ผู้ใช้ GitHub มากกว่า 178,000 คนกด star ไฟล์ markdown เพียงไฟล์เดียว ไฟล์นั้นแค่บอก AI ว่าจะทำตัวอย่างไร
สี่กฎ: คิดก่อนเขียนโค้ด ความเรียบง่ายมาก่อน เปลี่ยนแปลงอย่างแม่นยำ ลงมือทำโดยมีเป้าหมาย เท่านั้นเอง ไม่มีไลบรารี ไม่มีเฟรมเวิร์ก ไม่มีตัวติดตั้ง Forrest Chang นำข้อสังเกตของ Andrej Karpathy เกี่ยวกับรูปแบบความผิดพลาดของ LLM ในการเขียนโค้ดมาบรรจุเป็นไฟล์ CLAUDE.md เพียงไฟล์เดียว และชุมชนนักพัฒนาก็ดันมันทะลุ 178,000 GitHub star ในเดือนต่อๆ มา
ถ้าคุณเพ่งมองสิ่งที่เกิดขึ้นตรงนั้น มันดูคล้ายกับสิ่งที่ทุกองค์กรวิศวกรรมค้นพบในที่สุดว่าตัวเองต้องการ หลังจากเจ็บปวดมามากพอ: ชุดข้อจำกัดร่วมกันว่าโค้ดจะถูกเขียนอย่างไร ชั้นกฎ สิ่งที่เคยอยู่ในเช็กลิสต์การรีวิวโค้ด หรือ style guide หรือความทรงจำเชิงสถาบันของวิศวกรอาวุโส ชุมชน vibe coding พบเวอร์ชันที่เบากว่ามากของวินัยเดียวกันนั้น: เขียนกฎลงใน markdown และให้เอเจนต์อ่านมันก่อนที่จะเขียนโค้ด
นี่ไม่ใช่เรื่องที่เกิดขึ้นครั้งเดียว มันเป็นแพตเทิร์น
TL;DR (สรุปย่อ)
- อีโคซิสเต็มคำสั่งเอเจนต์ (CLAUDE.md, AGENTS.md, ไลบรารี skill ที่ใช้ร่วมกัน และเอเจนต์การเข้าถึง) กำลังกลายเป็นชั้นบังคับใช้คุณภาพแบบกระจายสำหรับการเขียนโค้ดที่ใช้ AI ช่วย
- ช่องว่างด้านคุณภาพที่มันตอบสนองต่อนั้นมีอยู่จริง: Snyk สแกน skill 3,984 ตัวจาก ClawHub และ skills.sh และพบว่า 1,467 ตัว หรือ 36.82% มีข้อบกพร่องด้านความปลอดภัยอย่างน้อยหนึ่งจุด; 534 ตัว หรือ 13.4% มีปัญหาระดับวิกฤตอย่างน้อยหนึ่งจุด
- การตอบสนองของชุมชนคือการสร้างกฎเพิ่มขึ้น ไม่ใช่ทิ้งแนวทางนี้ และสถาบันต่างๆ ตั้งแต่ Vercel ไปจนถึง OWASP และ Linux Foundation ก็เข้ามาเกี่ยวข้องแล้วในตอนนี้
ช่องว่างด้านคุณภาพมีอยู่จริง และชุมชนก็รู้ดี

13.4% ของไฟล์ skill ในชุมชนมีข้อบกพร่องด้านความปลอดภัยระดับวิกฤต นั่นมาจาก รายงาน ToxicSkills ของ Snykเผยแพร่เมื่อเดือนกุมภาพันธ์ 2026 หลังจากสแกน skill 3,984 ตัวจาก ClawHub และ skills.sh 36.82% มีช่องโหว่ด้านความปลอดภัยอย่างน้อยหนึ่งจุด 76 ตัวเป็นอันตรายโดยตรง โดย 91% ของจำนวนนั้นใช้ prompt injection เป็นกลไกในการส่งมอบ
เรื่องราวคุณภาพโค้ด AI ในภาพกว้างก็คล้ายกัน ตามการวิเคราะห์ข้อมูลการรีวิวโค้ดของ CodeRabbit โค้ดที่ใช้ AI ช่วยเขียนมีปัญหาเฉลี่ย 10.83 จุดต่อ pull request เทียบกับ 6.45 จุดสำหรับโค้ดที่เขียนโดยมนุษย์ ราวๆ 1.7 เท่าของจำนวนปัญหา การศึกษาโค้ดประจำปีของ GitClear รายงานสิ่งที่เรียกว่า "การเติบโต 4 เท่า" ในการโคลนโค้ด: เพิ่มขึ้นจาก 8.3% เป็น 12.3% ของบรรทัดที่เปลี่ยนแปลงระหว่างปี 2021 ถึง 2024
นี่เป็นตัวเลขจากผู้ขาย ดังนั้นจงรับเอาความแม่นยำนี้ด้วยความสงสัยตามสมควร ถึงอย่างนั้นก็มีประโยชน์ในเชิงทิศทาง: การเขียนโค้ดที่ใช้ AI ช่วยกำลังสร้างแรงกดดันด้านคุณภาพมากพอที่นักพัฒนากำลังสร้างราวกั้นใหม่ๆ ขึ้นมารอบมัน
สิ่งที่สำคัญคือสิ่งที่ชุมชนทำกับข้อมูลนี้ การตอบสนองไม่ใช่ "ไฟล์ skill อันตราย หยุดใช้มันเถอะ" แต่เป็น: OWASP เปิดตัว Agentic Skills Top 10 (AST10) ซึ่งเทียบเท่ากับ Web Application Security Top 10 สำหรับอีโคซิสเต็ม skill กฎเพิ่มขึ้น โครงสร้างเพิ่มขึ้น กรอบความปลอดภัยที่เป็นทางการสำหรับอีโคซิสเต็มที่ไม่เป็นทางการ
นั่นคือการตอบสนองแบบวิศวกรรมแบบคลาสสิก แม้แต่จากชุมชนที่มักพยายามหลีกเลี่ยงกระบวนการที่หนักหน่วง
อีโคซิสเต็มที่ปรากฏขึ้น

ตลอดครึ่งแรกของปี 2026 สิ่งนี้เริ่มดูเป็นเหมือนอีโคซิสเต็มแบบหลายชั้นมากกว่าไฟล์ markdown ที่กระจัดกระจายอยู่ไม่กี่ไฟล์
เริ่มจากชั้นพฤติกรรม CLAUDE.md ที่ได้แรงบันดาลใจจาก Karpathy นำเวอร์ชันของ Forrest Chang ที่ตีความข้อสังเกตของ Andrej Karpathy เกี่ยวกับความผิดพลาดในการเขียนโค้ดของ LLM มาบรรจุเป็นไฟล์คำสั่งเดียว และตอนนี้มันอยู่ที่มากกว่า 178,000 GitHub star เป็นหนึ่งใน repository ที่ถูกกด star มากที่สุดในประวัติศาสตร์ GitHub สำหรับไฟล์ที่สร้างขึ้นรอบกฎง่ายๆ สี่ข้อ กฎเหล่านั้นคืออะไรนั้นน่าสนใจน้อยกว่าสิ่งที่มันเป็นตัวแทน: ความพยายามในการเข้ารหัสวิจารณญาณที่วิศวกรอาวุโสจะใช้ในระหว่างการรีวิวโค้ด
เหนือสิ่งนั้นมีชั้นการรวบรวมของชุมชน Antigravity Awesome Skills ทะลุ 1,595+ agentic skill รวบรวม playbook ที่นำกลับมาใช้ใหม่ได้สำหรับ Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity และผู้ช่วยเขียนโค้ด AI อื่นๆ มันทำหน้าที่เหมือนไลบรารีที่ใช้ร่วมกันซึ่งเคลื่อนไหวรวดเร็วสำหรับวงการนี้: สิ่งที่คณะกรรมการมาตรฐานอาจสร้างขึ้นหากมันทำงานผ่าน GitHub แทนที่จะเป็น PDF
จากนั้นเฟรมเวิร์กก็ปรากฏขึ้น Vercel ทำให้ vercel-labs/agent-skills เป็น repository ขององค์กรอย่างเป็นทางการ ตอนนี้อยู่ที่ 28,000 star เพียงแค่ React Best Practices skill อย่างเดียวก็มีกฎมากกว่า 40 ข้อในแปดหมวดที่เน้นด้านประสิทธิภาพ รวมถึง waterfall, ขนาด bundle, ประสิทธิภาพฝั่งเซิร์ฟเวอร์, การดึงข้อมูลฝั่งไคลเอนต์, การปรับ re-render ให้เหมาะสม, ประสิทธิภาพการ render และการปรับ JavaScript ระดับเล็ก เมื่อบริษัทที่เป็นเจ้าของแพลตฟอร์มที่คุณ deploy ส่งกฎคุณภาพอย่างเป็นทางการสำหรับเอเจนต์ AI ออกมา อีโคซิสเต็มก็ได้เลื่อนขั้นจากการทดลองของชุมชนไปเป็นโครงสร้างพื้นฐานสำหรับการใช้งานจริง
และที่ด้านบนสุด คือชั้นมาตรฐาน OpenAI บริจาคข้อกำหนด AGENTS.md ให้กับ Agentic AI Foundation (AAIF) ของ Linux Foundation ควบคู่กับ MCP (Anthropic) และ Goose (Block): ข้ามเครื่องมือ ข้ามเอเจนต์ อยู่ในเส้นทางมาตรฐาน ทิศทางคือมุ่งสู่การพกพาได้: AGENTS.md ให้พื้นที่ร่วมกันแก่ทีมสำหรับคำแนะนำเอเจนต์เฉพาะโปรเจกต์ แม้ว่าเครื่องมือแต่ละตัวอาจยังต่างกันในวิธีที่มันโหลดและใช้คำสั่งเหล่านั้น
ชิ้นส่วนเหล่านี้ไม่ได้ปรากฏขึ้นมาเป็นสแตกเดียวที่วางแผนจากศูนย์กลาง มันบรรจบกันเพราะความต้องการมีอยู่จริง
มิติที่ไม่มีใครพูดถึง
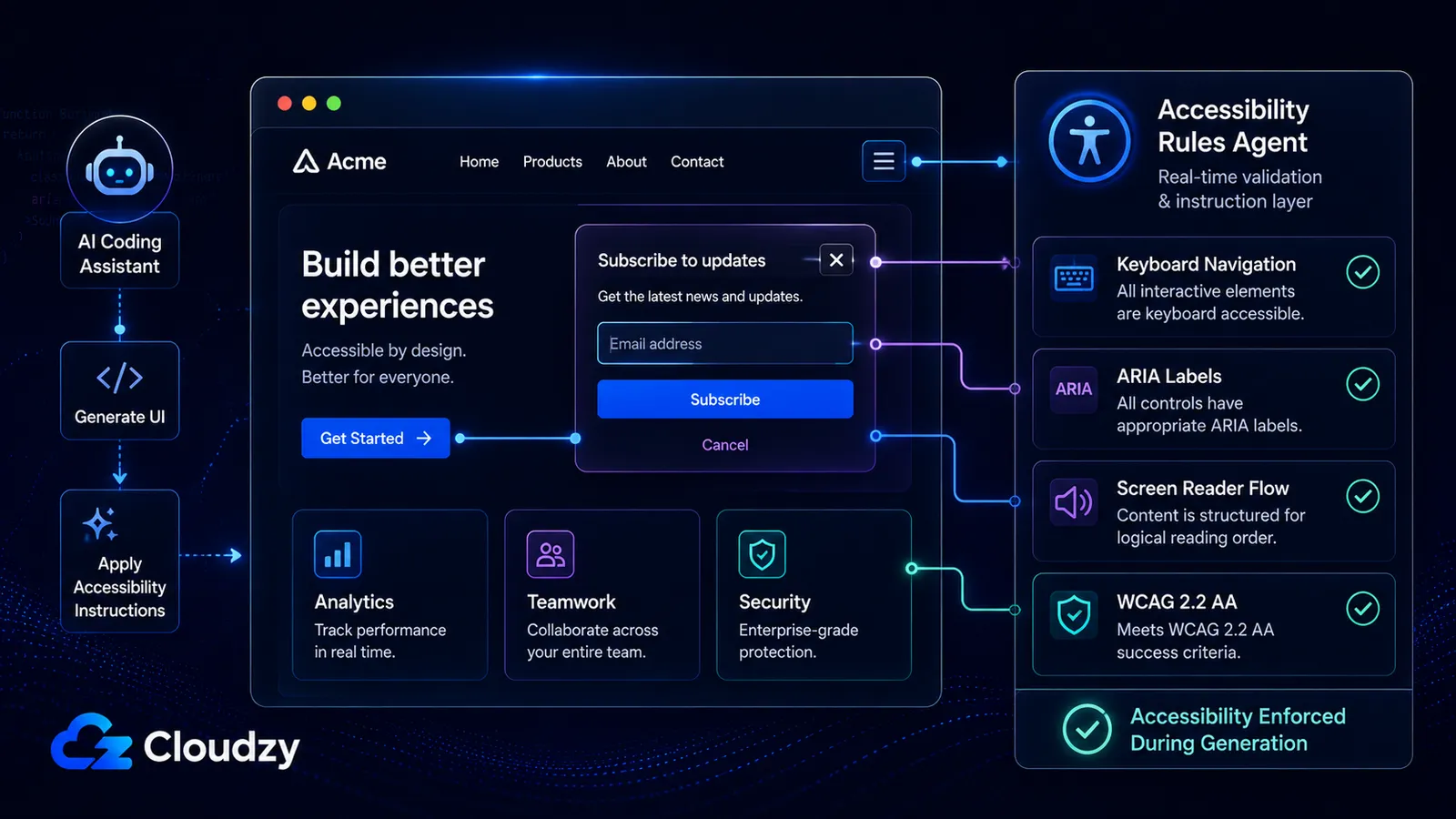
ข้อมูลด้านความปลอดภัยและคุณภาพโค้ดได้รับการพูดถึง แต่มิติด้านการเข้าถึงแทบไม่เคยได้รับเลย
Community-Access/accessibility-agents เริ่มต้นเมื่อวันที่ 21 กุมภาพันธ์ 2026 ด้วยเอเจนต์หกตัว ณ เดือนมิถุนายน 2026: เอเจนต์เฉพาะทาง 79 ตัวในแปดทีม, skill การเข้าถึงที่นำกลับมาใช้ใหม่ได้ 18 ตัว, การมุ่งเป้าที่ WCAG 2.2 AA และการรองรับห้าแพลตฟอร์ม: Claude Code, GitHub Copilot, Gemini CLI, Codex CLI และ MCP Server ที่สามารถให้บริการไคลเอนต์ที่รองรับ MCP ได้
โปรเจกต์นี้คืออะไรในแง่ที่เข้าใจง่าย: ชุมชนนักพัฒนากลุ่มหนึ่งตัดสินใจว่าเครื่องมือเขียนโค้ด AI สร้างโค้ดที่เข้าถึงไม่ได้โดยค่าเริ่มต้น (พวกมันข้ามกฎ ARIA, เพิกเฉยต่อการนำทางด้วยคีย์บอร์ด, สร้าง modal ที่ดักจับโปรแกรมอ่านหน้าจอ) และสร้างเอเจนต์เฉพาะทาง 79 ตัวเพื่อบังคับใช้กฎที่ AI มักลืม
นั่นเป็นสิ่งที่น่าทึ่งที่เกิดขึ้น วิศวกรฝั่ง frontend ส่งมอบเรื่องการเข้าถึงได้ต่ำกว่าเป้ามาโดยตลอดในเชิงประวัติศาสตร์ มันเป็นสิ่งแรกที่ถูกตัดออกภายใต้แรงกดดันด้านเส้นตาย โปรเจกต์ accessibility-agents คือ vibe coder ที่เขียนกฎที่ไม่เช่นนั้นพวกเขาจะต้องอาศัยวิศวกรอาวุโสมาบังคับใช้ และทำมันอย่างเปิดเผย ฟรี ครอบคลุมห้าการผสานรวมที่รองรับ
ในความเห็นของผม โปรเจกต์นี้ละเอียดถี่ถ้วนผิดปกติสำหรับความพยายามด้านการเข้าถึงโดยอาสาสมัคร โดยเฉพาะเพราะมันเปลี่ยนการเข้าถึงจากเรื่องที่ค่อยมาทำตอน QA ในช่วงท้าย ให้กลายเป็นคำสั่งเอเจนต์ที่นำกลับมาใช้ใหม่ได้ซึ่งรันในระหว่างการสร้างโค้ด
ทำไมสิ่งนี้จึงเป็นสิ่งที่หลีกเลี่ยงไม่ได้
ข้อโต้แย้งที่ว่า "ไฟล์ skill ก็แค่ README สำหรับ AI" นั้นยุติธรรมหากคุณมองที่ไฟล์ใดไฟล์หนึ่ง มันหยุดเป็นจริงเมื่อคุณมองที่ OWASP เปิดตัวกรอบความปลอดภัยสำหรับอีโคซิสเต็ม, Vercel ส่งไลบรารีคุณภาพอย่างเป็นทางการ หรือโปรเจกต์การเข้าถึงโดยอาสาสมัครเติบโตขึ้นเป็นเอเจนต์เฉพาะทาง 79 ตัว
นี่คือสิ่งที่กำลังเกิดขึ้นจริง: การบังคับใช้คุณภาพไม่ได้หายไปเมื่อคุณเอากระบวนการออก มันปรากฏขึ้นมาใหม่ในรูปแบบที่ต่างออกไป เพราะการขาดคุณภาพสร้างความเจ็บปวดอย่างรวดเร็ว และคนที่ใกล้ชิดกับความเจ็บปวดนั้นที่สุดก็แก้ไขมันที่ต้นตอ
วินัยทางวิศวกรรมแบบดั้งเดิม (การรีวิวโค้ด, style guide, ด่าน QA, การกำกับดูแลสถาปัตยกรรม) มีอยู่เพื่อจับสิ่งที่นักพัฒนาแต่ละคนข้ามไปภายใต้แรงกดดันด้านเวลา มันได้ผลเมื่อคุณมีทีมและมีกระบวนการ vibe coder โดยการออกแบบแล้วมักไม่มีทั้งสองอย่าง ดังนั้นพวกเขาจึงเข้ารหัสการรีวิวล่วงหน้าไว้ในคำสั่งของเอเจนต์
CLAUDE.md คือการรีวิวโค้ดที่เข้ารหัสไว้ล่วงหน้า Awesome Skills คือ style guide แบบกระจาย AGENTS.md คือมาตรฐานการกำกับดูแล คำพูดเปลี่ยนไป แต่หน้าที่ไม่เปลี่ยน
สิ่งที่น่าสนใจไม่ใช่การที่ข้อจำกัดปรากฏขึ้นมาใหม่ นั่นเป็นสิ่งที่หลีกเลี่ยงไม่ได้ สิ่งที่น่าสนใจคือมันปรากฏขึ้นมาใหม่เร็วกว่าครั้งแรก และเปิดเผยกว่า และในระดับคุณภาพที่ทำให้องค์กรวิศวกรรมบางแห่งที่มีกระบวนการเป็นผู้ใหญ่แล้วต้องอับอาย
ชุมชน vibe coding ไม่ได้สร้างวินัยทางวิศวกรรมขึ้นมาใหม่อย่างไม่เต็มใจภายใต้แรงกดดันจากฝ่ายบริหาร พวกเขาสร้างมันขึ้นมาเพราะพวกเขาชนกำแพง และเครื่องมือที่จะแก้ไขมันอยู่ห่างออกไปเพียงไฟล์ markdown ไฟล์เดียว
คำถามที่พบบ่อย
อะไรบ้างที่ใส่ลงในไฟล์ CLAUDE.md?
ข้อจำกัดด้านพฤติกรรมสำหรับ AI: สิ่งที่ต้องหลีกเลี่ยง, สิ่งที่ต้องให้ความสำคัญ, กฎด้านสถาปัตยกรรม, สัญญาณเตือนด้านความปลอดภัย และข้อตกลงเฉพาะโปรเจกต์ การใช้งานที่เน้นคุณภาพนั้นไปไกลกว่าทางลัดในเวิร์กโฟลว์: กฎอย่าง "ห้ามเอาการจัดการ error ออกเพื่อให้ test ผ่าน" อยู่เคียงข้างกับ "ใช้ TypeScript เสมอ" สำหรับตัวอย่างจริงที่ผ่านการทดสอบแล้ว เริ่มที่ การรวบรวมของชุมชน Awesome Skills. agent-skills ของ Vercel เป็นอีกหนึ่งแหล่งอ้างอิงที่ดี
AGENTS.md คืออะไร และต่างจาก CLAUDE.md อย่างไร?
AGENTS.md คือมาตรฐานสากลสำหรับคำแนะนำเอเจนต์เฉพาะโปรเจกต์ ปล่อยออกมาโดย OpenAI และบริจาคให้กับ Agentic AI Foundation ของ Linux Foundation ในเดือนธันวาคม 2025 CLAUDE.md คือไฟล์คำแนะนำโปรเจกต์ของ Claude Code ทั้งคู่มีจุดประสงค์ทับซ้อนกัน แต่ไม่ใช่รูปแบบที่เหมือนกันในทุกเครื่องมือ ข้อสรุปในทางปฏิบัติคือทีมสามารถเขียนคำสั่งเอเจนต์ครั้งเดียวและปรับใช้ข้ามเครื่องมือต่างๆ เช่น Codex, Cursor, Copilot, Gemini CLI และ Claude Code ได้มากขึ้นเรื่อยๆ
ไฟล์ Skill ปลอดภัยที่จะใช้ไหม?
skill ที่มาจากชุมชนควรอ่านก่อนนำเข้า รายงาน ToxicSkills ของ Snyk พบว่า 36% ของ skill ในชุมชนที่ถูกสแกนมีข้อบกพร่องด้านความปลอดภัยอย่างน้อยหนึ่งจุด และ 13.4% มีข้อบกพร่องระดับวิกฤต โดยมี prompt injection เป็นกลไกการโจมตีหลัก OWASP Agentic Skills Top 10 คือกรอบอ้างอิงสำหรับการเข้าใจพื้นผิวการโจมตี ไฟล์ skill จาก repository ทางการหรือโปรเจกต์โอเพนซอร์สที่มีชื่อเสียงโดยทั่วไปมีความเสี่ยงด้าน supply-chain ต่ำกว่าการบริจาคจากชุมชนแบบไม่ระบุตัวตน แต่ก็ยังควรได้รับการตรวจสอบก่อนนำเข้าอยู่ดี
OWASP Agentic Skills Top 10 (AST10) คืออะไร?
กรอบความปลอดภัยปี 2026 ของ OWASP สำหรับอีโคซิสเต็ม skill เปรียบได้กับ OWASP Web Application Security Top 10 แต่จัดการกับพื้นผิวการโจมตีที่เกิดจากไฟล์คำสั่งเอเจนต์ AI โดยเฉพาะ มันครอบคลุมความเสี่ยงด้านความปลอดภัยที่สำคัญที่สุดสิบอันดับแรกข้ามแพลตฟอร์ม รวมถึง Claude Code, Cursor/Codex และ VS Code กรอบนี้อยู่ระหว่างการพัฒนาอย่างต่อเนื่อง ณ ปี 2026 โดยมีกำหนดปล่อยเวอร์ชัน v1.0 ในไตรมาส 4 ปี 2026
ฉันจำเป็นต้องมีไฟล์ Skill ไหมถ้าฉันกำลังสร้างโปรเจกต์ส่วนตัว?
เฉพาะเมื่อคุณต้องการพฤติกรรม AI ที่สม่ำเสมอ เมื่อไม่มีข้อจำกัด เครื่องมือเขียนโค้ด AI จะปรับให้เหมาะกับการทำงานให้เสร็จ ไม่ใช่คุณภาพโค้ด ซึ่งใช้งานได้ดีจนกระทั่งมันสร้างตรรกะที่ซ้ำซ้อน, การจัดการ error ที่ขาดหายไป หรือองค์ประกอบ UI ที่เข้าถึงไม่ได้ ภาระมีน้อย: หนึ่งไฟล์ต่อโปรเจกต์ ดูแลรักษาไปตามที่คุณค้นพบว่า AI มักทำอะไรผิดพลาด กฎที่ได้แรงบันดาลใจจาก Karpathy เป็นจุดเริ่มต้นที่สมเหตุสมผล; ไลบรารี skill ของชุมชนช่วยให้คุณดึงกฎเฉพาะโดเมน (ความปลอดภัย, การเข้าถึง, สำนวนเฉพาะภาษา) เข้ามาได้โดยไม่ต้องเขียนขึ้นมาตั้งแต่ต้น