
Zamień GPT-5 na Claude w działającym agencie i przez większość czasu prawie nic się nie zmieni. Zmień sposób obsługi ponownych prób, to co podajesz do okna kontekstu lub kiedy agent decyduje się zatrzymać, a cały agent zachowuje się inaczej. Ta różnica jest wskazówką: model jest najmniejszą i najłatwiej wymienialną częścią działającego agenta. Ciekawa inżynieria tkwi we wszystkim, co go otacza.
Ten wrapper ma teraz nazwę. Praktycy przyjęli termin "harness" dla warstwy, która przekształca generator tekstu w coś, co z czasem podejmuje działania, zamiast uruchamiać stały skrypt. Termin szybko rozprzestrzenił się na Twitterze i blogach inżynierskich na początku 2026 roku, co oznacza, że był też używany swobodnie, a to samo słowo robiło nieco inną pracę w każdym czytanym wpisie. Ten artykuł to precyzuje: czym jest harness, z czego się składa, czym różni się od "frameworku" i "scaffoldu" oraz dlaczego większość jakości twojego agenta kryje się w harness, a nie w modelu.
Krótka wersja
- Agent harness to oprogramowanie otaczające LLM, które zarządza pętlą wykonawczą, narzędziami, pamięcią, kontekstem, stanem, obsługą błędów i zabezpieczeniami. Model generuje tekst; harness decyduje, co model widzi, co może robić, kiedy się zatrzymać i co się dzieje, gdy coś się psuje.
- Na produkcji wywołanie modelu jest często najmniejszą widoczną częścią powierzchni systemu. Słabszy model w dobrze zbudowanym harness może pokonać silniejszy model w niedopracowanym, szczególnie przy długotrwałych zadaniach wymagających wielu narzędzi.
- Harness ma około dziewięciu do jedenastu powtarzających się komponentów. Większość z nich to rzeczy, których model nigdy nie dotyka bezpośrednio.
- "Harness" to nie to samo co "framework". Framework (LangGraph, agents SDK) to biblioteka, przy pomocy której budujesz; harness to działająca warstwa, którą ta biblioteka pomaga ci złożyć.
Czym jest Agent Harness?
Agent harness to infrastruktura oprogramowania otaczająca model językowy, która zarządza pętlą wykonawczą, dostępem do narzędzi, pamięcią, kontekstem, trwałością stanu, obsługą błędów i zabezpieczeniami. Model generuje tekst. Harness decyduje, co model widzi w każdej turze, jakie działania może podjąć, kiedy się zatrzymuje i co się dzieje, gdy krok zawiedzie.
Najczystsze ujęcie pochodzi od LangChain, którzy sprowadzają to do równania: Agent = Model + Harness. Model dostarcza inteligencji. Harness to to, co sprawia, że ta inteligencja cokolwiek robi w realnym świecie.
"Harness to każdy fragment kodu, konfiguracji i logiki wykonania, który nie jest samym modelem."
— LangChain, Anatomia harness agenta
Granicę najłatwiej wyczuć przez jedno pytanie: gdy twój agent robi coś złego, czy rozumowanie samego modelu było błędne, czy też otaczający go system dostarczył modelowi zły kontekst, złe narzędzia lub brak możliwości odzyskania? W przypadku prawdziwego systemu przez większość czasu jest to to drugie. Model poprawnie rozumował nad złymi danymi wejściowymi. Harness kontroluje dane wejściowe.
Kluczowy wniosek: Model generuje; harness rządzi. Ten podział to cały koncept.
Jakie są komponenty harness agenta?
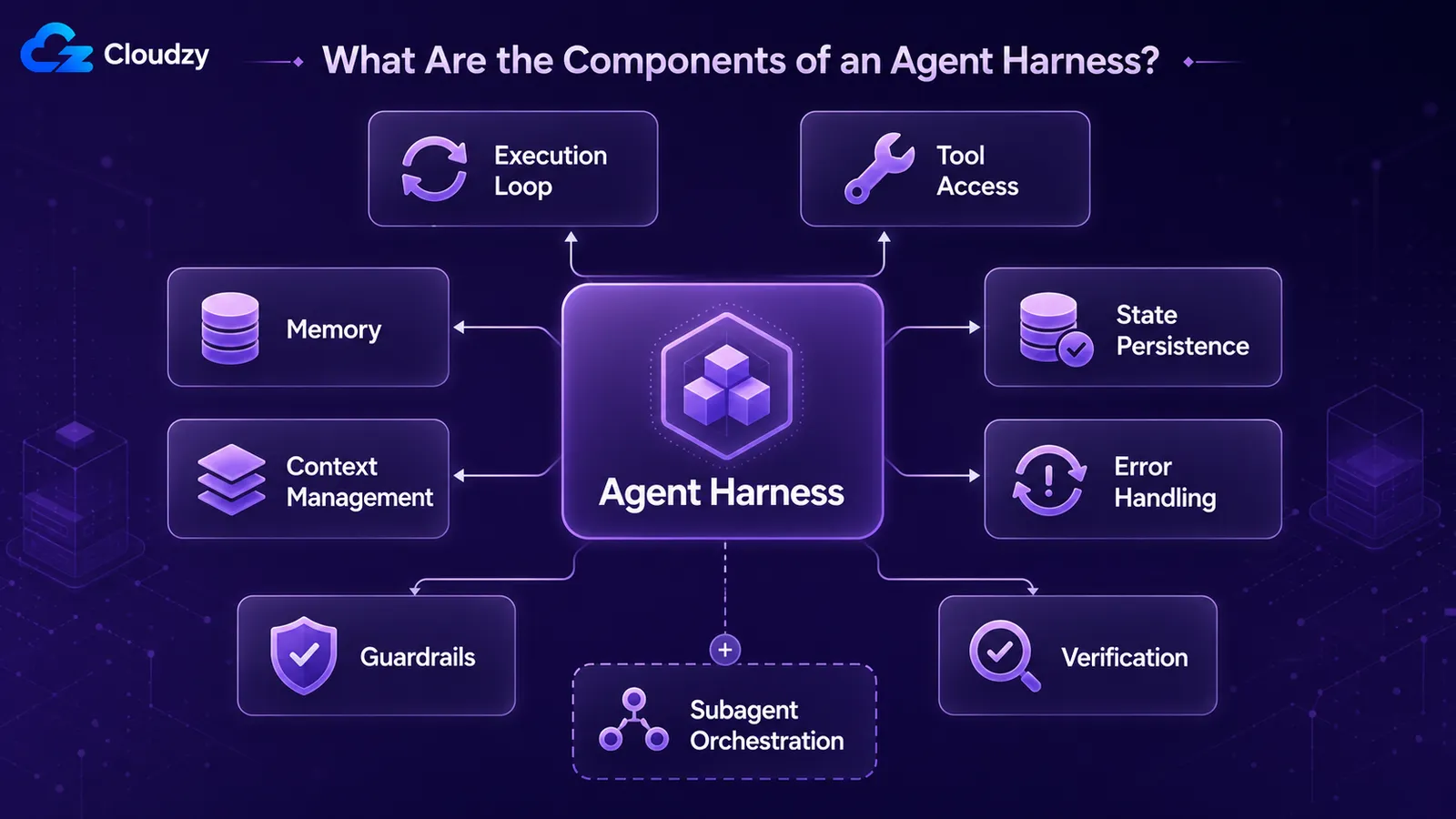
Każdy produkcyjny harness składa się z tych samych powtarzających się części: pętli wykonania napędzającej model tura po turze, dostępu do narzędzi umożliwiającego mu działanie, pamięci między turami, zarządzania kontekstem dla tego, co widzi teraz, trwałości stanu, aby praca przetrwała między sesjami, obsługi błędów dla nieudanych kroków oraz zabezpieczeń ograniczających to, co może robić. Systemy produkcyjne dodają pętle weryfikacji i orkiestrację subagentów.
Przydatna lista, oparta na tym, jak praktycy opisują rzeczywiste systemy:
- Pętla wykonania / sterowania: to, co napędza agenta krok po kroku. Wywołaj model, odczytaj jego dane wyjściowe, uruchom żądane narzędzie, zwróć wynik, powtarzaj do warunku zatrzymania.
- Dostęp do narzędzi: funkcje, API, wykonywanie kodu i system plików, do których model ma dostęp.
- Pamięć: to, co agent zachowuje między turami i sesjami.
- Zarządzanie kontekstem: co jest pakowane do okna modelu w każdej turze i co jest kompaktowane, gdy przepełni.
- Trwałość stanu / checkpointing: zapisywanie stanu agenta, aby przerwane lub wstrzymane wykonanie mogło zostać wznowione.
- Obsługa błędów: ponowne próby, alternatywy i odzyskiwanie po błędzie wywołania narzędzia lub modelu.
- Zabezpieczenia: ograniczenia dotyczące tego, co agent może robić, takie jak dozwolone narzędzia, limity kroków i walidacja wyjścia.
- Pętle weryfikacji: agent (lub harness) sprawdza własną pracę przed uznaniem jej za zakończoną.
- Orkiestracja subagentów: tworzenie subagentów, delegowanie im zadań i zbieranie wyników przy większych zadaniach.
Nie wszystkie z nich są uniwersalne. Pętla wykonania, narzędzia, obsługa kontekstu i obsługa błędów pojawiają się nawet w weekendowym prototypie. Trwałość stanu, weryfikacja i orkiestracja subagentów to miejsca, gdzie prototypy i systemy produkcyjne się rozchodzą. Prototyp może je pominąć; długo działający agent produkcyjny nie może. Opis Anthropic dotyczący długo działające agenty jest przeglądem części wyłącznie produkcyjnych: jak agent odbudowuje swoje rozumienie z pliku postępu po zresetowaniu okna kontekstu i jak testowanie jest wplatane w pętlę.
Dla tych, którzy chcą pomostu akademickiego, niedawny przegląd architektur agentów składa ten sam mechanizm w mniejszą formalną krotkę podstawowych komponentów. Lista praktyka i ramowanie przeglądu to dwa poziomy przybliżenia tej samej struktury: przegląd kompresuje, powyższy inwentarz rozszerza. Traktuj liczbę od dziewięciu do jedenastu jako komponenty, które podziela większość produkcyjnych harness, a nie jako ratyfikowany standard; dziedzina nie ratyfikowała jeszcze niczego.
Kluczowy wniosek: Większość ruchomych części agenta żyje w harness, nie w modelu. Model jest jednym z wielu komponentów.
Dlaczego harness jest ważniejszy niż model?
Słabszy model w dobrze zaprojektowanym harness często przewyższa mocniejszy model w źle zaprojektowanym. Powód jest mechaniczny, nie magiczny: niezawodność end-to-end agenta jest iloczynem niezawodności każdego kroku, a większość tych kroków (wybór narzędzi, składanie kontekstu, odzyskiwanie po błędach) to zadanie harness, a nie modelu. Popraw je, a cały łańcuch stanie się bardziej niezawodny, niezależnie od tego, jaki model jest w środku.
Arytmetyka to konkretyzuje. Załóżmy, że każdy krok w zadaniu składającym się z dziesięciu kroków kończy się sukcesem 99% czasu. Sukces end-to-end nie wynosi 99%. To 0,99 do potęgi dziesiątej, czyli około 90%. Popchnij każdy krok do 99,9%, a end-to-end skoczy do około 99%. Niezawodność na krok kumuluje się, a niezawodność na krok jest przytłaczająco właściwością harness. Dlatego optymalizacja obsługi błędów i zarządzania kontekstem przynosi więcej korzyści niż wymiana modelu na pół punktu lepszego w jakimś benchmarku.
Istnieje sygnał produkcyjny wskazujący w tym samym kierunku. MongoDB, powołując się na studium przypadku Vercel, informuje, że Vercel ograniczył większość narzędzi swojego agenta i obserwował, jak wskaźnik sukcesu gwałtownie wzrósł na tym samym modelu, z mniejszym i czystszym harness. Czytaj to jako dowód zbieżny, a nie dowód: to jeden przypadek produkcyjny, nie kontrolowany eksperyment, ale wskazuje w tym samym kierunku co powyższa arytmetyka złożona i praca ankietowa.
To jest heurystyka, do której wracam jako inżynier platformy: kontekst jest wąskim gardłem, a nie surową zdolnością modelu, a rusztowanie zbudowane do łatania dzisiejszych luk modelu ma tendencję do bycia pochłanianym w miarę ulepszania modeli. Buduj trwałe części harness (pętlę, stan, odzyskiwanie) i pozwól, aby model pod spodem poprawiał się według własnego harmonogramu.
Kluczowy wniosek: Gdy twój agent zawodzi, podejrzewaj harness przed modelem. Statystyki przemawiają za tym.
Jaka jest różnica między harness, scaffold a frameworkiem?
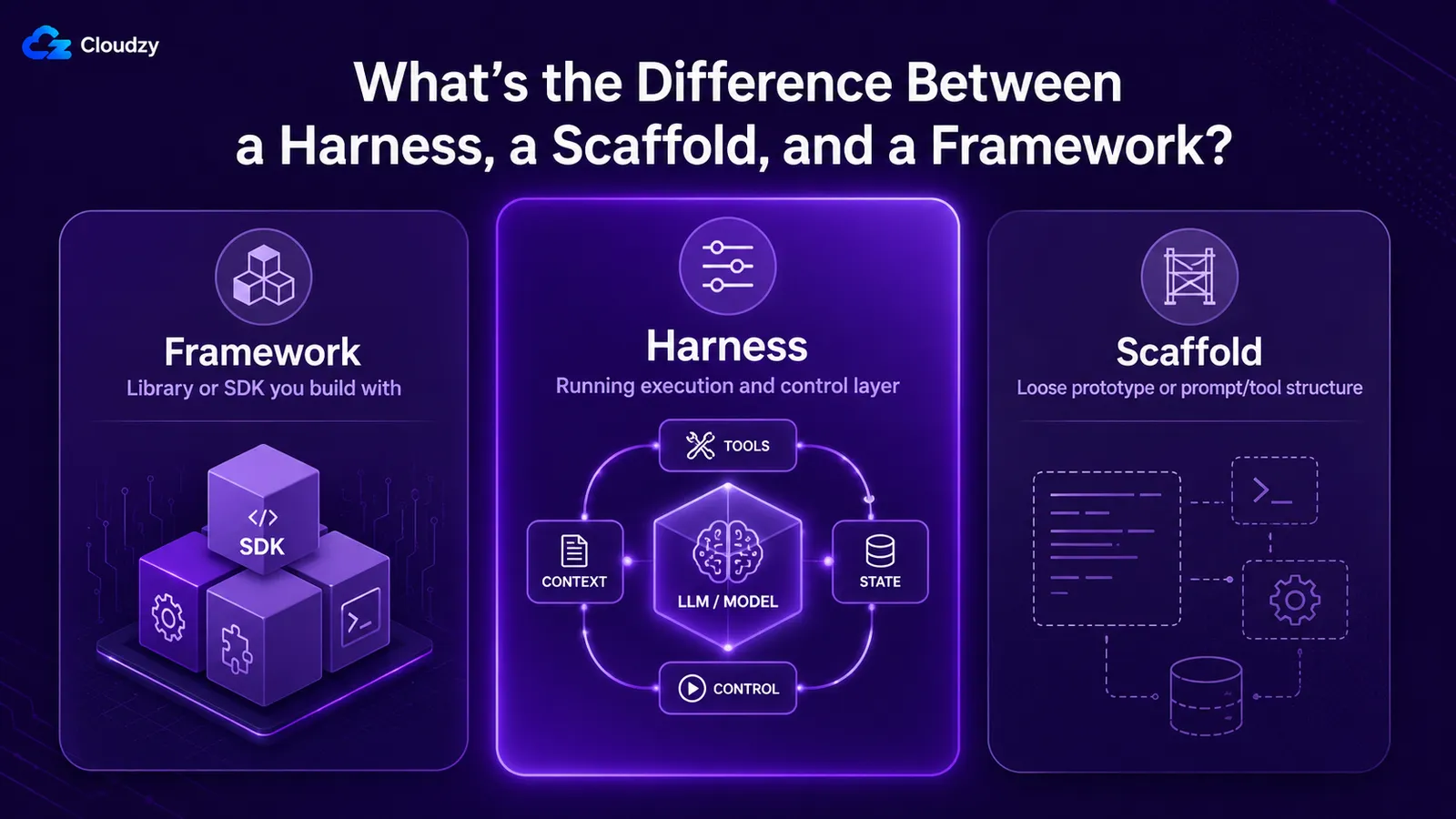
Te trzy są używane zamiennie, a nie powinny być. A framework to biblioteka lub SDK, za pomocą której budujesz, np. LangGraph lub agents SDK. A harness to działająca warstwa wykonania i zarządzania wokół modelu, którą framework pomaga ci złożyć. A scaffold jest najbardziej ogólnym z trzech: czasem prawie synonimem harness, czasem jego wersją prototypową, a czasem konkretnie warstwą promptu i opisu narzędzi.
Terminologia jest naprawdę nieuregulowana, a najlepszym podejściem jest mapowanie użyć zamiast narzucania jednego. Słownik HuggingFace Słownik agentów mówi o tym wprost:
"Wiele z tych terminów nie ma jeszcze powszechnie przyjętych definicji, a różne frameworki używają tego samego słowa w różny sposób."
— HuggingFace, Słownik agentów
| Termin | Co oznacza | Relacja |
|---|---|---|
| Framework | Biblioteka lub SDK, z którą budujesz (LangGraph, SDK agentów) | Narzędzie do składania harness |
| Harness | Działająca warstwa wokół modelu: pętla, narzędzia, kontekst, stan, guardrails | To, co wdrażasz i uruchamiasz |
| Scaffold | Używany luźno: quasi-synonim harness, lub wersja na poziomie prototypu / warstwy promptów | Pokrywa się z harness; mniej precyzyjne |
| Pętla | Cykl wykonania wewnątrz harness | Składnik harness |
Praktyczny wniosek do rozumowania o własnym systemie: gdy ktoś mówi "framework", zapytaj, czy ma na myśli bibliotekę, czy działającą rzecz. Gdy ktoś mówi "scaffold", zapytaj, czy ma na myśli cały harness, czy tylko warstwę prompt-i-narzędzi. Wartością jest tu disambiguacja, a nie roszczenie do ostatniego słowa.
Jak LangGraph implementuje wzorzec harness?
LangGraph to popularna implementacja wzorca harness w Pythonie jako open source. Modeluje wykonanie agenta jako skierowany graf węzłów i krawędzi, z typowanym stanem przepływającym między nimi i każdym przejściem, które można zapisać jako checkpoint. Jeśli abstrakcyjne komponenty powyżej wydają się nieuchwytne, LangGraph to miejsce, gdzie można zobaczyć, jak nabierają konkretnego kształtu w prawdziwym narzędziu.
Mapowanie jest bliskie jeden do jednego. Węzły i krawędzie to pętla wykonania: każdy węzeł wykonuje pracę, każda krawędź decyduje, gdzie idzie kontrola dalej. Typowany obiekt stanu przekazywany między węzłami to komponent context-and-state uczyniony jawnym. Checkpointing (LangGraph przechowuje stan przez savers jak jego implementacja oparta na Postgres) jest komponentem trwałości stanu. Konfigurowalny limit kroków to guardrail warunku zatrzymania, zapobiegający nieskończonemu pętleniu źle zachowującego się agenta. Te same komponenty, nazwane i połączone przez konkretną bibliotekę.
Jeśli chcesz uruchomić agenta LangGraph na własnym serwerze przez całą dobę, to jest pytanie o deployment, a nie konceptualne. Zobacz nasz przewodnik Linux VPS dla tej ścieżki. Tutaj LangGraph to tylko przepracowany przykład: dowód, że "pętla wykonania", "trwałość stanu" i "guardrail" nie są abstrakcjami, to rzeczy, na które możesz wskazać w prawdziwym kodzie.
Często zadawane pytania
Czym jest Agent Harness?
Agent harness to oprogramowanie wokół modelu językowego, które przekształca go w agenta. Zarządza pętlą wykonania, dostępem do narzędzi, pamięcią, kontekstem, trwałością stanu, obsługą błędów i guardrailami. Model generuje tekst; harness decyduje, co model widzi, co może robić, kiedy zatrzymać i co się dzieje, gdy coś zawiedzie.
Czy agent harness to to samo co agent framework?
Nie. Framework to biblioteka lub SDK, z którego budujesz, jak LangGraph lub agents SDK. Harness to działająca warstwa wykonania i zarządzania wokół modelu (pętla, narzędzia, kontekst, stan i zabezpieczenia), którą framework pomaga ci złożyć. Używasz frameworka do zbudowania harnessu.
Jakie komponenty ma każdy agent harness?
Większość harnessów dzieli wspólne jądro: pętlę wykonania, dostęp do narzędzi, pamięć, zarządzanie kontekstem, trwałość stanu, obsługę błędów i zabezpieczenia. Harnessy produkcyjne dodają pętle weryfikacyjne i orkiestrację subagentów. Prototypy mogą pominąć części tylko produkcyjne, ale pętla, narzędzia, obsługa kontekstu i obsługa błędów pojawiają się niemal wszędzie.
Co oznacza „LLM jest najmniejszą częścią twojego systemu agentów"?
Oznacza to, że większość zachowania i niezawodności agenta pochodzi z harnessu, a nie z modelu. Niezawodność end-to-end jest iloczynem wskaźnika sukcesu każdego kroku, a większość kroków to praca harnessu. MongoDB, powołując się na studium przypadku Vercel, raportuje skok wskaźnika sukcesu wynikający wyłącznie ze zmian harnessu, na tym samym modelu. To dowód, że naprawianie harnessu przewyższa naprawianie modelu.
Gdzie mieszka jakość twojego agenta
Harness to miejsce, gdzie żyje większość jakości agenta, i masz teraz słownictwo do lokalizowania problemów we własnym systemie. Możesz zdefiniować harness, nazwać jego komponenty, odróżnić go od frameworka i scaffoldu, oraz zastanowić się, czy dany błąd to problem modelu czy problem harnessu.
Więc następnym razem, gdy twój agent zachowuje się źle, najpierw przeprowadź audyt warstwy harnessu: kontekstu, który mu podajesz, narzędzi, które udostępniłeś, warunków zatrzymania, które ustawiłeś, sposobu, w jaki odzyskuje sprawność po nieudanym kroku. Sięgnij po większy model dopiero po sprawdzeniu tej warstwy. Przez większość czasu nie będzie to konieczne.


