
Otwierasz stronę GGUF popularnego modelu na Hugging Face i patrzy na ciebie piętnaście plików: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus osobne foldery dla GPTQ, AWQ i EXL2 przy pół tuzinie ustawień bitowych. Robisz szybkie obliczenia na serwetce dla pliku „4-bitowego”: 4 bity × 8 miliardów parametrów ÷ 8 = 4 GB. Ale plik pokazuje 4,6 GB. A gdy już go wczytasz, model zużywa jeszcze więcej pamięci.
Nazwy plików to nie szum. Kodują one realne, przyswajalne informacje o szerokości bitowej, środowisku uruchomieniowym, które je wczytuje, oraz sprzęcie, jakiego wymagają. Tabele rozmiarów, które czytałeś, mówią, że model 70B potrzebuje mniej więcej 40 GB, co jest przydatne, ale nigdy nie dekodują samego formatu ani nie tłumaczą, dlaczego działający model chce więcej pamięci niż plik na dysku.
Oto plan: rozszyfrować konwencję nazewnictwa GGUF (z prawdziwymi, nie nominalnymi szerokościami bitowymi), ustalić, który z czterech formatów twój sprzęt faktycznie może uruchomić, i uwzględnić jeden koszt pamięci niewidoczny w każdym rozmiarze pliku, pamięć podręczną KV. Na koniec będziesz w stanie odczytać repozytorium modelu i przewidzieć, jak zachowa się po wczytaniu.
TL;DR
- Poziomy kwantyzacji GGUF to efektywne szerokości bitowe, a nie dokładna liczba w nazwie. Q4_K_M to około 4,89 bita na wagę, dlatego „4-bitowy” plik 8B wychodzi na około 4,6 GiB zamiast naiwnego szacunku 4-bitowego.
- GGUF to najbardziej przenośna opcja, ponieważ llama.cpp może go uruchomić na CPU, GPU lub w konfiguracji hybrydowej. GPTQ, AWQ i EXL2 są bardziej specyficzne dla GPU i środowiska uruchomieniowego, przy czym EXL2 jest szczególnie związany z przepływami pracy NVIDIA/CUDA.
- Pamięć podręczna KV jest oddzielona od wag modelu i rośnie wraz z długością kontekstu. To dlatego model, który wczytuje się bez problemu, wciąż może ulec awarii z powodu braku pamięci, gdy rozmowa się wydłuży.
- Powyżej zakresu 5-bitowego utrata jakości jest zwykle niewielka. Wokół Q4 kompromis wciąż jest praktyczny dla wielu lokalnych zastosowań. Poniżej 4 bitów koszt jakości staje się dużo bardziej zauważalny. Q4_K_M pozostaje popularnym domyślnym wyborem społeczności, podczas gdy Q5_K_M i Q6_K są bezpieczniejsze, gdy masz pamięć do rozdania.
Co oznacza Q4_K_M w nazwie pliku GGUF?

Nazwa kwantyzacji GGUF ma wzór Q[bity]_[K]_[S/M/L]. Liczba to docelowa wartość bitów na wagę, K oznacza, że to „K-kwant”, który przechowuje współczynniki skalowania dla każdego małego bloku wag, a końcowe S, M lub L to poziom rozmiaru/jakości (mały, średni, duży). Ponieważ K-kwanty przechowują skalę i wartość minimalną dla każdego bloku obok wag, efektywna szerokość bitowa jest wyższa niż liczba w nagłówku. Q4_K_M wychodzi na około 4,89 bita na wagę, nie 4.
Ta różnica to cała odpowiedź na pytanie „dlaczego mój plik 4-bitowy waży 4,6 GB?”. Naiwne oszacowanie zakłada, że każda waga kosztuje dokładnie 4 bity. W rzeczywistości K-kwanty wydają dodatkowe bity na blok na metadane, które sprawiają, że niskobitowa kwantyzacja jest dokładna, skalę i minimum na blok, które pozwalają środowisku uruchomieniowemu odtworzyć każdą wagę. Pomnóż 4,89 bita przez 8 miliardów wag i wychodzi około 4,58 GiB, czyli tyle, ile plik faktycznie waży.
Oto zmierzone efektywne szerokości bitowe i rozmiary plików, zaczerpnięte z llama.cpp quantize documentation , dla Llama 3.1 8B jako modelu referencyjnego, wraz z kosztem perplexity dla każdego poziomu zmierzonym w pracy oceniającej kwantyzację llama.cpp (arXiv:2601.14277) na Llama-3.1-8B-Instruct:
| Poziom GGUF | Efektywne BPW | ~Rozmiar pliku (8B) | Perplexity vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | punkt odniesienia |
*Wartości perplexity dotyczą konkretnie Llama-3.1-8B-Instruct z arXiv:2601.14277. Kolumna BPW/rozmiar pliku i kolumna perplexity pochodzą z dwóch różnych źródeł mierzonych osobno, więc czytaj tabelę jako praktyczne zestawienie obok siebie, a nie jeden pojedynczy przebieg benchmarku. Degradacja zależna od zadania jest różna, wnioskowanie matematyczne zwykle cierpi bardziej niż rozumowanie zdroworozsądkowe przy niskich szerokościach bitowych, ale ogólny kształt się utrzymuje: 5 bitów i więcej jest zwykle bezpieczniejsze, Q4 to praktyczna strefa kompresji, a przy 3 bitach utrata jakości staje się dużo trudniejsza do zignorowania.
Praktycznie: Q4_K_M to domyślny wybór, po który powinna sięgać większość osób, Q5_K_M i Q6_K to wybory stawiające na jakość, gdy masz pamięć do rozdania, a wszystko na poziomie Q3_K_S lub poniżej to ostatnia deska ratunku dla sprzętu, który naprawdę nie zmieści więcej.
Który format kwantyzacji powinieneś pobrać: GGUF, GPTQ, AWQ czy EXL2?

GGUF jest najbardziej przenośny z czterech formatów: działa na CPU, GPU lub hybrydzie obu przez llama.cpp, więc jest najbezpieczniejszym wyborem, gdy nie masz pewności, co obsłuży twój sprzęt. GPTQ, AWQ i EXL2 są bardziej specyficzne dla GPU i środowiska uruchomieniowego. W praktyce są najczęstsze w konfiguracjach NVIDIA/CUDA, ale wsparcie GPTQ i AWQ może się różnić w zależności od loadera i stosu serwującego; vLLM na przykład rozdziela wsparcie kwantyzacji według sprzętu i implementacji. Jeśli działasz lokalnie na Macu, karcie AMD lub maszynie tylko z CPU, GGUF wciąż jest najbezpieczniejszą odpowiedzią. Jeśli masz GPU NVIDIA i chcesz jak najszybszych tokenów, wchodzą w grę pozostałe trzy.
| Format | Sprzęt/środowisko uruchomieniowe | Szybkość (względna) | VRAM w porównaniu z innymi | Najlepszy dla |
|---|---|---|---|---|
| GGUF Q4_K_M | Najszerszy, CPU, GPU lub hybryda przez llama.cpp | Umiarkowany | Najniższy | Dowolny sprzęt; domyślny lokalny |
| GPTQ 4-bit | Zwykle priorytetowo CUDA/GPU; zależne od środowiska uruchomieniowego | Szybki (ExLlama) | Średnie | Priorytetowo GPU, starsze narzędzia |
| AWQ 4-bit | Zwykle priorytetowo CUDA/GPU; zależne od środowiska uruchomieniowego | Szybko | Najwyższy | Serwowanie przez vLLM/TGI, szybkie wczytywanie |
| EXL2 ~4,9 bpw | Priorytetowo NVIDIA/CUDA | Najszybszy | Nisko-Średnie | Maksymalna szybkość na NVIDIA |
Zastrzeżenie do tej tabeli: rankingi szybkości i VRAM pochodzą z benchmarku oobabooga, który działał na sprzęcie z lat 2023/2024. Traktuj względny porządek jako trwały. EXL2 jest zbudowany pod szybkość, AWQ oddaje VRAM za szybkie wczytywanie, GGUF pozostaje lekki i przenośny, ale nie odczytuj oryginalnych bezwzględnych liczb tokenów na sekundę jako aktualnych. GPU z 2026 roku osiągnie zupełnie inną surową przepustowość; to kolejność jest tym, co się utrzymuje.
Z tego wynika więc reguła decyzyjna: jeśli masz kartę NVIDIA i najbardziej zależy ci na szybkości, EXL2; jeśli chcesz najbezpieczniejszej domyślnej opcji lokalnej na różnym sprzęcie, GGUF. AWQ i GPTQ mają znaczenie głównie wtedy, gdy konkretny stos serwujący (vLLM, TGI) lub istniejące narzędzia cię tam kierują.
Dlaczego lokalny LLM zużywa więcej pamięci niż jego plik?
Rozmiar pliku to tylko wagi modelu. W czasie działania płacisz też za pamięć podręczną KV (stan uwagi dla każdego tokena w oknie kontekstu), aktywacje (pośrednie obliczenia przejścia w przód) oraz narzut frameworka i sterownika. Razem elementy niebędące wagami w konfiguracji jednoosobowej zwykle dodają 10 do 20% ponad wagi, a sama pamięć podręczna KV może przyćmić wszystko, gdy kontekst się wydłuży. Plik 4,6 GB może potrzebować znacznie więcej niż 4,6 GB pamięci, by działać.
Wyobraź sobie pamięć w czasie działania jako cztery komponenty ułożone jeden na drugim:
- Wagi modelu. Plik, który pobrałeś. To jedyny element widoczny przed wczytaniem.
- Pamięć podręczna KV. Stan uwagi dla okna kontekstu. Mały przy krótkim kontekście, ogromny przy długim kontekście. To temat kolejnej sekcji, bo to on zaskakuje ludzi.
- Aktywacje. Pamięć robocza przejścia w przód. Dla jednostrumieniowej lokalnej inferencji (rozmiar wsadu 1) jest mała, zwykle kilkaset megabajtów.
- Narzut frameworka. Własny ślad środowiska uruchomieniowego plus kontekst sterownika GPU. Dla lekkiego lokalnego środowiska może być mały w porównaniu z wagami modelu i pamięcią podręczną KV; cięższe frameworki serwujące mogą rezerwować dużo więcej. Własna rezerwacja pamięci przez system operacyjny leży poza tym i jest znowu osobna.
Wagi i narzut frameworka są przewidywalne. Pamięć podręczna KV jest zmienną, która zamienia model, który się „mieści”, w model, który ulega awarii, więc warto przejść przez rzeczywistą matematykę.
Ile pamięci zużywa pamięć podręczna KV?
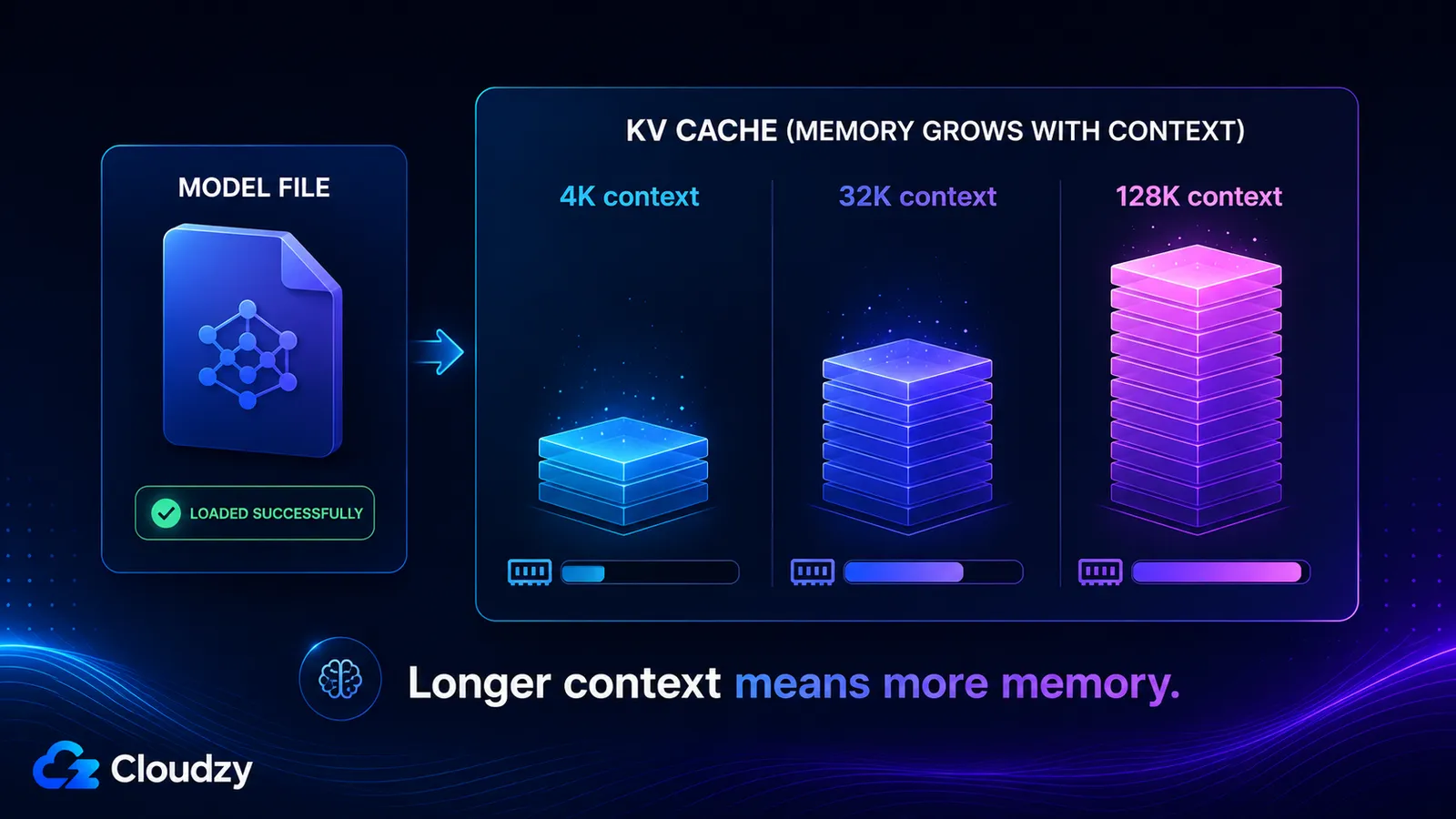
Pamięć podręczna KV przechowuje wektory klucza i wartości dla każdego tokena w oknie kontekstu, więc rośnie mniej więcej liniowo wraz z długością kontekstu i jest całkowicie oddzielona od wag modelu. Jej rozmiar zależy od liczby warstw modelu, liczby głowic KV, wymiaru głowicy, długości kontekstu i precyzji pamięci podręcznej. Włącz długi kontekst, a możesz dodać dziesiątki gigabajtów, o których model, który wczytał się bez problemu, nigdy cię nie ostrzegł.
Wzór jest wystarczająco krótki, by zapamiętać go na pamięć:
bajty pamięci podręcznej KV = 2 × warstwy × kv_heads × head_dim × context_tokens × bytes_per_element
Wiodąca 2 to za dwa tensory przechowywane na token, jeden dla kluczy, jeden dla wartości. bytes_per_element to 2 dla pamięci podręcznej FP16. Reszta to stałe architektoniczne, które odczytasz z karty modelu.
Policzmy to dla Llama 3.1 8B, która ma 32 warstwy, 8 głowic KV i wymiar głowicy 128. Przy kontekście 4096 tokenów, rozmiarze wsadu 1, pamięci podręcznej FP16:
2 × 32 × 8 × 128 × 4096 × 2 bajty ≈ 536 MB
Zwiększ kontekst, a liczba rośnie razem z nim, ponieważ każdy człon oprócz context_tokens jest stały:
- Kontekst 4K: ~536 MB
- Kontekst 32K: ~4,3 GB
- Kontekst 128K: ~17 GB
Te dwa ostatnie tłumaczą, dlaczego model może deklarować okno kontekstu 128K, wczytać się bez problemu, a potem wyczerpać pamięć w chwili, gdy faktycznie użyjesz tego okna. Pamięć podręczna KV przy pełnym kontekście jest większa niż same skwantyzowane wagi.
Oto część, dzięki której nowoczesne modele z długim kontekstem są w ogóle możliwe: Llama 3.1 8B używa Grouped Query Attention (GQA)Ma 32 głowice zapytań, ale tylko 8 głowic KV, pamięć podręczna przechowuje wektory klucz/wartość dla 8 głowic, nie 32. Uruchom ten sam wzór z 32 głowicami KV (starszy projekt Multi-Head Attention, w którym głowice KV równają się głowicom zapytań) i każda liczba powyżej mnoży się przez 4. Te 17 GB przy 128K staje się 68 GB. GQA to architektoniczny powód, dla którego matematyka pozostaje do udźwignięcia w miarę wzrostu okien kontekstu.
Rozmiar pliku to nie twój budżet pamięci. Gdy wagi lub pamięć podręczna KV przestają mieścić się na szybkiej ścieżce pamięci i środowisko uruchomieniowe musi przejść na RAM systemu przez PCIe, przepustowość nie degraduje się łagodnie. Spada gwałtownie, gdy przesuwasz dane przez PCIe przy każdym tokenie. Zaplanuj pamięć tak, by mieściły się zarówno wagi, jak i pamięć podręczna KV przy twojej rzeczywistej długości kontekstu, nie tylko same wagi.
Jak wybrać kwantyzację dla swojego GPU lub Maca?
Zacznij od swojego sprzętu i środowiska uruchomieniowego. Posiadacze GPU NVIDIA mają najszersze menu i powinni rozważyć EXL2 dla surowej szybkości lub GGUF dla przenośności. Jeśli masz AMD, Apple Silicon, sprzęt tylko z CPU lub konfigurację mieszaną, GGUF przez llama.cpp jest zwykle najbezpieczniejszym punktem wyjścia. Stamtąd wybierz najwyższy poziom kwantyzacji, który się zmieści po zaplanowaniu pamięci podręcznej KV dla długości kontekstu, której faktycznie używasz, a nie maksimum modelu.
Jedna pułapka Apple Silicon, o której warto wiedzieć: GPU nie dostaje całej twojej pamięci zunifikowanej (pełny obraz działania tej współdzielonej puli znajdziesz w naszym powiązanym artykule o tym, czym pamięć zunifikowana jest naprawdę ). Społeczność self-hostingu udokumentowała limit na poziomie około 75% z całkowitej pamięci zunifikowanej dostępnej dla GPU (nie jest to oficjalnie potwierdzone przez Apple i może się zmieniać wraz z aktualizacjami macOS). Więc „64 GB Mac” to realistycznie ~48 GB dla modelu plus jego pamięć podręczna KV, planuj według mniejszej liczby.
Ten artykuł dotyczy odczytywania formatu i przewidywania jego zachowania w czasie działania: rozszyfrowania nazwy kwantyzacji, wyboru formatu obsługiwanego przez twój sprzęt oraz zaplanowania pamięci podręcznej KV osobno od wag. Dopasowanie konkretnego modelu do konkretnej ilości pamięci, tabela odniesienia rozmiar-do-pamięci, to powiązane, ale osobne zagadnienie, które omówimy w przyszłym powiązanym artykule.
Przeczytaj repozytorium
Możesz teraz spojrzeć na stronę modelu i ją przeczytać zamiast zgadywać. Rozszyfruj nazwę kwantyzacji do jej efektywnej szerokości bitowej, uznaj, że GGUF to najszerszy lokalny format, podczas gdy GPTQ, AWQ i EXL2 są bardziej specyficzne dla środowiska uruchomieniowego, i pamiętaj, że rozmiar pliku to tylko podłoga, pamięć podręczna KV nakłada się na to i rośnie wraz z twoim kontekstem. Otwórz pliki dla modelu, który chcesz, wybierz format obsługiwany przez twój sprzęt, wybierz najwyższy poziom kwantyzacji, który się mieści po pozostawieniu miejsca na pamięć podręczną KV przy twojej rzeczywistej długości kontekstu, a unikniesz awarii z braku pamięci, która zapoczątkowała całe to pytanie.
Często zadawane pytania
Co oznacza Q4_K_M?
Q4_K_M to poziom kwantyzacji GGUF: mniej więcej 4 bity na wagę (Q4), przy użyciu skalowania K-kwant na blok (K), na średnim poziomie rozmiaru/jakości (M). Jego efektywna efektywnej wynosi około 4,89 bita na wagę, nie dokładnie 4, ponieważ K-kwanty przechowują skalę i wartość minimalną dla każdego bloku wag. Dlatego plik „4-bitowego” modelu 8B ma około 4,6 GB, a nie 3,5 GB.
Czy kwantyzacja obniża jakość LLM?
Tak, ale koszt zależy w dużym stopniu od tego, jak daleko to popchniesz. Dla Llama-3.1-8B-Instruct zmierzonego w arXiv:2601.14277 perplexity rośnie zaledwie o około 0,4% przy Q6_K i pozostaje blisko 1% w całym paśmie Q5. Zejdź do Q4, a wzrost wciąż jest skromny (kilka procent); poniżej Q3_K_M rośnie gwałtownie, osiągając +22% przy Q3_K_S. Dla większości zastosowań Q4_K_M i wyżej jest praktycznie bezstratny; stroma kara zaczyna się przy 3 bitach i poniżej.
Jaka jest różnica między GGUF, GPTQ, AWQ i EXL2?
GGUF (uruchamiany przez llama.cpp) to format przenośny, działa na CPU, GPU lub w konfiguracji hybrydowej na szerokim zakresie sprzętu. GPTQ, AWQ i EXL2 są bardziej specyficzne dla GPU i środowiska uruchomieniowego. Przy 4 bitach cała czwórka może wylądować w wąskim paśmie jakości, więc praktyczna różnica to sprzęt, wsparcie loadera, szybkość i wykorzystanie VRAM: EXL2 to wybór zorientowany na szybkość dla NVIDIA/CUDA, AWQ jest powszechny w stosach serwujących, GPTQ pasuje do starszych narzędzi GPU i repozytoriów modeli, a GGUF pozostaje najbardziej przenośną opcją lokalną.
Dlaczego mój lokalny LLM zużywa więcej pamięci niż plik?
Rozmiar pliku to tylko wagi modelu. W czasie działania płacisz też za pamięć podręczną KV (stan uwagi dla każdego tokena w oknie kontekstu), aktywacje oraz narzut frameworka i sterownika. Pamięć podręczna KV to zwykły winowajca, gdy różnica jest duża, ponieważ rośnie wraz z długością kontekstu i jest przydzielana osobno od wag, model, którego plik ma kilka gigabajtów, może potrzebować znacznie więcej pamięci po ustawieniu długiego kontekstu.
Jak długość kontekstu wpływa na zużycie pamięci?
Pamięć podręczna KV rośnie mniej więcej liniowo wraz z długością kontekstu, więc podwojenie kontekstu mniej więcej podwaja pamięć podręczną. Dla Llama 3.1 8B pamięć podręczna wynosi około 536 MB przy 4K tokenach, ~4,3 GB przy 32K i ~17 GB przy 128K (FP16, pojedynczy strumień). Ten wzrost jest całkowicie oddzielony od wag modelu, dlatego deklarowanie długiego okna kontekstu może wpędzić model w brak pamięci, mimo że wczytał się bez problemu.


