
Wybór GPU Cloud VPS może przytłaczać, gdy patrzysz na karty katalogowe pełne liczb. Liczba rdzeni waha się od 2560 do 21760, ale co to naprawdę oznacza?
CUDA core to jednostka przetwarzająca będąca częścią GPU NVIDIA GPU, która wykonuje tysiące obliczeń jednocześnie — od trenowania modeli AI po renderowanie 3D. Ten przewodnik wyjaśnia, jak działają, czym różnią się od rdzeni CPU i Tensor, oraz które liczby rdzeni pasują do Twoich potrzeb bez przeplacania.
Czym są rdzenie CUDA?

CUDA cores to jednostki przetwarzające wewnątrz GPU NVIDIA GPU, które wykonują instrukcje równolegle. Na czym polega technologia CUDA core w istocie? Wyobraź sobie te jednostki jako małych pracowników, którzy jednocześnie rozwiązują części tego samego zadania.
NVIDIA wprowadził CUDA (Compute Unified Device Architecture) w 2006 roku, aby wykorzystać moc GPU do obliczeń ogólnych, poza grafiką. Jego oficjalna dokumentacja CUDA zawiera szczegółowe informacje techniczne. Każda jednostka wykonuje proste operacje arytmetyczne na liczbach zmiennoprzecinkowych — doskonałe do obliczeń powtarzalnych.
Nowoczesne GPU NVIDIA GPU zawierają tysiące tych jednostek w jednym chipie. Karty graficzne konsumenckie najnowszej generacji mają ponad 21 tysięcy rdzeni, natomiast GPU data center oparte na architekturze Hopper posiadają do 16896 rdzeni. Te jednostki pracują razem poprzez Streaming Multiprocessors (SMs).
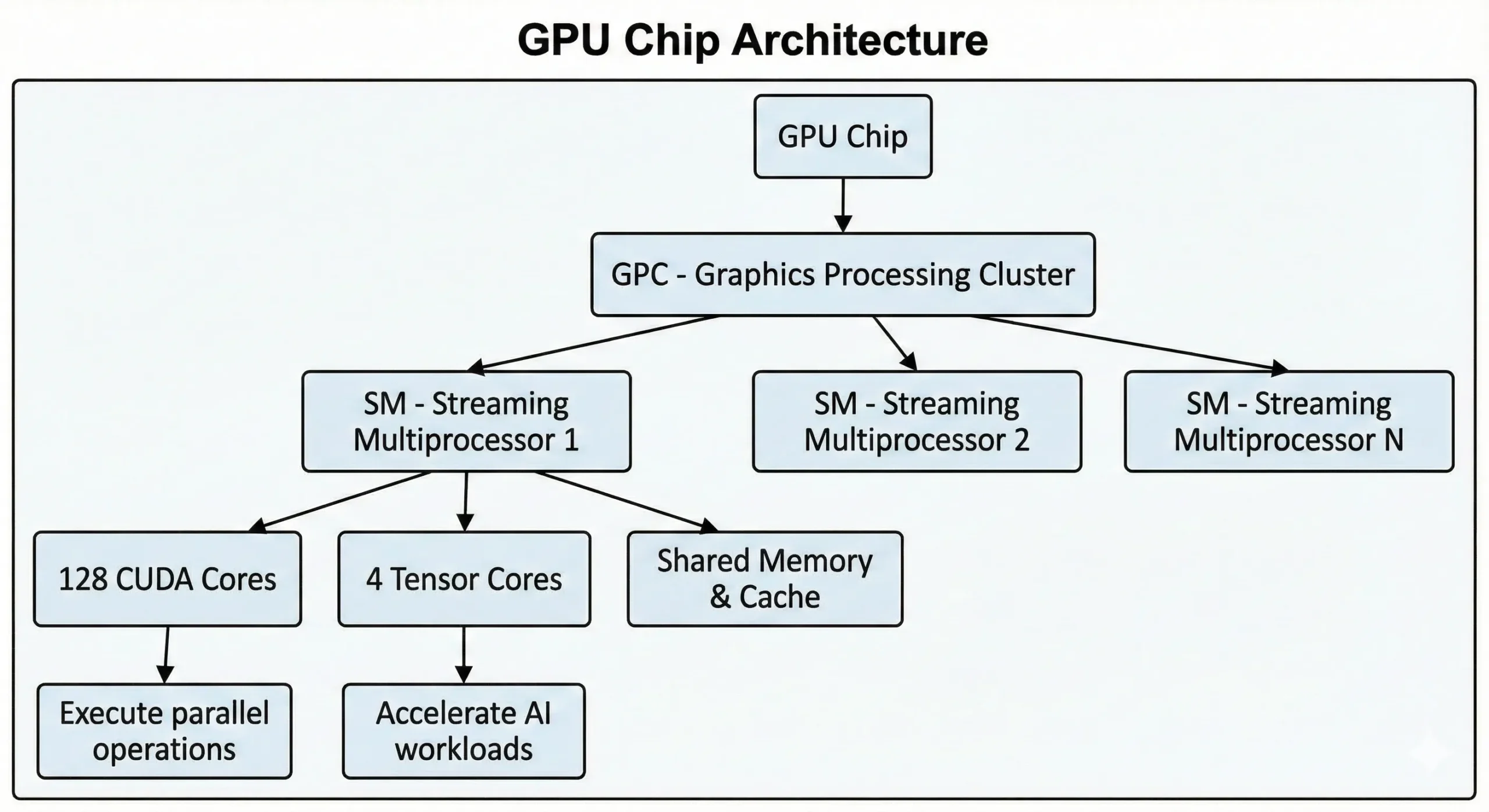
Jednostki wykonują operacje SIMT (Single Instruction, Multiple Threads) przy użyciu metod obliczeń równoległych. Jedna instrukcja wykonuje się na wielu punktach danych jednocześnie. Podczas trenowania sieci neuronowych lub renderowania scen 3D zachodzi tysiące podobnych operacji. System dzieli tę pracę na równoczesne strumienie, wykonując je równolegle zamiast sekwencyjnie.
CUDA Cores vs CPU Cores: Czym się różnią?

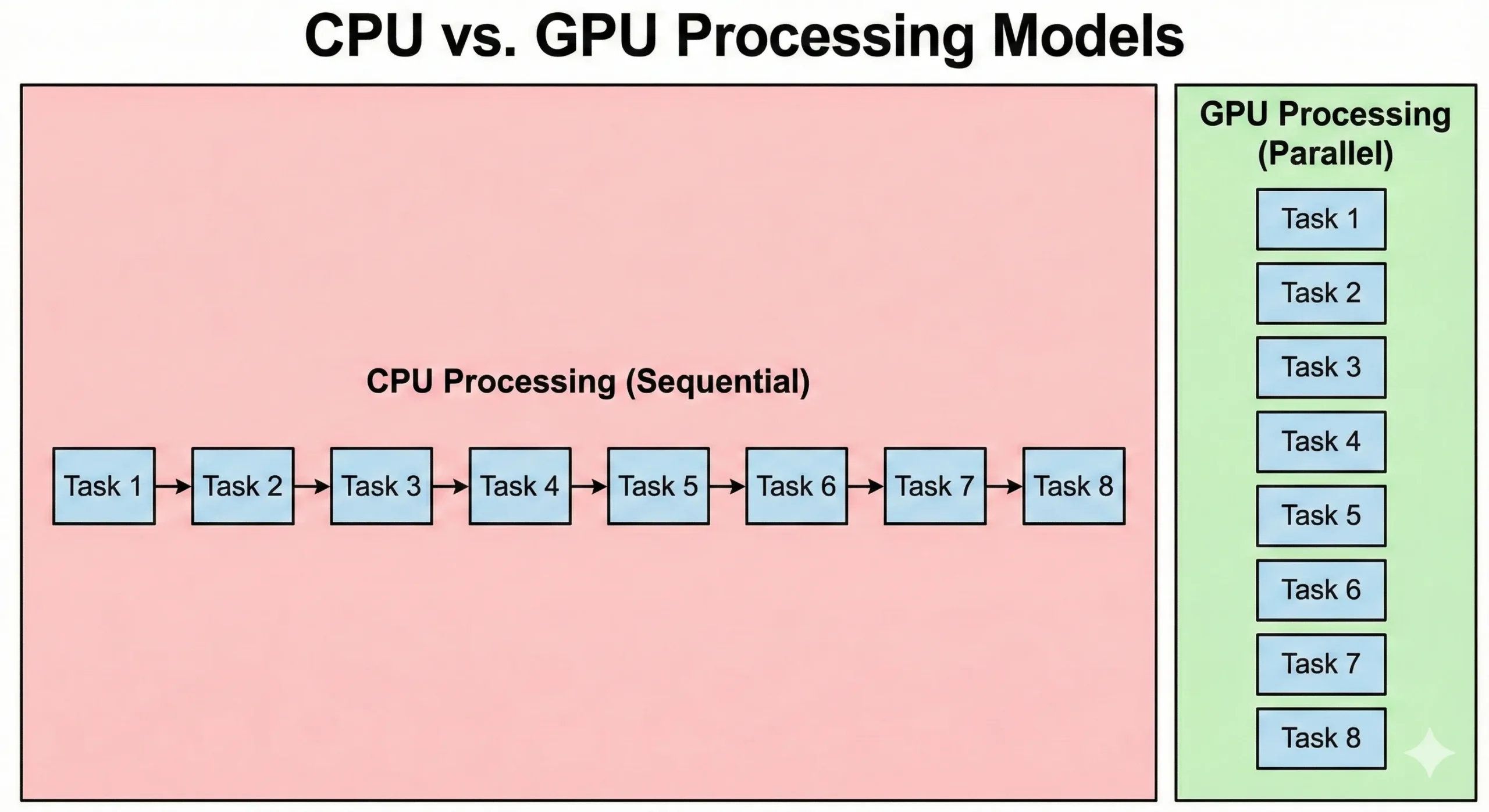
CPUs i GPUs rozwiązują problemy w fundamentalnie różne sposoby. Nowoczesny serwer CPU może mieć 8-128+ rdzeni pracujących przy wysokich częstotliwościach taktowania. Te procesory doskonale radzą sobie z operacjami sekwencyjnymi, gdzie każdy krok zależy od wyniku poprzedniego. Sprawnie obsługują złożoną logikę i rozgałęzienia.
GPUs odwracają to podejście. Zawierają tysiące prostszych CUDA cores pracujących przy niższych częstotliwościach taktowania. Te jednostki kompensują niższą szybkość poprzez równoległość. Gdy 16 000 pracuje razem, całkowita przepustowość przewyższa możliwości standardowego CPU.
CPUs wykonują kod systemu operacyjnego i złożoną logikę aplikacji. Gdy GPUs priorytetyzują przepustowość, obciążenie z inicjalizacji zadań i synchronizacji skutkuje wyższym opóźnieniem. Równoległa obróbka grafiki priorytetyzuje przesyłanie danych. Choć uruchomienie trwa dłużej, przetwarzają duże zestawy danych szybciej niż CPUs.
| Funkcja | Rdzenie CPU | Rdzenie CUDA |
| Liczba na chip | 4-128+ rdzeni | 2560-21760 rdzeni |
| Częstotliwość taktowania | 3,0-5,5 GHz | 1,4-2,5 GHz |
| Styl przetwarzania | Sekwencyjne, złożone instrukcje | Równoległe, proste instrukcje |
| Najlepszy dla | Systemy operacyjne, zadania jednowątkowe | Matematyka macierzowa, równoległa obróbka danych |
| Opóźnienie | Niska (mikrosekundy) | Wyższe (obciążenie uruchomienia) |
| Architektura | Ogólnego przeznaczenia | Wyspecjalizowane w powtarzalnych obliczeniach |
Technologie Virtual GPU (vGPU) i Multi-Instance GPU (MIG) obsługują partycjonowanie zasobów i planowanie, aby rozprowadzić procesory między wielu użytkowników. Ta konfiguracja pozwala zespołom maksymalizować wykorzystanie sprzętu poprzez współdzielenie czasowe lub dedykowane instancje sprzętu, w zależności od ustawień.
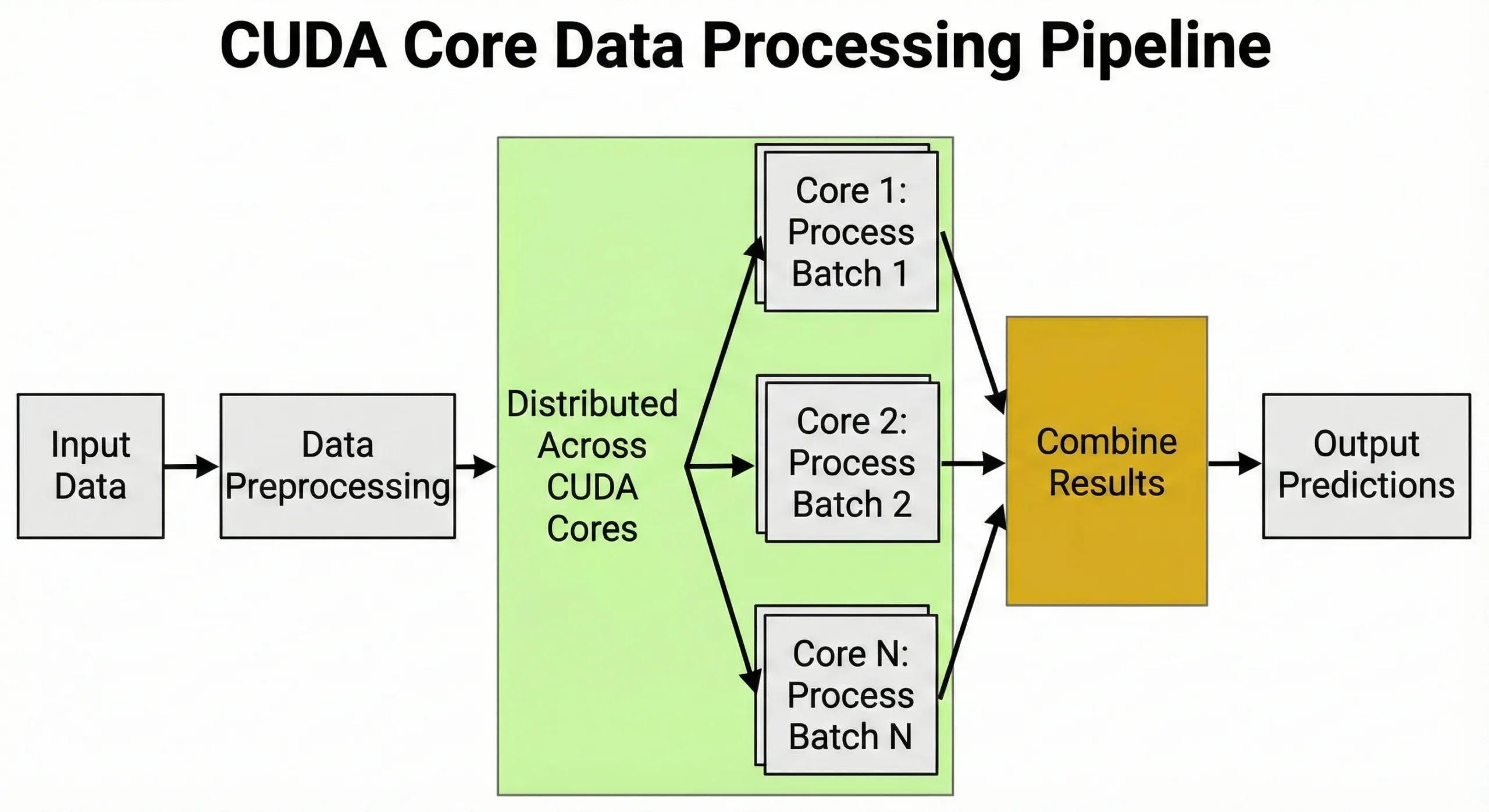
Trening sieci neuronowych obejmuje miliardy mnożeń macierzowych. GPU z 10 000 jednostkami nie po prostu wykonuje 10 000 operacji jednocześnie; zamiast tego zarządza tysiącami równoległych wątków zgrupowanych w "warpy", aby maksymalizować przepustowość. Dzięki takiemu masywnie równoległemu przetwarzaniu te jednostki są must-know dla deweloperów zajmujących się AI.
CUDA Cores vs Tensor Cores: Zrozumienie różnic

NVIDIA GPUs zawiera dwa wyspecjalizowane typy jednostek pracujące razem: standardowe CUDA cores i Tensor cores. Nie konkurują ze sobą; zajmują się różnymi częściami obciążenia.
Standardowe jednostki to procesory równoległe ogólnego przeznaczenia obsługujące obliczenia FP32 i FP64, matematykę całkowitą i transformacje współrzędnych. Ta podstawowa technologia CUDA stanowi fundament obliczeń GPU, uruchamiając wszystko od symulacji fizyki do wstępnego przetwarzania danych bez wyspecjalizowanego przyspieszenia.
Tensor cores to wyspecjalizowane jednostki zaprojektowane wyłącznie dla mnożenia macierzowego i zadań AI. Wprowadzone w architekturze NVIDIA Volta (2017), doskonale radzą sobie z obliczeniami o precyzji FP16 i TF32. Najnowsze generacje obsługują FP8 dla jeszcze szybszego wnioskowania AI.
| Funkcja | Rdzenie CUDA | Rdzenie Tensor |
| Cel | Ogólne obliczenia równoległe | Mnożenie macierzowe dla AI |
| Dokładność | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Szybkość dla sztucznej inteligencji | 1x punkt odniesienia | 2-10x szybciej niż CUDA cores |
| Przypadki użycia | Wstępne przetwarzanie danych, tradycyjne ML | Trenowanie i wnioskowanie w głębokim uczeniu |
| Dostępność | Wszystkie procesory NVIDIA GPU | RTX serii 20 i nowsze, procesory datacentrowe GPU |
Nowoczesne procesory GPU łączą oba typy. RTX 5090 ma 21 760 standardowych jednostek plus 680 rdzeni Tensor piątej generacji. H100 łączy 16 896 jednostek standardowych z 528 rdzeniami Tensor czwartej generacji do przyspieszenia głębokich sieci neuronowych.
Podczas trenowania sieci neuronowych rdzenie Tensor wykonują intensywne obliczenia w przednich i wstecznych przejściach przez model. Jednostki standardowe zarządzają ładowaniem danych, przetwarzaniem wstępnym, obliczeniami straty oraz aktualizacjami optymalizatora. Oba typy pracują razem, przy czym rdzenie Tensor przyspieszają operacje wymagające dużej mocy obliczeniowej.
W przypadku tradycyjnych algorytmów uczenia maszynowego, takich jak lasy losowe lub gradient boosting, jednostki standardowe wykonują pracę, ponieważ te algorytmy nie wykorzystują wzorców mnożenia macierzy, które przyspieszają rdzenie Tensor. Jednak dla modeli transformerów i sieci neuronowych splotowych rdzenie Tensor zapewniają znaczne przyspieszenia.
Do czego służą rdzenie CUDA?

Rdzenie CUDA zasilają zadania wymagające tysięcy identycznych obliczeń wykonywanych jednocześnie. Każda praca obejmująca operacje na macierzach lub powtarzające się obliczenia numeryczne korzysta z ich architektury.
Aplikacje sztucznej inteligencji i uczenia maszynowego
Głębokie uczenie opiera się na mnożeniu macierzy podczas trenowania i wnioskowania. Podczas trenowania sieci neuronowych każde przejście w przód wymaga milionów operacji mnożenia-dodawania na macierzach wag. Wsteczna propagacja błędu dodaje miliony więcej podczas przejścia w tył.
Jednostki zarządzają przetwarzaniem wstępnym danych, konwertowaniem obrazów na tensory, normalizacją wartości oraz stosowaniem transformacji augmentacji. Zdolność do obsługi tysięcy zadań jednocześnie to dokładnie powód, dla którego procesory GPU są ważne dla AI.
Podczas trenowania nadzorują harmonogramy współczynnika uczenia, obliczenia gradientów oraz aktualizacje stanu optymalizatora.
W przypadku VPS dla operacji wnioskowania AI z systemami rekomendacji lub chatbotami przetwarzają żądania równolegle, wykonując setki prognoz jednocześnie. Nasz poradnik na temat najlepszego procesora GPU dla AI w 2025 roku obejmuje konfiguracje odpowiednie dla różnych rozmiarów modeli.
H100 z 16 896 jednostkami w połączeniu z rdzeniami Tensor trenuje model z 7 miliardami parametrów w tygodniach zamiast miesięcy. Wnioskowanie w czasie rzeczywistym dla chatbotów obsługujących tysiące użytkowników wymaga podobnej mocy równoczesnego wykonywania.
Obliczenia naukowe i badania
Naukowcy używają tych procesorów do symulacji dynamiki molekularnej, modelowania klimatu i analizy genomiki. Każde obliczenie jest niezależne, co czyni je doskonałymi do równoczesnego wykonywania. Instytucje finansowe uruchamiają symulacje Monte Carlo z milionami scenariuszy jednocześnie.
Renderowanie 3D i produkcja wideo
Ray tracing oblicza odbicia światła w scenach 3D poprzez śledzenie niezależnych promieni przez każdy piksel. Podczas gdy dedykowane rdzenie RT obsługują przechodzenie, jednostki standardowe zarządzają próbkowaniem tekstur i oświetleniem. To rozdzielenie determinuje szybkość scen z milionami promieni.
NVENC obsługuje kodowanie H.264 i H.265, zaś najnowsze architektury (Ada Lovelace i Hopper) wprowadzają wsparcie sprzętowe dla AV1. CUDA wspomaga efekty, filtry, skalowanie, redukcję szumu, transformacje kolorów i integrację potoku. Umożliwia to silnikowi kodowania pracę równolegle z procesorami równoległymi dla szybszej produkcji wideo.
Renderowanie 3D w Blenderze lub Maya'ie rozprowadza miliady obliczeń modułu cieniującego powierzchni na dostępne jednostki. Systemy cząstek korzystają, ponieważ symulują tysiące cząstek oddziałujących jednocześnie. Te funkcje są kluczowe dla zaawansowanego tworzenia cyfrowego.
Jak rdzenie CUDA wpływają na wydajność procesora GPU

Liczba rdzeni daje ci przybliżone pojęcie o możliwości równoczesnego wykonywania, ale rdzenie CUDA wymagają pogłębionej analizy. Szybkość zegara, przepustowość pamięci, efektywność architektury i optymalizacja oprogramowania odgrywają kluczową rolę.
Procesor GPU z 10 000 jednostkami pracujący na 2,0 GHz daje inne wyniki niż jeden z 10 000 jednostkami na 1,5 GHz. Wyższa szybkość zegara oznacza, że każda jednostka wykonuje więcej obliczeń na sekundę. Nowsze architektury wykonują więcej pracy w każdym cyklu dzięki lepszemu planowaniu instrukcji.
Sprawdź, czy utrzymujesz urządzenie zajęte, ale pamiętaj, że nvidia-smi wykorzystanie to miernik przybliżony. Mierzy procent czasu, w którym jądro jest aktywne, a nie liczbę pracujących rdzeni.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderPrzykładowe wyniki: 85%, 92% (85% czasu aktywności, 92% aktywności kontrolera pamięci)
Jeśli GPU pokazuje wykorzystanie 60-70%, prawdopodobnie masz wąskie gardła na wcześniejszych etapach, takie jak ładowanie danych CPU lub małe rozmiary partii. Jednak nawet 100% wykorzystanie może być mylące, jeśli twoje jądra są ograniczone pamięcią lub jednowątkowe. Aby uzyskać rzeczywisty obraz nasycenia rdzeni, użyj profilerów takich jak Nsight Systems do śledzenia metryk "SM Efficiency" lub "SM Active".
Przepustowość pamięci często staje się wąskim gardłem przed maksymalizacją możliwości obliczeniowych. Jeśli GPU przetwarza dane szybciej niż pamięć je dostarcza, jednostki czekają. Model H100 SXM5 wykorzystuje przepustowość 3,35 TB/s aby zasilić swoje 16 896 rdzeni. Wersja PCIe zmniejsza to jednak do 2 TB/s.
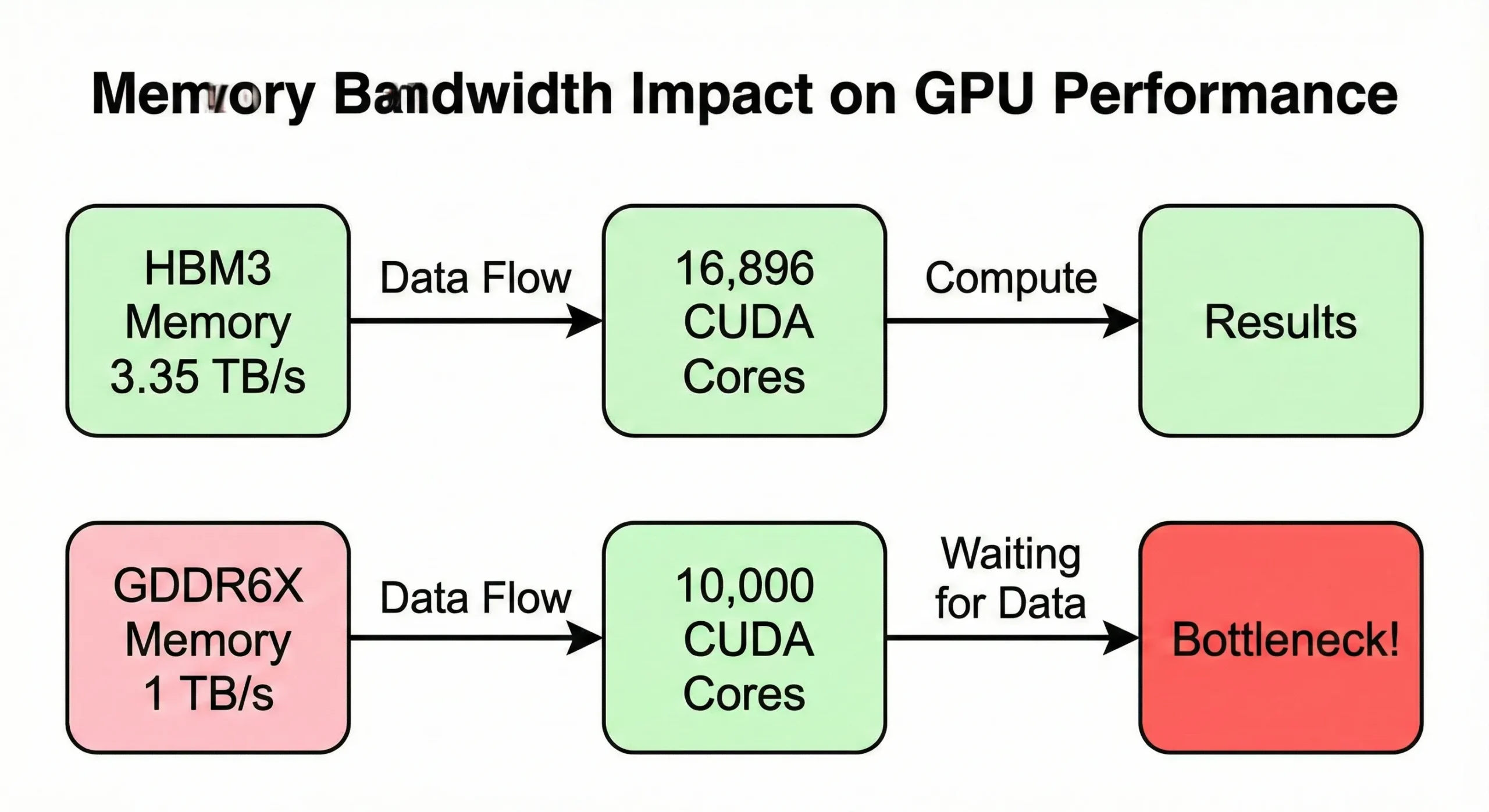
Konsumenckie procesory GPU o podobnej liczbie rdzeni, ale niższej przepustowości (około 1 TB/s) wykazują zmniejszoną rzeczywistą szybkość przy operacjach intensywnie korzystających z pamięci.
Pojemność VRAM określa rozmiar twoich zadań. Niezależnie od tego, czy chodzi o wagi FP16 dla Model 70B, pełne szkolenie wymaga więcej pamięci. Musisz uwzględnić gradienty i stany optymalizatora. Te stany często potrajają przepustowość, chyba że używasz strategii offloadowania
A100 80GB jest przeznaczony do wnioskowania o wysokiej przepływności i fine-tuningu. Tymczasem 24GB RTX 4090, często cytowany dla modeli 7B, może zaskakująco uruchomić modele z 30B+ parametrami, jeśli używasz nowoczesnych technik kwantyzacji, takich jak INT4. Jednak wyczerpanie VRAM zmusza do transferów danych CPU-GPU, które niszczą przepływność.
Optymalizacja oprogramowania decyduje o tym, czy twój kod faktycznie wykorzystuje wszystkie te jednostki. Słabo napisane jądra mogą zaangażować tylko ułamek dostępnych zasobów. Biblioteki takie jak cuDNN do deep learningu i RAPIDS do nauki o danych są intensywnie dostrajane, aby maksymalizować wykorzystanie.
Więcej rdzeni CUDA nie zawsze oznacza lepszą wydajność

Zakup GPU z największą liczbą rdzeni wydaje się logiczny, ale tracisz pieniądze, jeśli jednostki wyprzedzają inne komponenty systemu lub twoje zadanie nie skaluje się wraz z liczbą rdzeni.
Przepustowość pamięci tworzy pierwsze ograniczenie. 21 760 jednostek RTX 5090 jest zasilanych przez przepustowość pamięci 1 792 GB/s. Starsze procesory GPU z mniejszą liczbą jednostek mogą mieć proporcjonalnie wyższą przepustowość na jednostkę.
Różnice w architekturze są istotne. Nowszy GPU z 14 000 rdzeni na 2,2 GHz przewyższa starszy GPU z 16 000 na 1,8 GHz dzięki lepszym instrukcjom na cykl. Twój kod musi być odpowiednio zrównoleglony, aby efektywnie wykorzystać 20 000 rdzeni.
Dlaczego rdzenie CUDA mają znaczenie przy wyborze GPU VPS

Wybranie odpowiedniej konfiguracji GPU z rdzeniami CUDA do VPS zapobiega marnowaniu pieniędzy na nieużywane zasoby lub trafieniu na wąskie gardła w trakcie projektu.
Pamięć 80GB H100 obsługuje wnioskowanie dla modeli z 70B parametrami przy użyciu kwantyzacji 4-bitowej. Jednak do pełnego szkolenia nawet 80GB jest często niewystarczające dla modelu 34B, gdy uwzględnisz gradienty i stany optymalizatora. Podczas szkolenia FP16 przepustowość pamięci rośnie znacznie, co często wymaga dzielenia na wiele GPU.
Operacje wnioskowania obsługujące predykcje w czasie rzeczywistym wymagają mniej jednostek, ale korzystają z niskich opóźnień. Prace nad rozwojem i prototypowaniem sprawdzają się dobrze ze środkowymi GPUs do testowania algorytmów i debugowania kodu.
RTX 4060 Ti z 4352 jednostkami pozwala testować bez płacenia za nadmiarowy sprzęt. Po zatwierdzeniu podejścia skaluj do produkcyjnych GPUs do pełnych przebiegów treningowych.
Rendering i praca wideo skalują się wraz z jednostkami do pewnego punktu. Renderer Cycles aplikacji Blender efektywnie wykorzystuje wszystkie dostępne zasoby. GPU z 8000-10000 jednostkami renderuje sceny 2-3 razy szybciej niż z 4000.
W Cloudzy oferujemy hosting o wysokiej wydajności GPU VPS zbudowany do ciężkich zadań. Wybierz RTX 5090 lub RTX 4090 do szybkiego renderowania i opłacalnego wnioskowania AI, lub skaluj do A100s do masywnych obciążeń deep learning. Wszystkie plany działają w sieci 40 Gbps z polityką prywatności na pierwszym miejscu i opcjami płatności kryptowalutą, dając ci czystą moc bez biurokratii korporacyjnej.
Niezależnie od tego, czy trenujesz modele AI, renderujesz sceny 3D czy uruchamiasz symulacje naukowe, wybierasz liczbę rdzeni, która pasuje do twoich potrzeb.
Kwestie budżetu mają znaczenie. A100 z 6912 jednostkami kosztuje znacznie mniej niż H100 z 16896. W wielu operacjach dwa A100s zapewniają lepszy stosunek ceny do prędkości niż jeden H100. Punkt równowagi zależy od tego, czy twój kod skaluje się na wielu GPUs.
Jak wybrać właściwą liczbę rdzeni CUDA
Dopasuj swoje wymagania do rzeczywistych charakterystyk obciążenia zamiast gonić za największymi liczbami dostępnymi na rynku.
Zacznij od profilowania bieżącej pracy. Jeśli trenujesz modele na lokalnym sprzęcie lub instancjach w chmurze, sprawdź metryki wykorzystania GPU. Jeśli twój obecny GPU pokazuje konsekwentnie 60-70% wykorzystania, nie maksymalizujesz jednostek.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Ten prosty benchmark pokazuje, czy rdzenie twojego GPU dostarczają oczekiwaną przepustowość. Porównaj wyniki ze opublikowanymi benchmarkami dla twojego modelu GPU.
Uaktualnienie nie pomoże. Musisz najpierw usunąć wąskie gardła, takie jak pamięć, przepustowość lub zakleszzczenia CPU. Dalej oszacuj wymagania pamięci, obliczając rozmiar modelu w bajtach plus pamięć aktywacji.
Dodaj rozmiar partii razy wyjścia warstwy i dołącz stany optymizera. Ta suma musi zmieścić się w VRAM. Znając wymaganą pamięć, sprawdź które GPUs spełniają ten próg.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Rozważ swój harmonogram. Jeśli potrzebujesz wyników w godziny, zapłać za więcej jednostek. Przebiegi treningowe, które mogą trwać dni, działają dobrze na mniejszych GPUs z proporcjonalnie dłuższymi czasami ukończenia.
Koszt za godzinę razy liczba potrzebnych godzin daje koszt całkowity, czasem czyniąc wolniejsze GPUs tańszymi ogółem. Testuj efektywność skalowania używając wielu frameworków, które zapewniają narzędzia benchmarkingowe pokazujące zmianę przepustowości.
Jeśli podwojenie jednostek daje tylko 1.5x przyspieszenie, dodatkowe nie są warte ich kosztu. Szukaj słodkich punktów, gdzie stosunek ceny do prędkości osiąga maksimum.
| Typ obciążenia | Zalecane rdzenie | Przykładowe GPU | Uwagi |
| Tworzenie i debugowanie modeli | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Szybka iteracja, niższe koszty |
| Trening AI na małą skalę (<7B parametrów) | 6,000-10,000 | RTX 4090, L40S | Pasuje dla konsumentów i małych przedsiębiorstw |
| Trening AI na dużą skalę (7B-70B parametrów) | 14,000+ | A100, H100 | Wymaga GPUs centrów danych |
| Wnioskowanie w czasie rzeczywistym (wysoka przepustowość) | 10,000-16,000 | RTX 5080, L40 | Zrównoważ koszt i wydajność |
| Renderowanie 3D i kodowanie wideo | 8,000-12,000 | RTX 4080, RTX 4090 | Rośnie wraz ze złożonością |
| Obliczenia naukowe i HPC | 10,000+ | A100, H100 | Wymaga wsparcia FP64 |
Popularne procesory VPS i GPU oraz ich liczba rdzeni CUDA

Różne warianty GPU służą różnym grupom użytkowników. Co to jest GPUaaS? To GPU-as-a-Service, czyli usługa, w której dostawcy tacy jak Cloudzy udostępniają dostęp na żądanie do potężnych NVIDIA GPUs bez konieczności kupowania i utrzymywania fizycznego sprzętu.
| Model GPU | Rdzenie CUDA | VRAM | Przepustowość pamięci | Architektura | Najlepsze dla |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1 792 GB/s | Blackwell | Flagowa stacja robocza, rendering 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | Zaawansowana sztuczna inteligencja, renderowanie 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/s | Hopper | Trening sztucznej inteligencji na dużą skalę |
| H100 PCIe | 14,592 | 80GB HBM2e | 2000 GB/s | Hopper | Enterprise AI, tani datacenter |
| A100 | 6,912 | 40/80 GB HBM2e | 1555–2039 GB/s | Ampere | AI dla każdego, sprawdzona niezawodność |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gry, AI średniej klasy |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Datacenter wielozadaniowy |
Karty RTX dla konsumentów (4070, 4080, 4090, 5080, 5090) są przeznaczone dla twórców i graczy, ale doskonale sprawdzają się w rozwoju AI. Oferują dużą wydajność pojedynczego rdzenia w niższych cenach niż karty dla centrów danych.
VPS to karty wybierane przez dostawców dla użytkowników dbających o koszty. Karty do centrów danych (A100, H100, L40) stawiają na niezawodność, pamięć ECC i skalowanie wielu GPU. Radzą sobie z operacją 24/7 i wspierają zaawansowane funkcje.
Multi-Instance GPU (MIG) umożliwia podzielenie jednego GPU na wiele izolowanych instancji. A100 pozostaje popularny pomimo nowszych opcji ze względu na zbilansowane specyfikacje.
Doskonały stosunek rdzeni NVIDIA, pamięci i ceny sprawia, że to bezpieczny wybór do większości produkcyjnych operacji AI. H100 oferuje 2,4x więcej jednostek, ale kosztuje znacznie więcej.
Podsumowanie
Równoległe procesory obliczeniowe umożliwiają nowoczesną sztuczną inteligencję, renderowanie i obliczenia naukowe. Zrozumienie, jak działają i współpracują z pamięcią, taktowaniem i oprogramowaniem, pomoże ci wybrać odpowiednie konfiguracje GPU VPS.
Więcej rdzeni przydaje się, gdy Twoja praca dobrze się paralelizuje i komponenty takie jak przepustowość pamięci nadążają. Ale ślepy wyścig za największą liczbą rdzeni to marnowanie pieniędzy, jeśli wąskie gardła leżą gdzie indziej.
Zacznij od analizy rzeczywistych operacji, sprawdź gdzie czas się zużywa, i dopasuj specyfikacje GPU do swoich potrzeb bez przepłacania za zbędne zasoby.
W przypadku większości prac nad AI, 6000–10 000 jednostek to idealny punkt równowagi między ceną a wydajnością. Operacje produkcyjne, trenowanie dużych modeli czy serwowanie dużych przepływów inference'u wymagają 14 000+ jednostek GPUs, takich jak H100.
Rendering i montaż wideo działają efektywnie z instancjami do około 16 000 jednostek. Powyżej tej wartości przepustowość pamięci staje się wąskim gardłem.


