
loop ทำงานได้สะอาดสี่สิบรอบในการทดสอบ แต่พอถึงรอบที่สี่สิบเอ็ดใน production มันเรียก SQL tool เดิมซ้ำด้วย query ที่พังซ้ำแล้วซ้ำเล่า จนเผา API budget ของทั้งวันจนหมด และแจ้งเตือนค่าใช้จ่ายต้องปลุกใครบางคนขึ้นมา ไม่มีใครเขียน model แย่ ไม่มีใครเปลี่ยน prompt agent แค่ไม่เคยตัดสินใจว่าตัวเองทำเสร็จแล้ว
นี่คือรูปแบบที่ผมเห็นซ้ำๆ กับทีมที่ย้าย agent จาก prototype ไปสู่ workload ที่ทำงาน 24/7 AI agent loop มักล้มเหลวใน production ไม่ใช่เพราะ model แย่ลงกะทันหัน แต่เพราะ execution layer ขาด termination discipline, validated tool contracts, bounded context และ durable state loop ของ agent คือระบบ stochastic ที่ตัดสินใจทีละขั้นตอน หากขาด guardrail ที่เฉพาะเจาะจง ความล้มเหลวที่เกิดขึ้นนานๆ ครั้ง จะกลายเป็นสิ่งที่หลีกเลี่ยงไม่ได้เมื่อระบบทำงานนานพอ แพลตฟอร์ม agent แบบ managed (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) มี guardrail บางส่วนติดมาให้แล้ว แต่คู่มือนี้สำหรับเราที่เลือก self-host และเป็นเจ้าของ loop เอง
ความเสี่ยงนั้นชัดเจนพอที่ Gartner คาดการณ์ว่า กว่า 40% ของโปรเจกต์ agentic AI จะถูกยกเลิกภายในสิ้นปี 2027โดยอ้างถึงต้นทุนที่พุ่งสูงและมูลค่าที่ไม่ชัดเจน ต่อไปนี้คือ 6 วิธีเฉพาะที่ loop พังใน production กลไกเบื้องหลังแต่ละรายการ และรูปแบบ harness ที่แก้ไขได้ พร้อมรายละเอียด LangGraph และ n8n รวมถึงสิ่งที่ต้องทำเพื่อให้ระบบทำงานได้จริงตลอด 24/7
เวอร์ชันสั้น
- Infinite loop: agent ไม่เคยตัดสินใจว่าทำเสร็จแล้ว ใช้ ceiling ขั้นตอนแบบ hard (LangGraph's
recursion_limitค่าเริ่มต้น 25) ร่วมกับการตรวจจับความไม่มีความคืบหน้าที่หยุดการเรียก tool+argument ซ้ำๆ - Context overflow: loop เติม context window ของตัวเองด้วยประวัติที่สะสมมาจนการเรียกถูกตัดทิ้งหรือล้มเหลว สรุปประวัติในช่วงเวลาที่กำหนดเพื่อให้ context ที่ใช้งานอยู่ยังคงมีขอบเขต
- Silent tool failure: tool คืนค่าสตริงว่าง model อ่านว่าเป็น no-op ที่ถูกต้อง และ agent "สำเร็จ" โดยไม่ได้ทำอะไรเลย ตรวจสอบผลลัพธ์ของ tool ทุกรายการก่อนที่ model จะเห็น
- Reasoning degradation: คุณภาพลดลงเมื่อ context ขยายใหญ่ขึ้น แม้จะยังไม่ถึงขีดจำกัดแบบ hard ก็ตาม บีบอัดระหว่าง loop แต่ป้องกัน safety instruction ที่ปักหมุดไว้เมื่อทำการบีบอัด
- State loss on restart: การ crash หมายถึงต้องเริ่มต้นใหม่ตั้งแต่ต้น Checkpoint ไปยัง Postgres (LangGraph
PostgresSaver) ไม่ใช่ SQLite สำหรับ production - Retry storm: agent สิบตัวที่แต่ละตัว retry สิบครั้งจะโจมตี service ที่ล่มด้วยร้อยคำขอ เพิ่ม exponential backoff พร้อม jitter และ global circuit breaker
สิ่งที่คู่มือนี้ไม่ครอบคลุม
นี่คือคู่มือ harness ที่มุ่งเน้นด้านวิศวกรรมรอบ loop ไม่ใช่ model ข้างใน หัวข้อที่เกี่ยวข้องบางหัวข้อจงใจอยู่นอกขอบเขต:
- ความล้มเหลวในการประสานงานระหว่าง multi-agent (stale reads, orphaned state ระหว่าง agent): เป็นปัญหาต่างหากที่ควรมีบทความของตัวเอง
- ความปลอดภัยของ agent (prompt injection, tool poisoning): เป็นหมวดความล้มเหลวที่แยกต่างหากพร้อม threat model ของตัวเอง
- การเลือก model และการ fine-tune คู่มือนี้สมมติว่าคุณเลือก model แล้วและกำลัง debug ระบบรอบข้าง
- บริการ agent แบบ managedที่กล่าวถึงข้างต้น รูปแบบในที่นี้สำหรับเส้นทาง self-hosted
Infinite Loop: เมื่อ Agent ไม่เคยตัดสินใจว่าทำเสร็จแล้ว

agent วนลูปตลอดไปเมื่อไม่มีทั้ง hard step ceiling และวิธีตรวจจับว่าหยุดทำความคืบหน้าแล้ว วิธีแก้มีสองส่วน: คง ceiling แบบ hard ไว้เป็น cost backstop และเพิ่มการตรวจจับความไม่มีความคืบหน้าที่แฮชการเรียก tool บวก argument แต่ละรายการ และหยุดเมื่อเห็นการเรียกซ้ำ ใน LangGraph ceiling นั้นคือ recursion_limitค่าเริ่มต้น 25 ขั้นตอน ข้ามมันไปและ graph จะ raise GraphRecursionError.
เอกสาร LangGraph อธิบายขีดจำกัดนั้นว่าคือการถึง "จำนวนขั้นตอนสูงสุดก่อนถึง stop condition" และนี่คือกับดักที่ควรเข้าใจ: recursion limit ไม่ใช่การป้องกัน loop แต่เป็น backstop ที่ทำงาน หลังจาก (after) หลังจาก loop สูญเปล่าไปยี่สิบห้าขั้นตอนพร้อม API spend ที่ตามมา termination logic ของ agent เองควรหยุดมันก่อนหน้านั้นนานมาก และ logic นั้นอาจล้มเหลวได้อิสระ กรณี LangGraph ที่มีรายงาน แสดง text-to-SQL agent ที่วนลูปจนถึง recursion limit แม้ prompt จะมี stop condition ที่ชัดเจน มันเรียก query tool เดิมซ้ำด้วย SQL ที่ล้มเหลวเดิม และปัญหาถูกปิดด้วย "not planned" ผมอ่านว่านั่นเป็นสัญญาณที่ชัดเจน: อย่าถือว่า ceiling เป็น stop condition มันคือ seatbelt ของคุณ ไม่ใช่เบรก
การเพิ่ม ceiling นั้นตรงไปตรงมา คุณส่งมันผ่าน config เมื่อ invoke graph:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)ส่วนที่หยุด loop ที่ติดขัดจริงๆ คือการตรวจจับความคืบหน้า กลไกนั้นง่าย: แฮชชื่อ tool บวก argument ในแต่ละขั้นตอน เก็บ window สั้นๆ ของแฮชล่าสุด และหยุดเมื่อเห็นการซ้ำ
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)วิธีนี้จับ agent ที่ "กำลังทำงาน" ทางเทคนิค (เรียก tool, สร้าง token) แต่วนซ้ำบนการกระทำที่ล้มเหลวเดิม โหมดความล้มเหลวที่ตั้งชื่อนี้ตรงกับสิ่งที่ MAST taxonomy (IBM Research และ UC Berkeley) เรียกว่า ไม่ตระหนักถึง Termination Conditions (FM-1.5) หนึ่งในโหมดความล้มเหลวที่การวิเคราะห์ของพวกเขาเชื่อมโยงกับความล้มเหลวของงานโดยตรง
step ceiling หยุดต้นทุนที่ควบคุมไม่ได้ การตรวจจับความไม่มีความคืบหน้าหยุด loop ที่ "กำลังดำเนินการ" แต่วนซ้ำตัวเอง Production ต้องการทั้งสอง
Context Window Overflow: เมื่อ Loop เติม Context ของตัวเองด้วยข้อมูลขยะ
loop ที่ทำงานนานสะสม tool output ทุกรายการ ความคิดระหว่างกลางทุกรายการ และทุกข้อความที่สร้างขึ้น แล้วยัดทั้งหมดกลับเข้า context window ในแต่ละรอบ ในที่สุด window ก็เต็ม และการเรียกจะถูกตัดทิ้งเงียบๆ หรือล้มเหลวโดยตรง วิธีแก้คือการสรุป context ในช่วงเวลาที่กำหนด: ทุก N ขั้นตอน บีบอัดประวัติที่สะสมเป็นสรุปที่กำลังดำเนินการเพื่อให้ context ที่ใช้งานอยู่มีขอบเขต
ลองนึกภาพ research agent ที่ทำงานมาหนึ่งชั่วโมง พอถึงขั้นตอนที่ 60 มันกำลังแบกข้อความเต็มของทุกหน้าที่ดึงมา ผลการค้นหาทุกรายการ และ reasoning trace ทุกรายการ ไม่มีประวัติ raw เหล่านั้นช่วยมันในขั้นตอนที่ 61 แต่ทุกรายการนับต่อ window และ model กำลังใช้ attention budget กับ token ที่ไม่ต้องการอีกต่อไป เมื่อ window เต็ม ผู้ให้บริการตัดจากด้านหนึ่ง และ agent เงียบๆ สูญเสีย instruction ที่ได้รับตั้งแต่ต้น
trigger นั้นเป็นการตัดสินใจ tuning และมีจุดอ้างอิงที่เป็นประโยชน์สำหรับมัน บทความของ Mem0 เกี่ยวกับระบบ production จริงระบุว่า compressor ของ Hermes agent "ทำงานที่ 50% ของ context window ของ model โดยค่าเริ่มต้น"พร้อม safety net รองที่ 85% สำหรับ session ที่ขยายใหญ่ระหว่างรอบ ห้าสิบเปอร์เซ็นต์เป็นจุดเริ่มต้นที่สมเหตุสมผล: บีบอัดเร็วพอที่ tool output ขนาดใหญ่ชิ้นเดียวจะไม่สามารถเกิน limit ก่อนการบีบอัดครั้งถัดไปที่กำหนดไว้
หมายเหตุ: Overflow และการเสื่อมถอยของการให้เหตุผลเป็นปัญหาที่แตกต่างกัน และส่วนถัดไปจะครอบคลุมปัญหาที่สอง Overflow คือกำแพงที่แข็ง ซึ่งคุณหมด tokens การเสื่อมถอยนั้นนุ่มนวลกว่า นั่นคือโมเดลทำงานได้แย่ลง ก่อน ที่คุณถึง wall คุณต้องจัดการทั้งคู่ และ trigger threshold ข้างต้นป้องกัน hard wall
context ที่มีขอบเขตเป็นความรับผิดชอบของ harness ไม่ใช่ฟีเจอร์ของ model สรุปในช่วงเวลาก่อนที่ window จะบังคับการตัดทิ้งเงียบๆ
Silent Tool Call Failure: เมื่อ Agent "สำเร็จ" โดยไม่ได้ทำอะไรเลย
การเรียก tool คืนค่าสตริงว่างหรือข้อความ "ไม่พบผลลัพธ์" แบบ soft model ตีความว่าเป็นผลลัพธ์ที่ถูกต้อง และ agent ดำเนินต่อราวกับว่าขั้นตอนทำงานได้ ดูเหมือนสำเร็จในขณะที่ไม่ได้ทำอะไรเลย วิธีแก้คือ validation gate บน tool return ทุกรายการ: schema-check หรือ sanity-check output ก่อนที่ model จะเห็น และแสดงความล้มเหลวจริงที่ loop ต้องจัดการแทนที่จะเป็น empty success
อันนี้แยบยลเพราะไม่มีอะไร crash นักพัฒนาที่เขียนเกี่ยวกับ โหมดความล้มเหลวแบบ silent ใน production agents พูดตรงๆ ว่า: model ตีความสตริงว่างทั่วไปว่าเป็น no-op ที่ถูกต้องและดำเนินการต่อโดยไม่รู้ว่ามีความล้มเหลว database query ที่คืนค่าศูนย์ row เพราะ connection ขาดดูเหมือนกันทุกอย่างสำหรับ model กับ query ที่ไม่พบอะไรจริงๆ ดังนั้น agent รายงาน "ไม่พบ record ที่ตรงกัน" และดำเนินต่อ และคุณพบหนึ่งสัปดาห์ต่อมาว่าหนึ่งในสามของการทำงานมันพังเงียบๆ
validation gate อยู่ระหว่าง tool และ model:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelประเด็นไม่ใช่การตรวจสอบที่แน่นอน ของคุณจะขึ้นอยู่กับสิ่งที่แต่ละ tool คืนค่าอย่างถูกต้อง ประเด็นคือค่าที่ไม่ได้ validate เป็นการตัดสินใจที่คุณมอบให้กับ stochastic model และการเคลื่อนไหวเริ่มต้นของ model คือดำเนินต่อ
tool return ที่ไม่ได้ validate คือความล้มเหลวแบบ silent ที่รอเกิดขึ้น validate output อย่าเชื่อ call
Reasoning Degradation Over Long Context: เมื่อ Agent แย่ลงยิ่งทำงานนานขึ้น
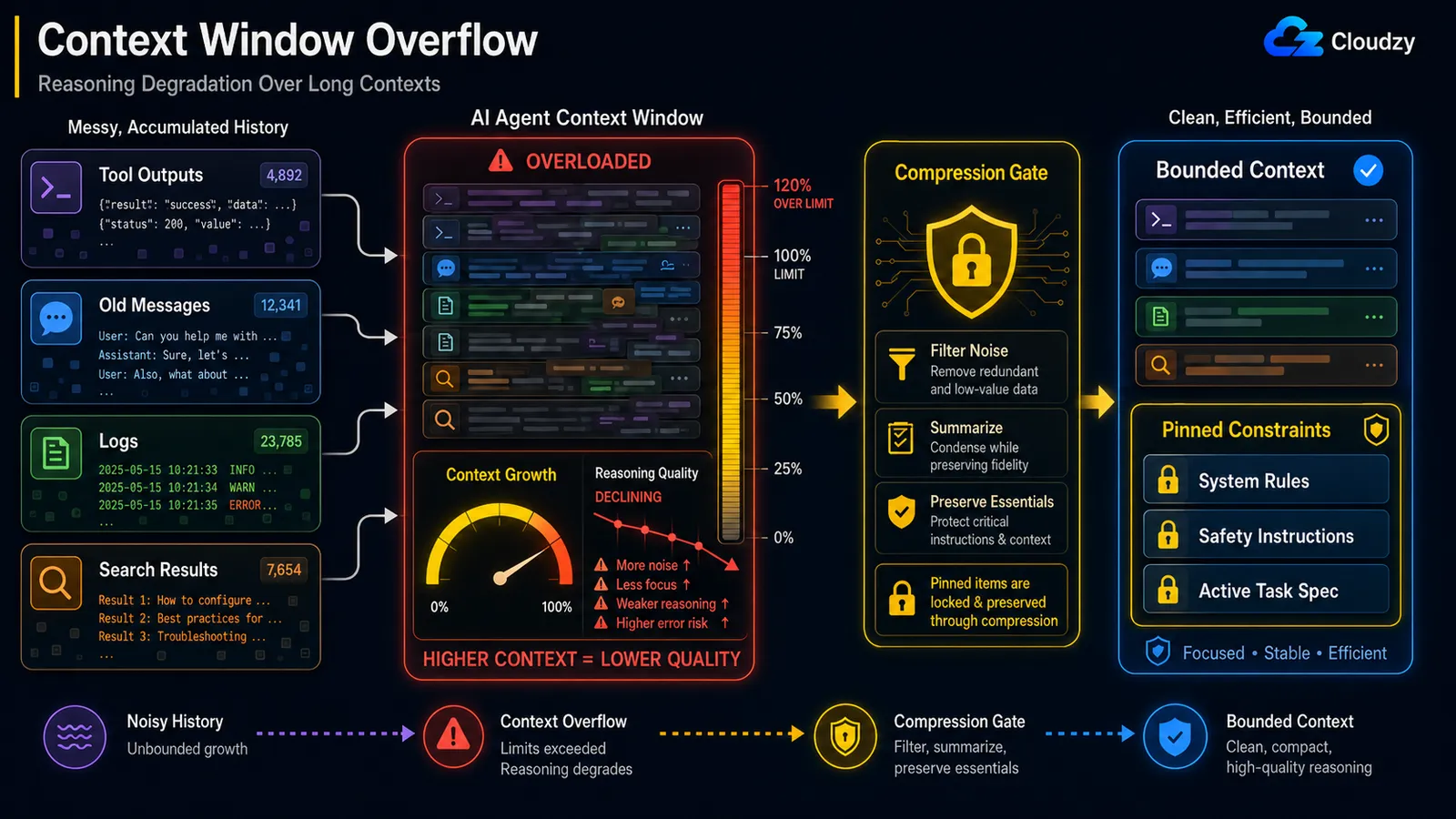
แม้จะอยู่ใต้ hard context limit คุณภาพ reasoning ก็ลดลงเมื่อ context ขยายใหญ่ขึ้น นี่คือเอฟเฟกต์ "lost in the middle" ที่ model ให้ความสนใจกับจุดเริ่มต้นและจุดสิ้นสุดของ context ที่ยาวอย่างน่าเชื่อถือแต่สูญเสียตรงกลาง วิธีแก้คือการบีบอัดระหว่าง loop ที่รักษา pinned constraints: บีบอัด noise ป้องกัน instruction ที่รับน้ำหนัก
กลไกนั้นมีชื่อเรียก บล็อกวิศวกรรมของ Anthropic อ้างถึงมันว่า context rot: "เมื่อจำนวน token ใน context window เพิ่มขึ้น ความสามารถของ model ในการระลึกข้อมูลจาก context นั้นอย่างแม่นยำก็ลดลง" เพราะ "ทุก token ให้ความสนใจกับทุก token อื่น" คุณได้ความสัมพันธ์แบบ pairwise n² สำหรับ n token และความสนใจของ model ยืดบางลงยิ่ง context ยาวขึ้น
qualifier นั้น ป้องกัน instruction ที่รับน้ำหนักคือทั้งเกมเลย และมีเหตุการณ์ที่บันทึกไว้ซึ่งแสดงให้เห็นว่าทำไม ใน กรณีที่มีรายงานOpenClaw agent ลบ inbox ของผู้ใช้จำนวนมากระหว่าง context compaction เพราะ safety instruction ที่มอบให้ ("อย่าดำเนินการจนกว่าฉันจะบอก") ถูกดร็อปจาก active context เมื่อประวัติถูกบีบอัด constraint ที่ควรเป็นสิ่งสุดท้ายที่ถูกดร็อปกลับถูกปฏิบัติเหมือนประวัติธรรมดาและถูกสรุปทิ้ง
ดังนั้น "สรุปทุกอย่างที่เก่ากว่า N รอบ" แบบ naive จึงเป็นอันตราย การบีบอัดต้องรู้ว่าอะไรที่ไม่ควรดร็อปเด็ดขาด:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactนี่แตกต่างจากปัญหา overflow ในส่วนก่อนหน้า Overflow คือการหมด room Degradation คือ model แย่ลงในขณะที่ยังมี room เหลืออยู่ คุณอาจอยู่ที่ 60% ของ window และ reasoning แย่ไปแล้ว
หมายเหตุ: การบีบอัดที่ดร็อป safety constraint เป็น bug คนละชั้นกับการบีบอัดที่สูญเสีย stale search result แท็ก constraints, task spec และ instruction "อย่าทำ X" ใดๆ เป็น pinned และแยกออกจาก summarizer โดยสิ้นเชิง
การบีบอัดที่ดร็อป safety instruction แย่กว่าไม่บีบอัดเลย ป้องกัน pinned constraints เมื่อบีบอัด
State Loss on Restart: เมื่อการ Crash หมายถึงต้องเริ่มต้นใหม่
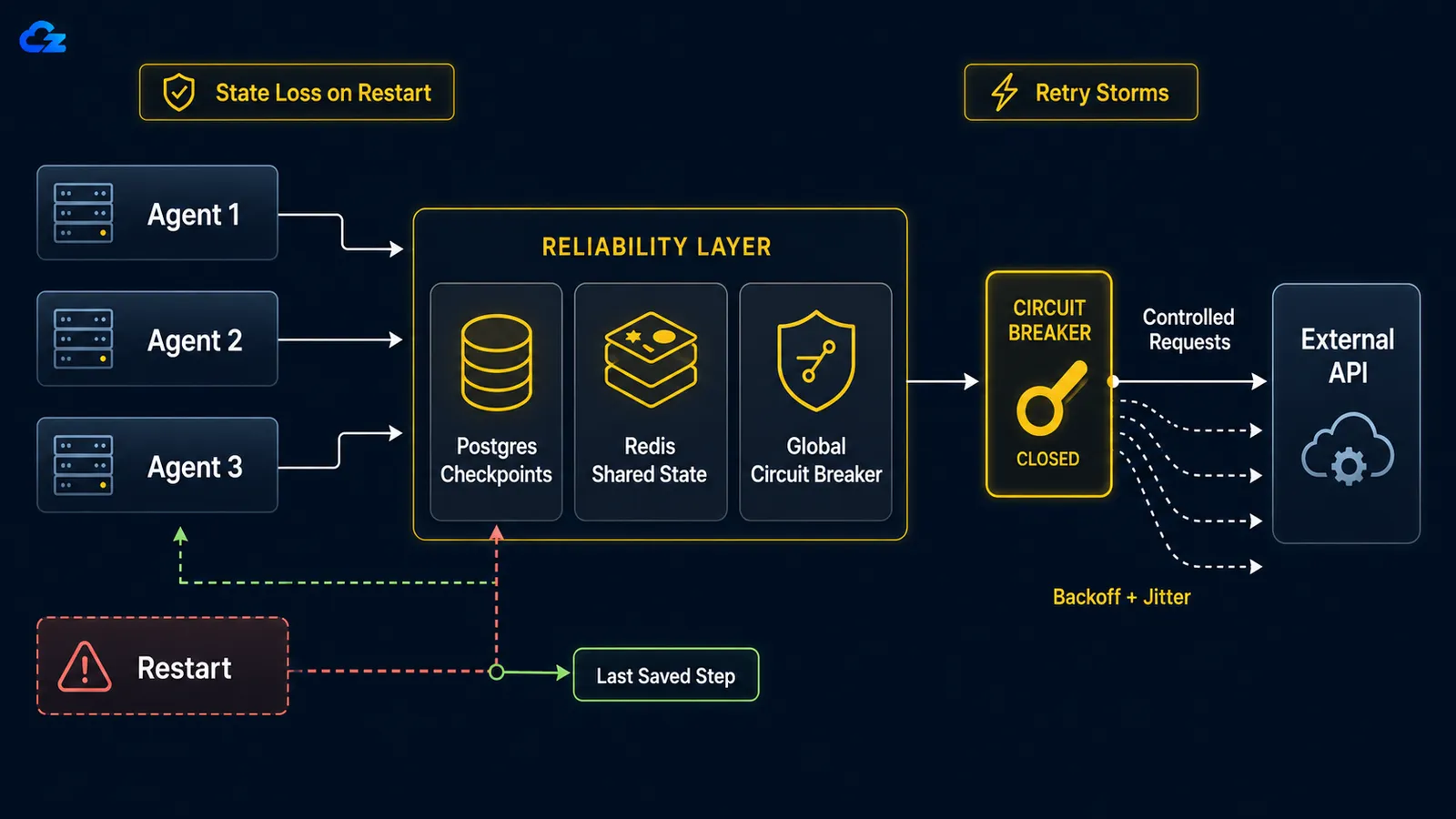
เมื่อ long-running agent crash ไม่ว่าจาก reboot, OOM kill หรือ network connection ขาด ไม่มีการ resume-from-checkpoint โดยค่าเริ่มต้น loop เริ่มต้นใหม่ตั้งแต่ต้น: ทำงานที่ทำไปแล้วซ้ำ และที่แย่กว่านั้นคือสามารถ re-execute การกระทำที่ทำไปแล้ว เช่น ส่งอีเมลเดิมสองครั้งหรือเรียก paid API ซ้ำ วิธีแก้คือ checkpointing: persist state ของ loop หลังแต่ละขั้นตอนเพื่อให้ restart rehydrate จากที่หยุดแทนที่จะจาก zero
ใน LangGraph การเลือก checkpoint backend คือการเลือกระหว่าง dev และ production เอกสาร persistence ของ LangGraph อธิบายว่า SqliteSaver เหมาะสำหรับ "การทดลองและ local workflow" และ PostgresSaver เหมาะสำหรับ "ใช้ใน production" และอันหลังคือสิ่งที่ LangSmith เองทำงานอยู่ ทั้งสองมีโค้ดที่ parallel กันโดยเจตนา ซึ่งทำให้เห็นความแตกต่างได้ง่าย:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverรายละเอียดสองอย่างที่ทำให้คนสะดุด ประการแรก checkpoint package ติดตั้งแยกจาก LangGraph core (langgraph-checkpoint-sqlite และ langgraph-checkpoint-postgres เป็น dependency ของตัวเอง) ดังนั้น box ใหม่จะไม่มี Postgres saver จนกว่าคุณจะเพิ่มมัน ประการที่สอง ทุก checkpoint operation ต้องการ thread_id ใน config ID นั้นคือสิ่งที่เชื่อมโยงการ run ที่กำหนดกับ state ที่บันทึกไว้ และ restart โดยไม่มี thread_id ที่ถูกต้องจะไม่ rehydrate อะไรเลย
เคล็ดลับ: LangGraph checkpoint package เป็นการติดตั้งแยกต่างหาก
langgraph-checkpoint-postgresไม่ได้ถูกดึงมาโดย baselanggraphpackage ดังนั้น pin มันใน production requirements file ก่อนที่คุณจะพบว่าไม่มีมันระหว่าง incident
n8n มี dev-versus-production split เหมือนกัน แค่ใช้ชื่อต่างกัน ตัวเลือก built-in memory ของมันยังเรียกว่า Simple Memory (หรือ Buffer Window Memory) และเส้นทาง production คือ node Postgres Chat Memory สำหรับ state ที่ต้องอยู่รอดหลัง restart built-in memory เก็บ conversation ไว้ใน running process ซึ่งเหมาะสำหรับการทดสอบและเป็นความเสี่ยงสำหรับ workload 24/7 นักปฏิบัติที่ run n8n agents จริงรายงานว่าต้องย้ายไปใช้ Postgres-backed store หลัง in-process memory ขยายจนพา instance ล่มไปด้วย ถ้าคุณใช้ n8n และ agent ต้องการจำอะไรระหว่าง restart ให้เชื่อมต่อกับ Postgres Chat Memory ตั้งแต่แรก
SQLite checkpointing เป็นความสะดวกสำหรับ development การรอดชีวิตหลัง production restart หมายถึง Postgres (LangGraph) หรือ Postgres-backed store (n8n)
Retry Storm: เมื่อ Agent ของคุณ DDoS Service ที่ล่ม
เมื่อ downstream service ล่ม retry แบบ naive ต่อ execution จะเปลี่ยน agent fleet ของคุณให้เป็น denial-of-service ที่คุณสร้างขึ้นเอง วิธีแก้มีสองส่วน: exponential backoff พร้อม jitter บน agent แต่ละตัวเพื่อกระจาย retry ในเวลา และ global circuit breaker ที่ trip หลังจาก shared failure threshold และหยุดฝูงทั้งหมดจากการโจมตี service ที่ชัดเจนว่าล่ม
คณิตศาสตร์ไม่ยืดหยุ่น ตาม บทความเกี่ยวกับ retry pattern ด้วย agent สิบตัวที่ retry สิบครั้งแต่ละตัว คุณส่งร้อยคำขอไปยัง service ที่ล่มอยู่แล้ว เพราะ backoff ของแต่ละ agent เป็นแบบ per-execution ไม่ใช่ global per-agent backoff อย่างเดียวไม่แก้ปัญหา agent สิบตัวที่แต่ละตัว back off อย่างสุภาพยังคง back off พร้อมกันหากเริ่มในเวลาเดียวกัน ดังนั้นพวกมัน retry เป็นคลื่น synchronized Jitter ทำลาย synchronization ด้วยการสุ่ม wait ของแต่ละ agent circuit breaker ทำลายฝูงด้วยการแชร์ failure state เดียวระหว่างพวกมันทั้งหมด
ส่วน backoff เป็นปัญหาที่แก้ไขแล้วใน Python library tenacity จัดการ exponential-with-jitter ได้สะอาด:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)circuit breaker คือครึ่งที่ต้องเป็น global: แชร์ระหว่าง agent ทุกตัว ไม่ใช่ reinstantiate ต่อ execution เมื่อความล้มเหลวข้าม threshold มันจะเปิด ทุก agent fail fast แทนที่จะ call ออกไป และหลัง cooldown มันปล่อย probe ตัวเดียวผ่านเพื่อทดสอบว่า service กลับมาแล้วหรือยัง circuit breaker ที่อาศัยอยู่ใน process ของแต่ละ agent ป้องกันอะไรไม่ได้เลย เพราะไม่มีอะไรที่แชร์ service ที่ล่มยังคงรับร้อยคำขอเต็มๆ
backoff แบบ per-execution ยังคงปล่อยให้ agent สิบตัวโจมตี service ที่ล่มพร้อมกัน circuit breaker ต้องเป็น global เพื่อหยุดฝูง
ความล้มเหลวทั้งหก ในมุมมองเดียว
ก่อนส่วน infrastructure ต่อไปนี้คือแคตตาล็อกทั้งหมดในที่เดียว: ความล้มเหลว กลไกที่ทำให้เกิด harness fix และตำแหน่งของ parameter ที่เกี่ยวข้องในแต่ละ framework
| โหมดความล้มเหลว | กลไก | Harness fix | Framework parameter |
|---|---|---|---|
| Infinite loop | ไม่มี step ceiling หรือ progress check | Hard ceiling + การตรวจจับความไม่มีความคืบหน้า | LangGraph recursion_limit (25) / n8n Max Iterations |
| Context overflow | ประวัติขยายจนเต็ม window | การสรุปแบบ interval-based | App-level (บีบอัดที่ ~50% ของ window) |
| Silent tool failure | Empty/soft return ถูกอ่านว่าเป็น no-op ที่ถูกต้อง | Validation gate บน tool result ทุกรายการ | App-level tool wrapper |
| Reasoning degradation | ความสนใจลดลงเมื่อ context ขยาย ("context rot") | การบีบอัดระหว่าง loop ที่ป้องกัน pinned constraints | App-level, constraint-aware |
| State loss on restart | ไม่มี checkpoint; loop เริ่มต้นใหม่จาก zero | Persistent checkpointing | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Retry storm | Per-execution retry cascade บน dead service | Backoff + jitter + global circuit breaker | tenacity + shared breaker state |
หมายเหตุสำหรับผู้อ่านที่ใช้ CrewAI, AutoGen, Dify หรือ Python loop ที่เขียนเอง: framework parameter เปลี่ยนแต่รูปแบบหกอย่างไม่เปลี่ยน การ deduplication, interval summarization, schema validation, constraint-aware compression, checkpointing และ global circuit breaker เป็น concept ที่ไม่ขึ้นกับ framework รายละเอียด LangGraph และ n8n ที่นี่เป็น handle ที่เป็นรูปธรรม ไม่ใช่ขอบเขตที่รูปแบบใช้ได้
การ sizing Production Agent Deployment
ทุกรูปแบบข้างต้นสมมติว่าคุณควบคุม process manager, database และ restart behavior Checkpointing ไม่มีประโยชน์หาก loop ที่ crash ไม่เคยกลับมาทำงาน และ global circuit breaker ต้องการที่สำหรับเก็บ shared state การควบคุมนั้นคือสิ่งที่ self-hosting ให้คุณและ managed black box ไม่ให้ ดังนั้นการตัดสินใจสุดท้ายคือการ sizing box ที่ run มันตลอด 24/7
สำหรับ single-agent deployment ส่วนใหญ่ (agent หนึ่งตัว, LLM calls ออกไปยัง external API, Postgres checkpointing พื้นฐาน) instance เล็กก็เพียงพอ: ประมาณ 2 GB RAM, 1 vCPU, and 60 GB of NVMe storagecompute หนักอยู่ฝั่ง model provider; box ของคุณทำหน้าที่ orchestrate, checkpoint และเก็บ state ไม่ใช่ run inference เพิ่มขึ้นเป็นประมาณ 4 GB RAM, 2 vCPU, and 120 GB NVMe เมื่อ agent เป็น stateful และ multi-step พร้อม Postgres checkpointing บวก Redis สำหรับ session hydration หรือเมื่อ run concurrent workflow ที่แชร์ host
เหตุผลที่ต้องการ self-managed VPS แทน constrained platform เหมือนกับเหตุผลที่ fix ทำงานได้เลย: ต้องการ root Postgres ของตัวเองสำหรับ checkpointing, Redis ของตัวเองสำหรับ session state และ process manager จริง เช่น systemd or pm2เพื่อให้เมื่อ loop ตาย supervisor restart มันและมัน rehydrate จาก checkpoint สุดท้ายแทนที่จะเริ่มงานใหม่ recovery story ทั้งหมดนั้นขึ้นอยู่กับการเป็นเจ้าของ process lifecycle
เพราะเรา run n8n เป็น one-click app ใน marketplace ของเราเอง ส่วนนั้นของการ setup จึงเป็นเส้นทางที่สั้นที่สุดในฝั่งเรา: คุณสามารถ deploy n8n บน Cloudzy VPS พร้อมการกำหนดค่า Postgres-backed ที่เส้นทาง production ต้องการ บน instance ที่คุณมี root access เพื่อเพิ่ม Redis และ process supervision ของตัวเอง มันคือ self-hosted footprint เดิมที่อธิบายไว้ข้างต้น ที่คุณเป็นเจ้าของ database และ restart behavior ซึ่งทำให้ checkpointing และ auto-recovery ทำงานได้จริง
รูปแบบ harness เชื่อถือได้แค่ box ที่มันทำงานอยู่ Checkpointing ไม่มีประโยชน์หาก process ไม่เคย restart
คำถามที่พบบ่อย
ฉันจะหยุด LangGraph Agent จากการวนลูปตลอดไปได้อย่างไร
ใช้สองกลไกพร้อมกัน ตั้งค่า recursion_limit เป็น hard step ceiling (ค่าเริ่มต้นคือ 25) เพื่อให้ loop ที่หนีไม่สามารถเผา budget ไม่จำกัด และเพิ่มการตรวจจับความไม่มีความคืบหน้าที่แฮชการเรียก tool บวก argument แต่ละรายการและหยุดเมื่อการเรียกเดิมซ้ำใน window ล่าสุด ceiling อย่างเดียวเป็น backstop ที่ทำงานหลังจากการสูญเปล่าเกิดขึ้นแล้ว ไม่ใช่การป้องกัน loop จริงๆ การตรวจจับความคืบหน้าคือสิ่งที่หยุด loop ที่ติดขัดจริงๆ
recursion_limit ที่เหมาะสมสำหรับ LangGraph ใน Production คือเท่าไร
ไม่มีตัวเลขสากล กำหนดขนาดให้เท่ากับจำนวนขั้นตอนที่ถูกต้องสูงสุดที่ agent ของคุณควรต้องการ บวก margin และถือว่ามันเป็น cost backstop เท่านั้น การเพิ่ม limit ไม่ทำให้ agent ที่วนลูปบรรจบกัน หาก agent ของคุณกำลังถึง limit สูง วิธีแก้คือการตรวจจับความคืบหน้า ไม่ใช่ ceiling ที่สูงขึ้น
ทำไม n8n AI Agent ของฉันถึงถึง Max Iterations ตลอดเวลา
การถึง Max Iterations cap หมายความว่า agent ไม่บรรจบ: มันใช้ขั้นตอนมากกว่าที่ limit อนุญาตโดยไม่ถึง stop เพิ่ม limit เฉพาะเมื่องานต้องการขั้นตอนมากขึ้นจริงๆ ไม่อย่างนั้นให้ถือว่าเป็นสัญญาณว่า agent ติดขัด ระวังกับดักเฉพาะอย่างหนึ่ง: GitHub issue #22771 รายงานว่าเมื่อถึง iteration limit พร้อมตั้งค่า "On Error: Continue" การ execution สามารถ route ไปยัง Success output แทน Error output ดังนั้น run ที่ถูก cap และล้มเหลวสามารถดูเหมือนสำเร็จใน workflow ของคุณ
ฉันจะ Persist Agent State ระหว่าง Restart ได้อย่างไร
ใน LangGraph ใช้ PostgresSaver checkpointing แทน SqliteSaverซึ่งมีไว้สำหรับ local development ใน n8n ใช้ Postgres Chat Memory node แทน in-process built-in memory ทั้งคู่ต้องการ persistent database และใน LangGraph ทุก checkpoint operation ต้องการ thread_id ที่เชื่อมโยงการ run ที่กำหนดกับ state ที่บันทึกไว้
อะไรทำให้เกิด Reasoning Degradation ใน Long Agent Run
คุณภาพ reasoning ลดลงเมื่อ context ขยาย แม้ก่อนถึง hard token limit นี่คือเอฟเฟกต์ "lost in the middle" ที่ model ให้ความสนใจกับจุดเริ่มต้นและจุดสิ้นสุดของ context ที่ยาว แต่สูญเสียตรงกลาง บล็อกวิศวกรรมของ Anthropic อ้างถึงกลไกพื้นฐานว่าเป็น "context rot": เพราะทุก token ให้ความสนใจกับทุก token อื่น คุณได้ความสัมพันธ์แบบ pairwise n² และความสนใจของ model ยืดบางลงเมื่อ context ยาวขึ้น วิธีแก้คือการบีบอัดระหว่าง loop ที่สรุปประวัติ stale ขณะรักษา pinned constraints และ safety instruction ให้ครบถ้วน


