
Výběr GPU VPS se může zdát přemáhavý, když se díváte na seznamy specifikací plné čísel. Počet jader skáče z 2 560 na 21 760, ale co to znamená?
CUDA core je jednotka paralelního zpracování uvnitř NVIDIA GPUu, která provádí tisíce výpočtů současně a pohání vše od trénování AI až po 3D rendering. Tato příručka vysvětluje, jak fungují, jak se liší od CPU a Tensor cores, a která počta jader odpovídají vašim potřebám bez přeplacení.
Co jsou CUDA jádra?

CUDA cores jsou jednotlivé procesní jednotky uvnitř NVIDIA GPUu, které paralelně vykonávají instrukce. Jaké je jádro technologie CUDA cores? Představte si tyto jednotky jako malé pracovníky, kteří zpracovávají části stejného úkolu současně.
NVIDIA v roce 2006 představila CUDA (Compute Unified Device Architecture), aby využila výkon GPU pro obecné výpočty mimo grafiku. Oficiální dokumentace CUDA poskytuje podrobné technické informace. Každá jednotka provádí základní aritmetické operace s čísly v plovoucí řádové čárce, ideální pro opakované výpočty.
Moderní NVIDIA GPUy obsahují tisíce těchto jednotek na jednom čipu. Spotřebitelské GPUy poslední generace obsahují přes 21 000 jader, zatímco dataCenterové GPUy na základě architektury Hopper mají až 16 896jader. Tyto jednotky pracují společně prostřednictvím Streaming Multiprocessors (SMs).
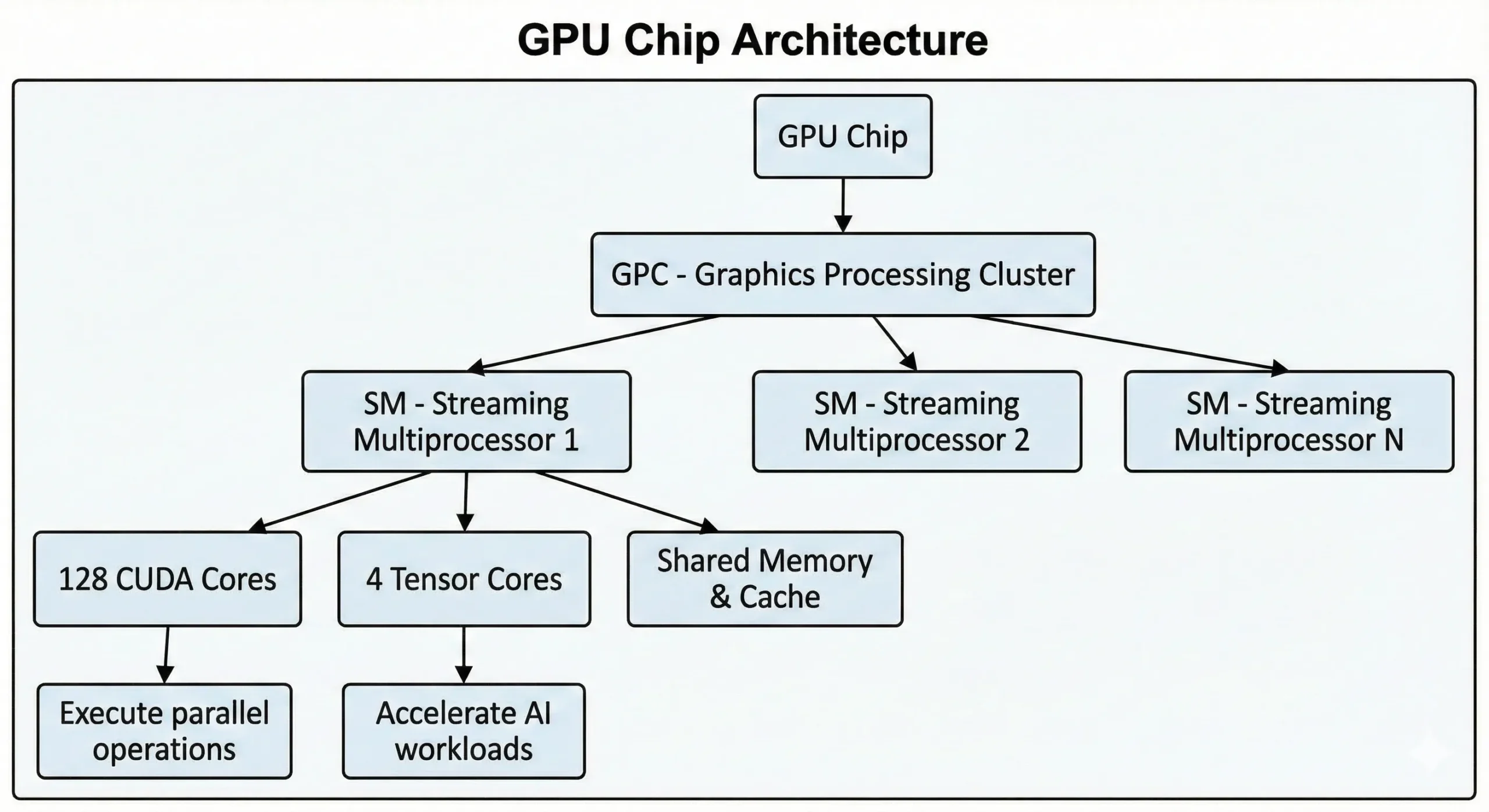
Jednotky provádějí operace SIMT (Single Instruction, Multiple Threads) prostřednictvím metod paralelního počítání. Jedna instrukce se spouští najednou na mnoha datových bodech. Při trénování neuronových sítí nebo vykreslování 3D scén dochází k tisícům podobných operací. Práce se rozdělí do souběžných toků, které se provádějí současně místo postupně.
CUDA Cores vs CPU Cores: Jaký je mezi nimi rozdíl?

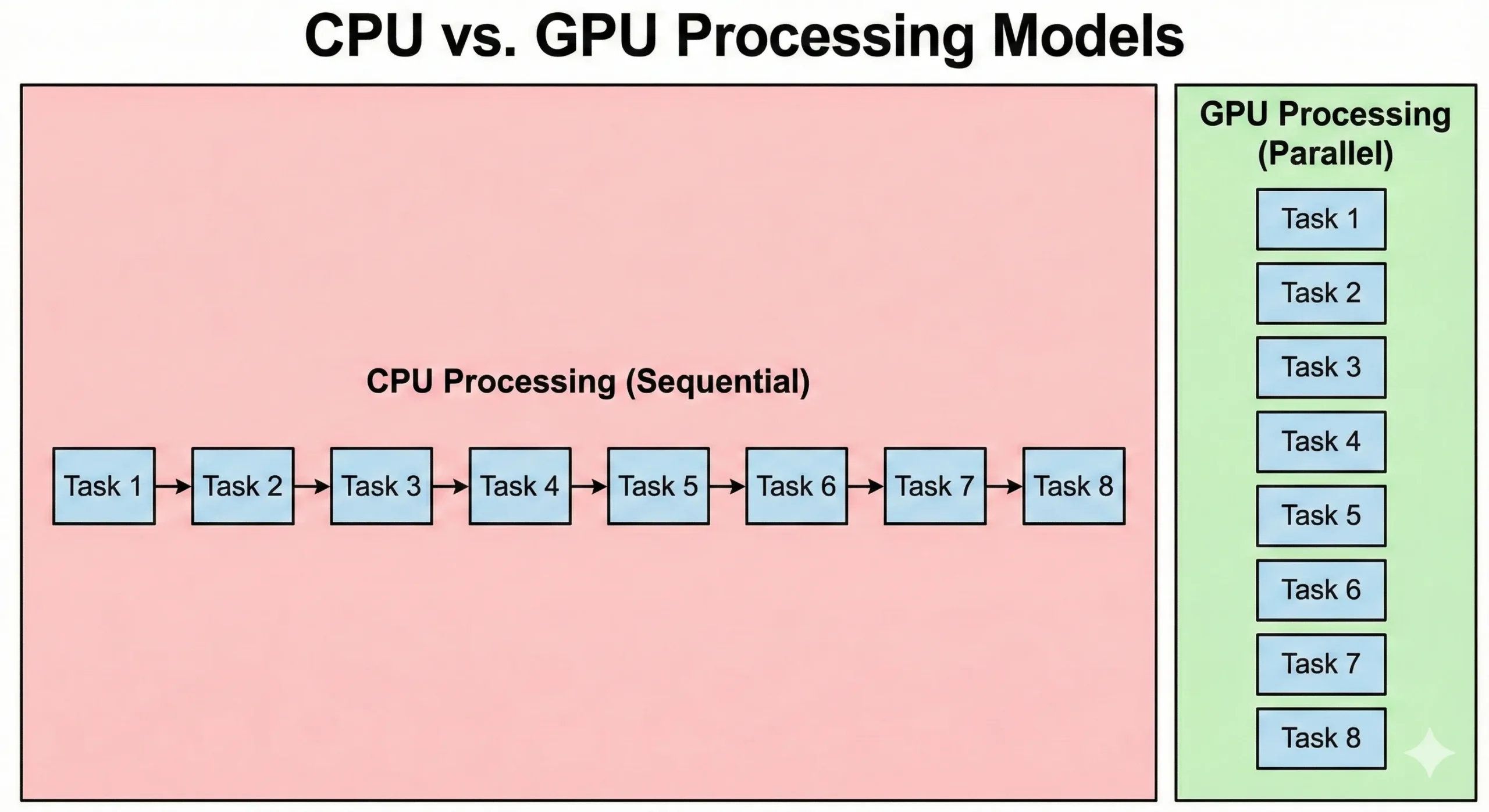
CPUs a GPUs řeší problémy zásadně odlišnými způsoby. Moderní server CPU může mít 8–128+ jader spuštěných na vysokých taktovacích frekvencích. Tyto procesory vynikají v sekvenčních operacích, kde každý krok závisí na předchozím výsledku. Efektivně zvládají složitou logiku a větvení.
GPUs mění tento přístup. Obsahují tisíce jednodušších CUDA jader spuštěných na nižších taktovacích frekvencích. Tyto jednotky kompenzují nižší rychlosti paralelismem. Když pracují společně 16 000 jader, celkový výkon překonává možnosti standardního CPU.
CPUs spouštějí kód operačního systému a složitou logiku aplikací. Zatímco GPUs upřednostňují propustnost, režie z inicializace úloh a synchronizace vede na vyšší latenci. Paralelní grafické zpracování upřednostňuje přesun dat. Ačkoli jejich spuštění trvá déle, zpracovávají velké datové sady rychleji než CPUs.
| Funkce | Jádra CPU | CUDA jádra |
| Počet na čip | 4-128+ jader | 2 560–21 760 jader |
| Taktovací frekvence | 3,0–5,5 GHz | 1,4–2,5 GHz |
| Styl zpracování | Postupné, komplexní instrukce | Jednoduché, paralelní pokyny |
| Nejlepší pro | Operační systémy, jednovláknové úlohy | Maticová matematika, paralelní zpracování dat |
| Latence | Nízká (mikrosekundy) | Vyšší (nářadí při spuštění) |
| Architektura | Univerzální | Optimalizované pro opakované výpočty |
Technologie Virtual GPU (vGPU) a Multi-Instance GPU (MIG) zajišťují rozdělování prostředků a plánování pro distribuci procesorů mezi více uživatelů. Toto řešení umožňuje týmům maximalizovat využití hardwaru buď prostřednictvím časového sdílení, nebo pomocí vyhrazených hardwarových instancí v závislosti na konfiguraci.
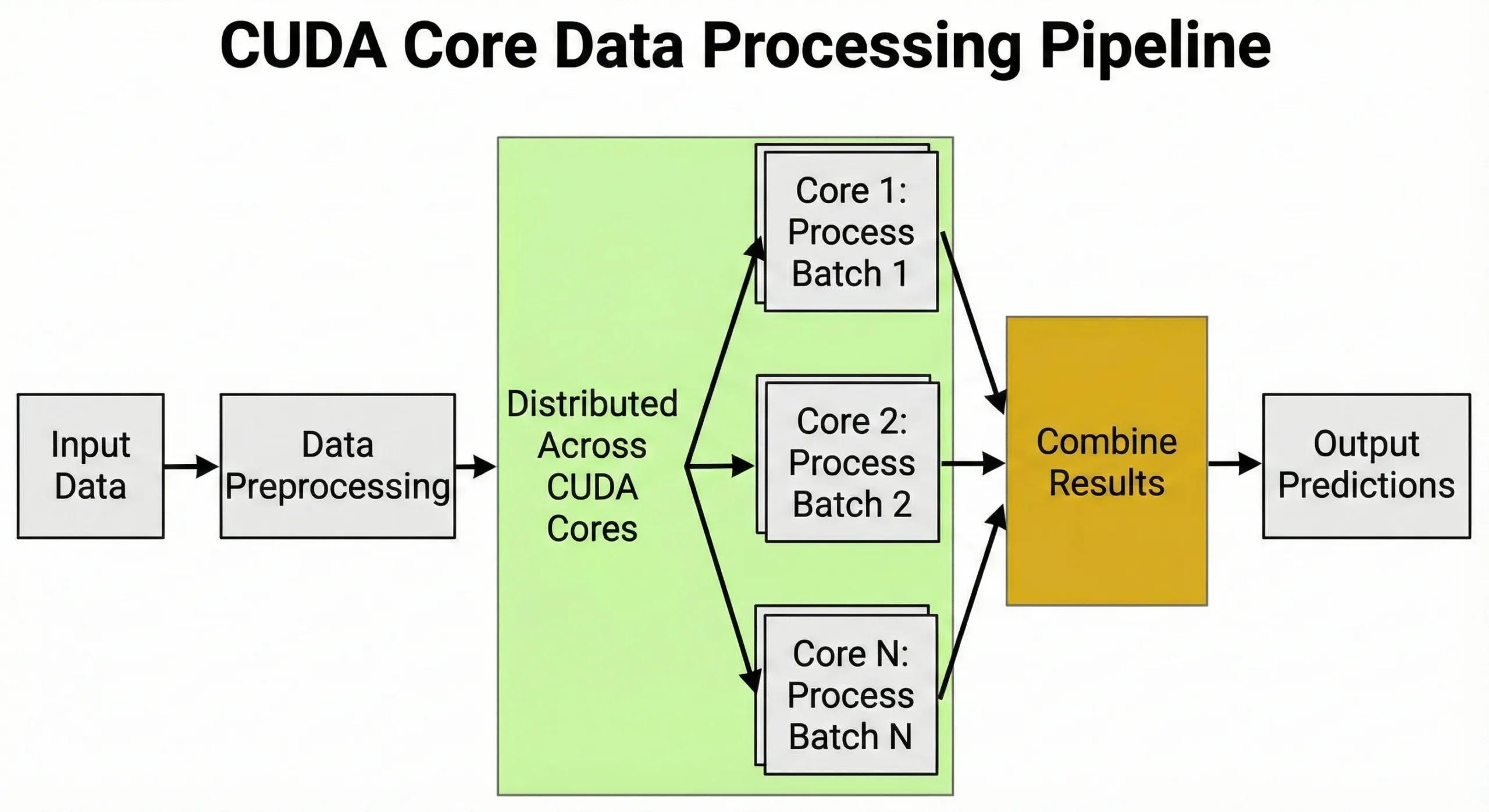
Trénink neuronových sítí zahrnuje miliardy maticových násobení. GPU s 10 000 jednotkami nekdy jednoduše nespustí 10 000 operací současně; místo toho spravuje tisíce paralelních vláken seskupených do "warpů", aby se maximalizovala propustnost. Právě tímto masivním paralelismem jsou tyto jednotky nezbytné pro vývojáře zaměřené na AI.
CUDA Cores vs Tensor Cores: Pochopte rozdíl

NVIDIA GPUs obsahují dva specializované typy jednotek, které pracují společně: standardní CUDA cores a Tensor cores. Nejde o konkurenční technologie; každá řeší jinou část úlohy.
Standardní jednotky jsou paralelní procesory pro obecné účely zpracovávající výpočty FP32 a FP64, celočíselnou matematiku a transformace souřadnic. Tato základní CUDA technologie tvoří základ výpočtů GPU a běží v řadě aplikací od fyzikálních simulací až po přípravu dat bez potřeby specializované akcelerace.
Tensor cores jsou speciální jednotky určené výhradně pro maticové operace a AI úlohy. Představeny v NVIDIA architektuře Volta (2017), vynikají při výpočtech s presností FP16 a TF32. Nejnovější generace podporuje FP8 pro ještě rychlejší AI inference.
| Funkce | CUDA jádra | Tensor Cores |
| Účel | Obecné paralelní výpočty | Maticové násobení pro AI |
| Přesnost | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Rychlost pro AI | 1x základní výkon | 2-10x rychlejší než CUDA jádra |
| Případy použití | Příprava dat, tradiční machine learning | Trénování a inference hlubokého učení |
| Dostupnost | Všechny NVIDIA GPUs | RTX řady 20 a novější, datové centrum GPUs |
Moderní GPUs spojují obojí. RTX 5090 má 21 760 standardních jader plus 680 Tensor jader páté generace. H100 páruje 16 896 standardních jader se 528 Tensor jádry čtvrté generace pro akceleraci hlubokého učení.
Při trénování neuronových sítí Tensor jádra pracují na nejnáročnějších operacích během dopředného a zpětného průchodu modelem. Standardní jádra se starají o načítání dat, předzpracování, výpočet ztráty a aktualizace optimizéru. Oba typy pracují společně, přičemž Tensor jádra zrychlují výpočetně náročné operace.
Při tradičních algoritmech strojového učení, jako jsou náhodné lesy nebo gradient boosting, se pracuje se standardními jádry, protože tyto algoritmy nepoužívají vzory maticového násobení, které by Tensor jádra zrychlovala. Ale u modelů transformerů a konvolučních neuronových sítí Tensor jádra poskytují dramatické zrychlení.
K čemu se používají CUDA jádra?

CUDA jádra pohánějí úkoly vyžadující velkého množství stejných výpočtů provedených současně. Jakákoliv práce zahrnující maticové operace nebo opakované numerické výpočty těží z jejich architektury.
Aplikace AI a strojového učení
Hluboké učení se opírá o maticové násobení během trénování a inference. Při trénování neuronových sítí každý dopředný průchod vyžaduje miliony operací násobení a sčítání přes váhové matice. Zpětná propagace přidá miliony dalších během zpětného průchodu.
Jádra spravují předzpracování dat, převod obrázků na tenzory, normalizaci hodnot a aplikaci transformací augmentace. Schopnost zvládat tisíce úkolů najednou je přesně důvod, proč jsou GPUs důležité pro AI.
Během trénování řídí plány učení, výpočty gradientů a aktualizace stavu optimizéru.
Pro VPS pro operace inference AI provozující systémy doporučení nebo chatboty zpracovávají požadavky souběžně, spouštějí stovky předpovědí současně. Náš průvodce na téma nejlepší GPU pro AI 2025 pokrývá, které konfigurace fungují pro různé velikosti modelů.
H100 s 16 896 jádry v kombinaci s Tensor jádry trénuje model se 7 miliardami parametrů v týdnech místo měsíců. Inference v reálném čase pro chatboty obsluhující tisíce uživatelů vyžaduje podobnou kapacitu souběžného spouštění.
Vědecké výpočty a výzkum
Výzkumní pracovníci používají tyto procesory na simulace molekulární dynamiky, modelování klimatu a analýzu genomiky. Každý výpočet je nezávislý, což je činí ideálními pro souběžné spouštění. Finanční instituce spouštějí simulace Monte Carlo s miliony scénářů současně.
3D rendering a produkce videa
Ray tracing počítá odraz světla skrz 3D scény sledováním nezávislých paprsků přes každý pixel. Zatímco dedikovaná RT jádra řeší procházení, standardní jádra spravují vzorkování textur a osvětlení. Toto rozdělení určuje rychlost scén s miliony paprsků.
NVENC zvládá kódování H.264 a H.265, zatímco nejnovější architektury (Ada Lovelace a Hopper) zavádějí hardwarovou podporu pro AV1. CUDA pomáhá s efekty, filtry, škálováním, odšumem, barevnými transformacemi a propojením pipeline. To umožňuje kódovacímu enginu pracovat vedle paralelních procesorů pro rychlejší produkci videa.
3D rendering v Blenderu nebo Maya rozděluje miliarly výpočtů shader povrchu přes dostupná jádra. Částicové systémy těží z toho, že simulují tisíce částic interagujících najednou. Tyto funkce jsou klíčové pro vysoce kvalitní digitální tvorbu.
Jak CUDA jádra ovlivňují výkon GPU

Počet jader vám dá hrubou představu o schopnosti souběžného spouštění, ale u CUDA jader je třeba jít dál než za čísla. Takt, šířka pásma paměti, efektivita architektury a optimalizace softwaru hrají zásadní roli.
GPU s 10 000 jednotkami běžícími na 2,0 GHz poskytuje jiné výsledky než jeden s 10 000 na 1,5 GHz. Vyšší takt znamená, že každá jednotka provede za sekundu více výpočtů. Novější architektury zvládnou více práce za cyklus díky lepšímu plánování instrukcí.
Zkontrolujte, zda zařízení využíváte naplno, ale nezapomeňte, že nvidia-smi využití je hrubá metrika. Měří procento času, kdy je jádro aktivní, ne kolik jader pracuje.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderPříklad výstupu: 85 %, 92 % (85 % čas aktivní, 92 % aktivita řadiče paměti)
Pokud váš GPU ukazuje 60–70 % využití, pravděpodobně máte úzké místa v toku dat, jako je načítání CPU dat nebo malé velikosti dávek. Avšak i 100 % využití může být zavádějící, pokud jsou vaše jádra vázána na paměť nebo jsou jednovláknová. Pro pravdivý obraz využití jader použijte profilery jako Nsight Systems ke sledování metrik SM Efficiency nebo SM Active.
Šířka pásma paměti se často stane úzkým místem dříve, než vyčerpáte výpočetní kapacitu. Pokud váš GPU zpracovává data rychleji, než je paměť dodává, jednotky zůstávají nečinné. Model H100 SXM5 používá šířku pásma 3,35 TB/s k napájení svých 16 896 jader. Verze PCIe se však sníží na 2 TB/s.
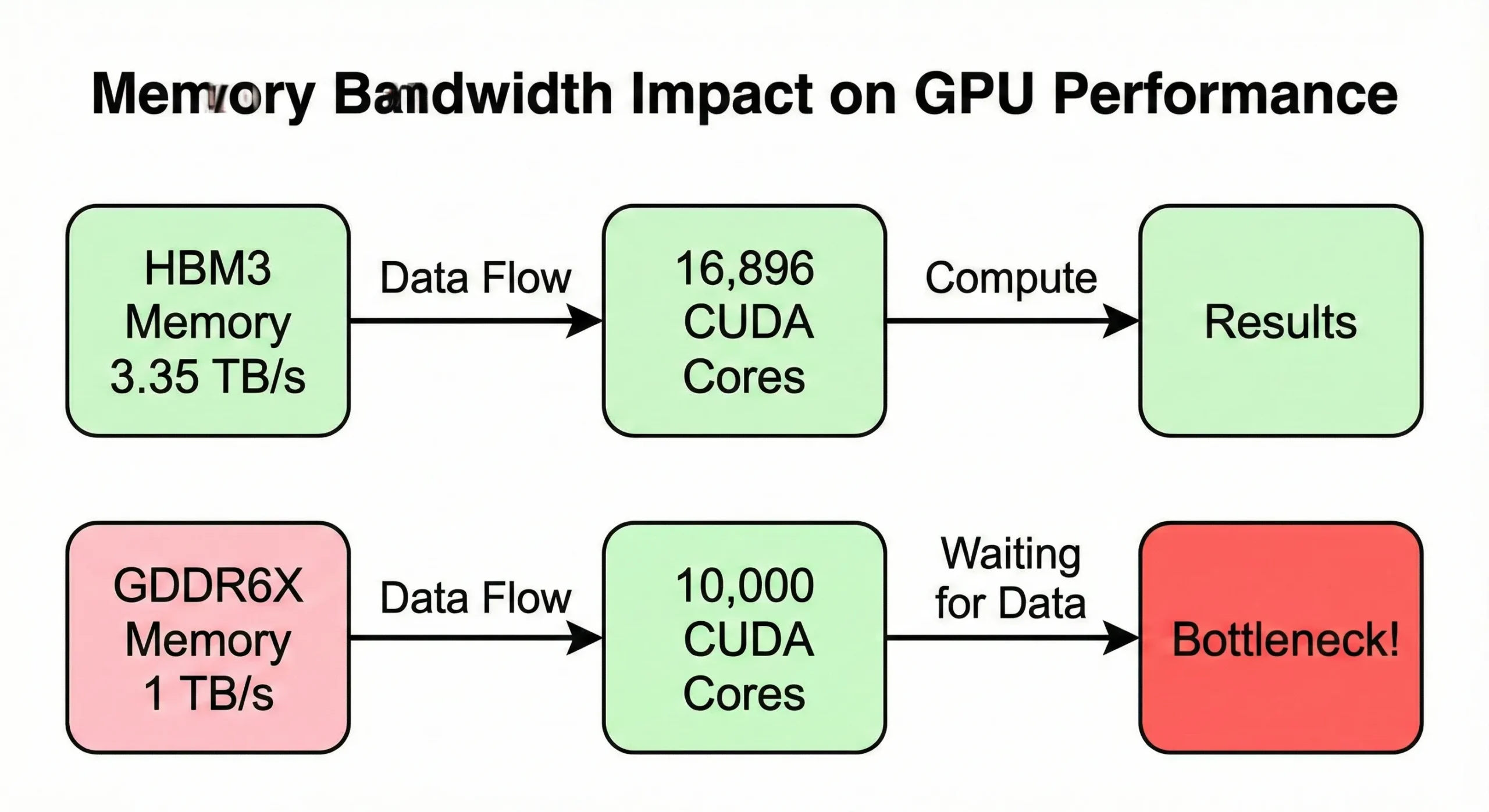
Spotřebitelské GPU se podobným počtem jader, ale nižší šířkou pásma (kolem 1 TB/s), vykazují redukovanou reálnou rychlost při operacích náročných na paměť.
Kapacita VRAM určuje velikost vašich úloh. Ať jde o váhy FP16 pro Model 70B, úplný trénink vyžaduje více paměti. Musíte počítat s gradienty a stavy optimizéru. Tyto stavy obvykle trojnásobí stopu paměti, pokud nepoužijete strategie offloadingu.
A100 s 80GB se zaměřuje na odvozování s vysokou propustností a dolaďování. Mezitím 24GB RTX 4090, často citován pro modely 7B, může překvapivě spustit modely 30B+ parametrů, pokud použijete moderní techniky kvantizace jako INT4. Nicméně když VRAM dojde, přenosy dat CPU-GPU zničí propustnost.
Optimalizace softwaru určuje, zda váš kód skutečně využívá všechny ty jednotky. Špatně napsaná jádra mohou aktivovat jen zlomek dostupných zdrojů. Knihovny jako cuDNN pro hluboké učení a RAPIDS pro datovou vědu jsou těžce optimalizovány pro maximální využití.
Více CUDA jader nemusí vždy znamenat lepší výkon

Koupit GPU s nejvyšším počtem jader se zdá logické, ale zbytečně utratíte peníze, pokud jednotky předběhnou ostatní součásti systému nebo se vaše úloha s počtem jader neškáluje.
Šířka pásma paměti vytváří první limit. 21 760 jednotky RTX 5090 je napájeno 1 792 GB/s šířky pásma paměti. Starší GPU s méně jednotkami mohou mít proporcionálně vyšší šířku pásma na jednotku.
Rozdíly v architektuře jsou důležité. Novější GPU s 14 000 jednotkami na 2,2 GHz překonává starší GPU s 16 000 na 1,8 GHz díky lepším instrukcím za cyklus. Váš kód potřebuje správnou paralelizaci k efektivnímu využití 20 000 jednotek.
Proč na CUDA jádrech záleží při výběru GPU VPS

Výběr správné konfigurace GPU s CUDA jádry pro váš VPS zabraňuje zbytečným výdajům na nevyužívané prostředky nebo získání problémů uprostřed projektu.
Paměť 80GB H100 zvládá odvozování pro modely se 70B parametry pomocí 4bitové kvantizace. Pro úplný trénink je však i 80GB často nedostatečné pro model 34B, jakmile zohledníte gradienty a stavy optimizéru. Při tréninku FP16 se stopa paměti výrazně zvětšuje, často vyžadující sharding více GPU.
Operace inference pro předpovědi v reálném čase vyžadují méně jader, ale profitují z nízké latence. Vývoj a prototypování fungují dobře se střední řadou GPU na testování algoritmů a ladění kódu.
RTX 4060 Ti se 4 352 jádry vám umožní testovat bez platby za zbytečně výkonný hardware. Jakmile ověříte svůj přístup, rozšiřte kapacitu na produkční GPU pro úplné trénovací běhy.
Renderování a video práce se mění s počtem jader až do určitého bodu. Blenderův Cycles renderer efektivně využívá všechny dostupné zdroje. GPU s 8 000-10 000 jádry renderuje scény 2-3x rychleji než ten se 4 000.
V Cloudzy nabízíme vysoce výkonný GPU VPS hosting stavěný na těžkou práci. Zvolte RTX 5090 nebo RTX 4090 pro rychlé renderování a cenově efektivní AI inference, nebo rozšiřte kapacitu na A100 pro obrovské deep learning úlohy. Všechny plány běží na síti 40 Gbps s politikou ochrany soukromí a možností platby v kryptoměnách, takže máte surový výkon bez korporátní vyrovávanosti.
Ať už trénujete AI modely, renderujete 3D scény nebo spouštíte vědecké simulace, vyberete si počet jader, který odpovídá vašim potřebám.
Rozpočet hraje roli. A100 s 6 912 jádry stojí výrazně méně než H100 s 16 896. Pro řadu operací nabízí dva A100 lepší poměr ceny a výkonu než jeden H100. Bod zvratu závisí na tom, zda se váš kód škáluje na více GPU.
Jak vybrat správný počet CUDA jader
Přizpůsobte své požadavky skutečným charakteristikám zátěže, místo než se honit za nejvyššími čísly dostupnými na trhu.
Začněte profilováním své aktuální práce. Pokud trénujete modely na místním hardwaru nebo instancích v cloudu, zkontrolujte metriky využití GPU. Pokud vaše současná GPU ukazuje konzistentní využití 60-70 procent, nekončíte jádra naplno.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Tento jednoduchý benchmark ukazuje, zda vaše GPU jádra dosahují očekávaného výkonu. Porovnejte své výsledky s publikovanými benchmarky pro váš model GPU.
Upgrade nepomůže. Nejprve musíte řešit úzká místa, jako je paměť, šířka pásma nebo zpoždění CPU. Dále odhadněte požadavky na paměť výpočtem velikosti modelu v bajtech plus paměti aktivací.
Přidejte velikost dávky krát výstupy vrstev a zahrňte stavy optimizéru. Tento součet se musí vejít do VRAM. Jakmile znáte potřebnou paměť, zkontrolujte, které GPU splňují tento práh.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Zvažte svůj časový plán. Pokud potřebujete výsledky během hodin, zaplaťte za více jader. Trénovací běhy, které mohou trvat dny, fungují dobře na menších GPU s odpovídajícím prodloužením doby dokončení.
Cena za hodinu krát počet potřebných hodin dává celkové náklady, někdy činí pomalejší GPU levnějšími celkově. Otestujte efektivitu škálování pomocí mnoha frameworků, které poskytují nástroje na měření propustnosti a změny výkonu.
Pokud zdvojnásobení jader přinese pouze 1,5x zrychlení, ta extra nejsou stojí za svoje náklady. Hledejte optimální body, kde se poměr ceny a výkonu dostane na vrchol.
| Typ pracovního zatížení | Doporučená jádra | Příkladné GPU | Poznámky |
| Vývoj a ladění modelů | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Rychlá iterace, nižší náklady |
| Trénování AI v malém měřítku (méně než 7B parametrů) | 6,000-10,000 | RTX 4090, L40S | Vyhovuje spotřebitelům a malým podnikům |
| Trénování AI ve velkém měřítku (7B-70B parametrů) | 14,000+ | A100, H100 | Vyžaduje datácentra GPU |
| Inference v reálném čase (vysoká propustnost) | 10,000-16,000 | RTX 5080, L40 | Vyvážení nákladů a výkonu |
| 3D rendering a kódování videa | 8,000-12,000 | RTX 4080, RTX 4090 | Zvyšuje se s rostoucí složitostí |
| Vědecké výpočty a HPC | 10,000+ | A100, H100 | Vyžaduje podporu FP64 |
Populární modely VPS GPU a jejich počty CUDA jader

Různé úrovně GPU slouží různým segmentům uživatelů. Co je GPUaaS? Jedná se o GPU-as-a-Service, kde poskytovatelé jako Cloudzy nabízejí přístup na vyžádání k těmto výkonným grafickým kartám NVIDIA GPU bez nutnosti kupovat a spravovat fyzický hardware sami.
| GPU Model | CUDA jádra | VRAM | Propustnost paměti | Architektura | Nejlépe pro |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1 792 GB/s | Blackwell | Špičková workstation, 8K rendering |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1 008 GB/s | Ada Lovelaceová | Pokročilá AI, 4K rendering |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3 350 GB/s | Hopper | Rozsáhlý training AI modelů |
| H100 PCIe | 14,592 | 80GB HBM2e | 2 000 GB/s | Hopper | Enterprise AI, nákladově efektivní datové centrum |
| A100 | 6,912 | 40/80GB HBM2e | 1 555–2 039 GB/s | Ampere | Střední třída AI, osvědčená spolehlivost |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelaceová | Hraní her, středně pokročilá AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelaceová | Datové centrum pro více úloh |
Spotřebitelské RTX karty (4070, 4080, 4090, 5080, 5090) cílí na tvůrce a hráče, ale dobře fungují i pro vývoj AI. Nabízejí silný výkon jednoho GPU za nižší cenu než karty pro datová centra.
Poskytovatelé VPS často skladují tyto karty pro cenově citlivé uživatele. Karty pro datová centra (A100, H100, L40) upřednostňují spolehlivost, ECC paměť a škálování s více GPU. Zvládají 24/7 provoz a podporují pokročilé funkce.
Multi-Instance GPU (MIG) umožňuje rozdělit jeden GPU na více izolovaných instancí. A100 zůstává populární přes novější možnosti díky svým vyváženým specifikacím.
Její vyvážení jader NVIDIA, paměti a ceny ji činí bezpečnou volbou pro většinu produkčních AI operací. H100 nabízí 2,4x více jader, ale stojí výrazně více.
Závěr
Paralelní procesory umožňují moderní AI, rendering a vědecké výpočty. Pochopení jejich fungování a interakce s pamětí, frekvencí a softwarem vám pomůže vybrat správné konfigurace GPU VPS.
Více jader pomáhá, když se vaše práce dobře paralelizuje a komponenty jako paměťová šířka pásma si s tím poradí. Ale bezmyšlenkovité honění za nejvyšším počtem jader zbytečně vynakládá peníze, pokud jsou vaše úzké místa jinde.
Začněte profilováním vašich skutečných operací, identifikací, kde se čas tráví, a přizpůsobením specifikací GPU těmto požadavkům bez překupování zbytečné kapacity.
Pro většinu prací s AI vývojem je 6 000 až 10 000 jader ideální kompromisem mezi náklady a možnostmi. Produkční operace trénující velké modely nebo obsluhující vysokou propustnost inferencí těží z GPU s 14 000+ jádry, jako je H100.
Rendering a video práce se efektivně škálují s jádry až kolem 16 000, poté se paměťová šířka pásma stává limitujícím faktorem.


