
Выбор GPU VPS может поставить в тупик, когда перед вами таблица спецификаций, полная цифр. Количество ядер варьируется от 2 560 до 21 760 — но что это означает на практике?
CUDA-ядро — это блок параллельной обработки внутри GPU NVIDIA GPU, который одновременно выполняет тысячи вычислений. На нём держится всё: от обучения AI-моделей до 3D-рендеринга. В этом руководстве разобрано, как они устроены, чем отличаются от ядер CPU и Tensor, и какое количество ядер подойдёт для ваших задач без лишних затрат.
Что такое ядра CUDA?

CUDA-ядра — это отдельные вычислительные блоки внутри GPU NVIDIA GPU, которые выполняют инструкции параллельно. В основе технологии CUDA лежит простая идея: представьте каждый такой блок как небольшого исполнителя, который одновременно с другими решает свою часть общей задачи.
NVIDIA представила CUDA (Compute Unified Device Architecture) в 2006 году, чтобы использовать вычислительную мощность GPU за пределами графики. Подробные технические сведения содержатся в официальной документации CUDA . Каждый блок выполняет базовые арифметические операции над числами с плавающей точкой — именно то, что нужно для повторяющихся вычислений.
Современные GPU NVIDIA GPU содержат тысячи таких блоков на одном чипе. Потребительские GPU последнего поколения насчитывают более 21 000 ядер, тогда как GPU для дата-центров на архитектуре Hopper — до 16 896. Все эти блоки работают совместно через потоковые мультипроцессоры (SM).
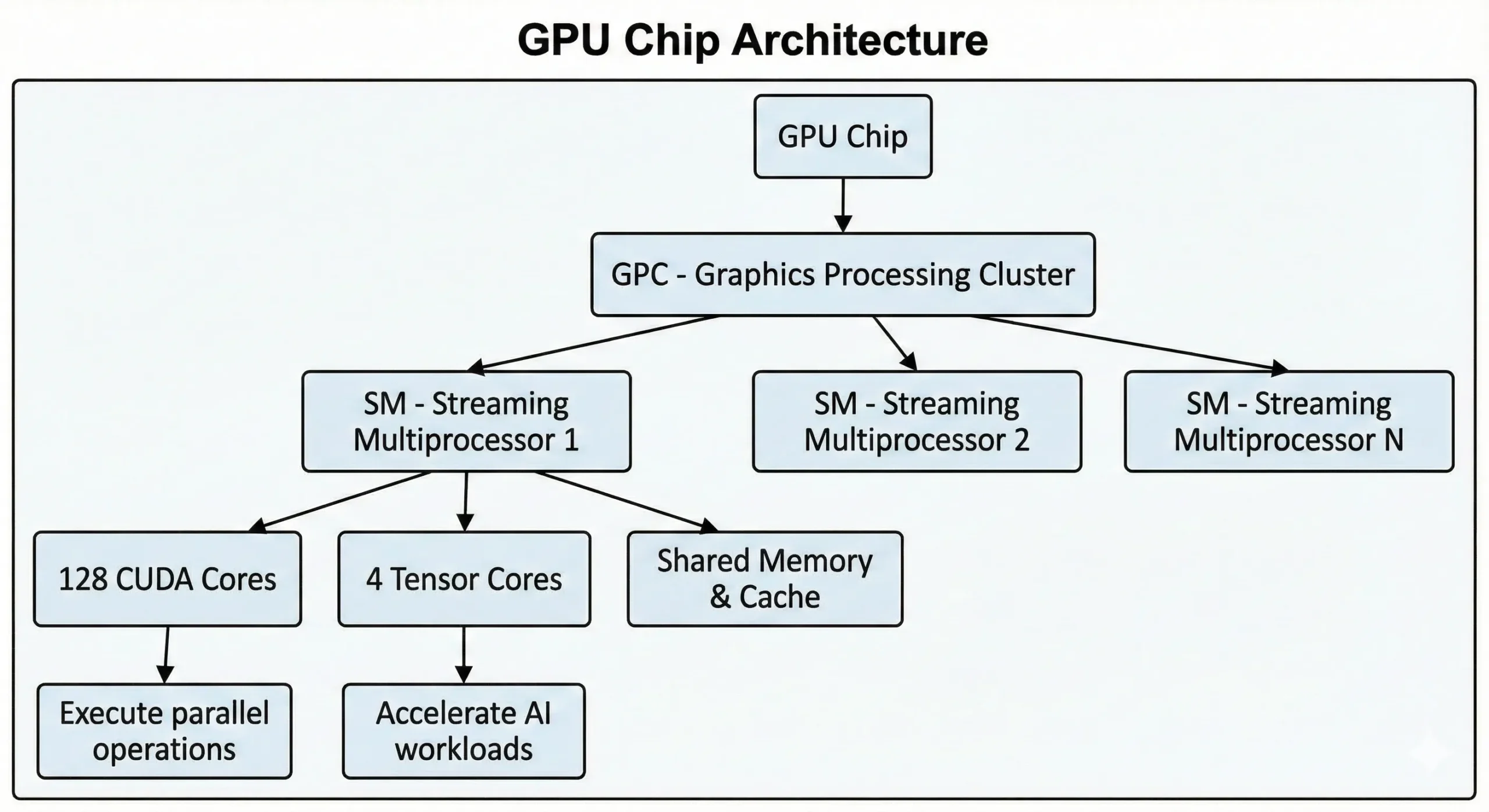
Блоки выполняют операции по модели SIMT (Single Instruction, Multiple Threads) с помощью параллельных вычислений. Одна инструкция применяется сразу ко множеству точек данных. При обучении нейронных сетей или рендеринге 3D-сцен возникают тысячи однотипных операций. GPU разбивает эту работу на параллельные потоки и выполняет их одновременно, а не последовательно.
CUDA-ядра против ядер CPU: в чём разница?

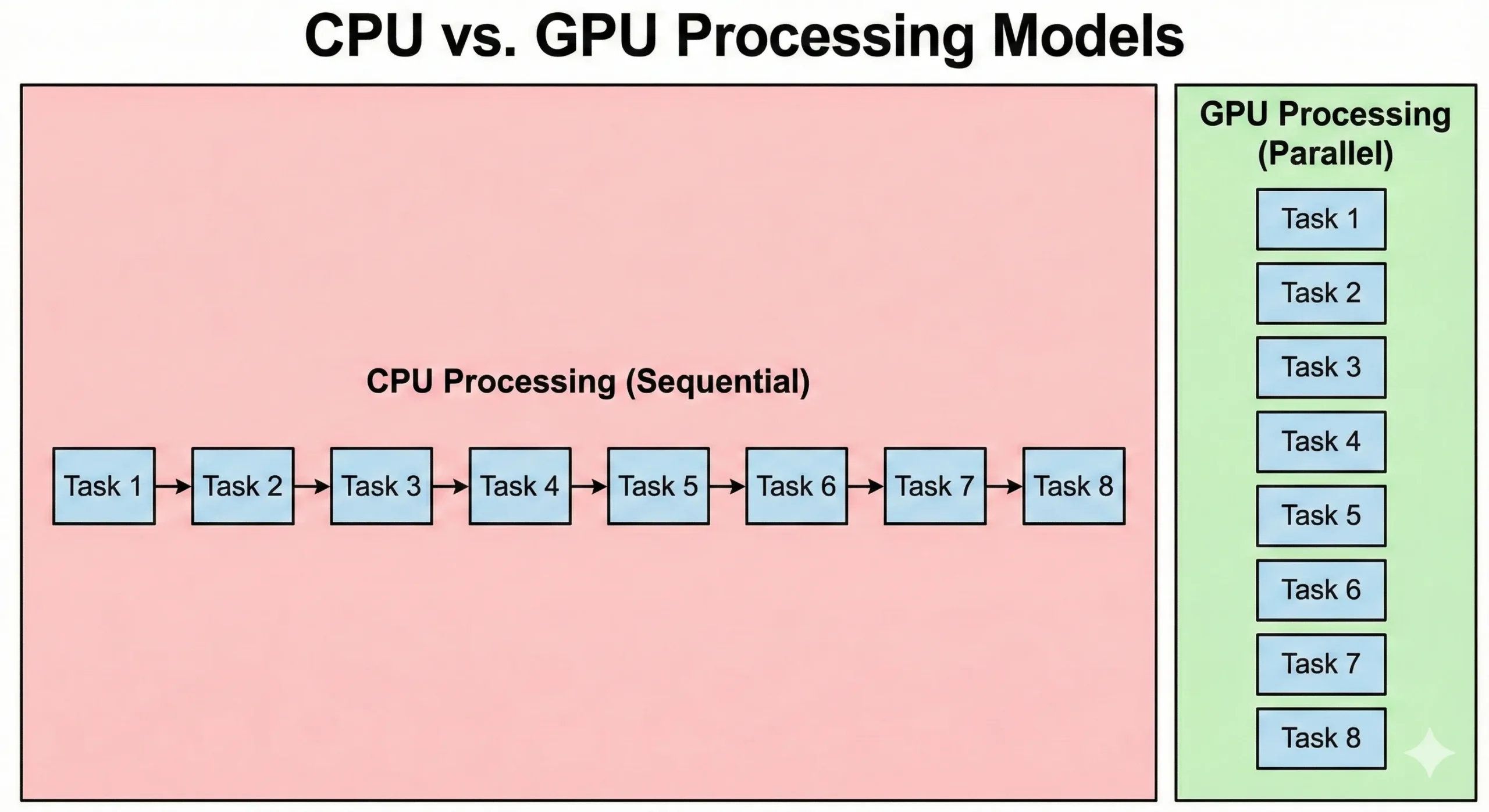
CPU CPU и GPU GPU решают задачи принципиально по-разному. Современный серверный CPU CPU может иметь от 8 до 128+ ядер с высокой тактовой частотой. Такие процессоры хорошо справляются с последовательными операциями, где каждый шаг зависит от результата предыдущего. Они эффективно обрабатывают сложную логику и ветвления.
GPU GPU устроены иначе. В них тысячи более простых CUDA-ядер с меньшей тактовой частотой. Этот недостаток компенсируется параллелизмом. Когда 16 000 ядер работают вместе, суммарная пропускная способность превышает возможности обычного CPU CPU.
CPU CPU выполняют код операционной системы и сложную логику приложений. GPU GPU ориентированы на пропускную способность, однако накладные расходы на запуск задач и синхронизацию увеличивают задержку. Параллельная графическая обработка рассчитана на перемещение больших объёмов данных. GPU дольше стартуют, но обрабатывают крупные наборы данных быстрее, чем CPU.
| Характеристика | Ядра CPU CPU | CUDA ядра |
| Количество на чип | 4-128+ ядер | 2 560-21 760 ядер |
| Тактовая частота | 3,0-5,5 GHz | 1.4–2.5 GHz |
| Стиль обработки | Последовательное выполнение сложных инструкций | Параллельное выполнение простых инструкций |
| Подходит для | Операционные системы, однопоточные задачи | Матричные вычисления, параллельная обработка данных |
| Задержка | Низкая (микросекунды) | Выше (накладные расходы на запуск) |
| Архитектура | Универсальное применение | Специализация на повторяющихся вычислениях |
Технологии Virtual GPU (vGPU) и Multi-Instance GPU (MIG) управляют разделением ресурсов и планированием задач, распределяя процессоры между несколькими пользователями. Это позволяет командам максимально загрузить оборудование: через разделение по времени или выделенные аппаратные инстансы — в зависимости от конфигурации.
Обучение нейронных сетей требует миллиардов матричных умножений. GPU с 10 000 ядрами не выполняет 10 000 операций одновременно в буквальном смысле — он управляет тысячами параллельных потоков, сгруппированных в «варпы», чтобы максимизировать пропускную способность. Именно такой масштаб параллелизма делает эти устройства обязательной темой для AI-разработчиков.
CUDA Cores vs Tensor Cores: в чём разница

NVIDIA GPU содержит два типа специализированных блоков, работающих совместно: стандартные CUDA cores и Tensor cores. Это не конкурирующие технологии — каждая из них решает свою часть задачи.
Стандартные блоки — это универсальные параллельные процессоры, выполняющие вычисления FP32 и FP64, целочисленную арифметику и координатные преобразования. Эта базовая технология CUDA лежит в основе вычислений на GPU и охватывает всё: от физических симуляций до предобработки данных — без специализированного ускорения.
Tensor cores — специализированные блоки, созданные исключительно для матричного умножения и задач AI. Впервые представленные в архитектуре Volta от NVIDIA (2017), они оптимизированы для вычислений с точностью FP16 и TF32. Последнее поколение поддерживает FP8 для ещё более быстрого AI-инференса.
| Характеристика | CUDA ядра | Tensor Cores |
| Назначение | Параллельные вычисления общего назначения | Матричное умножение для AI |
| Точность | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Скорость для AI | 1x (базовый уровень) | В 2–10 раз быстрее CUDA cores |
| Сценарии использования | Предобработка данных, классическое машинное обучение | Обучение и инференс глубоких нейронных сетей |
| Доступность | Все NVIDIA GPUs | RTX 20 серии и новее, серверные GPUs |
Современные GPUs сочетают оба типа ядер. RTX 5090 включает 21 760 стандартных ядер и 680 Tensor-ядер пятого поколения. H100 объединяет 16 896 стандартных ядер с 528 Tensor-ядрами четвёртого поколения для ускорения глубокого обучения.
При обучении нейронных сетей Tensor-ядра берут на себя основную нагрузку во время прямого и обратного проходов через модель. Стандартные ядра управляют загрузкой данных, предобработкой, вычислением функции потерь и обновлением оптимизатора. Оба типа работают совместно: Tensor-ядра ускоряют вычислительно интенсивные операции.
Для классических алгоритмов машинного обучения - таких как случайные леса или градиентный бустинг - стандартные ядра справляются самостоятельно, поскольку эти алгоритмы не используют паттерны матричного умножения, которые ускоряют Tensor-ядра. Но для трансформеров и свёрточных нейронных сетей Tensor-ядра дают значительный прирост скорости.
Для чего используются CUDA-ядра?

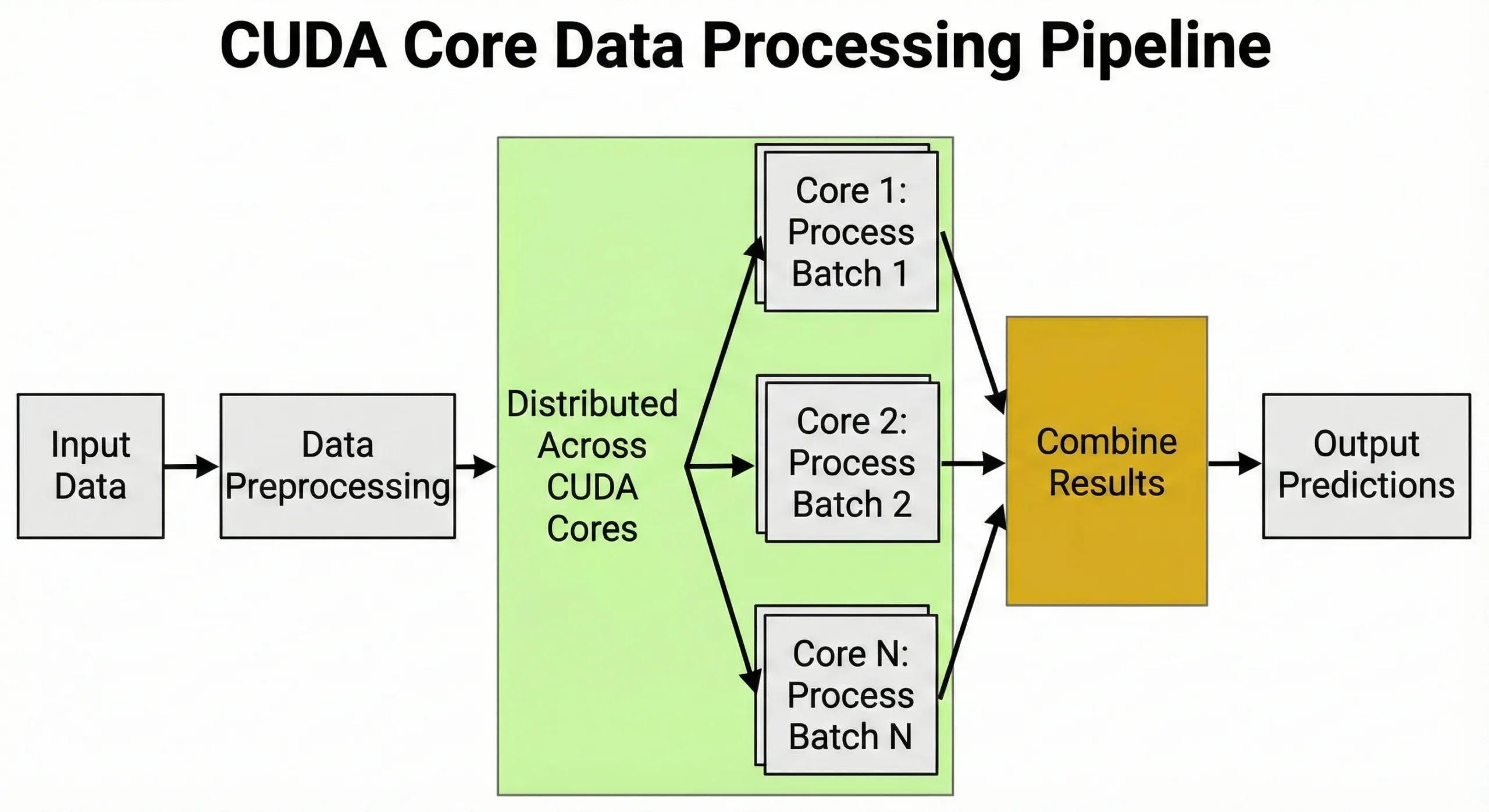
CUDA-ядра выполняют задачи, требующие одновременного проведения большого числа однотипных вычислений. Любые операции с матрицами или повторяющиеся числовые вычисления выигрывают от их архитектуры.
ИИ и приложения машинного обучения
Глубокое обучение строится на матричных умножениях при обучении и инференсе. При обучении нейронных сетей каждый прямой проход требует миллионов операций умножения-сложения над весовыми матрицами. Обратное распространение ошибки добавляет ещё столько же операций.
Ядра управляют предобработкой данных: преобразуют изображения в тензоры, нормализуют значения и применяют аугментацию. Способность обрабатывать тысячи задач одновременно - именно это делает GPUs незаменимыми для ИИ.
В процессе обучения они контролируют расписания скорости обучения, вычисление градиентов и обновление состояния оптимизатора.
Для VPS в задачах инференса ИИ - таких как системы рекомендаций или чат-боты - ядра обрабатывают запросы параллельно, одновременно выполняя сотни предсказаний. Наш обзор лучший GPU для AI 2025 охватывает конфигурации, подходящие для моделей разного размера.
16 896 ядер H100 совместно с Tensor-ядрами позволяют обучить модель на 7 миллиардов параметров за недели, а не месяцы. Инференс в реальном времени для чат-ботов, обслуживающих тысячи пользователей, требует сопоставимой мощности параллельного выполнения.
Научные вычисления и исследования
Исследователи применяют эти процессоры для моделирования молекулярной динамики, климатических моделей и анализа геномики. Каждое вычисление независимо, что делает их идеальными для параллельного выполнения. Финансовые организации запускают симуляции методом Монте-Карло с одновременной обработкой миллионов сценариев.
3D-рендеринг и видеопроизводство
Трассировка лучей вычисляет распространение света в 3D-сценах, прослеживая независимые лучи через каждый пиксель. RT-ядра отвечают за обход структур ускорения, тогда как стандартные ядра управляют сэмплированием текстур и освещением. Это распределение задач определяет скорость обработки сцен с миллионами лучей.
NVENC выполняет кодирование в форматы H.264 и H.265, а новейшие архитектуры (Ada Lovelace и Hopper) добавляют аппаратную поддержку AV1. CUDA берёт на себя эффекты, фильтры, масштабирование, шумоподавление, цветовые преобразования и связующие элементы конвейера. Это позволяет движку кодирования работать параллельно с другими процессорами, ускоряя видеопроизводство.
3D-рендеринг в Blender или Maya распределяет миллиарды вычислений шейдеров поверхностей по доступным ядрам. Системы частиц выигрывают от параллелизма, поскольку одновременно симулируют тысячи взаимодействующих частиц. Всё это критически важно для создания высококачественного цифрового контента.
Как CUDA-ядра влияют на производительность GPU

Количество ядер даёт лишь приблизительное представление о возможностях параллельного выполнения задач. Чтобы оценить CUDA-ядра по-настоящему, нужно смотреть глубже: тактовая частота, пропускная способность памяти, эффективность архитектуры и программная оптимизация играют не меньшую роль.
GPU с 10 000 ядрами на частоте 2,0 GHz даёт совсем другой результат, чем та же конфигурация на 1,5 GHz. Более высокая тактовая частота означает, что каждое ядро выполняет больше вычислений в секунду. Новые архитектуры успевают сделать больше за один такт за счёт улучшенного планирования инструкций.
Убедитесь, что устройство загружено постоянно, но помните: nvidia-smi утилизация — это грубая метрика. Она показывает, какой процент времени ядро активно, а не сколько ядер реально задействовано.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderПример вывода: 85%, 92% (85% — время активности, 92% — активность контроллера памяти)
Если GPU показывает 60–70% утилизации, скорее всего, узкое место находится раньше по конвейеру: например, загрузка данных с CPU или слишком маленький размер батча. Впрочем, даже 100% утилизация может вводить в заблуждение, если ядра ограничены пропускной способностью памяти или работают в однопоточном режиме. Чтобы получить реальную картину насыщенности ядер, используйте профилировщики — например, Nsight Systems — и отслеживайте метрики «SM Efficiency» или «SM Active».
Пропускная способность памяти нередко становится узким местом раньше, чем вычислительные ресурсы исчерпаны полностью. Если GPU обрабатывает данные быстрее, чем память их поставляет, ядра простаивают. Модель H100 SXM5 обеспечивает пропускную способность памяти 3,35 TB/s, чтобы питать свои 16 896 ядер. Версия PCIe снижает этот показатель до 2 TB/s.
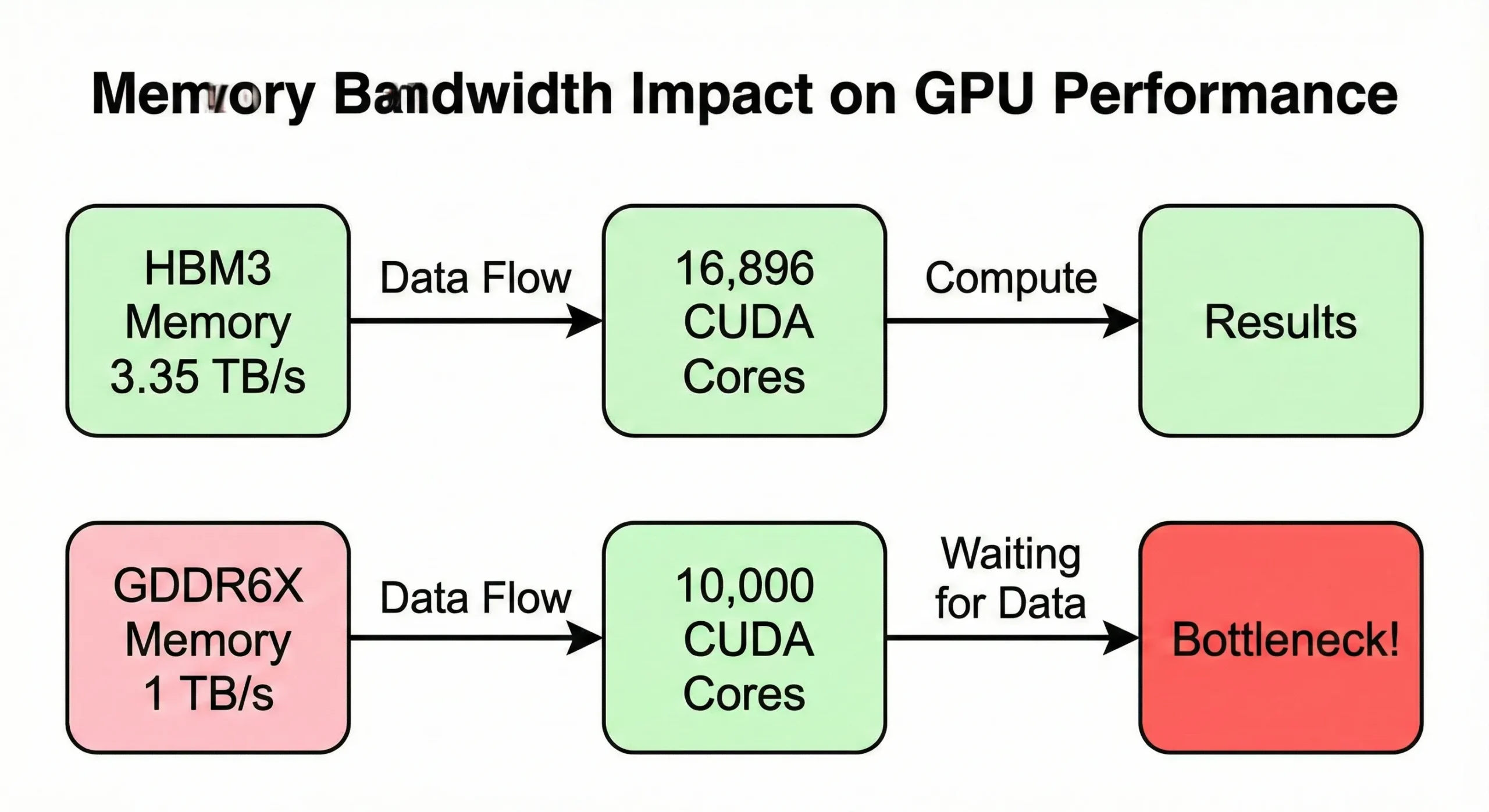
Потребительские GPU с сопоставимым числом ядер, но меньшей пропускной способностью (около 1 TB/s) показывают заметно меньшую реальную скорость на операциях, интенсивно использующих память.
Объём VRAM определяет масштаб решаемых задач. Например, FP16-веса для 70B-моделипри полном обучении требуют ещё больше памяти: нужно учитывать градиенты и состояния оптимизатора. Они нередко утраивают объём занятой памяти, если не применять стратегии выгрузки.
A100 80GB рассчитан на высокопроизводительный инференс и тонкую настройку. RTX 4090 с 24 GB, который обычно ассоциируется с 7B-моделями, при использовании современных техник квантования вроде INT4 способен запускать модели с 30B+ параметров. Однако нехватка VRAM вынуждает передавать данные между CPU и GPU, что полностью уничтожает пропускную способность.
Программная оптимизация определяет, задействует ли ваш код все доступные ядра по-настоящему. Плохо написанные ядра могут использовать лишь малую долю ресурсов. Библиотеки наподобие cuDNN для глубокого обучения и RAPIDS для работы с данными тщательно оптимизированы для максимальной утилизации.
Больше CUDA-ядер — не всегда лучше

Выбрать GPU с максимальным числом ядер кажется логичным, но деньги окажутся потрачены впустую, если ядра опережают остальные компоненты системы или ваша задача просто не масштабируется с количеством ядер.
Первое ограничение создаёт пропускная способность памяти. 21 760 ядер RTX 5090 питает 1 792 GB/s памяти. У более старых GPU с меньшим числом ядер пропускная способность на ядро может быть пропорционально выше.
Разница в архитектурах имеет значение. Новый GPU с 14 000 ядрами на 2,2 GHz обходит старый с 16 000 ядрами на 1,8 GHz благодаря более высокому числу инструкций за такт. Чтобы эффективно задействовать 20 000 ядер, ваш код должен быть правильно распараллелен.
Почему CUDA-ядра важны при выборе GPU VPS

Правильный выбор конфигурации CUDA-ядер GPU для вашего VPS позволяет не переплачивать за неиспользуемые ресурсы и не упираться в узкие места в середине проекта.
80 ГБ памяти H100 справляются с инференсом моделей на 70 млрд параметров при 4-битном квантовании. Однако для полноценного обучения даже 80 ГБ зачастую недостаточно для модели на 34 млрд параметров — с учётом градиентов и состояний оптимизатора. При обучении в FP16 объём памяти резко возрастает, и нередко требуется шардирование по нескольким GPU.
Инференс для предсказаний в реальном времени не требует большого количества ядер, но выигрывает от низкой задержки. Для разработки и прототипирования вполне подходят GPU среднего класса — для тестирования алгоритмов и отладки кода.
RTX 4060 Ti с 4 352 ядрами позволяет тестировать решения без лишних затрат на избыточное железо. Как только подход подтверждён, можно перейти на производственные GPU для полных циклов обучения.
Рендеринг и видеообработка масштабируются с ростом числа ядер — до определённого предела. Рендерер Cycles в Blender эффективно задействует все доступные ресурсы. GPU с 8 000–10 000 ядер рендерит сцены в 2–3 раза быстрее, чем с 4 000.
В Cloudzy мы предлагаем высокопроизводительный GPU VPS хостинг для ресурсоёмких задач. Выберите RTX 5090 или RTX 4090 для быстрого рендеринга и экономичного AI-инференса — или перейдите на A100 для масштабных задач глубокого обучения. Все тарифы работают на сети 40 Gbps с политикой приватности по умолчанию и поддержкой оплаты криптовалютой. Никакой корпоративной бюрократии — только вычислительная мощность.
Обучаете ли вы AI-модели, рендерите 3D-сцены или запускаете научные симуляции — вы сами выбираете количество ядер под свои задачи.
Бюджет имеет значение. A100 с 6 912 ядрами стоит существенно меньше, чем H100 с 16 896. Во многих задачах два A100 дают лучшее соотношение цены и скорости, чем один H100. Точка окупаемости зависит от того, умеет ли ваш код масштабироваться на несколько GPU.
Как выбрать правильное количество CUDA-ядер
Сопоставляйте требования с реальными характеристиками рабочей нагрузки, а не гонитесь за максимальными цифрами.
Начните с профилирования текущей работы. Если вы обучаете модели на локальном железе или облачных инстансах, проверьте метрики утилизации GPU. Если загрузка вашего GPU стабильно держится на уровне 60–70%, ядра не исчерпаны.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Этот простой тест покажет, даёт ли ваш GPU ожидаемую пропускную способность. Сравните результаты с опубликованными бенчмарками для вашей модели GPU.
Апгрейд не поможет. Сначала нужно устранить узкие места — нехватку памяти, пропускной способности или простои CPU. Затем оцените потребности в памяти: рассчитайте размер модели в байтах плюс память под активации.
Прибавьте размер батча, умноженный на выходы слоёв, и добавьте состояния оптимизатора. Всё это должно помещаться в VRAM. Зная необходимый объём памяти, проверьте, какие GPU соответствуют этому порогу.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Учитывайте сроки. Если результаты нужны через несколько часов — платите за больше ядер. Обучение, которое может занять дни, вполне укладывается на менее мощных GPU — просто займёт пропорционально больше времени.
Стоимость в час, умноженная на количество часов, даёт итоговую стоимость — иногда более медленные GPU оказываются дешевле в сумме. Проверяйте эффективность масштабирования с помощью инструментов бенчмаркинга, которые есть во многих фреймворках и показывают изменение пропускной способности.
Если удвоение числа ядер даёт лишь 1,5-кратное ускорение, доплата за них не оправдана. Ищите точку оптимума, где соотношение цены и скорости максимально.
| Тип рабочей нагрузки | Рекомендуемое число ядер | Примеры GPU | Примечания |
| Разработка и отладка моделей | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Быстрая итерация, меньше затрат |
| Небольшие задачи обучения AI (<7B параметров) | 6,000-10,000 | RTX 4090, L40S | Подходит для частных пользователей и небольших компаний |
| Обучение масштабных AI-моделей (7B–70B параметров) | 14,000+ | A100, H100 | Требуется центр обработки данных GPUs |
| Вывод в реальном времени (высокая пропускная способность) | 10,000-16,000 | RTX 5080, L40 | Оптимальное соотношение цены и производительности |
| 3D-рендеринг и видеокодирование | 8,000-12,000 | RTX 4080, RTX 4090 | Растёт вместе с задачами |
| Научные вычисления и HPC | 10,000+ | A100, H100 | Требуется поддержка FP64 |
Популярные VPS GPUs и количество их CUDA-ядер

Разные уровни GPU служат разным сегментам пользователей. Что такое GPUaaS? Это GPU-as-a-Service — модель, при которой провайдеры вроде Cloudzy предоставляют доступ к мощным GPU NVIDIA по запросу, без необходимости покупать и обслуживать физическое оборудование самостоятельно.
| Модель GPU | CUDA ядра | VRAM | Пропускная способность памяти | Архитектура | Лучше всего для |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1 792 ГБ/с | Blackwell | Флагманская рабочая станция для рендеринга в 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1 008 ГБ/с | Ада Лавлейс | AI высокого класса, рендеринг 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3 350 ГБ/с | Hopper | Масштабное обучение AI-моделей |
| H100 PCIe | 14,592 | 80GB HBM2e | 2 000 ГБ/с | Hopper | Корпоративный AI, экономичные датацентры |
| A100 | 6,912 | 40/80ГБ HBM2e | 1 555–2 039 ГБ/с | Ampere | AI среднего класса, проверенная надёжность |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ада Лавлейс | Игры, AI среднего уровня |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ада Лавлейс | Датацентры с разнородными нагрузками |
Потребительские карты RTX (4070, 4080, 4090, 5080, 5090) рассчитаны на геймеров и контент-мейкеров, но хорошо подходят и для AI-разработки. Они обеспечивают высокую скорость на одном GPU по цене ниже, чем у датацентровых карт.
Провайдеры VPS нередко предлагают их пользователям, чувствительным к стоимости. Датацентровые карты (A100, H100, L40) ориентированы на надёжность, ECC-память и масштабирование на несколько GPU. Они рассчитаны на круглосуточную работу и поддерживают расширенные функции.
Multi-Instance GPU (MIG) позволяет разделить один GPU на несколько изолированных экземпляров. A100 по-прежнему востребован, несмотря на появление более новых решений, благодаря сбалансированным характеристикам.
Оптимальное соотношение ядер NVIDIA, объёма памяти и цены делает его надёжным выбором для большинства AI-задач в production. H100 предлагает в 2,4 раза больше ядер, но стоит значительно дороже.
Заключение
Параллельная обработка лежит в основе современного AI, рендеринга и научных вычислений. Понимание того, как GPU взаимодействует с памятью, тактовой частотой и ПО, поможет выбрать правильную конфигурацию VPS.
Большее число ядер даёт результат, только если задача хорошо распараллеливается и остальные компоненты, например пропускная способность памяти, успевают за ним. Слепая погоня за максимальным числом ядер — пустая трата денег, если узкое место находится в другом месте.
Начните с профилирования реальных задач: определите, где теряется время, и подбирайте характеристики GPU именно под эти требования, не переплачивая за лишнюю мощность.
Для большинства AI-проектов оптимальный баланс цены и производительности обеспечивают 6 000–10 000 ядер. Для production-задач с обучением крупных моделей или высоконагруженным инференсом подойдут GPU с 14 000+ ядрами, например H100.
Рендеринг и видеомонтаж эффективно масштабируются до примерно 16 000 ядер, после чего узким местом становится пропускная способность памяти.


