Un logiciel de surveillance GPU, c'est ce qui transforme un vague « mon GPU se comporte bizarrement » en une explication claire et précise, du genre « point chaud détecté, fréquences réduites, VRAM saturée. »
Dans ce guide, je vous présente les outils adaptés aux jobs d'IA, aux overlays gaming et aux longues sessions de travail en station fixe, ainsi que les métriques GPU qui permettent de diagnostiquer les ralentissements, les saccades et les crashs.
À la fin, vous aurez une configuration de surveillance GPU adaptée à votre façon de travailler. Vous trouverez aussi des stacks prêtes à copier pour quatre cas d'usage courants, sans avoir à chercher ailleurs.
Réponse rapide : les meilleurs logiciels de surveillance GPU par cas d'usage
Si vous voulez simplement une liste courte qui correspond à la façon dont les gens travaillent vraiment, commencez par celle-ci. En pratique, le meilleur stack de surveillance GPU est souvent une combinaison : un outil pour les vérifications rapides, un autre pour les overlays ou les logs, et un dernier pour l'historique ou les alertes.
Voici la carte rapide :
| Cas d'usage | Stack de départ recommandé | Ce que vous obtenez |
| Entraînement IA, inférence, jobs HPC | nvidia-smi (NVIDIA) ou AMD SMI (AMD) + logging/exporter | Vérifications rapides, logs scriptables, alertes faciles à configurer |
| Gaming sur Windows | MSI Afterburner + RTSS + un outil de capture de frametime | Overlay et données concrètes pour distinguer les saccades des baisses de FPS |
| Gaming sur Linux | MangoHud + un outil en ligne de commande (nvtop) | Overlay léger avec vérifications par processus |
| Stations de travail (3D/vidéo/CAO) | Journalisation HWiNFO + test de charge simple | Journaux détaillés partageables, reproduction fiable |
| Machines partagées GPU | nvtop (Linux) + exportateur/tableau de bord | Visibilité VRAM par processus |
À partir de là, l'essentiel est d'associer le logiciel de surveillance GPU à la façon dont vous consommez les données : à l'écran, dans un journal ou dans un tableau de bord.
À qui s'adresse ce guide
Je vais écrire ce guide comme quelqu'un qui a dû déboguer de vraies machines. C'est parce que, par expérience, je sais que des lecteurs différents ont besoin d'outils GPU différents, même s'ils regardent le même GPU.
Voici les quatre profils que je cible :
- Le développeur de modèles (IA/ML) : se soucie de la marge VRAM, des fréquences soutenues, de la limitation thermique, et de savoir si le job a tourné toute la nuit sans planter.
- Le gamer compétitif/streamer : se soucie des temps d'image, de la stabilité de l'overlay et de la détection des régressions après les mises à jour de pilotes.
- L'utilisateur station de travail (3D/vidéo/CAO) : se soucie des journaux, des plantages reproductibles et de l'identification de la cause : chaleur, consommation ou comportement des pilotes.
- L'administrateur de machines GPU : se soucie des alertes, des graphiques de tendance, de la planification de capacité et de la détection précoce des pannes.
Une fois que vous savez dans quelle catégorie vous vous trouvez, vous pouvez facilement choisir le logiciel de surveillance GPU qui vous convient.
Comment choisir un logiciel de surveillance GPU
Beaucoup d'applications de surveillance des performances se ressemblent jusqu'au moment où vous les utilisez pendant une semaine. La vraie différence tient généralement à la qualité des sorties et à la fiabilité, plutôt qu'aux fonctionnalités que chacune met en avant.
Voici trois questions pour vous aider à choisir rapidement un logiciel de surveillance GPU :
- Avez-vous besoin d'un overlay, d'un journal, ou des deux ?
Les gamers veulent un overlay. Le travail IA et station de travail nécessite généralement une journalisation. Les administrateurs veulent des journaux et des alertes. - Avez-vous besoin d'une visibilité par processus ?
Si vous partagez une machine (lab, studio, serveur distant), le VRAM par processus est souvent la première chose que vous cherchez. - Avez-vous besoin d'un historique et d'alertes ?
Si vos tâches tournent la nuit, « je vérifierai plus tard » ne suffit pas. Il vous faut un graphique et une alerte.
Pour rester concret, la suite du guide est organisée par métriques GPU d'abord, puis par ensembles d'outils adaptés à chaque cas d'usage.
Métriques GPU à prioriser
Un bon logiciel de monitoring Go GPU vous affiche beaucoup de chiffres. Un logiciel vraiment utile vous donne la poignée de métriques qui expliquent réellement le comportement. Je regroupe les métriques GPU selon la décision qu'elles vous aident à prendre.
Métriques thermiques et de bridage
Ce sont les métriques GPU qui expliquent « c'était rapide pendant 10 minutes, puis ça ne l'était plus » :
- Température GPU
- Température des points chauds (souvent la première à grimper)
- Température mémoire / jonction (plus pertinent sur les longs traitements AI et les longs rendus)
- Vitesse des ventilateurs (utile pour repérer les profils laptop ou les courbes de ventilation mal configurées)
Si vous cherchez à améliorer la stabilité, enregistrez ces métriques : une capture isolée donne rarement assez d'informations.
Puissance, fréquences et limites
Ces métriques GPU expliquent la réduction de fréquence et les performances irrégulières :
- Consommation électrique de la carte
- Fréquence cœur et fréquence mémoire
- Limite de puissance / état de performance (si votre outil l'expose)
Dans la majorité des cas de débogage réels, la puissance et les fréquences donnent une image bien plus claire que le simple « % d'utilisation GPU ».
VRAM et pression mémoire
Ces métriques GPU expliquent les stutters, les erreurs OOM et les ralentissements « aléatoires » typiques :
- VRAM utilisée vs totale
- Activité du contrôleur mémoire (utile pour détecter les limites de bande passante)
- Pression système RAM (car un débordement de VRAM peut aussi dégrader le système entier)
Pour l'IA, la VRAM est souvent le plafond réel. Pour les jeux, la pression VRAM se manifeste généralement d'abord par des pics de frametime.
Métriques de frametime et de frame pacing
Pour le gaming et le streaming, le FPS seul peut être trompeur. La métrique à surveiller, c'est le frametime, car elle reflète la fluidité réelle de l'image :
- Temps de frame (ms)
- 1 % bas / 0,1 % bas (utile pour les comparaisons)
- GPU occupé vs CPU occupé (permet de distinguer les goulots d'étranglement GPU des goulots CPU)
C'est pourquoi les applications de monitoring axées sur le gaming intègrent souvent une capture de frametime. Maintenant que les métriques de base sont couvertes, parlons des meilleures configurations de logiciels de monitoring GPU selon chaque usage.
Logiciels de monitoring GPU pour l'IA, l'entraînement de modèles et les serveurs

Le monitoring pour l'IA repose sur une configuration simple : des vérifications rapides en terminal, des logs et des alertes pour les exécutions longues. Pour cela, un logiciel de monitoring GPU compatible CLI et capable d'exporter des métriques est ce qu'il vous faut.
NVIDIA : nvidia-smi pour les vérifications rapides et les logs scriptables
Sur les systèmes NVIDIA, nvidia-smi est généralement la première commande que les gens exécutent, car elle est incluse avec le pilote et conçue pour le monitoring et la gestion via NVML.
La documentation officielle est disponible ici : Interface de gestion système NVIDIA (nvidia-smi).
Si vous voulez une approche simple du type « logguer maintenant, analyser plus tard » (et vous seriez surpris de voir à quelle fréquence ça suffit), ce modèle est assez fiable :
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Il s'agit du comportement de base d'un logiciel de surveillance GPU : horodatages, métriques principales du GPU, et une sortie compatible avec les scripts.
AMD : AMD SMI pour les nœuds ROCm et HPC
Sur les nœuds de calcul AMD Linux, AMD SMI est l'interface moderne de surveillance et de gestion. AMD le présente comme un outil unifié pour la surveillance et le contrôle dans les environnements HPC.
La documentation officielle est disponible ici : Documentation AMD SMI.
Si votre environnement repose principalement sur AMD, AMD SMI constitue la base de surveillance GPU sur laquelle s'appuient la plupart des autres outils.
Visibilité par processus : nvtop pour les GPU partagés
Si vous avez déjà eu un serveur partagé où la VRAM reste « mystérieusement » saturée, la visibilité par processus vous fera gagner du temps. Sur Linux, nvtop est populaire précisément pour cette raison : il rend évidente la question « qui utilise la VRAM ? ». Sur AMD/Intel, un noyau récent peut être nécessaire pour obtenir les statistiques par processus.
Dans les équipes mixtes, je vois souvent des gens lancer nvtop en parallèle avec nvidia-smi ou AMD SMI. C'est une combinaison simple qui évite beaucoup d'approximations, et je la recommande vivement.
Ne négligez pas le choix du matériel !
La surveillance ne supprime pas un plafond de VRAM, elle le rend seulement visible. Si vous êtes encore en train de répartir vos charges de travail entre les niveaux de GPU, notre guide sur Les meilleurs GPU pour le machine learning en 2025 est un bon complément, car il aborde la VRAM et la bande passante de la même façon que vous les lirez ensuite dans les journaux et les tableaux de bord.
Une fois la surveillance GPU côté serveur maîtrisée, l'étape suivante concerne les overlays et les frametimes, car les charges interactives se comportent différemment.
Logiciels de surveillance GPU pour le jeu et le streaming

Le jeu vidéo est le domaine où les avis sur les outils GPU sont les plus tranchés, surtout parce que les overlays tombent en panne au pire moment. Pour le jeu, vous voulez des overlays simples et des captures de frametime reproductibles.
MSI Afterburner + RTSS pour les overlays sur Windows
Cette combinaison est très répandue : elle permet de construire un overlay épuré avec exactement les métriques GPU qui vous intéressent, comme l'utilisation, les fréquences, la VRAM, les températures, le frametime, et éventuellement la vitesse des ventilateurs.
Un avertissement sérieux revient souvent dans les forums communautaires : les faux sites de téléchargement. La page officielle d'Afterburner de MSI précise que les téléchargements légitimes doivent provenir de msi.com et Guru3D, et elle indique également la version actuelle (4.6.6 final, publiée en octobre 2025).
Les problèmes d'overlay sont aussi à surveiller. Par exemple, RTSS fonctionne dans certains jeux et échoue dans d'autres, notamment avec les pipelines de rendu modernes. Des utilisateurs signalent des cas où l'overlay s'affiche dans Vulkan mais pas dans DX12 pour le même titre, ou disparaît après les mises à jour.
Ce n'est pas une erreur de votre part - c'est simplement ce qui arrive quand les overlays s'accrochent à des stacks de jeux et de pilotes en constante évolution.
Pour un overlay de référence stable, restez minimaliste :
- temps de frame
- Utilisation GPU
- VRAM utilisé
- Température GPU
Ajoutez la puissance et les horloges uniquement si vous déboguez activement le throttling.
Capture de frametime pour analyser les stutters
C'est là que les outils de surveillance des performances capables d'enregistrer des graphiques de frametime font toute la différence. La moyenne de FPS peut sembler correcte alors que le frame pacing est catastrophique. Les graphiques de frametime dissipent cette confusion rapidement.
De nombreux workflows de benchmark gaming s'appuient sur PresentMon en coulisses, et NVIDIA documente que son analyse FrameView utilise PresentMon pour capturer la fréquence d'images et le frame time.
Inutile de benchmarker chaque jeu. La capture de frametime est surtout utile pour les comparaisons : avant et après une mise à jour de pilote, avant et après un changement de limiteur, avant et après une modification de paramètres, et ainsi de suite.
MangoHud pour les overlays Linux
Sur Linux, MangoHud est souvent recommandé car il est léger et s'intègre proprement avec les configurations Steam/Proton. Les reproches les plus fréquents concernent des capteurs manquants ou des lectures erratiques sur les laptops hybrides.
En pratique, vous pouvez facilement associer MangoHud à un outil de vérification en terminal comme nvtop. C'est aussi un bon exemple de la raison pour laquelle un logiciel de surveillance GPU fonctionne nettement mieux sous forme d'une petite pile d'outils ciblés, plutôt qu'une seule application tentaculaire.
Après le gaming, l'étape suivante naturelle est la surveillance en environnement workstation, car c'est là que les logs et la reproductibilité deviennent vos priorités.
Hébergez des serveurs de jeu sans latence avec un hébergement VPS NVMe haute vitesse.
VPS pour le gaming
Logiciels de surveillance GPU pour workstations et applications pro
La surveillance d'une workstation ressemble moins à la veille d'un agent de sécurité devant un overlay en direct, et davantage à la recherche d'une réponse à la question : "Que s'est-il passé dans le temps, et puis-je le reproduire ?"
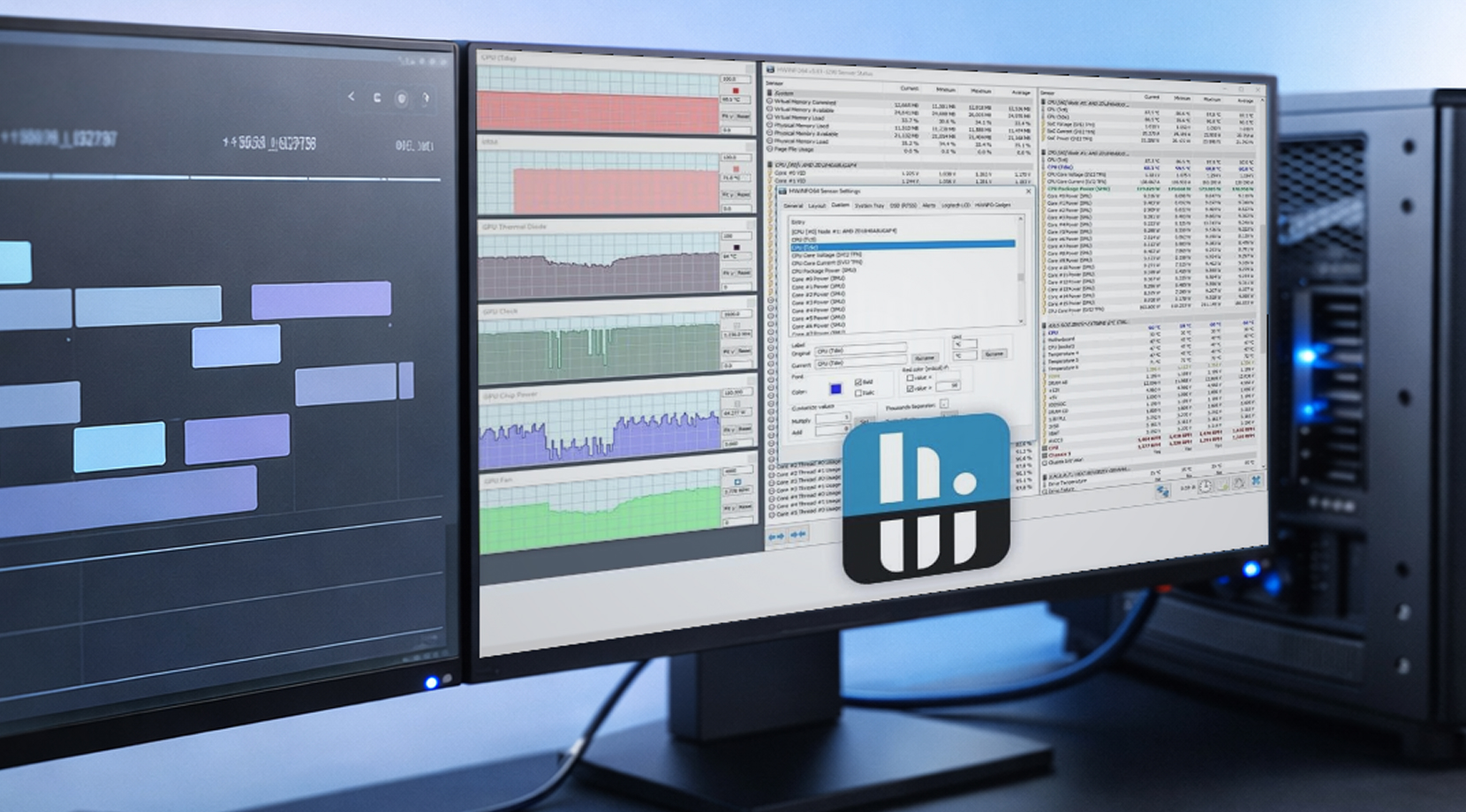
HWiNFO pour la journalisation sur Windows
HWiNFO est populaire dans les environnements workstation grâce à sa couverture approfondie des capteurs et à sa journalisation facile à partager. Un simple log CSV avec horodatage suffit à transformer un rapport vague en quelque chose d'exploitable pour corriger les problèmes.
Si vous construisez un log workstation pour la stabilité GPU, commencez par ces métriques GPU :
- Température et hotspot du GPU
- VRAM utilisé
- Puissance de la carte
- Fréquence du cœur
- Puissance du package CPU (car les limites de puissance de la plateforme peuvent poser problème)
C'est le jeu de données suffisant pour expliquer ce qui se passe. Enregistrer chaque capteur ne fait que rendre le fichier plus difficile à lire.
GPU-Z pour vérifier rapidement "Quel GPU est-ce ?"
GPU-Z reste utile parce qu'il est rapide et ciblé. Dans les équipes avec du matériel varié, c'est le moyen le plus rapide de confirmer le modèle de GPU, les informations de base du pilote et les capteurs actifs, sans fouiller dans les menus.
Tests de charge : utiles seulement avec journalisation
Les tests de charge peuvent aider à reproduire un plantage, mais seulement si votre logiciel de surveillance du GPU enregistre les données pendant leur exécution. Sans ces journaux, vous vous retrouvez avec "ça a encore planté" et pratiquement aucune chronologie.
À ce stade, la plupart des gens rencontrent les mêmes problèmes : les overlays n'apparaissent pas, les relevés de puissance semblent incorrects, et les journaux deviennent illisibles. Voici comment y remédier directement.
Problèmes courants avec les logiciels de surveillance GPU et corrections rapides

La plupart des problèmes suivent quelques schémas récurrents. Ce sont les correctifs que j'essaie en premier, car ils règlent rapidement les problèmes les plus courants.
Overlay absent dans un jeu
Si un overlay disparaît dans un jeu récent, c'est souvent un problème d'injection par jeu ou un conflit avec les couches anti-triche ou anti-falsification.
Ce que vous pouvez faire, et qui aide souvent :
- Mettez à jour RTSS et réinitialisez le profil par jeu
- Définissez un "niveau de détection d'application" plus élevé pour le profil du jeu
- Essayez un autre API si le jeu le prend en charge
- Revenez aux overlays intégrés quand un jeu bloque les overlays tiers
Tous les jeux ne coopèrent pas, et ça ne vaut pas la peine de passer des heures sur un titre récalcitrant.
Relevés de puissance aberrants (0 W, lignes plates, capteurs manquants)
Ce problème est fréquent sur les laptops et les configurations hybrides où le GPU actif peut changer. Dans ces cas, vérifiez avec un second outil, comme nvidia-smi (NVIDIA) ou AMD SMI (AMD), qui permettent de confirmer si le GPU est bien actif.
Journaux trop volumineux
Le suréchantillonnage en est généralement la cause. Pour la plupart des dépannages, un intervalle de 1 à 5 secondes suffit. Pour les tâches AI longues, 5 secondes conviennent. Des intervalles plus courts font grossir la taille des fichiers et rendent les graphiques plus difficiles à lire.
Une fois ces bases établies, la surveillance à distance devient l'étape suivante, car beaucoup de workflows GPU tournent désormais hors machine.
Surveillance GPU à distance et une option cloud pratique
Le travail à distance change ce que signifie « un bon logiciel de surveillance GPU ». Vous n'êtes pas toujours devant la machine, donc vous avez besoin de vérifications rapides et d'un historique consultable plus tard.
Une configuration à distance bien organisée ressemble généralement à ceci :
- Vérifications CLI (nvidia-smi ou AMD SMI)
- un fichier de logs que vous pouvez récupérer plus tard
- un exporteur/tableau de bord si vous avez besoin d'alertes
Si le matériel local bloque votre progression (limites VRAM, partage d'un seul GPU, besoin d'un environnement propre par projet), exécuter vos workloads sur un VPS GPU peut être la solution la plus directe pour avancer.
Cloudzy GPU VPS

Si vous cherchez du temps GPU à distance adapté aux workflows d'IA, de gaming et de rendu, notre Cloudzy GPU VPS inclut des options NVIDIA comme RTX 5090, A100 et RTX 4090, ainsi que du stockage NVMe, un accès root complet, des connexions jusqu'à 40 Gbps, la protection DDoS et un objectif de disponibilité de 99,95 %.
Du point de vue de la surveillance, il se comporte comme une machine classique : vous pouvez exécuter votre logiciel de surveillance GPU via SSH, enregistrer les métriques GPU sur des jobs longs, et ajouter des tableaux de bord pour l'historique et les alertes.
Si vous hésitez encore entre une instance GPU et une configuration CPU uniquement, nos articles sur Qu'est-ce qu'un VPS GPU ? et GPU vs VPS CPU détaillent les différences concrètes selon le type de workload.
La surveillance à distance étant couverte, il ne reste plus qu'à tout assembler dans des configurations prêtes à l'emploi.
Configurations prêtes à l'emploi par profil
Voici des configurations simples à adopter sans réécrire l'ensemble de votre workflow. Ce sont de bons points de départ que vous pourrez ensuite adapter à vos besoins spécifiques.
- Model Builder (IA/ML) : logiciel de surveillance GPU via nvidia-smi ou AMD SMI, plus un simple log CSV, plus un exporteur/tableau de bord si les jobs tournent sans surveillance.
- Gamer compétitif/Streamer : logiciel de surveillance GPU en overlay via Afterburner + RTSS, plus un outil de capture du frametime pour les comparaisons, plus un jeu minimal de métriques à l'écran.
- Utilisateur workstation : logiciel de surveillance GPU via la journalisation HWiNFO, plus GPU-Z pour des vérifications rapides, plus un test de charge uniquement quand vous pouvez enregistrer l'exécution.
- Administration des machines GPU en cours d'exécution : GPU monitoring software as a service : exportateur + tableaux de bord + alertes, avec visibilité par processus (nvtop) pour les serveurs partagés.
Si vous ne retenez qu'une seule chose de ce guide, c'est celle-ci : choisissez votre GPU monitoring software en fonction de l'endroit où vous avez besoin des données (overlay, journal, tableau de bord), puis limitez votre ensemble de métriques à ce que vous utiliserez vraiment.