
GPU VPS を選ぶときは、数字で埋め尽くされたスペックシートを見ているとうんざりすることがあります。コア数は2560から21760に跳ね上がります。でも、これは何を意味するのでしょうか?
CUDAコアはNVIDIA GPU内の並列処理ユニットで、膨大な計算を同時に実行し、AI学習から3Dレンダリングまで様々な処理を支えています。このガイドでは、CUDAコアの仕組み、CPU およびテンソルコアとの違い、そしてどのコア数があなたのニーズに最適で、無駄なく購入できるかについて説明します。
CUDAコアとは

CUDAコアはNVIDIA GPU内の個別の処理ユニットであり、命令を並列に実行します。CUDAコア技術の基礎は何ですか?これらのユニットを、同時に同じタスクの一部に取り組む小さなワーカーとして考えてください。
NVIDIAは2006年にCUDA(Compute Unified Device Architecture)を導入し、グラフィックス処理を超えた一般的なコンピューティングのためにGPUの力を活用しました。 公式CUDA ドキュメント 包括的な技術詳細を提供します。各ユニットは浮動小数点数に対する基本的な演算を実行し、反復的な計算に最適です。
最新のNVIDIA GPUには、これらのユニットが数千個搭載されています。最新世代のコンシューマー GPU には21000を超えるコアが含まれますが、 Hopperアーキテクチャに基づくデータセンター GPU では最大16896これらのユニットはStreaming Multiprocessors (SMs)を通じて協働します。
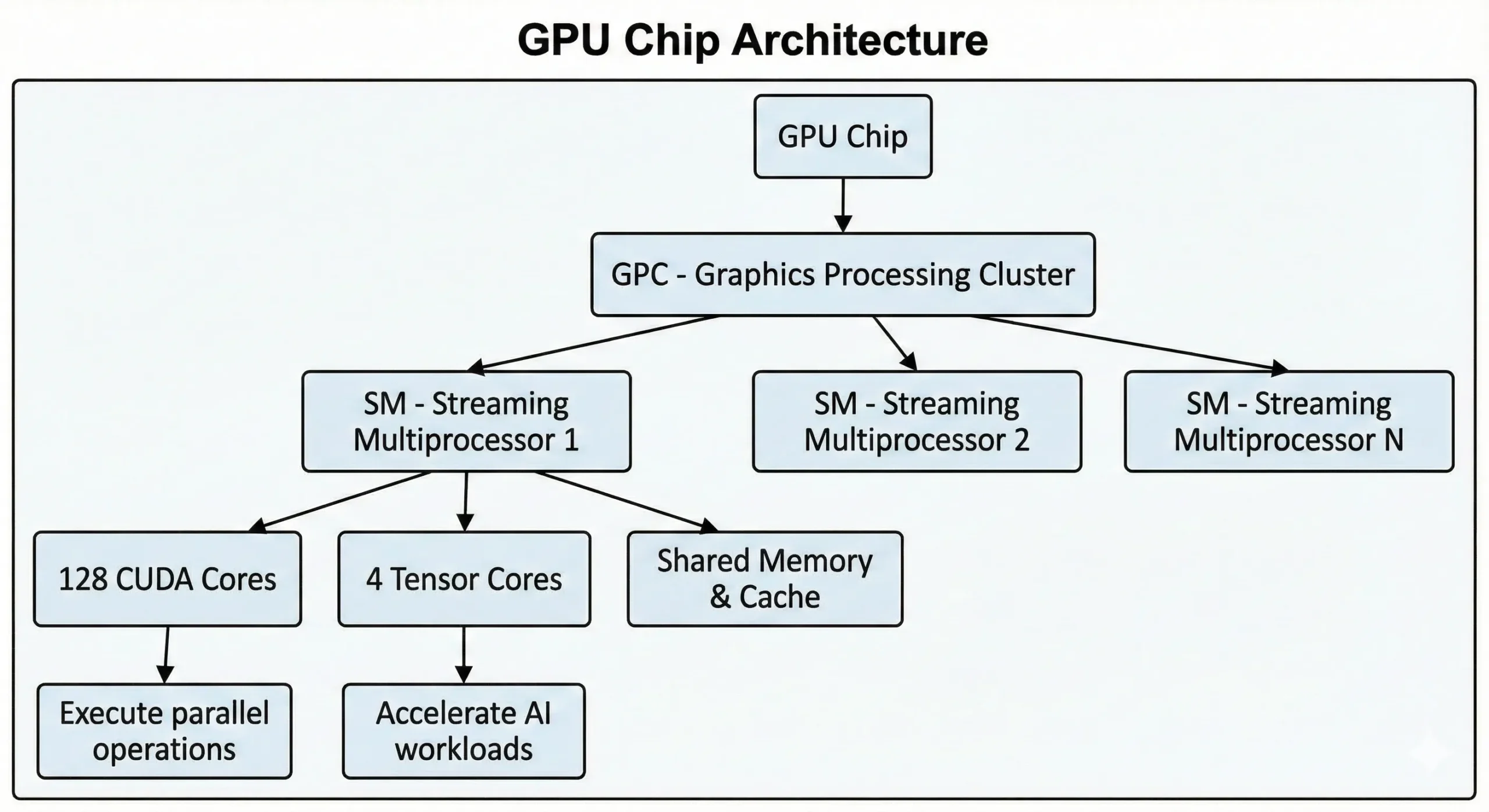
ユニットはSIMT(シングルインストラクション・マルチプルスレッド)操作を並列コンピューティング方式で実行します。1つの命令が複数のデータポイント全体で同時に実行されます。ニューラルネットワークのトレーニングや3Dシーンのレンダリングでは、数千の類似操作が同時に行われます。この作業を複数の並行ストリームに分割し、順序立てて実行するのではなく同時に実行します。
CUDAコアとCPUコア:何が異なるのか?

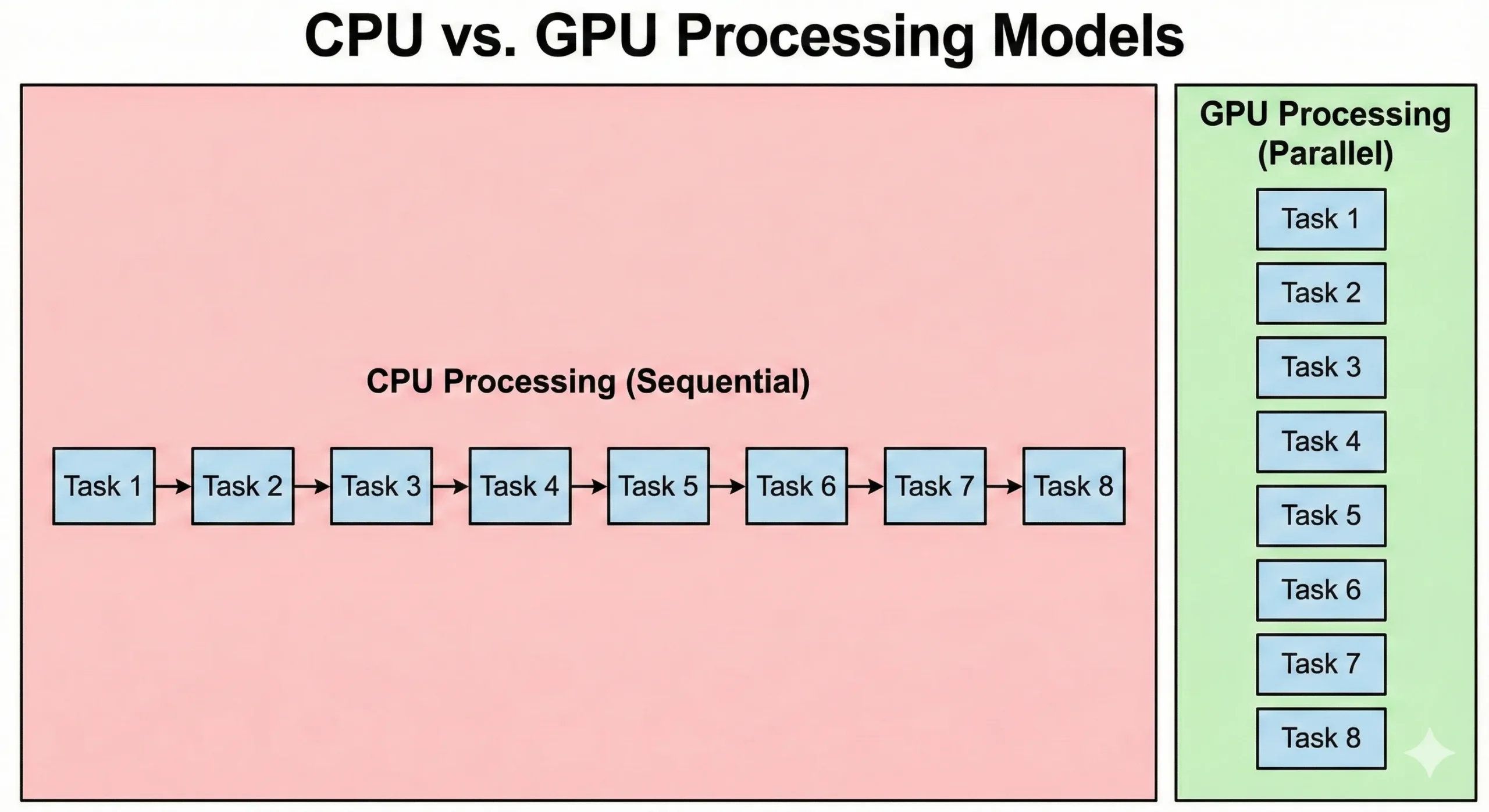
CPUとGPUは根本的に異なるアプローチで問題を解決します。最新のサーバーCPUは、高いクロック速度で動作する8〜128以上のコアを備えています。これらのプロセッサは、各ステップが前のステップの結果に依存する順序実行に優れています。複雑なロジックと分岐を効率的に処理します。
GPUはこのアプローチを逆転させます。数千の単純なCUDAコアを低いクロック速度で搭載しています。これらのユニットは低速をパラレル処理で補います。16,000が一緒に動作すると、総スループットは標準的なCPUの能力を超えます。
CPUはオペレーティングシステムのコードと複雑なアプリケーションロジックを実行します。GPUはスループットを優先する一方で、タスク初期化と同期のオーバーヘッドにより、より高いレイテンシが発生します。パラレルグラフィックス処理はデータ移動を優先します。開始には時間がかかりますが、大規模データセットの処理ではCPUより高速です。
| 機能 | CPUコア | CUDA コア |
| チップあたりの数 | 4~128+コア | 2,560~21,760コア |
| クロック速度 | 3.0~5.5 GHz | 1.4~2.5 GHz |
| 処理方式 | 順序立てた複雑な指示 | 並列で実行される簡潔な手順 |
| 最適 | オペレーティングシステム、シングルスレッドタスク | 行列演算、並列データ処理 |
| レイテンシ | 低(マイクロ秒) | より高い(起動オーバーヘッド) |
| 建築 | 汎用 | 反復計算に特化 |
仮想GPU(vGPU)とマルチインスタンスGPU(MIG)技術は、リソース分割とスケジューリングを処理して、複数のユーザー間でプロセッサを分散します。このセットアップにより、チームはタイムスライス共有か専用ハードウェアインスタンスかの設定に応じて、ハードウェア利用率を最大化できます。
ニューラルネットワークの訓練には数十億の行列乗算が含まれます。10,000のユニットを持つGPUは単に10,000の演算を同時に実行するのではなく、スループットを最大化するために「ワープ」にグループ化された数千のパラレルスレッドを管理します。この膨大なパラレル処理がAI開発者にとってこれらのユニットが必須の理由です。
CUDA コアとテンソルコアの比較:違いを理解する

NVIDIA GPUは、連携して動作する2つの特殊なユニットタイプを含んでいます:標準的なCUDA coresとTensor cores。これらは競合する技術ではなく、異なるワークロード部分に対応しています。
標準的なユニットはFP32とFP64の計算、整数演算、座標変換を処理する汎用パラレルプロセッサです。このコアとなるCUDAテクノロジーはGPUコンピューティングの基盤を形成し、物理シミュレーションからデータ前処理まで、専門的なアクセラレーションなしに実行します。
テンソルコアは行列乗算とAIタスク専用に設計された特化したユニットです。NVIDIAのVoltaアーキテクチャ(2017)で導入され、FP16とTF32精度計算に優れています。最新世代はFP8に対応し、さらに高速なAI推論が可能です。
| 機能 | CUDA コア | Tensor コア |
| 目的 | 汎用並列計算 | AI向けの行列乗算 |
| 精度 | FP32、FP64、INT8、INT32 | FP16, FP8, TF32, INT8 |
| AI のための速度 | 1倍のベースライン | CUDA コアと比べて2~10倍高速 |
| ユースケース | データ前処理、従来型ML | ディープラーニングの訓練/推論 |
| 可用性 | すべてのNVIDIA GPU | RTX 20シリーズ以降、データセンターGPU |
最新のGPUは両方を組み合わせています。RTX 5090は21,760の標準ユニットと680の第5世代テンソルコアを備えています。H100は16,896の標準ユニットと528の第4世代テンソルコアをペアリングして、ディープラーニング加速を実現しています。
ニューラルネットワークを訓練する際、テンソルコアはモデルを通じたフォワードパスとバックワードパス中の負荷の高い処理を実行します。標準ユニットはデータロード、前処理、損失計算、オプティマイザ更新を管理します。両方のタイプが連携し、テンソルコアが計算量の多い演算を加速します。
ランダムフォレストや勾配ブースティングのような従来の機械学習アルゴリズムでは、テンソルコアが加速する行列乗算パターンを使用しないため、標準ユニットが処理を管理します。しかし、トランスフォーマーモデルと畳み込みニューラルネットワークでは、テンソルコアが劇的な高速化をもたらします。
CUDAコアは何に使われるのか?

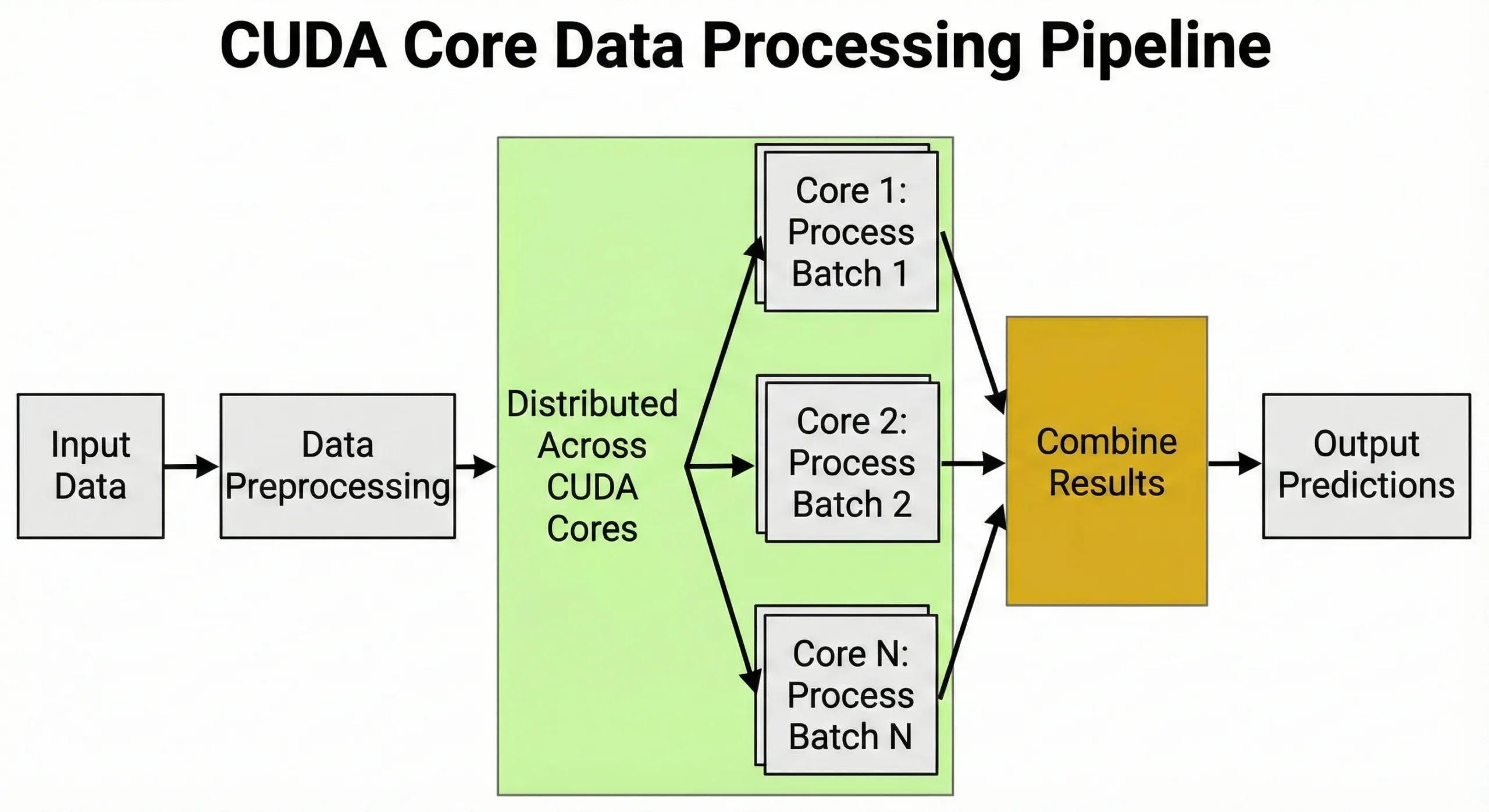
CUDAコアは、大量の同一の計算を同時に実行する必要があるタスクを駆動します。行列演算または反復的な数値計算を含むあらゆる作業は、それらのアーキテクチャから恩恵を受けます。
AI and Machine Learning Applicationsのこと、日本語では: 人工知能と機械学習アプリケーション
ディープラーニングは訓練と推論中の行列乗算に依存しています。ニューラルネットワークを訓練する際、各フォワードパスは重み行列全体にわたって数百万の乗加算演算が必要です。バックプロパゲーションはバックワードパス中にさらに数百万の演算を追加します。
ユニットはデータ前処理を管理し、画像をテンソルに変換し、値を正規化し、拡張変換を適用します。この数千のタスクを同時に処理する能力が、GPUがAIに重要である理由です。
トレーニング中、彼らは学習率スケジュール、勾配計算、およびオプティマイザー状態更新を監督します。
推奨システムやチャットボットを実行するVPSのAI推論操作では、リクエストを並行処理し、数百の予測を同時に実行します。についてのガイドをご覧ください。 AIに最適なGPU 2025 さまざまなモデルサイズに対応する構成をカバーしています。
H100の16,896のユニットとテンソルコアを組み合わせると、70億パラメータモデルを数カ月ではなく数週間で訓練できます。数千のユーザーをサービスするチャットボットのリアルタイム推論には、同様の並行実行能力が必要です。
科学計算と研究
研究者はこれらのプロセッサを分子動力学シミュレーション、気候モデリング、ゲノミクス分析に使用しています。各計算は独立しているため、並行実行に最適です。金融機関は数百万のシナリオを同時に実行するモンテカルロシミュレーションを実行しています。
3Dレンダリングとビデオプロダクション
レイトレーシングは3Dシーン内で光の跳ね返りを計算し、各ピクセルを通じて独立したレイをトレースします。専用RTコアが走査を処理する一方で、標準ユニットはテクスチャサンプリングと照明を管理します。この分割は数百万のレイを持つシーンの速度を決定します。
NVENCはH.264とH.265のエンコーディングを処理し、最新のアーキテクチャ(Ada LovelaceとHopper)はAV1のハードウェアサポートを提供します。CUDAはエフェクト、フィルター、スケーリング、ノイズ除去、色変換、パイプラインの接合に役立ちます。これにより、エンコードエンジンは並列プロセッサと協働して、より高速なビデオプロダクションを実現できます。
BlenderやMayaの3Dレンダリングは、数十億の表面シェーダ計算を利用可能なユニット全体に分割します。パーティクルシステムはそれらが数千のパーティクルが同時に相互作用するのをシミュレートするため、恩恵を受けます。これらの機能はハイエンドデジタルクリエーション向けのキーです。
CUDA Coresがどのようにして GPU性能に影響を与えるか

コア数は並行実行能力の概算を提供しますが、CUDAコアはその数値を超えて考える必要があります。クロック速度、メモリ帯域幅、アーキテクチャ効率、ソフトウェア最適化はすべて重要な役割を果たします。
2.0 GHzで動作する10,000のユニットを持つGPUは、1.5 GHzで10,000のユニットを持つものとは異なる結果をもたらします。より高いクロック速度は各ユニットが1秒あたりより多くの計算を完了することを意味します。より新しいアーキテクチャはより優れた命令スケジューリングを通じて各サイクルでより多くの処理を詰め込みます。
デバイスが十分に利用されているかを確認してみてください。ただし、利用率は粗い指標に過ぎないことを忘れずに。 nvidia-smi 利用率はカーネルがアクティブな時間の割合を測定するもので、実際に仕事をしているコア数を反映していません。
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheader出力例:85%、92%(85%のアクティブ時間、92%のメモリコントローラアクティビティ)
GPU の利用率が 60~70% の場合、CPU データローディングやバッチサイズが小さいなど、上流側のボトルネックが存在する可能性が高いです。ただし、カーネルがメモリバウンドあるいはシングルスレッドの場合、100% の利用率でも誤解を招くことがあります。コア飽和度を正確に把握するには、Nsight Systems などのプロファイラーを使用して「SM Efficiency」や「SM Active」といったメトリクスを追跡してください。
メモリ帯域幅は、コンピュート性能を最大化する前にボトルネックになることが多いです。GPU がデータをメモリから供給される速度より速く処理すると、ユニットはアイドル状態になります。 H100 SXM5モデルは3.35 TB/sの帯域幅を使用しています 16,896個のコアに給電するため。ただし、PCIeバージョンではこれが2 TB/sに低下します。
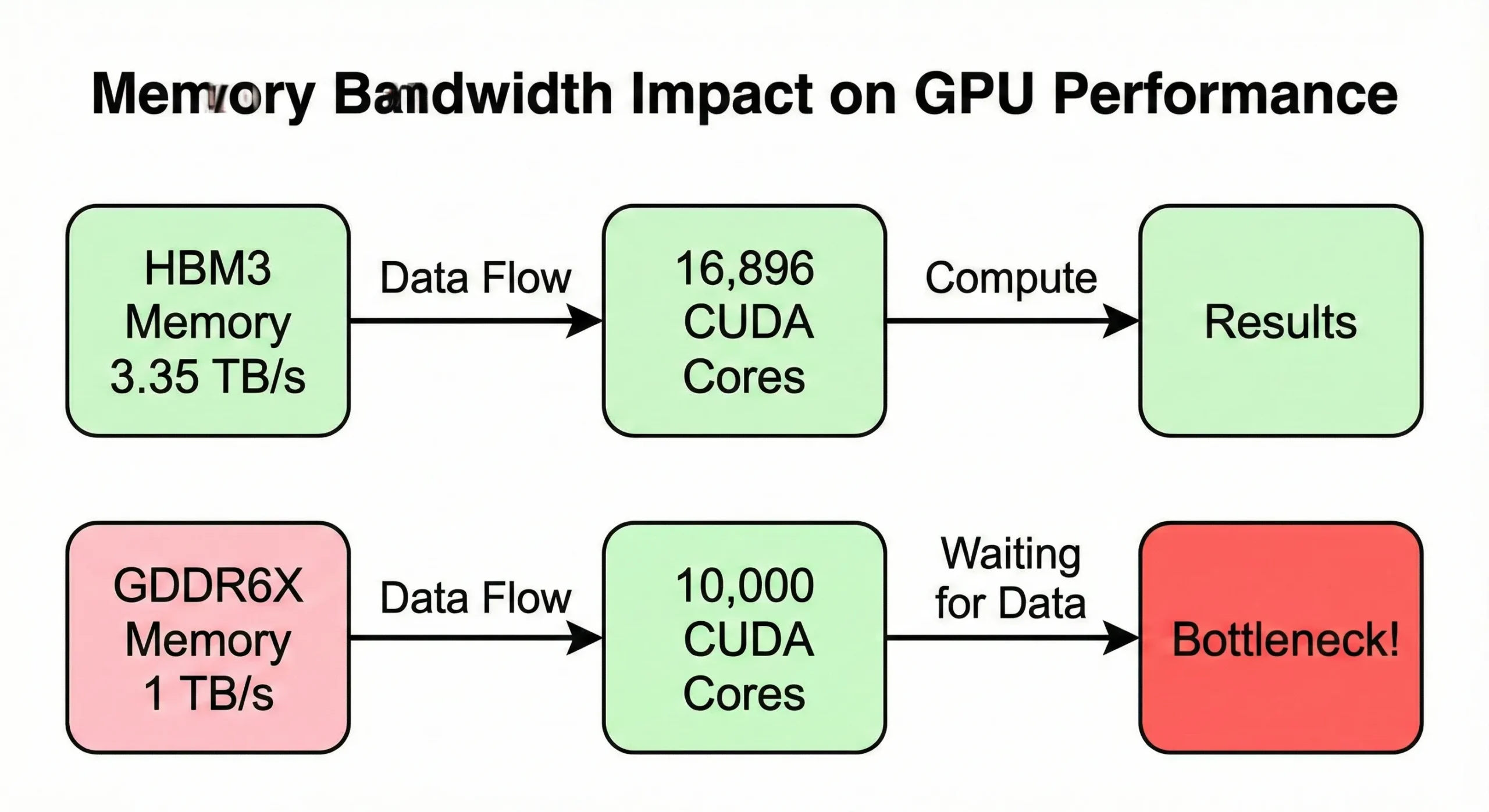
コンシューマーGPUは同様のコア数を持ちながらもより低い帯域幅(約1 TB/s)であり、メモリ集約的な操作での実世界のパフォーマンスが低下します。
VRAMの容量は、実行できるタスクのサイズを決定します。モデルのFP16重みであれ、 70Bモデル完全なトレーニングにはさらに多くのメモリが必要です。勾配とオプティマイザー状態を考慮する必要があります。オフロード戦略を使用しない限り、これらの状態はフットプリントを 3 倍以上に増加させることが多いです。
A100 80GB はハイスループット推論とファインチューニングを対象としています。一方、7B モデル向けとしてよく引用される 24GB の RTX 4090 は、INT4 などの最新量子化手法を使用すれば、驚くことに 30B 以上のパラメータモデルを実行できます。ただし、VRAM がなくなると CPU から GPU へのデータ転送が強制され、スループットが劇的に低下します。
ソフトウェアの最適化は、コードが実際にそれらすべてのユニットを使用するかどうかを決定します。書き込みの悪いカーネルは、利用可能なリソースのほんの一部しか利用しないかもしれません。深層学習向けの cuDNN やデータサイエンス向けの RAPIDS などのライブラリは、利用率を最大化するために入念にチューニングされています。
より多くのCUDA Coresが必ずしもより良いパフォーマンスを意味するわけではありません

最も高いコア数を備えた GPU を購入するのは論理的に見えますが、ユニットが他のシステムコンポーネントより速く処理したり、タスクがコア数でスケーリングしない場合、お金を無駄にすることになります。
メモリ帯域幅が最初のボトルネックとなります。RTX 5090の21,760ユニットは1,792 GB/sのメモリ帯域幅によって供給されます。ユニット数が少ない古いGPUは、ユニットあたりの帯域幅がより高い可能性があります。
アーキテクチャの違いは重要です。2.2 GHz で 14,000 ユニットを備えた新しい GPU は、クロック当たりの命令がより優れているため、1.8 GHz で 16,000 ユニットを備えた古い GPU を上回ります。20,000 ユニットを効果的に使用するには、コードの適切な並列化が必要です。
GPU VPSを選択する際にCUDA Coresが重要である理由

CUDA コア GPU 構成を正しく選択することで、VPS では未使用のリソースにお金を無駄にしたり、プロジェクト途中でボトルネックにぶつかることを防げます。
H100 の 80GB メモリは、4 ビット量子化を使用した 70B パラメータモデルの推論を処理できます。ただし、完全なトレーニングの場合、勾配とオプティマイザー状態を考慮すると、34B モデルでも 80GB では不足することが多いです。FP16 トレーニングではメモリフットプリントが大幅に増加し、複数 GPU シャーディングが必要になることがよくあります。
リアルタイム予測を処理する推論操作は、ユニット数は少なくて済みますが、低遅延のメリットがあります。開発やプロトタイプ作成は、アルゴリズムをテストしてコードをデバッグするのに中堅クラスの GPU で十分です。
RTX 4060 Ti の 4,352 ユニットで、過剰なハードウェアにお金をかけることなくテストできます。アプローチを検証したら、完全なトレーニング実行のために本番用 GPU にスケールアップします。
レンダリングやビデオ処理は、ある程度までユニット数でスケーリングします。Blender の Cycles レンダラーは、利用可能なすべてのリソースを効率的に使用します。8,000~10,000 ユニットを備えた GPU は、4,000 ユニットのものよりシーンを 2~3 倍速くレンダリングします。
Cloudzyでは、高性能な GPU VPS ヘビーな処理向けホスティング。高速レンダリングとコスト効率的な AI 推論には RTX 5090 または RTX 4090 を選択し、大規模な深層学習ワークロードにはスケールアップして A100 を使用します。すべてのプランは 40 Gbps ネットワーク上で実行され、プライバシー重視ポリシーと暗号通貨による支払いオプションが備わっており、企業向けのわずらわしさなしに圧倒的なパワーを提供します。
AI モデルのトレーニングであれ、3D シーン のレンダリングであれ、科学シミュレーションの実行であれ、ニーズに合ったコア数を選択します。
予算も重要な考慮事項です。6,912 ユニットを備えた A100 は、16,896 ユニットを備えた H100 よりもかなり安くなります。多くの操作では、2 つの A100 は 1 つの H100 よりも優れた価格対速度比を提供します。損益分岐点は、コードが複数の GPU にスケーリングするかどうかに依存します。
CUDA コア数の正しい選択方法
市場で入手可能な最高の数字を追い求めるのではなく、実際のワークロード特性に合わせて要件を整合させてください。
現在の作業をプロファイリングすることから始めてください。ローカルハードウェアまたはクラウドインスタンスでモデルをトレーニングしている場合、GPU 利用率メトリクスを確認します。現在の GPU が一貫して 60~70% の利用率を示している場合、ユニットを最大化していません。
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")このシンプルなベンチマークは、GPU コアが予想されるスループットを実現しているかどうかを示します。GPU モデルの公開ベンチマークに対して結果を比較してください。
アップグレードは役に立ちません。メモリ、帯域幅、CPU ストールなど、ボトルネックに最初に対処する必要があります。次にモデルサイズ (バイト単位) に活性化メモリを加算して、メモリ要件を推定します。
バッチサイズとレイヤー出力を乗じてオプティマイザー状態を含めます。この合計が VRAM に適合する必要があります。必要なメモリがわかったら、そのしきい値を満たす GPU を確認します。
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)スケジュールを見直してください。数時間で結果が必要なら、ユニット数を増やします。数日かかるトレーニング実行は、GPU の小規模構成でも機能します。完了時間が長くなるだけです。
1時間あたりのコストに必要な時間数を掛けると総コストが得られ、場合によってはGPUの速度が遅いほど全体的にコストが安くなることもあります。スループットの変化を示すベンチマークツールを提供する多くのフレームワークを使用してスケーリング効率をテストします。
ユニット数を2倍にしても速度が1.5倍にしかならないなら、追加コストに見合いません。価格と速度の比率がピークの地点を探してください。
| ワークロードタイプ | 推奨コア数 | 例のGPU | 注意事項 |
| モデル開発とデバッグ | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | 高速反復、低コスト |
| 小規模なAIトレーニング(7B未満のパラメータ) | 6,000-10,000 | RTX 4090, L40S | 消費者と小規模企業に対応 |
| 大規模AIトレーニング(7B~70Bパラメータ) | 14,000+ | A100, H100 | データセンターGPUが必要です |
| リアルタイム推論(高スループット) | 10,000-16,000 | RTX 5080, L40 | コストとパフォーマンスのバランス |
| 3Dレンダリング&ビデオエンコーディング | 8,000-12,000 | RTX 4080, RTX 4090 | 複雑性に応じてスケールします |
| 科学計算・HPC | 10,000+ | A100, H100 | FP64サポートが必要です |
一般的なVPS GPUとそのCUDAコア数

異なる GPU ティアはさまざまなユーザーセグメントに対応します。GPUaaS とは何ですか。これは GPU-as-a-Service のことで、Cloudzy のようなプロバイダーが強力な NVIDIA GPU へのオンデマンドアクセスを提供し、物理ハードウェアを購入・保守する必要がありません。
| GPU モデル | CUDA コア | VRAM | メモリ帯域幅 | 建築 | 向いている用途 |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1,792 GB/s | Blackwell | フラッグシップワークステーション、8Kレンダリング |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/秒 | エイダ・ラブレス | 高度なAI、4Kレンダリング |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/s | Hopper | 大規模なAIトレーニング |
| H100 PCIe | 14,592 | 80GB HBM2e | 2,000 GB/秒 | Hopper | エンタープライズAI、コスト効率的なデータセンター |
| A100 | 6,912 | 40/80GB HBM2e | 1,555~2,039 GB/秒 | Ampere | 中程度のAI、実証済みの信頼性 |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | エイダ・ラブレス | ゲーミング、中堅AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | エイダ・ラブレス | マルチワークロード データセンター |
一般向け RTX カード(4070、4080、4090、5080、5090)はクリエイターとゲーミングをターゲットにしていますが、AI 開発でもよく機能します。データセンターカードより低い価格で強力な単一 GPU 速度を提供します。
VPSプロバイダーは、コスト意識の高いユーザー向けにこれらをよく在庫しています。データセンターカード(A100、H100、L40)は、信頼性、ECCメモリ、マルチGPUスケーリングを優先します。24時間365日の運用を管理し、高度な機能をサポートしています。
マルチインスタンス GPU(MIG)では、1つの GPU を複数の独立したインスタンスに分割できます。A100 は新しいオプションがあるにもかかわらず、バランスの取れた仕様により人気があります。
NVIDIA コア、メモリ、価格のバランスにより、ほとんどの本番 AI 操作では安全な選択です。H100 は2.4倍以上のユニットを提供しますが、コストが大幅に高くなります。
結論
並列処理エンジンは、最新の AI、レンダリング、科学計算を可能にします。それらがメモリ、クロック速度、ソフトウェアとどのように相互作用するかを理解することで、GPU および VPS 構成を選択できます。
作業が効果的に並列化される場合、ユニット数が多いほど役立ちます。メモリバンド幅などのコンポーネントが対応していることも重要です。ただし、ボトルネックが他の場所にあれば、無闇にコア数を追い求めるのは無駄です。
実際の操作をプロファイリングして、時間がどこに費やされているかを特定し、不要な容量を買わずに GPU の仕様をその要件に合わせることから始めてください。
ほとんどの AI 開発作業では、6,000~10,000ユニットがコストと性能のバランスの最適地点です。大規模モデルのトレーニングまたは高スループット推論を実行する本番操作では、H100 のような 14,000ユニット以上の GPU の恩恵を受けます。
レンダリングとビデオ作業はユニット数が約 16,000 までスケーリングが効率的です。それ以上になるとメモリバンド幅がボトルネックになります。


