
เริ่มได้เร็ว จ่ายเฉพาะที่ใช้จริง และโยนงาน patch ให้คนอื่นดูแล ฟังดูน่าสนใจเสมอ แต่ความรู้สึกนั้นเริ่มจางหายเมื่อค่าเก็บข้อมูลพุ่งสูงโดยไม่คาดคิด หรือ policy ของ S3 ที่ตั้งผิดทำให้ bucket เปิดเผยต่อสาธารณะ จากประสบการณ์จริง ปัญหาหลักของ cloud computing มักผุดขึ้นซ้ำๆ ข้ามสถาปัตยกรรมและอุตสาหกรรม การจัดการกับมันตั้งแต่เนิ่นๆ ช่วยให้ทีมโฟกัสกับการ deploy ฟีเจอร์ แทนที่จะวิ่งแก้ปัญหาตลอดเวลา
ทำไมปัญหาเหล่านี้ถึง Go ไม่หายไปเสียที
ความล้มเหลวของ cloud แทบไม่เคยมาจาก bug ร้ายแรงเพียงจุดเดียว แต่มักสะสมจากช่องโหว่เล็กๆ ที่ทับซ้อนกันในสถาปัตยกรรม กระบวนการ และคน ก่อนเจาะลึกแต่ละหมวด ลองดูสัญญาณเตือนที่บ่งบอกว่ามีปัญหาลึกกว่าที่เห็น:
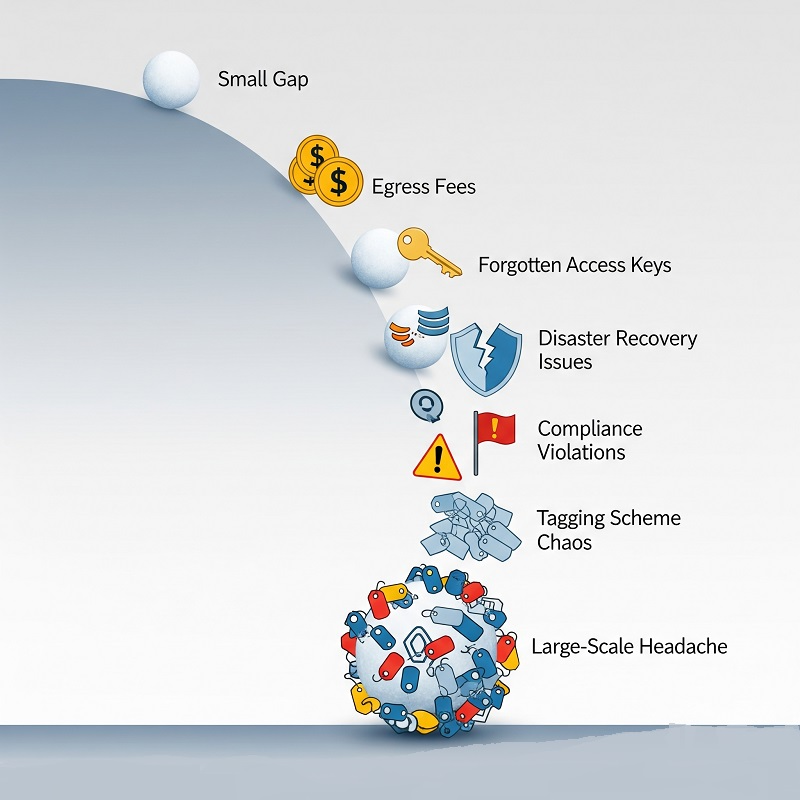
- ค่า egress ที่พุ่งขึ้นกะทันหันกินกำไรสองเดือนหายไปในพริบตา
- access key ที่ลืมลบถูกนำไปใช้ขุด crypto ข้ามคืน
- outage ระดับ region ทดสอบแผน disaster recovery ที่ไม่เคยซักซ้อมจริง
- การตรวจสอบ compliance เจอข้อมูลสำคัญที่ไม่ได้ติดป้ายกำกับจอดอยู่ใน object storage
- สิบทีมใช้สิบวิธีแท็กคนละแบบ ทำให้รายงาน charge-back อ่านแล้วงงเหมือนอ่านอักษรโบราณ
สัญญาณแต่ละอย่างล้วนสาวกลับไปหาความเสี่ยงหลักอย่างน้อยหนึ่งประเภท เก็บแผนที่นี้ไว้ใกล้มือ มันจะนำทางทุกขั้นตอนการรับมือในภายหลัง
ความเสี่ยงของ Cloud Computing
ผลการศึกษาในอุตสาหกรรมชี้ตรงกันว่ามีความเสี่ยงหลัก 7 ประเภทที่เป็นต้นเหตุของเหตุการณ์ส่วนใหญ่ในทุกภาคส่วน แม้แต่ละประเภทจะเกี่ยวพันกัน แต่รวมกันแล้วครอบคลุม ความท้าทายหลักของ cloud computing ที่ทีมต้องเผชิญทุกวัน ตั้งแต่ค่าใช้จ่ายบานปลายไปจนถึงการรั่วไหลของข้อมูล:
การตั้งค่าผิดพลาดและสิทธิ์ที่มากเกินไป
แม้แต่วิศวกรผู้เชี่ยวชาญก็ยังคลิกผิดในคอนโซลได้เป็นครั้งคราว security group ที่เปิดกว้างเกินไปหรือ storage bucket ที่เป็น public อาจเปลี่ยนเครื่องมือภายในให้กลายเป็นช่องโหว่บนอินเทอร์เน็ตได้ทันที
ข้อผิดพลาดที่พบบ่อย
- ไพ่ป่า 0.0.0.0/0 กฎบน admin port
- IAM role ที่ให้สิทธิ์เต็มรูปแบบทิ้งไว้นานหลัง migration เสร็จสิ้น
การรั่วไหลและการละเมิดข้อมูล
เมื่อการตั้งค่าผิดพลาด ประตูก็เปิด และข้อมูลก็รั่วไหล การรั่วไหลข้อมูล เป็นปัญหาซ้ำซากในการรักษาความปลอดภัยบนคลาวด์ และแทบไม่เคยเริ่มจากช่องโหว่ zero-day ที่ซับซ้อน แต่ไหลผ่าน endpoint ที่เปิดโล่งหรือ credential ที่ล้าสมัย
ภัยคุกคามจากภายในและ Shadow Admin
ไม่ใช่ทุกความเสี่ยงที่มาจากภายนอก พนักงานสัญญาจ้างที่ยังคงสิทธิ์เก่าไว้ หรือพนักงานที่เปิดบริการโดยไม่ได้รับอนุญาต ล้วนสร้างจุดบอดที่ระบบตรวจสอบทั่วไปมองไม่เห็น
API ที่ไม่ปลอดภัยและความเสี่ยงจาก Supply Chain
แอปพลิเคชัน cloud-native ทุกตัวพึ่งพา SDK และ API จากบุคคลที่สาม การขาด rate limit หรือไลบรารีที่ไม่ได้รับการแพตช์เปิดโอกาสให้ถูกโจมตี เปลี่ยนฟีเจอร์ธรรมดาให้กลายเป็นพื้นที่โจมตีได้
การมองเห็นที่จำกัดและช่องว่างในการตรวจสอบ
ถ้า log อยู่ในบัญชีหนึ่งและ alert อยู่ในอีกบัญชี ทีมก็ต้องเสียเวลาค้นหาบริบทขณะที่ incident ยังดำเนินอยู่ จุดบอดซ่อนทั้งความผิดปกติด้านประสิทธิภาพและการบุกรุกที่กำลังเกิดขึ้น
ความกังวลด้านความปลอดภัยที่ทำให้ทีมนอนไม่หลับ
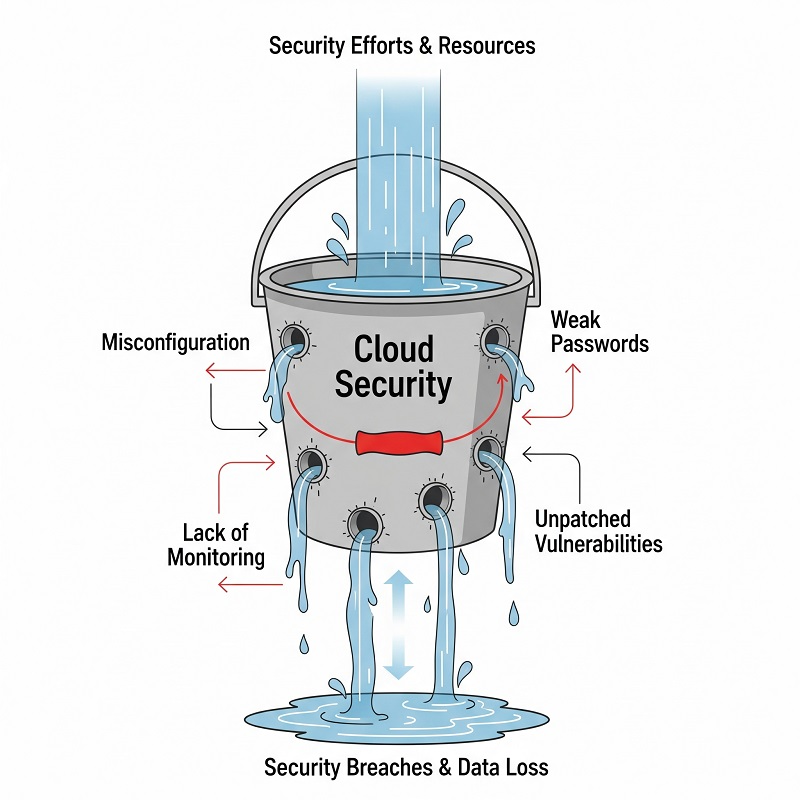
หลักการที่เราได้อธิบายไว้ในบทความเรื่อง cloud security คืออะไร วางพื้นฐานที่ดี แต่ผู้โจมตีที่มีทักษะยังสามารถหลุดรอดได้ หากบริษัทไม่ทำให้การตรวจสอบ log, MFA และการออกแบบสิทธิ์ขั้นต่ำเป็นอัตโนมัติ หากขาดกลไกเหล่านั้น ปัญหาความปลอดภัยหลักในการประมวลผลแบบคลาวด์ จะเปลี่ยนจากเรื่องนามธรรมเป็นเรื่องเร่งด่วน ทันสมัย เครื่องมือความปลอดภัยบนคลาวด์ ช่วยลดเวลาในการตรวจจับได้ แต่ต่อเมื่อทีมนำมาใช้ในขั้นตอนการทำงานประจำวัน
ประเด็นสำคัญ
- ตรวจสอบ endpoint ภายนอกทุกจุด และสแกนหาการเปิดเผยข้อมูลที่ไม่ตั้งใจทุกสัปดาห์
- หมุนเวียน key โดยอัตโนมัติ และมอง credential ที่อยู่มานานเป็นหนี้ทางเทคนิค
- ส่ง audit log เข้า SIEM กลาง แล้วตั้ง alert เมื่อพบความผิดปกติ แทนการแจ้งเตือนข้อผิดพลาดดิบ
เรื่องไม่คาดฝันด้านการดำเนินงานและการเงิน
High availability ฟังดูง่าย จนกว่า database cluster แบบ multi-AZ จะเริ่มทำให้ค่าใช้จ่ายพุ่งเป็นสองเท่า ในบรรดา ความท้าทายหลักของ cloud computing ที่ซ่อนอยู่ต่อหน้าต่อตา ค่าใช้จ่ายที่เพิ่มขึ้นโดยไม่รู้ตัวติดอันดับต้น ๆ ทิกเก็ต support กองพะเนิน ทุกครั้งที่ instance family ถูกยกเลิกหรือเมื่อ capacity limit ขัดขวางการขยาย
ทีมที่ต้องการควบคุมอย่างละเอียดบางครั้งย้ายบริการที่ sensitive ต่อ latency ไปยัง VPS Cloud ที่เบากว่า ด้วยการผูก workload ไว้กับ vCPU ที่รับประกัน พวกเขาหลีกเลี่ยงผลกระทบจาก noisy neighbor ขณะยังคงความยืดหยุ่นในการเลือก provider
ปัญหาคลาวด์ทั่วไปในด้านการดำเนินงาน
- ขีดจำกัดที่ไม่เพียงพอ ขัดขวาง traffic ที่พุ่งสูงขึ้นกะทันหัน
- การล็อกตัวเองไว้กับผู้ให้บริการรายเดียวทำให้การเปลี่ยนแปลง data-plane ช้าและมีค่าใช้จ่ายสูง
- ค่าธรรมเนียมโอนข้อมูลข้ามภูมิภาคที่ไม่คาดคิดระหว่างการทดสอบ failover
การจัดการกำกับดูแลและความเสี่ยงด้านการปฏิบัติตามกฎระเบียบ
ผู้ตรวจสอบมีภาษาของตัวเอง และ cloud ยิ่งเพิ่มศัพท์เฉพาะใหม่เข้ามาอีก เมื่อนโยบายการแท็ก การเก็บข้อมูล และการเข้ารหัสเริ่มหละหลวม ข้อบกพร่องก็สะสมขึ้นอย่างรวดเร็ว ตารางด้านล่างรวบรวมช่องว่างที่พบบ่อยสี่ข้อที่มักเจอในการตรวจสอบความพร้อม
| ช่องว่างการปฏิบัติตามกฎ | ตัวกระตุ้นทั่วไป | ความเป็นไปได้ | ผลกระทบต่อธุรกิจ |
| ข้อมูลส่วนบุคคลที่ยังไม่ได้จัดประเภทซึ่งเก็บอยู่ใน object storage | ไม่มี data inventory | ปานกลาง | ค่าปรับ และความเสียหายต่อชื่อเสียง |
| ไม่มี MFA บนบัญชีที่มีสิทธิ์สูง | เร่งความเร็วโดยข้ามขั้นตอน | สูง | ยึดครองบัญชี |
| แผน disaster-recovery ที่ไม่เคยถูกทดสอบ | ความกดดันทรัพยากร | ปานกลาง | ดาวน์ไทม์ที่ยาวนาน |
| คุณสมบัติเฉพาะของผู้ให้บริการที่ฝังลึกอยู่ในระบบ | ความสะดวกในช่วงสร้างระบบ | ต่ำ | ค่าใช้จ่ายในการออกจากระบบสูง และการย้ายข้อมูลล่าช้า |
สังเกตได้ว่าแต่ละแถวสัมพันธ์กับความท้าทายด้านการประมวลผลที่กล่าวถึงข้างต้น ความชัดเจน สิทธิ์ขั้นต่ำที่จำเป็น และการทดสอบซ้ำได้อย่างสม่ำเสมอ คือแกนหลักของวงจรการตรวจสอบที่ประสบความสำเร็จ
จัดการกับ Pain Points
ไม่มีวิธีแก้ปัญหาครอบจักรวาล แต่การลงมือแบบเป็นชั้นๆ ช่วยลดความเสี่ยงได้อย่างรวดเร็ว แบ่งกลยุทธ์ออกเป็นสามกลุ่ม
- เสริมความแข็งแกร่งให้รากฐาน
- กำหนด baseline ให้ทุกบัญชีด้วย infrastructure-as-code แล้วใช้ drift alert เพื่อตรวจจับการเปลี่ยนแปลงที่ไม่ตั้งใจ
- บังคับใช้ MFA ที่ระดับ identity provider ไม่ใช่รายแอปพลิเคชัน
- ทำให้การตรวจจับและการตอบสนองเป็นแบบอัตโนมัติ
- รวบรวม log ไว้ที่เดียว แล้วจัดกลุ่มด้วย resource tag เพื่อให้ alert บอกได้ว่า อะไร เกิดข้อผิดพลาดที่ไหน ไม่ใช่แค่ว่า ที่ไหน มันแตก
- เริ่มต้น sandbox สำเนาทุกสัปดาห์เพื่อทดสอบชุด patch ก่อนนำขึ้น production
- วางแผนรับมือกับสิ่งที่หลีกเลี่ยงไม่ได้
- จัดการซ้อมรับมือจริง: ปิด service แล้วดู dashboard ว่าตอบสนองอย่างไร บทเรียนจากการลงมือทำจริงติดทนกว่าการนั่งดูสไลด์
- เก็บ image ที่สะอาดและพกพาได้ไว้พร้อมใช้งาน พร้อมตัวเลือก ซื้อ Cloud Server แบบคลิกเดียวที่ทำหน้าที่เป็นวาล์วนิรภัยเมื่อ region เกิดปัญหา
เริ่มจากส่วนที่เข้ากับ stack ของคุณก่อน แล้วค่อยขยายการครอบคลุม ชัยชนะเล็กๆ อย่างการแท็กอัตโนมัติหรือการหมุนเวียน key รายวัน จะสะสมผลลัพธ์ที่ดีขึ้นเรื่อยๆ ตามเวลา
บทสรุป
การใช้งาน Cloud ยังคงเติบโตอย่างต่อเนื่อง ดังนั้นการมองข้ามปัญหาที่เกิดขึ้นจึงไม่ใช่ทางเลือก การวิเคราะห์สภาพแวดล้อมของคุณเทียบกับ ความท้าทายหลักของ cloud computing ที่อธิบายไว้ที่นี่ ช่วยให้คุณค้นพบจุดอ่อนได้ตั้งแต่เนิ่นๆ คาดการณ์ค่าใช้จ่ายได้แม่นยำ และให้นักพัฒนา deploy ฟีเจอร์ได้อย่างมั่นใจ เส้นทางนี้ไม่มีวันสิ้นสุด แต่ด้วยมุมมองที่ชัดเจน เครื่องมือที่ดี และนิสัยการทบทวนสม่ำเสมอ Cloud จะยังคงเป็นตัวเร่งความก้าวหน้า ไม่ใช่ต้นเหตุของการตื่นนอนกลางดึก
ความเร็ว ความสม่ำเสมอ และการรักษาความปลอดภัยที่แน่นหนา ถูกรวมไว้พร้อมใช้งานใน VPS Cloud portfolio แนวทางการจัดการแต่ละ instance ทำงานบน storage NVMe, CPU ความถี่สูง และเส้นทาง Tier-1 แบบซ้ำซ้อน ทำให้ workload เริ่มต้นได้รวดเร็วและตอบสนองได้ดีแม้ในช่วงที่มีการใช้งานสูง Firewall ระดับองค์กร, tenant ที่แยกออกจากกัน และการ patch อย่างต่อเนื่อง รักษาความปลอดภัยของ stack โดยไม่ทำให้ประสิทธิภาพลดลง หากคุณต้องการซื้อ คลาวด์เซิร์ฟเวอร์ ที่ผ่านเกณฑ์ด้านความปลอดภัยและความเชื่อถือได้ครบถ้วน ที่นี่คือคำตอบ


