Meer dan 178.000 GitHub-gebruikers gaven een enkel markdown-bestand een ster. Het bestand vertelt een AI gewoon hoe hij zich moet gedragen.
Vier regels: Think Before Coding. Simplicity First. Surgical Changes. Goal-Driven Execution. Dat is alles. Geen library. Geen framework. Geen installer. Forrest Chang verpakte Andrej Karpathy's observaties over de faalmodi van LLM-coding in een enkel CLAUDE.md-bestand, en de ontwikkelaarsgemeenschap stuwde het in de maanden die volgden voorbij de 178.000 GitHub-sterren.
Als je tuurt naar wat daar gebeurde, lijkt het sterk op wat elke engineering-organisatie uiteindelijk ontdekte nodig te hebben, na genoeg pijn: een gedeelde set beperkingen voor hoe code wordt geschreven. Een regelslaag. Het soort ding dat vroeger in een code review checklist leefde, of een stijlgids, of het institutionele geheugen van een senior engineer. De vibe coding-gemeenschap vond een veel lichtere versie van diezelfde discipline: schrijf de regels op in markdown en laat de agent ze lezen voordat hij code schrijft.
Dit is geen eenmalige zaak. Het is een patroon.
TL;DR
- Het ecosysteem van agent-instructies (CLAUDE.md, AGENTS.md, gedeelde skills-libraries en toegankelijkheidsagents) wordt een gedistribueerde kwaliteitsafdwingingslaag voor AI-ondersteund coderen.
- De kwaliteitskloof waarop het reageert is echt: Snyk scande 3.984 skills van ClawHub en skills.sh en vond dat 1.467, ofwel 36,82%, ten minste één beveiligingsfout had; 534, ofwel 13,4%, had ten minste één issue op kritiek niveau.
- De reactie van de gemeenschap was om meer regels te bouwen, niet om de aanpak op te geven, en instanties van Vercel tot OWASP tot de Linux Foundation zijn nu betrokken.
De kwaliteitskloof is echt, en de gemeenschap weet het

13,4% van de skills-bestanden van de gemeenschap bevat kritieke beveiligingsfouten. Dat komt uit Snyk's ToxicSkills-rapport, gepubliceerd in februari 2026 na het scannen van 3.984 skills van ClawHub en skills.sh. 36,82% had ten minste één beveiligingskwetsbaarheid. 76 waren ronduit kwaadaardig, waarbij 91% daarvan prompt injectie gebruikte als afleveringsmechanisme.
Het bredere verhaal over de kwaliteit van AI-code is vergelijkbaar. Volgens CodeRabbit's analyse van code review-data bevat AI-ondersteunde code gemiddeld 10,83 issues per pull request tegenover 6,45 voor door mensen geschreven code, ongeveer 1,7x meer issues. GitClear's jaarlijkse code-studie rapporteerde wat het "4x groei" noemt in code cloning: een stijging van 8,3% naar 12,3% van de gewijzigde regels tussen 2021 en 2024.
Dit zijn cijfers van leveranciers, dus neem de precisie met gepaste scepsis. Toch zijn ze qua richting nuttig: AI-ondersteund coderen creëert genoeg kwaliteitsdruk dat ontwikkelaars er nieuwe vangrails omheen bouwen.
Wat telt is wat de gemeenschap met deze informatie deed. De reactie was niet "skills-bestanden zijn gevaarlijk, stop met ze te gebruiken." Het was: OWASP lanceerde de Agentic Skills Top 10 (AST10), het skills-ecosysteem-equivalent van de Web Application Security Top 10. Meer regels. Meer structuur. Een formeel beveiligingsraamwerk voor een informeel ecosysteem.
Dat is een klassieke engineering-reactie, zelfs van een gemeenschap die vaak probeert zwaar proces te vermijden.
Het ecosysteem dat verscheen

In de eerste helft van 2026 begon dit er minder uit te zien als een handvol geïsoleerde markdown-bestanden en meer als een gelaagd ecosysteem.
Begin met de gedragslaag. De door Karpathy geïnspireerde CLAUDE.md verpakt Forrest Chang's versie van Andrej Karpathy's observaties over LLM-coding-faalmodi in een enkel instructiebestand, en het staat nu op meer dan 178.000 GitHub-sterren, een van de meest gesterde repositories in de geschiedenis van GitHub, voor een bestand gebouwd rond vier eenvoudige regels. Wat die regels zijn is minder interessant dan wat ze vertegenwoordigen: een poging om het oordeel te coderen dat een senior engineer tijdens een code review zou toepassen.
Daarboven zit een aggregatielaag van de gemeenschap. Antigravity Awesome Skills is voorbij de 1.595+ agentic skills gegaan, en verzamelt herbruikbare playbooks voor Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity en andere AI-codeerassistenten. Het functioneert als een snel bewegende gedeelde library voor het vakgebied: het soort ding dat een normalisatiecommissie zou kunnen produceren als het via GitHub in plaats van PDF's zou werken.
Toen verschenen de frameworks. Vercel maakte van vercel-labs/agent-skills een officiële organisatie-repository, nu op 28.000 sterren. De React Best Practices skill alleen al bevat 40+ regels verdeeld over acht prestatiegerichte categorieën, waaronder waterfalls, bundelgrootte, server-side prestaties, client-side dataophaling, re-render-optimalisatie, renderingprestaties en JavaScript micro-optimalisaties. Wanneer het bedrijf dat je deploymentplatform bezit officiële kwaliteitsregels voor AI-agents levert, is het ecosysteem afgestudeerd van community-experiment naar productie-infrastructuur.
En aan de top, een standaardenlaag. OpenAI doneerde de AGENTS.md-specificatie aan de Agentic AI Foundation (AAIF) van de Linux Foundation, naast MCP (Anthropic) en Goose (Block): cross-tool, cross-agent, standards-track. De richting is naar portabiliteit: AGENTS.md geeft teams een gedeelde plek voor projectspecifieke agent-aanwijzingen, ook al kunnen afzonderlijke tools nog steeds verschillen in hoe ze die instructies laden en toepassen.
Deze onderdelen verschenen niet als één centraal geplande stack. Ze convergeerden omdat de vraag echt was.
De dimensie waar niemand het over heeft
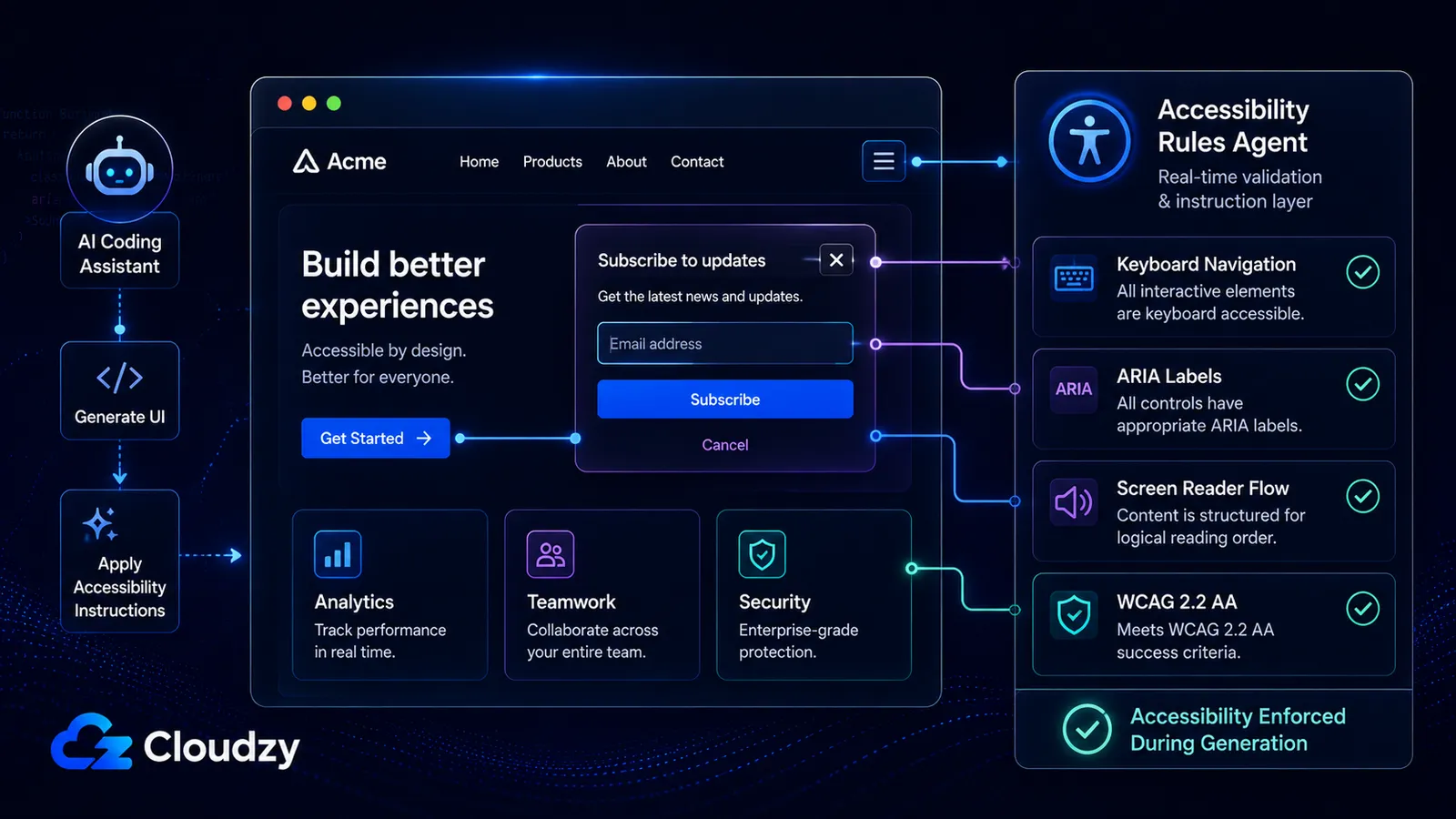
De data over beveiliging en codekwaliteit krijgt aandacht. De toegankelijkheidsdimensie vrijwel nooit.
Community-Access/accessibility-agents begon op 21 februari 2026 met zes agents. Per juni 2026: 79 gespecialiseerde agents verdeeld over acht teams, 18 herbruikbare toegankelijkheidsskills, gericht op WCAG 2.2 AA, en ondersteuning over vijf platforms: Claude Code, GitHub Copilot, Gemini CLI, Codex CLI, en een MCP Server die MCP-compatibele clients kan bedienen.
Wat dit project is, in gewone bewoordingen: een gemeenschap van ontwikkelaars besloot dat AI-codeertools standaard ontoegankelijke code genereren (ze slaan ARIA-regels over, negeren toetsenbordnavigatie, produceren modals die schermlezers vangen) en bouwden 79 gespecialiseerde agents om de regels af te dwingen die de AI steeds vergeet.
Dat is een opmerkelijk iets om te zien gebeuren. Frontend-engineers hebben historisch ondergepresteerd op toegankelijkheid. Het is het eerste wat sneuvelt onder deadlinedruk. Het accessibility-agents-project is vibe coders die de regels schrijven die ze anders een senior engineer zouden nodig hebben om af te dwingen, en dat in het openbaar doen, gratis, over vijf ondersteunde integraties.
In mijn lezing is het project ongewoon grondig voor een vrijwilligersinspanning op het gebied van toegankelijkheid, vooral omdat het toegankelijkheid omzet van een late QA-zorg naar herbruikbare agent-instructies die draaien tijdens de codegeneratie.
Waarom dit onvermijdelijk was
Het argument dat "skills-bestanden gewoon READMEs voor AI zijn" is terecht als je naar één bestand kijkt. Het houdt niet langer stand wanneer je kijkt naar OWASP die een beveiligingsraamwerk voor het ecosysteem lanceert, Vercel die een officiële kwaliteitslibrary levert, of een vrijwilligersproject voor toegankelijkheid dat uitgroeit tot 79 gespecialiseerde agents.
Hier is wat er werkelijk gebeurt: kwaliteitsafdwinging verdwijnt niet wanneer je proces weghaalt. Het verschijnt opnieuw in een andere vorm, omdat de afwezigheid van kwaliteit snel pijn veroorzaakt, en de persoon die het dichtst bij die pijn staat lost het bij de bron op.
Traditionele engineering-discipline (code review, stijlgidsen, QA-gates, architecturale governance) bestaat om op te vangen wat individuele ontwikkelaars overslaan onder tijdsdruk. Het werkt wanneer je een team en een proces hebt. Vibe coders hebben, door hun aard, vaak geen van beide. Dus codeerden ze de review vooraf in de instructies van de agent.
CLAUDE.md is vooraf gecodeerde code review. Awesome Skills is een gedistribueerde stijlgids. AGENTS.md is een governance-standaard. De woorden veranderden. De functie niet.
Wat interessant is, is niet dat de beperkingen opnieuw verschenen, dat was onvermijdelijk. Wat interessant is, is dat ze sneller opnieuw verschenen dan de eerste keer, en meer in het openbaar, en op een kwaliteitsniveau dat sommige engineering-organisaties met volwassen processen beschaamt.
De vibe coding-gemeenschap vond engineering-discipline niet met tegenzin opnieuw uit, onder druk van het management. Ze bouwden het omdat ze tegen een muur aanliepen en de tools om het te fixen een markdown-bestand verderop lagen.
Veelgestelde vragen
Wat gaat er in een CLAUDE.md-bestand?
Gedragsbeperkingen voor de AI: wat te vermijden, wat prioriteit te geven, architecturale regels, beveiligings-rode-vlaggen en projectspecifieke conventies. Op kwaliteit gericht gebruik gaat verder dan workflow-snelkoppelingen: regels als "verwijder nooit foutafhandeling om tests te laten slagen" staan naast "gebruik altijd TypeScript." Voor echte, geteste voorbeelden begin je met de Awesome Skills community-aggregatie. Vercel's agent-skills is nog een sterke referentie.
Wat is AGENTS.md en hoe verschilt het van CLAUDE.md?
AGENTS.md is een universele standaard voor projectspecifieke agent-aanwijzingen, uitgebracht door OpenAI en bijgedragen aan de Agentic AI Foundation van de Linux Foundation in december 2025. CLAUDE.md is het projectaanwijzingsbestand van Claude Code. Ze overlappen in doel, maar ze zijn niet in elke tool identieke formaten. De praktische conclusie is dat teams agent-instructies steeds vaker één keer kunnen schrijven en ze kunnen aanpassen over tools zoals Codex, Cursor, Copilot, Gemini CLI en Claude Code.
Zijn skills-bestanden veilig om te gebruiken?
Skills uit de gemeenschap zouden gelezen moeten worden voordat je ze importeert. Snyk's ToxicSkills-rapport vond dat 36% van de gescande community-skills ten minste één beveiligingsfout had, en 13,4% kritieke fouten had, met prompt injectie als het primaire aanvalsmechanisme. De OWASP Agentic Skills Top 10 is het referentieraamwerk voor het begrijpen van het aanvalsoppervlak. Skills-bestanden uit officiële repositories of gevestigde open-source projecten dragen over het algemeen een lager supply-chain-risico dan anonieme community-bijdragen, maar ze zouden toch gereviewd moeten worden voor import.
Wat is de OWASP Agentic Skills Top 10 (AST10)?
OWASP's beveiligingsraamwerk uit 2026 voor het skills-ecosysteem, analoog aan de OWASP Web Application Security Top 10 maar specifiek gericht op het aanvalsoppervlak dat wordt gecreëerd door AI-agent-instructiebestanden. Het dekt de tien meest kritieke beveiligingsrisico's over platforms waaronder Claude Code, Cursor/Codex en VS Code. Het raamwerk is in actieve ontwikkeling per 2026, met een v1.0-release gepland voor Q4 2026.
Heb ik skills-bestanden nodig als ik een persoonlijk project bouw?
Alleen als je consistent AI-gedrag wilt. Zonder beperkingen optimaliseren AI-codeertools voor taakvoltooiing, niet voor codekwaliteit, wat prima werkt totdat het gedupliceerde logica, ontbrekende foutafhandeling of ontoegankelijke UI-componenten produceert. De overhead is laag: één bestand per project, onderhouden naarmate je ontdekt wat de AI steeds verkeerd doet. De door Karpathy geïnspireerde regels zijn een redelijk uitgangspunt; de community skills-libraries laten je domeinspecifieke regels (beveiliging, toegankelijkheid, taalidiomen) binnenhalen zonder ze vanaf nul te schrijven.