
En af de vigtigste — hvis ikke den vigtigste — aspekter af machine learning er at opnå præcise og pålidelige forudsigelser. En innovativ tilgang til dette mål, der har vundet fremgang, er Bootstrap Aggregating, mere kendt som bagging i machine learning. Denne artikel gennemgår bagging i machine learning, sammenligner bagging og boosting, viser et eksempel på en bagging-klassificeringsenhed, forklarer hvordan bagging fungerer, og udforsker fordele og ulemper ved bagging i machine learning.
Hvad er bagging i machine learning?
De to billeder er de eneste relevante billeder brugt i populære artikler. Et eller begge kan bruges (et her og det andet andre steder), hvis designholdet laver Cloudzy-versioner af dem.
Hvad er Bagging?
Forestil dig, at du prøver at gætte vægten på en genstand ved at spørge flere personer om deres estimater. Deres gæt kan variere meget hver for sig, men ved at tage gennemsnittet af alle estimaterne kan du nå frem til et mere pålideligt tal. Det er essensen af bagging: at kombinere output fra flere modeller for at producere en mere præcis og stabil forudsigelse.
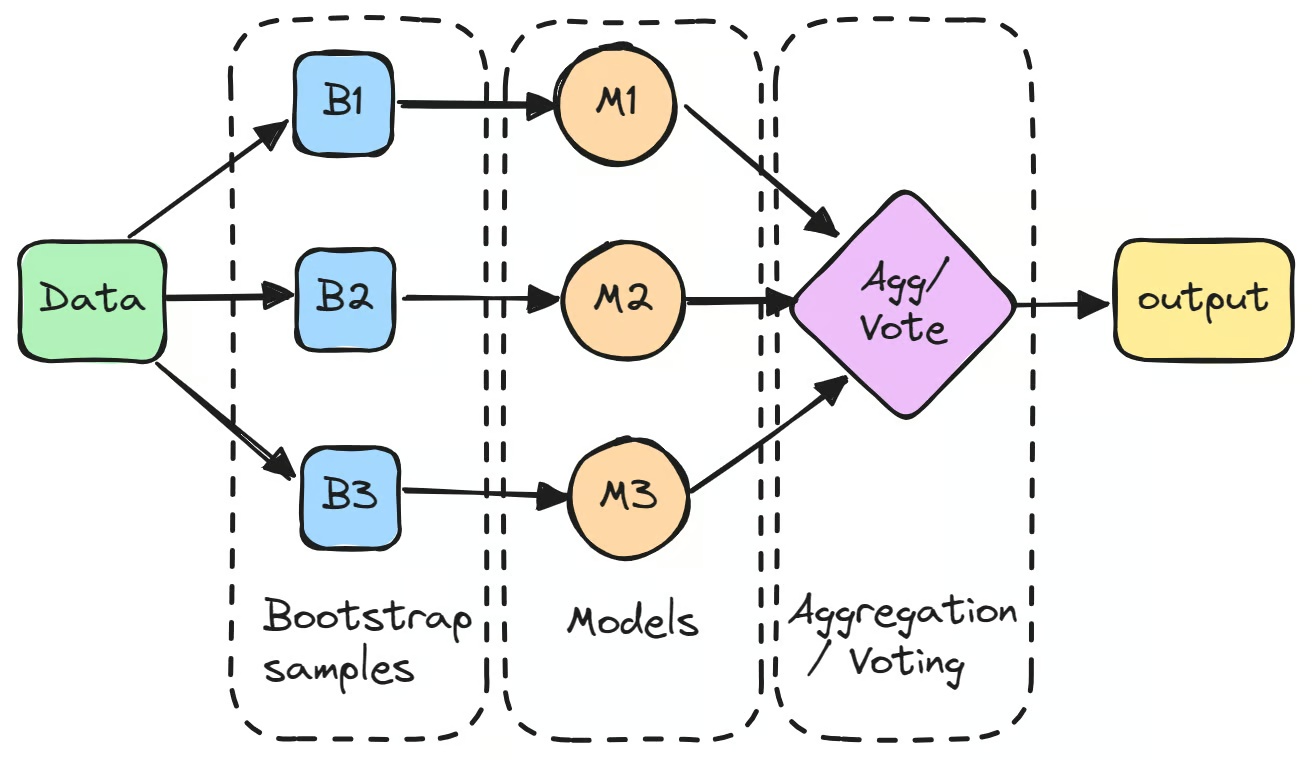
Processen begynder med at skabe flere delmængder af det oprindelige datasæt gennem bootstrapping, som er tilfældig sampling med tilbagelægning. Hver delmængde bruges til at træne en separat model uafhængigt.
Disse enkelte modeller, ofte kaldet "svage lærere", udfører måske ikke særlig godt på egen hånd på grund af høj varians. Men når deres forudsigelser kombineres, typisk gennem gennemsnit for regressionopgaver eller flertalsafstemning for klassificeringsopgaver, overgår det kombinerede resultat ofte ydeevnen for enhver enkelt model.
En velkendt bagging-klassificerer-eksempel er Random Forest-algoritmen, som konstruerer et ensemble af beslutningstrær for at forbedre forudsigelsesydeevnen. Det skal siges at bagging ikke bør forveksles med boosting inden for machine learning, som tager en anden tilgang ved at træne modeller sekventielt for at reducere bias. Bagging fungerer ved at træne modeller parallelt for at reducere varians.
Både bagging og boosting inden for machine learning sigter mod at forbedre modelydeevnen, men de fokuserer på forskellige aspekter af modellens adfærd.
Hvorfor er Bagging nyttigt?
En af de vigtigste fordele ved bagging inden for machine learning er dets evne til at reducere varians og hjælpe modeller med at generalisere bedre til usete data. Bagging er særligt gavnligt, når man arbejder med algoritmer, der er følsomme over for udsving i træningsdataene, såsom beslutningstrær.
Ved at forhindre overfitting sikrer det en mere stabil og pålidelig model. Når man sammenligner bagging og boosting inden for machine learning, fokuserer bagging på at reducere varians ved at træne flere modeller parallelt, mens boosting sigter mod at reducere bias ved at træne modeller sekventielt.
Et eksempel på bagging inden for machine learning kan ses i finansiel risikovurdering, hvor flere beslutningstrær trænes på forskellige delmængder af historiske markedsdata. Ved at kombinere deres forudsigelser skaber bagging en mere robust prognosmodel, som reducerer virkningen af fejl fra individuelle modeller.
I sin essens udnytter bagging inden for machine learning den kollektive visdom fra flere modeller for at levere forudsigelser, der er mere præcise og pålidelige end dem, der stammer fra individuelle modeller alene.
Hvordan Bagging i Machine Learning Fungerer: Trin for Trin
For fuldt at forstå, hvordan bagging forbedrer modelydeevnen, lad os nedbryde processen trin for trin.
Tag Flere Bootstrap-Prøver fra Datasættet
Det første trin i bagging inden for machine learning er at skabe flere nye delmængder af det oprindelige datasæt ved hjælp af bootstrapping. Denne teknik indebærer tilfældig sampling af data med tilbagelægning, så nogle datapunkter kan optræde flere gange i samme delmængde, mens andre måske slet ikke optræder. Denne proces udføres for at sikre, at hver model trænes på en let forskellig version af dataene.
Træn en Separat Model på Hver Prøve
Hver bootstrap-prøve bruges derefter til at træne en separat model, typisk af samme type, såsom beslutningstrær. Disse modeller, ofte kaldet "basislærere" eller "svage lærere", trænes uafhængigt på deres respektive delmængder. Et bagging-klassificerer-eksempel er det beslutningstre, der bruges i Random Forest-algoritmen, som danner grundlaget for mange bagging-baserede modeller. Selvom hver enkelt model måske ikke udfører godt på egen hånd, bidrager de hver med unikke indsigter baseret på deres specifikke træningsdata.
Kombiner Forudsigelserne
Efter at have trænet modellerne kombineres deres forudsigelser for at danne det endelige output.
- For regressionopgaver gennemsnitliggøres forudsigelserne, hvilket reducerer modellens varians.
- For klassificeringsopgaver bestemmes den endelige forudsigelse gennem flertalsafstemning, hvor den klasse, som de fleste modeller forudsiger, vælges. Denne metode giver en mere stabil forudsigelse sammenlignet med en enkelt models output.
Endelig forudsigelse
Ved at kombinere forudsigelser fra flere modeller reducerer bagging virkningen af fejl fra enhver enkelt model og forbedrer den samlede nøjagtighed. Denne kombinationsproces er det, der gør bagging til sådan en kraftfuld teknik, især i machine learning-opgaver, hvor høj-varians-modeller som beslutningstrær bruges. Det udjævner effektivt uoverensstemmelser i forudsigelser fra individuelle modeller, hvilket resulterer i en stærkere endelig model.
Selvom bagging er effektivt til at stabilisere forudsigelser, er der nogle få ting at være opmærksom på, blandt andet risikoen for overfitting, hvis basislærerne er for komplekse, på trods af baggings almene formål med at reducere det.
Det er også beregningsmæssigt dyrt, så justering af antallet af basislærere eller overvejelse af mere effektive ensemble-metoder kan hjælpe. valg af den rigtige GPU til ML og DL er altid vigtig.
Sørg for at have en vis modelvariation blandt basislærerne for bedre resultater, og hvis du arbejder med ubalancerede data, kan teknikker som SMOTE være nyttige før anvendelse af bagging for at undgå dårlig ydeevne på minoritetsklasser.
Bagging-anvendelser
Nu hvor vi har udforsket, hvordan bagging virker, er det tid til at se, hvor det faktisk bruges i praksis. Bagging er blevet brugt inden for mange forskellige industrier og hjælper med at forbedre nøjagtigheden og stabiliteten af forudsigelser i komplekse scenarier. Lad os tage et nærmere kig på nogle af de vigtigste anvendelser:
- Klassifikation og regression: Bagging bruges bredt til at forbedre ydeevnen af klassifikatorer og regressorer ved at reducere varians og forhindre overtilpasning. For eksempel er Random Forests, som bruger bagging, effektive til opgaver som billedklassifikation og prediktiv modellering.
- Anomaliregistrering: Inden for områder som svindeldetektering og opdagelse af netværksindbrud tilbyder bagging-algoritmer overlegen ydeevne ved at effektivt identificere afvigelser og uregelmæssigheder i data.
- Vurdering af finansiel risiko: Bagging-teknikker bruges i bankbranchen til at forbedre kreditscoringsmodeller og øge nøjagtigheden af lånegodelses- og finansiel risikovurderingsprocesser.
- Medicinsk diagnostik: Inden for sundhedsvæsenet er bagging blevet anvendt til at opdage neurokognitive sygdomme som Alzheimers sygdom ved at analysere MRI-datasæt og hjælpe med tidlig diagnose og behandlingsplanlægning.
- Naturlig sprogbehandling (NLP): Bagging bidrager til opgaver som tekstklassifikation og sentimentanalyse ved at kombinere forudsigelser fra flere modeller, hvilket fører til mere robust sprogforståelse.
Fordele og ulemper ved bagging
Som enhver machine learning-teknik har bagging sine egne fordele og ulemper. At forstå disse kan hjælpe med at bestemme, hvornår og hvordan du skal bruge bagging i dine modeller.
Fordelene ved Bagging:
- Reducerer varians og overtilpasning: En af de vigtigste fordele ved bagging i machine learning er dets evne til at reducere varians, hvilket hjælper med at forhindre overtilpasning. Ved at træne flere modeller på forskellige dele af data giver bagging dig sikkerhed for, at modellen ikke bliver for følsom over for udsving i træningsdataene, hvilket resulterer i en mere generaliserbar og stabil model.
- Fungerer godt med modeller med høj varians: Bagging er særlig effektiv, når det bruges med modeller med høj varians som beslutningstrær. Disse modeller har en tendens til at overtilpasse dataene og have høj varians, men bagging begrænser dette ved at gennemsnitlige eller stemme over flere modeller. Dette hjælper med at gøre forudsigelser mere pålidelige og mindre tilbøjelige til at blive påvirket af støj i dataene.
- Forbedrer modelstabilitet og ydeevne: Ved at kombinere flere modeller trænet på forskellige dele af data fører bagging ofte til bedre samlet ydeevne. Det hjælper med at forbedre forudsigelsesnøjagtigheden samtidig med at reducere modellens følsomhed over for små ændringer i datasættet, hvilket i sidste ende gør modellen mere pålidelig.
Ulemperne ved Bagging:
- Øger beregningsomkostninger: Da bagging kræver træning af flere modeller, øges beregningsomkostningerne naturligt. Træning og aggregering af forudsigelser fra mange modeller kan være tidskrævende, især når der bruges store datasæt eller komplekse modeller som beslutningstrær.
- Ikke effektiv for modeller med lav varians: Selvom bagging er meget effektiv for modeller med høj varians, giver det ikke meget fordel, når det anvendes på modeller med lav varians såsom lineær regression. I disse tilfælde har de enkelte modeller allerede lave fejlrater, så aggregering af forudsigelser gør lidt for at forbedre resultaterne.
- Tab af fortolkelighed: Med kombinationen af flere modeller kan bagging reducere tolkeligheden af den endelige model. For eksempel i Random Forest er beslutningsprocessen baseret på flere beslutningstrær, hvilket gør det sværere at spore ræsonnementet bag en specifik forudsigelse.
Hvornår skal jeg bruge bagging?
Det er afgørende at vide, hvornår bagging skal bruges i machine learning-projekter for at opnå optimale resultater. Teknikken fungerer godt i specifikke situationer, men det er ikke altid det bedste valg for ethvert problem.
Når din model er tilbøjelig til overfitting
Et af de primære tilfælde for bagging er, når din model er tilbøjelig til overfitting, især med høj-varians-modeller som beslutningstrær. Disse modeller kan præstere godt på træningsdata, men generaliserer ofte dårligt til nye data, da de passer for tæt til det specifikke mønster i træningssættet.
Bagging hjælper med at bekæmpe dette ved at træne flere modeller på forskellige delmængder af data og derefter gennemsnitsværdien eller stemmer for at skabe en mere stabil forudsigelse. Dette reducerer risikoen for overfitting og gør modellen bedre til at håndtere nye, ukendte data.
Når du vil forbedre stabilitet og nøjagtighed
Hvis du ønsker at forbedre stabiliteten og nøjagtigheden af din model uden at give købt for meget tolkelighed, er bagging et glimrende valg. Aggregeringen af forudsigelser fra flere modeller gør det endelige resultat mere kraftfuldt, hvilket er især nyttigt ved opgaver med støjende data.
Uanset om du arbejder med klassifikationsproblemer eller regressionopgaver, kan bagging hjælpe med at producere mere konsistente resultater og øge nøjagtigheden samtidig med at bevare effektiviteten.
Når du har tilstrækkelige computeressourcer
En anden vigtig faktor, når du skal afgøre, om bagging skal bruges, er tilgængeligheden af computeressourcer. Da bagging kræver at træne flere modeller samtidigt, kan beregningsomkostningerne blive betydelige, især med store datasæt eller komplekse modeller.
Hvis du har adgang til den nødvendige computerkraft, opvejer fordelene ved bagging omkostningerne langt. Hvis ressourcerne er begrænsede, kan du dog overveje alternative teknikker eller reducere antallet af modeller i dit ensemble.
Når du arbejder med høj-varians-modeller
Bagging er særlig nyttig, når man arbejder med modeller, der har høj varians og er følsomme over for udsving i træningsdataene. Beslutningstrær bruges for eksempel ofte med bagging i form af Random Forests, fordi deres ydeevne har tendens til at variere meget afhængigt af træningsdataene.
Ved at træne flere modeller på forskellige datadelmængder og kombinere deres forudsigelser, udjevner bagging variansen, hvilket resulterer i en mere pålidelig model.
Når du har brug for en robust klassifikator
Hvis du arbejder på klassifikationsproblemer og har brug for en robust klassifikator, kan bagging betydeligt forbedre stabiliteten af dine forudsigelser. For eksempel kan en Random Forest, som er et eksempel på en bagging-klassifikator, give en mere nøjagtig forudsigelse ved at aggregere resultaterne fra mange individuelle beslutningstrær.
Denne tilgang fungerer godt, når individuelle modeller kan være svage, men deres kombinerede kraft resulterer i en stærk samlet model.
Derudover, hvis du leder efter den rigtige platform til at implementere bagging-teknikker effektivt, kan værktøjer som Databricks og Snowflake give dig en samlet analyseplatform, der kan være meget nyttig til at administrere store datasæt og køre ensemblemetoder som bagging.
Hvis du leder efter en mindre teknisk tilgang til machine learning, no-code AI-værktøjer kan også være en mulighed. Selvom de ikke fokuserer direkte på avancerede teknikker som bagging, gør mange no-code-platforme det muligt for brugere at eksperimentere med ensemble learning-metoder, herunder bagging, uden at skulle have omfattende kodningskompetencer.
Dette gør det muligt for dig at anvende mere sofistikerede teknikker og stadig opnå nøjagtige forudsigelser, mens du fokuserer på modelydeevne i stedet for den underliggende kode.
Afsluttende tanker
Bagging i machine learning er en kraftfuld teknik, der forbedrer modelydeevne ved at reducere varians og forbedre stabilitet. Ved at aggregere forudsigelser fra flere modeller trænet på forskellige datadelmængder hjælper bagging med at skabe mere nøjagtige og pålidelige resultater. Det er særlig effektivt for høj-varians-modeller som beslutningstrær, hvor det hjælper med at forhindre overfitting og sikrer, at modellen generaliserer bedre til nye data.
Selvom bagging har betydelige fordele, såsom at reducere overfitting og forbedre nøjagtighed, kommer det med nogle afvejninger. Det øger beregningsomkostningerne på grund af træning af flere modeller og kan reducere tolkelighed. På trods af disse ulemper gør dets evne til at øge ydeevne det til en værdifuld teknik inden for ensemble learning, sammen med andre metoder som boosting og stacking.
Har du brugt bagging i machine learning-projekter? Fortæl os om dine erfaringer og hvordan det fungerede for dig!


