
Sie öffnen die GGUF-Seite eines beliebten Modells auf Hugging Face, und fünfzehn Dateien starren zurück: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus separate Ordner für GPTQ, AWQ und EXL2 mit einem halben Dutzend Bit-Einstellungen. Sie machen die Überschlagsrechnung für die „4-Bit“-Datei: 4 Bit × 8 Milliarden Parameter ÷ 8 = 4 GB. Aber die Datei zeigt 4,6 GB an. Und einmal geladen, verbraucht das Modell noch mehr Speicher als das.
Die Dateinamen sind kein Rauschen. Sie kodieren echte, lernbare Informationen über Bit-Breite, die Laufzeitumgebung, die sie lädt, und die Hardware, die sie benötigen. Die Größentabellen, die Sie gelesen haben, sagen Ihnen, dass ein 70B-Modell etwa 40 GB braucht, nützlich, aber sie entschlüsseln nie das Format selbst oder erklären, warum das laufende Modell mehr Speicher will als die Datei auf der Festplatte.
Also hier der Plan: die GGUF-Namenskonvention entschlüsseln (mit den tatsächlichen Bit-Breiten, nicht den nominellen), herausfinden, welches der vier Formate Ihre Hardware tatsächlich ausführen kann, und den einen Speicherkostenfaktor berücksichtigen, der in jeder Dateigröße unsichtbar bleibt: den KV cache. Am Ende können Sie ein Modell-Repo lesen und vorhersagen, wie es sich beim Laden verhält.
Kurzfassung
- GGUF-Quantstufen sind effektive Bit-Breiten, nicht die genaue Zahl im Namen. Q4_K_M entspricht etwa 4,89 Bit pro Gewicht, weshalb eine „4-Bit“-8B-Datei bei rund 4,6 GiB landet statt bei der naiven 4-Bit-Schätzung.
- GGUF ist die portabelste Option, weil llama.cpp es auf CPU, GPU oder einer Hybrid-Konfiguration ausführen kann. GPTQ, AWQ und EXL2 sind stärker GPU- und laufzeitspezifisch, wobei EXL2 besonders an NVIDIA/CUDA-Workflows gebunden ist.
- Der KV cache ist von den Modellgewichten getrennt und wächst mit der Kontextlänge. Das ist der Grund, warum ein Modell, das sauber lädt, dennoch mit einem Speicherüberlauf abstürzen kann, sobald die Konversation lang wird.
- Oberhalb des 5-Bit-Bereichs ist der Qualitätsverlust meist gering. Bei Q4 ist der Kompromiss für viele lokale Anwendungsfälle noch praktikabel. Unter 4 Bit wird der Qualitätsverlust deutlich spürbarer. Q4_K_M bleibt ein verbreiteter Community-Standard, während Q5_K_M und Q6_K sicherer sind, wenn Sie Speicher übrig haben.
Was bedeutet Q4_K_M in einem GGUF-Dateinamen?

Ein GGUF-Quant-Name folgt dem Muster Q[Bits]_[K]_[S/M/L]. Die Zahl ist die angestrebte Bit pro Gewicht, K bedeutet, dass es sich um einen „K-Quant“ handelt, der Skalierungsfaktoren pro kleinem Gewichtsblock speichert, und das abschließende S, M oder L ist die Größen-/Qualitätsstufe (small, medium, large). Da K-Quants zusätzlich zu den Gewichten für jeden Block einen Skalierungs- und einen Minimalwert speichern, ist die effektive Bit-Breite höher als die Headline-Zahl. Q4_K_M liegt bei etwa 4,89 Bit pro Gewicht, nicht 4.
Diese Lücke beantwortet vollständig die Frage „Warum ist meine 4-Bit-Datei 4,6 GB groß?“. Die naive Schätzung geht davon aus, dass jedes Gewicht exakt 4 Bit kostet. Tatsächlich stecken K-Quants zusätzliche Bits pro Block in Metadaten, die die Niedrig-Bit-Quantisierung präzise machen: Skalierung und Minimum pro Block, mit denen die Laufzeitumgebung jedes Gewicht rekonstruiert. Multiplizieren Sie 4,89 Bit mit 8 Milliarden Gewichten, und Sie landen bei rund 4,58 GiB, genau das, was die Datei tatsächlich wiegt.
Hier sind die gemessenen effektiven Bit-Breiten und Dateigrößen, entnommen aus llama.cpp quantize documentation für Llama 3.1 8B als Referenzmodell, zusammen mit den Perplexitätskosten jeder Stufe, gemessen im Auswertungspapier zur llama.cpp-Quantisierung (arXiv:2601.14277) für Llama-3.1-8B-Instruct:
| GGUF-Stufe | Effektiver BPW | ~Dateigröße (8B) | Perplexität vs. F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | Basiswert |
*Die Perplexitätswerte gelten speziell für Llama-3.1-8B-Instruct aus arXiv:2601.14277. Die BPW-/Dateigrößenspalte und die Perplexitätsspalte stammen aus zwei unterschiedlichen, separat gemessenen Quellen, lesen Sie die Tabelle also als praktische Nebeneinanderstellung, nicht als Ergebnis eines einzigen Benchmark-Laufs. Die aufgabenspezifische Verschlechterung variiert, mathematisches Schlussfolgern leidet bei niedriger Bit-Breite tendenziell stärker als Alltagsverstand-Schlussfolgern, aber das grobe Muster bleibt bestehen: 5 Bit und höher sind meist sicherer, Q4 ist die praktische Kompressionszone, und bei 3 Bit wird der Qualitätsverlust deutlich schwerer zu ignorieren.
In der Praxis: Q4_K_M ist der Standard, zu dem die meisten Menschen greifen sollten, Q5_K_M und Q6_K sind die qualitätsorientierten Optionen, wenn Speicher übrig ist, und alles bei oder unter Q3_K_S ist die letzte Option für Hardware, die wirklich nicht mehr fassen kann.
Welches Quantisierungsformat sollten Sie herunterladen: GGUF, GPTQ, AWQ oder EXL2?

GGUF ist das portabelste der vier Formate: Es läuft über llama.cpp auf CPU, GPU oder einer Hybrid-Kombination beider, weshalb es die sicherste Wahl ist, wenn Sie nicht sicher sind, was Ihre Hardware unterstützt. GPTQ, AWQ und EXL2 sind stärker GPU- und laufzeitspezifisch. In der Praxis sind sie meist auf NVIDIA/CUDA-Setups anzutreffen, aber die Unterstützung von GPTQ und AWQ kann je nach Loader und Serving-Stack variieren; vLLM zum Beispiel unterscheidet die Quantisierungsunterstützung nach Hardware und Implementierung. Wenn Sie lokal auf einem Mac, einer AMD-Karte oder einer reinen CPU-Box arbeiten, bleibt GGUF die sicherste Antwort. Wenn Sie eine NVIDIA-GPU haben und die schnellstmöglichen Token wollen, kommen die anderen drei ins Spiel.
| Format | Hardware/Laufzeitumgebung | Geschwindigkeit (relativ) | VRAM im Vergleich | Am besten geeignet für |
|---|---|---|---|---|
| GGUF Q4_K_M | Am breitesten, CPU, GPU oder Hybrid über llama.cpp | Moderat | Am niedrigsten | Beliebige Hardware; lokaler Standard |
| GPTQ 4-Bit | Meist CUDA/GPU-first; laufzeitabhängig | Schnell (ExLlama) | Mittel | GPU-first, ältere Tooling-Basis |
| AWQ 4-Bit | Meist CUDA/GPU-first; laufzeitabhängig | Schnell | Höchste | vLLM/TGI-Serving, schnelles Laden |
| EXL2 ~4,9 bpw | NVIDIA/CUDA-first | Schnellste | Niedrig–Mittel | Maximale Geschwindigkeit auf NVIDIA |
Ein Vorbehalt zu dieser Tabelle: Die Geschwindigkeits- und VRAM-Rankings stammen aus dem oobabooga-Benchmark, der auf Hardware aus der Ära 2023/2024 lief. Behandeln Sie die relative Reihenfolge als beständig. EXL2 ist auf Geschwindigkeit ausgelegt, AWQ tauscht VRAM gegen schnelles Laden, GGUF bleibt schlank und portabel, aber lesen Sie die ursprünglichen absoluten Token-pro-Sekunde-Werte nicht als aktuell. Eine GPU von 2026 liefert einen ganz anderen rohen Durchsatz; die relative Rangfolge ist das, was Bestand hat.
Die Entscheidungsregel, die sich daraus ergibt: Wenn Sie eine NVIDIA-Karte haben und Geschwindigkeit am wichtigsten ist, EXL2; wenn Sie den sichersten lokalen Standard über verschiedene Hardware hinweg wollen, GGUF. AWQ und GPTQ sind vor allem relevant, wenn ein bestimmter Serving-Stack (vLLM, TGI) oder vorhandenes Tooling Sie dorthin drängt.
Warum verbraucht ein lokales LLM mehr Speicher als seine Datei?
Die Dateigröße umfasst nur die Modellgewichte. Zur Laufzeit zahlen Sie zusätzlich für den KV cache (den Attention-Zustand für jedes Token in Ihrem Kontextfenster), Aktivierungen (die Zwischenrechnungen eines Forward-Pass) sowie Framework- und Treiber-Overhead. Zusammen fügen die Nicht-Gewichts-Komponenten bei einem Einzelnutzer-Setup üblicherweise 10 bis 20% zu den Gewichten hinzu, und der KV cache allein kann alles andere in den Schatten stellen, sobald der Kontext lang wird. Eine 4,6-GB-Datei kann zum Betrieb deutlich mehr als 4,6 GB Speicher benötigen.
Stellen Sie sich den Laufzeitspeicher als vier übereinandergestapelte Komponenten vor:
- Modellgewichte. Die heruntergeladene Datei. Das ist der einzige Teil, der vor dem Laden sichtbar ist.
- KV cache. Der Attention-Zustand für das Kontextfenster. Klein bei kurzem Kontext, riesig bei langem Kontext. Das ist der nächste Abschnitt, denn er ist es, der die Leute überrascht.
- Aktivierungen. Der Arbeitsspeicher eines Forward-Pass. Bei lokaler Single-Stream-Inferenz (Batchgröße 1) ist das klein, typischerweise ein paar hundert Megabyte.
- Framework-Overhead. Der eigene Fußabdruck der Laufzeitumgebung plus der GPU-Treiberkontext. Bei einer schlanken lokalen Laufzeitumgebung kann das im Vergleich zu Modellgewichten und KV cache klein sein; schwerere Serving-Frameworks können deutlich mehr reservieren. Die eigene Speicherreservierung Ihres Betriebssystems liegt außerhalb davon und ist noch einmal separat.
Die Gewichte und der Framework-Overhead sind vorhersehbar. Der KV cache ist die Variable, die ein Modell, das „passt“, in ein abstürzendes Modell verwandelt, daher lohnt es sich, die tatsächliche Rechnung durchzugehen.
Wie viel Speicher verbraucht der KV cache?
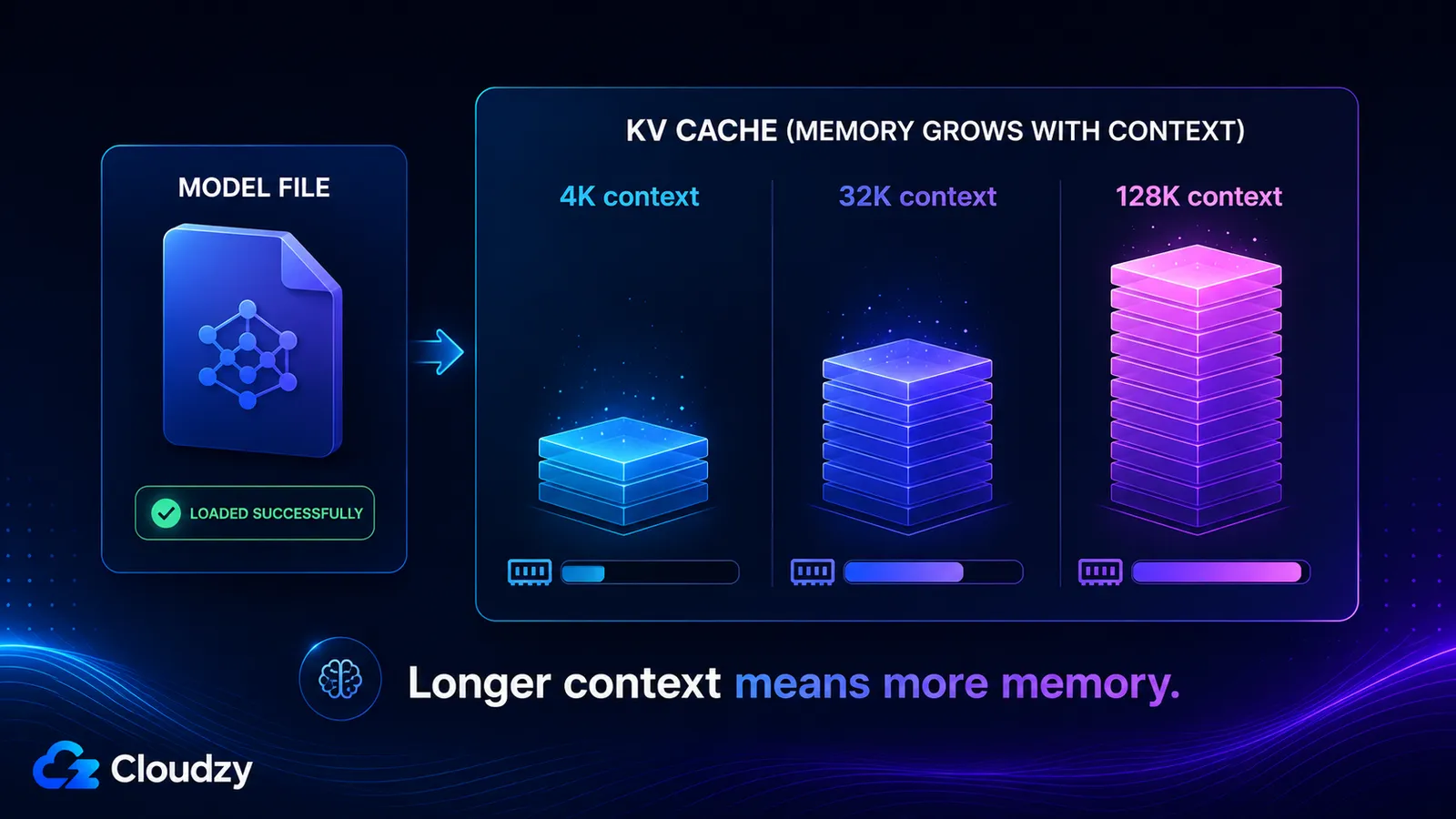
Der KV cache speichert die Key- und Value-Vektoren für jedes Token in Ihrem Kontextfenster, wächst also grob linear mit der Kontextlänge und ist völlig getrennt von den Modellgewichten. Seine Größe wird durch die Layer-Anzahl des Modells, seine Anzahl an KV-Heads, die Head-Dimension, die Kontextlänge und die Präzision des Caches bestimmt. Aktivieren Sie einen langen Kontext, und Sie können Dutzende Gigabyte hinzufügen, vor denen ein Modell, das problemlos lud, Sie nie gewarnt hat.
Die Formel ist kurz genug, um sie im Kopf zu behalten:
KV-cache-Bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Die führende 2 steht für die zwei pro Token gespeicherten Tensoren, einen für Keys, einen für Values. bytes_per_element ist 2 bei einem FP16-Cache. Der Rest sind Architekturkonstanten, die Sie einer Modellkarte entnehmen können.
Rechnen wir es für Llama 3.1 8B durch, das 32 Layer, 8 KV-Heads und eine Head-Dimension von 128 hat. Bei einem 4.096-Token-Kontext, Batchgröße 1, FP16-Cache:
2 × 32 × 8 × 128 × 4096 × 2 Byte ≈ 536 MB
Skalieren Sie den Kontext hoch, und die Zahl skaliert mit, weil jeder Term außer context_tokens fest ist:
- 4K-Kontext: ~536 MB
- 32K-Kontext: ~4,3 GB
- 128K-Kontext: ~17 GB
Diese letzten beiden Zahlen erklären, warum ein Modell ein 128K-Kontextfenster angeben, problemlos laden und dann genau in dem Moment den Speicher erschöpfen kann, in dem Sie dieses Fenster tatsächlich nutzen. Der KV cache bei vollem Kontext ist größer als die quantisierten Gewichte selbst.
Hier kommt der Teil, der moderne Long-Context-Modelle überhaupt erst möglich macht: Llama 3.1 8B verwendet Grouped Query Attention (GQA)Es hat 32 Query-Heads, aber nur 8 KV-Heads, der Cache speichert Key/Value-Vektoren für 8 Heads, nicht 32. Wenden Sie dieselbe Formel mit 32 KV-Heads an (das ältere Multi-Head-Attention-Design, bei dem KV-Heads gleich Query-Heads sind), und jede obige Zahl vervierfacht sich. Die 17 GB bei 128K werden zu 68 GB. GQA ist der architektonische Grund, warum die Rechnung angesichts gewachsener Kontextfenster überschaubar bleibt.
Die Dateigröße ist nicht Ihr Speicherbudget. Wenn Gewichte oder KV cache nicht mehr in den schnellen Speicherpfad passen und die Laufzeitumgebung auf System-RAM über PCIe zurückgreifen muss, verschlechtert sich der Durchsatz nicht sanft. Er bricht schlagartig ein, sobald bei jedem Token Daten über PCIe bewegt werden. Planen Sie den Speicher so, dass sowohl die Gewichte als auch der KV cache bei Ihrer tatsächlichen Kontextlänge passen, nicht nur die Gewichte.
Wie wählen Sie eine Quantisierung für Ihre GPU oder Ihren Mac?
Beginnen Sie bei Ihrer Hardware und Laufzeitumgebung. Besitzer von NVIDIA-GPUs haben die breiteste Auswahl und sollten EXL2 für rohe Geschwindigkeit oder GGUF für Portabilität abwägen. Wenn Sie AMD, Apple Silicon, reine CPU-Hardware oder ein gemischtes Setup haben, ist GGUF über llama.cpp meist der sicherste Ausgangspunkt. Wählen Sie von dort aus die höchste Quantstufe, die passt, nachdem Sie den KV cache bei der Kontextlänge eingeplant haben, die Sie tatsächlich nutzen, nicht beim Maximum des Modells.
Eine Apple-Silicon-Falle, die man kennen sollte: Die GPU bekommt nicht Ihren gesamten Unified Memory (siehe unseren begleitenden Artikel darüber, was Unified Memory eigentlich ist für das vollständige Bild, wie dieser gemeinsame Pool funktioniert). Die Self-Hosting-Community hat eine Obergrenze von rund 75% des gesamten Unified Memory dokumentiert, das der GPU zur Verfügung steht (dies ist von Apple nicht offiziell bestätigt und kann sich mit macOS-Updates ändern). Ein „64-GB-Mac“ bietet also realistisch nur rund 48 GB für das Modell plus seinen KV cache, planen Sie mit der kleineren Zahl.
In diesem Artikel geht es darum, das Format zu lesen und sein Laufzeitverhalten vorherzusagen: den Quant-Namen entschlüsseln, das von Ihrer Hardware unterstützte Format wählen und den KV cache getrennt von den Gewichten einplanen. Ein bestimmtes Modell einer bestimmten Speichermenge zuzuordnen, die Nachschlagetabelle von Größe zu Speicher, ist eine verwandte, aber separate Frage, die wir in einem künftigen begleitenden Artikel behandeln.
Lesen Sie das Repo
Sie können jetzt eine Modellseite ansehen und sie lesen, statt zu raten. Entschlüsseln Sie den Quant-Namen zu seiner effektiven Bit-Breite, erkennen Sie, dass GGUF das breiteste lokale Format ist, während GPTQ, AWQ und EXL2 stärker laufzeitspezifisch sind, und denken Sie daran, dass die Dateigröße nur die Untergrenze ist, der KV cache stapelt sich obendrauf und wächst mit Ihrem Kontext. Öffnen Sie die Dateien für das gewünschte Modell, wählen Sie das Format, das Ihre Hardware ausführen kann, wählen Sie die höchste Quantstufe, die passt, nachdem Sie Spielraum für den KV cache bei Ihrer tatsächlichen Kontextlänge gelassen haben, und Sie vermeiden den Speicherüberlauf-Absturz, mit dem diese ganze Frage begann.
Häufig gestellte Fragen
Was bedeutet Q4_K_M?
Q4_K_M ist eine GGUF-Quantisierungsstufe: etwa 4 Bit pro Gewicht (Q4), mit K-Quant-Blockskalierung (K), auf der mittleren Größen-/Qualitätsstufe (M). Seine effektive effektive Bit-Breite liegt bei etwa 4,89 Bit pro Gewicht, nicht genau bei 4, weil K-Quants für jeden Gewichtsblock einen Skalierungs- und einen Minimalwert speichern. Deshalb ist eine „4-Bit“-8B-Modelldatei rund 4,6 GB groß statt 3,5 GB.
Verringert Quantisierung die Qualität von LLMs?
Ja, aber die Kosten hängen stark davon ab, wie weit man geht. Bei Llama-3.1-8B-Instruct, gemessen in arXiv:2601.14277, steigt die Perplexität bei Q6_K nur um etwa 0,4% und bleibt über die gesamte Q5-Bandbreite nahe 1%. Sinkt man auf Q4, bleibt der Anstieg noch moderat (wenige Prozent); unter Q3_K_M steigt sie steil an und erreicht bei Q3_K_S +22%. Für die meisten Anwendungen ist Q4_K_M und darüber praktisch verlustfrei; die starke Einbuße liegt bei 3 Bit und darunter.
Was ist der Unterschied zwischen GGUF, GPTQ, AWQ und EXL2?
GGUF (ausgeführt von llama.cpp) ist das portable Format, es läuft auf CPU, GPU oder einer Hybrid-Konfiguration über ein breites Hardware-Spektrum. GPTQ, AWQ und EXL2 sind stärker GPU- und laufzeitspezifisch. Bei 4 Bit können alle vier in einem engen Qualitätsband landen, sodass der praktische Unterschied bei Hardware, Loader-Unterstützung, Geschwindigkeit und VRAM-Nutzung liegt: EXL2 ist die geschwindigkeitsorientierte NVIDIA/CUDA-Wahl, AWQ ist in Serving-Stacks verbreitet, GPTQ passt zu älterem GPU-Tooling und Modell-Repos, und GGUF bleibt die portabelste lokale Option.
Warum verbraucht mein lokales LLM mehr Speicher als die Datei?
Die Dateigröße sind nur die Modellgewichte. Zur Laufzeit zahlen Sie zusätzlich für den KV cache (Attention-Zustand für jedes Token im Kontextfenster), Aktivierungen sowie Framework- plus Treiber-Overhead. Der KV cache ist meist der Übeltäter, wenn die Lücke groß ist, weil er mit der Kontextlänge wächst und separat von den Gewichten zugeteilt wird, ein Modell, dessen Datei nur wenige Gigabyte groß ist, kann weit mehr Speicher benötigen, sobald Sie einen langen Kontext einstellen.
Wie wirkt sich die Kontextlänge auf den Speicherverbrauch aus?
Der KV cache wächst grob linear mit der Kontextlänge, eine Verdopplung Ihres Kontexts verdoppelt also ungefähr den Cache. Bei Llama 3.1 8B beträgt der Cache etwa 536 MB bei 4K Token, ~4,3 GB bei 32K und ~17 GB bei 128K (FP16, Single Stream). Dieses Wachstum ist völlig unabhängig von den Modellgewichten, weshalb die Angabe eines langen Kontextfensters ein Modell in einen Speicherüberlauf treiben kann, obwohl es problemlos geladen hat.


