
ローカルLLMの需要が高まり続ける中、多くのユーザーは最適なものを選択する際に混乱しています。しかし、使用することはあなたが思うほど簡単ではありません。かなりの電力を消費するため、中にはそれに近づくことを避ける者もいます。初心者がターミナルの前で費やす多くの時間を言うまでもなく。
しかし、生活をシンプルにする2つの有力な候補があります。OllamaとLM Studioは、ローカルLLMを実行するための最も広く使用されているプラットフォームの2つで、高いパフォーマンスを備えています。ただし、各プラットフォームが異なるワークフロー向けに設計されているため、2つを選択することは難しい場合があります。それでは、Ollama対LM Studioの比較を見てみましょう。
技術者向けツールとしてのOllama
ローカルXQNT0023Zランナーの点では、Ollamaは多くの機能のおかげで強力な選択肢です。高度な設定可能性があるだけでなく、コミュニティが支援するオープンソースプラットフォームであるため、無料でアクセスできます。
OllamaはローカルLLMの実行をシンプルにしていますが、CLI-first(コマンドラインインターフェース)なため、ターミナルの知識が必要です。CLI-firstは開発ワークフロー向けに大きな利点があります。CLIを扱うのは簡単なタスクではありませんが、ローカルLLMを自分で実行するよりも理解するのにかかる時間は少なくなります。
OllamaはあなたのパーソナルコンピュータをHTTP API搭載のローカルミニサーバーとして機能させ、アプリとスクリプトが多くのモデルにアクセスできるようにします。つまり、データをクラウドに送信することなく、オンラインのLLMと同じ方法でプロンプトに応答します。さらに、APIによってユーザーはOllamaを統合し、ウェブサイトやチャットボットに接続できます。
CLI特性のため、Ollamaは非常に軽量で、リソース消費が少なく、パフォーマンスに焦点を当てています。ただし、これはあなたがどんなコンピュータでも実行できるという意味ではありませんが、リソースを絞り出してLLMモデル自体に注ぎ込みたいユーザーにとってはまだ有望です。
これまでのところ、Ollamaが開発ワークフローに大きく焦点を当てていることに気付いたかもしれません。その通りです。統合の容易さ、ローカルプライバシー、API-first設計のおかげで、開発者志向の考え方を持っている場合は、選択するのに迷いがありません。
Ollama対LM Studioの議論において、OllamaはAPI-first開発によってより好まれる可能性があります。CLIランタイムが非常に不慣れな場合は、使いやすさを重視した軽量なオプションが登場するまで待ってください。
LM Studio: ユーザーフレンドリーなオプション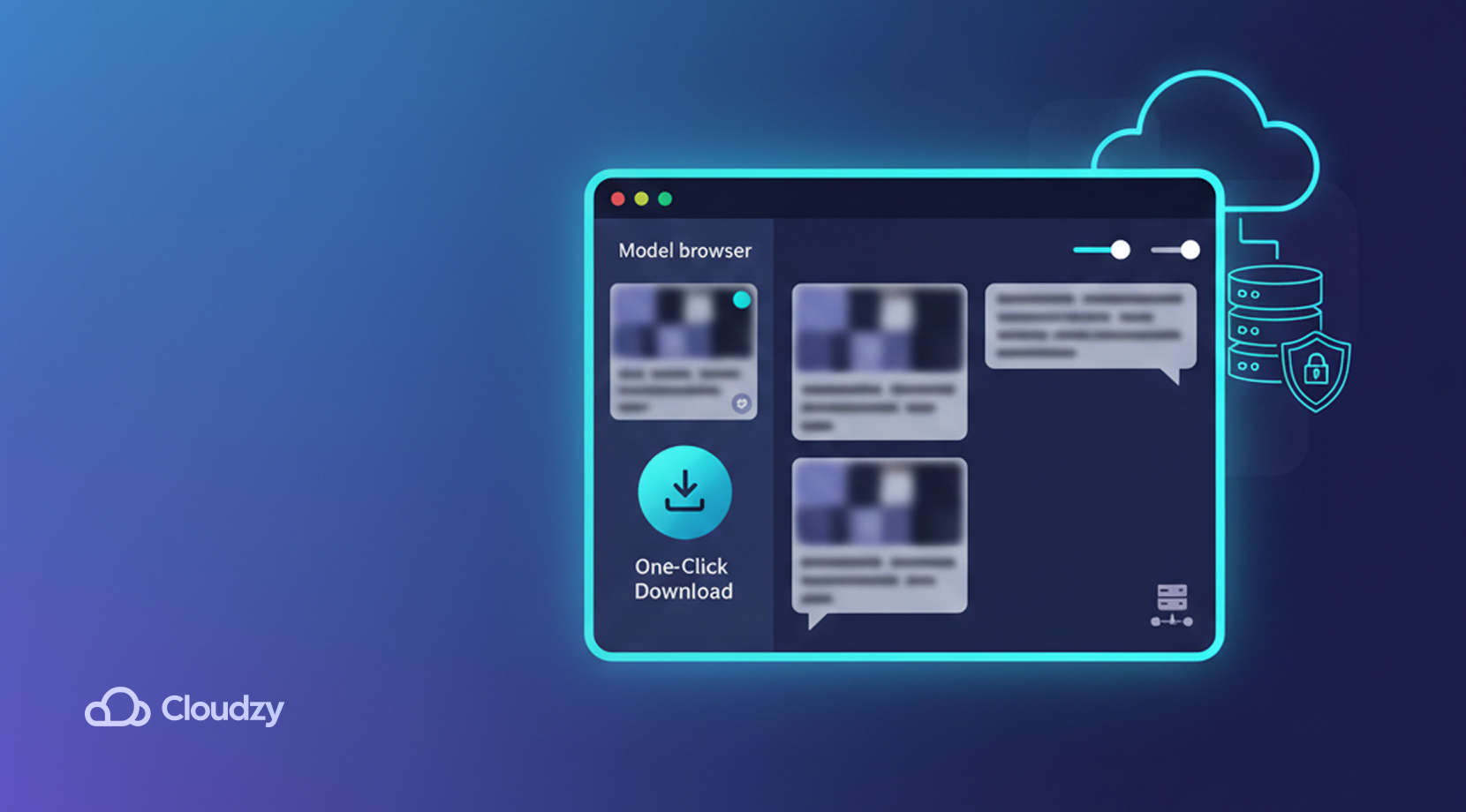
LM StudioはOllamaとは大きく対比しています。フル機能のCLIインターフェースではなく、ターミナルコマンドを実行する必要はなく、GUI(グラフィカルユーザーインターフェース)を備えているため、他のデスクトップアプリと同じように見えます。初心者にとって、Ollama対LM Studioはシンプルなクリ対GUIの比較になります。
技術的な障壁を取り除く方法により、LM Studioはどのユーザーにも対応するシンプルなスペースを提供します。コマンドラインでモデルを追加して実行する代わりに、提供されたメニューを使用してチャットボックスのようなボックスに入力するだけです。LM StudioはChatGPTのようにシンプルに見えるため、誰でもローカルLLMを試すのに使用できるようです。
さらに、ユーザーが好みのモデルを検出してデプロイできるネットアプリモデルブラウザが付属しています。軽量なモデルから日常的なアクション向けから、より困難なタスク向けの高性能なものまでさまざまです。さらに、このブラウザは利用可能なモデルの簡潔な説明と推奨される使用例を提供し、ユーザーはワンクリックでモデルをダウンロードできます。
ほとんどのモデルは無料でダウンロードできますが、追加のライセンスや利用規約が含まれる場合もあります。ワークフローによっては、LM Studioがローカルサーバーモードを提供して統合を簡単にすることもできますが、基本的には初心者向けのシンプルなデスクトップUIを中心に設計されています。いずれにせよ、OllamaとLM Studioを並べて比較してみましょう。
注目すべき比較: Ollama vs LM Studio
進める前に、重要な点を指摘しておく必要があります。「Ollama vs LM Studio」というフレーズは、一方が客観的に優れていることを示唆するかもしれませんが、それは事実ではありません。この2つは異なるユーザーを想定して設計されています。OllamaとLM Studioの簡単な比較を以下にまとめました。
| 機能 | Ollama | LM Studio |
| 使いやすさ | 最初は使いやすくない。ターミナルの知識が必要 | 初心者向け。マウスでクリックして操作する |
| モデルサポート | 多くの人気のあるオープンウェイトモデル: gpt-oss、gemma 3、qwen 3 | Ollamaと同じ。gpt-oss、gemma3、qwen3 |
| カスタマイズ | 高度なカスタマイズ性。APIを使った統合が簡単 | カスタマイズの自由度は低い。トグルやスライダーで一般的な設定を調整 |
| ハードウェア要件 | それは状況次第です、十分なハードウェアがないと、より大きなモデルは遅くなります | こちらもモデルサイズとお使いのハードウェアに依存します |
| プライバシー | プライバシーがデフォルトで保護されている。外部のAPIは不要 | チャットはローカルに保存されます。ただし、アプリはアップデートやモデルの検索・ダウンロードのためにサーバーと通信します |
| オフライン使用 | モデルをダウンロードすればオフライン対応が完全 | モデルをダウンロード後、オフライン対応も優秀です |
| 利用可能なプラットフォーム | Linux、Windows、macOS | Linux、Windows、macOS |
- 高度なモデルはハードウェア負荷が課題: より大きく、より高性能なモデルを使える場合、ほとんどの人がそうします。しかし、ほとんどのノートパソコンでそれらを実行すると、大きなモデルがRAMとVRAMを大量に消費するため、深刻な問題が生じる可能性があります。これにより、応答が遅くなったり、コンテキスト長が制限されたり、モデルがまったく読み込まれなくなったりすることがあります。
- バッテリーの問題: LLMをローカルで実行すると、高い負荷がかかると電池が急速に消耗します。バッテリー駆動時間が短くなるだけでなく、ファンやヒートシンクが出す音も煩わしいでしょう。
Ollama vs LM Studio: モデルの取得方法
OllamaとLM Studioのもう一つの違いは、モデルの取得方法です。前述の通り、Ollamaは1クリックでローカルのLLMsをインストールしません。代わりに、ネイティブターミナルとコマンドラインを使う必要があります。ただし、コマンドは理解しやすいものです。
Ollamaでモデルを実行する簡単な方法を紹介します。
- ollama pull gpt-ossと入力するか、好みの別のモデルを入力して、好きなモデルを取得します。(ライブラリから選べるタグを必ず含めてください。)
例: ollama pull gpt-oss:20b - その後、ollama run gpt-ossコマンドを使ってモデルを実行できます
- 追加のコーディングツールも同様に追加できます。例えば ollama launch claude でClaudeを追加できます。
ターミナルやコマンドに慣れていない場合は、LM Studioを試してみてください。動作を開始してモデルをダウンロードするためにターミナルに何かを入力する必要はありません。組み込みのモデルダウンローダーにアクセスして、LlamaやGemmaなどのキーワードでLLMsを検索するだけです。
別の方法として、検索バーにHugging Face URLsの全文を入力することもできます。
任意の場所からディスカバータブにアクセスするオプションさえあります。以下を押すことで ⌘ + 2 MacまたはMac上で、または Ctrl + 2 Windows / Linux 上で
Ollama: 速度で優位に立つ
ユーザーと企業にとって、速度が唯一の問題となることもあります。OllamaとLM Studioの速度を比較すると、Ollamaの方が高速ですが、これは構成やハードウェアの設定によって異なる可能性があります。
r/ollamaサブレディットで報告されたあるユーザーの例ではOllamaはLM Studioより高速に処理しました。
これは根拠のない主張ではありません。ユーザーはqwen2.5:1.5bを5回実行してOllamaとLM Studioの両方をテストし、平均トークン/秒を計算しました。
Ollama対LM Studio: パフォーマンスとハードウェア要件
パフォーマンスでは、Ollama対LM StudioはUIの問題というより、むしろハードウェアの問題になります。初めてローカルLLMsを使用することは、私たちが慣れているクラウドLLMsとは明らかに異なります。自分専用のLLMを持つことは素晴らしく感じられますが、パフォーマンスの限界に達するまでの話です。
ここ数年、RAMとVRAMの価格が急騰しているため、大規模なLLMsを実行するのに十分なパワーでマシンを装備するのは非常に困難です。
人気モデルはGoで24~64GBのRAMを消費する傾向があります
その通りです。ハードウェア要件は、Ollama対LM Studioのどちらが優れているかという問題ではありません。遅延や失敗なく人気のある中規模~大規模モデルを滑らかに実行したい場合、最良の選択肢は24~64GBのRAMをインストールすることです。ただし、ほとんどの場合、より長いコンテキストと重いワークロードでは、その量のRAMでさえ無関係になります。
ただし、8~16GBのRAMで、量子化されたモデルと呼ばれることもある小規模モデルを実行することはできますが、より大規模なものと同じ利便性やパフォーマンスは得られません。それに加えて、品質と速度のトレードオフが存在します。残念ながら、RAMだけが問題ではなく、他のコンポーネントも高性能である必要があります。
強力な GPU は、ストレスを抑えるための基盤となります
モデルはCPUs上で実行できますが、グラフィックスプロセッシングユニットはモデルを実現するのに重要な役割を果たします。高速なGPUと十分なVRAMがないと、トークン単位の遅い生成、長い応答の遅延が発生し、すぐに耐えられなくなります。
期待は禁物です。何を隠そう RTX 5070TiもRTX 5080も 本格的なディープラーニングには十分ではありません。その理由は、60k+コンテキストセットアップの場合、Ollama自体が約23GBのVRAMを必要としますが、これらのGPUsから得られる一般的な16GBのVRAMよりもはるかに多いです。
その電力範囲以上をGoするにはもの凄く高額になります。価格が問題でなければ、ローカルLLMsを実行する際に考慮すべき点がまだいくつかあります。 GPUオプション を考慮する必要があります。
ここまで来ると、より大規模なローカルLLMモデルを実行するのに十分な能力を持つマシンを組み立てる方法についても、混乱しているかもしれません。これは、多くの人々が異なるソリューションを検討する転機となります。
愛好家が検討する別のアプローチは、堅牢で事前インストールされたハードウェアを備えた仮想マシンを使用することです。例えば、VPS (仮想プライベートサーバー) を使用することは、ホームラップトップまたは他の個人用ハードウェアを、すべての前提条件がすでに設定されている選択したプライベートサーバーに接続する優れた方法です。
VPS の使用が良い選択肢だと思うなら、Cloudzy の利用を強くお勧めします Ollama VPS。ここではクリーンな環境で作業できます。Ollama がプリインストールされているため、ローカル LLM を完全なプライバシーで扱い始められます。12 の拠点、99.95% のアップタイム、24/7 サポートで低価格です。リソースは豊富で、専用の VCPU、DDR5 メモリ、最大 40 Gbps のリンク上で NVMe ストレージを利用できます
Ollama vs LM Studio: どちらが必要か
どちらのプラットフォームも高い機能を備えており、一概にどちらが優れているとは言えません。ですが、ここが重要な点です。それぞれ異なるワークフローに適しているため、自分の用途次第です
オートメーションと開発なら Ollama を選ぶ
Ollama を使う目的は、単にモデルとチャットすることではなく、別のプロジェクト内に組み込むことです。Ollama が理想的なのは
- 開発者 チャットボット、コパイロット、深層学習が必要なその他の製品を作成する場合
- 大量のオートメーションが必要なワークフロー レポート要約スクリプトやスケジュール実行の原案生成など
- チーム どの環境でも一貫したモデルバージョンを必要とする場合
- API ファーストアプローチを求めるユーザー向け 他のツールが定期的にモデルに接続できるように
結局のところ、アプリケーションでモデルの信頼性を求めるなら、Ollama が最良の選択肢です
LM Studio はローカル LLM へのアクセスが簡単
技術的な手間をかけずにローカル AI を試したいなら、LM Studio が確実に良い選択肢です
一般的に、LM Studio が適しているのは
- 初心者 ターミナルとコマンドラインに不安がある人
- 執筆者、クリエイター、学生 シンプルなチャットボックス型の AI アシスタントが必要な人
- 異なるオプションを試す人 複数のモデルを素早く比較して自分に合ったものを見つけたい人
- プロンプトの入力に慣れ始めたばかりの人 タイピングなしに設定を調整したい人
要するに、ローカル LLM をダウンロードしてすぐに始めたいなら、LM Studio があなたのニーズを満たします
Ollama vs LM Studio: 最終推奨
Ollama と LM Studio の競争にまつわるうわさを脇に置けば、本当に大事なのは日々の使い心地です。それはあなたのワークフローとハードウェアの限界を中心に決まります。
Ollamaは一般的には以下の通りです:
- 柔軟で開発者向け
LM Studioは以下の特徴があります:
- 初心者向けの専用 GUI で利用可能
どちらも大規模に動かすには高性能で高価なハードウェアが必要です。ローカルで大規模な LLM を自分で運用できる人は少ないのが実情です。だからこそ、 ハードウェアに負荷をかけずに高度なモデルを実行したいなら、Ollama を 専用 GPU VPS で試してみてください。下記をご覧ください Ollama vs LM Studio についてよくある質問


