
Dans les années 60 et 70, l'architecture monolithique était privilégiée pour le développement d'applications en raison des ressources informatiques limitées de l'époque, qui imposaient de regrouper toutes les fonctionnalités dans une seule unité cohérente.
C'est vers la fin des années 90 et dans les années 2000 que cette approche a commencé à montrer ses limites face à la taille et à la complexité croissantes des applications, notamment avec l'essor d'Internet et des systèmes distribués.
Cela a conduit au développement d'approches plus modulaires, comme les architectures orientées services (SOA) puis, plus tard, les architectures de microservices (MSA), qui se sont imposées au début des années 2010.
Cela dit, ce n'est qu'une introduction aux concepts de base des microservices. Voyons donc comment les microservices ont remplacé l'architecture monolithique, comment ils fonctionnent, et quelques exemples concrets. Nous aborderons ensuite les aspects clés du déploiement de microservices et la marche à suivre si vous souhaitez vous lancer.
Qu'est-ce que les microservices ? Comment fonctionnent-ils ?
Comme évoqué précédemment, les microservices sont apparus comme une réponse à la complexité et à la taille croissantes des applications, permettant aux entreprises de décomposer leurs fonctions en services déployables de manière indépendante.
Le terme « microservices » a été popularisé par des experts du secteur comme Martin Fowler et James Lewis, qui l'ont formellement introduit dans un article de blog en 2014. Leurs travaux ont défini les principes et caractéristiques fondamentaux, notamment la nécessité de services déployables indépendamment, une gestion décentralisée des données et une neutralité technologique.
Depuis lors, les microservices sont devenus un choix architectural courant, porté par les avancées en matière de technologies de conteneurisation comme Docker, d'outils d'orchestration comme Kubernetes, et de plateformes de calcul serverless. Mais comment fonctionnent concrètement les microservices ?
Comment fonctionnent les microservices ?
Dans son principe, une architecture de microservices décompose une application volumineuse en services plus petits et distincts, chacun responsable d'une capacité métier spécifique. Ces services communiquent entre eux via un réseau, souvent par le biais de REST APIs, de gRPC, ou de brokers de messages comme RabbitMQ ou Apache Kafka.
Selon la définition de Martin Fowler et James Lewis, les microservices partagent quatre caractéristiques fondamentales :
- Responsabilité unique : Chaque microservice est conçu pour accomplir une tâche ou une fonction précise, ce qui favorise la spécialisation et réduit la complexité.
- Indépendance : Les microservices peuvent être développés, déployés et mis à l'échelle indépendamment les uns des autres, ce qui offre flexibilité et résilience.
- Gestion décentralisée des données : Les microservices disposent souvent de leurs propres bases de données, évitant ainsi la dépendance à une base de données unique et centralisée.
- Indépendance technologique : Les équipes peuvent choisir la technologie la plus adaptée à chaque service, sans être contraintes par les choix faits pour les autres services.
Cette approche s'oppose à l'architecture monolithique traditionnelle, dans laquelle tous les composants d'une application sont étroitement intégrés dans une seule unité cohésive.
Les étapes clés du déploiement de microservices
Si une architecture microservices offre de nombreux avantages - haute disponibilité, flexibilité, efficacité, isolation des pannes, etc. - elle exige de savoir comment déployer les microservices efficacement et une planification rigoureuse pour aboutir.
C'est pourquoi maîtriser les concepts fondamentaux, les étapes et les bonnes pratiques du déploiement de microservices est indispensable à la réussite d'une telle architecture. Voici les étapes clés du déploiement de microservices et ce que chacune implique.
Planification et préparation du déploiement de microservices
Toute réussite demande de la planification et de la rigueur. Déployer des microservices ne fait pas exception : une préparation sérieuse est incontournable. Il est donc essentiel de suivre les bonnes pratiques et de tout préparer en amont avant de déployer vos microservices.
Comme mentionné précédemment, l'un des principes et caractéristiques fondamentaux des microservices est le Principe de responsabilité unique. En restant fidèle à ce principe et en veillant à ce que chaque microservice se concentre sur une seule fonction et en soit responsable, vous permettez à votre équipe de développer, déployer et faire évoluer les services de manière indépendante.
Ce principe recouvre également une notion connexe : le principe de couplage faible. Cela signifie que chaque service peut fonctionner et communiquer de façon autonome, avec une dépendance minimale envers les autres services. Ainsi, toute modification d'un service n'affecte pas les autres, ce qui permet une mise à l'échelle indépendante des microservices.
Cela réduit le risque de défaillances en cascade, où un problème dans une partie du système déclenche une réaction en chaîne, provoquant des pannes successives et mettant hors service l'ensemble de l'application.
Une bonne pratique importante consiste à attribuer un stockage de données dédié à chaque service lors du déploiement des microservices, dans le prolongement du principe de couplage faible. Cela évite les conflits et facilite la mise à l'échelle de chaque service.
Par ailleurs, des patterns de communication asynchrone entre microservices, comme les gestionnaires de messages, sont nécessaires pour que chaque service puisse communiquer sans dépendances directes.
Le dernier élément essentiel est la mise en place de pipelines d'intégration continue et de livraison continue (CI/CD) pour les microservices. Ces pipelines permettent aux équipes de déployer de nouvelles fonctionnalités ou des correctifs via des outils CI/CD comme Jenkins et GitLab, afin que les équipes puissent maintenir la stabilité du système tout en livrant régulièrement de nouvelles fonctionnalités.
Maintenant que vous avez une vue d'ensemble de la planification et de la préparation nécessaires au déploiement de microservices, parlons des stratégies de déploiement.
Stratégies de déploiement de microservices
Lorsque vous déployez des microservices, le choix d'une stratégie de déploiement dépend de la fonction du service, du trafic, de la configuration de l'infrastructure, de l'expertise de l'équipe et des contraintes budgétaires. En règle générale, les stratégies de déploiement de microservices sont les suivantes :
- Une instance de service par conteneur : Dans cette approche, chaque microservice s'exécute dans son propre conteneur, offrant une meilleure isolation que le modèle avec plusieurs instances par hôte. Les conteneurs facilitent la mise à l'échelle et améliorent l'allocation des ressources.
- Une instance de service par machine virtuelle : Chaque service s'exécute dans une machine virtuelle (VM) distincte, ce qui offre une isolation encore plus grande que les conteneurs. Cela améliore la sécurité et la stabilité, mais engendre généralement une charge supplémentaire plus importante.
- Déploiements progressifs : Commencez par déployer les nouvelles versions de microservices auprès d'un petit groupe d'utilisateurs afin de tester leur stabilité avant un déploiement complet. Cette approche limite l'impact en cas de problème et permet des retours en arrière rapides pour préserver l'intégrité du système.
- Déploiement Blue-Green : Cette méthode repose sur deux environnements de production identiques : l'un sert le trafic en production pendant que l'autre est utilisé pour tester la prochaine version. Le déploiement blue-green facilite les retours en arrière et les mises à jour sans interruption de service, le trafic pouvant être basculé instantanément d'un environnement à l'autre.
- Déploiements par étapes : Cette stratégie consiste à déployer les mises à jour progressivement auprès de différents segments d'utilisateurs ou environnements. Elle commence généralement par les environnements internes avant d'atteindre la production, ce qui limite la portée des problèmes potentiels et permet aux équipes de les traiter étape par étape.
- Déploiement serverless : Cette approche s'appuie sur des plateformes serverless comme AWS Fargate et Google Cloud Run, qui automatisent la gestion de l'infrastructure en prenant en charge la mise à l'échelle et l'allocation des ressources à votre place. Avec le déploiement serverless, inutile de gérer les serveurs sous-jacents : vous pouvez vous concentrer directement sur vos microservices.
Une fois que vous avez choisi l'une des stratégies de déploiement ci-dessus, vous aurez besoin d'un outil d'orchestration de microservices.
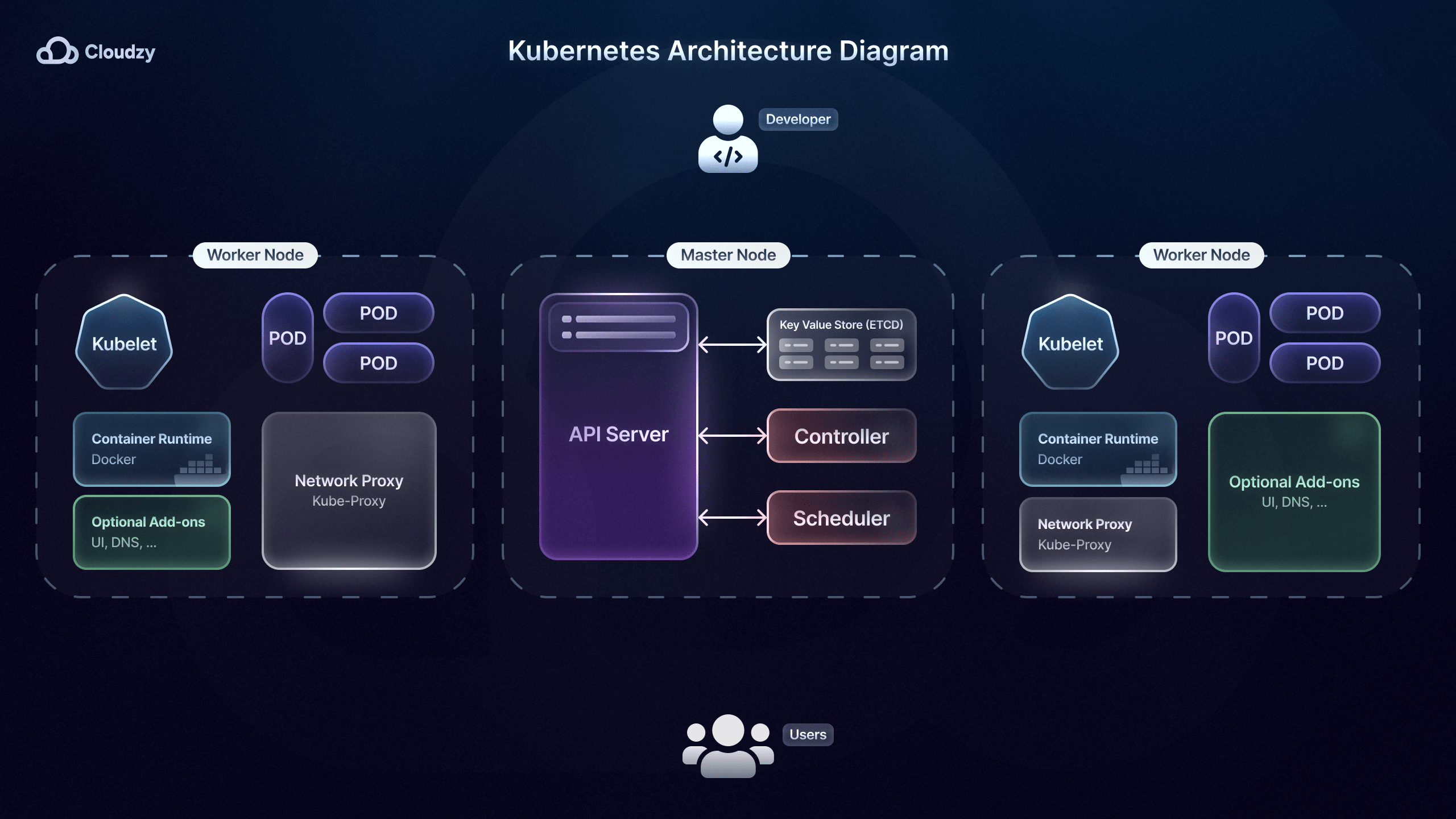
Orchestration de microservices
Après avoir choisi l'une des nombreuses stratégies de déploiement de microservices, vous aurez besoin d'un chef d'orchestre pour l'orchestration des microservices. Les outils d'orchestration de microservices, tels que Kubernetes, permettent d'automatiser le déploiement, la mise à l'échelle, la supervision et la gestion des microservices conteneurisés.
Airbnb, par exemple, utilise Kubernetes, ce qui permet à ses ingénieurs de déployer des centaines de modifications sur leurs microservices sans supervision manuelle. L'une des fonctionnalités importantes des outils d'orchestration comme Kubernetes est l'équilibrage de charge intégré.
Un équilibrage de charge efficace permet de répartir le trafic entrant sur plusieurs instances d'un microservice. Cela évite qu'une instance unique ne devienne un goulot d'étranglement et améliore la capacité du système à absorber les pics de charge.
Kubernetes joue un rôle clé dans la gestion des microservices grâce à ses capacités d'auto-réparation : les conteneurs défaillants sont automatiquement remplacés et redémarrés. Le New York Times utilise cette fonctionnalité pour maintenir ses microservices opérationnels sans impact sur l'expérience utilisateur ni interruption de service.
De plus, Kubernetes renforce la sécurité des microservices en gérant les configurations et les secrets, comme les identifiants de base de données ou les clés API, via les ConfigMaps et les Secrets. C'est particulièrement important pour des entreprises et services comme Uber, qui traitent des données sensibles sur leurs clients et utilisateurs.
Enfin, les outils d'orchestration de microservices comme Kubernetes sont particulièrement adaptés aux stratégies impliquant des mises à jour progressives et des retours en arrière, comme les déploiements par étapes. Les mises à jour progressives permettent de déployer de nouvelles versions de microservices sans interruption de service, en maintenant certaines instances de l'ancienne version en fonctionnement.
Une fois votre outil d'orchestration de microservices en place, vous devrez construire et automatiser vos pipelines CI/CD pour le déploiement de microservices.
Pipelines CI/CD pour le déploiement de microservices
Comme mentionné précédemment, les pipelines d'intégration continue et de livraison continue (CI/CD) occupent une place centrale dans le déploiement de microservices. La partie CD de ces pipelines se charge de déployer automatiquement les modifications de code en production dès qu'elles franchissent les étapes de test et d'intégration.
La partie CD entre alors en jeu : dès qu'une modification de code passe les étapes de test et d'intégration, le service est déployé vers un outil d'orchestration de microservices tel qu'un cluster Kubernetes.
Par ailleurs, les étapes de test et d'intégration sont entièrement automatisées par les pipelines CI/CD, qui intègrent des tests unitaires, des tests d'intégration et des tests de bout en bout.
Cela permet aux équipes de valider les mises à jour à chaque étape tout en préservant la stabilité du système. De plus, si des problèmes surviennent malgré les différents tests, des rollbacks automatiques peuvent rétablir la dernière version stable.
Enfin, mettre en place des pipelines CI/CD pour les microservices en suivant les bonnes pratiques permet aux équipes de livrer plus vite, de réduire les erreurs manuelles et de maintenir un niveau de qualité élevé.
De nombreuses entreprises comme Spotify, Expedia, iRobot, Lufthansa ou Pandora utilisent des pipelines CI/CD pour leurs microservices via des outils comme CircleCI, AWS CodePipeline et GitLab, afin d'automatiser les déploiements, garantir une qualité de code constante et livrer rapidement de nouvelles fonctionnalités tout en maintenant la stabilité du système.
Modèles de communication entre microservices
La façon dont les microservices communiquent entre eux dépend entièrement de leur fonction, de l'architecture globale, du niveau de performance souhaité et de la fiabilité attendue. En règle générale, on distingue deux grands types de modèles de communication : synchrone et asynchrone modèles de communication entre microservices.
Dans les modèles de communication synchrone, les services interagissent en temps réel : un service envoie une requête et attend la réponse avant de continuer. Les modèles de communication synchrone les plus utilisés sont : REST (Transfert d'État Représentationnel) API, gRPC (Appel de procédure distante de Google), et GraphQL.
Ce type de communication est généralement adopté par des secteurs et des entreprises qui ont besoin de traitement de données en temps réel et de réponses immédiates. La finance, la santé et le commerce en ligne ont souvent recours à la communication synchrone pour garantir que les transactions, les accès aux données et les interactions se produisent instantanément, offrant ainsi une expérience utilisateur fluide et réactive.
Cela dit, si la communication synchrone présente des avantages comme la réponse en temps réel et la simplicité, elle comporte aussi des inconvénients : risques de goulets d'étranglement liés à un couplage fort, faible montée en charge, temps de réponse dégradés et latence élevée en cas de fort trafic.
À l'inverse, les modèles de communication asynchrone sont généralement mieux adaptés aux microservices, car ils reposent sur le principe de couplage faible évoqué précédemment.
Ce type de communication découple les services en leur permettant d'échanger des messages via un broker comme Kafka ou RabbitMQ. En envoyant des messages dans une file d'attente qui sert de tampon, les services communiquent de façon indépendante sans attendre de réponse, contrairement à la communication synchrone. Ce tampon permet aux autres services de traiter les messages à leur propre rythme, libérant ainsi l'émetteur pour qu'il puisse poursuivre son travail sans attendre le destinataire.
La communication asynchrone ne se contente pas d'offrir une architecture découplée pour le déploiement de microservices : elle permet également des réponses en temps réel, au même titre que la communication synchrone.
C'est grâce à l'architecture orientée événements des modèles de communication asynchrones : les services communiquent en émettant des événements lorsqu'une action spécifique se produit. D'autres services peuvent s'abonner à ces événements et réagir en conséquence. Cela permet de construire des systèmes très réactifs, capables de répondre aux changements en temps réel sans couplage direct entre services.
De plus, en mode asynchrone, Publier-S'abonner (Pub/Sub) patterns de communication pour les microservices, les services (publishers) envoient des messages à un topic, et d'autres services (subscribers) écoutent ce topic pour recevoir les mises à jour. Ce modèle prend en charge plusieurs subscribers, diffusant simultanément les messages à de nombreux services.
Enfin, à l'instar des patterns événementiels, les communications asynchrones Saga basée sur la chorégraphie patterns de communication pour les microservices utilisent également des événements pour communiquer entre eux ; dans ce pattern, cependant, un ordre précis est respecté : chaque événement déclenche l'étape suivante et active le service concerné.
La différence avec les patterns événementiels réside dans l'absence de séquence ou de flux de travail défini : plusieurs services peuvent réagir à un même événement, contrairement au processus ordonné propre au pattern choreography-based saga.
Le type de pattern de communication asynchrone à utiliser dépend de la tâche et de la fonction globale de vos microservices. Les files de messages comme RabbitMQ et Amazon SQS sont généralement utilisées pour la planification de tâches, la distribution de charge, et le traitement des commandes et des notifications dans le commerce en ligne.
Les brokers de messages événementiels, tels que Apache Kafka et AWS EventBridge, sont généralement utilisés pour le traitement de flux d'événements à grande échelle en temps réel et le routage d'événements entre microservices, notamment dans les services financiers et les environnements AWS.
Quant aux brokers de messages Publish-Subscribe (Pub/Sub) comme Google Cloud Pub/Sub et Redis Streams, ils sont généralement utilisés pour la messagerie distribuée à grande échelle, l'analyse en temps réel, l'ingestion d'événements, ainsi que les notifications en temps réel et les applications de chat.
Enfin, les brokers de messages choreography-based saga sont principalement utilisés pour le traitement des commandes en e-commerce, les systèmes de réservation de voyages, et tous les cas où des transactions complexes en plusieurs étapes doivent être coordonnées entre plusieurs services sans contrôle centralisé.
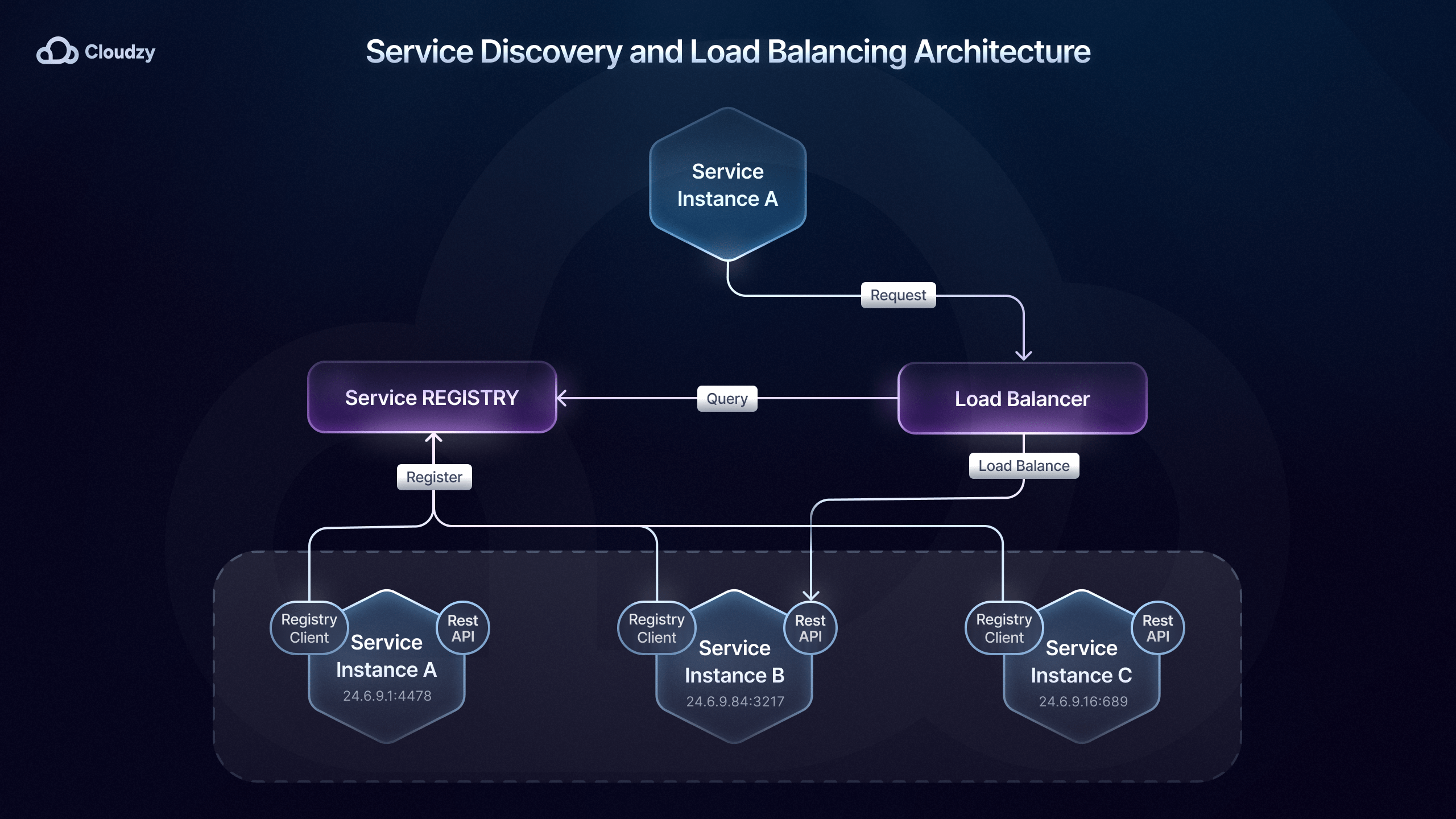
Découverte de services dans une architecture microservices
Une fois que vous avez mis en place un pattern de communication adapté à vos besoins, vous devez vous assurer que vos services peuvent se localiser mutuellement. Comme mentionné plus haut, les outils d'orchestration de microservices tels que Kubernetes jouent un rôle clé dans la découverte de services.
Cela repose sur la découverte de services intégrée que Kubernetes DNS fournit, qui met à jour dynamiquement les adresses IP et les enregistrements DNS à mesure que les services évoluent ou changent d'emplacement au sein du cluster.
Cette méthode de découverte de services est appelée découverte côté serveur, car la responsabilité du routage est déléguée à un équilibreur de charge, qui interroge le registre et dirige le trafic vers l'instance appropriée.
À l'inverse, la découverte côté client est une autre méthode dans laquelle le service ou la passerelle API interroge un registre de services, comme Consul ou Eureka, pour trouver les instances disponibles.
Le choix de la méthode de découverte de services la mieux adaptée à votre déploiement de microservices dépend des exigences et de l'échelle du système.
Avec la découverte de services côté client, le client contrôle entièrement l'instance avec laquelle il communique. Cela offre plus de flexibilité et réduit la complexité, car aucun service de découverte centralisé n'est nécessaire.
Par exemple, le déploiement de microservices de Netflix utilise la découverte côté client avec Eureka et Ribbon pour l'équilibrage de charge, ce qui permet au client de choisir la meilleure instance selon des critères tels que la latence et la charge serveur.
La découverte côté serveur est en revanche plus adaptée aux environnements de grande taille, car un service de découverte centralisé améliore l'efficacité et garantit un équilibrage de charge cohérent au sein d'un système distribué.
Les solutions de découverte de services côté serveur telles que Kubernetes, AWS Elastic Load Balancing et les passerelles API (Kong, NGINX, etc.) permettent de router le trafic efficacement et de maintenir une haute disponibilité. Elles sont utilisées par des entreprises comme Airbnb, Pinterest, Expedia, Lyft, etc.
Sécurité des microservices
Si l'architecture monolithique est globalement moins performante que la MSA, elle avait un avantage en matière de sécurité. Les microservices reposant sur le principe de couplage faible et étant distribués par nature, il n'est pas possible d'appliquer une mesure de sécurité unique et générale.
Chaque service devant être sécurisé indépendamment, des protections supplémentaires sont nécessaires, car la surface d'attaque est bien plus grande dans une architecture microservices. À cette fin, des standards tels que OAuth2 et les JSON Web Tokens (JWT) sont couramment utilisés pour l'authentification et l'autorisation.
Une passerelle API est également souvent utilisée pour gérer la sécurité des microservices : elle applique l'authentification et l'autorisation au point d'entrée. Les passerelles API peuvent aussi mettre en place la limitation de débit, la journalisation et la surveillance, ce qui ajoute des couches de sécurité supplémentaires.
Ces mesures sécurisent le point d'entrée principal, mais des protections supplémentaires sont nécessaires pour couvrir les communications inter-services.
C'est là qu'interviennent les maillages de services : ils ajoutent une couche de sécurité réseau aux microservices, chiffrent le trafic entre les services et appliquent des politiques comme le TLS mutuel. Ces maillages de services mettent en place un chiffrement de bout en bout complet qui améliore considérablement la sécurité des microservices.
Mise à l'échelle des microservices
L'un des principaux avantages de la MSA, et la raison même pour laquelle elle a été développée pour remplacer l'architecture monolithique, est sa haute capacité de mise à l'échelle. En général, la mise à l'échelle des microservices peut se faire de deux façons : verticale et horizontale.
La mise à l'échelle verticale des microservices (scale up) consiste à ajouter des ressources supplémentaires, comme du CPU ou de la mémoire, à une instance existante. La mise à l'échelle horizontale (scale out), quant à elle, distribue la charge et augmente la capacité.
En termes de mise en œuvre, la mise à l'échelle verticale est la plus simple des deux : il suffit de modifier une seule instance en migrant vers un serveur plus puissant, en augmentant la mémoire ou la puissance de traitement dans une instance cloud, ou en ajoutant du stockage.
Ce type de mise à l'échelle est généralement utilisé dans les cas où augmenter la puissance RAM ou CPU peut améliorer les performances des requêtes et le traitement des données, comme pour les services responsables de la mise en cache en mémoire.
Cela dit, si la mise à l'échelle verticale est plus simple et offre un gain de performance immédiat, elle présente aussi des inconvénients. Elle est limitée par la capacité matérielle du serveur : à un moment donné, vous devrez passer à la mise à l'échelle horizontale pour continuer à progresser.
De plus, la mise à l'échelle verticale coûte cher, car le matériel et les instances plus grandes ont généralement un prix élevé. Enfin, si l'instance mise à l'échelle tombe en panne, le service est entièrement indisponible, faute d'instances supplémentaires pour absorber la charge.
Pour la mise à l'échelle horizontale des microservices, plutôt que d'augmenter les ressources d'une seule instance, vous déployez de nouvelles instances de ce service. Bien que ces instances fonctionnent de manière indépendante, elles gèrent toutes le même service et une partie de la même charge de travail.
Contrairement à la mise à l'échelle verticale, la mise à l'échelle horizontale des microservices est sans limite : vous pouvez ajouter autant d'instances que nécessaire pour absorber les pics de trafic et les charges croissantes, offrant ainsi une plus grande capacité de mise à l'échelle.
De plus, avec plusieurs instances en place, si l'une tombe en panne, les autres continuent de traiter les requêtes - vous ne mettez pas tous vos œufs dans le même panier. Enfin, la mise à l'échelle horizontale est bien plus rentable sur le long terme, car plusieurs instances plus petites et moins coûteuses peuvent offrir ensemble des performances plus fiables et plus puissantes.
Cela dit, la mise à l'échelle horizontale et l'ajout de nouvelles instances nécessitent davantage d'équilibreurs de charge, de mécanismes de découverte de services et d'outils d'orchestration de microservices, ce qui rend l'architecture microservices nettement plus complexe.
La mise à l'échelle horizontale convient mieux aux cas d'usage tels que les services web et les applications comme les plateformes e-commerce ou les réseaux sociaux, qui connaissent souvent des pics de trafic importants et un volume élevé de requêtes.
Cela dit, il ne s'agit pas vraiment de choisir l'un ou l'autre : les deux types de mise à l'échelle sont pris en charge dans les microservices et sont nécessaires dans de nombreux cas. En général, les petites organisations optent pour la mise à l'échelle verticale, plus simple à mettre en place et à gérer, puis introduisent la mise à l'échelle horizontale au fil du temps, à mesure que l'application prend de l'ampleur.
Enfin, les plateformes cloud proposent des services d'auto-scaling qui ajoutent ou suppriment automatiquement des instances en fonction de la demande en temps réel, ce qui aide considérablement les organisations à trouver le bon équilibre entre mise à l'échelle verticale et horizontale.
Surveillance des microservices
À ce stade, votre déploiement de microservices est pratiquement terminé. Il ne reste plus qu'à s'assurer qu'il fonctionne de manière cohérente et fiable. C'est là qu'entrent en jeu les outils de surveillance des microservices comme Prometheus et Grafana .
Ces outils fournissent des informations en temps réel sur les métriques des services, permettant aux équipes de suivre l'utilisation des ressources, la latence et les taux d'erreur. Ils proposent également le traçage distribué (Jaeger, Zipkin, etc.), qui aide à visualiser les flux de requêtes entre les services et peut être extrêmement utile pour diagnostiquer les problèmes.
Enfin, comme les pannes peuvent se propager d'un service à l'autre en raison de la nature distribuée des microservices, l'agrégation des journaux est une pratique essentielle dans la surveillance des microservices. En centralisant les journaux sur une plateforme unique et en configurant des alertes en temps réel, vous gardez toujours une longueur d'avance sur les problèmes et pouvez y répondre de manière proactive avant qu'ils n'affectent les utilisateurs.
Pour conclure
L'univers des microservices est certes complexe à appréhender, mais comprendre les fondamentaux et les grandes étapes du déploiement rend l'ensemble du processus bien plus accessible. De plus, au fil du temps, de nouveaux outils aux fonctionnalités toujours plus nombreuses sont disponibles, ce qui simplifie le déploiement des microservices comme jamais auparavant.
Questions fréquemment posées
Quelles stratégies de déploiement sont couramment utilisées pour les microservices ?
Il existe de nombreuses stratégies de déploiement pour les microservices, mais les plus courantes sont : les instances de service par conteneur, les déploiements progressifs, le déploiement blue-green et le déploiement serverless. Chacune offre des niveaux différents d'isolation, de flexibilité et de capacité de mise à l'échelle.
Quel rôle joue Kubernetes dans l'orchestration des microservices ?
Les microservices reposent sur des outils d'orchestration de conteneurs comme Kubernetes pour automatiser le déploiement, la mise à l'échelle et la gestion des services conteneurisés. Ces outils assurent l'équilibrage de charge, la mise à l'échelle automatique et l'auto-correction afin de garantir des microservices fiables et performants.
Comment garantir la sécurité dans un environnement de microservices ?
De par leur nature distribuée, les microservices posent des défis de sécurité plus complexes que l'architecture monolithique. Sécuriser des microservices implique d'authentifier et d'autoriser les requêtes, de chiffrer les communications entre services, et de déployer des passerelles API ainsi que des maillages de services comme Istio pour centraliser la gestion de la sécurité.


