
Megnyitod egy népszerű modell GGUF oldalát a Hugging Face-en, és tizenöt fájl néz vissza rád: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plusz külön mappák GPTQ-hoz, AWQ-hoz és EXL2-höz fél tucat bitbeállításban. Elvégzed a fejszámolást a "4-bites" fájlra: 4 bit × 8 milliárd paraméter ÷ 8 = 4 GB. De a fájl 4,6 GB-ot mutat. És miután betöltötted, a modell még ennél is több memóriát használ.
A fájlnevek nem zaj. Valós, megtanulható információt kódolnak a bitszélességről, a betöltő futtatókörnyezetről és a szükséges hardverről. Az általad olvasott méretezési táblázatok azt mondják, egy 70B-s modellhez nagyjából 40 GB kell, ez hasznos, de sosem fejtik meg magát a formátumot, és nem magyarázzák meg, miért kér a futó modell több memóriát, mint a lemezen lévő fájl.
Íme tehát a terv: fejtsük meg a GGUF elnevezési konvenciót (a valós, nem a névleges bitszélességekkel), tisztázzuk, hogy a négy formátum közül melyiket tudja ténylegesen futtatni a hardvered, és számoljunk azzal az egyetlen memóriaköltséggel, amely minden fájlméretben láthatatlan: a KV cache-sel. A végére képes leszel elolvasni egy modell-repót, és megjósolni, hogyan fog viselkedni betöltéskor.
Röviden
- A GGUF kvantálási szintek effektív bitszélességek, nem a névben szereplő pontos szám. A Q4_K_M nagyjából 4,89 bit súlyonként, ezért egy "4-bites" 8B-s fájl nagyjából 4,6 GiB-nál landol, nem a naiv 4-bites becslésnél.
- A GGUF a legjobban hordozható lehetőség, mert a llama.cpp CPU-n, GPU-n vagy hibrid elrendezésben is tudja futtatni. A GPTQ, az AWQ és az EXL2 inkább GPU- és futtatókörnyezet-specifikus, az EXL2 pedig különösen az NVIDIA/CUDA-munkafolyamatokhoz kötődik.
- A KV cache elkülönül a modell súlyaitól, és a kontextushosszal együtt növekszik. Ez az oka annak, hogy egy tisztán betöltődő modell mégis összeomolhat memóriahiánnyal, amint a beszélgetés hosszúra nyúlik.
- Az 5-bites tartomány felett a minőségromlás általában kicsi. A Q4 körül az átváltás még mindig praktikus sok helyi felhasználási esetre. 4 bit alatt a minőségköltség sokkal jobban érezhetővé válik. A Q4_K_M továbbra is gyakori közösségi alapértelmezés, míg a Q5_K_M és a Q6_K biztonságosabb, ha van felesleges memóriád.
Mit jelent a Q4_K_M egy GGUF fájlnévben?

Egy GGUF kvantálási név a Q[bit]_[K]_[S/M/L] mintát követi. A szám a cél- bitek/súly számot jelöli, a K azt jelenti, hogy "K-kvant", amely skálázási tényezőket tárol a súlyok kis blokkjai szerint, a végén álló S, M vagy L pedig a méret-/minőségi szint (small, medium, large). Mivel a K-kvantok minden blokkhoz tárolnak egy skálát és egy minimumértéket a súlyok mellett, a effektív bitszélesség magasabb, mint a névben szereplő szám. A Q4_K_M nagyjából 4,89 bitnél landol súlyonként, nem 4-nél.
Ez a különbség a teljes válasz arra a kérdésre, hogy "miért 4,6 GB a 4-bites fájlom?". A naiv becslés azt feltételezi, hogy minden súly pontosan 4 bitbe kerül. A valóságban a K-kvantok extra biteket költenek blokkonként arra a metaadatra, amely pontossá teszi az alacsony bites kvantálást, vagyis a blokkonkénti skálára és minimumértékre, amely lehetővé teszi a futtatókörnyezet számára az egyes súlyok rekonstruálását. Szorozd meg a 4,89 bitet 8 milliárd súllyal, és nagyjából 4,58 GiB-nál landolsz, ez az, amit a fájl valójában nyom.
Íme a mért effektív bitszélességek és fájlméretek, a llama.cpp quantize documentation referenciamodellként a Llama 3.1 8B-t használva, valamint az egyes szintek perplexitási költsége, amelyet a llama.cpp kvantálásértékelő tanulmányában mértek (arXiv:2601.14277) a Llama-3.1-8B-Instruct modellen:
| GGUF szint | Effektív BPW | ~Fájlméret (8B) | Perplexitás vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | alapérték |
*A perplexitási számok kifejezetten a Llama-3.1-8B-Instructra vonatkoznak az arXiv:2601.14277 alapján. A BPW/fájlméret oszlop és a perplexitás oszlop két különböző, külön-külön mért forrásból származik, ezért a táblázatot inkább gyakorlati, egymás mellé állított referenciaként érdemes kezelni, nem pedig egyetlen benchmark-futtatásként. A feladatspecifikus romlás mértéke változó, a matematikai következtetés általában jobban szenved, mint a józan ész alapú következtetés alacsony bitszélességeknél, de a nagy vonalak megmaradnak: az 5 bit és afölött általában biztonságosabb, a Q4 a gyakorlati tömörítési zóna, a 3 bit pedig az a tartomány, ahol a minőségromlást már sokkal nehezebb figyelmen kívül hagyni.
Gyakorlatilag: a Q4_K_M az az alapértelmezett, amelyet a legtöbb embernek érdemes választania, a Q5_K_M és a Q6_K a minőségorientált választás, ha van felesleges memóriád, és minden, ami Q3_K_S vagy az alatt van, csak végső megoldás olyan hardverhez, amely valóban nem tud többet befogadni.
Melyik kvantálási formátumot töltsd le: GGUF, GPTQ, AWQ vagy EXL2?

A GGUF a négy közül a leginkább hordozható: CPU-n, GPU-n vagy mindkettő hibrid kombinációján fut a llama.cpp segítségével, így ez a legbiztonságosabb választás, ha nem vagy biztos benne, mit támogat a hardvered. A GPTQ, az AWQ és az EXL2 inkább GPU- és futtatókörnyezet-specifikus. A gyakorlatban leginkább NVIDIA/CUDA elrendezéseken terjedtek el, de a GPTQ és az AWQ támogatása betöltőnként és kiszolgáló-stack-enként eltérhet; a vLLM például hardver és implementáció szerint különíti el a kvantálástámogatást. Ha Macen, AMD-kártyán vagy csak CPU-t tartalmazó gépen futtatsz helyben, a GGUF továbbra is a legbiztonságosabb válasz. Ha NVIDIA GPU-d van, és a lehető leggyorsabb tokeneket akarod, a másik három jön szóba.
| Formátum | Hardver/futtatókörnyezet | Sebesség (relatív) | VRAM a versenytársakhoz képest | A legjobb választás: |
|---|---|---|---|---|
| GGUF Q4_K_M | A legszélesebb körű, CPU, GPU vagy hibrid a llama.cpp-n keresztül | Mérsékelt | Legalacsonyabb | Bármilyen hardver; helyi alapértelmezés |
| GPTQ 4-bites | Általában elsősorban CUDA/GPU; futtatókörnyezettől függő | Gyors (ExLlama) | Közepes | Elsősorban GPU, örökölt eszközkészlet |
| AWQ 4-bites | Általában elsősorban CUDA/GPU; futtatókörnyezettől függő | Gyors | Legmagasabb | vLLM/TGI kiszolgálás, gyors betöltés |
| EXL2 ~4,9 bpw | Elsősorban NVIDIA/CUDA | Leggyorsabb | Alacsony-Közepes | Maximális sebesség NVIDIA-n |
Egy megjegyzés a táblázathoz: a sebesség- és VRAM-rangsorok a oobabooga benchmarkbólszármaznak, amelyet 2023/2024 korabeli hardveren futtattak. Kezeld a relatív relatív sorrendet tartósnak. Az EXL2 sebességre lett tervezve, az AWQ VRAM-ot cserél gyors betöltésre, a GGUF marad karcsú és hordozható, de ne olvasd az eredeti abszolút tokens/másodperc számokat aktuálisnak. Egy 2026-os GPU nagyon eltérő nyers átviteli sebességet fog produkálni; ami továbbra is érvényes, az a rangsor.
Az ebből levonható döntési szabály tehát: ha van NVIDIA kártyád, és leginkább a sebesség érdekel, EXL2; ha a legbiztonságosabb helyi alapértelmezést akarod különböző hardvereken keresztül, GGUF. Az AWQ és a GPTQ leginkább akkor számít, ha egy adott kiszolgáló-stack (vLLM, TGI) vagy meglévő eszközkészlet abba az irányba terel.
Miért használ egy helyi LLM több memóriát, mint amennyi a fájlja?
A fájlméret csak a modell súlyait tartalmazza. Futás közben fizetsz még a KV cache-ért is (a figyelmi állapot a kontextusablak minden egyes tokenjéhez), az aktivációkért (egy előrehaladó lépés köztes matematikájáért), valamint a keretrendszer és az illesztőprogram overheadjéért. Ezek a nem súly jellegű részek egy egyfelhasználós elrendezésnél tipikusan 10-20%-kal növelik a súlyok tetejére a memóriaigényt, és a KV cache önmagában is elnyomhat mindent, ha a kontextus hosszúra nyúlik. Egy 4,6 GB-os fájl futtatásához jóval több mint 4,6 GB memóriára lehet szükség.
Gondolj a futásidejű memóriára úgy, mint négy komponensre, amelyek egymásra vannak halmozva:
- Modell súlyok. A letöltött fájl. Ez az egyetlen rész, amely a betöltés előtt látható.
- KV cache. Figyelmi állapot a kontextusablakhoz. Rövid kontextusnál kicsi, hosszú kontextusnál óriási. Ez a következő szakasz témája, mert ez az, ami meglepi az embereket.
- Aktivációk. Egy előrehaladó lépés munkamemóriája. Egyszálú, helyi következtetésnél (batch size 1) ez kicsi, jellemzően néhány száz megabájt.
- Keretrendszer overhead. A futtatókörnyezet saját lábnyoma plusz a GPU-illesztőprogram kontextusa. Egy könnyű, helyi futtatókörnyezet esetén ez kicsi lehet a modell súlyaihoz és a KV cache-hez képest; a nehezebb kiszolgáló-keretrendszerek sokkal többet is lefoglalhatnak. Az operációs rendszer saját memóriafoglalása ezen kívül esik, és megint csak külön kezelendő.
A súlyok és a keretrendszer overheadje kiszámíthatók. A KV cache az a változó, amely egy "elférő" modellt összeomló modellé alakíthat, ezért érdemes végigszámolni a valós matematikát.
Mennyi memóriát használ a KV cache?
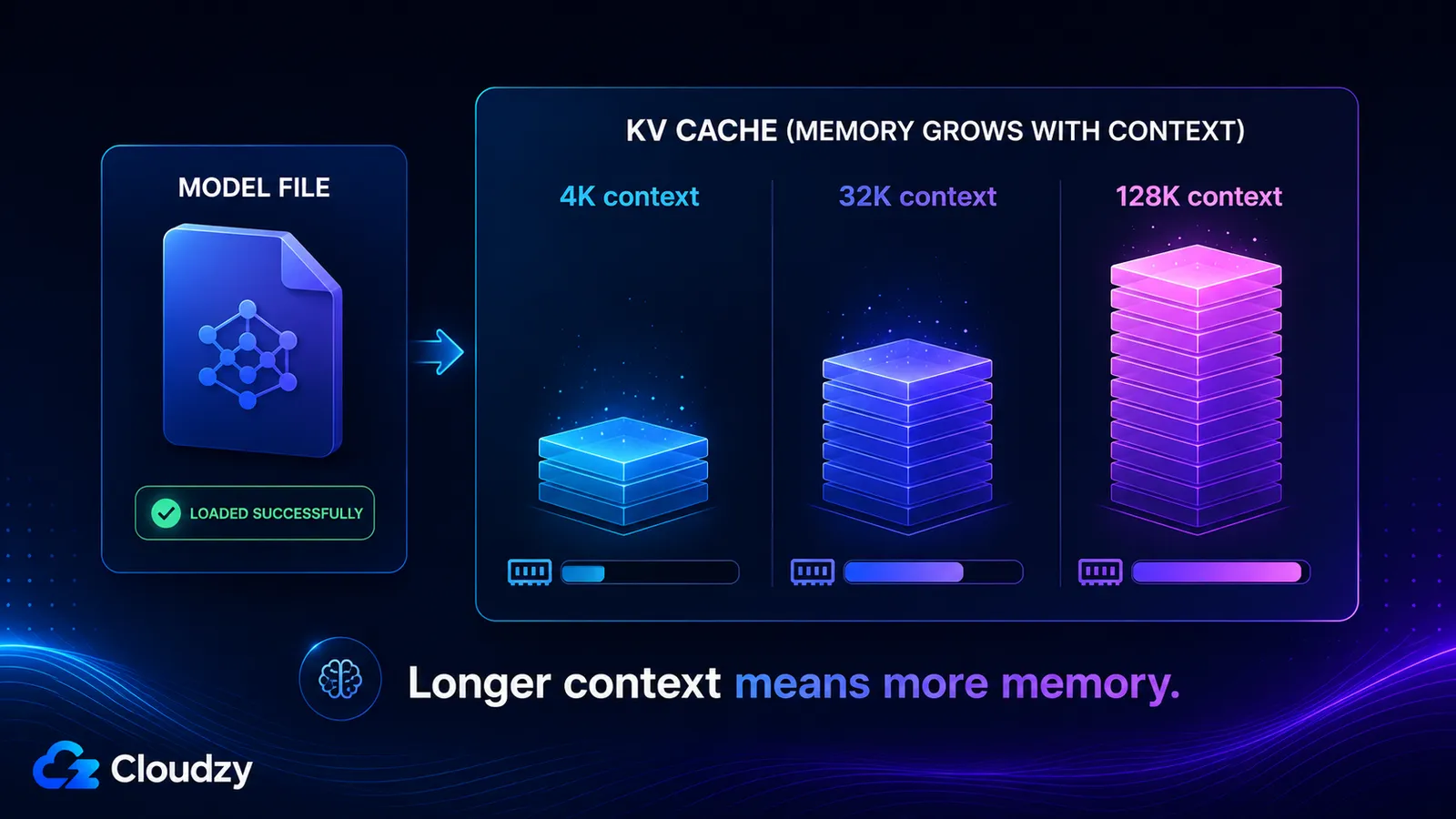
A KV cache tárolja a kulcs- és értékvektorokat a kontextusablak minden egyes tokenjéhez, így nagyjából lineárisan növekszik a kontextushosszal, és teljesen elkülönül a modell súlyaitól. Méretét a modell rétegszáma, a KV-fejek száma, a fej dimenziója, a kontextushossz és a cache pontossága határozza meg. Kapcsolj be egy hosszú kontextust, és tíz gigabájtokat is hozzáadhatsz, amiről egy amúgy hibátlanul betöltődő modell soha nem figyelmeztetett.
A képlet elég rövid ahhoz, hogy fejben tartsd:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
A kezdő 2-es a tokenenként tárolt két tenzorra utal, egy a kulcsokhoz, egy az értékekhez. A bytes_per_element FP16 cache esetén 2. A többi olyan architektúra-konstans, amelyet le tudsz olvasni egy model cardról.
Számold ki a Llama 3.1 8B-hez, amelynek 32 rétege, 8 KV-feje és 128-as fejdimenziója van. 4096 tokenes kontextusnál, batch size 1, FP16 cache mellett:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Skálázd fel a kontextust, és a szám vele együtt skálázódik, mert minden tag a context_tokens kivételével fix:
- 4K kontextus: ~536 MB
- 32K kontextus: ~4,3 GB
- 128K kontextus: ~17 GB
Ez az utolsó két érték magyarázza, miért jelenthet ki egy modell 128K kontextusablakot, tölthet be gond nélkül, majd fogyaszthatja el a memóriát abban a pillanatban, amikor ténylegesen használod azt az ablakot. A teljes kontextusnál a KV cache nagyobb, mint maguk a kvantált súlyok.
Íme az a rész, ami egyáltalán lehetővé teszi a modern, hosszú kontextusú modelleket: a Llama 3.1 8B Grouped Query Attention (GQA)ezt használja. 32 lekérdezési (query) feje van, de csak 8 KV-feje, a cache 8 fejhez tárol kulcs/érték vektorokat, nem 32-höz. Futtasd le ugyanazt a képletet 32 KV-fejjel (a régebbi Multi-Head Attention elrendezés, ahol a KV-fejek száma megegyezik a lekérdezési fejek számával), és minden fenti szám 4-gyel szorzódik. Az a bizonyos 17 GB 128K-nál 68 GB-ra nő. A GQA az architekturális oka annak, hogy a matematika kezelhető maradt, ahogy a kontextusablakok nőttek.
A fájlméret nem a memóriakereted. Amikor a súlyok vagy a KV cache már nem férnek el a gyors memóriaútvonalon, és a futtatókörnyezetnek vissza kell esnie a rendszer RAM-ra PCIe-n keresztül, az átviteli sebesség nem finoman romlik. Zuhanásszerűen esik, amint minden egyes tokennél PCIe-n keresztül mozgatod az adatokat. Úgy tervezd meg a memóriát, hogy a valós kontextushosszadnál mind a súlyok, mind a KV cache elférjen, ne csak a súlyok.
Hogyan válassz kvantálást a GPU-dhoz vagy Machez?
Kezdd a hardvereddel és a futtatókörnyezeteddel. Az NVIDIA GPU tulajdonosoknak van a legszélesebb választékuk, és érdemes mérlegelniük az EXL2-t a nyers sebességért vagy a GGUF-ot a hordozhatóságért. Ha AMD-n, Apple Siliconön, csak CPU-t tartalmazó hardveren vagy vegyes elrendezésen dolgozol, a GGUF a llama.cpp-n keresztül általában a legbiztonságosabb kiindulópont. Innentől válaszd a legmagasabb kvantálási szintet, amely elfér, miután megterveztél a KV cache-hez a ténylegesen használt kontextushosszon, nem a modell maximumán.
Egy Apple Silicon-csapda, amelyet érdemes ismerni: a GPU nem kapja meg az összes unified memoryd (nézd meg a kísérőcikkünket arról, hogy valójában mi is az unified memory a teljes képért, hogyan is működik az a megosztott pool). Az önüzemeltetői közösség dokumentált egy nagyjából 75%-os korlátot a GPU számára elérhető teljes unified memóriából (ezt az Apple hivatalosan nem erősítette meg, és macOS-frissítésekkel változhat). Így egy "64 GB-os Mac" realisztikusan nagyjából ~48 GB-ot jelent a modellhez plusz a KV cache-hez, a tervezésnél a kisebb számmal számolj.
Ez a cikk arról szól, hogyan olvasd a formátumot, és hogyan jósold meg a futásidejű viselkedését: fejtsd meg a kvant nevét, válaszd ki azt a formátumot, amelyet a hardvered támogat, és tervezd meg a KV cache-t külön a súlyoktól. Egy adott modell összepárosítása egy adott memóriamennyiséggel, a méret-memória megfeleltető táblázat, ehhez kapcsolódó, de külön kérdés, amelyet egy jövőbeli kísérőcikkben tárgyalunk.
Olvasd el a repót
Mostantól úgy nézhetsz egy modell oldalára, hogy tényleg elolvasod, nem csak találgatsz. Fejtsd meg a kvant nevét az effektív bitszélességére, ismerd fel, hogy a GGUF a legszélesebb körű helyi formátum, míg a GPTQ, az AWQ és az EXL2 inkább futtatókörnyezet-specifikus, és ne feledd, hogy a fájlméret csak az alap, a KV cache erre rakódik rá, és a kontextusoddal együtt nő. Nyisd meg a kívánt modell fájljait, válaszd ki azt a formátumot, amelyet a hardvered futtatni tud, válaszd a legmagasabb kvantálási szintet, amely elfér, miután hagytál helyet a KV cache-nek a valós kontextushosszadnál, és elkerülöd azt a memóriahiányos összeomlást, amely ezt az egész kérdést elindította.
Gyakran ismételt kérdések
Mit jelent a Q4_K_M?
A Q4_K_M egy GGUF kvantálási szint: nagyjából 4 bit súlyonként (Q4), K-kvant blokkonkénti skálázással (K), közepes méret-/minőségi szinten (M). A effektív bitszélessége nagyjából 4,89 bit súlyonként, nem pontosan 4, mert a K-kvantok minden súlyblokkhoz tárolnak egy skálát és egy minimumértéket. Ezért van az, hogy egy "4-bites" 8B-s modellfájl nagyjából 4,6 GB, nem 3,5 GB.
Csökkenti a kvantálás az LLM minőségét?
Igen, de a költség nagyban attól függ, mennyire mész el vele messzire. A Llama-3.1-8B-Instructon, az arXiv:2601.14277 mérése szerint, a perplexitás mindössze nagyjából 0,4%-kal nő Q6_K-nál, és a Q5 sávban is 1% közelében marad. Ha lemész Q4-re, a növekedés még mindig szerény (néhány százalék); Q3_K_M alatt meredeken emelkedik, elérve a +22%-ot Q3_K_S-nél. A legtöbb felhasználásra a Q4_K_M és afölötti szintek gyakorlatilag veszteségmentesek; a meredek büntetés 3 bitnél és az alatt kezdődik.
Mi a különbség a GGUF, a GPTQ, az AWQ és az EXL2 között?
A GGUF (amelyet a llama.cpp futtat) a hordozható formátum, CPU-n, GPU-n vagy hibrid elrendezésben is működik, hardverek széles körén keresztül. A GPTQ, az AWQ és az EXL2 inkább GPU- és futtatókörnyezet-specifikus. 4 biten mind a négy egy szűk minőségi sávban landolhat, így a gyakorlati különbség a hardver, a betöltő-támogatás, a sebesség és a VRAM-használat: az EXL2 a sebességre fókuszáló NVIDIA/CUDA választás, az AWQ gyakori a kiszolgáló-stackekben, a GPTQ illik a régebbi GPU-eszközökhöz és modell-repókhoz, a GGUF pedig a leginkább hordozható helyi opció marad.
Miért használ a helyi LLM-em több memóriát, mint amennyi a fájl?
A fájlméret csak a modell súlyait tartalmazza. Futás közben fizetsz még a KV cache-ért (a figyelmi állapotért a kontextusablak minden tokenjéhez), az aktivációkért, valamint a keretrendszer és az illesztőprogram overheadjéért. A KV cache a szokásos bűnös, ha nagy az eltérés, mert a kontextushosszal együtt nő, és a súlyoktól elkülönítve foglal helyet, egy olyan modell, amelynek fájlja néhány gigabájt, sokkal több memóriát igényelhet, amint hosszú kontextust állítasz be.
Hogyan hat a kontextushossz a memóriahasználatra?
A KV cache nagyjából lineárisan nő a kontextushosszal, így a kontextus megkettőzése nagyjából megkettőzi a cache-t is. A Llama 3.1 8B esetén a cache nagyjából 536 MB 4K tokennél, ~4,3 GB 32K-nál, és ~17 GB 128K-nál (FP16, egyszálú). Ez a növekedés teljesen elkülönül a modell súlyaitól, ezért fordulhat elő, hogy egy hosszú kontextusablak deklarálása memóriahiányba sodorhat egy modellt, még akkor is, ha az egyébként rendben betöltődött.


