
Choisir un GPU VPS peut sembler intimidant quand on se retrouve face à des fiches techniques remplies de chiffres. Le nombre de cœurs varie de 2 560 à 21 760, mais qu'est-ce que ça signifie concrètement ?
Un cœur CUDA est une unité de traitement parallèle intégrée aux GPUs NVIDIA. Il exécute des milliers de calculs en même temps, qu'il s'agisse d'entraîner des modèles d'IA ou de faire du rendu 3D. Ce guide explique leur fonctionnement, leurs différences avec les cœurs CPU et Tensor, et comment choisir le bon nombre de cœurs selon vos besoins sans payer pour l'inutile.
Qu'est-ce que les cœurs CUDA ?

Les cœurs CUDA sont des unités de traitement individuelles intégrées aux GPUs NVIDIA, qui exécutent des instructions en parallèle. À la base, la technologie CUDA repose sur ce principe : des unités spécialisées qui travaillent simultanément sur différentes parties d'un même calcul.
NVIDIA a introduit CUDA (Compute Unified Device Architecture) en 2006 pour exploiter la puissance des GPUs à des fins de calcul général, au-delà du simple rendu graphique. La documentation officielle CUDA fournit tous les détails techniques. Chaque unité effectue des opérations arithmétiques de base sur des nombres à virgule flottante, ce qui la rend idéale pour les calculs répétitifs.
Les GPUs NVIDIA modernes intègrent des milliers de ces unités sur une seule puce. Les GPUs grand public de dernière génération en comptent plus de 21 000, tandis que les GPUs datacenter basés sur l'architecture Hopper en embarquent jusqu'à 16 896. Ces unités fonctionnent ensemble via des Streaming Multiprocessors (SMs).
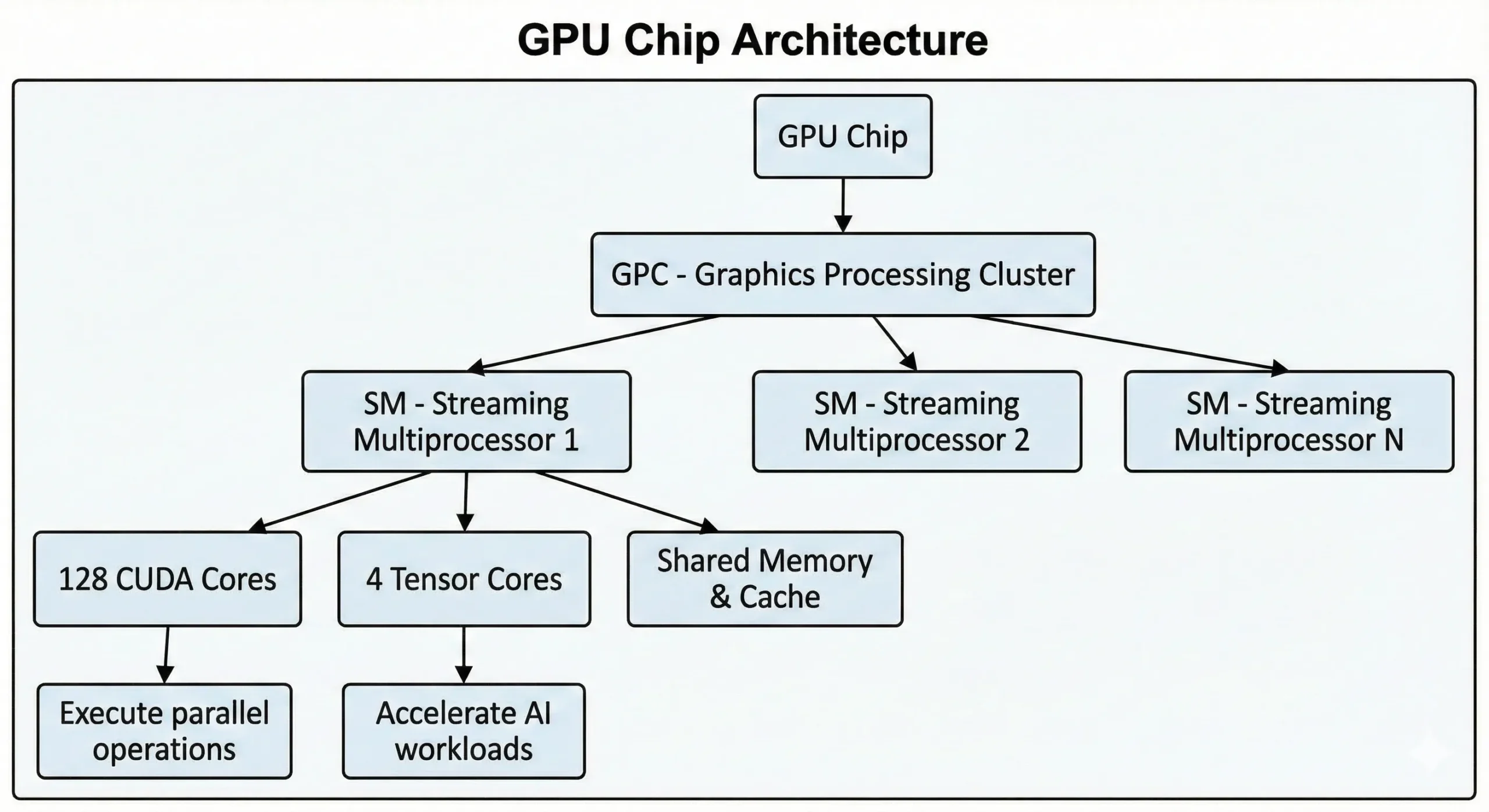
Les unités exécutent des opérations SIMT (Single Instruction, Multiple Threads) via des méthodes de calcul parallèle. Une seule instruction s'applique simultanément à de nombreux points de données. Lors de l'entraînement de réseaux de neurones ou du rendu de scènes 3D, des milliers d'opérations similaires s'exécutent en même temps. Le travail est réparti en flux concurrents, traités en parallèle plutôt que les uns après les autres.
Cœurs CUDA vs cœurs CPU : quelles différences ?

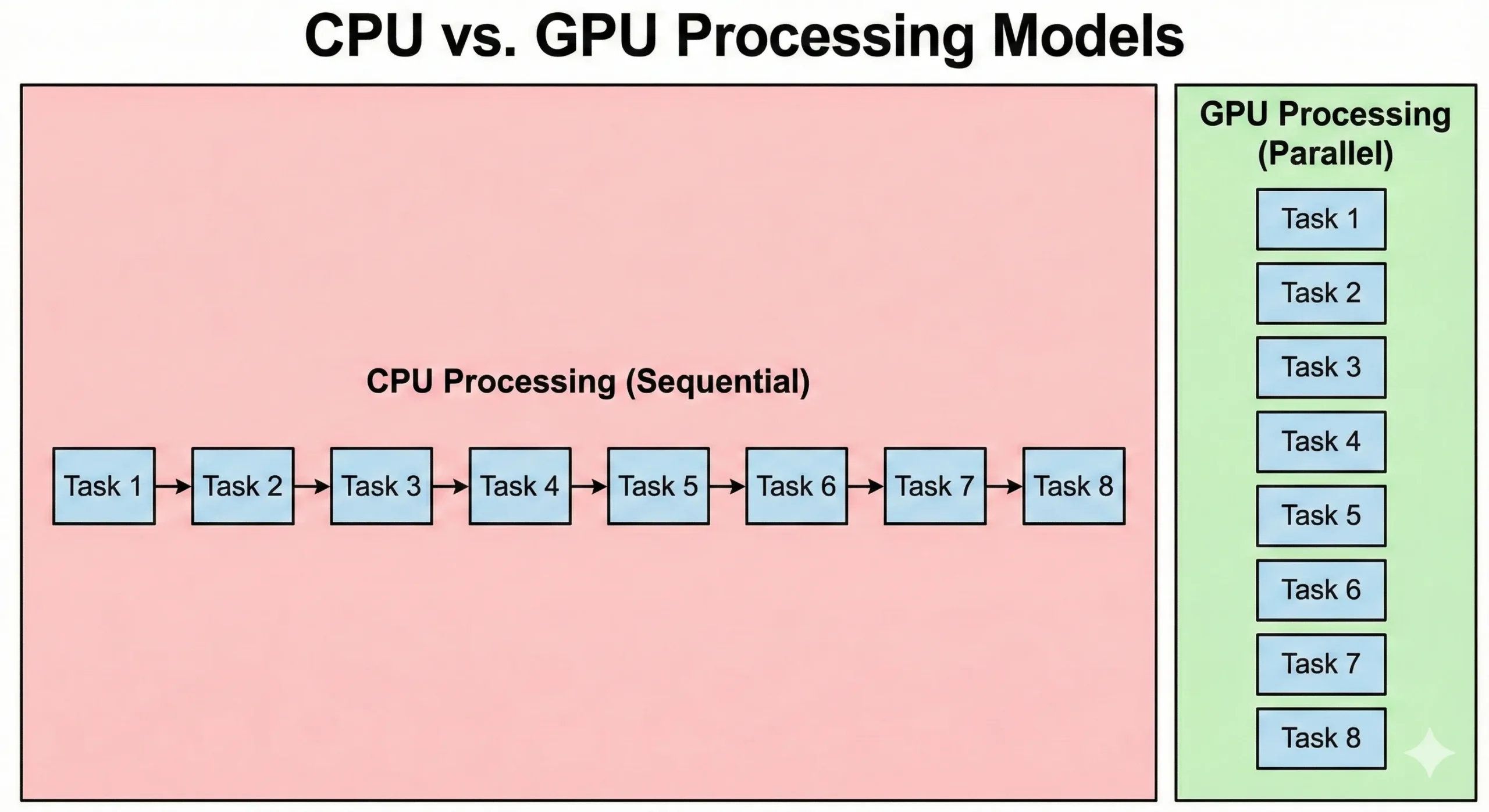
Les CPUs et les GPUs abordent les problèmes de façon fondamentalement différente. Un CPU serveur moderne peut avoir entre 8 et 128 cœurs ou plus, cadencés à haute fréquence. Ces processeurs excellent dans les opérations séquentielles, où chaque étape dépend du résultat précédent. Ils gèrent efficacement la logique complexe et les branchements conditionnels.
Les GPUs adoptent une approche opposée. Ils embarquent des milliers de cœurs CUDA plus simples, fonctionnant à des fréquences plus basses. Ces unités compensent leur cadence réduite par le parallélisme. Quand 16 000 cœurs travaillent ensemble, le débit total dépasse largement les capacités d'un CPU standard.
Les CPUs exécutent le code du système d'exploitation et la logique applicative complexe. Là où les GPUs privilégient le débit, la surcharge liée à l'initialisation des tâches et à la synchronisation entraîne une latence plus élevée. Le traitement graphique parallèle est optimisé pour le mouvement des données : même si le démarrage est plus lent, le traitement de grands ensembles de données est nettement plus rapide que sur un CPU.
| Fonctionnalité | Cœurs CPU | Cœurs CUDA |
| Nombre par puce | 4 à 128+ cœurs | 2 560 à 21 760 cœurs |
| Fréquence d'horloge | 3,0 à 5,5 GHz | 1,4-2,5 GHz |
| Style de traitement | Instructions séquentielles et complexes | Instructions simples et parallèles |
| Idéal pour | Systèmes d'exploitation, tâches mono-thread | Calcul matriciel, traitement parallèle des données |
| Latence | Faible (microsecondes) | Plus élevée (surcharge au lancement) |
| Architecture | Usage général | Optimisé pour les calculs répétitifs |
Les technologies Virtual GPU (vGPU) et Multi-Instance GPU (MIG) gèrent le partitionnement des ressources et la planification pour distribuer les processeurs entre plusieurs utilisateurs. Cette configuration permet aux équipes de maximiser l'utilisation du matériel, que ce soit par partage en tranches de temps ou par instances matérielles dédiées, selon la configuration choisie.
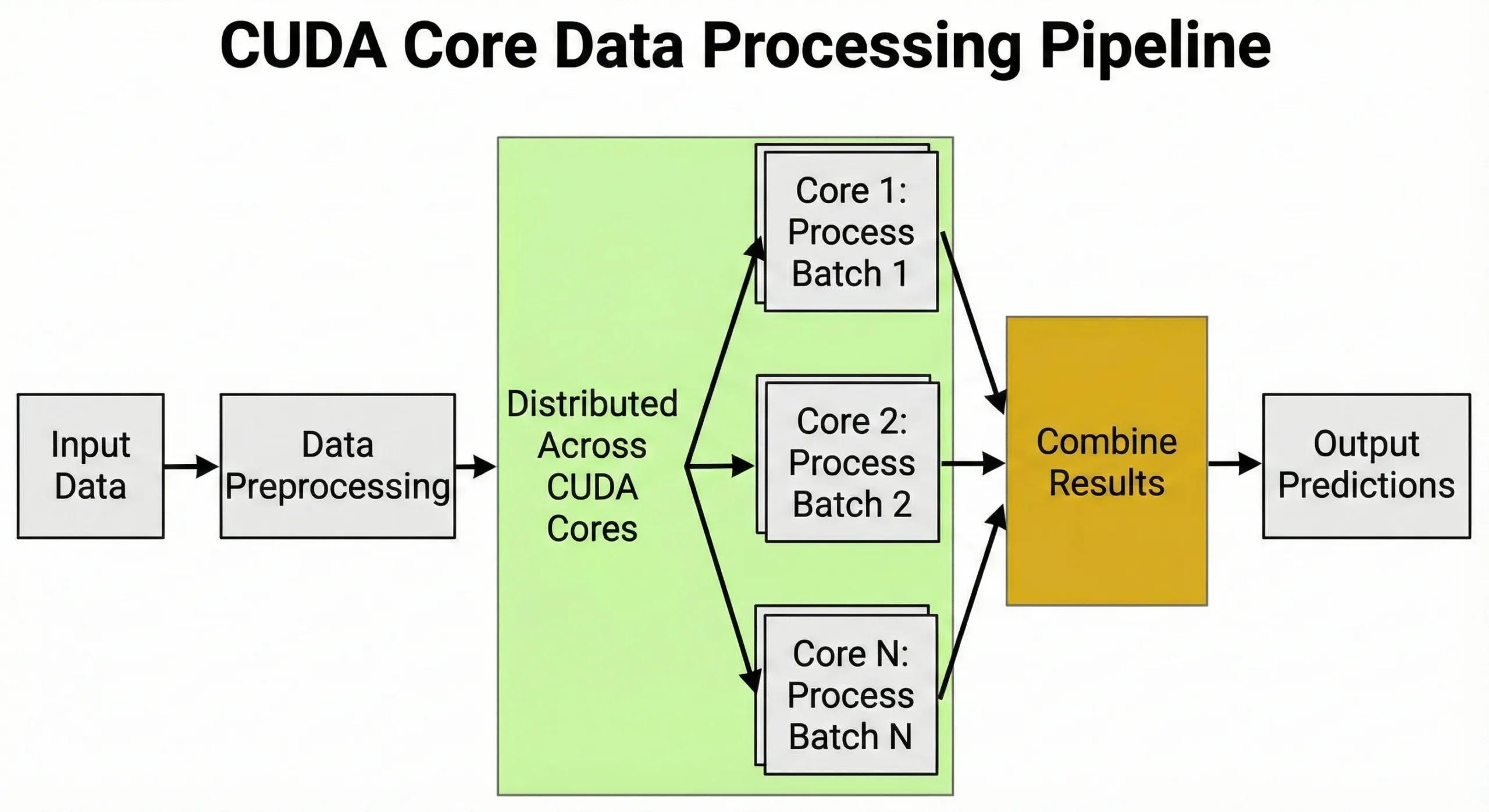
L'entraînement des réseaux de neurones repose sur des milliards de multiplications matricielles. Un GPU équipé de 10 000 unités n'exécute pas simplement 10 000 opérations en parallèle : il orchestre des milliers de threads parallèles regroupés en « warps » pour maximiser le débit. Ce parallélisme massif explique pourquoi ces unités sont incontournables pour les développeurs en IA.
CUDA Cores et Tensor Cores : comprendre la différence

Les NVIDIA GPU embarquent deux types d'unités spécialisées qui fonctionnent de concert : les cœurs CUDA standard et les Tensor cores. Ce ne sont pas des technologies concurrentes ; chacune prend en charge une partie distincte de la charge de travail.
Les unités standard sont des processeurs parallèles polyvalents chargés des calculs FP32 et FP64, des opérations entières et des transformations de coordonnées. Cette technologie CUDA de base constitue le socle du calcul GPU, couvrant tout — des simulations physiques au prétraitement des données — sans accélération spécialisée.
Les tensor cores sont des unités spécialisées conçues exclusivement pour la multiplication matricielle et les tâches d'IA. Introduits avec l'architecture Volta de NVIDIA en 2017, ils excellent dans les calculs en précision FP16 et TF32. La dernière génération prend en charge le FP8 pour une inférence IA encore plus rapide.
| Fonctionnalité | Cœurs CUDA | Cœurs Tensor |
| Rôle | Calcul parallèle général | Multiplication de matrices pour l'IA |
| Précision | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Vitesse pour l'IA | 1x de base | 2 à 10 fois plus rapide que les cœurs CUDA |
| Cas d'usage | Prétraitement des données, ML traditionnel | Entraînement et inférence deep learning |
| Disponibilité | Tous les NVIDIA GPUs | Série RTX 20 et supérieure, GPUs datacenter |
Les GPUs modernes combinent les deux types. Le RTX 5090 dispose de 21 760 unités standard et de 680 Tensor cores de cinquième génération. Le H100 associe 16 896 unités standard à 528 Tensor cores de quatrième génération pour accélérer le deep learning.
Lors de l'entraînement de réseaux de neurones, les Tensor cores assurent le gros du travail pendant les passes avant et arrière à travers le modèle. Les unités standard gèrent le chargement des données, le prétraitement, le calcul de la loss et les mises à jour de l'optimiseur. Les deux types fonctionnent de concert, les Tensor cores accélérant les opérations les plus gourmandes en calcul.
Pour les algorithmes de machine learning traditionnel comme les forêts aléatoires ou le gradient boosting, les unités standard prennent en charge tout le travail, car ces méthodes n'exploitent pas les multiplications matricielles que les Tensor cores accélèrent. En revanche, pour les modèles Transformer et les réseaux de neurones convolutifs, les Tensor cores offrent des gains de vitesse considérables.
À quoi servent les CUDA cores ?

Les CUDA cores prennent en charge les tâches qui nécessitent un grand nombre de calculs identiques exécutés en parallèle. Toute opération impliquant des matrices ou des calculs numériques répétitifs tire parti de leur architecture.
Applications IA et machine learning
Le deep learning repose sur des multiplications matricielles lors de l'entraînement et de l'inférence. À chaque passe avant, l'entraînement d'un réseau de neurones exige des millions d'opérations multiply-add sur les matrices de poids. La rétropropagation en ajoute des millions supplémentaires lors de la passe arrière.
Les unités gèrent le prétraitement des données : conversion des images en tenseurs, normalisation des valeurs et application des transformations d'augmentation. Cette capacité à traiter des milliers d'opérations simultanément explique pourquoi les GPUs sont indispensables pour l'IA.
Pendant l'entraînement, elles supervisent les plannings de taux d'apprentissage, les calculs de gradients et les mises à jour de l'état de l'optimiseur.
Pour les VPS dédiés à l'inférence IA qui font tourner des systèmes de recommandation ou des chatbots, ils traitent les requêtes en parallèle et exécutent des centaines de prédictions simultanément. Notre guide sur les meilleurs GPU pour l'IA en 2025 détaille les configurations adaptées à chaque taille de modèle.
Les 16 896 unités du H100, combinées aux Tensor cores, permettent d'entraîner un modèle de 7 milliards de paramètres en quelques semaines plutôt qu'en plusieurs mois. L'inférence en temps réel pour des chatbots servant des milliers d'utilisateurs exige une capacité d'exécution parallèle comparable.
Calcul scientifique et recherche
Les chercheurs utilisent ces processeurs pour des simulations de dynamique moléculaire, la modélisation climatique et l'analyse génomique. Chaque calcul étant indépendant, ils se prêtent parfaitement à l'exécution parallèle. Les institutions financières y font tourner des simulations Monte Carlo portant sur des millions de scénarios simultanément.
Rendu 3D et production vidéo
Le ray tracing calcule la propagation de la lumière dans des scènes 3D en traçant des rayons indépendants pour chaque pixel. Les RT cores dédiés gèrent la traversée de la scène, tandis que les unités standard s'occupent de l'échantillonnage des textures et du calcul de l'éclairage. Cette répartition conditionne la vitesse de rendu des scènes comportant des millions de rayons.
NVENC gère l'encodage H.264 et H.265, tandis que les dernières architectures (Ada Lovelace et Hopper) introduisent la prise en charge matérielle de l'AV1. CUDA intervient pour les effets, les filtres, la mise à l'échelle, la réduction du bruit, les transformations colorimétriques et l'orchestration du pipeline. L'encodeur peut ainsi fonctionner en parallèle avec les processeurs de calcul pour accélérer la production vidéo.
Le rendu 3D dans Blender ou Maya répartit des milliards de calculs de shaders de surface sur les unités disponibles. Les systèmes de particules en bénéficient également, car ils simulent des milliers de particules en interaction simultanée. Ces fonctionnalités sont au cœur de la création numérique haut de gamme.
Comment les CUDA Cores influencent les performances de GPU

Le nombre de cœurs donne une indication approximative de la capacité d'exécution parallèle, mais les CUDA Cores demandent une analyse plus fine. La vitesse d'horloge, la bande passante mémoire, l'efficacité de l'architecture et l'optimisation logicielle jouent toutes un rôle déterminant.
Un GPU avec 10 000 unités cadencées à 2,0 GHz ne donne pas les mêmes résultats qu'un autre avec 10 000 unités à 1,5 GHz. Une fréquence plus élevée signifie que chaque unité effectue davantage de calculs par seconde. Les architectures récentes font également plus de travail par cycle grâce à un meilleur ordonnancement des instructions.
Vérifiez si vous maintenez l'appareil occupé, mais gardez à l'esprit que nvidia-smi l'utilisation est une métrique imprécise. Elle mesure le pourcentage de temps pendant lequel un kernel est actif, et non le nombre de cœurs en cours d'utilisation.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderExemple de sortie : 85 %, 92 % (85 % de temps actif, 92 % d'activité du contrôleur mémoire)
Si votre GPU affiche 60 à 70 % d'utilisation, vous avez probablement des goulots d'étranglement en amont, comme le chargement de données CPU ou des tailles de batch trop petites. Cependant, même 100 % d'utilisation peut être trompeur si vos kernels sont limités par la mémoire ou mono-threadés. Pour une image fidèle de la saturation des cœurs, utilisez des profileurs comme Nsight Systems pour suivre les métriques « SM Efficiency » ou « SM Active ».
La bande passante mémoire devient souvent le goulot d'étranglement avant même d'atteindre la limite de calcul. Si votre GPU traite les données plus vite que la mémoire ne peut les fournir, les unités restent inactives. Le modèle H100 SXM5 dispose d'une bande passante de 3,35 TB/s pour alimenter ses 16 896 cœurs. La version PCIe, en revanche, descend à 2 TB/s.
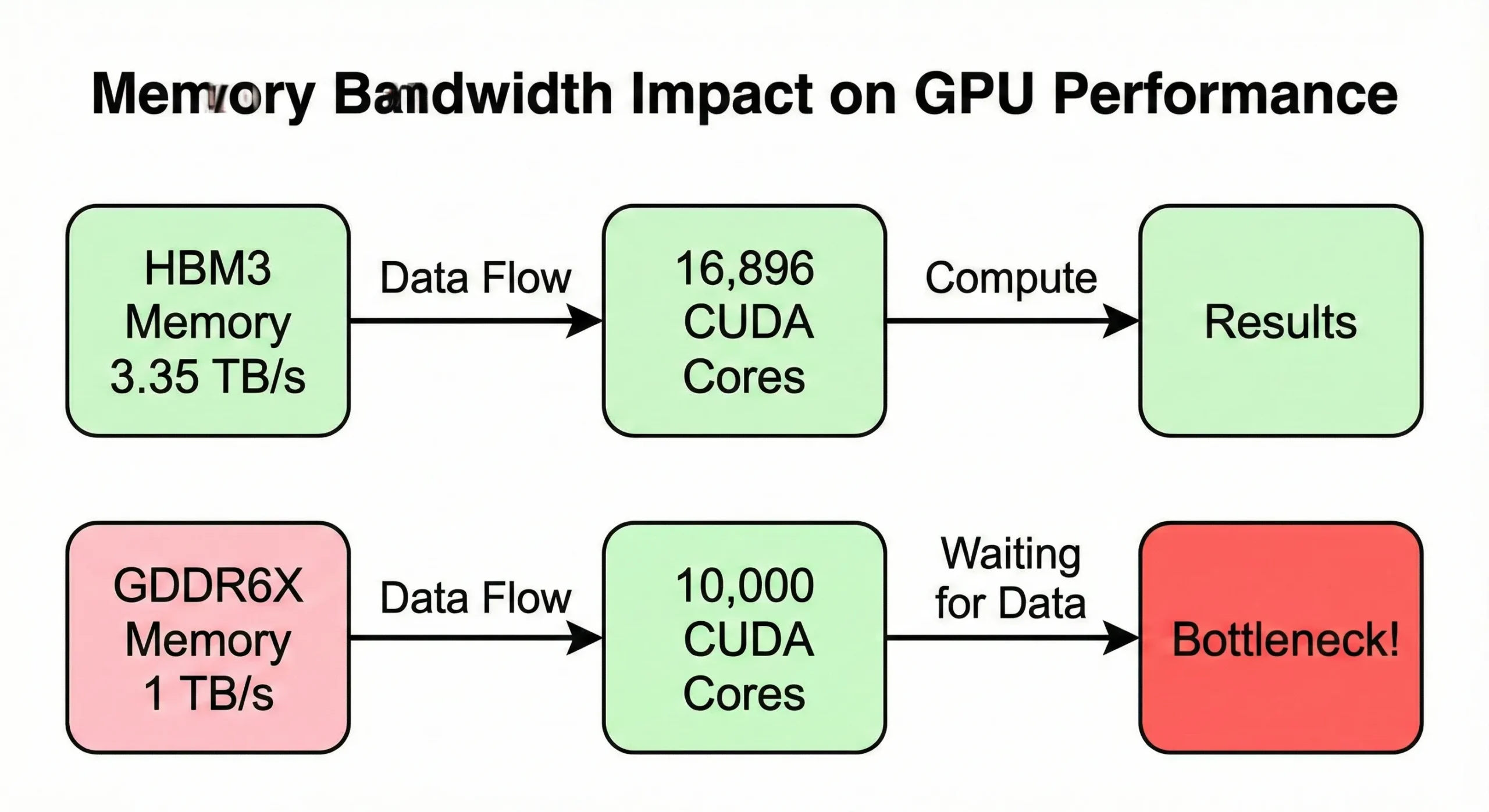
Les GPU grand public avec des nombres de cœurs similaires mais une bande passante plus faible (autour de 1 TB/s) affichent des vitesses réelles réduites sur les opérations intensives en mémoire.
La capacité VRAM détermine la taille de vos tâches. Que ce soit pour des poids FP16 sur un modèle de 70B, l'entraînement complet nécessite davantage de mémoire. Vous devez tenir compte des gradients et des états de l'optimiseur, qui triplent souvent l'empreinte mémoire, sauf si vous utilisez des stratégies de déchargement.
Le A100 80 Go cible l'inférence à haut débit et le fine-tuning. De son côté, le RTX 4090 24 Go, souvent cité pour les modèles 7B, peut étonnamment faire tourner des modèles de 30B+ paramètres avec des techniques de quantification modernes comme INT4. Toutefois, saturer la VRAM force des transferts de données CPU vers GPU qui dégradent sévèrement le débit.
L'optimisation logicielle détermine si votre code exploite réellement toutes ces unités. Des kernels mal écrits peuvent n'utiliser qu'une fraction des ressources disponibles. Des bibliothèques comme cuDNN pour le deep learning et RAPIDS pour la data science sont fortement optimisées pour maximiser l'utilisation.
Plus de CUDA Cores ne signifie pas toujours de meilleures performances

Choisir un GPU avec le plus grand nombre de cœurs semble logique, mais vous gaspillez votre budget si les unités dépassent les capacités des autres composants ou si votre tâche ne tire pas parti du parallélisme.
La bande passante mémoire impose la première limite. Les 21 760 unités du RTX 5090 sont alimentées par 1 792 GB/s de bande passante mémoire. Des GPU plus anciens avec moins d'unités peuvent avoir proportionnellement une bande passante par unité plus élevée.
Les différences d'architecture comptent. Un GPU récent avec 14 000 unités à 2,2 GHz surpasse un GPU plus ancien avec 16 000 unités à 1,8 GHz grâce à un meilleur nombre d'instructions par cycle. Votre code doit être correctement parallélisé pour tirer parti de 20 000 unités.
Pourquoi les CUDA Cores sont importants dans le choix de GPU VPS

Choisir la bonne configuration GPU pour votre VPS vous évite de payer pour des ressources inutilisées ou de vous heurter à des goulots d'étranglement en cours de projet.
Les 80 Go de mémoire du H100 permettent l'inférence sur des modèles à 70 milliards de paramètres avec une quantification 4 bits. Pour l'entraînement complet, en revanche, même 80 Go s'avèrent souvent insuffisants pour un modèle à 34 milliards de paramètres, une fois les gradients et les états de l'optimiseur pris en compte. En entraînement FP16, l'empreinte mémoire augmente considérablement, nécessitant souvent une répartition sur plusieurs GPU.
Les opérations d'inférence servant des prédictions en temps réel nécessitent moins d'unités, mais tirent parti d'une faible latence. Le développement et le prototypage fonctionnent bien avec des GPU de gamme intermédiaire pour tester les algorithmes et déboguer le code.
Un RTX 4060 Ti avec 4 352 unités vous permet de tester sans payer pour un matériel surdimensionné. Une fois votre approche validée, passez aux GPU de production pour les cycles d'entraînement complets.
Le rendu et le traitement vidéo évoluent avec le nombre d'unités, jusqu'à un certain point. Le moteur de rendu Cycles de Blender exploite efficacement toutes les ressources disponibles. Un GPU avec 8 000 à 10 000 unités rend les scènes 2 à 3 fois plus vite qu'un modèle avec 4 000 unités.
Chez Cloudzy, nous proposons un hébergement haute performance le VPS GPU conçu pour les charges de travail intensives. Choisissez le RTX 5090 ou le RTX 4090 pour un rendu rapide et une inférence IA économique, ou montez en puissance avec les A100 pour les workloads deep learning les plus exigeants. Tous les plans s'appuient sur un réseau 40 Gbps, une politique axée sur la confidentialité et des options de paiement en cryptomonnaie - de la puissance brute, sans les contraintes administratives des grandes structures.
Que vous entraîniez des modèles IA, rendiez des scènes 3D ou exécutiez des simulations scientifiques, vous choisissez le nombre de cœurs qui correspond à vos besoins.
Le coût entre en jeu. Un A100 avec 6 912 unités coûte nettement moins cher qu'un H100 avec 16 896 unités. Dans bien des cas, deux A100 offrent un meilleur rapport prix/performance qu'un seul H100. Le point d'équilibre dépend de la capacité de votre code à s'exécuter sur plusieurs GPU.
Comment choisir le bon nombre de cœurs CUDA
Faites correspondre vos besoins aux caractéristiques réelles de vos charges de travail, plutôt que de viser les chiffres les plus élevés du marché.
Commencez par analyser votre charge de travail actuelle. Si vous entraînez des modèles sur du matériel local ou des instances cloud, consultez les métriques d'utilisation du GPU. Si votre GPU actuel affiche systématiquement 60 à 70 % d'utilisation, vous n'êtes pas en train de saturer les unités.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Ce test simple indique si les cœurs de votre GPU délivrent le débit attendu. Comparez vos résultats aux benchmarks publiés pour votre modèle de GPU.
Une mise à niveau n'y changera rien. Commencez par identifier les goulots d'étranglement : mémoire, bande passante ou blocages CPU. Estimez ensuite les besoins en mémoire en calculant la taille du modèle en octets, plus la mémoire d'activation.
Ajoutez la taille de batch multipliée par les sorties de chaque couche, et incluez les états de l'optimiseur. Ce total doit tenir dans la VRAM. Une fois la mémoire nécessaire connue, vérifiez quels GPU répondent à ce seuil.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Tenez compte de vos délais. Si vous avez besoin de résultats en quelques heures, investissez dans plus d'unités. Les cycles d'entraînement pouvant durer plusieurs jours fonctionnent très bien sur des GPU moins puissants, avec des temps d'exécution proportionnellement plus longs.
Coût horaire multiplié par le nombre d'heures nécessaires donne le coût total - ce qui rend parfois les GPU moins rapides plus économiques au final. Testez l'efficacité du passage à l'échelle grâce aux outils de benchmarking intégrés à de nombreux frameworks, qui affichent l'évolution du débit.
Si doubler le nombre d'unités ne donne qu'un gain de 1,5x, le surcoût ne se justifie pas. Cherchez le point optimal où le rapport prix/performance est le plus avantageux.
| Type de charge de travail | Cœurs recommandés | Exemples de GPU | Remarques |
| Développement et débogage de modèles | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Itérations rapides, coûts réduits |
| Entraînement IA à petite échelle (moins de 7 milliards de paramètres) | 6,000-10,000 | RTX 4090, L40S | Convient aux particuliers et aux petites entreprises |
| Entraînement IA à grande échelle (7B-70B paramètres) | 14,000+ | A100, H100 | Nécessite des centres de données GPUs |
| Inférence en temps réel (haut débit) | 10,000-16,000 | RTX 5080, L40 | Équilibrez coût et performance |
| Rendu 3D et encodage vidéo | 8,000-12,000 | RTX 4080, RTX 4090 | S'adapte à la complexité |
| Calcul scientifique et HPC | 10,000+ | A100, H100 | Nécessite la prise en charge FP64 |
Les VPS GPUs les plus populaires et leur nombre de cœurs CUDA

Les différents niveaux de GPU s'adressent à des segments d'utilisateurs distincts. Qu'est-ce que le GPUaaS ? C'est le GPU-as-a-Service : des fournisseurs comme Cloudzy vous donnent accès à ces NVIDIA GPUs puissants à la demande, sans que vous ayez à acheter ni à maintenir le matériel physique vous-même.
| Modèle GPU | Cœurs CUDA | VRAM | Bande passante mémoire | Architecture | Idéal pour |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1 792 Go/s | Blackwell | Station de travail haut de gamme, rendu 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1 008 Go/s | Ada Lovelace | IA haut de gamme, rendu 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3 350 GB/s | Hopper | Entraînement IA à grande échelle |
| H100 PCIe | 14,592 | 80GB HBM2e | 2 000 GB/s | Hopper | IA en entreprise, datacenter économique |
| A100 | 6,912 | 40/80 Go HBM2e | 1 555-2 039 GB/s | Ampere | IA milieu de gamme, fiabilité éprouvée |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming, IA intermédiaire |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Datacenter multi-charges |
Les cartes grand public RTX (4070, 4080, 4090, 5080, 5090) visent les créateurs et les gamers, mais conviennent bien au développement IA. Elles offrent une vitesse GPU élevée par cœur à des prix inférieurs aux cartes datacenter.
Les fournisseurs VPS proposent souvent ces cartes pour les budgets serrés. Les cartes datacenter (A100, H100, L40) privilégient la fiabilité, la mémoire ECC et la montée en charge multi-GPU. Elles sont conçues pour fonctionner en continu et prennent en charge des fonctionnalités avancées.
Le mode Multi-Instance GPU (MIG) permet de diviser un GPU en plusieurs instances isolées. Malgré les alternatives plus récentes, le A100 reste populaire grâce à ses caractéristiques équilibrées.
Son rapport entre cœurs NVIDIA, mémoire et prix en fait le choix sûr pour la plupart des charges IA en production. Le H100 propose 2,4 fois plus d'unités, mais à un coût nettement plus élevé.
Conclusion
Les moteurs de traitement parallèle rendent possibles l'IA moderne, le rendu et le calcul scientifique. Comprendre leur fonctionnement et leurs interactions avec la mémoire, les fréquences d'horloge et les logiciels vous aide à choisir les configurations GPU VPS adaptées.
Un plus grand nombre d'unités est utile lorsque vos tâches se parallélisent efficacement et que des éléments comme la bande passante mémoire suivent. Mais viser aveuglément le nombre de cœurs le plus élevé est inutile si vos goulots d'étranglement sont ailleurs.
Commencez par analyser vos charges réelles, identifiez où le temps est perdu, puis faites correspondre les caractéristiques du GPU à ces besoins sans acheter de capacité superflue.
Pour la plupart des projets de développement IA, entre 6 000 et 10 000 unités offrent le meilleur compromis entre coût et performance. Les charges de production entraînant de grands modèles ou gérant une inférence à haut débit bénéficient de GPU avec 14 000 unités ou plus, comme le H100.
Le rendu et le travail vidéo évoluent efficacement jusqu'à environ 16 000 unités, au-delà desquelles la bande passante mémoire devient le facteur limitant.


