Il software di monitoraggio GPU è quello che trasforma "il mio GPU non funziona bene" in una spiegazione diretta e chiara, tipo "hotspot alle stelle, clock in calo, VRAM pieno".
In questa guida ti mostro gli strumenti che puoi usare per lavori AI, overlay per il gaming e sessioni di lavoro prolungate, e ti spiego le metriche GPU che ti aiutano a diagnosticare rallentamenti, stuttering e crash.
Alla fine avrai una configurazione di software di monitoraggio GPU che si adatta al tuo modo di lavorare. Avrai anche stack pronti da copiare per quattro casi d'uso comuni, così non dovrai cercarne altri su internet.
Risposta veloce: i migliori software di monitoraggio GPU per caso d'uso
Se vuoi solo una lista breve che corrisponda a come la gente lavora davvero, inizia da questi. In pratica, lo stack migliore di software di monitoraggio GPU è di solito una combinazione: uno strumento per i controlli rapidi, uno per overlay o log, e uno per la cronologia o gli avvisi.
Ecco la mappa veloce:
| ", così puoi gestire stack Docker Compose con pieno controllo su servizi, volumi, domini e aggiornamenti." | Stack iniziale consigliato | Cosa ottieni |
| Lavori AI, inferenza, HPC | nvidia-smi (NVIDIA) o AMD SMI (AMD) + logging/exporter | Controlli rapidi, log scripabili, avvisi facili |
| Gaming su Windows | MSI Afterburner + RTSS + uno strumento di cattura dei tempi di frame | Overlay più prova dello stuttering rispetto a bassi FPS |
| Gioco su Linux | MangoHud + uno strumento da terminale (nvtop) | Overlay leggero più controlli per singolo processo |
| Workstation (3D/video/CAD) | HWiNFO logging + un semplice test di stress | Log lunghi che puoi condividere, riproduzione ripetibile |
| Macchine GPU condivise | nvtop (Linux) + esportatore/pannello di controllo | Visibilità VRAM per singolo processo |
Da qui, il lavoro principale è adattare il software di monitoraggio GPU al modo in cui consumi i dati: su schermo, in un log, o in una dashboard.
A chi è rivolta questa guida
Scrivo questo come chi ha dovuto debuggare macchine reali. Perché, dall'esperienza, so che lettori diversi hanno bisogno di strumenti GPU diversi, anche se guardano lo stesso GPU.
Ecco i quattro profili che ho in mente:
- Chi costruisce modelli (AI/ML): si preoccupa di headroom VRAM, clock sostenuti, throttling, e "il job è girato tutta la notte senza crashare?".
- Chi gioca o fa streaming competitivo: si preoccupa di frametimes, stabilità degli overlay, e di beccaregressioni dopo gli aggiornamenti dei driver.
- Chi lavora con stazioni di lavoro (3D/video/CAD): si preoccupa di log, crash riproducibili, e di individuare se è calore, potenza o il driver a causare il problema.
- Chi amministra macchine con GPU: si preoccupa di alert, grafici di trend, capacity planning, e di individuare guasti prima che diventino critici.
Una volta che sai in quale categoria rientri, puoi facilmente scegliere il software di monitoraggio GPU che fa per te.
Come scegliere il software di monitoraggio GPU
Molte app di performance monitoring si somigliano finché non le usi per una settimana. La vera differenza è di solito in output e affidabilità, non in quelle "feature" appariscenti che ognuna pubblicizza disperatamente.
Ti pongo tre domande per aiutarti a scegliere il software di monitoraggio GPU rapidamente:
- Ti serve un overlay, un log, o entrambi?
I gamer vogliono un overlay. Il lavoro con AI e workstation di solito richiede log. Gli admin vogliono log più alert. - Ti serve visibilità per singolo processo?
Se condividi una macchina (lab, studio, server remoto), la visibilità per processo su VRAM è spesso la prima cosa che cerchi. - Ti serve storico e alert?
Se i job girano di notte, "controllo dopo" non basta. Ti serve un grafico e un alert.
Per mantenere questo pratico, il resto dell'articolo è organizzato per metriche GPU prima, poi per tool stack che si adattano a ogni caso d'uso.
Metriche GPU da dare la priorità
Ogni software di monitoraggio GPU ti dà un sacco di numeri. Un software di monitoraggio GPU veramente utile ti dà quel pugno di metriche che spiega il comportamento. Organizzo le metriche GPU per la decisione che aiutano a prendere.
Termiche e metriche di throttling
Queste sono le metriche GPU che spiegano "era veloce per 10 minuti, poi non lo era più":
- temperatura GPU
- Temperatura hotspot (spesso la prima cosa a salire)
- Temperatura memoria/giunzione (più rilevante su lunghe esecuzioni AI e rendering prolungati)
- Velocità ventola (aiuta a individuare profili laptop o curve ventola scadenti)
Se stai cercando di migliorare la stabilità, registra questi valori: singole istantanee raramente forniscono informazioni sufficienti.
Potenza, clock e limiti
Queste metriche GPU spiegano il downclocking e le prestazioni incoerenti:
- Consumo energetico della scheda
- Clock del core e clock della memoria
- Limite potenza/stato prestazioni (se il tuo strumento lo espone)
In molti debug nel mondo reale, potenza e clock offrono un quadro molto più chiaro del semplice "utilizzo GPU %".
VRAM e pressione memoria
Queste metriche GPU spiegano stuttering, errori OOM e i tipici rallentamenti "casuali":
- VRAM utilizzata vs totale
- Attività del controllore memoria (aiuta a individuare limiti di larghezza di banda)
- Pressione RAM del sistema (perché lo spill VRAM può trascinare giù anche il sistema)
Per l'AI, VRAM è spesso il limite invalicabile. Per i giochi, la pressione VRAM si manifesta prima come picchi di frametime.
Metriche di frametime e frame pacing
Per gaming e streaming, gli FPS da soli possono essere fuorvianti. Il frametime è la metrica su cui concentrarsi, poiché traccia la fluidità o la mancanza di essa:
- Tempo del fotogramma (ms)
- 1% basso / 0.1% basso (utile per i confronti)
- GPU occupato vs CPU occupato (aiuta a separare i colli di bottiglia di GPU da quelli di CPU)
È per questo che le app di monitoraggio delle prestazioni orientate al gaming spesso includono un percorso di acquisizione del frametime. Con le nozioni di base sulle metriche, possiamo parlare dei migliori stack di software di monitoraggio GPU per ogni flusso di lavoro.
Software di monitoraggio GPU per AI, addestramento e server

Il monitoraggio dell'AI ha una configurazione semplice con controlli rapidi in un terminale, più log e avvisi per le esecuzioni lunghe. Per questo, il software di monitoraggio GPU che parla CLI ed esporta metriche è quello che serve.
NVIDIA: nvidia-smi per controlli rapidi e log scriptabili
Su sistemi NVIDIA, nvidia-smi è di solito il primo comando che le persone eseguono perché viene fornito con il driver ed è progettato per il monitoraggio e la gestione tramite NVML.
La documentazione ufficiale è qui: Interfaccia di gestione del sistema NVIDIA (nvidia-smi).
Se vuoi un approccio semplice "registra e controlla dopo" (e sorprenderti di quanto spesso risolve il problema), questo pattern è affidabile:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Questo è il comportamento base del software di monitoraggio GPU con timestamp, metriche core di GPU e un output che funziona bene con gli script.
AMD: AMD SMI per ROCm e nodi HPC
Sui nodi di calcolo AMD Linux, AMD SMI è l'interfaccia moderna di monitoraggio e gestione, e AMD la documenta come un set di strumenti unificato per il monitoraggio e il controllo in contesti HPC.
La documentazione ufficiale è qui: Documentazione di AMD SMI.
Se il tuo ambiente è pesante in AMD, AMD SMI è la base del software di monitoraggio GPU su cui tendono a costruire gli altri strumenti.
Visibilità per processo: nvtop per GPU condivisi
Se hai mai avuto una macchina condivisa dove VRAM rimane "misteriosamente" piena, la visibilità per processo fa risparmiare tempo. Su Linux, nvtop è popolare proprio per questo motivo, poiché rende ovvio "chi sta usando VRAM?". Su AMD/Intel, potresti aver bisogno di un kernel recente per le statistiche per processo.
Nei team misti, spesso vedo persone eseguire nvtop fianco a fianco con nvidia-smi o AMD SMI. È un abbinamento semplice che evita molte supposizioni, quindi lo consiglio vivamente.
Non trascurare la scelta dell'hardware!
Il monitoraggio non risolve un limite VRAM; lo rende solo visibile. Se stai ancora mappando i carichi di lavoro sui tier GPU, la nostra guida su Migliori GPU per il machine learning nel 2025 è una risorsa utile perché inquadra VRAM e la larghezza di banda nello stesso modo in cui le leggerai poi nei log e nelle dashboard.
Una volta che hai il software di monitoraggio GPU in stile server sotto controllo, il passo successivo è overlays e frametimes, perché i carichi di lavoro interattivi si comportano diversamente.
Software di Monitoraggio GPU per Gaming e Streaming

Il gaming è dove le persone hanno le opinioni più forti sugli strumenti GPU, soprattutto perché gli overlay falliscono al momento peggiore. Per il gaming, vuoi overlay semplici e catture frametime ripetibili.
MSI Afterburner + RTSS per Overlay su Windows
Questa combinazione è piuttosto popolare perché puoi costruire un overlay pulito con esattamente le metriche GPU che ti interessano, come utilizzo, clock, VRAM, temperature, frametime e magari velocità della ventola.
Un avvertimento serio che emerge spesso nei thread della community riguarda i siti di download falsi. La pagina Afterburner di MSI stessa sottolinea che i download legittimi dovrebbero provenire da msi.com e i piani Guru3D, ed elenca anche la linea di rilascio corrente (4.6.6 final, rilasciato ottobre 2025).
I problemi di overlay sono un'altra cosa da tenere d'occhio. Ad esempio, RTSS funziona in alcuni giochi e fallisce in altri, specialmente con i percorsi di rendering moderni. Le persone riportano casi in cui l'overlay appare in Vulkan ma non in DX12 per lo stesso titolo, o scompare dopo gli aggiornamenti.
Tuttavia, non è dovuto a un errore da parte tua, è solo quello che succede quando gli overlay si integrano in stack di giochi e driver in continuo cambiamento.
Se vuoi un overlay di base stabile, mantienilo semplice:
- tempo di fotogramma
- Utilizzo GPU
- VRAM utilizzata
- temperatura GPU
Aggiungi power e clock solo se stai attivamente debuggando il throttling.
Cattura Frametime per "Stuttering"
È qui che i software di monitoraggio delle prestazioni che riescono a catturare grafici frametime sono molto utili. Un FPS medio può sembrare ok mentre il frame pacing si sente terribile. I grafici frametime risolvono quella confusione rapidamente.
Molti workflow di benchmark gaming si affidano a PresentMon dietro le quinte, e Documenti NVIDIA che la sua analitca FrameView usa PresentMon per la cattura di frame rate e frame time.
Non hai bisogno di eseguire il benchmark di ogni gioco. La cattura frametime è più utile per i confronti, come prima e dopo un aggiornamento del driver, prima e dopo aver cambiato un limiter, prima e dopo aver scambiato le impostazioni, e così via.
MangoHud per Overlay Linux
Su Linux, MangoHud viene consigliato spesso perché è leggero e si integra perfettamente con le configurazioni Steam/Proton. I reclami più comuni riguardano sensori mancanti o letture strane su configurazioni laptop ibride.
In pratica, puoi facilmente accoppiare MangoHud con un checker da terminale come nvtop. È anche un buon esempio di come il software di monitoraggio GPU funziona significativamente meglio come piccolo stack, invece di un'unica app gigantesca.
Dal gaming, il passo naturale successivo è il monitoraggio della workstation, perché lì i log e la possibilità di riprodurre i problemi sono quello che conta.
Ospita server di gioco senza lag con hosting VPS NVMe ad alta velocità.
VPS per il gaming
GPU Software di Monitoraggio per Workstation e App Professionali
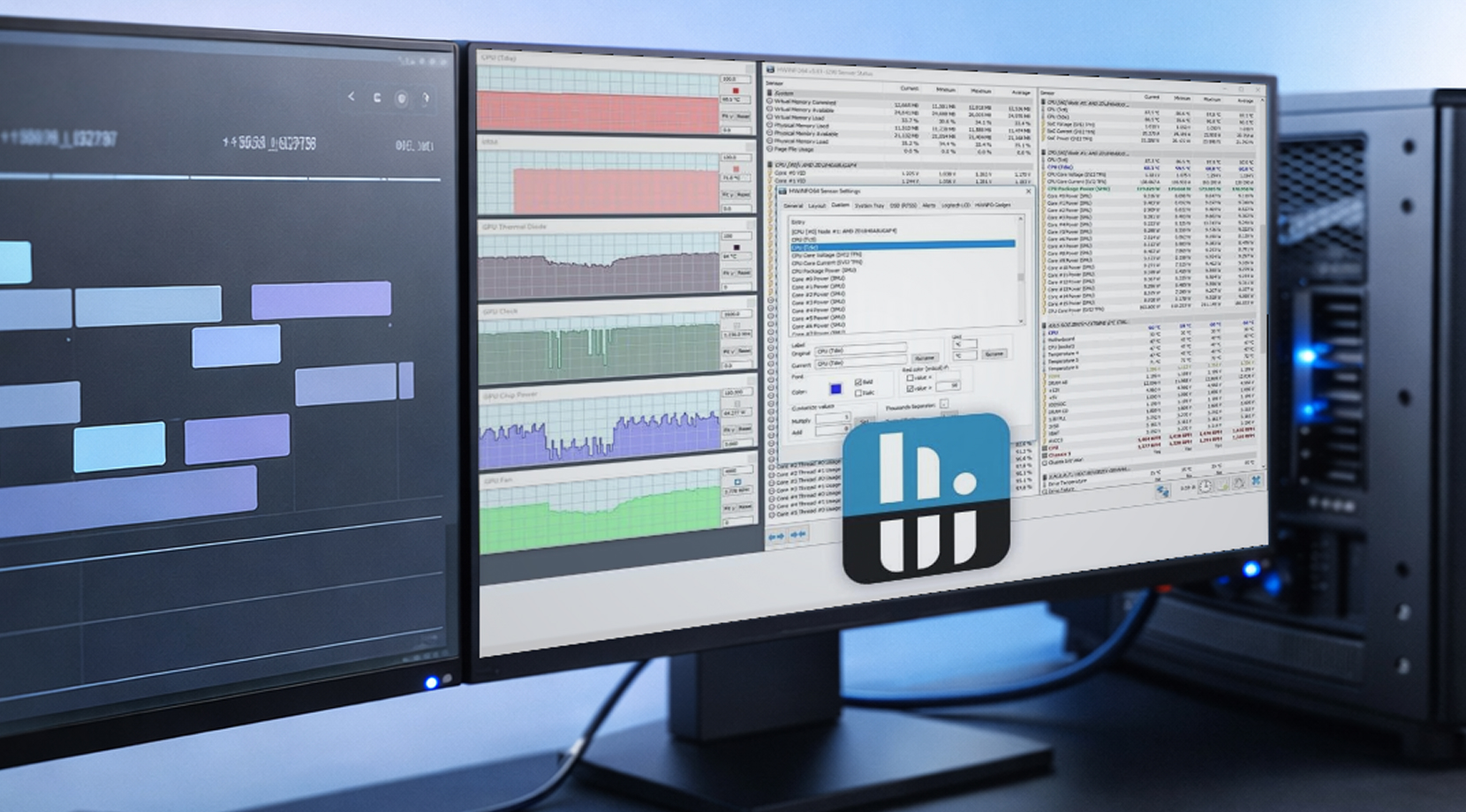
Il monitoraggio della workstation non è tanto un lavoro da responsabile della sicurezza che guarda un overlay live, quanto piuttosto rispondere a: "Cosa è successo nel tempo, e posso riprodurlo?"
HWiNFO per il Logging su Windows
HWiNFO è popolare negli ambienti delle workstation perché ha una copertura sensoriale profonda e logging facile da condividere. Un semplice log CSV con timestamp può trasformare un rapporto vago in qualcosa che puoi usare attivamente per risolvere i problemi.
Se stai creando un log della workstation per la stabilità di GPU, inizia con queste metriche GPU:
- Temperatura e hotspot di GPU
- VRAM utilizzata
- alimentazione scheda
- frequenza base
- Potenza del pacchetto CPU (perché i limiti di potenza della piattaforma possono creare problemi)
Questo è il set "abbastanza dati per spiegarlo". Perché loggare ogni sensore rende solo il file più difficile da leggere.
GPU-Z per Controlli Veloci "Quale GPU è Questo?"
GPU-Z è ancora utile perché è veloce e mirato. Su team con hardware misto, è il modo più rapido per confermare il modello GPU, le basi del driver e i sensori live senza scavare nei menu.
Stress Test: Utili Solo con il Logging
I test di stress possono aiutare a riprodurre un crash, ma solo se il tuo software di monitoraggio GPU sta loggando mentre li esegui. Senza quei log, rimani con "si è bloccato di nuovo" e praticamente nessuna cronologia.
A questo punto, la maggior parte delle persone si scontra con gli stessi problemi: overlay non visibili, letture di potenza che sembrano sbagliate, log che diventano illeggibili. Affrontiamoli direttamente.
Problemi comuni con il software di monitoraggio GPU e soluzioni rapide

La maggior parte dei problemi rientra in pochi schemi. Queste sono le soluzioni che provo per prime perché risolvono le cose scontate velocemente.
Overlay Mancante in un Gioco
Se un overlay scompare in un titolo moderno, spesso è un problema di hook per gioco specifico o un conflitto con livelli anti-cheat o anti-tamper.
Quello che puoi fare che spesso aiuta:
- Aggiorna RTSS e ripristina il profilo per gioco
- Imposta un "livello di rilevamento dell'applicazione" più alto per il profilo del gioco
- Prova un API diverso se il gioco lo supporta
- Ricadi su overlay integrati quando un titolo blocca gli overlay di terze parti
Non tutti i giochi coopereranno, e non vale la pena perdere ore per un titolo testardo.
Letture Energetiche Anomale (0W, Linee Piatte, Sensori Mancanti)
Capita spesso su laptop e configurazioni ibride dove il GPU attivo può cambiare. In questi casi, verificare con uno strumento secondario, come nvidia-smi (NVIDIA) o AMD SMI (AMD), perché sono ottimi per controllare se il GPU è davvero attivo.
Log Troppo Rumorosi
Il sovracampionamento è il motivo solito. Per la maggior parte delle verifiche, 1-5 secondi basta. Per lavori AI lunghi, 5 secondi vanno benissimo. Intervalli più brevi gonfiano la dimensione dei file e rendono i grafici più difficili da leggere.
Una volta risolti questi aspetti base, il monitoraggio remoto diventa il passo logico successivo, perché molti flussi GPU ora girano su macchine esterne.
Monitoraggio GPU Remoto e un'Opzione Cloud Pratica
Il lavoro remoto cambia cosa significa "buon software di monitoraggio GPU". Non stai sempre davanti alla macchina, quindi hai bisogno di verifiche veloci e di una cronologia da consultare dopo.
Una configurazione remota pulita di solito è così:
- Controlli CLI (nvidia-smi o AMD SMI)
- un file di log che puoi recuperare dopo
- un esportatore/dashboard se hai bisogno di avvisi
Se il hardware locale ti sta bloccando (limiti VRAM, condivisione di un singolo GPU, ambienti isolati per progetto), eseguire i carichi di lavoro su un GPU VPS può essere il modo più semplice per andare avanti.
Cloudzy GPU VPS

Se vuoi tempo GPU remoto adatto a flussi AI, gaming e rendering, il nostro Cloudzy GPU VPS include opzioni NVIDIA come RTX 5090, A100 e RTX 4090, più storage NVMe, accesso root completo, connessioni fino a 40 Gbps, protezione DDoS e un obiettivo di uptime del 99,95%.
Da un punto di vista di monitoraggio, si comporta come una macchina normale perché puoi eseguire software di monitoraggio GPU su SSH, registrare metriche GPU per lavori lunghi e aggiungere dashboard se vuoi cronologia e avvisi.
Se stai ancora decidendo tra un'istanza GPU e una configurazione CPU-only, i nostri articoli su Cos'è un GPU VPS? e i piani GPU contro CPU VPS spiegano le differenze pratiche per tipo di carico di lavoro.
Con il monitoraggio remoto affrontato, l'ultimo passo è mettere tutto insieme in stack copiabili.
Stack Copiabili per Ogni Profilo
Ecco stack facili da seguire che puoi usare senza riscrivere tutto il tuo flusso di lavoro. Sono ottimi punti di partenza per le tue configurazioni, che puoi poi personalizzare in base alle tue esigenze specifiche.
- Generatore di modelli (AI/ML): Software di monitoraggio GPU tramite nvidia-smi o AMD SMI, più un semplice log CSV, più un esportatore/dashboard se i lavori girano senza sorveglianza.
- Gamer/Streamer Competitivo: Overlay software di monitoraggio GPU tramite Afterburner + RTSS, più uno strumento di acquisizione frametime per confronti, più una serie minima di metriche a schermo.
- Utente Workstation Software di monitoraggio GPU tramite logging HWiNFO, più GPU-Z per controlli rapidi di identità, più un test di stress solo quando riesci a registrare l'esecuzione.
- Macchine GPU in esecuzione amministrativa: Software di monitoraggio GPU come servizio: esportatore + dashboard + avvisi, più visibilità per processo (nvtop) per macchine condivise.
Se vuoi ricordare una cosa da questa guida, sia questa: scegli il software di monitoraggio GPU in base a dove devi avere i dati (overlay, log, dashboard), poi mantieni l'insieme di metriche abbastanza piccolo da usarlo davvero.