
В 60-х и 70-х годах монолитная архитектура была предпочтительным подходом к разработке приложений из-за ограниченных вычислительных ресурсов: все функции приходилось объединять в единый, цельный модуль.
Так продолжалось до конца 90-х и начала 2000-х, когда монолитная структура перестала справляться с постоянно растущим объёмом и сложностью приложений — особенно на фоне развития интернета и распределённых систем.
Это привело к появлению более модульных подходов, таких как сервис-ориентированная архитектура (SOA) а впоследствии и микросервисная архитектура (MSA), которая окончательно закрепилась в начале 2010-х.
Это лишь краткое введение в базовые концепции микросервисов. Давайте разберём подробнее: как микросервисы пришли на смену монолитной архитектуре, как они работают и какие у них примеры применения. Затем рассмотрим ключевые аспекты развёртывания микросервисов и что нужно для этого сделать.
Что такое микросервисы и как они работают?
Как уже было сказано, микросервисы появились как ответ на рост сложности и объёма приложений — они позволяют разбивать функциональность на независимо развёртываемые сервисы.
Термин «микросервисы» был введён в широкий обиход такими специалистами, как Мартин Фаулер и Джеймс Льюис, которые официально представили его в статье в блоге в 2014 году. В своей работе они определили ключевые принципы и характеристики: необходимость независимо развёртываемых сервисов, децентрализованное управление данными и технологическая нейтральность.
С тех пор микросервисы стали одним из основных архитектурных решений, которому способствовало развитие технологий контейнеризации, в частности Docker, инструментов оркестрации — Kubernetes, а также платформ бессерверных вычислений. Но как именно работают микросервисы?
Как работают микросервисы?
В основе микросервисной архитектуры лежит разбиение крупного приложения на небольшие, чётко разграниченные сервисы, каждый из которых отвечает за конкретную бизнес-функцию. Эти сервисы взаимодействуют друг с другом по сети — как правило, через REST API, gRPC или брокеры сообщений, например RabbitMQ или Apache Kafka.
Согласно определению Мартина Фаулера и Джеймса Льюиса, каждому микросервису присущи четыре ключевые характеристики:
- Единственная ответственность: каждый микросервис выполняет одну конкретную задачу или функцию, что обеспечивает специализацию и снижает сложность системы.
- Независимость: Микросервисы можно разрабатывать, развёртывать и масштабировать независимо друг от друга — это даёт гибкость и устойчивость к сбоям.
- Децентрализованное управление данными: У каждого микросервиса, как правило, есть собственная база данных — единая централизованная БД не нужна.
- Технологическая независимость: Команды выбирают оптимальный стек для каждого сервиса, не привязываясь к решениям других команд.
Этот подход противопоставляется традиционной монолитной архитектуре, в которой все компоненты приложения тесно связаны и образуют единый цельный модуль.
Ключевые этапы развёртывания микросервисов
Микросервисная архитектура даёт ряд ощутимых преимуществ: высокую масштабируемость, гибкость, эффективность, изоляцию отказов и многое другое. Но чтобы всё это работало, нужно уметь грамотно развёртывать микросервисы и заранее тщательно всё спланировать.
Именно поэтому важно разбираться в ключевых концепциях, этапах и лучших практиках развёртывания. Разберём каждый этап подробнее.
Планирование и подготовка к развёртыванию микросервисов
Любое качественное решение требует планирования. Развёртывание микросервисов — не исключение: здесь без чёткого плана и терпения не обойтись. Важно придерживаться проверенных практик и заблаговременно подготовить всё необходимое.
Как уже говорилось, одним из ключевых принципов микросервисной архитектуры является принцип единственной ответственности. Если каждый микросервис отвечает ровно за одну функцию, команда может разрабатывать, развёртывать и масштабировать сервисы независимо друг от друга.
Этот принцип дополняет принцип слабой связанности. Он означает, что каждый сервис работает самостоятельно и минимально зависит от других. Благодаря этому изменения в одном сервисе не затрагивают остальные, что позволяет масштабировать их независимо.
Это снижает риск каскадных отказов, когда сбой в одном месте системы запускает цепную реакцию и приводит к падению всего сервиса.
Ещё одна важная практика — выделять отдельное хранилище данных для каждого сервиса. Это продолжение принципа слабой связанности: изолированные данные исключают конфликты и упрощают масштабирование.
Кроме того, потребуются асинхронные паттерны взаимодействия — например, брокеры сообщений. Они позволяют сервисам общаться без прямых зависимостей между собой.
Наконец, необходимо выстроить CI/CD-пайплайны для микросервисов. Они позволяют командам выпускать новые функции и исправления через CI/CD-инструменты такие как Jenkins и GitLab, не нарушая стабильность системы при регулярных релизах.
Теперь, когда мы разобрались с планированием и подготовкой, перейдём к стратегиям развёртывания микросервисов.
Стратегии развёртывания микросервисов
При развёртывании микросервисов выбор стратегии зависит от функции сервиса, трафика, инфраструктуры, опыта команды и бюджета. В целом стратегии развёртывания микросервисов делятся на следующие:
- Один экземпляр сервиса на контейнер: В этом подходе каждый микросервис работает в собственном контейнере, что обеспечивает лучшую изоляцию по сравнению с моделью нескольких экземпляров на одном хосте. Контейнеры упрощают масштабирование и улучшают распределение ресурсов.
- Один экземпляр сервиса на виртуальную машину: Каждый сервис работает в отдельной виртуальной машине (VM), что обеспечивает ещё большую изоляцию, чем контейнеры. Это повышает безопасность и стабильность, но, как правило, увеличивает накладные расходы.
- Поэтапные выпуски: На начальном этапе новые версии микросервиса развёртываются для небольшой группы пользователей, чтобы проверить стабильность перед полным выпуском. Такой подход минимизирует последствия возможных проблем и позволяет быстро откатиться к предыдущей версии.
- Сине-зелёное развёртывание: Метод предполагает два идентичных производственных окружения: одно обслуживает живой трафик, второе используется для тестирования следующего релиза. Сине-зелёное развёртывание позволяет легко откатываться и обновлять сервис без простоев, переключая трафик между окружениями.
- Поступательные выпуски: Стратегия предполагает постепенное распространение обновлений на разные сегменты пользователей или окружения. Как правило, процесс начинается с внутренних окружений и только потом доходит до продакшена. Это ограничивает область влияния возможных проблем и позволяет командам устранять их поэтапно.
- Бессерверное развёртывание: Этот подход опирается на бессерверные платформы, такие как AWS Fargate и Google Cloud Run, которые автоматически управляют инфраструктурой, включая масштабирование и распределение ресурсов. При бессерверном развёртывании не нужно администрировать серверы — можно сосредоточиться непосредственно на разработке микросервисов.
После выбора одной из перечисленных стратегий развёртывания микросервисов потребуется инструмент оркестрации.
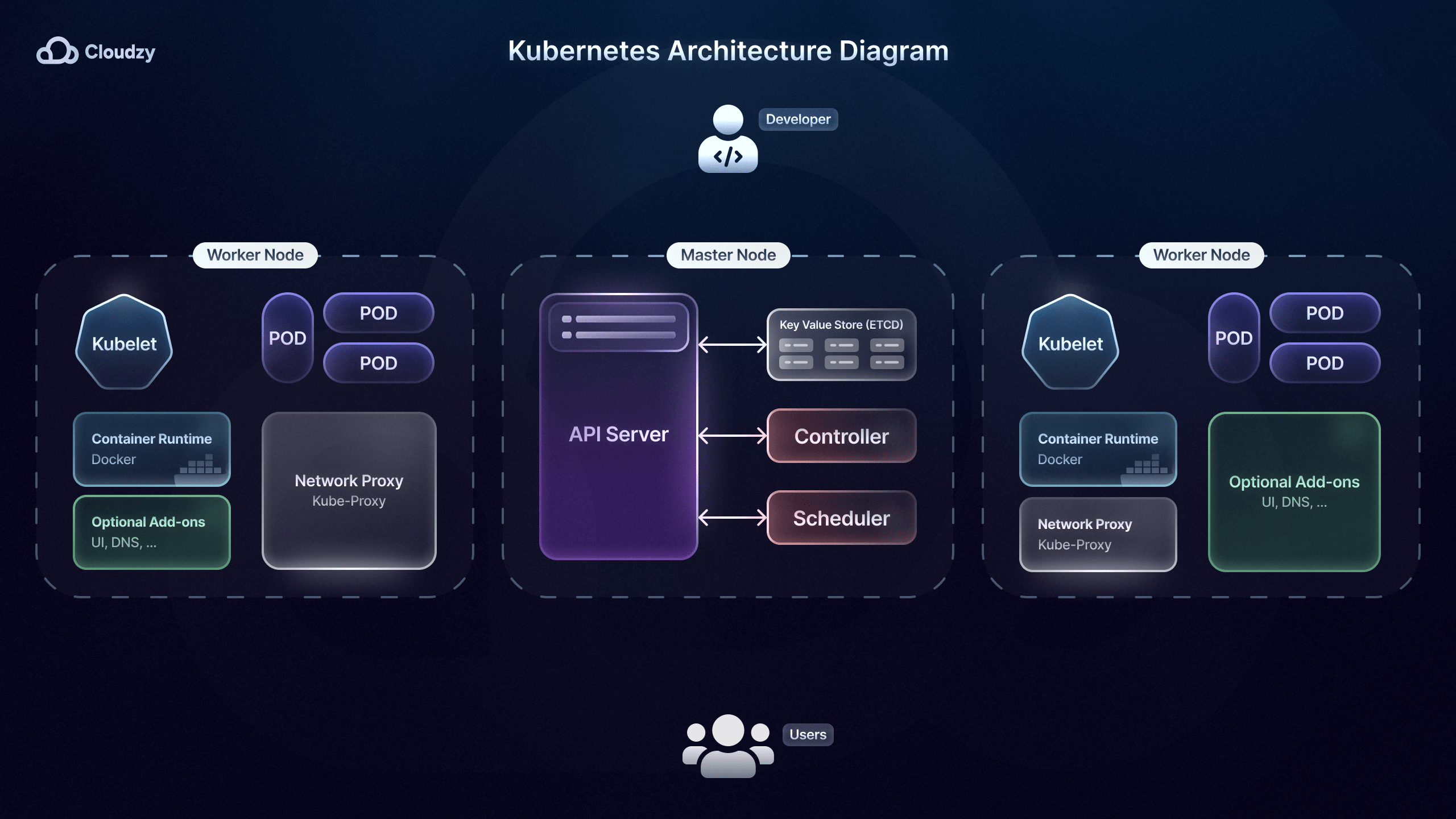
Оркестрация микросервисов
Выбрав стратегию развёртывания, вам понадобится инструмент оркестрации микросервисов. Такие инструменты, как Kubernetes, помогают автоматизировать развёртывание, масштабирование, мониторинг и управление контейнеризованными микросервисами.
Airbnb, например, использует Kubernetes, что позволяет инженерам выкатывать сотни изменений в микросервисы без ручного контроля. Одна из ключевых возможностей таких инструментов, как Kubernetes, — встроенная балансировка нагрузки.
Грамотная балансировка нагрузки распределяет входящий трафик между несколькими экземплярами микросервиса. Это исключает превращение отдельного экземпляра в узкое место и повышает способность системы справляться с пиковыми нагрузками.
Kubernetes играет важную роль в управлении микросервисами благодаря механизму самовосстановления: отказавшие контейнеры автоматически пересоздаются и перезапускаются. The New York Times использует эту возможность, чтобы поддерживать работу своих микросервисов без простоев и ущерба для пользователей.
Кроме того, Kubernetes усиливает безопасность микросервисов, управляя конфигурациями и секретами — такими как учётные данные баз данных или ключи API — через ConfigMaps и Secrets. Это особенно важно для компаний и сервисов, подобных Uber, которые работают с конфиденциальными данными клиентов.
Наконец, инструменты оркестрации вроде Kubernetes особенно полезны для стратегий, предполагающих поступательные обновления и откаты, например поступательные выпуски. Поступательные обновления позволяют развёртывать новые версии микросервисов без прерывания работы сервиса, сохраняя часть экземпляров старой версии активными.
После настройки инструмента оркестрации микросервисов необходимо выстроить и автоматизировать CI/CD-пайплайны для развёртывания микросервисов.
CI/CD Пайплайны для развёртывания микросервисов
Как мы уже упоминали, пайплайны Continuous Integration и Continuous Delivery для микросервисов — ключевой элемент их развёртывания. Часть CD в CI/CD пайплайнах отвечает за автоматическое развёртывание изменений кода в продакшн сразу после того, как они проходят этапы тестирования и интеграции.
Затем в работу вступает CD часть CI/CD пайплайнов: как только изменения кода проходят этапы тестирования и интеграции, сервис развёртывается в инструмент оркестрации микросервисов — например, в кластер Kubernetes.
При этом этапы тестирования и интеграции полностью автоматизированы: CI/CD пайплайны включают модульные тесты, интеграционные тесты и сквозные тесты (end-to-end).
Это позволяет командам проверять обновления на каждом этапе, не нарушая стабильность системы. Если в изменениях кода обнаруживаются проблемы — несмотря на многоуровневое тестирование — автоматический откат вернёт систему к предыдущей стабильной версии.
Наконец, внедрение CI/CD пайплайнов для микросервисов в соответствии с лучшими практиками позволяет командам ускорить разработку, снизить количество ручных ошибок и поддерживать высокое качество кода.
Многие компании — Spotify, Expedia, iRobot, Lufthansa, Pandora и другие — используют CI/CD пайплайны для микросервисов с помощью таких инструментов, как CircleCI, AWS CodePipeline и GitLab. Это позволяет им автоматизировать процессы развёртывания, поддерживать стабильное качество кода и быстро выпускать новые функции, не жертвуя надёжностью системы.
Паттерны взаимодействия микросервисов
То, как микросервисы взаимодействуют друг с другом, напрямую зависит от функциональности, общей архитектуры, требований к масштабированию и надёжности вашей системы. Как правило, выделяют два основных типа паттернов взаимодействия микросервисов: синхронные и асинхронные паттерны взаимодействия микросервисов.
В синхронных паттернах взаимодействия микросервисы общаются в режиме реального времени: сервис отправляет запрос и ждёт ответа, прежде чем продолжить работу. Наиболее распространённые синхронные паттерны взаимодействия микросервисов: REST (передача репрезентативного состояния) API, gRPC (удаленный вызов процедур Google), и GraphQL.
Такие паттерны взаимодействия, как правило, применяются в отраслях и компаниях, где требуется обработка данных в реальном времени и немедленный отклик. Финансы, здравоохранение, электронная коммерция — в этих сферах синхронные паттерны обеспечивают мгновенное выполнение транзакций, получение данных и пользовательских взаимодействий, сохраняя отзывчивость интерфейса.
Вместе с тем синхронные паттерны взаимодействия микросервисов, при всех своих преимуществах — таких как отклик в реальном времени и простота реализации — имеют и недостатки: из-за тесной связанности сервисов могут возникать узкие места, снижается масштабируемость под высокой нагрузкой, увеличивается время отклика и растут задержки в периоды пиковой нагрузки.
Асинхронные паттерны взаимодействия, напротив, лучше подходят для микросервисов, поскольку основаны на принципе слабой связанности (Loose Coupling), который мы рассматривали ранее.
Этот тип паттерна разделяет сервисы, позволяя им обмениваться сообщениями через брокер — например, Kafka или RabbitMQ. Сообщения отправляются в очередь, которая выступает буфером: сервисы взаимодействуют независимо, не дожидаясь ответа, как это происходит в синхронных паттернах. Буфер позволяет другим сервисам обрабатывать сообщения в удобном темпе, а отправителю — продолжать работу, не ожидая получателя.
Асинхронный паттерн взаимодействия микросервисов не только обеспечивает слабую связанность при развёртывании, но и даёт тот же отклик в реальном времени, что и синхронные паттерны.
Это достигается за счёт событийно-ориентированной архитектуры (event-driven): сервисы взаимодействуют, генерируя события при наступлении определённых действий. Другие сервисы подписываются на эти события и реагируют соответственно. Такой подход позволяет строить высокоотзывчивые системы, реагирующие на изменения в реальном времени без прямой связанности между сервисами.
Кроме того, в асинхронных Публикация-подписка (Pub/Sub) В паттернах взаимодействия микросервисов сервисы (публикаторы) отправляют сообщения в топик, а другие сервисы (подписчики) слушают этот топик и получают обновления. Модель поддерживает несколько подписчиков и позволяет одновременно рассылать сообщения множеству сервисов.
Наконец, как и событийно-ориентированные паттерны, асинхронный паттерн хореографической саги в паттернах взаимодействия микросервисов также использует события для общения между сервисами. Отличие в том, что здесь действует строгий порядок: каждое событие запускает следующий шаг и активирует конкретный сервис.
Разница с событийно-ориентированными паттернами в том, что там нет фиксированной последовательности или рабочего процесса: на событие могут реагировать сразу несколько сервисов, тогда как в хореографической саге задан строгий порядок выполнения шагов.
Выбор асинхронного паттерна взаимодействия микросервисов зависит от задачи и общего назначения ваших сервисов. Очереди сообщений, например RabbitMQ и Amazon SQS, как правило применяются для планирования задач, распределения нагрузки, а также в электронной коммерции — для обработки заказов и систем уведомлений.
Событийно-ориентированные брокеры сообщений, такие как Apache Kafka и AWS EventBridge, обычно используются для обработки крупных потоков событий в реальном времени и маршрутизации событий между микросервисами — в частности, в финансовых сервисах и средах AWS.
Брокеры сообщений по модели «Публикация-Подписка» (Pub/Sub) — например Google Cloud Pub/Sub и Redis Streams — как правило применяются для масштабируемого обмена сообщениями в распределённых системах: аналитики в реальном времени, приёма событий, push-уведомлений и чат-приложений.
Наконец, брокеры сообщений на основе хореографической саги в основном используются для обработки заказов в электронной коммерции, систем бронирования путешествий и других сценариев, где сложные многошаговые транзакции требуют координации между несколькими сервисами без единого центра управления.
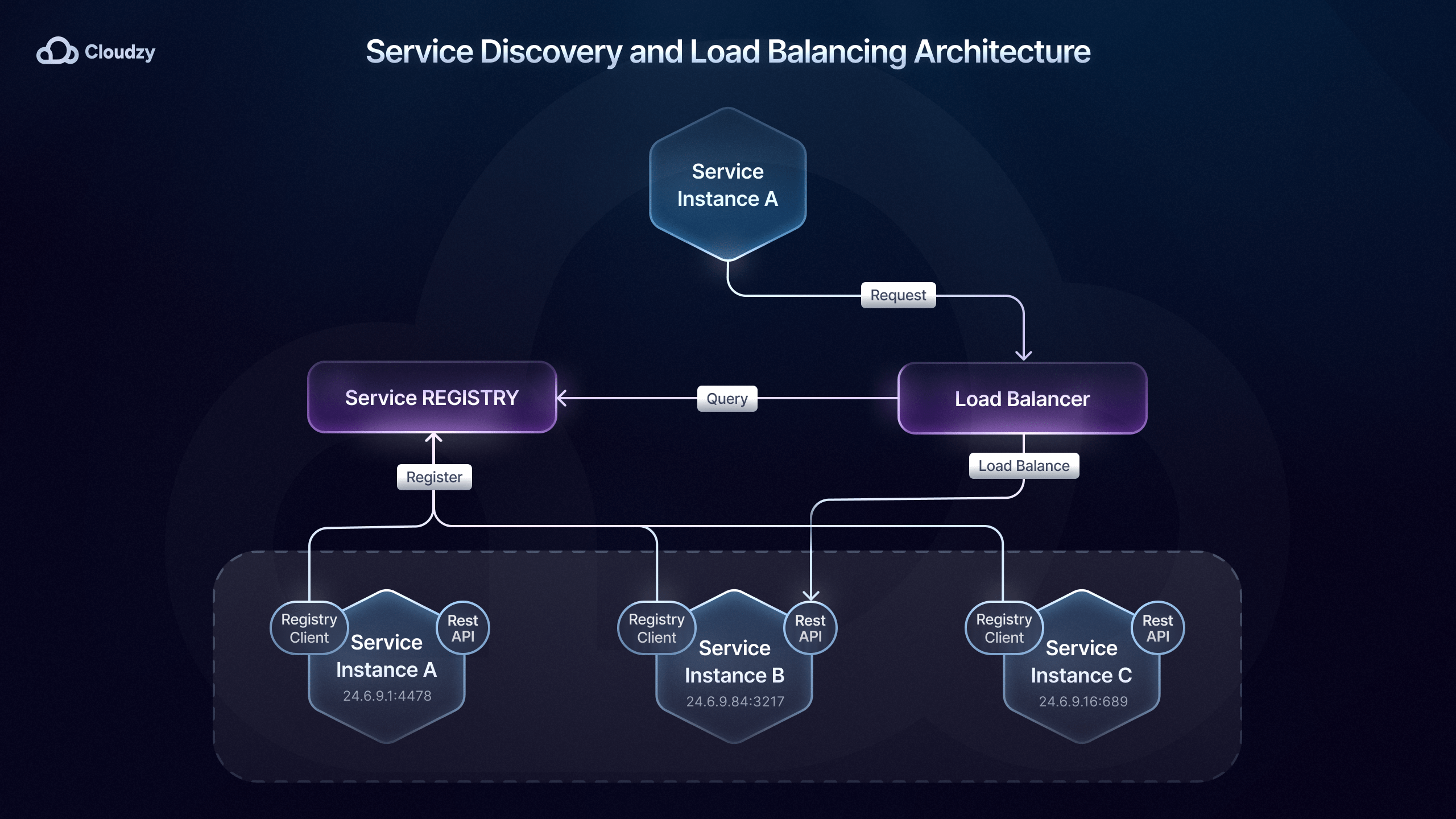
Обнаружение сервисов в микросервисной архитектуре
После того как паттерн взаимодействия выбран и реализован, нужно убедиться, что сервисы вообще способны находить друг друга. Как упоминалось ранее, инструменты оркестрации микросервисов, например Kubernetes, играют здесь ключевую роль.
Это достигается за счёт встроенного обнаружения сервисов в Kubernetes DNS: система динамически обновляет IP-адреса и записи DNS по мере того, как сервисы масштабируются или меняют расположение внутри кластера.
Такой подход к обнаружению сервисов называется серверным: ответственность за маршрутизацию делегируется балансировщику нагрузки, который опрашивает реестр и направляет трафик к нужному экземпляру.
Помимо этого, существует клиентский способ обнаружения сервисов: сам сервис или шлюз API обращается к реестру сервисов, например Consul или Eureka, чтобы найти доступные экземпляры.
Выбор между клиентским и серверным обнаружением сервисов зависит от требований к системе и её масштаба.
При клиентском обнаружении сервисов клиент полностью контролирует, с каким экземпляром взаимодействовать. Это даёт больше гибкости в настройке и упрощает архитектуру: централизованный сервис обнаружения не нужен.
Например, в микросервисной инфраструктуре Netflix применяется клиентское обнаружение сервисов с Eureka и Ribbon для балансировки нагрузки: клиент сам выбирает оптимальный экземпляр по таким критериям, как задержка и загрузка сервера.
Тем не менее серверное обнаружение сервисов лучше подходит для крупных сред: централизованный сервис обнаружения повышает эффективность и обеспечивает согласованную балансировку нагрузки в распределённой системе.
Серверные решения для обнаружения сервисов — Kubernetes, AWS Elastic Load Balancing, шлюзы API (Kong, NGINX и другие) — эффективно маршрутизируют трафик и поддерживают высокую доступность. Их используют такие компании, как Airbnb, Pinterest, Expedia, Lyft и другие.
Безопасность микросервисов
Монолитная архитектура уступает MSA почти по всем параметрам, однако в одном она традиционно имела преимущество — в безопасности. Поскольку микросервисы строятся на принципе слабой связанности и распределены по своей природе, единую общую меру защиты применить невозможно.
Каждый сервис необходимо защищать отдельно, а значит, нужны дополнительные меры: поверхность атаки в микросервисной архитектуре значительно больше. Для этого, как несложно догадаться, широко применяются стандарты OAuth2 и JSON Web Tokens (JWT) — для аутентификации и авторизации.
Кроме того, для управления безопасностью микросервисов часто используется шлюз API: он применяет аутентификацию и авторизацию на точке входа. Шлюзы API также могут реализовывать ограничение частоты запросов, логирование и мониторинг, обеспечивая дополнительные уровни защиты.
Однако эти меры закрывают только основную точку входа. Для защиты межсервисного взаимодействия необходимы дополнительные меры безопасности.
Именно здесь в игру вступают сервисные сети: они добавляют сетевой уровень безопасности для микросервисов, шифруют трафик между сервисами и применяют такие политики, как mutual TLS. По сути, сервисные сети обеспечивают сквозное шифрование, которое существенно повышает защищённость микросервисной архитектуры.
Масштабирование микросервисов
Одно из главных преимуществ MSA — и именно то, ради чего она пришла на смену монолитной архитектуре — это высокая масштабируемость. Как правило, масштабирование микросервисов происходит двумя способами: вертикальным и горизонтальным.
Вертикальное масштабирование микросервисов (scaling up) — это добавление ресурсов, например CPU или памяти, к существующему инстансу. Горизонтальное масштабирование (scaling out), напротив, распределяет нагрузку и увеличивает общую ёмкость.
С точки зрения реализации вертикальное масштабирование проще: достаточно изменить один инстанс — перейти на более мощный сервер, увеличить объём памяти или вычислительную мощность в облачном инстансе, либо добавить дополнительное хранилище.
Этот тип масштабирования применяется там, где рост RAM или мощности CPU напрямую улучшает производительность запросов и обработку данных — например, в сервисах, отвечающих за кэширование в памяти.
При этом, несмотря на простоту и мгновенный прирост производительности, у вертикального масштабирования есть ограничения. Его потолок определяется физическими характеристиками сервера, поэтому в какой-то момент придётся переходить к горизонтальному масштабированию.
Кроме того, вертикальное масштабирование обходится дорого: более мощное железо и крупные инстансы стоят значительно больше. И наконец, если масштабированный инстанс выходит из строя, сервис полностью останавливается — дополнительных инстансов для обработки нагрузки просто нет.
При горизонтальном масштабировании микросервисов вместо наращивания ресурсов одного инстанса вы разворачиваете новые инстансы того же сервиса. Каждый из них работает независимо, но все они обслуживают один и тот же сервис и берут на себя часть общей нагрузки.
В отличие от вертикального, горизонтальное масштабирование практически не имеет предела: можно добавлять столько инстансов, сколько нужно для обработки растущей нагрузки и пиков трафика.
Кроме того, при наличии нескольких инстансов отказ одного из них не влечёт за собой остановку всего сервиса — остальные инстансы продолжают обрабатывать запросы. И ещё один плюс: в долгосрочной перспективе горизонтальное масштабирование значительно выгоднее, так как несколько небольших и дешёвых инстансов в сумме дают надёжную и мощную инфраструктуру.
Вместе с тем горизонтальное масштабирование и увеличение числа инстансов требуют дополнительных балансировщиков нагрузки, механизмов обнаружения сервисов и инструментов оркестрации, что существенно усложняет всю микросервисную архитектуру.
Горизонтальное масштабирование лучше подходит для веб-сервисов и приложений — например, платформ электронной коммерции или социальных сетей, которые сталкиваются с нестабильным трафиком и высоким объёмом запросов.
При этом речь не идёт о выборе одного из двух подходов: оба типа масштабирования поддерживаются в микросервисах и в большинстве случаев используются вместе. Как правило, небольшие команды начинают с вертикального масштабирования — оно проще в реализации и управлении. Но по мере роста приложения подключается горизонтальное, чтобы справляться с возрастающей нагрузкой.
Наконец, облачные платформы предлагают сервисы автомасштабирования, которые автоматически добавляют или убирают инстансы в зависимости от текущего спроса. Это значительно упрощает баланс между вертикальным и горизонтальным масштабированием.
Мониторинг микросервисов
На этом этапе развёртывание микросервисов практически завершено. Остаётся последнее: убедиться, что всё работает стабильно и предсказуемо. Именно здесь пригодятся инструменты мониторинга микросервисов — такие как Prometheus и Grafana .
Эти инструменты предоставляют данные о метриках сервисов в реальном времени, позволяя командам отслеживать использование ресурсов, задержки и частоту ошибок. Помимо этого, они поддерживают распределённую трассировку (Jaeger, Zipkin и другие), которая помогает визуализировать прохождение запросов через сервисы и незаменима при диагностике проблем.
Наконец, поскольку сбои в распределённой архитектуре микросервисов могут быстро распространяться по всей системе, агрегация логов становится обязательной практикой мониторинга. Централизованный сбор логов и настройка оповещений в реальном времени позволяют замечать проблемы заранее и устранять их до того, как они затронут пользователей.
Заключение
Мир микросервисов непрост для понимания, однако знание ключевых принципов и этапов развёртывания значительно упрощает весь процесс. К тому же с каждым годом появляется всё больше инструментов с расширенными возможностями, и работать с микросервисами становится всё проще.
Часто задаваемые вопросы
Какие стратегии развёртывания обычно используются для микросервисов?
Существует немало подходов к развёртыванию микросервисов, но наиболее распространены: один инстанс сервиса на контейнер, поэтапные релизы, сине-зелёное развёртывание и бессерверное развёртывание. Каждый из них предлагает разный уровень изоляции, гибкости и масштабируемости.
Какую роль играет Kubernetes в оркестрации микросервисов?
Микросервисы зависят от инструментов оркестрации, таких как Kubernetes, которые автоматизируют развёртывание, масштабирование и управление контейнеризованными сервисами. Такие инструменты обеспечивают балансировку нагрузки, автомасштабирование и самовосстановление, что делает микросервисную архитектуру отказоустойчивой и эффективной.
Как обеспечить безопасность в микросервисной среде?
Из-за распределённой природы микросервисов обеспечить их безопасность сложнее, чем в монолитной архитектуре. Безопасность микросервисов включает аутентификацию и авторизацию запросов, шифрование межсервисного взаимодействия, а также использование шлюзов API и сервисных сеток вроде Istio для централизованного управления безопасностью.


