты облачной безопасности помогают сократить время обнаружения угроз, но только если команды встраивают их в ежедневный рабочий процесс.
Ключевые выводы:
- Составьте карту всех внешних эндпоинтов и еженедельно проверяйте их на наличие непреднамеренных открытых доступов.
- Ротируйте ключи автоматически; долгоживущие учётные данные — это технический долг.
- Передавайте аудит-логи в централизованную SIEM-систему и настройте оповещения об аномалиях, а не о сырых ошибках.
Операционные и финансовые сюрпризы
Высокая доступность кажется простой задачей — до тех пор, пока multi-AZ кластер базы данных не начинает удваивать счёт. Среди основные проблемы облачных вычислений скрытых на виду проблем дрейф затрат занимает одно из первых мест. Тикеты в поддержку накапливаются каждый раз, когда семейства инстансов устаревают или когда ограничения по ёмкости тормозят масштабирование.
Команды, которым нужен точечный контроль, иногда переносят чувствительные к задержкам сервисы на облегчённую VPS Cloud конфигурацию. Привязывая нагрузки к гарантированным CPU, они избегают эффекта «шумного соседа» и сохраняют свободу выбора провайдера.
Типичные операционные проблемы в облаке
- Недостаточные лимиты, блокирующие внезапные всплески трафика.
- Привязка к вендору, из-за которой изменения на уровне data plane обходятся дорого и занимают много времени.
- Непредвиденные расходы на межрегиональную передачу данных во время тестов аварийного переключения.
Goоверанс и подводные камни соответствия требованиям
У аудиторов свой язык, а облако добавляет к нему ещё один слой жаргона. Когда политики тегирования, хранения и шифрования начинают расходиться с требованиями, количество замечаний быстро растёт. В таблице ниже — четыре распространённых пробела, с которыми я сталкиваюсь при проверках готовности:
| Пробел в соответствии | Типичная причина | Вероятность | Влияние на бизнес |
| Неклассифицированные персональные данные в объектном хранилище | Отсутствие инвентаризации данных | Средняя | Штрафы, репутационный ущерб |
| Отсутствие MFA на привилегированных аккаунтах | Скорость в ущерб процессу | Высокая | Захват аккаунта |
| План аварийного восстановления никогда не тестировался | Нагрузка на ресурсы | Средняя | Продолжительные простои |
| Проприетарные функции глубоко встроены в инфраструктуру | Удобство на этапе разработки | Низкая | Дорогостоящий выход и замедленная миграция |
Обратите внимание: каждая строка таблицы соответствует одной из описанных выше проблем. Прозрачность, принцип минимальных привилегий и воспроизводимое тестирование — это основа любого успешного аудит-цикла.
Решение болевых точек
Универсального решения не существует, но многоуровневый подход быстро снижает риски. Я разбиваю тактики на три группы:
- Укрепить фундамент
- Описывайте всю инфраструктуру как код и настройте алерты на дрейф конфигурации — они поймают незаметные изменения.
- Применяйте MFA на уровне провайдера идентификации, а не в каждом приложении отдельно.
- Автоматизировать обнаружение и реагирование
- Централизуйте логи и агрегируйте их по тегам ресурсов, чтобы алерты объясняли, что сломалось, а не только где это произошло.
- Каждую неделю поднимайте копии среды в sandbox и тестируйте на них наборы патчей до выхода в продакшн.
- Готовиться к неизбежному
- Проводите учебные сценарии: отключайте сервис и смотрите, как реагируют дашборды. Такие уроки запоминаются лучше любых презентаций.
- Держите наготове чистый портативный образ. Опция Купить облачный сервер в один клик работает как предохранительный клапан, когда целый регион выходит из строя.
Начните с тактик, которые подходят вашему стеку прямо сейчас, а потом расширяйте охват. Небольшие улучшения — авто-теггинг или ежедневная ротация ключей — со временем дают ощутимый эффект.
Заключение
Облачные технологии продолжают набирать популярность, поэтому игнорировать связанные с ними проблемы — не вариант. Сопоставьте свою среду с основные проблемы облачных вычислений описанных здесь подходов, вы обнаруживаете слабые места заблаговременно, держите расходы под контролем и даёте разработчикам уверенно выпускать новые функции. Этот путь не заканчивается никогда, но при чётком понимании ситуации, надёжном инструментарии и привычке к регулярным проверкам облако остаётся ускорителем, а не источником ночных инцидентов.
Скорость, стабильность и надёжная защита заложены в основу облачного портфолио VPS. Каждый инстанс работает на хранилище NVMe, высокочастотных CPU и резервных маршрутах Tier-1: нагрузки запускаются быстро и остаются отзывчивыми даже при пиковом трафике. Межсетевые экраны корпоративного уровня, изолированные тенанты и непрерывное применение патчей защищают стек, не снижая производительности. Если вам нужен Облачный сервер который отвечает всем требованиям безопасности и надёжности, ищите не дальше!


