Программы мониторинга GPU превращают расплывчатое «что-то не так с моим GPU» в конкретную картину: «температура в горячей точке выросла, частоты упали, VRAM заполнена».
В этом руководстве я разберу инструменты для задач AI, игровых оверлеев и длительных сессий на рабочей станции, а также покажу, какие метрики GPU помогают диагностировать просадки производительности, фризы и вылеты.
По итогу у вас будет настроенный стек мониторинга GPU, который подойдёт именно под ваш рабочий процесс. Плюс — готовые конфигурации для четырёх распространённых сценариев, чтобы больше не искать инструкции заново.
Быстрый ответ: лучшие программы мониторинга GPU по сценариям использования
Если нужен короткий список под реальные задачи — начните с этого. На практике лучший стек мониторинга GPU обычно состоит из нескольких инструментов: один для быстрых проверок, один для оверлеев или логов, один для истории или алертов.
Краткая схема:
| Сценарий использования | Рекомендуемый стек | Что вы получаете |
| Обучение AI, инференс, HPC-задачи | nvidia-smi (NVIDIA) или AMD SMI (AMD) + логирование/экспортёр | Быстрые проверки, скриптуемые логи, удобные алерты |
| Игры на Windows | MSI Afterburner + RTSS + инструмент захвата frametime | Оверлей и наглядное сравнение фризов и просадок FPS |
| Игры на Linux | MangoHud + терминальный мониторинг (nvtop) | Лёгкий оверлей и проверки работоспособности для каждого процесса |
| Рабочие станции (3D/видео/САПР) | Логирование через HWiNFO и базовый стресс-тест | Подробные логи, которыми можно поделиться, и воспроизводимые сценарии |
| Общие машины GPU | nvtop (Linux) + экспортер/дашборд | Мониторинг VRAM на уровне процессов |
Дальше главная задача - подобрать программу мониторинга GPU под то, как вы работаете с данными: на экране, в логах или в дашборде.
Для кого это руководство
Я пишу это так, как пишет человек, которому приходилось отлаживать реальные машины. Потому что на практике я знаю: разным читателям нужны разные инструменты мониторинга GPU - даже если они смотрят на одну и ту же GPU.
Вот четыре сценария, на которые я ориентируюсь:
- Обучение моделей (AI/ML): важен запас VRAM, устойчивые частоты, троттлинг и ответ на вопрос «задача отработала всю ночь без сбоев?»
- Киберспортсмен/стример: важны фреймтаймы, стабильность оверлея и обнаружение регрессий после обновления драйверов.
- Пользователь рабочей станции (3D/видео/САПР): важны логи, воспроизводимые сбои и точное определение причины: перегрев, питание или поведение драйвера.
- Администратор парка машин GPU: важны оповещения, графики трендов, планирование ёмкости и раннее выявление отказов.
Как только вы понимаете, к какой категории относитесь, выбрать подходящую программу мониторинга GPU становится просто.
Как выбрать программу мониторинга GPU
Многие приложения для мониторинга производительности выглядят похоже - до тех пор, пока не начинаешь пользоваться ими каждый день. Главное различие обычно в выводе данных и надёжности, а не в тех «фичах», которые каждый из них активно продвигает.
Вот три вопроса, которые помогут быстро выбрать программу мониторинга GPU:
- Вам нужен оверлей, логи или и то и другое?
Геймерам нужен оверлей. Для AI и работы на рабочей станции обычно нужно логирование. Администраторам - логи плюс оповещения. - Нужна ли вам статистика по отдельным процессам?
Если вы работаете на общем сервере (лаборатория, студия, удалённый сервер), первое, что обычно ищут — это VRAM по каждому процессу. - Нужны ли вам история и оповещения?
Если задачи выполняются ночью, «проверю потом» — не вариант. Нужны график и оповещение.
Чтобы руководство было практичным, дальше всё организовано по метрикам GPU, а затем — по наборам инструментов для каждого сценария.
Метрики GPU, на которые стоит обратить внимание
Good программы мониторинга GPU выдают много цифр. По-настоящему полезные — дают тот конкретный набор, который объясняет поведение системы. Я группирую метрики GPU по тому, какое решение они помогают принять.
Температура и троттлинг
Эти метрики GPU объясняют ситуацию «первые 10 минут всё летело, потом резко просело»:
- Температура GPU
- Температура горячей точки (часто первой начинает расти)
- Температура памяти / junction (важнее всего при долгих AI-задачах и длинных рендерах)
- Скорость вентиляторов (помогает выявить ноутбучные профили или кривые кривые вентилятора)
Если хотите повысить стабильность — логируйте эти метрики: одиночные снимки почти никогда не дают достаточно информации.
Питание, частоты и лимиты
Эти метрики GPU объясняют даунклокинг и нестабильную производительность:
- Потребляемая мощность платы
- Тактовая частота ядра и частота памяти
- Лимит мощности / состояние производительности (если это показывает ваш инструмент)
На практике питание и частоты дают куда более ясную картину, чем простой «% нагрузки на GPU».
VRAM и нехватка памяти
Эти метрики GPU объясняют фризы, ошибки OOM и типичные «случайные» просадки производительности:
- Использованный VRAM vs общий
- Активность контроллера памяти (помогает выявить ограничения пропускной способности)
- Давление системной RAM (потому что переполнение VRAM может тормозить всю систему)
Для AI VRAM — это зачастую жёсткий потолок. В играх давление VRAM обычно сначала проявляется в виде скачков frametime.
Метрики Frametime и Frame Pacing
Для игр и стриминга одних FPS недостаточно. Нужный показатель — frametime: именно он отражает плавность картинки или её отсутствие:
- Время кадра (мс)
- 1% низкое / 0.1% низкое (удобно для сравнений)
- GPU занят vs CPU занят (помогает разделить узкие места GPU и CPU)
Именно поэтому игровые приложения для мониторинга производительности часто включают захват frametime. Разобравшись с базовыми метриками, перейдём к лучшим стекам ПО для мониторинга GPU под каждый сценарий.
ПО для мониторинга GPU в AI, обучении моделей и на серверах

Мониторинг AI требует минимальной настройки: быстрые проверки в терминале плюс логи и алерты для долгих задач. Здесь нужно ПО для мониторинга GPU, которое работает через CLI и умеет экспортировать метрики.
NVIDIA: nvidia-smi для быстрых проверок и скриптуемых логов
На системах NVIDIA nvidia-smi обычно запускают первым делом — он поставляется вместе с драйвером и создан для мониторинга и управления через NVML.
Официальная документация: Интерфейс управления системой NVIDIA (nvidia-smi).
Если нужен простой подход «запиши и разберись потом» (и вы удивитесь, как часто это решает проблему), вот надёжный шаблон:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Это стандартное поведение программ мониторинга GPU: временные метки, основные показатели GPU и вывод, удобный для скриптов.
AMD: AMD SMI для ROCm и HPC-узлов
На вычислительных узлах AMD Linux интерфейс AMD SMI является основным инструментом мониторинга и управления. AMD позиционирует его как единый набор инструментов для мониторинга и управления в HPC-среде.
Официальная документация: Документация AMD SMI.
Если ваша инфраструктура построена на AMD, AMD SMI — это основа мониторинга GPU, на которой строится большинство других инструментов.
Видимость на уровне процессов: nvtop для общих GPU
Если у вас когда-либо была общая машина, где VRAM «таинственно» оставалась забитой, видимость на уровне процессов экономит время. На Linux nvtop популярен именно по этой причине: он сразу показывает, кто занимает VRAM. На AMD/Intel для статистики по процессам может потребоваться свежее ядро.
В смешанных командах я часто вижу, как запускают nvtop рядом с nvidia-smi или AMD SMI. Простое сочетание, которое убирает много неопределённости, поэтому я настоятельно его рекомендую.
Не забывайте о выборе железа!
Мониторинг не устраняет ограничение по VRAM — он лишь делает его видимым. Если вы ещё подбираете рабочие нагрузки под уровни GPU, наш гид по Лучшие GPU для машинного обучения в 2025 году будет хорошим дополнением: он рассматривает VRAM и пропускную способность именно так, как вы впоследствии увидите их в логах и дашбордах.
Когда серверный мониторинг GPU настроен, следующий шаг — оверлеи и фреймтаймы, так как интерактивные нагрузки ведут себя иначе.
Программы мониторинга GPU для игр и стриминга

В играх у всех особенно твёрдые мнения насчёт инструментов для GPU — в основном потому, что оверлеи перестают работать в самый неподходящий момент. Для игр нужны простые оверлеи и воспроизводимые замеры фреймтаймов.
MSI Afterburner + RTSS для оверлеев на Windows
Это сочетание популярно потому, что позволяет собрать чистый оверлей именно с теми показателями GPU, которые вам важны: загрузка, частоты, VRAM, температура, фреймтаймы и, при желании, скорость вентиляторов.
В обсуждениях на форумах постоянно звучит одно серьёзное предупреждение: фейковые сайты с загрузками. На официальной странице MSI Afterburner прямо указано, что легитимные загрузки следует искать на msi.com и Guru3D, а также приведена актуальная версия релиза (4.6.6 final, выпущена в октябре 2025 года).
Ещё одна проблема — сбои оверлея. Например, RTSS работает в одних играх и не работает в других, особенно с современными путями рендеринга. Пользователи сообщают о случаях, когда оверлей отображается в Vulkan, но не в DX12 для одной и той же игры, или пропадает после обновлений.
Это не ваша ошибка — так бывает, когда оверлеи цепляются за постоянно меняющийся стек игры и драйверов.
Если нужен стабильный базовый оверлей, ограничьтесь минимумом:
- время кадра
- использование GPU
- использовано VRAM
- Температура GPU
Добавляйте мощность и тактовые частоты только при активной отладке троттлинга.
Захват frametime для анализа «подвисаний»
Здесь на помощь приходят приложения для мониторинга производительности с функцией захвата графиков frametime. Средний FPS может выглядеть нормально, тогда как frame pacing ощущается ужасно. Графики frametime быстро расставляют всё по местам.
Многие бенчмарк-решения для игр используют PresentMon под капотом, и документация NVIDIA подтверждает, что аналитика FrameView использует PresentMon для захвата частоты кадров и frametime.
Не нужно бенчмаркать каждую игру. Захват frametime наиболее полезен для сравнений: до и после обновления драйвера, до и после смены ограничителя, до и после изменения настроек — и так далее.
MangoHud для оверлеев Linux
На Linux MangoHud рекомендуют чаще всего: он легковесный и хорошо интегрируется с Steam/Proton. Основные жалобы касаются отсутствующих датчиков или некорректных показаний на гибридных ноутбуках.
На практике MangoHud легко сочетать с терминальным инструментом вроде nvtop. Это также хороший пример того, почему программы мониторинга GPU работают заметно лучше как небольшой набор инструментов, а не одно громоздкое приложение.
От игрового мониторинга логичный следующий шаг — мониторинг рабочих станций, где на первый план выходят логи и воспроизводимая диагностика.
Размещайте игровые серверы без лагов на скоростном NVMe VPS-хостинге.
VPS для игр
Программы мониторинга GPU для рабочих станций и профессиональных приложений
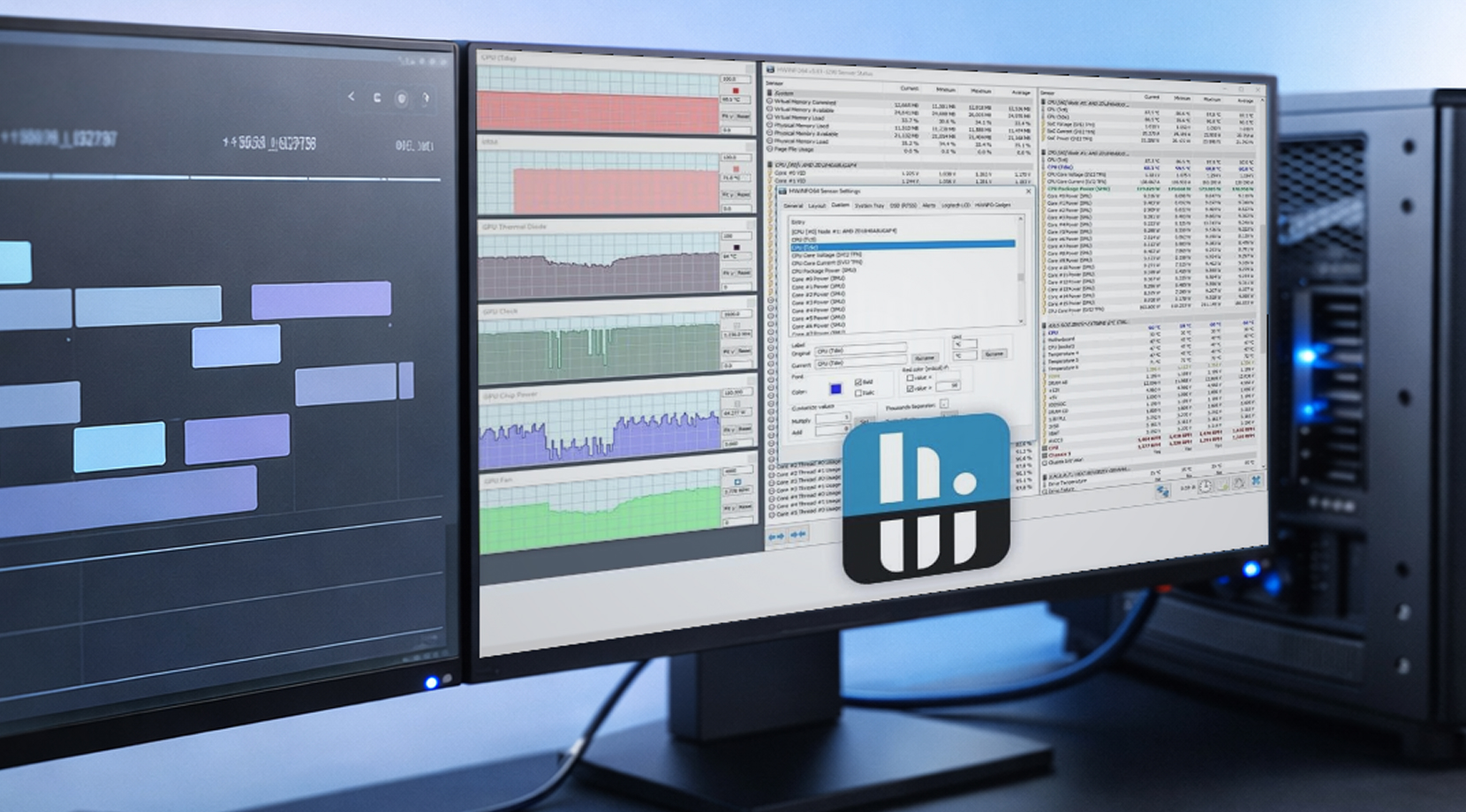
Мониторинг рабочей станции — это не наблюдение за живым оверлеем в режиме охранника. Главный вопрос здесь: «Что происходило с течением времени и можно ли это воспроизвести?»
HWiNFO для логирования на Windows
HWiNFO популярен среди пользователей рабочих станций благодаря широкому охвату датчиков и удобному логированию. Простой CSV-лог с временными метками легко превращает размытый отчёт в конкретную основу для устранения проблем.
Если вы формируете лог рабочей станции для отслеживания стабильности GPU, начните с этих метрик GPU:
- температура и хотспот GPU
- использовано VRAM
- мощность платы
- частота ядра
- мощность пакета CPU (лимиты мощности платформы могут неприятно удивить)
Это набор данных, которого достаточно, чтобы разобраться в ситуации. Логировать каждый сенсор не имеет смысла: файл становится сложнее читать.
GPU-Z для быстрой проверки «что это за GPU?»
GPU-Z по-прежнему полезен, потому что работает быстро и по делу. В командах с разным железом это самый быстрый способ узнать модель GPU, базовую информацию о драйвере и текущие показания сенсоров — без лишних переходов по меню.
Стресс-тесты: полезны только вместе с логированием
Стресс-тест может помочь воспроизвести сбой, но только если ПО для мониторинга GPU пишет логи во время его выполнения. Без логов у вас останется лишь «снова упало» и никакой временной шкалы.
На этом этапе большинство сталкивается с одними и теми же проблемами: оверлей не отображается, показания мощности выглядят неверными, логи становятся нечитаемыми. Разберём каждую из них напрямую.
Распространённые проблемы с программами мониторинга GPU и их быстрые решения

Большинство проблем укладываются в несколько шаблонов. Я начинаю именно с этих решений, потому что они быстро разбираются с типовыми случаями.
Оверлей не отображается в игре
Если оверлей пропадает в современной игре, чаще всего причина — проблема с хуком для конкретной игры или конфликт с античитом или защитой от модификаций.
Что обычно помогает:
- Обновите RTSS и сбросьте профиль для этой игры
- Установите более высокий уровень «обнаружения приложения» в профиле игры
- Попробуйте другой API, если игра его поддерживает
- Переключитесь на встроенный оверлей, если игра блокирует сторонние
Не каждая игра будет сотрудничать, и тратить часы на один упрямый тайтл не стоит.
Странные показания мощности (0W, прямая линия, отсутствующие сенсоры)
Это часто встречается на ноутбуках и гибридных конфигурациях, где активный GPU может меняться. В таких случаях перепроверьте данные вторым инструментом — например, nvidia-smi (NVIDIA) или AMD SMI (AMD): они хорошо подходят для проверки «а GPU вообще активен?».
Логи слишком зашумлены
Обычная причина — слишком высокая частота опроса. Для большинства задач диагностики достаточно интервала 1-5 секунд. Для долгих AI-задач хватит 5 секунд. Более короткие интервалы раздувают размер файла и делают графики нечитаемыми.
После того как базовые задачи решены, следующий логичный шаг — удалённый мониторинг, потому что многие рабочие процессы GPU теперь выполняются вне локальной машины.
Удалённый мониторинг GPU и практические облачные варианты
Удалённая работа меняет само понятие «хорошего ПО для мониторинга GPU». Вы не всегда находитесь рядом с машиной, поэтому нужны проверки, которые можно запустить быстро, и история, которую можно изучить позже.
Чистая схема удалённого мониторинга обычно выглядит так:
- CLI-проверки (nvidia-smi или AMD SMI)
- лог-файл, который можно скачать позже
- экспортёр и дашборд — если нужны оповещения
Если локальное железо тормозит вашу работу (ограничения VRAM, совместное использование одного GPU, необходимость изолированного окружения под каждый проект), запуск задач на GPU VPS — часто самый простой способ продолжить работу.
Cloudzy GPU VPS

Если вам нужен удалённый доступ к GPU для задач AI, гейминга и рендеринга, наш Cloudzy GPU VPS включает варианты NVIDIA: RTX 5090, A100 и RTX 4090, а также хранилище NVMe, полный root-доступ, соединения до 40 Gbps, защиту DDoS и заявленный аптайм 99,95%.
С точки зрения мониторинга он ведёт себя как обычная машина: вы можете запускать ПО для мониторинга GPU через SSH, логировать метрики GPU для долгих задач и добавлять дашборды для хранения истории и настройки оповещений.
Если вы ещё выбираете между инстансом GPU и конфигурацией только с CPU, наши материалы Что такое GPU VPS? и GPU и CPU VPS подробно разбирают практические различия в зависимости от типа нагрузки.
Разобравшись с удалённым мониторингом, последний шаг — собрать всё вместе в готовые к копированию стеки.
Готовые стеки для разных сценариев
Ниже — простые стеки, которые можно взять и использовать без переработки всего рабочего процесса. Это хорошие отправные точки, которые вы затем сможете адаптировать под свои задачи.
- Разработчик моделей (AI/ML): ПО для мониторинга GPU через nvidia-smi или AMD SMI, простой лог в CSV, плюс экспортёр и дашборд — если задачи выполняются без участия оператора.
- Соревновательный геймер / стример: оверлей для мониторинга GPU через Afterburner + RTSS, инструмент захвата frametime для сравнений, минимальный набор метрик на экране.
- Пользователь рабочей станции: мониторинг GPU через логирование в HWiNFO, GPU-Z для быстрой проверки конфигурации, стресс-тест — только когда есть возможность сохранить лог прогона.
- Администрирование машин GPU: ПО мониторинга GPU как сервис: экспортер + дашборды + алерты, а также видимость на уровне процессов (nvtop) для общих серверов.
Если вы вынесете из этого руководства только одно — пусть это будет следующее: выбирайте ПО мониторинга GPU исходя из того, где вам нужны данные (оверлей, лог, дашборд), и держите набор метрик достаточно компактным, чтобы вы действительно им пользовались.