
Otevřete stránku GGUF oblíbeného modelu na Hugging Face a zírá na vás patnáct souborů: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus samostatné složky pro GPTQ, AWQ a EXL2 v půltuctu bitových nastavení. Provedete odhad pro „4bitový“ soubor na ubrousku: 4 bity × 8 miliard parametrů ÷ 8 = 4 GB. Jenže soubor uvádí 4,6 GB. A jakmile ho načtete, model spotřebuje ještě víc paměti.
Názvy souborů nejsou šum. Kódují reálné, naučitelné informace o šířce bitů, běhovém prostředí, které je načítá, a hardwaru, jaký potřebují. Tabulky velikostí, které jste četli, vám řeknou, že model 70B potřebuje zhruba 40 GB, což je užitečné, ale nikdy nedekódují samotný formát ani nevysvětlí, proč běžící model chce víc paměti, než kolik váží soubor na disku.
Takže tady je plán: rozluštit pojmenovávací konvenci GGUF (se skutečnou, ne nominální šířkou bitů), zjistit, který ze čtyř formátů váš hardware skutečně zvládne, a započítat jednu paměťovou položku, která je neviditelná v každé velikosti souboru, KV cache. Na konci budete umět přečíst repozitář modelu a předpovědět, jak se zachová po načtení.
Stručně
- Úrovně kvantizace GGUF jsou efektivní šířky bitů, ne přesné číslo v názvu. Q4_K_M je zhruba 4,89 bitu na váhu, a proto „4bitový“ soubor 8B skončí na zhruba 4,6 GiB místo naivního 4bitového odhadu.
- GGUF je nejpřenosnější možnost, protože llama.cpp ho dokáže spustit na CPU, GPU nebo hybridní sestavě. GPTQ, AWQ a EXL2 jsou víc vázané na GPU a konkrétní běhové prostředí, přičemž EXL2 je obzvlášť svázán s pracovními postupy NVIDIA/CUDA.
- KV cache je oddělená od vah modelu a roste s délkou kontextu. Proto model, který se čistě načte, může přesto spadnout na nedostatek paměti, jakmile se konverzace protáhne.
- Nad rozsahem 5 bitů je ztráta kvality obvykle malá. Kolem Q4 je kompromis pro řadu lokálních použití stále praktický. Pod 4 bity se cena za kvalitu stává mnohem znatelnější. Q4_K_M zůstává běžnou výchozí volbou komunity, zatímco Q5_K_M a Q6_K jsou bezpečnější, pokud máte paměť nazbyt.
Co znamená Q4_K_M v názvu souboru GGUF?

Název kvantizace GGUF se řídí vzorem Q[bity]_[K]_[S/M/L]. Číslo je cílová hodnota bitů na váhu, K znamená, že jde o „K-kvant“, který ukládá škálovací faktory pro každý malý blok vah, a koncové S, M nebo L určuje úroveň velikosti/kvality (malá, střední, velká). Protože K-kvanty ukládají u každého bloku vedle vah škálu a minimální hodnotu, efektivní šířka bitů je vyšší, než uvádí hlavní číslo. Q4_K_M skončí na zhruba 4,89 bitu na váhu, ne 4.
Tento rozdíl je celou odpovědí na otázku „proč můj 4bitový soubor váží 4,6 GB?“. Naivní odhad předpokládá, že každá váha stojí přesně 4 bity. Ve skutečnosti K-kvanty utrácejí extra bity na blok za metadata, díky nimž je nízkobitová kvantizace přesná, škálu a minimum na blok, které umožňují runtime rekonstruovat každou váhu. Vynásobte 4,89 bitu osmi miliardami vah a dostanete se na zhruba 4,58 GiB, což je to, co soubor skutečně váží.
Zde jsou naměřené efektivní šířky bitů a velikosti souborů, převzaté z llama.cpp quantize documentation , pro Llama 3.1 8B jako referenční model, spolu s nákladem na perplexitu u každé úrovně naměřeným ve vyhodnocovací studii kvantizace llama.cpp (arXiv:2601.14277) na Llama-3.1-8B-Instruct:
| Úroveň GGUF | Efektivní BPW | ~Velikost souboru (8B) | Perplexita vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | výchozí hodnota |
*Hodnoty perplexity platí konkrétně pro Llama-3.1-8B-Instruct z arXiv:2601.14277. Sloupec BPW/velikost souboru a sloupec perplexity pocházejí ze dvou různých zdrojů měřených odděleně, takže tabulku čtěte spíš jako praktický souhrnný přehled vedle sebe než jako jeden jediný běh benchmarku. Degradace se liší podle úlohy, matematické uvažování obvykle trpí při nízkých šířkách bitů víc než zdravý úsudek, ale obecný obrazec platí: 5 bitů a víc je obvykle bezpečnější, Q4 je praktická kompresní zóna a u 3 bitů se ztráta kvality stává mnohem hůř přehlédnutelnou.
Prakticky: Q4_K_M je výchozí volba, po které by měla sáhnout většina lidí, Q5_K_M a Q6_K jsou volby nakloněné kvalitě, pokud máte paměť nazbyt, a cokoli na úrovni Q3_K_S nebo pod ní je poslední záchranou pro hardware, který se skutečně na víc nevejde.
Který formát kvantizace byste si měli stáhnout: GGUF, GPTQ, AWQ nebo EXL2?

GGUF je ze čtyř formátů nejpřenosnější: běží na CPU, GPU nebo hybridní kombinaci obojího přes llama.cpp, takže je nejbezpečnější volbou, když si nejste jistí, co váš hardware zvládne. GPTQ, AWQ a EXL2 jsou víc vázané na GPU a konkrétní běhové prostředí. V praxi jsou nejběžnější na sestavách NVIDIA/CUDA, ale podpora GPTQ a AWQ se může lišit podle loaderu a serving stacku; vLLM například rozlišuje podporu kvantizace podle hardwaru a implementace. Pokud běžíte lokálně na Macu, kartě AMD nebo krabičce jen s CPU, GGUF je stále nejbezpečnější odpověď. Pokud máte GPU NVIDIA a chcete co nejrychlejší tokeny, přichází na řadu ostatní tři formáty.
| Formát | Hardware/runtime | Rychlost (relativní) | VRAM ve srovnání s ostatními | Nejlepší pro |
|---|---|---|---|---|
| GGUF Q4_K_M | Nejširší, CPU, GPU nebo hybrid přes llama.cpp | Umírněný | Nejnižší | Jakýkoli hardware; lokální výchozí volba |
| GPTQ 4-bit | Obvykle přednostně CUDA/GPU; závisí na runtime | Rychlé (ExLlama) | Střední | Přednostně GPU, starší nástroje |
| AWQ 4-bit | Obvykle přednostně CUDA/GPU; závisí na runtime | Rychlý | Nejvyšší | Servírování přes vLLM/TGI, rychlé načtení |
| EXL2 ~4,9 bpw | Přednostně NVIDIA/CUDA | Nejrychlejší | Nízko-Střední | Maximální rychlost na NVIDIA |
Výhrada k této tabulce: pořadí rychlosti a VRAM pochází z benchmarku oobabooga, který běžel na hardwaru z let 2023/2024. Berte to relativní pořadí jako trvalé. EXL2 je stavěné na rychlost, AWQ vyměňuje VRAM za rychlé načítání, GGUF zůstává úsporné a přenosné, ale nečtěte původní absolutní čísla tokenů za sekundu jako aktuální. GPU z roku 2026 předvede úplně jinou surovou propustnost; do budoucna přetrvává právě to pořadí.
Z toho tedy plyne rozhodovací pravidlo: pokud máte kartu NVIDIA a nejvíc vám záleží na rychlosti, EXL2; pokud chcete nejbezpečnější lokální výchozí volbu napříč různým hardwarem, GGUF. AWQ a GPTQ hrají roli hlavně tehdy, když vás tam nasměruje konkrétní serving stack (vLLM, TGI) nebo existující nástroje.
Proč lokální LLM spotřebuje víc paměti, než je jeho soubor?
Velikost souboru je jen váhy modelu. Za běhu navíc platíte za KV cache (stav pozornosti pro každý token ve vašem kontextovém okně), aktivace (mezivýpočty dopředného průchodu) a režii frameworku a ovladače. Dohromady tyto nevahové položky u jednouživatelské sestavy obvykle přidají 10 až 20 % navrch k vahám a samotná KV cache dokáže vše ostatní zastínit, jakmile se kontext protáhne. Soubor o velikosti 4,6 GB může ke svému běhu potřebovat mnohem víc než 4,6 GB paměti.
Představte si paměť za běhu jako čtyři komponenty naskládané na sebe:
- Váhy modelu. Soubor, který jste stáhli. To je jediná část viditelná ještě před načtením.
- KV cache. Stav pozornosti pro kontextové okno. Malý při krátkém kontextu, obrovský při dlouhém kontextu. To je téma další sekce, protože právě to lidi zaskočí.
- Aktivace. Pracovní paměť dopředného průchodu. Pro jednoproudou lokální inferenci (velikost dávky 1) je malá, typicky pár stovek megabajtů.
- Režie frameworku. Vlastní paměťová stopa runtime plus kontext ovladače GPU. U lehkého lokálního runtime může být malá ve srovnání s vahami modelu a KV cache; těžší serving frameworky mohou rezervovat mnohem víc. Vlastní paměťová rezervace operačního systému stojí mimo toto a je opět samostatná.
Váhy a režie frameworku jsou předvídatelné. KV cache je proměnná, která z modelu, který se „vejde“, udělá model, který spadne, takže se vyplatí projít si skutečnou matematiku.
Kolik paměti spotřebuje KV cache?
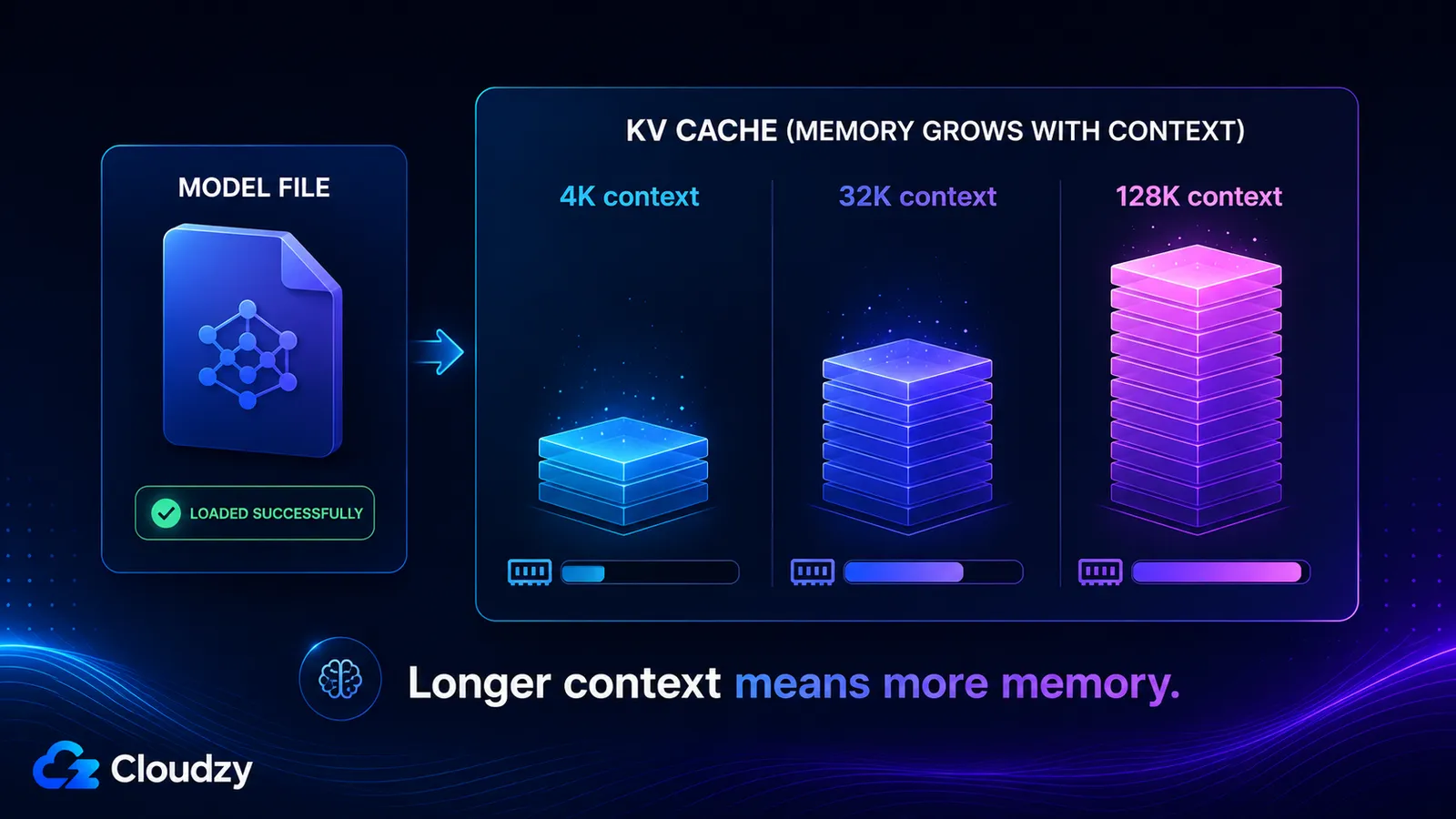
KV cache ukládá vektory klíčů a hodnot pro každý token ve vašem kontextovém okně, takže roste zhruba lineárně s délkou kontextu a je zcela oddělená od vah modelu. Její velikost určuje počet vrstev modelu, počet KV hlav, dimenze hlavy, délka kontextu a přesnost cache. Zapněte dlouhý kontext a můžete přidat desítky gigabajtů, na které vás model, který se v pořádku načetl, nikdy nevaroval.
Vzorec je dost krátký na to, abyste si ho pamatovali:
bajty KV cache = 2 × vrstvy × kv_heads × head_dim × context_tokens × bytes_per_element
Úvodní 2 je za dva tenzory uložené na token, jeden pro klíče, jeden pro hodnoty. bytes_per_element je 2 pro cache ve FP16. Zbytek jsou architektonické konstanty, které vyčtete z model card.
Vypočítejme to pro Llama 3.1 8B, která má 32 vrstev, 8 KV hlav a dimenzi hlavy 128. Při kontextu 4 096 tokenů, velikosti dávky 1, cache FP16:
2 × 32 × 8 × 128 × 4096 × 2 bajty ≈ 536 MB
Zvyšte kontext a číslo poroste s ním, protože všechny členy kromě context_tokens jsou pevné:
- Kontext 4K: ~536 MB
- Kontext 32K: ~4,3 GB
- Kontext 128K: ~17 GB
Poslední dvě čísla vysvětlují, proč model může deklarovat kontextové okno 128K, v pohodě se načíst, a pak vyčerpat paměť ve chvíli, kdy to okno skutečně použijete. KV cache při plném kontextu je větší než samotné kvantizované váhy.
Tady je část, díky které jsou moderní modely s dlouhým kontextem vůbec možné: Llama 3.1 8B používá Grouped Query Attention (GQA)Má 32 dotazovacích hlav, ale jen 8 KV hlav, cache ukládá vektory klíč/hodnota jen pro 8 hlav, ne pro 32. Spusťte stejný vzorec s 32 KV hlavami (starší návrh Multi-Head Attention, kde se počet KV hlav rovná počtu dotazovacích hlav) a každé číslo výše se vynásobí čtyřmi. Těch 17 GB při 128K se stane 68 GB. GQA je architektonický důvod, proč matematika zůstává zvládnutelná i s tím, jak rostou kontextová okna.
Velikost souboru není váš paměťový rozpočet. Když se váhy nebo KV cache už nevejdou do rychlé paměťové cesty a runtime se musí uchýlit k systémové RAM přes PCIe, propustnost nedegraduje pozvolna. Prudce se zřítí, jakmile přesouváte data přes PCIe u každého tokenu. Naplánujte paměť tak, aby se vešly jak váhy, tak KV cache při vaší skutečné délce kontextu, ne jen samotné váhy.
Jak vybrat kvantizaci pro svou GPU nebo Mac?
Vyjděte ze svého hardwaru a runtime. Majitelé GPU NVIDIA mají nejširší nabídku a měli by zvážit EXL2 pro syrovou rychlost nebo GGUF pro přenositelnost. Pokud máte AMD, Apple Silicon, hardware jen s CPU nebo smíšenou sestavu, GGUF přes llama.cpp je obvykle nejbezpečnějším výchozím bodem. Odtud vyberte nejvyšší úroveň kvantizace, která se vejde poté, co jste naplánovali KV cache pro délku kontextu, kterou skutečně používáte, ne pro maximum modelu.
Jedna past u Apple Silicon, o které stojí za to vědět: GPU nedostane celou vaši sjednocenou paměť (podrobný obrázek toho, jak sdílený fond funguje, najdete v našem doprovodném článku o tom co je sjednocená paměť ve skutečnosti ). Komunita self-hostingu zdokumentovala limit kolem 75 % z celkové sjednocené paměti dostupné pro GPU (Apple to oficiálně nepotvrzuje a hodnota se může s aktualizacemi macOS měnit). Takže „64GB Mac“ má reálně zhruba 48 GB pro model plus jeho KV cache, plánujte podle toho menšího čísla.
Tento článek je o tom, jak číst formát a předvídat jeho chování za běhu: rozluštit název kvantizace, vybrat formát, který podporuje váš hardware, a naplánovat KV cache odděleně od vah. Přiřazení konkrétního modelu ke konkrétnímu množství paměti, vyhledávací tabulka velikosti k paměti, je související, ale samostatná otázka, kterou probereme v budoucím doprovodném článku.
Přečtěte si repozitář
Teď se dokážete podívat na stránku modelu a přečíst si ji, místo abyste hádali. Rozluštěte název kvantizace na jeho efektivní šířku bitů, uvědomte si, že GGUF je nejširší lokální formát, zatímco GPTQ, AWQ a EXL2 jsou víc vázané na konkrétní runtime, a pamatujte, že velikost souboru je jen podlaha, KV cache se skládá nahoru a roste s vaším kontextem. Otevřete soubory pro model, který chcete, vyberte formát, který váš hardware zvládne, zvolte nejvyšší úroveň kvantizace, která se vejde poté, co jste nechali prostor pro KV cache při vaší skutečné délce kontextu, a vyhnete se pádu na nedostatek paměti, který celou tuto otázku spustil.
Časté dotazy
Co znamená Q4_K_M?
Q4_K_M je úroveň kvantizace GGUF: zhruba 4 bity na váhu (Q4), s použitím škálování K-kvant na blok (K), na střední úrovni velikosti/kvality (M). Jeho efektivní je zhruba 4,89 bitu na váhu, ne přesně 4, protože K-kvanty ukládají u každého bloku vah škálu a minimální hodnotu. Proto je soubor „4bitového“ modelu 8B kolem 4,6 GB, ne 3,5 GB.
Snižuje kvantizace kvalitu LLM?
Ano, ale náklad silně závisí na tom, jak daleko to dotáhnete. U Llama-3.1-8B-Instruct naměřeného v arXiv:2601.14277 stoupá perplexita jen o zhruba 0,4 % u Q6_K a zůstává kolem 1 % v celém pásmu Q5. Klesněte na Q4 a nárůst je stále skromný (pár procent); pod Q3_K_M prudce stoupá, u Q3_K_S dosahuje +22 %. Pro většinu použití je Q4_K_M a výš efektivně bezztrátové; strmá penalizace nastupuje na 3 bitech a níž.
Jaký je rozdíl mezi GGUF, GPTQ, AWQ a EXL2?
GGUF (spouštěný přes llama.cpp) je přenosný formát, funguje na CPU, GPU nebo hybridní sestavě napříč širokou škálou hardwaru. GPTQ, AWQ a EXL2 jsou víc vázané na GPU a konkrétní runtime. Při 4 bitech se všechny čtyři mohou vejít do úzkého pásma kvality, takže praktický rozdíl spočívá v hardwaru, podpoře loaderu, rychlosti a využití VRAM: EXL2 je volba zaměřená na rychlost pro NVIDIA/CUDA, AWQ je běžný v serving stackách, GPTQ sedí do starších nástrojů pro GPU a repozitářů modelů a GGUF zůstává nejpřenosnější lokální možností.
Proč můj lokální LLM spotřebuje víc paměti, než je soubor?
Velikost souboru jsou jen váhy modelu. Za běhu navíc platíte za KV cache (stav pozornosti pro každý token v kontextovém okně), aktivace a režii frameworku plus ovladače. KV cache je obvyklý viník, když je rozdíl velký, protože roste s délkou kontextu a alokuje se odděleně od vah, model, jehož soubor má pár gigabajtů, může potřebovat mnohem víc paměti, jakmile nastavíte dlouhý kontext.
Jak délka kontextu ovlivňuje spotřebu paměti?
KV cache roste zhruba lineárně s délkou kontextu, takže zdvojnásobení kontextu zhruba zdvojnásobí cache. U Llama 3.1 8B je cache zhruba 536 MB při 4K tokenech, ~4,3 GB při 32K a ~17 GB při 128K (FP16, jeden proud). Tento růst je zcela oddělený od vah modelu, a proto může deklarování dlouhého kontextového okna zahnat model do nedostatku paměti, i když se v pořádku načetl.


