
หนึ่งในแง่มุมที่สำคัญที่สุดของ Machine Learning คือการสร้างการพยากรณ์ที่แม่นยำและเชื่อถือได้ แนวทางหนึ่งที่ได้รับความสนใจอย่างกว้างขวางในการบรรลุเป้าหมายนี้คือ Bootstrap Aggregating หรือที่รู้จักกันทั่วไปในชื่อ Bagging ในวงการ Machine Learning บทความนี้จะอธิบายว่า Bagging ใน Machine Learning คืออะไร เปรียบเทียบ Bagging และ Boosting ใน Machine Learning ยกตัวอย่าง Bagging Classifier อธิบายหลักการทำงานของ Bagging และสำรวจข้อดีและข้อจำกัดของ Bagging ใน Machine Learning
Bagging ใน Machine Learning คืออะไร?
รูปภาพสองรูปนี้เป็นรูปที่ใช้ในบทความยอดนิยม สามารถใช้หนึ่งหรือทั้งสองรูปได้ (รูปหนึ่งตรงนี้ อีกรูปในตำแหน่งอื่น) หาก Design ทำเวอร์ชัน Cloudzy ขึ้นมา
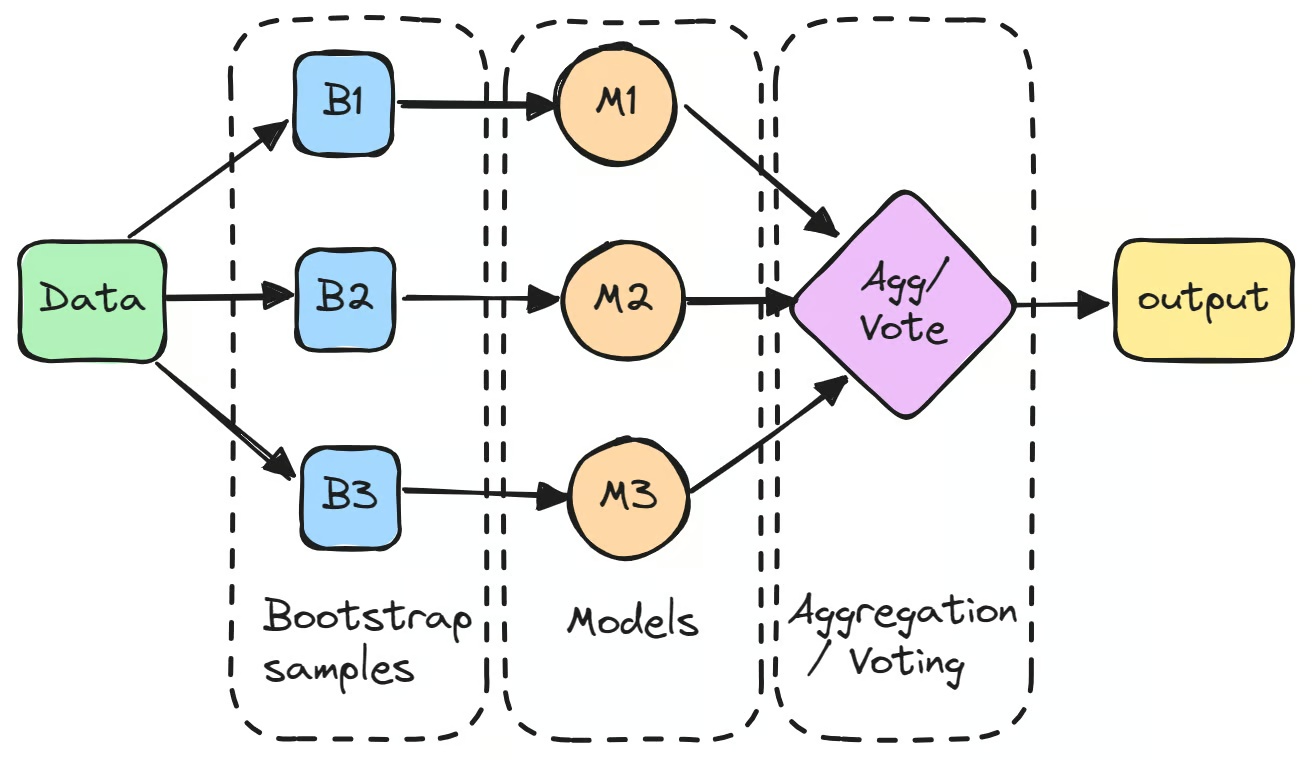
Bagging คืออะไร
ลองนึกภาพว่าคุณกำลังพยายามเดาน้ำหนักของวัตถุชิ้นหนึ่งโดยถามหลายคนให้ช่วยประมาณ แต่ละคนอาจได้คำตอบที่แตกต่างกัน แต่เมื่อนำค่าเฉลี่ยของทุกคำตอบมาใช้ ผลที่ได้จะแม่นยำกว่ามาก นี่คือแก่นของ Bagging นั่นคือการรวมผลลัพธ์จากหลายโมเดลเพื่อให้ได้การพยากรณ์ที่แม่นยำและน่าเชื่อถือยิ่งขึ้น
กระบวนการเริ่มต้นด้วยการสร้างชุดข้อมูลย่อยหลายชุดจากชุดข้อมูลต้นฉบับผ่าน Bootstrapping ซึ่งเป็นการสุ่มตัวอย่างแบบมีการทดแทน จากนั้นแต่ละชุดข้อมูลจะถูกนำไปฝึกโมเดลแยกกันอย่างอิสระ
โมเดลแต่ละตัวเหล่านี้มักเรียกว่า Weak Learner และอาจทำงานได้ไม่ดีนักเมื่อใช้เพียงตัวเดียวเนื่องจาก Variance สูง อย่างไรก็ตาม เมื่อนำผลการพยากรณ์มารวมกัน โดยทั่วไปใช้การเฉลี่ยสำหรับงาน Regression หรือการโหวตเสียงข้างมากสำหรับงาน Classification ผลลัพธ์รวมมักจะดีกว่าโมเดลตัวใดตัวหนึ่งอย่างชัดเจน
ตัวอย่าง Bagging Classifier ที่รู้จักกันดีคืออัลกอริทึม Random Forest ซึ่งสร้าง Ensemble ของ Decision Tree เพื่อเพิ่มประสิทธิภาพการพยากรณ์ แต่ควรระวังไม่ให้สับสนระหว่าง Bagging กับ Boosting ใน Machine Learning เพราะ Boosting ฝึกโมเดลแบบต่อเนื่องเพื่อลด Bias ในขณะที่ Bagging ฝึกโมเดลแบบขนานเพื่อลด Variance
ทั้ง Bagging และ Boosting ใน Machine Learning มีเป้าหมายเพื่อเพิ่มประสิทธิภาพของโมเดล แต่แต่ละวิธีจัดการกับปัญหาคนละด้านของพฤติกรรมโมเดล
ทำไม Bagging ถึงมีประโยชน์
ข้อได้เปรียบสำคัญของ Bagging ใน Machine Learning คือความสามารถในการลด Variance ช่วยให้โมเดล Generalize ข้อมูลที่ไม่เคยเห็นมาก่อนได้ดียิ่งขึ้น Bagging มีประโยชน์เป็นพิเศษกับอัลกอริทึมที่ไวต่อการเปลี่ยนแปลงในข้อมูลฝึก เช่น Decision Tree
การป้องกัน Overfitting ทำให้โมเดลมีความเสถียรและน่าเชื่อถือมากขึ้น เมื่อเปรียบเทียบ Bagging กับ Boosting ใน Machine Learning จะเห็นว่า Bagging มุ่งลด Variance ด้วยการฝึกโมเดลหลายตัวแบบขนาน ในขณะที่ Boosting มุ่งลด Bias ด้วยการฝึกโมเดลแบบต่อเนื่อง
ตัวอย่างการใช้ Bagging ใน Machine Learning ในชีวิตจริงคือการพยากรณ์ความเสี่ยงทางการเงิน โดยฝึก Decision Tree หลายตัวบนชุดข้อมูลตลาดย้อนหลังที่แตกต่างกัน การรวมผลการพยากรณ์ทำให้ Bagging สร้างโมเดลพยากรณ์ที่แม่นยำขึ้น และลดผลกระทบจากข้อผิดพลาดของโมเดลแต่ละตัว
โดยสรุป Bagging ใน Machine Learning อาศัยความฉลาดร่วมกันของหลายโมเดลเพื่อให้ได้การพยากรณ์ที่แม่นยำและน่าเชื่อถือกว่าการใช้โมเดลตัวเดียว
หลักการทำงานของ Bagging ใน Machine Learning แบบทีละขั้นตอน
เพื่อให้เข้าใจอย่างถ่องแท้ว่า Bagging ช่วยเพิ่มประสิทธิภาพของโมเดลได้อย่างไร มาดูกระบวนการทีละขั้นตอนกัน
การสุ่มตัวอย่างข้อมูลหลายชุดจาก Dataset
ขั้นตอนแรกของ bagging ใน machine learning คือการสร้าง subset ของ dataset ต้นฉบับหลายชุดด้วยวิธี bootstrapping เทคนิคนี้สุ่มเลือกข้อมูลแบบมีการคืนค่า ทำให้บางจุดข้อมูลอาจปรากฏซ้ำในชุดเดียวกัน ขณะที่บางจุดอาจไม่ถูกเลือกเลย กระบวนการนี้ช่วยให้แต่ละโมเดลได้รับการฝึกบนข้อมูลที่แตกต่างกันเล็กน้อย
ฝึกโมเดลแยกกันบนแต่ละตัวอย่าง
แต่ละ bootstrap sample จะถูกนำไปฝึกโมเดลแยกกัน ซึ่งมักเป็นโมเดลประเภทเดียวกัน เช่น decision tree โมเดลเหล่านี้มักเรียกว่า "base learners" หรือ "weak learners" และฝึกอย่างอิสระบน subset ของตัวเอง ตัวอย่าง bagging classifier ที่เห็นได้ชัดคือ decision tree ใน Random Forest ซึ่งเป็นรากฐานของโมเดลแบบ bagging หลายตัว แม้โมเดลแต่ละตัวอาจให้ผลไม่ดีนักเมื่อทำงานเดี่ยว แต่ทุกตัวมีส่วนเพิ่มมุมมองที่แตกต่างกันตามข้อมูลที่ใช้ฝึก
การรวมผลการพยากรณ์
เมื่อฝึกโมเดลทั้งหมดแล้ว ผลการพยากรณ์จะถูกรวมกันเพื่อสร้าง output สุดท้าย
- สำหรับงาน regression ผลการพยากรณ์จะถูกเฉลี่ย ซึ่งช่วยลด variance ของโมเดล
- สำหรับงาน classification ผลการพยากรณ์สุดท้ายถูกตัดสินด้วยการโหวตเสียงข้างมาก โดยเลือก class ที่โมเดลส่วนใหญ่ทำนาย วิธีนี้ให้ผลที่เสถียรกว่าการใช้โมเดลเดี่ยว
การทำนายขั้นสุดท้าย
การรวมผลการพยากรณ์จากหลายโมเดลช่วยลดผลกระทบจากข้อผิดพลาดของโมเดลใดโมเดลหนึ่ง และเพิ่มความแม่นยำโดยรวม กระบวนการรวมผลนี้คือสิ่งที่ทำให้ bagging มีประสิทธิภาพสูง โดยเฉพาะในงาน machine learning ที่ใช้โมเดล high-variance อย่าง decision tree ช่วยปรับให้ความไม่สม่ำเสมอของโมเดลแต่ละตัวหมดไป และได้โมเดลสุดท้ายที่แข็งแกร่งขึ้น
แม้ bagging จะช่วยทำให้การพยากรณ์มีความเสถียร แต่มีบางเรื่องที่ต้องคำนึงถึง เช่น ความเสี่ยงของ overfitting หากโมเดลพื้นฐานซับซ้อนเกินไป แม้ว่า bagging จะออกแบบมาเพื่อลดปัญหานี้โดยทั่วไป
นอกจากนี้ยังใช้ทรัพยากรการประมวลผลสูง ดังนั้นการปรับจำนวน base learner หรือพิจารณาใช้ ensemble method ที่มีประสิทธิภาพมากกว่าอาจช่วยได้ และ การเลือก GPU ที่เหมาะสมสำหรับ ML และ DL มีความสำคัญเสมอ
ควรสร้างความหลากหลายของโมเดลในกลุ่ม base learner เพื่อผลลัพธ์ที่ดีขึ้น และหากทำงานกับข้อมูลที่ไม่สมดุล เทคนิคอย่าง SMOTE อาจเป็นประโยชน์ก่อนนำ bagging มาใช้ เพื่อหลีกเลี่ยงประสิทธิภาพที่ต่ำบน minority class
การประยุกต์ใช้ของ Bagging
ตอนนี้เราเข้าใจหลักการทำงานของ bagging แล้ว ถึงเวลาดูว่ามันถูกนำไปใช้จริงในโลกจริงอย่างไร bagging เข้าไปมีบทบาทในหลากหลายอุตสาหกรรม ช่วยเพิ่มความแม่นยำและความเสถียรของการพยากรณ์ในสถานการณ์ที่ซับซ้อน ลองดูแอปพลิเคชันที่มีผลกระทบสูงที่สุดบางส่วน:
- Classification และ Regression: bagging ถูกใช้อย่างแพร่หลายเพื่อเพิ่มประสิทธิภาพของ classifier และ regressor โดยลด variance และป้องกัน overfitting ตัวอย่างเช่น Random Forest ที่ใช้ bagging มีประสิทธิภาพสูงในงานอย่าง image classification และ predictive modeling
- การตรวจจับความผิดปกติ ในด้านการตรวจจับการฉ้อโกงและการตรวจจับการบุกรุกเครือข่าย อัลกอริทึม bagging ให้ผลที่โดดเด่นด้วยการ ระบุ outlier และความผิดปกติในข้อมูลได้อย่างแม่นยำ.
- การประเมินความเสี่ยงทางการเงิน: เทคนิค bagging ถูกนำมาใช้ในภาคธนาคารเพื่อพัฒนาโมเดล credit scoring ช่วยเพิ่มความแม่นยำในกระบวนการอนุมัติสินเชื่อและการประเมินความเสี่ยงทางการเงิน
- การวินิจฉัยทางการแพทย์ ในด้านสาธารณสุข bagging ถูกนำมาใช้ตรวจหาความผิดปกติทางการรับรู้ เช่น โรคอัลไซเมอร์ โดยการวิเคราะห์ชุดข้อมูล MRI ซึ่งช่วยในด้าน การวินิจฉัยโรคตั้งแต่เนิ่นๆ และการวางแผนการรักษา.
- การประมวลผลภาษาธรรมชาติ (NLP): bagging ช่วยเพิ่มประสิทธิภาพในงานอย่าง text classification และ sentiment analysis โดยรวมผลการพยากรณ์จากหลายโมเดล ทำให้เข้าใจภาษาได้แม่นยำยิ่งขึ้น
ข้อดีและข้อเสียของ Bagging
เช่นเดียวกับเทคนิค machine learning อื่นๆ bagging มีทั้งข้อดีและข้อจำกัดของตัวเอง การเข้าใจสิ่งเหล่านี้จะช่วยให้คุณตัดสินใจได้ว่าควรใช้ bagging กับโมเดลของคุณเมื่อไหร่และอย่างไร
ข้อดีของ Bagging:
- ลด Variance และป้องกัน Overfitting: หนึ่งในข้อดีที่สำคัญที่สุดของ bagging คือความสามารถในการลด variance ซึ่งช่วยป้องกัน overfitting ได้อย่างมีประสิทธิภาพ การฝึกโมเดลหลายตัวบนชุดข้อมูลย่อยที่แตกต่างกัน ทำให้โมเดลไม่ไวต่อความผันผวนในข้อมูล training มากเกินไป ผลลัพธ์ที่ได้คือโมเดลที่เสถียรและ generalize ได้ดีขึ้น
- ทำงานได้ดีกับโมเดลที่มี Variance สูง: bagging มีประสิทธิภาพเป็นพิเศษเมื่อใช้กับโมเดลที่มี variance สูง เช่น decision tree โมเดลเหล่านี้มักเกิด overfitting และมี variance สูง แต่ bagging แก้ปัญหานี้ได้ด้วยการเฉลี่ยหรือโหวตผลจากโมเดลหลายตัว ทำให้การทำนายแม่นยำและไม่ถูกรบกวนจาก noise ในข้อมูล
- เพิ่มความเสถียรและประสิทธิภาพของโมเดล: การรวมโมเดลหลายตัวที่ฝึกบนชุดข้อมูลย่อยที่ต่างกันมักนำไปสู่ประสิทธิภาพโดยรวมที่ดีขึ้น bagging ช่วยเพิ่มความแม่นยำในการทำนาย และลดความไวของโมเดลต่อการเปลี่ยนแปลงเล็กน้อยในชุดข้อมูล ทำให้โมเดลเชื่อถือได้มากขึ้นในที่สุด
ข้อเสียของ Bagging:
- เพิ่มต้นทุนในการคำนวณ: เนื่องจาก bagging ต้องฝึกโมเดลหลายตัว จึงเพิ่มต้นทุนในการคำนวณตามไปด้วยอย่างหลีกเลี่ยงไม่ได้ การฝึกและรวมผลการทำนายจากโมเดลจำนวนมากอาจใช้เวลานาน โดยเฉพาะเมื่อใช้กับชุดข้อมูลขนาดใหญ่หรือโมเดลที่ซับซ้อน เช่น decision tree
- ไม่ได้ผลกับโมเดลที่มี Variance ต่ำ: แม้ bagging จะมีประสิทธิภาพสูงกับโมเดลที่มี variance สูง แต่ไม่ได้ให้ประโยชน์มากนักเมื่อใช้กับโมเดลที่มี variance ต่ำ เช่น linear regression ในกรณีเหล่านี้ แต่ละโมเดลมี error rate ต่ำอยู่แล้ว การรวมผลการทำนายจึงแทบไม่ช่วยปรับปรุงผลลัพธ์ได้
- การสูญเสียความสามารถในการตีความ การรวมโมเดลหลายตัวใน bagging อาจทำให้ตีความโมเดลสุดท้ายได้ยากขึ้น ตัวอย่างเช่น ใน Random Forest กระบวนการตัดสินใจอาศัย decision tree หลายต้น ซึ่งทำให้ติดตามเหตุผลเบื้องหลังการทำนายแต่ละครั้งได้ยากขึ้น
ควรใช้ Bagging เมื่อไหร่?
การรู้ว่าควรใช้ bagging ในสถานการณ์ใดเป็นสิ่งสำคัญสำหรับการได้ผลลัพธ์ที่ดีที่สุด เทคนิคนี้ทำงานได้ดีในบางสถานการณ์ แต่ก็ไม่ใช่ตัวเลือกที่เหมาะกับทุกปัญหาเสมอไป
เมื่อโมเดลของคุณมีแนวโน้มเกิด Overfitting
หนึ่งในกรณีการใช้งานหลักของ bagging คือเมื่อโมเดลของคุณมีแนวโน้มเกิด overfitting โดยเฉพาะกับโมเดลที่มี variance สูง เช่น decision tree โมเดลเหล่านี้อาจทำงานได้ดีบนข้อมูล training แต่มักล้มเหลวในการ generalize กับข้อมูลที่ไม่เคยเห็น เพราะโมเดลจำรูปแบบเฉพาะในชุดข้อมูล training มากเกินไป
bagging ช่วยแก้ปัญหานี้ด้วยการฝึกโมเดลหลายตัวบนชุดข้อมูลย่อยที่ต่างกัน แล้วเฉลี่ยหรือโหวตเพื่อสร้างการทำนายที่เสถียรกว่า ซึ่งช่วยลดโอกาสเกิด overfitting และทำให้โมเดลรับมือกับข้อมูลใหม่ที่ไม่เคยเห็นได้ดีขึ้น
เมื่อต้องการเพิ่มความเสถียรและความแม่นยำ
ถ้าคุณต้องการเพิ่มความเสถียรและความแม่นยำของโมเดลโดยไม่เสียสละการตีความมากนัก bagging เป็นตัวเลือกที่ดี การรวมผลการทำนายจากโมเดลหลายตัวทำให้ผลลัพธ์สุดท้ายน่าเชื่อถือมากขึ้น ซึ่งมีประโยชน์โดยเฉพาะกับงานที่ข้อมูลมี noise สูง
ไม่ว่าจะเป็นปัญหา classification หรืองาน regression bagging ช่วยให้ผลลัพธ์สม่ำเสมอขึ้น เพิ่มความแม่นยำในขณะที่ยังคงประสิทธิภาพการทำงานไว้
เมื่อคุณมีทรัพยากรการคำนวณเพียงพอ
อีกปัจจัยสำคัญในการตัดสินใจว่าจะใช้ bagging หรือไม่คือทรัพยากรการคำนวณที่มีอยู่ เนื่องจาก bagging ต้องฝึกโมเดลหลายตัวพร้อมกัน ต้นทุนในการคำนวณจึงอาจสูงขึ้นได้มาก โดยเฉพาะกับชุดข้อมูลขนาดใหญ่หรือโมเดลที่ซับซ้อน
ถ้าคุณมีพลังการประมวลผลเพียงพอ ประโยชน์ของ bagging คุ้มค่ากับต้นทุนอย่างแน่นอน แต่ถ้าทรัพยากรมีจำกัด อาจต้องพิจารณาเทคนิคอื่นหรือลดจำนวนโมเดลใน ensemble ของคุณ
เมื่อทำงานกับโมเดลที่มี Variance สูง
bagging มีประโยชน์เป็นพิเศษเมื่อทำงานกับโมเดลที่มี variance สูงและไวต่อความผันผวนในข้อมูล training ตัวอย่างเช่น decision tree มักถูกนำมาใช้กับ bagging ในรูปแบบของ Random Forest เพราะประสิทธิภาพของมันมักแปรปรวนอย่างมากตามข้อมูล training ที่ใช้
การฝึกโมเดลหลายตัวบนชุดข้อมูลย่อยที่แตกต่างกัน แล้วรวมผลลัพธ์เข้าด้วยกัน ช่วยให้ bagging ลดความแปรปรวน และได้โมเดลที่เชื่อถือได้มากขึ้น
เมื่อคุณต้องการ Classifier ที่มีความเสถียร
หากคุณทำงานกับปัญหาการจำแนกประเภทและต้องการ classifier ที่มีความเสถียร bagging สามารถเพิ่มความแม่นยำของการทำนายได้อย่างมีนัยสำคัญ ตัวอย่างเช่น Random Forest ซึ่งเป็นหนึ่งในตัวอย่างของ bagging classifier สามารถให้ผลการทำนายที่แม่นยำกว่าด้วยการรวมผลลัพธ์จาก decision tree หลายต้นเข้าด้วยกัน
วิธีนี้ได้ผลดีเมื่อโมเดลแต่ละตัวอาจมีประสิทธิภาพไม่สูงนัก แต่เมื่อนำมารวมกันแล้ว กลับได้โมเดลที่แข็งแกร่งโดยรวม
นอกจากนี้ หากคุณกำลังมองหาแพลตฟอร์มที่เหมาะสมสำหรับการนำเทคนิค bagging ไปใช้งานได้อย่างมีประสิทธิภาพ เครื่องมืออย่าง Databricks และ Snowflake มีแพลตฟอร์ม analytics แบบครบวงจรที่เป็นประโยชน์มากในการจัดการชุดข้อมูลขนาดใหญ่และรัน ensemble methods อย่าง bagging
หากคุณต้องการแนวทาง machine learning ที่ไม่ต้องเขียนโค้ดมาก เครื่องมือ AI แบบไม่ต้องเขียนโค้ด อาจเป็นตัวเลือกที่น่าสนใจ แม้ว่าแพลตฟอร์ม no-code เหล่านี้จะไม่ได้มุ่งเน้นเทคนิคขั้นสูงอย่าง bagging โดยตรง แต่ก็ช่วยให้คุณทดลองใช้งาน ensemble learning รวมถึง bagging ได้โดยไม่ต้องมีทักษะการเขียนโค้ดมากนัก
วิธีนี้ช่วยให้คุณนำเทคนิคที่ซับซ้อนขึ้นมาใช้ได้จริง และยังคงได้ผลการทำนายที่แม่นยำ โดยมุ่งความสนใจไปที่ประสิทธิภาพของโมเดลแทนที่จะต้องกังวลกับโค้ดเบื้องหลัง
บทสรุป
Bagging ใน machine learning เป็นเทคนิคที่มีประสิทธิภาพในการเพิ่มคุณภาพโมเดล ด้วยการลดความแปรปรวนและเพิ่มความเสถียร การรวมผลการทำนายจากโมเดลหลายตัวที่ฝึกบนชุดข้อมูลย่อยต่างกัน ช่วยให้ได้ผลลัพธ์ที่แม่นยำและเชื่อถือได้มากขึ้น เทคนิคนี้เหมาะอย่างยิ่งกับโมเดลที่มีความแปรปรวนสูงอย่าง decision tree ซึ่งช่วยป้องกัน overfitting และทำให้โมเดล generalize ได้ดีขึ้นกับข้อมูลที่ไม่เคยเห็นมาก่อน
แม้ bagging จะมีข้อดีที่ชัดเจน เช่น ลด overfitting และเพิ่มความแม่นยำ แต่ก็มีข้อแลกเปลี่ยนบางอย่างเช่นกัน ได้แก่ ต้นทุนการประมวลผลที่สูงขึ้นเพราะต้องฝึกหลายโมเดล และอาจทำให้การตีความผลยากขึ้น อย่างไรก็ตาม ความสามารถในการเพิ่มประสิทธิภาพโมเดลยังคงทำให้ bagging เป็นเทคนิคที่มีคุณค่าใน ensemble learning ควบคู่ไปกับวิธีอื่นๆ อย่าง boosting และ stacking
คุณเคยใช้ bagging ในโปรเจกต์ machine learning บ้างไหม? แชร์ประสบการณ์และบอกเล่าว่ามันได้ผลอย่างไรสำหรับคุณ!


