
Je opent de GGUF-pagina van een populair model op Hugging Face en er staren vijftien bestanden je aan: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus aparte mappen voor GPTQ, AWQ en EXL2 bij een half dozijn bitinstellingen. Je maakt een snelle berekening voor het "4-bit"-bestand: 4 bits × 8 miljard parameters ÷ 8 = 4 GB. Maar het bestand zegt 4,6 GB. En zodra je het laadt, gebruikt het model meer geheugen dan dat.
De bestandsnamen zijn geen ruis. Ze coderen echte, leerbare informatie over bitbreedte, de runtime die ze laadt, en de hardware die ze nodig hebben. De sizingtabellen die je hebt gelezen vertellen je dat een 70B-model ruwweg 40 GB nodig heeft, nuttig, maar ze decoderen nooit het formaat zelf of leggen uit waarom het draaiende model meer geheugen wil dan het bestand op schijf.
Dus hier is het plan: de GGUF-naamgevingsconventie decoderen (met de werkelijke bitbreedtes, niet de nominale), uitzoeken welke van de vier formaten je hardware daadwerkelijk kan draaien, en rekening houden met de ene geheugenkost die in elke bestandsgrootte onzichtbaar is, de KV-cache. Aan het eind kun je een modelrepo lezen en voorspellen hoe het zich zal gedragen bij het laden.
TL;DR
- GGUF-kwantisatieniveaus zijn effectieve bitbreedtes, niet het exacte getal in de naam. Q4_K_M is ongeveer 4,89 bits per gewicht, wat verklaart waarom een "4-bit" 8B-bestand rond 4,6 GiB uitkomt in plaats van de naïeve 4-bit schatting.
- GGUF is de meest overdraagbare optie omdat llama.cpp het op CPU, GPU of een hybride opstelling kan draaien. GPTQ, AWQ en EXL2 zijn meer GPU- en runtime-specifiek, waarbij EXL2 vooral gebonden is aan NVIDIA/CUDA-workflows.
- De KV-cache is gescheiden van de modelgewichten en groeit met de contextlengte. Dit is de reden waarom een model dat netjes laadt, alsnog kan crashen door geheugentekort zodra het gesprek lang wordt.
- Boven het 5-bit bereik is het kwaliteitsverlies meestal klein. Rond Q4 is de afweging nog steeds praktisch voor veel lokale toepassingen. Onder 4-bit wordt de kwaliteitskost veel merkbaarder. Q4_K_M blijft een veelgebruikte standaard in de community, terwijl Q5_K_M en Q6_K veiliger zijn als je geheugen over hebt.
Wat betekent Q4_K_M in een GGUF-bestandsnaam?

Een GGUF-kwantisatienaam volgt het patroon Q[bits]_[K]_[S/M/L]. Het getal is de beoogde bits per gewicht, K betekent dat het een "K-quant" is die schaalfactoren per klein blok gewichten opslaat, en de afsluitende S, M of L is de grootte-/kwaliteitsklasse (klein, middel, groot). Omdat K-quants een schaal- en minimumwaarde per blok opslaan naast de gewichten, is de effectieve bitbreedte hoger dan het genoemde getal. Q4_K_M komt uit op ongeveer 4,89 bits per gewicht, niet 4.
Dat verschil is het volledige antwoord op de vraag "waarom is mijn 4-bit bestand 4,6 GB?" De naïeve schatting gaat ervan uit dat elk gewicht precies 4 bits kost. In werkelijkheid besteden K-quants extra bits per blok aan de metadata die lage-bit kwantisatie accuraat maakt, de schaal en het minimum per blok waarmee de runtime elk gewicht kan reconstrueren. Vermenigvuldig 4,89 bits met 8 miljard gewichten en je komt uit op bijna 4,58 GiB, wat het bestand daadwerkelijk weegt.
Hier zijn de gemeten effectieve bitbreedtes en bestandsgroottes, afkomstig uit de llama.cpp quantize documentation voor Llama 3.1 8B als referentiemodel, samen met de perplexiteitskost van elk niveau gemeten in het llama.cpp-kwantisatie-evaluatiepaper (arXiv:2601.14277) op Llama-3.1-8B-Instruct:
| GGUF-niveau | Effectieve BPW | ~Bestandsgrootte (8B) | Perplexiteit vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | basislijn |
*De perplexiteitscijfers zijn specifiek voor Llama-3.1-8B-Instruct uit arXiv:2601.14277. De BPW/bestandsgrootte-kolom en de perplexiteitskolom komen uit twee verschillende, apart gemeten bronnen, dus lees de tabel als een praktisch naast-elkaar-referentie in plaats van één enkele benchmarkrun. Taakspecifieke achteruitgang varieert, wiskundig redeneren heeft doorgaans meer last van lage bitbreedtes dan gezond-verstandredeneren, maar de brede lijn blijft staan: 5-bit en hoger is meestal veiliger, Q4 is de praktische compressiezone, en 3-bit is waar kwaliteitsverlies veel moeilijker te negeren wordt.
Praktisch gezien: Q4_K_M is de standaard waar de meeste mensen naar zouden moeten grijpen, Q5_K_M en Q6_K zijn de kwaliteitsgerichte keuzes als je geheugen over hebt, en alles op of onder Q3_K_S is een laatste redmiddel voor hardware die echt niet meer kan bevatten.
Welk kwantisatieformaat moet je downloaden: GGUF, GPTQ, AWQ of EXL2?

GGUF is de meest overdraagbare van de vier: het draait via llama.cpp op CPU, GPU, of een hybride van beide, dus het is de veiligste keuze als je niet zeker weet wat je hardware aankan. GPTQ, AWQ en EXL2 zijn meer GPU- en runtime-specifiek. In de praktijk komen ze het meest voor bij NVIDIA/CUDA-opstellingen, maar GPTQ- en AWQ-ondersteuning kan verschillen per loader en serving-stack; vLLM bijvoorbeeld, verdeelt de kwantisatieondersteuning per hardware en implementatie. Als je lokaal draait op een Mac, een AMD-kaart of een CPU-only doos, is GGUF nog steeds het veiligste antwoord. Als je een NVIDIA-GPU hebt en de snelst mogelijke tokens wilt, komen de andere drie in beeld.
| Formaat | Hardware/runtime | Snelheid (relatief) | VRAM vs vergelijkbare formaten | Beste voor |
|---|---|---|---|---|
| GGUF Q4_K_M | Breedst, CPU, GPU of hybride via llama.cpp | Gemiddeld | Laagste | Elke hardware; lokale standaard |
| GPTQ 4-bit | Meestal CUDA/GPU-eerst; afhankelijk van runtime | Snel (ExLlama) | Gemiddeld | GPU-eerst, verouderde tooling |
| AWQ 4-bit | Meestal CUDA/GPU-eerst; afhankelijk van runtime | Snel | Hoogste | vLLM/TGI serving, snel laden |
| EXL2 ~4,9 bpw | NVIDIA/CUDA-eerst | Snelste | Laag-Gemiddeld | Maximale snelheid op NVIDIA |
Een kanttekening bij die tabel: de snelheids- en VRAM-rangschikkingen komen uit de oobabooga-benchmark, die op hardware uit 2023/2024 draaide. Behandel de relatieve rangschikking als blijvend. EXL2 is gebouwd voor snelheid, AWQ ruilt VRAM in voor snel laden, GGUF blijft licht en overdraagbaar, maar lees de oorspronkelijke absolute tokens-per-seconde-cijfers niet als actueel. Een GPU uit 2026 zal een heel andere ruwe doorvoer laten zien; de onderlinge volgorde is wat blijft gelden.
Dus de beslisregel die hieruit voortvloeit: heb je een NVIDIA-kaart en gaat het je vooral om snelheid, dan EXL2; wil je de veiligste lokale standaard over verschillende hardware heen, dan GGUF. AWQ en GPTQ zijn vooral relevant wanneer een specifieke serving-stack (vLLM, TGI) of bestaande tooling je die kant op duwt.
Waarom gebruikt een lokale LLM meer geheugen dan zijn bestand?
De bestandsgrootte is alleen de modelgewichten. Tijdens runtime betaal je ook voor de KV-cache (de attention-status voor elk token in je contextvenster), activaties (de tussentijdse berekeningen van een forward pass), en framework- en driveroverhead. Samen voegen de niet-gewicht-onderdelen routinematig 10 tot 20% toe bovenop de gewichten voor een single-user opstelling, en de KV-cache alleen al kan alles overschaduwen zodra de context lang wordt. Een bestand van 4,6 GB kan ruim meer dan 4,6 GB geheugen nodig hebben om te draaien.
Zie runtime-geheugen als vier componenten die op elkaar zijn gestapeld:
- Modelgewichten. Het bestand dat je hebt gedownload. Dit is het enige onderdeel dat zichtbaar is vóór het laden.
- KV-cache. Attention-status voor het contextvenster. Klein bij korte context, enorm bij lange context. Dit is het volgende onderdeel, want het is degene die mensen verrast.
- Activaties. Het werkgeheugen van een forward pass. Voor single-stream lokale inferentie (batchgrootte 1) is dit klein, doorgaans een paar honderd megabyte.
- Frameworkoverhead. De eigen footprint van de runtime plus de GPU-drivercontext. Voor een lichte lokale runtime kan dit klein zijn vergeleken met de modelgewichten en KV-cache; zwaardere serving-frameworks kunnen veel meer reserveren. De eigen geheugenreservering van je besturingssysteem valt hierbuiten en is opnieuw apart.
De gewichten en de frameworkoverhead zijn voorspelbaar. De KV-cache is de variabele die een model dat "past" verandert in een model dat crasht, dus het loont om de daadwerkelijke berekening door te nemen.
Hoeveel geheugen gebruikt de KV-cache?
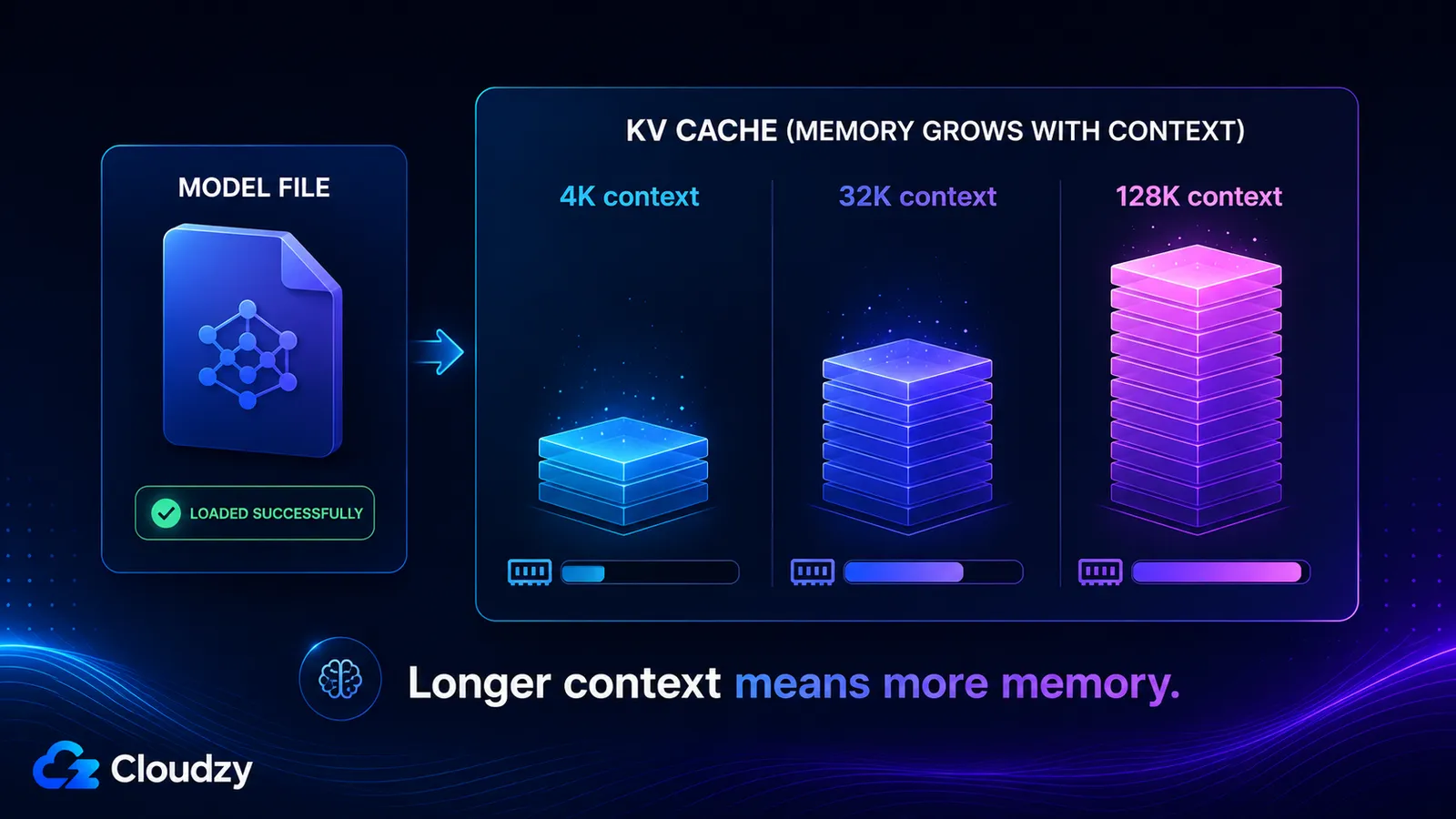
De KV-cache slaat de key- en value-vectoren op voor elk token in je contextvenster, dus het groeit ruwweg lineair met de contextlengte en staat volledig los van de modelgewichten. De grootte wordt bepaald door het aantal lagen van het model, het aantal KV-heads, de head-dimensie, de contextlengte en de precisie van de cache. Schakel een lange context in en je kunt tientallen gigabytes toevoegen waarvoor een model dat prima laadde je nooit heeft gewaarschuwd.
De formule is kort genoeg om te onthouden:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
De voorste 2 staat voor de twee tensors die per token worden opgeslagen, één voor keys, één voor values. bytes_per_element is 2 voor een FP16-cache. De rest zijn architectuurconstanten die je van een modelkaart kunt aflezen.
Werk het uit voor Llama 3.1 8B, dat 32 lagen, 8 KV-heads en een head-dimensie van 128 heeft. Bij een context van 4.096 tokens, batchgrootte 1, FP16-cache:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Schaal de context omhoog en het getal schaalt mee, want elke term behalve context_tokens ligt vast:
- 4K-context: ~536 MB
- 32K-context: ~4,3 GB
- 128K-context: ~17 GB
Die laatste twee cijfers verklaren waarom een model een contextvenster van 128K kan claimen, prima kan laden, en vervolgens het geheugen uitput zodra je dat venster daadwerkelijk gebruikt. De KV-cache bij volledige context is groter dan de gekwantiseerde gewichten zelf.
Dit is het onderdeel dat moderne long-context modellen überhaupt mogelijk maakt: Llama 3.1 8B gebruikt Grouped Query Attention (GQA). Het heeft 32 query-heads maar slechts 8 KV-heads, de cache slaat key/value-vectoren op voor 8 heads, niet 32. Voer dezelfde formule uit met 32 KV-heads (het oudere Multi-Head Attention-ontwerp, waarbij KV-heads gelijk zijn aan query-heads) en elk getal hierboven wordt vermenigvuldigd met 4. Die 17 GB bij 128K wordt dan 68 GB. GQA is de architecturale reden waarom de rekensom haalbaar blijft naarmate contextvensters zijn gegroeid.
De bestandsgrootte is niet je geheugenbudget. Wanneer de gewichten of de KV-cache niet langer in het snelle geheugenpad passen en de runtime moet terugvallen op systeem-RAM via PCIe, degradeert de doorvoer niet geleidelijk. Het valt van een klif zodra je elk token data over PCIe moet verplaatsen. Begroot geheugen zo dat zowel de gewichten als de KV-cache bij je werkelijke contextlengte passen, niet alleen de gewichten.
Hoe kies je een kwantisatie voor je GPU of Mac?
Begin bij je hardware en runtime. NVIDIA-GPU-eigenaren hebben het breedste menu en moeten EXL2 overwegen voor pure snelheid of GGUF voor overdraagbaarheid. Zit je op AMD, Apple Silicon, CPU-only hardware, of een gemengde opstelling, dan is GGUF via llama.cpp meestal het veiligste startpunt. Kies vandaaruit het hoogste kwantisatieniveau dat past nadat je hebt begroot voor de KV-cache bij de contextlengte die je daadwerkelijk gebruikt, niet het maximum van het model.
Eén Apple Silicon-valkuil die het weten waard is: de GPU krijgt niet al je unified memory (zie ons zusterartikel over wat unified memory werkelijk is voor het volledige beeld van hoe die gedeelde pool werkt). De self-hosting community heeft een limiet van rond de 75% gedocumenteerd van het totale unified memory dat beschikbaar is voor de GPU (dit is niet officieel bevestigd door Apple en kan verschuiven met macOS-updates). Dus een "64 GB Mac" is realistisch gezien ~48 GB voor het model plus zijn KV-cache, plan op basis van het kleinere getal.
Dit artikel gaat over het lezen van het formaat en het voorspellen van het runtime-gedrag: decodeer de kwantisatienaam, kies het formaat dat je hardware ondersteunt, en begroot de KV-cache los van de gewichten. Een specifiek model matchen met een specifieke hoeveelheid geheugen, de opzoektabel van grootte naar geheugen, is een gerelateerde maar aparte vraag die we in een toekomstig zusterartikel behandelen.
Lees de repo
Je kunt nu naar een modelpagina kijken en die lezen in plaats van gokken. Decodeer de kwantisatienaam naar zijn effectieve bitbreedte, herken dat GGUF het breedste lokale formaat is terwijl GPTQ, AWQ en EXL2 meer runtime-specifiek zijn, en onthoud dat de bestandsgrootte slechts de ondergrens is, de KV-cache stapelt zich erbovenop en groeit met je context. Open de bestanden voor het model dat je wilt, kies het formaat dat je hardware kan draaien, kies het hoogste kwantisatieniveau dat past nadat je ruimte hebt overgelaten voor de KV-cache bij je werkelijke contextlengte, en je vermijdt de out-of-memory-crash waarmee deze hele vraag begon.
Veelgestelde vragen
Wat betekent Q4_K_M?
Q4_K_M is een GGUF-kwantisatieniveau: ruwweg 4 bits per gewicht (Q4), met K-quant-schaling per blok (K), op de middelste grootte-/kwaliteitsklasse (M). De effectieve bitbreedte is ongeveer 4,89 bits per gewicht, niet precies 4, omdat K-quants een schaal- en minimumwaarde opslaan voor elk blok gewichten. Daarom is een "4-bit" 8B-modelbestand ongeveer 4,6 GB in plaats van 3,5 GB.
Vermindert kwantisatie de kwaliteit van een LLM?
Ja, maar de kost hangt sterk af van hoe ver je het doorvoert. Bij Llama-3.1-8B-Instruct gemeten in arXiv:2601.14277 stijgt de perplexiteit slechts ongeveer 0,4% bij Q6_K en blijft rond 1% door de hele Q5-band. Zak naar Q4 en de stijging is nog steeds bescheiden (een paar procent); onder Q3_K_M loopt het steil op, tot +22% bij Q3_K_S. Voor de meeste toepassingen is Q4_K_M en hoger effectief lossless; de steile straf zit bij 3 bits en lager.
Wat is het verschil tussen GGUF, GPTQ, AWQ en EXL2?
GGUF (gedraaid door llama.cpp) is het overdraagbare formaat, het werkt op CPU, GPU, of een hybride opstelling op een breed scala aan hardware. GPTQ, AWQ en EXL2 zijn meer GPU- en runtime-specifiek. Bij 4-bit kunnen alle vier in een smalle kwaliteitsband uitkomen, dus het praktische verschil zit in hardware, loader-ondersteuning, snelheid en VRAM-gebruik: EXL2 is de op snelheid gerichte NVIDIA/CUDA-keuze, AWQ is gangbaar in serving-stacks, GPTQ past bij oudere GPU-tooling en modelrepo's, en GGUF blijft de meest overdraagbare lokale optie.
Waarom gebruikt mijn lokale LLM meer geheugen dan het bestand?
De bestandsgrootte is slechts de modelgewichten. Tijdens runtime betaal je ook voor de KV-cache (attention-status voor elk token in het contextvenster), activaties, en framework- plus driveroverhead. De KV-cache is meestal de boosdoener als het verschil groot is, omdat die groeit met de contextlengte en apart van de gewichten wordt toegewezen; een model waarvan het bestand een paar gigabyte is, kan veel meer geheugen nodig hebben zodra je een lange context instelt.
Hoe beïnvloedt contextlengte het geheugengebruik?
De KV-cache groeit ruwweg lineair met de contextlengte, dus het verdubbelen van je context verdubbelt ruwweg de cache. Voor Llama 3.1 8B is de cache ongeveer 536 MB bij 4K tokens, ~4,3 GB bij 32K, en ~17 GB bij 128K (FP16, single stream). Die groei staat volledig los van de modelgewichten, wat verklaart waarom het claimen van een lang contextvenster een model in out-of-memory kan duwen, ook al laadde het prima.


