
De lus draaide veertig keer zonder problemen in de testomgeving. Bij de eenenveertigste uitvoering, in productie, riep hij steeds hetzelfde SQL-tool aan met dezelfde kapotte query, totdat hij het volledige API-budget van die dag had opgesoupeerd en een factuurmelding iemand eindelijk wakker schudde. Niemand had een slechte model geschreven. Niemand had de prompt gewijzigd. De agent had simpelweg nooit besloten dat hij klaar was.
Dit is het patroon dat ik keer op keer zie bij teams die een agent van een prototype naar een 24/7-werkload verplaatsen. AI-agentlussen falen in productie niet omdat het model plotseling slechter is geworden, maar omdat de uitvoeringslaag ontbrekende termination discipline, gevalideerde toolcontracten, begrensde context, en duurzame toestand mist. Een agentlus is een stochastisch systeem dat de ene na de andere sequentiele beslissing neemt. Zonder een paar specifieke guardrails wordt een zeldzame storing gegarandeerd zodra je hem lang genoeg draait. Beheerde agentplatforms (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) bakken sommige van deze guardrails in; deze gids is bedoeld voor degenen van ons die kozen voor zelfhosting en de lus zelf beheren.
De inzet is groot genoeg dat Gartner verwacht dat meer dan 40% van de agentic AI-projecten voor eind 2027 wordt geannuleerd, vanwege oplopende kosten en onduidelijke waarde. Hieronder volgen zes specifieke manieren waarop lussen in productie falen, het mechanisme achter elk geval, en het harness-patroon dat het oplost, inclusief LangGraph- en n8n-details plus wat er nodig is om dit daadwerkelijk 24/7 te draaien.
De korte versie
- Oneindige lussen: De agent besluit nooit dat hij klaar is. Combineer een harde stappengrens (LangGraph's
recursion_limit, standaard 25) met no-progress-detectie die herhaalde tool+argument-aanroepen afbreekt. - Context overflow: De lus vult zijn eigen contextvenster met geaccumuleerde geschiedenis totdat aanroepen worden afgekapt of mislukken. Vat de geschiedenis samen op vaste intervallen zodat de werkende context begrensd blijft.
- Stille toolfouten: Een tool geeft een lege string terug, het model leest dit als een geldige no-op, en de agent "slaagt" zonder iets te doen. Valideer elk toolresultaat voordat het model het ziet.
- Redeneerverval: Kwaliteit neemt af naarmate de context groeit, zelfs onder de harde limiet. Comprimeer tussentijds, maar bescherm vastgezette veiligheidsinstructies daarbij.
- Statusverlies bij herstart: Een crash betekent opnieuw beginnen. Sla checkpoints op in Postgres (LangGraph
PostgresSaver), niet SQLite, voor productiegebruik. - Retry storms: Tien agents die elk tien keer opnieuw proberen, bestoken een uitgevallen dienst met honderd verzoeken. Voeg exponential backoff met jitter en een globale circuit breaker toe.
Wat deze gids niet behandelt
Dit is een harness-gids, gericht op de engineering rondom de lus, niet op het model erin. Een aantal verwante onderwerpen valt bewust buiten de scope:
- Multi-agent coordinatieproblemen (verouderde reads, achtergelaten toestand tussen agents): een ander probleem dat zijn eigen beschrijving verdient.
- Agent beveiliging (prompt injection, tool poisoning): een aparte faalcategorie met zijn eigen dreigingsmodel.
- Modelselectie en fine-tuning. Deze gids gaat ervan uit dat je een model hebt gekozen en de omgeving eromheen debugt.
- Beheerde agentdiensten, hierboven vermeld; de patronen hier zijn voor het zelfgehoste pad.
Oneindige lussen: wanneer de agent nooit besluit dat hij klaar is

Een agent loopt voor altijd door als er noch een harde stappengrens noch een manier is om te detecteren dat hij geen voortgang meer maakt. De oplossing bestaat uit twee delen: een harde grens als kostenbegrenzer, en no-progress-detectie die elke tool-plus-argument-aanroep hasht en beëindigt wanneer dezelfde aanroep wordt herhaald. In LangGraph is die grens de recursion_limit, standaard 25 stappen; overschrijd je die, dan geeft de graaf een GraphRecursionError.
LangGraph's docs omschrijven die limiet als het bereiken van "het maximale aantal stappen voordat een stopconditie wordt bereikt", en hier is de valkuil die je moet begrijpen: de recursion limit is geen lusbeveiliging. Het is een vangneet die activeert nadat nadat de lus al vijfentwintig stappen heeft verspild inclusief de bijbehorende API-kosten. De eigen aangeleerde terminatielogica van de agent hoort hem lang daarvoor te stoppen, en die logica kan onafhankelijk falen. Een gemeld LangGraph-geval toont een text-to-SQL-agent die bleef doorlussen totdat hij de recursion limit bereikte, ondanks duidelijke stopcondities in de prompt. Hij bleef hetzelfde querytool aanroepen met dezelfde falende SQL, en het issue werd gesloten als "not planned." Ik lees dat als een duidelijk signaal: behandel de grens niet als je stopconditie. Het is je gordel, niet je remmen.
De grens verhogen is eenvoudig; je geeft hem mee via de config bij het aanroepen van de graaf:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Wat een vastgelopen lus daadwerkelijk stopt, is progressiedetectie. Het mechanisme is eenvoudig: hash de toolnaam plus de argumenten bij elke stap, bewaar een kort venster van recente hashes, en breek af wanneer je een herhaling ziet.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Dit vangt de agent op die technisch "actief is" (tools aanroept, tokens genereert) maar steeds dezelfde mislukte actie uitvoert. Het genoemde faalpatroon correspondeert met wat de MAST-taxonomie (IBM Research en UC Berkeley) aanduidt als Unaware of Termination Conditions (FM-1.5), een van de faalpatronen die hun analyse koppelt aan directe taakfouten.
Een stappengrens stopt ongebreidelde kosten. No-progress-detectie stopt de lus die technisch "vordert" maar zichzelf herhaalt. Productie heeft beide nodig.
Contextvenster overflow: wanneer de lus zijn eigen context met rommel vult
Een langlopende lus verzamelt elke tooluitvoer, elke tussentijdse gedachte en elk bericht dat hij heeft geproduceerd, en propt dat vervolgens bij elke beurt terug in het contextvenster. Uiteindelijk loopt het venster vol en worden aanroepen ofwel stilzwijgend afgekapt ofwel mislukken ze volledig. De oplossing is contextsamenvatting op vaste intervallen: elke N stappen de geaccumuleerde geschiedenis comprimeren tot een lopende samenvatting, zodat de werkende context begrensd blijft.
Stel je een onderzoeksagent voor die al een uur draait. Bij stap 60 draagt hij de volledige tekst van elke pagina die hij heeft opgehaald, elk zoekresultaat en elke redeneertrace mee. Geen van die ruwe geschiedenis helpt hem bij stap 61, maar het telt allemaal mee in het venster, en het model betaalt aandachtsbudget aan tokens die het niet langer nodig heeft. Wanneer het venster vol loopt, kapt de provider van een kant af, en de agent verliest stilzwijgend de instructie die hem aan het begin was gegeven.
De drempelwaarde is een afstemmingsbeslissing, en er is een nuttig referentiepunt. De beschrijving van Mem0 van een echt productiesysteem stelt dat de compressor van de Hermes-agent "standaard activeert op 50% van het contextvenster van het model", met een secundair vangnet op 85% voor sessies die tussen beurten sterk groeien. Vijftig procent is een verstandig startpunt: comprimeer vroeg genoeg dat een enkele grote tooluitvoer de limiet niet kan overschrijden voor de volgende geplande compressie.
Opmerking: Overflow en redenatiebederf zijn verschillende problemen, en het volgende gedeelte behandelt het tweede. Overflow is een harde limiet: je raakt de tokens op. Bederf is geleidelijk: het model presteert slechter. voordat je de muur bereikt. Je moet beide aanpakken, en de drempelwaarde hierboven beschermt tegen de harde muur.
Begrensde context is een harness-verantwoordelijkheid, geen modelfunctie. Vat samen op een interval voordat het venster een stille afkap forceert.
Stille toolaanroepfouten: wanneer de agent "slaagt" door niets te doen
Een toolaanroep geeft een lege string of een zachte "geen resultaten gevonden"-melding terug, het model interpreteert dat als een geldig resultaat, en de agent gaat verder alsof de stap gelukt is, waarbij het lijkt te slagen terwijl het niets doet. De oplossing is een validatiepoort bij elke toolreturn: controleer de uitvoer op schema of sanity voordat het model die ooit te zien krijgt, en geef een echte fout terug die de lus moet afhandelen in plaats van een lege successtatus.
Dit is verraderlijk omdat er niets crasht. Een ontwikkelaar die stille faalpatronen in productieagents beschreef stelde het direct: modellen interpreteren generieke lege strings als geldige no-ops en gaan door zonder bewustzijn van de fout. De databasequery die nul rijen teruggaf omdat de verbinding wegviel, ziet er voor het model identiek uit als de query die legitiem niets vond. De agent rapporteert dus "geen overeenkomende records" en gaat verder, en je ontdekt een week later dat een derde van de runs stilzwijgend defect was.
De validatiepoort zit tussen het tool en het model:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelHet gaat niet om de exacte checks; die hangen af van wat elk tool legitiem teruggeeft. Het punt is dat een niet-gevalideerde retourwaarde een beslissing is die je aan een stochastisch model hebt overgelaten, en de standaardmove van het model is om door te gaan.
Een niet-gevalideerde toolreturn is een stille fout die wacht te gebeuren. Valideer de uitvoer, vertrouw niet op de aanroep.
Redeneerverval bij lange contexten: wanneer de agent slechter wordt naarmate hij langer draait
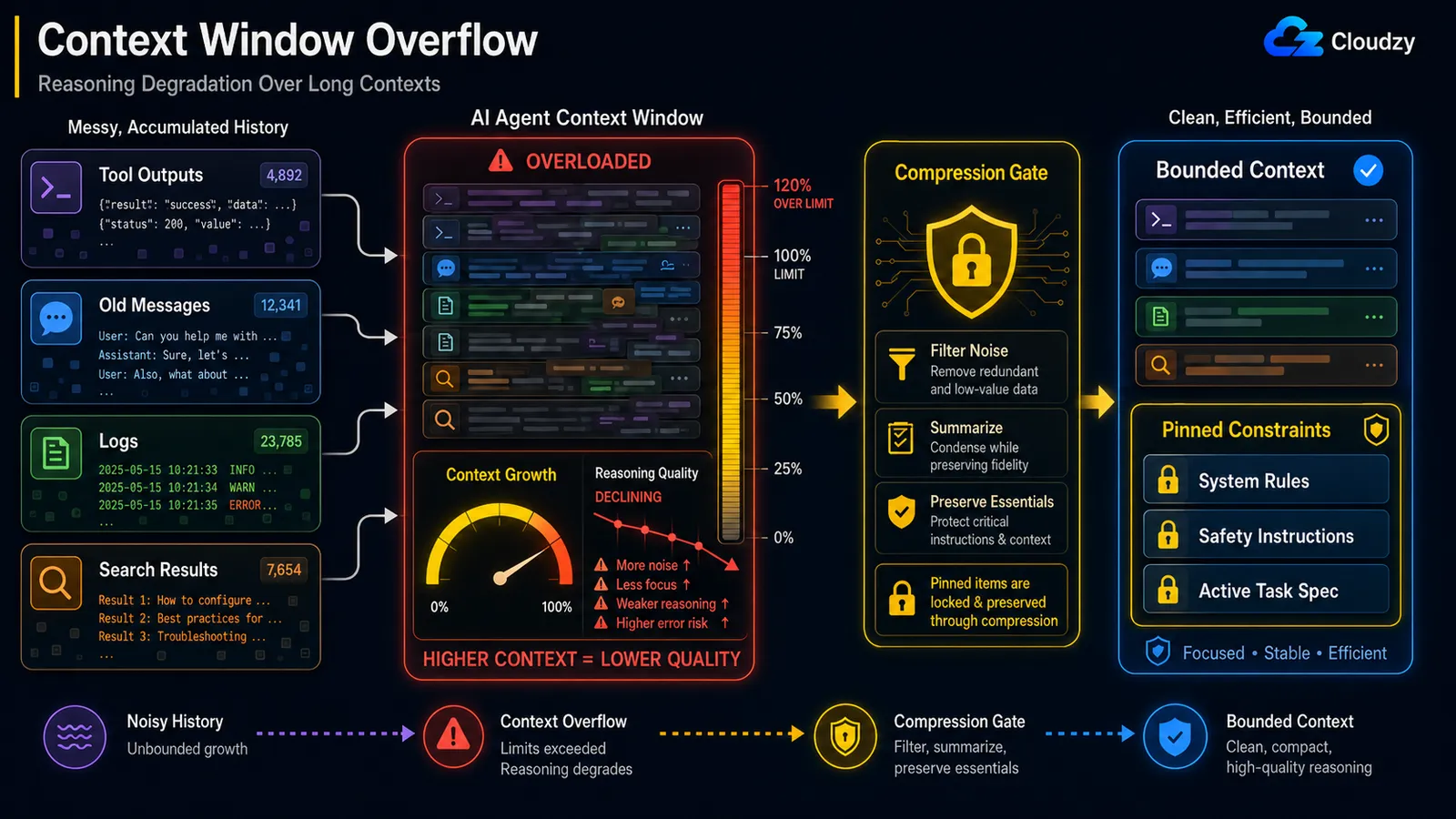
Zelfs wanneer je onder de harde contextlimiet blijft, neemt de redeneerkwaliteit af naarmate de context groeit. Dit is het "lost in the middle"-effect, waarbij het model betrouwbaar aandacht besteedt aan het begin en einde van een lange context maar het midden verliest. De oplossing is tussentijdse compressie die vastgezette beperkingen behoudt: comprimeer de ruis, bescherm de dragende instructies.
Het mechanisme heeft een naam. De engineeringblog van Anthropic verwijst ernaar als context rot: "naarmate het aantal tokens in het contextvenster toeneemt, neemt het vermogen van het model om informatie uit die context nauwkeurig terug te halen af." Omdat "elk token aandacht besteedt aan elk ander token," krijg je n2 paarsgewijze relaties voor n tokens, en de aandacht van het model strekt zich dunner uit naarmate de context langer wordt.
Die kwalificatie, bescherm de dragende instructies, is het hele spel, en er is een gedocumenteerd incident dat laat zien waarom. In een gemeld geval, verwijderde een OpenClaw-agent de inbox van een gebruiker in bulk tijdens een contextcompressie, omdat de veiligheidsinstructie die het had gekregen ("voer geen actie uit totdat ik het je zeg") uit de actieve context was verwijderd toen de geschiedenis werd gecomprimeerd. De beperking die als laatste had moeten gaan, werd behandeld als gewone geschiedenis en samengevat.
Een naive "vat alles ouder dan N beurten samen" is dus gevaarlijk. Compressie moet weten wat het nooit mag weggooien:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactDit verschilt van het overflow-probleem in het vorige gedeelte. Overflow gaat over het opraken van ruimte; verval gaat over het model dat slechter wordt terwijl er nog ruimte over is. Je kunt op 60% van je venster zitten en al slecht redeneren.
Opmerking: Compressie die een veiligheidsbeperking weggooit, is een andere klasse bug dan compressie die een verouderd zoekresultaat verliest. Tag de beperkingen, de taakspecificatie en alle "doe X niet"-instructies als vastgezet, en sluit ze volledig uit van de samenvatter.
Compressie die een veiligheidsinstructie weggooit, is erger dan geen compressie. Bescherm vastgezette beperkingen bij compressie.
Statusverlies bij herstart: wanneer een crash betekent opnieuw beginnen
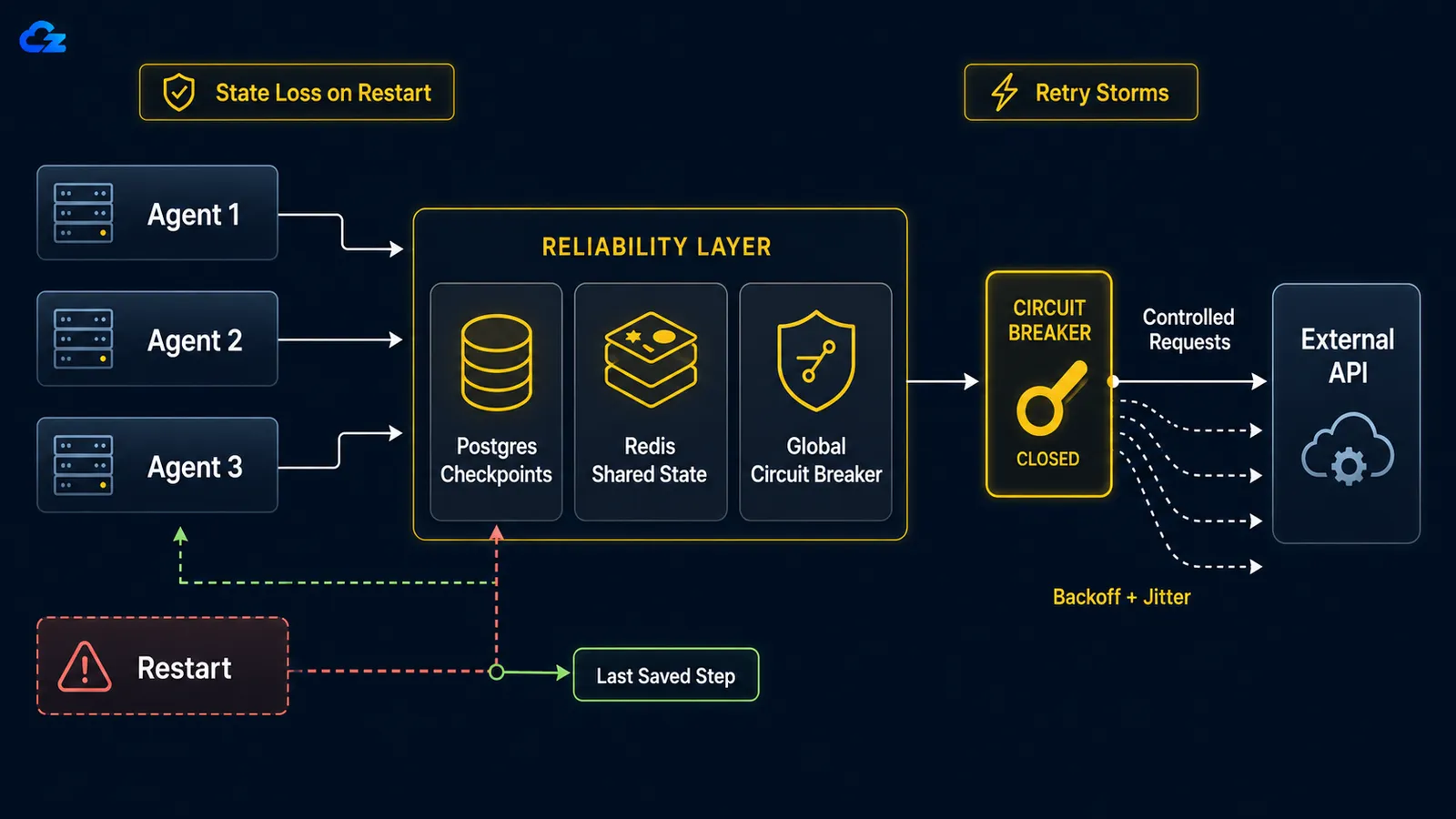
Wanneer een langlopende agent crasht, of door een reboot, een OOM kill, of een verbroken netwerkverbinding, is er standaard geen resume-from-checkpoint. De lus begint opnieuw vanaf het begin: hij herhaalt werk dat al gedaan was en, erger nog, kan acties opnieuw uitvoeren die al uitgevoerd waren, zoals hetzelfde e-mailbericht twee keer verzenden of een betaalde API-aanroep opnieuw uitvoeren. De oplossing is checkpointing: sla de toestand van de lus op na elke stap zodat een herstart rehydrateert vanaf waar hij gestopt was in plaats van vanaf nul.
In LangGraph is de keuze van checkpoint-backend de keuze tussen ontwikkeling en productie. LangGraph's persistentiedocs beschrijven SqliteSaver als "ideaal voor experimenten en lokale workflows" en PostgresSaver als "ideaal voor gebruik in productie", en het laatste is wat LangSmith zelf op draait. De twee zijn bewust parallel in code, wat het contrast gemakkelijk zichtbaar maakt:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverTwee details die mensen verrassen. Ten eerste installeren de checkpoint-pakketten apart van core LangGraph (langgraph-checkpoint-sqlite en langgraph-checkpoint-postgres zijn hun eigen afhankelijkheden), dus een verse installatie heeft de Postgres saver niet totdat je hem toevoegt. Ten tweede heeft elke checkpoint-operatie een thread_id in de config nodig. Dat ID koppelt een gegeven uitvoering aan zijn opgeslagen toestand, en een herstart zonder de juiste thread_id rehydrateert niets.
Pro-tip: De LangGraph checkpoint-pakketten zijn aparte installaties.
langgraph-checkpoint-postgreswordt niet meegeleverd met het basis-langgraphpakket, dus voeg het toe in je productiebestandslijst voordat je het op de harde manier ontdekt tijdens een incident.
n8n heeft dezelfde ontwikkeling-versus-productie-splitsing, alleen onder andere namen. De ingebouwde geheugenoptie heet ook Simple Memory (of Buffer Window Memory), en het productiepad is het Postgres Chat Memory node voor toestand die een herstart moet overleven. Het ingebouwde geheugen houdt het gesprek bij in het actieve proces, wat prima is voor testen maar een risico voor een 24/7-werkload. Praktijkgebruikers die n8n-agents live draaien, melden dat ze moesten migreren naar een Postgres-backed store nadat het in-process-geheugen zo groot werd dat het de instantie meenam. Als je n8n gebruikt en je agent iets moet onthouden na een herstart, koppel het dan meteen aan Postgres Chat Memory.
SQLite checkpointing is een ontwikkelingsgemak. Een productieherstart overleven vereist Postgres (LangGraph) of een Postgres-backed store (n8n).
Retry storms: wanneer je eigen agents een uitgevallen dienst DDoS'en
Wanneer een downstreamdienst uitvalt, veranderen naive per-executie-retries je agentfleet in een zelfveroorzaakte denial-of-service. De oplossing heeft twee kanten: exponential backoff met jitter per agent om de retries over de tijd te spreiden, en een globale circuit breaker die activeert na een gedeelde mislukkingsdrempel en de hele groep stopt met het bestoken van een dienst die duidelijk down is.
De wiskunde is meedogenloos. Zoals een retry-patronenbeschrijving het formuleert: met tien parallelle agents die elk tien keer opnieuw proberen, stuur je honderd verzoeken naar een dienst die al plat ligt, omdat de backoff van elke agent per-executie is, niet globaal. Per-agent-backoff alleen lost dit niet op. Tien agents die elk netjes terugdeinzen, deinzen nog steeds tegelijk terug als ze allemaal op hetzelfde moment zijn gestart, dus ze proberen het opnieuw in gesynchroniseerde golven. Jitter verbreekt de synchronisatie door de wachttijd van elke agent te randomiseren; de circuit breaker verbreekt de kudde door een stuk faaltoestand te delen tussen alle agents.
De backoff-helft is een opgelost probleem in Python; de tenacity bibliotheek verwerkt exponentieel-met-jitter correct:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)De circuit breaker is de helft die globaalmoet zijn: gedeeld tussen alle agents, niet per executie opnieuw geinstantieerd. Wanneer fouten een drempel overschrijden, opent hij, elke agent faalt snel in plaats van een aanroep te doen, en na een cooldown laat hij een enkele sonde door om te testen of de dienst terug is. Een breaker die in elk eigen agentproces leeft, beschermt niets, omdat niets wordt gedeeld; de uitgevallen dienst krijgt nog steeds de volledige honderd verzoeken.
Per-executie-backoff laat tien agents nog steeds gezamenlijk een uitgevallen dienst bestoken. De circuit breaker moet globaal zijn om de kudde te stoppen.
De zes faalpatronen in een oogopslag
Voordat we naar de infrastructuur gaan, hier is de volledige catalogus op een rij: het faalpatroon, het mechanisme dat het veroorzaakt, de harness-fix, en waar de relevante parameter in elk framework te vinden is.
| Foutiestanden | Mechanisme | Harness-fix | Framework-parameter |
|---|---|---|---|
| Oneindige lus | Geen stappengrens of voortgangscontrole | Harde grens + no-progress-detectie | LangGraph recursion_limit (25) / n8n Max Iterations |
| Context overflow | Geschiedenis groeit totdat het venster vol is | Intervalgebaseerde samenvatting | App-niveau (comprimeer bij ~50% van het venster) |
| Stille toolfout | Lege/zachte returns worden gelezen als geldige no-ops | Validatiepoort bij elk toolresultaat | App-niveau tool wrapper |
| Redeneerverval | Aandacht neemt af naarmate de context groeit ("context rot") | Tussentijdse compressie die vastgezette beperkingen beschermt | App-niveau, beperkingsbewust |
| Statusverlies bij herstart | Geen checkpoint; lus begint opnieuw vanaf nul | Persistent checkpointing | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Retry storm | Per-executie retries cascaderen bij een uitgevallen dienst | Backoff + jitter + globale circuit breaker | tenacity + gedeelde breaker-toestand |
Een opmerking voor lezers op CrewAI, AutoGen, Dify, of een handgeschreven Python-lus: de framework-parameters wijzigen, maar de zes patronen niet. Deduplicatie, intervalgebaseerde samenvatting, schemavalidatie, beperkingsbewuste compressie, checkpointing en een globale circuit breaker zijn frameworkonafhankelijke concepten. De LangGraph- en n8n-specifics hier zijn concrete handvatten, niet de grens van waar de patronen van toepassing zijn.
Een productie-agentdeployment dimensioneren
Elk patroon hierboven veronderstelt dat je controle hebt over de procesmanager, de database en het herstartgedrag. Checkpointing biedt je niets als een gecrasht proces nooit weer opstart, en een globale circuit breaker heeft een plek nodig om zijn gedeelde toestand te bewaren. Die controle is precies wat zelfhosting je geeft en een beheerde black box niet, dus de laatste beslissing is het dimensioneren van de server die dit 24/7 draait.
Voor de meeste single-agent-deployments (een agent, LLM-aanroepen naar een extern API, basis Postgres-checkpointing) is een kleine instantie voldoende: ongeveer 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. De zware compute zit aan de kant van de modelprovider; jouw server orkestreert, slaat checkpoints op en houdt toestand bij, maar voert geen inference uit. Stap op naar ongeveer 4 GB RAM, 2 vCPU, and 120 GB NVMe wanneer de agent stateful en meerstaps is met Postgres-checkpointing plus Redis voor sessiehydratie, of wanneer je gelijktijdige workflows draait die de host delen.
De reden dat dit een zelfbeheerde VPS vraagt in plaats van een beperkt platform is dezelfde reden waarom de fixes uberhaupt werken: ze hebben root nodig. Je eigen Postgres voor checkpointing, je eigen Redis voor sessiestatus, en een echte procesmanager zoals systemd or pm2, zodat wanneer een lus wegvalt, de supervisor hem herstart en hij rehydrateert vanuit zijn laatste checkpoint in plaats van de taak opnieuw te beginnen. Dat hele herstelscenario is afhankelijk van het bezitten van de proceslevenscyclus.
Omdat we n8n als een one-click-app in onze eigen marketplace aanbieden, is dat deel van de setup aan onze kant het kortste pad: je kunt n8n deployen op een Cloudzy VPS met de Postgres-backed configuratie die het productiepad nodig heeft, op een instantie waar je root-toegang hebt om je eigen Redis en procestoezicht toe te voegen. Dit is dezelfde zelfgehoste voetafdruk die hierboven beschreven staat, waarbij je eigenaar bent van de database en het herstartgedrag, wat checkpointing en automatisch herstel daadwerkelijk laat werken.
De harness-patronen zijn slechts zo betrouwbaar als de server waarop ze draaien. Checkpointing biedt je niets als het proces nooit herstart.
Veelgestelde vragen
Hoe stop ik mijn LangGraph-agent van eindeloos doorlussen?
Gebruik twee mechanismen samen. Stel recursion_limit in als harde stappengrens (de standaard is 25) zodat een ontspoorde lus niet onbeperkt budget kan verbranden, en voeg no-progress-detectie toe die elke tool-plus-argument-aanroep hasht en beëindigt wanneer dezelfde aanroep zich herhaalt binnen een recent venster. De grens alleen is een vangneet die activeert nadat de verspilling al heeft plaatsgevonden, geen echte lusbeveiliging. Progressiedetectie is wat een vastgelopen lus daadwerkelijk stopt.
Wat is de juiste recursion_limit voor LangGraph in productie?
Er is geen universeel getal. Stel het in op het maximale aantal legitieme stappen dat je agent ooit nodig zou moeten hebben, plus een marge, en behandel het strikt als een kostenbegrenzer. Het verhogen van de limiet zorgt er niet voor dat een loopende agent convergeert. Als je agent een hoge limiet bereikt, is de fix progressiedetectie, geen hogere grens.
Waarom blijft mijn n8n AI-agent Max Iterations bereiken?
Het bereiken van de Max Iterations-grens betekent dat de agent niet convergeert: hij neemt meer stappen dan de limiet toestaat zonder een stop te bereiken. Verhoog de limiet alleen als de taak legitiem meer stappen nodig heeft; behandel het anders als een signaal dat de agent vastzit. Let op een specifieke valkuil: GitHub issue #22771 meldt dat wanneer de iteratielimiet wordt bereikt met "On Error: Continue" ingesteld, de uitvoering kan worden doorgestuurd naar de Success-uitvoer in plaats van de Error-uitvoer, waardoor een gecapte, mislukte run eruit kan zien als een succes in je workflow.
Hoe bewaar ik de agentstatus over herstarts heen?
In LangGraph, gebruik PostgresSaver checkpointing in plaats van SqliteSaver, wat bedoeld is voor lokale ontwikkeling. Gebruik in n8n de Postgres Chat Memory node in plaats van het ingebouwde in-process-geheugen. Beide vereisen een persistente database, en in LangGraph heeft elke checkpoint-operatie een thread_id nodig dat een gegeven uitvoering koppelt aan zijn opgeslagen toestand.
Wat veroorzaakt redeneerverval bij lange agentuitvoeringen?
Redeneerkwaliteit neemt af naarmate de context groeit, zelfs voordat je de harde tokenlimiet bereikt. Dit is het "lost in the middle"-effect, waarbij het model aandacht besteedt aan het begin en einde van een lange context maar het midden verliest. De engineeringblog van Anthropic verwijst naar het onderliggende mechanisme als "context rot": omdat elk token aandacht besteedt aan elk ander token, krijg je n2 paarsgewijze relaties en strekt de aandacht van het model zich dunner uit naarmate de context langer wordt. De oplossing is tussentijdse compressie die verouderde geschiedenis samenvat terwijl vastgezette beperkingen en veiligheidsinstructies intact blijven.


