GPU-monitoringsoftware is wat "mijn GPU voelt raar" omzet in een concrete verklaring, zoals: "hotspot piekte, klokken vertraagden en VRAM liep vol."
In deze handleiding laat ik je zien welke tools je kunt gebruiken voor AI-taken, gaming-overlays en lange werksessies, en welke GPU-metrics je helpen om vertragingen, haperingen en crashes te diagnosticeren.
Aan het einde heb je een GPU-monitoringopstelling die aansluit bij hoe jij werkt. Je krijgt ook kant-en-klare stacks voor vier veelvoorkomende gebruiksscenario's, zodat je niet telkens opnieuw hoeft te zoeken.
Kort antwoord: beste GPU-monitoringsoftware per gebruiksscenario
Als je gewoon een kort overzicht wilt dat aansluit bij hoe mensen in de praktijk werken, begin dan hier. De beste GPU-monitoringstack is in de praktijk meestal een combinatie: één tool voor snelle checks, één voor overlays of logs, en één voor geschiedenis of meldingen.
Hier is het snelle overzicht:
| Gebruikssituatie | Aanbevolen startstack | Wat je krijgt |
| AI-training, inferentie, HPC-taken | nvidia-smi (NVIDIA) of AMD SMI (AMD) + logging/exporter | Snelle checks, scriptbare logs, eenvoudige meldingen |
| Gaming op Windows | MSI Afterburner + RTSS + een frametime-capture tool | Overlay plus bewijs voor stutter vs lage FPS |
| Gamen op Linux | MangoHud + een terminaltool (nvtop) | Lichte overlay plus per-process controles |
| Werkstations (3D/video/CAD) | HWiNFO logging + een eenvoudige stresstest | Uitgebreide logs die je kunt delen, reproduceerbaar probleem |
| Gedeelde GPU machines | nvtop (Linux) + exporteur/dashboard | Per-process VRAM inzicht |
Vanaf hier is het belangrijkste: de juiste GPU monitoring software kiezen op basis van hoe jij data wilt bekijken: op het scherm, in een logbestand of in een dashboard.
Voor wie deze gids is
Ik schrijf dit als iemand die echte machines heeft moeten debuggen. Want uit ervaring weet ik: verschillende gebruikers hebben verschillende GPU tools nodig, ook als ze naar dezelfde GPU kijken.
Dit zijn de vier profielen waar ik op richt:
- De model builder (AI/ML): let op VRAM ruimte, aanhoudende kloksnelheden, throttling en "liep de taak de hele nacht zonder problemen?"
- De competitieve gamer/streamer: let op frametimes, overlay-stabiliteit en het opsporen van regressies na driver-updates.
- De workstation gebruiker (3D/video/CAD): let op logs, reproduceerbare crashes en het onderscheiden van hitte, stroomverbruik en drivergedrag.
- De beheerder van GPU machines: let op meldingen, trendgrafieken, capaciteitsplanning en het vroegtijdig signaleren van fouten.
Zodra je weet in welke categorie je valt, kun je eenvoudig de GPU monitoring software kiezen die bij jou past.
Hoe kies je GPU monitoring software
Veel performance monitoring apps lijken op elkaar totdat je ze een week gebruikt. Het verschil zit vrijwel altijd in output en betrouwbaarheid, niet in de aantrekkelijke "features" die elk product zo graag aanprijst.
Ik geef je drie vragen om snel de juiste GPU-monitoringsoftware te kiezen:
- Heb je een overlay, een log, of allebei nodig?
Gamers willen een overlay. AI- en workstationwerk vraagt meestal om logging. Beheerders willen logs én meldingen. - Heb je inzicht per proces nodig?
Als je een machine deelt (lab, studio, externe server), is VRAM per proces vaak het eerste waar je naar zoekt. - Heb je geschiedenis en meldingen nodig?
Als taken 's nachts draaien, is 'ik kijk er later naar' niet genoeg. Je wilt een grafiek en een melding.
Om dit praktisch te houden, is de rest van deze gids ingedeeld op GPU-metrieken eerst, gevolgd door toolstacks die bij elk gebruiksscenario passen.
GPU-metrieken die je prioriteit moet geven
Goede GPU-monitoringsoftware geeft je veel getallen. Echt nuttige GPU-monitoringsoftware geeft je precies die paar die het gedrag verklaren. Ik groepeer GPU-metrieken op basis van de beslissing die ze je helpen maken.
Temperatuur- en throttlingmetrieken
Dit zijn de GPU-metrieken die verklaren waarom iets 10 minuten snel was en daarna niet meer:
- GPU-temperatuur
- Hotspot-temperatuur (vaak het eerste dat uitschiet)
- Geheugentemperatuur/junction (relevanter bij lange AI-runs en lange renders)
- Ventilatorsnelheid (helpt bij het herkennen van laptopprofielen of slechte ventilatorcurves)
Als je de stabiliteit wilt verbeteren, log deze dan - losse momentopnamen geven zelden genoeg informatie.
Vermogen, kloksnelheden en limieten
Deze GPU-metrieken verklaren downclocking en inconsistente prestaties:
- Vermogenverbruik van het board
- Core clock en memory clock
- Vermogenlimiet/prestatieniveau (als je tool dit weergeeft)
In veel praktijksituaties geven vermogen en kloksnelheden een veel duidelijker beeld dan een simpel 'GPU-gebruik %'.
VRAM en geheugendruk
Deze GPU-metrics verklaren stutter, OOM-fouten en de typische "willekeurige" vertragingen:
- Gebruikte vs totale VRAM
- Activiteit van de memory controller (helpt bandbreedtelimieten op te sporen)
- RAM-druk op systeemniveau (omdat VRAM-overloop ook het hele systeem kan vertragen)
Voor AI is VRAM vaak het harde plafond. Voor games uit VRAM-druk zich doorgaans het eerst als frametime-pieken.
Frametime- en frame pacing-metrics
Voor gaming en streaming kan FPS alleen misleidend zijn. Frametime is de metric waar je op moet letten, omdat die de vloeiendheid - of het gebrek daaraan - bijhoudt:
- Frametime (ms)
- 1% laag / 0,1% laag (handig voor vergelijkingen)
- GPU bezig vs CPU bezig (helpt onderscheid te maken tussen GPU-bottlenecks en CPU-bottlenecks)
Dat is waarom op gaming gerichte prestatiemonitoringapps vaak een frametime-opnamepad bevatten. Nu de basismetrics behandeld zijn, kunnen we het hebben over de beste GPU-monitoringsoftware per workflow.
GPU-monitoringsoftware voor AI, training en servers

AI-monitoring heeft een eenvoudige opzet: korte controles in een terminal, aangevuld met logs en meldingen voor langdurige runs. Daarvoor wil je GPU-monitoringsoftware die werkt via de CLI en metrics exporteert.
NVIDIA: nvidia-smi voor snelle controles en scriptbare logs
Op NVIDIA-systemen, nvidia-smi is meestal het eerste commando dat mensen uitvoeren, omdat het meegeleverd wordt met de driver en ontworpen is voor monitoring en beheer via NVML.
Officiële documentatie is hier te vinden: NVIDIA System Management Interface (nvidia-smi).
Als je een eenvoudige aanpak wilt van "loggen en later bekijken" (en het zal je verbazen hoe vaak dit het probleem oplost), is dit patroon vrij betrouwbaar:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Dit is standaard gedrag van GPU-monitoringsoftware: tijdstempels, kern-GPU-metrics en uitvoer die goed werkt met scripts.
AMD: AMD SMI voor ROCm- en HPC-nodes
Op AMD Linux compute nodes is AMD SMI de standaard interface voor monitoring en beheer, en AMD documenteert het als een uniforme toolset voor monitoring en besturing in HPC-omgevingen.
Officiële documentatie is hier te vinden: AMD SMI Documentatie.
Als je omgeving zwaar leunt op AMD, is AMD SMI de monitoringbasis voor GPU waarop andere tools doorgaans voortbouwen.
Zichtbaarheid per proces: nvtop voor gedeelde GPUs
Als je ooit een gedeelde machine hebt gehad waarbij VRAM 'mysterieus' volloopt, bespaar je tijd met zichtbaarheid per proces. Op Linux is nvtop precies daarom populair: het maakt direct duidelijk wie VRAM gebruikt. Op AMD/Intel heb je mogelijk een recente kernel nodig voor statistieken per proces.
In gemengde teams zie ik mensen vaak nvtop naast elkaar draaien met nvidia-smi of AMD SMI. Het is een simpele combinatie die veel giswerk voorkomt, dus ik raad het sterk aan.
Vergeet je hardwarekeuze niet!
Monitoring lost een VRAM-limiet niet op; het maakt die limiet alleen zichtbaar. Als je nog bezig bent met het toewijzen van workloads aan GPU-tiers, is onze gids over Beste GPUs voor machine learning in 2025 een handig naslagwerk, omdat het VRAM en bandbreedte op dezelfde manier behandelt als je ze later in logs en dashboards tegenkomt.
Zodra je server-stijl GPU-monitoringsoftware onder controle hebt, is de volgende stap overlays en frametimes, omdat interactieve workloads anders gedragen.
GPU Monitoringsoftware voor Gaming en Streaming

Gaming is waar mensen de sterkste meningen over GPU-tools hebben, vooral omdat overlays op het slechtste moment uitvallen. Voor gaming wil je eenvoudige overlays en herhaalbare frametime-opnames.
MSI Afterburner + RTSS voor overlays op Windows
Deze combinatie is erg populair omdat je een overzichtelijke overlay kunt samenstellen met precies de GPU-metrics die je nodig hebt, zoals gebruik, kloksnelheden, VRAM, temperaturen, frametime en eventueel ventilatorsnelheid.
Een serieuze waarschuwing die steeds terugkomt in community-threads zijn nep-downloadsites. MSI's eigen Afterburner-pagina stelt duidelijk dat legitieme downloads alleen van msi.com en Guru3Dafkomstig zijn, en vermeldt ook een actuele releaseversie (4.6.6 final, uitgebracht oktober 2025).
Overlayproblemen zijn een ander aandachtspunt. Zo werkt RTSS in sommige games wel en in andere niet, met name bij moderne render-paden. Gebruikers melden gevallen waarbij de overlay wel zichtbaar is in Vulkan maar niet in DX12 voor hetzelfde spel, of verdwijnt na updates.
Dat is echter geen fout van jou, maar gewoon wat er gebeurt als overlays inhaken op veranderende game- en driver-stacks.
Als je een stabiele basis-overlay wilt, houd het dan beperkt:
- frametime
- GPU-gebruik
- VRAM gebruikt
- GPU-temperatuur
Voeg power en clocks alleen toe als je actief throttling debugt.
Frametime-registratie voor "Stutter"
Dit is waar performance monitoring-apps die frametime-grafieken kunnen vastleggen echt het verschil maken. De gemiddelde FPS kan er prima uitzien terwijl de frame pacing verschrikkelijk aanvoelt. Frametime-grafieken maken die verwarring snel duidelijk.
Veel gaming-benchmark-workflows maken achter de schermen gebruik van PresentMon, en NVIDIA-documenten dat de FrameView-analyses PresentMon gebruiken voor het vastleggen van framerate en frametime.
Je hoeft niet elk spel te benchmarken. Frametime-registratie is het nuttigst voor vergelijkingen: voor en na een driver-update, voor en na het wijzigen van een limiter, voor en na het aanpassen van instellingen, enzovoort.
MangoHud voor Linux-overlays
Op Linux wordt MangoHud vaak aanbevolen omdat het lichtgewicht is en goed integreert met Steam/Proton-omgevingen. De meest voorkomende klachten gaan over ontbrekende sensoren of vreemde meetwaarden op hybride laptop-configuraties.
In de praktijk kun je MangoHud eenvoudig combineren met een terminal-checker zoals nvtop. Het is ook een mooi voorbeeld van hoe GPU-monitoringsoftware aanzienlijk beter werkt als een kleine stack, in plaats van één grote monolithische app.
Vanuit gaming is de logische volgende stap workstation-monitoring, want daar zijn logs en reproduceerbare probleemdiagnose je prioriteiten.
Host lagvrije gameservers met hogesnelheids NVMe VPS-hosting.
VPS voor gaming
GPU-monitoringsoftware voor workstations en professionele applicaties
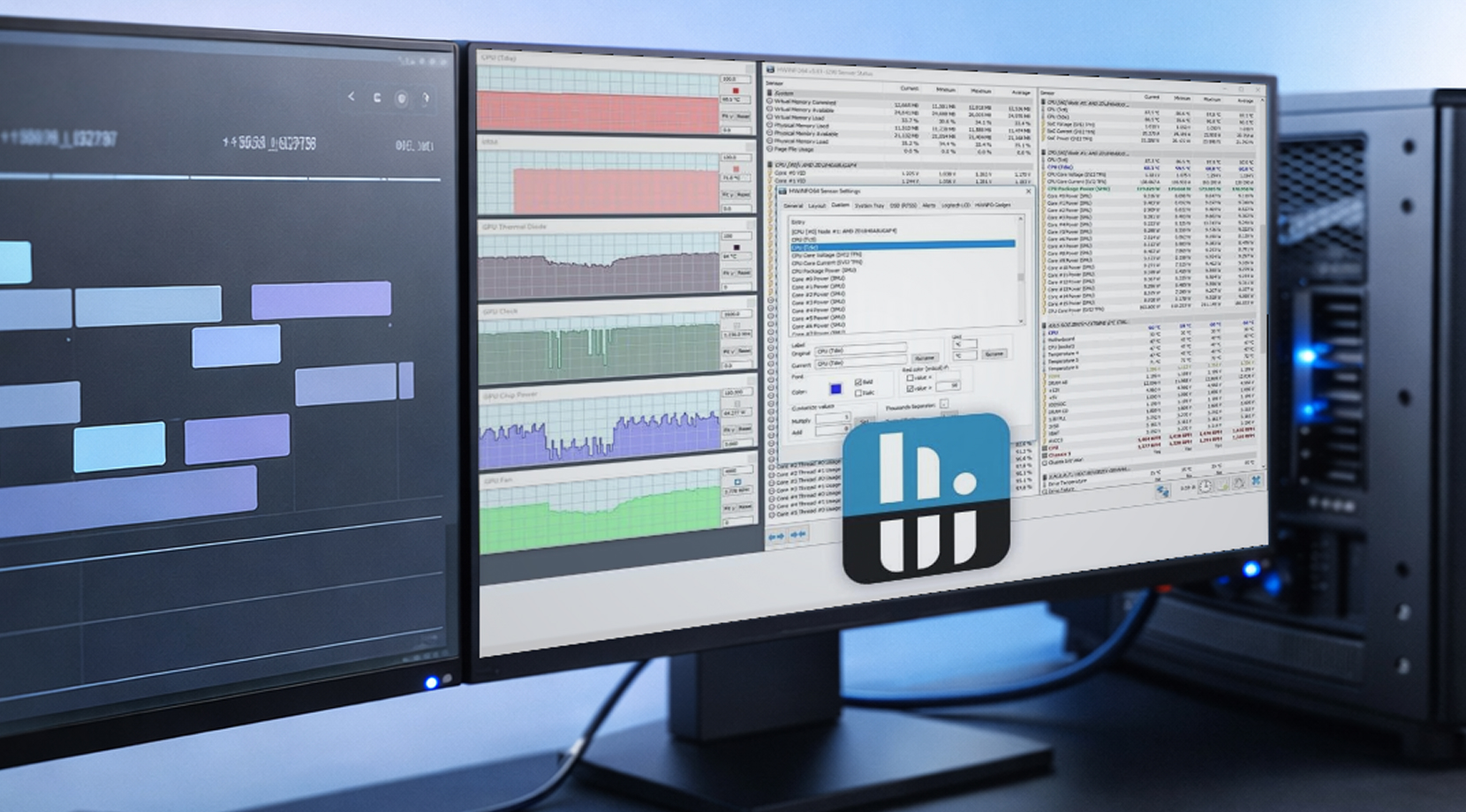
Workstation-monitoring is veel minder een kwestie van een live overlay bewaken als een soort beveiligingsagent, en veel meer het beantwoorden van de vraag: "Wat is er in de loop van de tijd gebeurd, en kan ik het reproduceren?"
HWiNFO voor logging op Windows
HWiNFO is populair in workstation-kringen vanwege de uitgebreide sensordekking en de logs die eenvoudig te delen zijn. Een simpel CSV-logbestand met tijdstempels kan een vaag rapport al snel omzetten in iets waar je concreet mee aan de slag kunt.
Als je een workstation-log voor GPU-stabiliteit opbouwt, begin dan met deze GPU-metrieken:
- GPU-temperatuur en hotspot
- VRAM gebruikt
- stroomtoevoer
- kernklok
- CPU-pakketvermogen (omdat platform-vermogenlimieten je kunnen terugpakken)
Dit is de "genoeg data om het uit te leggen"-set. Want als je elke sensor logt, wordt het bestand alleen maar moeilijker leesbaar.
GPU-Z voor snelle "Welke GPU is dit?"-controles
GPU-Z blijft handig omdat het snel en gericht is. In teams met gemengde hardware is het de snelste manier om het GPU-model, de basis van de drivers en live sensorwaarden te bevestigen zonder door menu's te hoeven bladeren.
Stresstests: alleen nuttig met logging
Stresstests kunnen helpen een crash te reproduceren, maar alleen als je GPU-monitoringsoftware tijdens de test aan het loggen is. Zonder die logs blijf je zitten met "hij is weer gecrasht" en vrijwel geen tijdlijn.
Op dit punt lopen de meeste mensen tegen dezelfde problemen aan: overlays die niet verschijnen, vermogensmetingen die er niet kloppen, en logs die onleesbaar worden. Laten we die direct aanpakken.
Veelvoorkomende problemen met GPU-monitoring-software en snelle oplossingen

De meeste problemen volgen een herkenbaar patroon. Dit zijn de oplossingen die ik als eerste probeer, omdat ze de voor de hand liggende oorzaken snel afhandelen.
Overlay verdwenen in een game
Als een overlay verdwijnt in een moderne game, ligt het vaak aan een probleem met de per-game hook, of aan een conflict met anti-cheat- of anti-tamperlagen.
Wat je kunt proberen:
- Werk RTSS bij en reset het per-game profiel
- Stel een hoger 'application detection level' in voor het gameprofiel
- Probeer een andere API als de game dat ondersteunt
- Val terug op ingebouwde overlays als een game overlays van derden blokkeert
Niet elke game werkt mee, en het is de moeite niet waard om uren te verspillen aan één koppige titel.
Vreemde vermogensmetingen (0W, vlakke lijnen, ontbrekende sensors)
Dit komt veel voor op laptops en hybride systemen waarbij de actieve GPU kan wisselen. Controleer in die gevallen met een tweede tool, zoals nvidia-smi (NVIDIA) of AMD SMI (AMD), want die zijn goed geschikt om te controleren of de GPU daadwerkelijk actief is.
Logbestanden te rommelig
Oversampling is de gebruikelijke oorzaak. Voor de meeste probleemanalyses is een interval van 1 tot 5 seconden ruim voldoende. Voor lange AI-taken volstaat 5 seconden. Kortere intervallen laten de bestandsgrootte snel oplopen en maken grafieken moeilijker leesbaar.
Zodra die basisaspecten op orde zijn, is monitoring op afstand de logische volgende stap, omdat veel GPU-workflows inmiddels buiten de eigen machine draaien.
GPU-monitoring op afstand en een praktische cloudoptie
Werken op afstand verandert wat 'goede GPU-monitorsoftware' inhoudt. Je kijkt niet altijd mee op de machine, dus je hebt checks nodig die je snel kunt uitvoeren, plus een geschiedenis die je later kunt raadplegen.
Een nette remote-opzet ziet er meestal zo uit:
- CLI-controles (nvidia-smi of AMD SMI)
- een logbestand dat je later kunt ophalen
- een exporter of dashboard als je meldingen nodig hebt
Als lokale hardware je tegenhoudt, door VRAM-limieten, het delen van één GPU met anderen, of de behoefte aan een schone omgeving per project, dan is het draaien van workloads op een GPU VPS vaak de eenvoudigste manier om verder te kunnen.
Cloudzy GPU VPS

Als je GPU-tijd op afstand wilt die past bij AI-, gaming- en renderingworkloads, biedt ons Cloudzy GPU VPS NVIDIA-opties zoals RTX 5090, A100 en RTX 4090, plus NVMe-opslag, volledige root-toegang, verbindingen tot 40 Gbps, DDoS-beveiliging en een gegarandeerde uptimedoelstelling van 99,95%.
Vanuit monitoringperspectief gedraagt het zich als een gewone machine: je kunt GPU-monitorsoftware via SSH uitvoeren, GPU-metrics loggen voor lange taken, en dashboards toevoegen als je geschiedenis en meldingen wilt.
Als je nog twijfelt tussen een GPU-instantie en een puur CPU-opstelling, leggen onze artikelen over Wat is een GPU VPS? en GPU versus CPU VPS de praktische verschillen per workload uit.
Nu remote monitoring is besproken, is de laatste stap alles samenvoegen tot kant-en-klare stacks.
Kant-en-klare stacks per gebruikersprofiel
Hieronder vind je stacks die je direct kunt overnemen zonder je hele workflow te herschrijven. Goede startpunten die je daarna naar eigen behoefte kunt aanpassen.
- Modelbuilder (AI/ML): GPU-monitoringsoftware via nvidia-smi of AMD SMI, plus een eenvoudig CSV-logbestand, plus een exporter/dashboard als taken onbeheerd draaien.
- Competitieve gamer/streamer: GPU-monitoringsoftware overlay via Afterburner + RTSS, plus een frametime-tool voor vergelijkingen, plus een minimale set statistieken op het scherm.
- Workstation-gebruiker: GPU-monitoringsoftware via HWiNFO-logging, plus GPU-Z voor snelle identificatie, plus een stresstest alleen wanneer je de run kunt vastleggen.
- Beheerder van GPU-machines: GPU-monitoringsoftware als service: exporter + dashboards + meldingen, plus zichtbaarheid per proces (nvtop) voor gedeelde servers.
Als je één ding uit deze gids meeneemt, laat het dan dit zijn: kies GPU-monitoringsoftware op basis van waar je de data nodig hebt (overlay, logbestand, dashboard), en houd je set statistieken klein genoeg om daadwerkelijk te gebruiken.