
คุณเปิดหน้า GGUF ของโมเดลยอดนิยมบน Hugging Face และมีไฟล์สิบห้าไฟล์จ้องกลับมา: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0 บวกกับโฟลเดอร์แยกสำหรับ GPTQ, AWQ และ EXL2 ที่การตั้งค่าบิตครึ่งโหล คุณคำนวณคร่าวๆ สำหรับไฟล์ "4-บิต": 4 บิต × 8 พันล้านพารามิเตอร์ ÷ 8 = 4 GB แต่ไฟล์บอกว่า 4.6 GB และเมื่อคุณโหลดมันแล้ว โมเดลใช้หน่วยความจำมากกว่านั้น
ชื่อไฟล์ไม่ใช่สัญญาณรบกวน มันเข้ารหัสข้อมูลที่แท้จริงและเรียนรู้ได้เกี่ยวกับความกว้างบิต รันไทม์ที่โหลดมัน และฮาร์ดแวร์ที่ต้องการ ตารางขนาดที่คุณเคยอ่านบอกคุณว่าโมเดล 70B ต้องการประมาณ 40 GB มีประโยชน์ แต่พวกมันไม่เคยถอดรหัสฟอร์แมตเองหรืออธิบายว่าทำไมโมเดลที่กำลังรันถึงต้องการหน่วยความจำมากกว่าไฟล์บนดิสก์
นี่คือแผน: ถอดรหัสข้อตกลงการตั้งชื่อของ GGUF (ด้วยความกว้างบิตที่แท้จริง ไม่ใช่ค่าที่ระบุไว้) แยกแยะว่าฮาร์ดแวร์ของคุณสามารถรันฟอร์แมตใดในสี่แบบได้จริง และคำนึงถึงต้นทุนหน่วยความจำหนึ่งอย่างที่มองไม่เห็นในขนาดไฟล์ทุกไฟล์ นั่นคือ KV cache เมื่ออ่านจบคุณจะสามารถดูรีโปของโมเดลและคาดเดาได้ว่ามันจะทำงานอย่างไรเมื่อโหลด
TL;DR (สรุปย่อ)
- ระดับการควอนไทซ์ของ GGUF คือความกว้างบิตที่มีผลจริง ไม่ใช่ตัวเลขที่ระบุตรงในชื่อ Q4_K_M อยู่ที่ประมาณ 4.89 บิตต่อน้ำหนัก ซึ่งเป็นเหตุผลที่ไฟล์ "4-บิต" ขนาด 8B อยู่ที่ประมาณ 4.6 GiB แทนที่จะเป็นค่าประมาณ 4-บิตแบบง่ายๆ
- GGUF เป็นตัวเลือกที่พกพาได้มากที่สุด เพราะ llama.cpp สามารถรันมันบน CPU, GPU หรือการตั้งค่าแบบไฮบริดได้ GPTQ, AWQ และ EXL2 เจาะจงกับ GPU และรันไทม์มากกว่า โดยเฉพาะ EXL2 ที่ผูกติดกับเวิร์กโฟลว์ NVIDIA/CUDA
- KV cache แยกออกจากน้ำหนักของโมเดลและเติบโตตามความยาวของบริบท นี่คือเหตุผลที่โมเดลที่โหลดได้อย่างสมบูรณ์ก็ยังสามารถล่มด้วยหน่วยความจำไม่พอเมื่อบทสนทนายาวขึ้น
- เหนือช่วง 5-บิต การสูญเสียคุณภาพมักจะน้อย รอบๆ Q4 การแลกเปลี่ยนยังคงใช้งานได้จริงสำหรับกรณีการใช้งานท้องถิ่นหลายแบบ ต่ำกว่า 4-บิต ต้นทุนด้านคุณภาพจะเห็นได้ชัดขึ้นมาก Q4_K_M ยังคงเป็นค่าเริ่มต้นทั่วไปของชุมชน ในขณะที่ Q5_K_M และ Q6_K ปลอดภัยกว่าเมื่อคุณมีหน่วยความจำเหลือเฟือ
Q4_K_M ในชื่อไฟล์ GGUF หมายความว่าอย่างไร?

ชื่อการควอนไทซ์ GGUF ตามรูปแบบ Q[บิต]_[K]_[S/M/L] ตัวเลขคือ เป้าหมาย บิตต่อน้ำหนัก K หมายความว่ามันคือ "K-quant" ที่จัดเก็บปัจจัยการปรับสเกลต่อบล็อกเล็กๆ ของน้ำหนัก และตัวท้าย S, M หรือ L คือระดับขนาด/คุณภาพ (เล็ก กลาง ใหญ่) เนื่องจาก K-quant จัดเก็บสเกลและค่าต่ำสุดสำหรับทุกบล็อกควบคู่ไปกับน้ำหนัก ที่มีผลจริง ความกว้างบิตสูงกว่าตัวเลขที่ระบุไว้ในชื่อ Q4_K_M อยู่ที่ประมาณ 4.89 บิตต่อน้ำหนัก ไม่ใช่ 4
ช่องว่างนั้นคือคำตอบทั้งหมดของคำถาม "ทำไมไฟล์ 4-บิตของฉันถึงมีขนาด 4.6 GB?" การประมาณแบบง่ายๆ สมมติว่าน้ำหนักทุกตัวมีต้นทุนพอดี 4 บิต ในความเป็นจริง K-quant ใช้บิตเพิ่มเติมต่อบล็อกสำหรับข้อมูลเมตาที่ทำให้การควอนไทซ์บิตต่ำแม่นยำ นั่นคือสเกลและค่าต่ำสุดต่อบล็อกที่ทำให้รันไทม์สามารถสร้างน้ำหนักแต่ละตัวขึ้นใหม่ได้ คูณ 4.89 บิตด้วยน้ำหนัก 8 พันล้านตัว แล้วคุณจะได้ประมาณ 4.58 GiB ซึ่งเป็นสิ่งที่ไฟล์มีน้ำหนักจริงๆ
นี่คือความกว้างบิตที่มีผลจริงและขนาดไฟล์ที่วัดได้ นำมาจาก llama.cpp quantize documentation สำหรับ Llama 3.1 8B เป็นโมเดลอ้างอิง พร้อมกับต้นทุน perplexity ของแต่ละระดับที่วัดในเปเปอร์การประเมินการควอนไทซ์ของ llama.cpp (arXiv:2601.14277) บน Llama-3.1-8B-Instruct:
| ระดับ GGUF | BPW ที่มีผลจริง | ~ขนาดไฟล์ (8B) | Perplexity เทียบกับ F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3.4 GiB | +22% |
| Q3_K_M | 3.95 | ~3.7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4.0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4.4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4.6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5.3 GiB | +1.1% |
| Q6_K | 6.56 | ~6.1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8.0 GiB | +0.1% |
| F16 | 16.00 | ~15.0 GiB | พื้นฐาน |
*ตัวเลข perplexity เป็นค่าเฉพาะสำหรับ Llama-3.1-8B-Instruct จาก arXiv:2601.14277 คอลัมน์ BPW/ขนาดไฟล์และคอลัมน์ perplexity มาจากแหล่งที่มาสองแหล่งที่แตกต่างกันซึ่งวัดแยกกัน ดังนั้นให้อ่านตารางนี้เป็นข้อมูลอ้างอิงเชิงปฏิบัติแบบเทียบเคียงกัน ไม่ใช่การทดสอบเกณฑ์มาตรฐานเดียว ความเสื่อมลงเฉพาะงานนั้นแตกต่างกันไป การให้เหตุผลทางคณิตศาสตร์มักได้รับผลกระทบมากกว่าการให้เหตุผลแบบสามัญสำนึกที่ความกว้างบิตต่ำ แต่รูปแบบโดยรวมยังคงเป็นจริง: 5-บิตขึ้นไปมักจะปลอดภัยกว่า Q4 คือโซนการบีบอัดที่ใช้งานได้จริง และ 3-บิตคือจุดที่การสูญเสียคุณภาพยากที่จะมองข้ามมากขึ้น
ในทางปฏิบัติ: Q4_K_M คือค่าเริ่มต้นที่คนส่วนใหญ่ควรเลือกใช้ Q5_K_M และ Q6_K เป็นตัวเลือกที่เน้นคุณภาพเมื่อคุณมีหน่วยความจำเหลือเฟือ และอะไรก็ตามที่ระดับ Q3_K_S หรือต่ำกว่านั้นเป็นทางเลือกสุดท้ายสำหรับฮาร์ดแวร์ที่ใส่มากกว่านี้ไม่ได้จริงๆ
คุณควรดาวน์โหลดฟอร์แมตการควอนไทซ์แบบไหน: GGUF, GPTQ, AWQ หรือ EXL2?

GGUF พกพาได้มากที่สุดในบรรดาทั้งสี่: มันรันบน CPU, GPU หรือแบบผสมทั้งสองอย่างผ่าน llama.cpp ดังนั้นจึงเป็นตัวเลือกที่ปลอดภัยที่สุดเมื่อคุณไม่แน่ใจว่าฮาร์ดแวร์ของคุณรองรับอะไรได้บ้าง GPTQ, AWQ และ EXL2 เจาะจงกับ GPU และรันไทม์มากกว่า ในทางปฏิบัติ พวกมันพบได้บ่อยที่สุดในการตั้งค่า NVIDIA/CUDA แต่การรองรับ GPTQ และ AWQ อาจแตกต่างกันไปตามตัวโหลดและสแต็กการให้บริการ ตัวอย่างเช่น vLLM แยกการรองรับการควอนไทซ์ตามฮาร์ดแวร์และการใช้งานจริงหากคุณกำลังรันในเครื่องบน Mac การ์ด AMD หรือกล่องที่มีแต่ CPU GGUF ยังคงเป็นคำตอบที่ปลอดภัยที่สุด หากคุณมี GPU ของ NVIDIA และต้องการโทเคนที่เร็วที่สุดเท่าที่จะเป็นไปได้ อีกสามตัวจะเข้ามามีบทบาท
| รูปแบบ | ฮาร์ดแวร์/รันไทม์ | ความเร็ว (เชิงเปรียบเทียบ) | VRAM เทียบกับคู่แข่ง | เหมาะสำหรับ |
|---|---|---|---|---|
| GGUF Q4_K_M | กว้างที่สุด CPU, GPU หรือไฮบริดผ่าน llama.cpp | ปานกลาง | Router ที่ตั้งค่ามาแล้ว | ฮาร์ดแวร์ใดก็ได้ ค่าเริ่มต้นสำหรับใช้งานท้องถิ่น |
| GPTQ 4-bit | มักเน้น CUDA/GPU เป็นหลัก ขึ้นอยู่กับรันไทม์ | เร็ว (ExLlama) | ปานกลาง | เน้น GPU เป็นหลัก เครื่องมือรุ่นเก่า |
| AWQ 4-bit | มักเน้น CUDA/GPU เป็นหลัก ขึ้นอยู่กับรันไทม์ | เร็ว | สูงสุด | การให้บริการแบบ vLLM/TGI โหลดเร็ว |
| EXL2 ~4.9 bpw | เน้น NVIDIA/CUDA เป็นหลัก | เร็วที่สุด | ต่ำ-ปานกลาง | ความเร็วสูงสุดบน NVIDIA |
ข้อควรระวังเกี่ยวกับตารางนั้น: อันดับความเร็วและ VRAM มาจาก การทดสอบเกณฑ์มาตรฐาน oobaboogaซึ่งรันบนฮาร์ดแวร์ยุค 2023/2024 ให้ปฏิบัติต่อลำดับ เชิงเปรียบเทียบ เป็นสิ่งที่ยั่งยืน EXL2 ถูกสร้างมาเพื่อความเร็ว AWQ แลก VRAM กับการโหลดที่รวดเร็ว GGUF ยังคงเบาและพกพาได้ แต่อย่าอ่านตัวเลขโทเคนต่อวินาทีแบบสัมบูรณ์ดั้งเดิมว่าเป็นปัจจุบัน GPU ปี 2026 จะให้ปริมาณงานดิบที่แตกต่างกันมาก แต่ลำดับความสำคัญคือสิ่งที่ยังคงใช้ได้ต่อไป
ดังนั้นกฎการตัดสินใจที่ได้จากสิ่งนี้คือ: ถ้าคุณมีการ์ด NVIDIA และให้ความสำคัญกับความเร็วมากที่สุด ให้เลือก EXL2 ถ้าคุณต้องการค่าเริ่มต้นสำหรับใช้งานท้องถิ่นที่ปลอดภัยที่สุดในฮาร์ดแวร์ที่หลากหลาย ให้เลือก GGUF AWQ และ GPTQ มีความสำคัญส่วนใหญ่เมื่อสแต็กการให้บริการเฉพาะ (vLLM, TGI) หรือเครื่องมือที่มีอยู่ผลักดันให้คุณไปทางนั้น
ทำไม LLM ท้องถิ่นถึงใช้หน่วยความจำมากกว่าขนาดไฟล์?
ขนาดไฟล์คือเพียงน้ำหนักของโมเดลเท่านั้น ในขณะรันไทม์คุณยังต้องจ่ายสำหรับ KV cache (สถานะความสนใจสำหรับทุกโทเคนในหน้าต่างบริบทของคุณ) แอกทิเวชัน (คณิตศาสตร์ระหว่างกลางของการส่งไปข้างหน้า) และโอเวอร์เฮดของเฟรมเวิร์กและไดรเวอร์ ส่วนที่ไม่ใช่น้ำหนักรวมกันมักจะเพิ่มขึ้น 10 ถึง 20% เหนือน้ำหนักสำหรับการตั้งค่าผู้ใช้คนเดียว และ KV cache เพียงอย่างเดียวอาจใหญ่กว่าทุกอย่างเมื่อบริบทยาวขึ้น ไฟล์ขนาด 4.6 GB อาจต้องการหน่วยความจำมากกว่า 4.6 GB มากในการรัน
ลองนึกภาพหน่วยความจำรันไทม์เป็นสี่องค์ประกอบที่ซ้อนกัน:
- น้ำหนักของโมเดล ไฟล์ที่คุณดาวน์โหลดมา นี่คือส่วนเดียวที่มองเห็นได้ก่อนที่คุณจะโหลด
- KV cache สถานะความสนใจสำหรับหน้าต่างบริบท เล็กเมื่อบริบทสั้น ใหญ่มหาศาลเมื่อบริบทยาว นี่คือส่วนถัดไป เพราะเป็นส่วนที่ทำให้คนประหลาดใจ
- แอกทิเวชัน หน่วยความจำที่ใช้งานของการส่งไปข้างหน้า สำหรับการอนุมานท้องถิ่นแบบสตรีมเดียว (ขนาดแบทช์ 1) สิ่งนี้มีขนาดเล็ก โดยทั่วไปไม่กี่ร้อยเมกะไบต์
- โอเวอร์เฮดของเฟรมเวิร์ก รอยเท้าของรันไทม์เองบวกกับบริบทไดรเวอร์ GPU สำหรับรันไทม์ท้องถิ่นแบบเบา สิ่งนี้อาจมีขนาดเล็กเมื่อเทียบกับน้ำหนักของโมเดลและ KV cache เฟรมเวิร์กการให้บริการที่หนักกว่าอาจจองไว้มากกว่านั้นมาก การจองหน่วยความจำของระบบปฏิบัติการของคุณเองอยู่นอกเหนือจากนี้และแยกออกไปอีกต่างหาก
น้ำหนักและโอเวอร์เฮดของเฟรมเวิร์กสามารถคาดเดาได้ KV cache คือตัวแปรที่เปลี่ยนโมเดลที่ "ใส่ได้พอดี" ให้กลายเป็นโมเดลที่ล่ม ดังนั้นจึงคุ้มค่าที่จะคำนวณเลขคณิตที่แท้จริง
KV Cache ใช้หน่วยความจำเท่าไร?
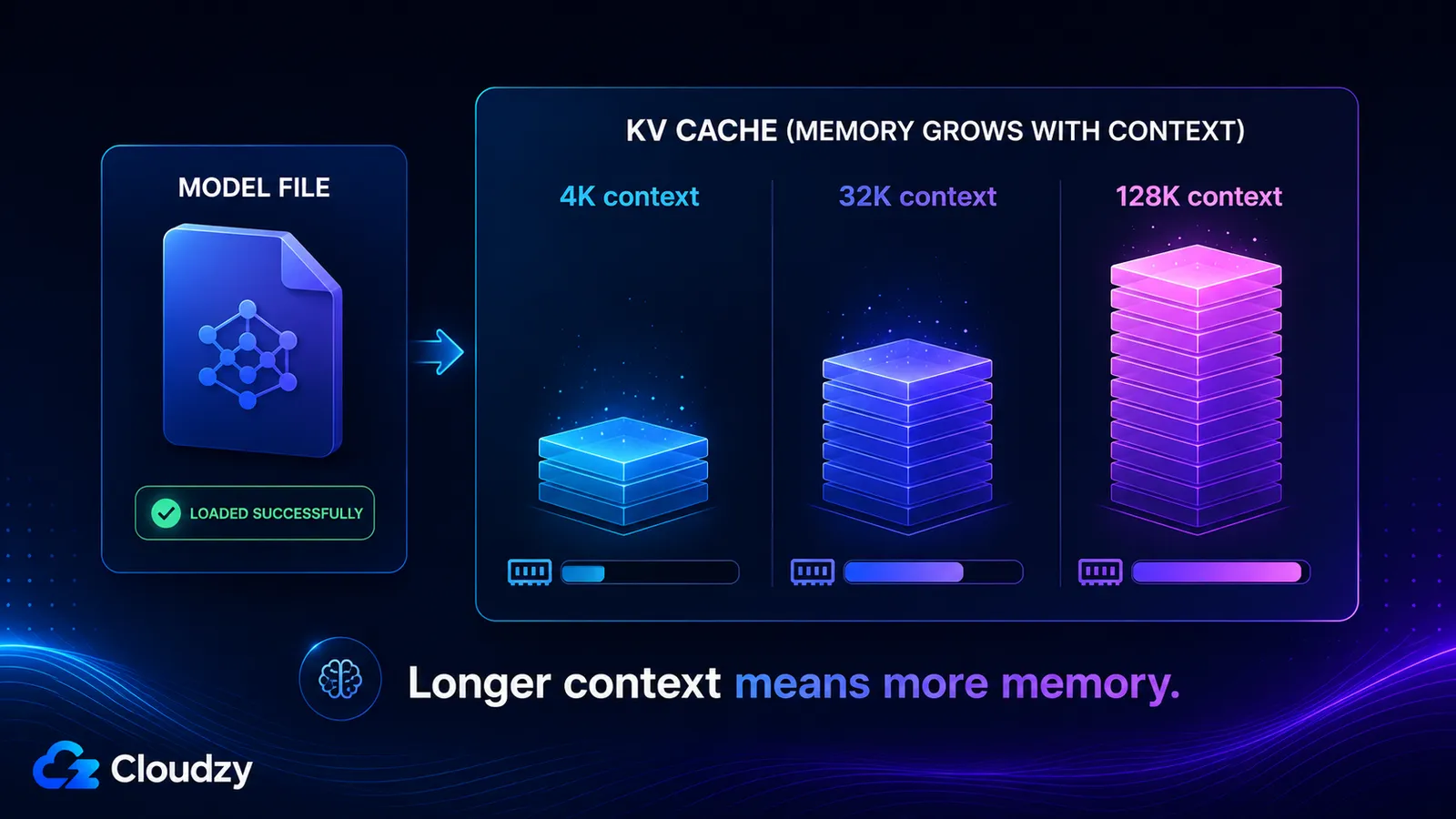
KV cache จัดเก็บเวกเตอร์คีย์และค่าสำหรับทุกโทเคนในหน้าต่างบริบทของคุณ ดังนั้นมันจึงเติบโตแบบเชิงเส้นคร่าวๆ ตามความยาวบริบทและแยกออกจากน้ำหนักของโมเดลโดยสิ้นเชิง ขนาดของมันถูกกำหนดโดยจำนวนเลเยอร์ของโมเดล จำนวน KV head ขนาดของ head ความยาวบริบท และความแม่นยำของแคช เปิดใช้บริบทยาวและคุณอาจเพิ่มหน่วยความจำหลายสิบกิกะไบต์ที่โมเดลซึ่งโหลดได้ดีไม่เคยเตือนคุณ
สูตรนี้สั้นพอที่จะจำไว้ในหัวได้:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
เลข 2 นำหน้าเป็นตัวแทนของเทนเซอร์สองตัวที่จัดเก็บต่อโทเคน หนึ่งสำหรับคีย์ หนึ่งสำหรับค่า bytes_per_element เท่ากับ 2 สำหรับแคช FP16 ที่เหลือคือค่าคงที่ทางสถาปัตยกรรมที่คุณสามารถอ่านได้จากการ์ดโมเดล
ลองคำนวณสำหรับ Llama 3.1 8B ซึ่งมี 32 เลเยอร์ 8 KV head และขนาด head 128 ที่บริบท 4,096 โทเคน ขนาดแบทช์ 1 แคช FP16:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
ขยายบริบทและตัวเลขก็จะขยายตามไปด้วย เพราะทุกเทอมยกเว้น context_tokens นั้นคงที่:
- บริบท 4K: ~536 MB
- บริบท 32K: ~4.3 GB
- บริบท 128K: ~17 GB
ตัวเลขสองตัวสุดท้ายนั้นคือเหตุผลที่โมเดลสามารถประกาศหน้าต่างบริบท 128K โหลดได้อย่างราบรื่น แล้วก็หมดหน่วยความจำทันทีที่คุณใช้หน้าต่างนั้นจริงๆ KV cache ที่บริบทเต็มมีขนาดใหญ่กว่าน้ำหนักที่ถูกควอนไทซ์เองเสียอีก
นี่คือส่วนที่ทำให้โมเดลบริบทยาวสมัยใหม่เป็นไปได้เลย: Llama 3.1 8B ใช้ Grouped Query Attention (GQA)มันมี query head 32 ตัว แต่มี KV head เพียง 8 ตัว แคชจัดเก็บเวกเตอร์คีย์/ค่าสำหรับ 8 head ไม่ใช่ 32 ลองรันสูตรเดียวกันด้วย KV head 32 ตัว (การออกแบบ Multi-Head Attention แบบเก่าที่ KV head เท่ากับ query head) แล้วตัวเลขทุกตัวข้างต้นจะคูณด้วย 4 17 GB ที่ 128K นั้นจะกลายเป็น 68 GB GQA คือเหตุผลเชิงสถาปัตยกรรมที่ทำให้เลขคณิตยังพอรับมือได้ในขณะที่หน้าต่างบริบทขยายใหญ่ขึ้น
ขนาดไฟล์ไม่ใช่งบประมาณหน่วยความจำของคุณ เมื่อน้ำหนักหรือ KV cache ไม่สามารถใส่ในเส้นทางหน่วยความจำที่รวดเร็วได้อีกต่อไป และรันไทม์ต้องถอยกลับไปใช้ RAM ระบบผ่าน PCIe ปริมาณงานจะไม่ลดลงอย่างนุ่มนวล มันจะร่วงลงเหมือนหน้าผาทันทีที่คุณต้องย้ายข้อมูลผ่าน PCIe ทุกโทเคน จัดงบประมาณหน่วยความจำให้ทั้งน้ำหนักและ KV cache ที่ความยาวบริบทจริงของคุณใส่ได้พอดี ไม่ใช่แค่น้ำหนักเท่านั้น
คุณจะเลือกควอนต์สำหรับ GPU หรือ Mac ของคุณอย่างไร?
เริ่มต้นจากฮาร์ดแวร์และรันไทม์ของคุณ เจ้าของ GPU ของ NVIDIA มีเมนูที่กว้างที่สุดและควรพิจารณา EXL2 สำหรับความเร็วดิบหรือ GGUF สำหรับความพกพาได้ หากคุณใช้ AMD, Apple Silicon, ฮาร์ดแวร์ที่มีแต่ CPU หรือการตั้งค่าแบบผสม GGUF ผ่าน llama.cpp มักเป็นจุดเริ่มต้นที่ปลอดภัยที่สุด จากนั้นเลือกระดับควอนต์ที่สูงที่สุดที่ใส่ได้พอดีหลังจากที่คุณจัดงบประมาณสำหรับ KV cache ที่ความยาวบริบทที่คุณใช้จริง ไม่ใช่ค่าสูงสุดของโมเดล
กับดักของ Apple Silicon ที่ควรรู้ไว้อย่างหนึ่ง: GPU ไม่ได้รับหน่วยความจำรวมทั้งหมดของคุณ (ดูบทความคู่กันของเราเรื่อง หน่วยความจำรวมคืออะไรจริงๆ เพื่อภาพรวมทั้งหมดว่าพูลที่ใช้ร่วมกันนั้นทำงานอย่างไร) ชุมชนที่โฮสต์เอง บันทึกเพดานไว้ที่ประมาณ 75% ของหน่วยความจำรวมทั้งหมดที่ GPU สามารถใช้ได้ (สิ่งนี้ไม่ได้รับการยืนยันอย่างเป็นทางการจาก Apple และอาจเปลี่ยนแปลงได้ตามการอัปเดต macOS) ดังนั้น "Mac 64 GB" ตามความเป็นจริงจึงมีประมาณ ~48 GB สำหรับโมเดลบวกกับ KV cache ของมัน ให้วางแผนโดยอิงจากตัวเลขที่น้อยกว่า
บทความนี้เกี่ยวกับการอ่านฟอร์แมตและคาดเดาพฤติกรรมรันไทม์ของมัน: ถอดรหัสชื่อควอนต์ เลือกฟอร์แมตที่ฮาร์ดแวร์ของคุณรองรับ และจัดงบประมาณ KV cache แยกจากน้ำหนัก การจับคู่โมเดลเฉพาะกับปริมาณหน่วยความจำเฉพาะ ตารางค้นหาขนาดต่อหน่วยความจำ เป็นคำถามที่เกี่ยวข้องแต่แยกออกไปซึ่งเราจะกล่าวถึงในบทความคู่กันในอนาคต
อ่านรีโป
ตอนนี้คุณสามารถดูหน้าโมเดลและอ่านมันแทนที่จะเดา ถอดรหัสชื่อควอนต์ให้เป็นความกว้างบิตที่มีผลจริง จดจำว่า GGUF เป็นฟอร์แมตท้องถิ่นที่กว้างที่สุดในขณะที่ GPTQ, AWQ และ EXL2 เจาะจงกับรันไทม์มากกว่า และจำไว้ว่าขนาดไฟล์เป็นเพียงพื้นฐาน KV cache จะซ้อนทับขึ้นไปและเติบโตตามบริบทของคุณ เปิดไฟล์สำหรับโมเดลที่คุณต้องการ เลือกฟอร์แมตที่ฮาร์ดแวร์ของคุณรันได้ เลือกระดับควอนต์ที่สูงที่สุดที่ใส่ได้พอดีหลังจากที่คุณเผื่อพื้นที่ไว้สำหรับ KV cache ที่ความยาวบริบทจริงของคุณ แล้วคุณจะหลีกเลี่ยงการล่มด้วยหน่วยความจำไม่พอที่เป็นจุดเริ่มต้นของคำถามทั้งหมดนี้ได้
คำถามที่พบบ่อย
Q4_K_M หมายความว่าอย่างไร?
Q4_K_M คือระดับการควอนไทซ์ GGUF: ประมาณ 4 บิตต่อน้ำหนัก (Q4) ใช้การปรับสเกลแบบ K-quant ต่อบล็อก (K) ที่ระดับขนาด/คุณภาพปานกลาง (M) ที่มีผลจริง ความกว้างบิตของมันอยู่ที่ประมาณ 4.89 บิตต่อน้ำหนัก ไม่ใช่ 4 พอดี เพราะ K-quant จัดเก็บสเกลและค่าต่ำสุดสำหรับน้ำหนักแต่ละบล็อก นี่คือเหตุผลที่ไฟล์โมเดล 8B แบบ "4-บิต" มีขนาดประมาณ 4.6 GB แทนที่จะเป็น 3.5 GB
การควอนไทซ์ลดคุณภาพของ LLM หรือไม่?
ใช่ แต่ต้นทุนขึ้นอยู่กับว่าคุณผลักดันมันไปไกลแค่ไหนเป็นอย่างมาก บน Llama-3.1-8B-Instruct ที่วัดใน arXiv:2601.14277 perplexity เพิ่มขึ้นเพียงประมาณ 0.4% ที่ Q6_K และอยู่ใกล้ 1% ตลอดช่วง Q5 ลดลงมาที่ Q4 การเพิ่มขึ้นยังคงพอประมาณ (สองสามเปอร์เซ็นต์) ต่ำกว่า Q3_K_M มันไต่ขึ้นอย่างรวดเร็ว ไปถึง +22% ที่ Q3_K_S สำหรับการใช้งานส่วนใหญ่ Q4_K_M ขึ้นไปแทบจะไม่มีการสูญเสียเลย บทลงโทษที่รุนแรงอยู่ที่ 3 บิตและต่ำกว่า
ความแตกต่างระหว่าง GGUF, GPTQ, AWQ และ EXL2 คืออะไร?
GGUF (รันโดย llama.cpp) เป็นฟอร์แมตที่พกพาได้ มันทำงานบน CPU, GPU หรือการตั้งค่าแบบไฮบริดในฮาร์ดแวร์หลากหลายประเภท GPTQ, AWQ และ EXL2 เจาะจงกับ GPU และรันไทม์มากกว่า ที่ 4-บิต ทั้งสี่แบบสามารถลงเอยในย่านคุณภาพที่แคบ ดังนั้นความแตกต่างในทางปฏิบัติคือฮาร์ดแวร์ การรองรับตัวโหลด ความเร็ว และการใช้ VRAM: EXL2 คือตัวเลือกที่เน้น NVIDIA/CUDA เพื่อความเร็ว AWQ พบได้ทั่วไปในสแต็กการให้บริการ GPTQ เข้ากับเครื่องมือ GPU รุ่นเก่าและรีโปโมเดล และ GGUF ยังคงเป็นตัวเลือกท้องถิ่นที่พกพาได้มากที่สุด
ทำไม LLM ท้องถิ่นของฉันถึงใช้หน่วยความจำมากกว่าไฟล์?
ขนาดไฟล์เป็นเพียงน้ำหนักของโมเดลเท่านั้น ในขณะรันไทม์คุณยังต้องจ่ายสำหรับ KV cache (สถานะความสนใจสำหรับทุกโทเคนในหน้าต่างบริบท) แอกทิเวชัน และโอเวอร์เฮดของเฟรมเวิร์กบวกไดรเวอร์ KV cache มักเป็นตัวการเมื่อช่องว่างมีขนาดใหญ่ เพราะมันเติบโตตามความยาวบริบทและถูกจัดสรรแยกจากน้ำหนัก โมเดลที่มีไฟล์ขนาดไม่กี่กิกะไบต์อาจต้องการหน่วยความจำมากกว่านั้นมากเมื่อคุณตั้งค่าบริบทยาว
ความยาวบริบทส่งผลต่อการใช้หน่วยความจำอย่างไร?
KV cache เติบโตแบบเชิงเส้นคร่าวๆ ตามความยาวบริบท ดังนั้นการเพิ่มบริบทของคุณเป็นสองเท่าจะทำให้แคชโตขึ้นประมาณสองเท่าเช่นกัน สำหรับ Llama 3.1 8B แคชมีขนาดประมาณ 536 MB ที่ 4K โทเคน ~4.3 GB ที่ 32K และ ~17 GB ที่ 128K (FP16 สตรีมเดียว) การเติบโตนั้นแยกออกจากน้ำหนักของโมเดลโดยสิ้นเชิง ซึ่งเป็นเหตุผลที่การประกาศหน้าต่างบริบทยาวสามารถผลักดันให้โมเดลหมดหน่วยความจำได้แม้ว่ามันจะโหลดได้ดีก็ตาม


