
L'un des aspects les plus importants du machine learning, sinon le plus important, est d'obtenir des prédictions précises et fiables. Une approche innovante qui a gagné en popularité pour atteindre cet objectif est le Bootstrap Aggregating, plus communément appelé bagging en machine learning. Cet article présente le bagging en machine learning, compare le bagging et le boosting, illustre le concept avec un exemple de classifieur bagging, explique son fonctionnement et examine ses avantages ainsi que ses limites.
Qu'est-ce que le bagging en machine learning ?
Voici les deux seules images pertinentes utilisées dans les articles populaires. L'une ou les deux peuvent être utilisées (l'une ici, l'autre ailleurs) si nous demandons au pôle Design de créer des versions aux couleurs de Cloudzy.
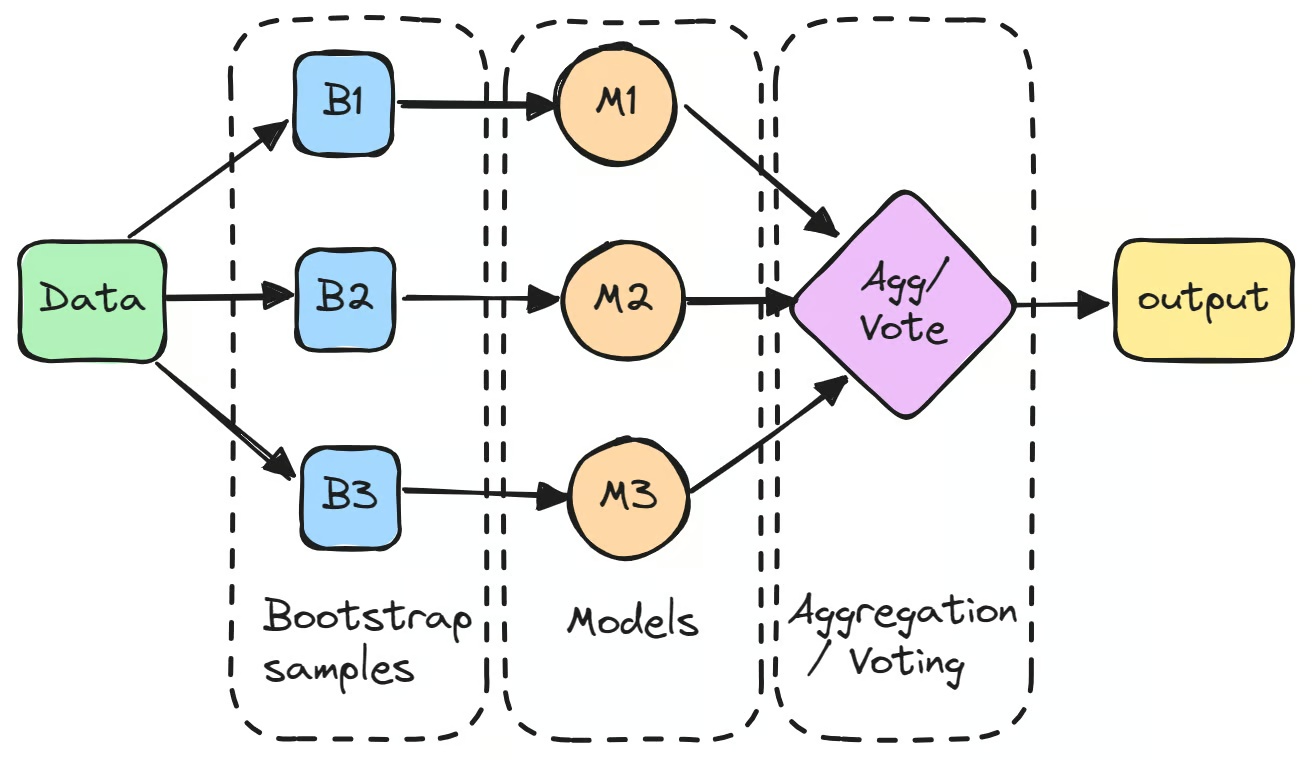
Qu'est-ce que le bagging ?
Imaginez que vous essayez d'estimer le poids d'un objet en demandant à plusieurs personnes de le deviner. Individuellement, leurs réponses peuvent varier considérablement, mais en faisant la moyenne de toutes les estimations, vous obtenez un résultat plus fiable. C'est le principe du bagging : combiner les sorties de plusieurs modèles pour produire une prédiction plus précise et plus stable.
Le processus commence par la création de plusieurs sous-ensembles du jeu de données original par bootstrapping, c'est-à-dire un échantillonnage aléatoire avec remise. Chaque sous-ensemble est ensuite utilisé pour entraîner un modèle distinct de façon indépendante.
Ces modèles individuels, souvent appelés « apprenants faibles », peuvent ne pas performer de manière exceptionnelle seuls, en raison d'une variance élevée. Cependant, lorsque leurs prédictions sont agrégées, généralement par moyennage pour les tâches de régression ou par vote majoritaire pour les tâches de classification, le résultat combiné dépasse souvent les performances de n'importe quel modèle pris isolément.
Un exemple courant de classifieur bagging est l'algorithme de Random Forest, qui construit un ensemble d'arbres de décision pour améliorer les performances prédictives. Cela dit, le bagging ne doit pas être confondu avec le boosting en machine learning : celui-ci adopte une approche différente en entraînant les modèles séquentiellement pour réduire le biais, tandis que le bagging entraîne les modèles en parallèle pour réduire la variance.
Le bagging et le boosting en machine learning visent tous deux à améliorer les performances des modèles, mais ils ciblent des aspects différents du comportement du modèle.
Pourquoi le bagging est-il utile ?
L'un des principaux avantages du bagging en machine learning est sa capacité à réduire la variance, ce qui aide les modèles à mieux généraliser sur des données inédites. Le bagging est particulièrement bénéfique pour les algorithmes sensibles aux variations des données d'entraînement, comme les arbres de décision.
En évitant le surapprentissage, il garantit un modèle plus stable et plus fiable. Lorsqu'on compare le bagging et le boosting en machine learning, le bagging se concentre sur la réduction de la variance en entraînant plusieurs modèles en parallèle, tandis que le boosting vise à réduire le biais en entraînant les modèles séquentiellement.
Le bagging en machine learning peut s'illustrer par la prédiction du risque financier : plusieurs arbres de décision sont entraînés sur différents sous-ensembles de données historiques de marché. En agrégeant leurs prédictions, le bagging produit un modèle de prévision plus fiable, en limitant l'impact des erreurs de chaque modèle individuel.
En résumé, le bagging en machine learning tire parti de l'intelligence collective de plusieurs modèles pour produire des prédictions plus précises et plus fiables que celles issues d'un seul modèle.
Comment fonctionne le bagging en machine learning : étape par étape
Pour bien comprendre comment le bagging améliore les performances des modèles, décomposons le processus étape par étape.
Tirer plusieurs échantillons bootstrap du jeu de données
La première étape du bagging en machine learning consiste à créer plusieurs nouveaux sous-ensembles du jeu de données original par bootstrapping. Cette technique repose sur un échantillonnage aléatoire avec remise : certains points de données peuvent donc apparaître plusieurs fois dans le même sous-ensemble, tandis que d'autres peuvent ne pas apparaître du tout. Ce procédé garantit que chaque modèle est entraîné sur une version légèrement différente des données.
Entraîner un modèle distinct sur chaque échantillon
Chaque échantillon bootstrap est ensuite utilisé pour entraîner un modèle distinct, généralement du même type, comme des arbres de décision. Ces modèles, souvent appelés « apprenants de base » ou « apprenants faibles », sont entraînés indépendamment sur leurs sous-ensembles respectifs. L'arbre de décision utilisé dans l'algorithme Random Forest en est un exemple typique de classifieur bagging, et constitue la base de nombreux modèles fondés sur le bagging. Même si chaque modèle individuel peut ne pas performer de manière optimale seul, il apporte des informations uniques issues de ses données d'entraînement spécifiques.
Agréger les prédictions
Une fois les modèles entraînés, leurs prédictions sont agrégées pour former la sortie finale.
- Pour les tâches de régression, les prédictions sont moyennées, ce qui réduit la variance du modèle.
- Pour les tâches de classification, la prédiction finale est déterminée par vote majoritaire : la classe prédite par le plus grand nombre de modèles est retenue. Cette méthode produit une prédiction plus stable que celle d'un modèle unique.
Prédiction finale
En combinant les prédictions de plusieurs modèles, le bagging réduit l'impact des erreurs d'un modèle isolé et améliore la précision globale. Ce processus d'agrégation est ce qui fait du bagging une technique particulièrement efficace, notamment pour les tâches de machine learning faisant appel à des modèles à forte variance comme les arbres de décision. Il lisse efficacement les incohérences des prédictions individuelles, aboutissant à un modèle final plus solide.
Bien que le bagging soit efficace pour stabiliser les prédictions, quelques points méritent attention : un risque de surapprentissage subsiste si les modèles de base sont trop complexes, malgré l'objectif général du bagging de le réduire.
Le bagging peut également être coûteux en calcul. Ajuster le nombre d'apprenants de base ou se tourner vers des méthodes d'ensemble plus efficaces peut aider, et choisir le bon GPU pour le ML et le DL est toujours important.
Veillez à diversifier les modèles de base pour de meilleurs résultats. Si vous travaillez avec des données déséquilibrées, des techniques comme SMOTE peuvent être utiles avant d'appliquer le bagging, afin d'éviter de mauvaises performances sur les classes minoritaires.
Applications du bagging
Maintenant que nous avons vu comment le bagging fonctionne, voyons où il est réellement utilisé. Le bagging s'est imposé dans de nombreux secteurs, en améliorant la précision et la stabilité des prédictions dans des situations complexes. Voici quelques-unes de ses applications les plus marquantes :
- Classification et régression : Le bagging est largement utilisé pour améliorer les performances des classifieurs et des régresseurs en réduisant la variance et en limitant le surapprentissage. Par exemple, les forêts aléatoires (Random Forests), qui s'appuient sur le bagging, donnent de bons résultats dans des tâches comme la classification d'images et la modélisation prédictive.
- Détection d'anomalies : Dans des domaines comme la détection de fraude ou l'intrusion réseau, les algorithmes de bagging offrent de meilleures performances en identifiant efficacement les valeurs aberrantes et les anomalies dans les données.
- Évaluation du risque financier : Les techniques de bagging sont utilisées dans le secteur bancaire pour améliorer les modèles de scoring de crédit, ce qui renforce la précision des décisions d'octroi de prêts et des évaluations du risque financier.
- Diagnostic médical : Dans le domaine de la santé, le bagging a été appliqué à la détection de troubles neurocognitifs comme la maladie d'Alzheimer, par l'analyse de jeux de données IRM, contribuant au diagnostic précoce et à la planification du traitement.
- Traitement automatique du langage naturel (NLP) : Le bagging améliore des tâches comme la classification de texte et l'analyse de sentiment en agrégeant les prédictions de plusieurs modèles, ce qui conduit à une meilleure compréhension du langage.
Avantages et inconvénients du bagging
Comme toute technique de machine learning, le bagging a ses propres avantages et inconvénients. Les comprendre permet de mieux décider quand et comment l'utiliser dans vos modèles.
Avantages du bagging :
- Réduction de la variance et du surapprentissage : L'un des principaux atouts du bagging est sa capacité à réduire la variance, ce qui limite le surapprentissage. En entraînant plusieurs modèles sur des sous-ensembles différents des données, le bagging vous assure que le modèle ne devient pas trop sensible aux variations dans les données d'entraînement, ce qui produit un modèle plus stable et mieux généralisable.
- Efficace avec les modèles à forte variance : Le bagging est particulièrement efficace avec les modèles à forte variance, comme les arbres de décision. Ces modèles ont tendance à surapprendre et présentent une variance élevée, mais le bagging atténue ce problème en moyennant les prédictions ou en procédant à un vote entre plusieurs modèles. Les prédictions sont ainsi plus fiables et moins sensibles au bruit dans les données.
- Amélioration de la stabilité et des performances du modèle : En combinant plusieurs modèles entraînés sur des sous-ensembles différents des données, le bagging conduit souvent à de meilleures performances globales. Il améliore la précision prédictive tout en réduisant la sensibilité du modèle aux petites variations dans le jeu de données, ce qui le rend au final plus fiable.
Inconvénients du bagging :
- Coût de calcul plus élevé : Le bagging nécessite d'entraîner plusieurs modèles, ce qui augmente naturellement le coût de calcul. L'entraînement et l'agrégation des prédictions de nombreux modèles peuvent prendre beaucoup de temps, surtout avec de grands jeux de données ou des modèles complexes comme les arbres de décision.
- Peu efficace pour les modèles à faible variance : Si le bagging est très efficace pour les modèles à forte variance, il apporte peu d'avantages lorsqu'il est appliqué à des modèles à faible variance comme la régression linéaire. Dans ces cas, les modèles individuels affichent déjà de faibles taux d'erreur, et l'agrégation des prédictions n'améliore que marginalement les résultats.
- Perte d'interprétabilité : En combinant plusieurs modèles, le bagging réduit l'interprétabilité du modèle final. Dans une Random Forest, par exemple, le processus de décision repose sur de nombreux arbres de décision, ce qui rend difficile l'analyse du raisonnement derrière une prédiction spécifique.
Quand utiliser le bagging ?
Savoir quand appliquer le bagging dans vos projets de machine learning est essentiel pour obtenir des résultats optimaux. Cette technique fonctionne bien dans des situations précises, mais elle n'est pas toujours le meilleur choix pour chaque problème.
Quand votre modèle est sujet au surapprentissage
Le bagging est particulièrement indiqué lorsque votre modèle est sujet au surapprentissage, notamment avec des modèles à forte variance comme les arbres de décision. Ces modèles peuvent obtenir de bonnes performances sur les données d'entraînement, mais peinent souvent à généraliser sur des données inédites, car ils s'adaptent trop étroitement aux patterns spécifiques du jeu d'entraînement.
Le bagging permet de contrer ce phénomène en entraînant plusieurs modèles sur différents sous-ensembles de données, puis en combinant leurs prédictions par moyenne ou vote majoritaire. Cela réduit le risque de surapprentissage et améliore la capacité du modèle à traiter de nouvelles données.
Quand vous souhaitez améliorer la stabilité et la précision
Si vous cherchez à améliorer la stabilité et la précision de votre modèle sans trop sacrifier l'interprétabilité, le bagging est un excellent choix. L'agrégation des prédictions de plusieurs modèles renforce la fiabilité du résultat final, ce qui est particulièrement utile lorsque les données contiennent du bruit.
Que vous travailliez sur des problèmes de classification ou des tâches de régression, le bagging permet d'obtenir des résultats plus cohérents, en améliorant la précision tout en maintenant l'efficacité.
Quand vous disposez de ressources de calcul suffisantes
La disponibilité des ressources de calcul est un facteur déterminant pour décider d'utiliser le bagging. Comme cette technique nécessite d'entraîner plusieurs modèles en parallèle, le coût de calcul peut devenir significatif, surtout avec de grands jeux de données ou des modèles complexes.
Si vous disposez de la puissance de calcul nécessaire, les avantages du bagging dépassent largement ses coûts. En revanche, si les ressources sont limitées, il peut être préférable d'envisager des techniques alternatives ou de réduire le nombre de modèles dans votre ensemble.
Quand vous travaillez avec des modèles à forte variance
Le bagging est particulièrement utile avec des modèles à forte variance, sensibles aux variations des données d'entraînement. Les arbres de décision, par exemple, sont fréquemment utilisés avec le bagging sous la forme de Random Forests, car leurs performances varient considérablement selon les données d'entraînement.
En entraînant plusieurs modèles sur différents sous-ensembles de données et en combinant leurs prédictions, le bagging lisse la variance et produit un modèle plus fiable.
Quand vous avez besoin d'un classifieur fiable
Si vous travaillez sur des problèmes de classification et avez besoin d'un classifieur fiable, le bagging peut améliorer sensiblement la stabilité de vos prédictions. Une Random Forest, qui est un exemple typique de classifieur par bagging, produit des prédictions plus précises en agrégeant les résultats de nombreux arbres de décision individuels.
Cette approche fonctionne bien lorsque les modèles individuels sont relativement faibles, mais que leur combinaison donne un modèle global performant.
Par ailleurs, si vous cherchez la bonne plateforme pour implémenter efficacement des techniques de bagging, des outils comme Databricks et Snowflake proposent une plateforme d'analyse unifiée particulièrement utile pour gérer de grands volumes de données et exécuter des méthodes d'ensemble comme le bagging.
Si vous cherchez une approche moins technique du machine learning, les outils d'IA sans code peuvent être une option intéressante. Même s'ils ne se concentrent pas directement sur des techniques avancées comme le bagging, de nombreuses plateformes sans code permettent d'expérimenter des méthodes d'apprentissage par ensemble, y compris le bagging, sans nécessiter de compétences poussées en programmation.
Vous pouvez ainsi appliquer des techniques plus sophistiquées et obtenir des prédictions précises, en vous concentrant sur les performances du modèle plutôt que sur le code sous-jacent.
Pour conclure
Le bagging en machine learning est une technique efficace qui améliore les performances des modèles en réduisant la variance et en augmentant leur stabilité. En agrégeant les prédictions de plusieurs modèles entraînés sur différents sous-ensembles de données, le bagging produit des résultats plus précis et plus fiables. Il est particulièrement adapté aux modèles à forte variance comme les arbres de décision, où il aide à prévenir le surapprentissage et à mieux généraliser sur des données inédites.
Malgré ses avantages indéniables - réduction du surapprentissage et amélioration de la précision - le bagging implique quelques compromis. Il augmente le coût de calcul en raison de l'entraînement de plusieurs modèles et peut réduire l'interprétabilité. Ces inconvénients mis à part, sa capacité à améliorer les performances en fait une technique précieuse en apprentissage par ensemble, aux côtés d'autres méthodes comme le boosting et le stacking.
Avez-vous utilisé le bagging dans vos projets de machine learning ? Dites-nous comment ça s'est passé et ce que vous en avez retiré !


