
I 60'erne og 70'erne, monolitisk arkitektur blev foretrukket til applikationsudvikling på grund af begrænsede computeressourcer, hvilket krævede, at alle funktionaliteter kombineres til en enkelt, sammenhængende enhed.
Det var indtil slutningen af 90'erne og 2000'erne, da den monolitiske struktur begyndte at blive for begrænset for den stadigt større størrelse og kompleksitet af applikationer, især med internettets og distribuerede systemers fremkomst.
Dette førte til udviklingen af mere modulære tilgange, såsom serviceorienteret arkitektur (SOA) og senere mikroservices-arkitektur (MSA), som blev fremtrædende i begyndelsen af 2010'erne.
Når det er sagt, er dette blot en kort forklaring af det grundlæggende koncept og brugen af mikroservices. Lad os derfor diskutere, hvordan mikroservices erstattede monolitisk arkitektur, hvordan mikroservices fungerer, og nogle eksempler på mikroservices. Derefter diskuterer vi vigtige aspekter af mikroservices-udrulning og hvad du skal gøre, hvis du ønsker at implementere mikroservices.
Hvad er mikroservices? Hvordan fungerer de?
Som jeg nævnte tidligere, opstod mikroservices som en løsning på stigende applikationskompleksitet og størrelse, hvilket tillod virksomheder at opdele funktioner i uafhængigt implementerbare services.
Termen "mikroservices" blev populariseret af brancheeksperter som Martin Fowler og James Lewis, som formelt introducerede den i et blogindlæg i 2014. Deres arbejde definerede nøgleprincipper og karakteristika, herunder behovet for uafhængigt implementerbare services, decentraliseret datastyring og teknologiuafhængighed.
Siden da er microservices blevet et mainstream arkitekturvalg, understøttet af fremskridt inden for containerteknologier som Docker, orkestreringsværktøjer som Kubernetes og serverless computing-platforme. Men hvordan fungerer microservices?
Hvordan fungerer microservices?
En microservices-arkitektur deler i bund og grund en stor applikation op i mindre, adskilte services, hvor hver enkelt er ansvarlig for en specifik forretningskapacitet. Disse services kommunikerer med hinanden over et netværk, ofte via REST APIs, gRPC eller message brokers som RabbitMQ eller Apache Kafka.
Ifølge Martin Fowler og James Lewis' definition har microservices fire centrale karakteristika:
- Enkelt ansvar: Hver microservice er designet til at udføre en specifik opgave eller funktion, hvilket muliggør specialisering og reducerer kompleksitet.
- Uafhængighed: Microservices kan udvikles, implementeres og skaleres uafhængigt af hinanden, hvilket giver fleksibilitet og resiliens.
- Decentraliseret datahåndtering: Microservices har ofte deres egne databaser, hvilket eliminerer behovet for en enkelt, centraliseret database.
- Teknologiuafhængighed: Teams kan vælge den bedste teknologi til hver service uden at være bundet af andre services' valg.
Denne tilgang står i kontrast til traditionel monolitisk arkitektur, hvor alle applikationskomponenter er tæt integreret i en enkelt, kohærent enhed.
Vigtige faser i microservices-implementering
Selvom en microservices-arkitektur tilbyder mange fordele, såsom høj skalerbarhed, fleksibilitet, effektivitet og fejlisolation, kræver det viden om, hvordan man implementerer microservices effektivt, og grundig planlægning for at lykkes.
Derfor er det afgørende for en succesfuld microservices-arkitektur at have en omfattende forståelse af centrale begreber, faser og best practices for microservices-implementering. Lad os derfor gennemgå de vigtige faser i microservices-implementering og hvad hver fase indebærer.
Planlægning og forberedelse til microservices-implementering
Alle gode ting kræver planlægning og tålmodighed, og for at implementere microservices med succes har du absolut brug for grundig planlægning og tålmodighed. Derfor er det vigtigt at følge best practices for microservices og planlægge og forberede alt, hvad du har brug for, når du implementerer microservices.
Som jeg nævnte tidligere, er et af microservices' centrale principper og karakteristika det Enkeltansvarsudtryk. Ved at overholde dette princip og sikre, at hver microservice fokuserer på og er ansvarlig for en enkelt funktion og kapacitet, gør du det muligt for dit team at udvikle, implementere og skalere services uafhængigt.
Desuden er en underkategori af dette princip løs koblet designprincip. Det betyder, at hver service kan fungere uafhængigt med hensyn til kommunikation og afhænger minimalt af andre services. Dette gør det muligt for ændringer eller opdateringer i en service ikke at påvirke andre services, hvilket tillader uafhængig skalering af microservices.
Dette mindsker risikoen for kaskaderende fejl, hvor et problem eller svigt i en del af systemet udløser en kædereaktion, som fører til fejl i hele systemet og får hele servicen til at gå ned.
En vigtig microservices-praksis er at have dedikeret datalagring for hver service, når du implementerer microservices som en udvidelse af loose coupling design principle, da dette forhindrer konflikter og giver mulighed for bedre service-skalerbarhed.
Desuden skal du bruge asynkron mikroservices-kommunikation via meddelelsesbrokere, så hver service kan kommunikere uden direkte afhængigheder.
Det sidste vigtige element er at implementere CI/CD-pipelines (Continuous Integration og Continuous Delivery) til mikroservices. Disse pipelines gør det muligt for teams at udsende nye funktioner eller rettelser via CI/CD-værktøjer som Jenkins og GitLab, hvilket giver organisationer mulighed for at bevare systemstabilitet samtidig med hyppige nye releases.
Nu hvor du har et overblik over planlægning og forberedelse til mikroservices-udrulning, lad os tale om strategier for mikroservices-udrulning.
Strategier for mikroservices-udrulning
Når du udrulles mikroservices, afhænger valget af strategi af servicefunktion, trafik, infrastrukturopsætning, teamets kompetencer og omkostninger. Generelt ser strategier for mikroservices-udrulning sådan ud:
- Serviceinstans pr. container Her kører hver mikroservice i sin egen container, hvilket giver bedre isolation end modellen med flere instanser per vært. Containere gør det nemt at skalere og forbedrer ressourceallokeringen.
- Serviceinstans pr. virtuel maskine Hver service kører i en separat virtuel maskine (VM), som giver endnu bedre isolation end containere. Selvom dette forbedrer sikkerhed og stabilitet, medfører det typisk mere overhead.
- Faseopdelte udgivelser: Udrull først mikroservices-versioner til en lille gruppe brugere for at teste stabilitet før fuld udrulning. Denne tilgang minimerer påvirkning hvis problemer opstår, og tillader hurtige rollbacks for at bevare systemintegritet.
- Blue-Green-udrulning Denne metode bruger to identiske produktionsmiljøer, hvor det ene miljø håndterer live-trafik mens det andet bruges til test af næste release. Blue-Green-udrulning giver nem rollback og nultids-nedetid, da trafik kan skifte seamlessly mellem de to miljøer.
- Faseinddelte Udgivelser: Denne strategi udrulles opdateringer gradvist til forskellige brugergrupper eller miljøer. Det starter ofte med interne miljøer før produktion, hvilket begrænser påvirkningen af potentielle problemer og tillader teams at løse dem trinvist.
- Serverløs installation: Denne tilgang bruger serverløse platforme som AWS Fargate og Go Google Cloud Run, som automatiserer infrastruktur-management ved at håndtere skalering og ressourceallokeringen for dig. Med serverløs udrulning behøver du ikke at administrere underliggende servere, så du kan fokusere på dine mikroservices.
Når du har valgt en af de ovenstående mikroservices-udrulningsstrategier, skal du bruge et orkestreringsværktøj til mikroservices.
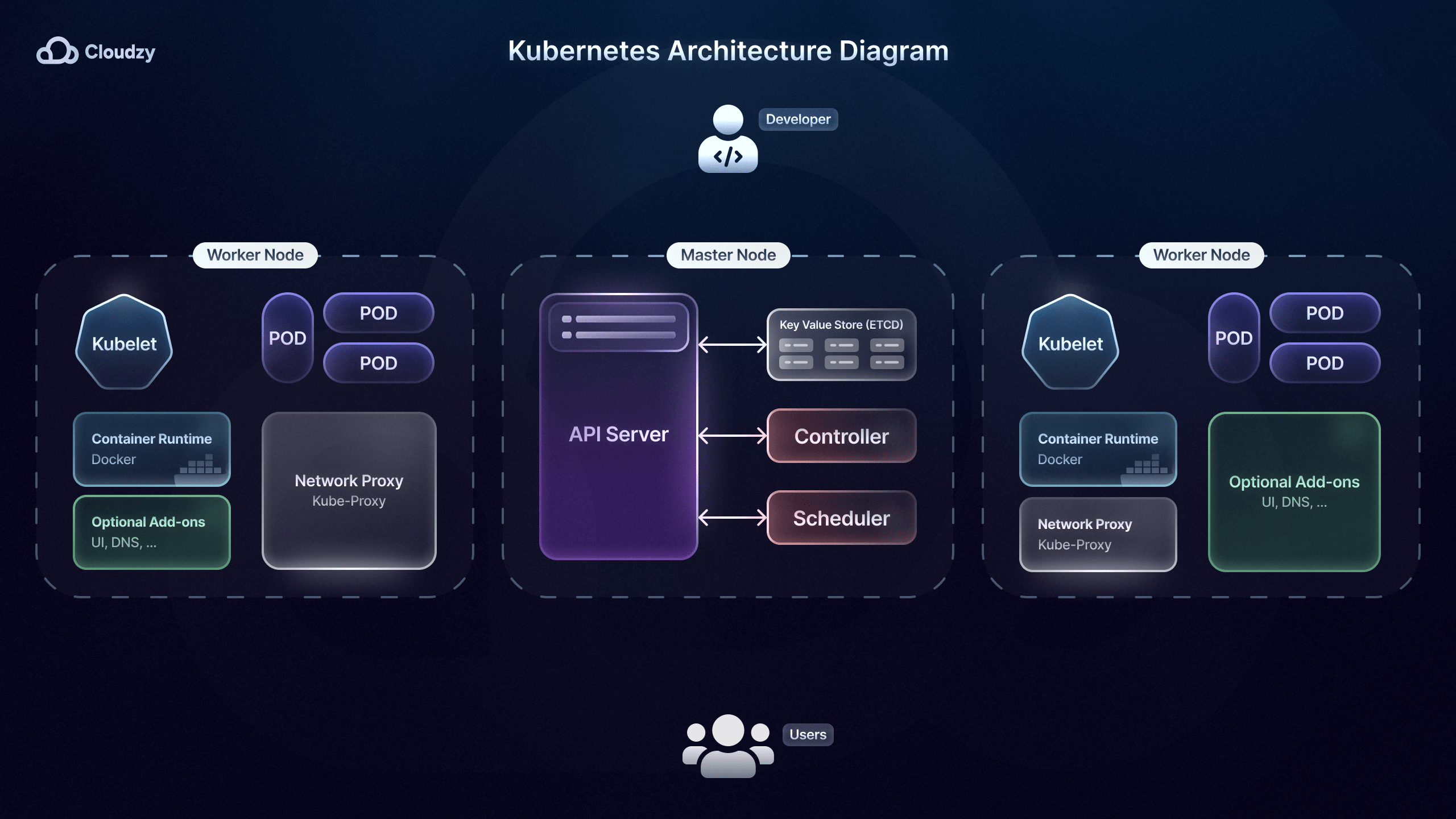
Microservices-orkestrering
Efter at have valgt en af mange mikroservices-udrulningsstrategier, skal du bruge et orkestreringsværktøj til mikroservices. Orkestreringsværktøjer til mikroservices, såsom Kubernetes, hjælper med at automatisere udrulning, skalering, overvågning og styring af containeriserede mikroservices.
Airbnb bruger for eksempel Kubernetes, som gør det muligt for dets ingeniører at udsende hundredvis af ændringer til deres mikroservices uden manuel indsats. Et vigtigt feature i orkestreringsværktøjer som Kubernetes er built-in load balancing.
Et kompetent load-balancing-feature hjælper med at distribuere indgående trafik på flere instanser af en mikroservice. Dette forhindrer enhver enkelt instans i at blive en flaskehals og forbedrer systemets evne til at håndtere trafiktoppe.
Kubernetes spiller en vigtig rolle i administrering af mikroservices gennem dets self-healing-muligheder, hvor mislykkede containere erstattes og genstartes automatisk. The New York Times bruger dette feature til at vedligeholde sine mikroservices uden at påvirke brugeroplevelsen eller have nedetid.
Desuden forbedrer Kubernetes også mikroservices-sikkerhed ved at sikre konfigurationer og secrets såsom databasecredentials eller API-nøgler ved hjælp af ConfigMaps og Secrets. Dette er især vigtigt for virksomheder og tjenester som Uber, der håndterer følsomme kunde- og brugerdata.
Endelig er orkestreringsværktøjer til mikroservices som Kubernetes særligt gavnlige for mikroservices-strategier, der involverer rolling updates og rollbacks, såsom staged releases. Rolling updates gør det muligt at udsende nye mikroservices-versioner uden serviceafbrydelser ved at holde nogle instanser af den gamle version kørende.
Når du har sat dit orkestreringsværktøj til mikroservices op, skal du bygge og automatisere CI/CD-pipelines til microservices-deployment.
CI/CD-pipelines til microservices-deployment
Som vi diskuterede tidligere, er Continuous Integration og Continuous Delivery-pipelines til microservices vigtige aspekter af microservices-deployment. CD-pipelinerne i CI/CD-pipelines står for automatisk at deploye kodeændringer til produktion, så snart de består test- og integrationsfaserne i CI/CD-pipelinen.
Derefter træder CD-delen af CI/CD-pipelinerne i kraft, så når kodeændringer består test- og integrationsfaserne, deployes servicen til et microservices-orkestrationsværktøj såsom en Kubernetes-cluster.
Desuden udføres test- og integrationsfaserne helt automatisk af CI/CD-pipelinerne, da unit tests, integrationstests og end-to-end tests indgår i pipelinen.
Dette gør det muligt for teams at validere opdateringer på hvert trin og samtidig opretholde systemstabilitet. Hvis der er problemer med kodeændringer på trods af forskellige tests, kan automatiserede tilbagerulninger vende tilbage til den tidligere stabile version.
Til sidst hjælper implementering af CI/CD-pipelines til microservices i overensstemmelse med best practices for microservices organisationer med at opnå hurtigere udvikling, reducere manuelle fejl og opretholde høje kvalitetsstandarder.
Mange virksomheder som Spotify, Expedia, iRobot, Lufthansa, Pandora osv. bruger CI/CD-pipelines til microservices gennem CI/CD-værktøjer som CircleCI, AWS CodePipeline og GitLab til at automatisere deploymentprocesser, sikre ensartet kodekvalitet og levere nye funktioner hurtigt, samtidig med at systemstabiliteten opretholdes.
Mikroservices-kommunikationsmønstre
Hvordan mikroservices kommunikerer med hinanden afhænger fuldstændigt af funktionen, den overordnede arkitektur, ønsket skalerbarhed og pålideligheden af dine mikroservices. Generelt anvendes to hovedtyper af mikroservices-kommunikationsmønstre: synkron og asynkron mikroservices-kommunikationsmønstre.
I synkron mikroservices-kommunikation interagerer services i realtid, hvilket betyder, at en service sender en forespørgsel og venter på et svar, før den fortsætter. De mest almindeligt anvendte synkrone mikroservices-kommunikationsmønstre er REST (Representational State Transfer) API'er, gRPC (Go Google Remote Procedure Call), og GraphQL.
Typisk bruges denne form for mikroservices-kommunikationsmønstre i brancher og af virksomheder, der kræver realtidsbehandling af data og øjeblikkelige svar. Brancher som finans, sundhedsvæsen og e-handel bruger ofte synkron kommunikation for at sikre, at transaktioner, datahentning eller interaktioner sker øjeblikkeligt og giver en problemfri og responsiv brugeroplevelse.
Men selv om synkrone mikroservices-kommunikationsmønstre har fordele som realtidssvar og enkelhed, har de også visse ulemper som potentielle flaskehalse på grund af deres stramme koblingen, lav skalerbarhed under høje belastninger, langsomme svartider og høj latens under tung trafik.
På den anden side er asynkrone mikroservices-kommunikationsmønstre normalt mere egnede til mikroservices, da de er baseret på Loose Coupling-princippet, som vi diskuterede tidligere.
Denne form for mikroservices-kommunikationsmønster dekobler services ved at give dem mulighed for at sende og modtage beskeder gennem en mægler som Kafka eller RabbitMQ. Ved at sende beskeder til en kø, der fungerer som en buffer, kommunikerer services uafhængigt i stedet for at vente på et svar, som de ville gøre i synkron kommunikation. Denne buffer gør det muligt for andre services at behandle beskeder i deres eget tempo, så afsenderen kan fortsætte sitt arbejde uden at vente på modtageren.
Det asynkrone mikroservices-kommunikationsmønster tilbyder ikke blot en dekobl struktur til mikroservices-deployment, men tilbyder også de samme realtidssvar, som synkrone mikroservices-kommunikationsmønstre giver.
Dette skyldes den event-driven arkitektur af de asynkrone event-driven mikroservices-kommunikationsmønstre, da services kommunikerer ved at udsende events, når en specifik handling forekommer. Andre services kan abonnere på disse events og reagere i overensstemmelse hermed. Dette muliggør højtresponsive systemer, der reagerer på ændringer i realtid uden direkte kobling mellem services.
Desuden, i asynkron Publicer-Abonner (Pub/Sub) mikroservices-kommunikationsmønstre sender services (udgiver) beskeder til et emne, og andre services (abonnenter) lytter til det emne for at modtage opdateringer. Denne model understøtter flere abonnenter og udsender samtidigt beskeder til mange services.
Til sidst bruger asynkrone kommunikationsmønstre, svarende til event-driven mønstre, også choreography-baseret saga mikroservices-kommunikationsmønstre events til at kommunikere med hinanden; dog er der i dette mønster en bestemt rækkefølge på plads, hvilket betyder, at events udløser næste trin og aktiverer en bestemt service.
Forskellen her er, at der ved event-drevne mønstre ikke er en bestemt sekvens eller arbejdsgang, og flere services kan reagere på en begivenhed i stedet for den specifikke proces og rækkefølge i det koreografi-baserede sagamønster.
Hvilken type asynkron mikrotjeneste-kommunikationsmønster du bruger, afhænger af opgaven og det overordnede formål med dine mikrotjenester. Meddelelseswaitro såsom RabbitMQ og Amazon SQS bruges typisk til opgaveplanlægning, arbejdsbelastningsfordeling og e-handel til ordrebehandling og notifikationssystemer.
Event-drevne meddelelses-mæglere som Apache Kafka og AWS EventBridge bruges typisk til at behandle store strømme af begivenheder i realtid og event-routing mellem mikrotjenester inden for områder som finansielle tjenester og AWS-miljøer.
Med hensyn til Publish-Subscribe (Pub/Sub) meddelelses-mæglere som Google Cloud Pub/Sub og Redis Streams bruges disse meddelelses-mæglere normalt til skalerbar messaging på tværs af distribuerede systemer til real-time analytik og event-indtagelse samt real-time notifikationer og chat-applikationer.
Endelig bruges koreografi-baserede saga-meddelelses-mæglere hovedsageligt til e-handel ordrebehandling, rejsebookingsystemer og use cases hvor komplekse flertrin-transaktioner skal koordineres på tværs af flere services uden central kontrol.
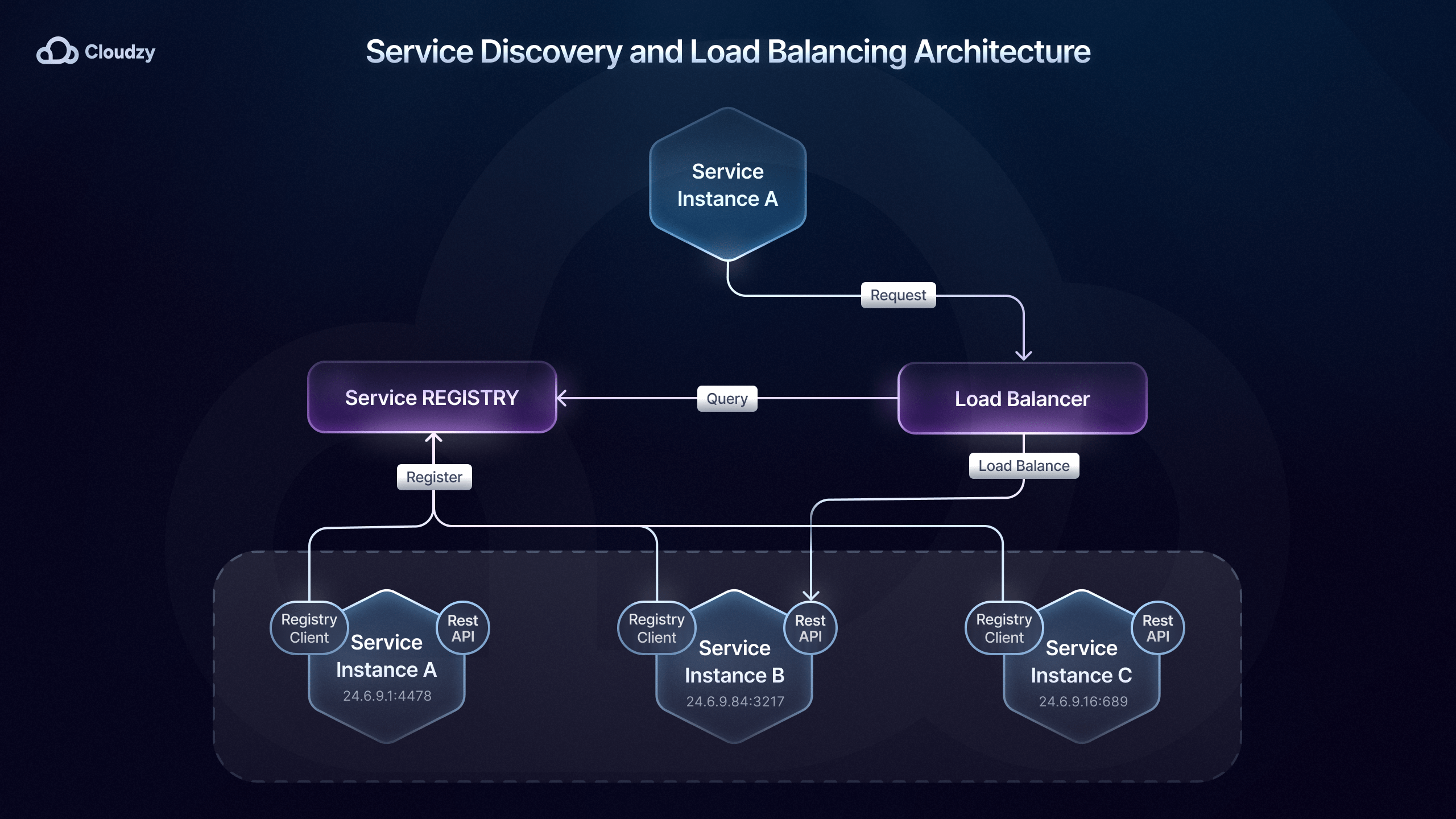
Mikrotjeneste Service Discovery
Når du har sat op og implementeret et kommunikationsmønster, der passer til dine behov, skal du sikre, at dine services kan finde hinanden. Som jeg nævnte tidligere, spiller mikrotjeneste-orkestreringsværktøjer som Kubernetes en vigtig rolle i mikrotjeneste service discovery.
Dette gøres gennem den indbyggede service discovery, som Kubernetes DNS tilbyder, der dynamisk opdaterer IP-adresser og DNS-poster, når services skaleres eller ændrer placering inden for klyngen.
Denne metode til mikrotjeneste service discovery kaldes server-side discovery, da routingansvar er delegeret til en belastningsfordeler, som derefter forespørger registreringen og dirigerer trafik til den passende instans.
På den anden side har vi også client-side discovery-metoden til mikrotjeneste service discovery, hvor servicen eller API gateway forespørger et service-register såsom Consul eller Eureka for at finde tilgængelige instanser.
Valg af hvilken service discovery-metode der er bedst for din mikrotjeneste-implementering afhænger af systemets krav og skala.
Med client-side mikrotjeneste service discovery har klienten fuld kontrol over, hvilken instans den kommunikerer med. Dette giver ikke kun mulighed for mere tilpasning, men reducerer også kompleksitet, da der ikke er behov for en centraliseret discovery-service.
Netflix' mikrotjeneste-implementering bruger for eksempel client-side mikrotjeneste service discovery med Eureka og Ribbon til belastningsfordeling, hvilket giver klienten mulighed for at vælge den bedste instans baseret på kriterier som latency og serverbelastning.
Server-side mikrotjeneste service discovery er dog mere velegnet til større miljøer, da en centraliseret service discovery kan forbedre effektiviteten og muliggøre konsistent belastningsfordeling på tværs af et distribueret system.
Server-side mikrotjeneste service discovery-løsninger såsom Kubernetes, AWS Elastic Load Balancing og API Gateways (Kong, NGINX osv.) hjælper med at dirigere trafik effektivt og opretholde høj tilgængelighed og bruges af virksomheder som Airbnb, Pinterest, Expedia, Lyft osv.
Microservice-sikkerhed
Mens monolitisk arkitektur for det meste er ringere end MSA, var sikkerhed et område, hvor monolitisk arkitektur havde fordelen. Siden mikrotjenester er bygget på Loose Coupling-princippet og er distribueret af natur, kan en enkelt, generel sikkerhedsforanstaltning ikke implementeres.
Siden hver service skal sikres uafhængigt, er der brug for yderligere sikkerhedsforanstaltninger, da angrebsfladen er meget større i mikrotjenester. Til dette formål bruges standarder som OAuth2 og JSON Web Tokens (JWT) almindeligvis til, som du måske kunne gætte, godkendelse og autorisering.
Desuden bruges en API gateway også ofte til at administrere sikkerhed på tværs af mikrotjenester, da den håndhæver godkendelse og autorisering ved indgangspunktet. Plus, gateway APIs kan også implementere rate limiting, logging og monitoring, som giver ekstra lag af mikrotjeneste-sikkerhed.
Selv om disse sikrer indgangspunktet, er der behov for flere mikrotjeneste-sikkerhedsforanstaltninger for at dække kommunikation mellem services.
Det er her service meshes kommer ind i billedet, da de tilføjer et lag af netværks-mikrotjeneste-sikkerhed og krypterer trafik mellem services og håndhæver politikker som mutual TLS. Disse server meshes opstiller grundlæggende end-to-end-kryptering, der betydeligt forbedrer mikrotjeneste-sikkerhed.
Mikroservice-skalering
En af de største fordele ved MSA, og den meget grund til, at det blev udviklet til at erstatte monolitisk arkitektur, er dets høje skalerbarhed. Typisk kan mikrotjeneste-skalering ske på to måder: vertikal og horisontal.
Grundlæggende betyder vertikal mikrotjeneste-skalering (skalering op) at tilføje flere ressourcer, såsom CPU eller hukommelse, til en eksisterende instans. Alternativt distribuerer horisontal mikrotjeneste-skalering (skalering ud) belastningen og øger kapaciteten.
Med hensyn til implementering er vertikal mikrotjeneste-skalering det nemmeste af de to, siden alt du skal gøre er at ændre en enkelt instans ved at opgradere til en større server, øge hukommelse eller processingkraft i en cloud-instans eller tilføje mere lagring.
Denne type skalering bruges typisk i tilfælde, hvor øget RAM eller CPU-kraft kan forbedre forespørgselsydeevne og databehandling, såsom services, der er ansvarlige for in-memory caching.
Det er dog værd at bemærke, at selv om vertikal mikroservices-skalering er nemmere og giver en øjeblikkelig ydelsesforbedring, har den også ulemper. Vertikal skalering er begrænset af serverens hardwarekapacitet, så på et tidspunkt bliver du nødt til at skifte til horisontal skalering for at fortsætte skaleringen.
Desuden har vertikal skalering høje omkostninger, da hardware og større instanser generelt kommer med en høj pris. Endelig, hvis den skaleret-op instans fejler, går hele tjenesten ned, da der ikke er yderligere instanser til at håndtere belastningen.
Ved horisontal mikroservices-skalering i stedet for at opgradere ressourcerne på en enkelt instans, implementerer du nye instanser af denne tjeneste. Mens disse instanser arbejder uafhængigt, håndterer de stadig den samme tjeneste og dele af den samme arbejdsbyrde.
I modsætning til vertikal skalering er horisontal mikroservices-skalering ubegrænset, hvilket betyder, at du kan tilføje så mange instanser, som du ønsker, for at håndtere stigende arbejdsbyrder og trafiktoppe, hvilket giver større skalerbarhed.
Derudover, da du har flere instanser, hvis en går ned, lægger du ikke alle dine æg i én kurv, da andre instanser kan fortsætte med at håndtere anmodninger. Endelig er horisontal skalering meget mere omkostningseffektiv på lang sigt, da du kan bruge flere mindre og billigere instanser til at danne en mere pålidelig og mere kraftfuld ydeevne.
Det er dog værd at bemærke, at horisontal skalering og tilføjelse af flere instanser kræver flere load balancere, mikroservices-tjenesteopdagelsesmekanismer og orkestreringsværktøjer til mikroservices, hvilket gør din mikroservices-arkitektur meget mere kompleks.
Horisontal skalering er bedre egnet til use cases som webtjenester og applikationer som e-handel eller sociale medieplatforme, som ofte oplever svingende trafik og et høj volumen af anmodninger.
Det er dog værd at bemærke, at det ikke virkelig er et spørgsmål om det ene eller det andet, da begge skaleringtyper understøttes i mikroservices og er nødvendige i mange tilfælde. Typisk bruger mindre organisationer vertikal skalering, da det er meget enklere at implementere og administrere, men over tid og når applikationen vokser, introduceres horisontal skalering for at håndtere den høje efterspørgsel.
Endelig tilbyder cloud-platforme auto-skaleringstjenester, der automatisk tilføjer eller fjerner instanser baseret på realtidsefterspørgsel, hvilket i høj grad hjælper organisationer med at balancere vertikal og horisontal skalering.
Microservice-overvågning
På dette tidspunkt er du stort set færdig med din mikroservices-udrulning. Alt, der mangler, er at sikre, at den fungerer konsistent og pålideligt. Det er her, mikroservices-overvågningsværktøjer som Prometheus og Grafana Trin ind.
Disse værktøjer giver realtidsindsigt i servicemetrikker, så teams kan spore ressourceforbrug, latens og fejlrate. Desuden tilbyder disse værktøjer også distribueret tracing (Jaeger, Zipkin osv.), som hjælper med at visualisere anmodningsflow på tværs af tjenester og kan være enormt brugbart til diagnosticering af problemer.
Endelig, da fejl kan kaskadere på tværs af tjenester på grund af det distribuerede design af mikroservices, er logaggrering en kritisk praksis i mikroservices-overvågning. Ved at konsolidere logs til en centraliseret platform og opsætning af realtidsadvarsler, vil du altid være to skridt foran problemerne og kan reagere proaktivt på dem, før de påvirker brugerne.
Afsluttende tanker
Selvom verden af mikroservices helt sikkert er vanskelig at få grep om, kan forståelse af grundlæggende principper og vigtige trin i mikroservices-udrulning gøre hele processen meget nemmere. Desuden kommer der med årene flere og flere værktøjer med betydeligt flere funktioner til din rådighed, hvilket gør mikroservices-udrulning nemmere end nogensinde før.
Ofte stillede spørgsmål
Hvilke deployment-strategier bruges typisk til mikrotjenester?
Selvom der er mange forskellige strategier til mikroservices-udrulning, omfatter de mest almindeligt anvendte udrulningsstrategier serviceinstanser pr. container, trinvise frigivelser, blå-grøn udrulning og serverløs udrulning, som hver tilbyder forskellige niveauer af isolering, fleksibilitet og skalerbarhed.
Hvilken rolle spiller Kubernetes i orkestrering af mikrotjenester?
Mikroservices er afhængige af orkestreringsværktøjer til mikroservices som Kubernetes for at automatisere udrulning, skalering og administration af containeriserede tjenester, hvilket giver load balancing, auto-skalering og selv-helende evner for at sikre modstandsdygtige og effektive mikroservices.
Hvordan sikrer jeg sikkerhed i et mikroservices-miljø?
På grund af deres distribuerede karakter er mikroservices mere komplicerede, når det kommer til sikkerhed sammenlignet med monolitisk arkitektur. Sikkerhed i mikroservices involverer autentificering og autorisering af anmodninger, kryptering af inter-service-kommunikation og implementering af API-gateways og service meshes som Istio til centraliseret sikkerhedsstyring.


