
Popüler bir modelin Hugging Face'teki GGUF sayfasını açıyorsun ve karşında on beş dosya duruyor: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, artı GPTQ, AWQ ve EXL2 için yarım düzine bit ayarında ayrı klasörler. "4-bit" dosya için peçete hesabı yapıyorsun: 4 bit × 8 milyar parametre ÷ 8 = 4 GB. Ama dosya 4,6 GB diyor. Ve onu yükledikten sonra, model bundan daha fazla bellek kullanıyor.
Dosya adları gürültü değildir. Bit genişliği, onları yükleyen çalışma zamanı ve ihtiyaç duydukları donanım hakkında gerçek, öğrenilebilir bilgiler kodlarlar. Okuduğunuz boyutlandırma tabloları size 70B'lik bir modelin kabaca 40 GB gerektirdiğini söyler, faydalıdır, ama formatın kendisini asla çözmezler veya çalışan modelin diskteki dosyadan neden daha fazla bellek istediğini açıklamazlar.
İşte plan: GGUF adlandırma kuralını (isim üzerindeki değil gerçek bit genişlikleriyle) çözmek, dört formattan hangisini donanımınızın gerçekten çalıştırabileceğini belirlemek ve her dosya boyutunda görünmez olan tek bellek maliyetini, KV önbelleğini, hesaba katmak. Sonunda bir model deposunu okuyup yüklendiğinde nasıl davranacağını tahmin edebileceksiniz.
Özetle
- GGUF kuantizasyon seviyeleri, isimdeki tam sayı değil etkin bit genişlikleridir. Q4_K_M ağırlık başına yaklaşık 4,89 bittir, bu yüzden "4-bit" bir 8B dosyası, saf 4-bit tahmini yerine yaklaşık 4,6 GiB civarında olur.
- GGUF en taşınabilir seçenektir çünkü llama.cpp onu CPU'da, GPU'da veya hibrit bir kurulumda çalıştırabilir. GPTQ, AWQ ve EXL2 daha çok GPU'ya ve çalışma zamanına özgüdür; özellikle EXL2, NVIDIA/CUDA iş akışlarına bağlıdır.
- KV önbelleği model ağırlıklarından ayrıdır ve bağlam uzunluğuyla birlikte büyür. Temiz bir şekilde yüklenen bir modelin, konuşma uzadıkça yine de bellek yetersizliğiyle çökebilmesinin nedeni budur.
- 5-bit aralığının üzerinde, kalite kaybı genellikle küçüktür. Q4 civarında, takas hâlâ birçok yerel kullanım durumu için pratiktir. 4-bitin altında, kalite maliyeti çok daha belirgin hale gelir. Q4_K_M yaygın bir topluluk varsayılanı olmaya devam ederken, Q5_K_M ve Q6_K bellek fazlanız olduğunda daha güvenlidir.
Bir GGUF Dosya Adında Q4_K_M Ne Anlama Gelir?

Bir GGUF kuantizasyon adı Q[bit]_[K]_[S/M/L] desenini izler. Sayı, hedef ağırlık başına bit; K, ağırlıkların küçük her bloğu için ölçekleme faktörleri depolayan bir "K-kuant" olduğu anlamına gelir ve sondaki S, M veya L boyut/kalite katmanıdır (küçük, orta, büyük). K-kuantlar her blok için ağırlıkların yanında bir ölçek ve minimum değer sakladığından, etkin bit genişliği başlıktaki sayıdan daha yüksektir. Q4_K_M ağırlık başına yaklaşık 4,89 bite ulaşır, 4'e değil.
Bu fark, "neden 4-bit dosyam 4,6 GB?" sorusunun tüm cevabıdır. Saf tahmin, her ağırlığın tam olarak 4 bite mal olduğunu varsayar. Gerçekte, K-kuantlar düşük bitli kuantizasyonu doğru kılan meta veriler için blok başına ekstra bit harcar; bu, çalışma zamanının her ağırlığı yeniden oluşturmasını sağlayan blok başına ölçek ve minimum değerdir. 4,89 biti 8 milyar ağırlıkla çarparsanız, dosyanın gerçekte tarttığı yaklaşık 4,58 GiB'ye ulaşırsınız.
İşte ölçülen etkin bit genişlikleri ve dosya boyutları, şuradan alınmıştır: llama.cpp quantize documentation referans model olarak Llama 3.1 8B için, llama.cpp kuantizasyon değerlendirme makalesinde ölçülen her seviyenin perplexity maliyetiyle birlikte (arXiv:2601.14277) Llama-3.1-8B-Instruct üzerinde:
| GGUF seviyesi | Etkin BPW | ~Dosya boyutu (8B) | F16'ya Karşı Perplexity* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | referans |
*Perplexity rakamları arXiv:2601.14277'den Llama-3.1-8B-Instruct'a özgüdür. BPW/dosya boyutu sütunu ve perplexity sütunu, ayrı ayrı ölçülmüş iki farklı kaynaktan gelir, bu yüzden tabloyu tek bir kıyaslama çalışması olarak değil, pratik bir yan yana referans olarak okuyun. Göreve özgü bozulma değişkenlik gösterir; matematiksel akıl yürütme, düşük bit genişliklerinde sağduyulu akıl yürütmeden daha fazla zarar görme eğilimindedir, ancak genel şekil geçerliliğini korur: 5-bit ve üzeri genellikle daha güvenlidir, Q4 pratik sıkıştırma bölgesidir ve 3-bit, kalite kaybının görmezden gelinmesinin çok daha zorlaştığı yerdir.
Pratikte: Q4_K_M çoğu kişinin tercih etmesi gereken varsayılandır, Q5_K_M ve Q6_K bellek fazlanız olduğunda kaliteye yönelen seçeneklerdir ve Q3_K_S veya altındaki her şey, gerçekten daha fazlasını sığdıramayan donanımlar için son çaredir.
Hangi Kuantizasyon Formatını İndirmelisiniz: GGUF, GPTQ, AWQ mı EXL2 mi?

GGUF, dördü arasında en taşınabilir olanıdır: llama.cpp aracılığıyla CPU'da, GPU'da veya ikisinin bir hibritinde çalışır, bu yüzden donanımınızın neyi destekleyebileceğinden emin değilseniz en güvenli seçimdir. GPTQ, AWQ ve EXL2 daha çok GPU'ya ve çalışma zamanına özgüdür. Pratikte en yaygın olarak NVIDIA/CUDA kurulumlarında görülürler, ancak GPTQ ve AWQ desteği yükleyiciye ve sunum yığınına göre değişebilir; örneğin vLLM, kuantizasyon desteğini donanım ve uygulamaya göre ayırır. Mac'te, bir AMD kartta veya yalnızca CPU'lu bir kutuda yerel olarak çalışıyorsanız, GGUF hâlâ en güvenli cevaptır. NVIDIA GPU'nuz varsa ve mümkün olan en hızlı token'ları istiyorsanız, diğer üçü devreye girer.
| Format | Donanım/çalışma zamanı | Hız (göreceli) | Emsallerine Karşı VRAM | Şunlar için ideal |
|---|---|---|---|---|
| GGUF Q4_K_M | En geniş, llama.cpp aracılığıyla CPU, GPU veya hibrit | Orta | En düşük | Herhangi bir donanım; yerel varsayılan |
| GPTQ 4-bit | Genellikle CUDA/GPU öncelikli; çalışma zamanına bağlı | Hızlı (ExLlama) | Orta | GPU öncelikli, eski araçlar |
| AWQ 4-bit | Genellikle CUDA/GPU öncelikli; çalışma zamanına bağlı | Hızlı | En yüksek | vLLM/TGI sunumu, hızlı yükleme |
| EXL2 ~4,9 bpw | NVIDIA/CUDA öncelikli | En Hızlı | Düşük-Orta | NVIDIA'da maksimum hız |
Bu tabloyla ilgili bir uyarı: hız ve VRAM sıralamaları şuradan geliyor: oobabooga kıyaslaması, bu 2023/2024 dönemi donanımlarda çalıştırıldı. Sıralamayı göreceli sıralamayı kalıcı olarak ele alın. EXL2 hız için tasarlanmıştır, AWQ hızlı yükleme için VRAM'i feda eder, GGUF sade ve taşınabilir kalır, ancak orijinal mutlak saniyedeki token sayısı rakamlarını güncelmiş gibi okumayın. 2026 model bir GPU çok farklı ham verim gösterecektir; kalıcı olan sıralamadır.
Bu durumda ortaya çıkan karar kuralı şu: NVIDIA kartınız varsa ve en çok hızı önemsiyorsanız, EXL2; farklı donanımlar arasında en güvenli yerel varsayılanı istiyorsanız, GGUF. AWQ ve GPTQ, çoğunlukla belirli bir sunum yığını (vLLM, TGI) veya mevcut araçlar sizi oraya yönlendirdiğinde önem kazanır.
Yerel Bir LLM Neden Dosyasından Daha Fazla Bellek Kullanır?
Dosya boyutu yalnızca model ağırlıklarıdır. Çalışma zamanında ayrıca KV önbelleği (bağlam pencerenizdeki her token için dikkat durumu), etkinleştirmeler (bir ileri geçişin ara matematiği) ve çerçeve ile sürücü ek yükü için de bedel ödersiniz. Ağırlık dışı parçalar toplamda, tek kullanıcılı bir kurulum için ağırlıkların üzerine rutin olarak %10 ila %20 ekler ve bağlam uzadıkça tek başına KV önbelleği her şeyi gölgede bırakabilir. 4,6 GB'lık bir dosya, çalışması için 4,6 GB'tan çok daha fazla belleğe ihtiyaç duyabilir.
Çalışma zamanı belleğini üst üste yığılmış dört bileşen olarak düşünün:
- Model ağırlıkları. İndirdiğiniz dosya. Yüklemeden önce görünen tek parça budur.
- KV önbelleği. Bağlam penceresi için dikkat durumu. Kısa bağlamda küçük, uzun bağlamda devasa. Bu bir sonraki bölüm, çünkü insanları şaşırtan kısım bu.
- Etkinleştirmeler. Bir ileri geçişin çalışma belleği. Tek akışlı yerel çıkarım için (grup boyutu 1), bu küçüktür, tipik olarak birkaç yüz megabayt.
- Çerçeve ek yükü. Çalışma zamanının kendi ayak izi artı GPU sürücü bağlamı. Hafif bir yerel çalışma zamanı için bu, model ağırlıkları ve KV önbelleğine kıyasla küçük olabilir; daha ağır sunum çerçeveleri çok daha fazlasını ayırabilir. İşletim sisteminizin kendi bellek ayırması bunun dışında kalır ve yine ayrıdır.
Ağırlıklar ve çerçeve ek yükü öngörülebilirdir. KV önbelleği, "sığan" bir modeli çöken bir modele dönüştüren değişkendir, bu yüzden gerçek matematiği baştan sona işlemeye değer.
KV Önbelleği Ne Kadar Bellek Kullanır?
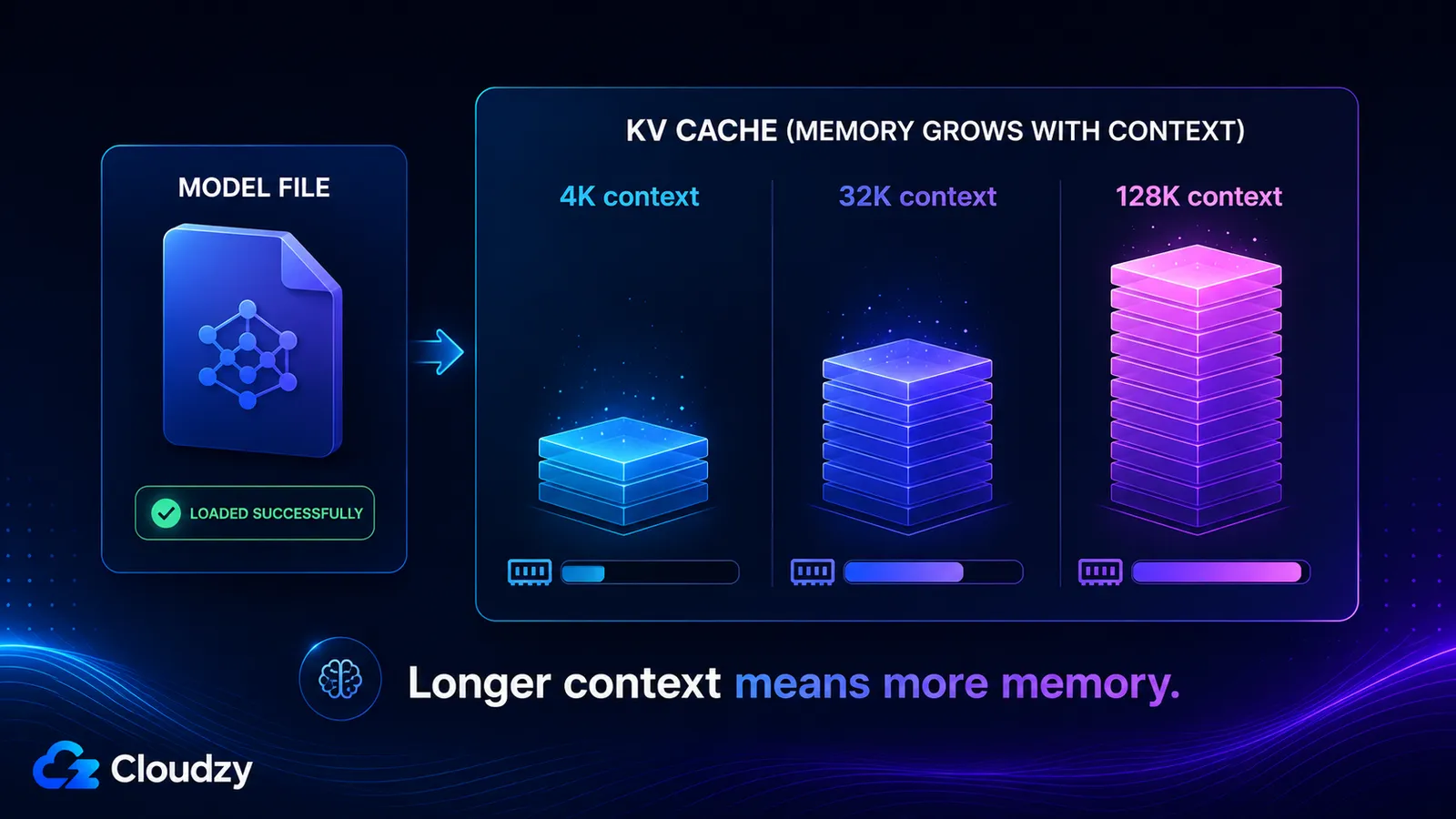
KV önbelleği, bağlam pencerenizdeki her token için anahtar ve değer vektörlerini depolar, bu yüzden bağlam uzunluğuyla kabaca doğrusal olarak büyür ve model ağırlıklarından tamamen ayrıdır. Boyutu, modelin katman sayısı, KV kafa sayısı, kafa boyutu, bağlam uzunluğu ve önbelleğin hassasiyeti tarafından belirlenir. Uzun bir bağlamı açtığınızda, sorunsuz yüklenen bir modelin sizi hiç uyarmadığı onlarca gigabayt ekleyebilirsiniz.
Formül aklınızda tutabileceğiniz kadar kısadır:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Baştaki 2, token başına depolanan iki tensör içindir; biri anahtarlar, biri değerler için. bytes_per_element, FP16 önbellek için 2'dir. Geri kalanı, bir model kartından okuyabileceğiniz mimari sabitleridir.
Bunu, 32 katmana, 8 KV kafasına ve 128'lik bir kafa boyutuna sahip Llama 3.1 8B için hesaplayın. 4.096 token'lık bir bağlamda, grup boyutu 1, FP16 önbelleğiyle:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Bağlamı büyüttükçe rakam da onunla birlikte büyür, çünkü context_tokens dışındaki her terim sabittir:
- 4K bağlam: ~536 MB
- 32K bağlam: ~4,3 GB
- 128K bağlam: ~17 GB
Bu son iki rakam, bir modelin 128K'lık bir bağlam penceresi ilan edip mutlu bir şekilde yüklenebilmesinin, ardından o pencereyi gerçekten kullandığınız anda belleği tüketebilmesinin nedenidir. Tam bağlamdaki KV önbelleği, kuantize edilmiş ağırlıkların kendisinden bile daha büyüktür.
İşte modern uzun bağlamlı modelleri mümkün kılan kısım: Llama 3.1 8B şunu kullanır: Grouped Query Attention (GQA). 32 sorgu kafası var ama yalnızca 8 KV kafası var; önbellek 32 değil 8 kafa için anahtar/değer vektörlerini depolar. Aynı formülü 32 KV kafasıyla (KV kafalarının sorgu kafalarına eşit olduğu eski Multi-Head Attention tasarımı) çalıştırırsanız, yukarıdaki her rakam 4 ile çarpılır. 128K'daki o 17 GB, 68 GB'a çıkar. GQA, bağlam pencereleri büyüdükçe matematiğin katlanılabilir kalmasının mimari nedenidir.
Dosya boyutu bellek bütçeniz değildir. Ağırlıklar veya KV önbelleği artık hızlı bellek yoluna sığmadığında ve çalışma zamanı PCIe üzerinden sistem RAM'ine geri dönmek zorunda kaldığında, verim yumuşak bir şekilde düşmez. Her token için veriyi PCIe üzerinden taşımaya başladığınızda uçurumdan düşer. Belleği yalnızca ağırlıkların değil, gerçek bağlam uzunluğunuzdaki ağırlıkların ve KV önbelleğinin ikisinin de sığacağı şekilde bütçeleyin.
GPU'nuz veya Mac'iniz İçin Bir Kuantizasyon Nasıl Seçersiniz?
Donanımınızdan ve çalışma zamanınızdan başlayın. NVIDIA GPU sahiplerinin en geniş menüsü vardır ve ham hız için EXL2'yi veya taşınabilirlik için GGUF'u tartmalıdır. AMD, Apple Silicon, yalnızca CPU'lu donanım veya karma bir kurulumdaysanız, llama.cpp aracılığıyla GGUF genellikle en güvenli başlangıç noktasıdır. Oradan, modelin maksimumu değil gerçekte kullandığınız bağlam uzunluğunda KV önbelleğini bütçeledikten sonra sığan en yüksek kuantizasyon seviyesini seçin.
Bilinmeye değer bir Apple Silicon tuzağı: GPU, birleşik belleğinizin tamamını almaz (bu paylaşımlı havuzun nasıl çalıştığının tam resmi için şu konudaki eşlik eden yazımıza bakın: birleşik belleğin gerçekte ne olduğu paylaşımlı havuzun nasıl çalıştığının tam resmi için). Kendi kendine barındırma topluluğu, yaklaşık %75'lik bir sınırı belgeledi toplam birleşik belleğin GPU'ya sunulabilen kısmı için (bu Apple tarafından resmi olarak doğrulanmamıştır ve macOS güncellemeleriyle değişebilir). Bu yüzden "64 GB'lık bir Mac", model artı KV önbelleği için gerçekçi olarak ~48 GB'tır; daha küçük rakama göre plan yapın.
Bu makale, formatı okumak ve çalışma zamanı davranışını tahmin etmekle ilgilidir: kuantizasyon adını çözün, donanımınızın desteklediği formatı seçin ve KV önbelleğini ağırlıklardan ayrı olarak bütçeleyin. Belirli bir modeli belirli bir bellek miktarıyla eşleştirmek, yani boyuttan belleğe arama tablosu, gelecekteki bir eşlik eden yazıda ele alacağımız ilişkili ama ayrı bir konudur.
Depoyu Okuyun
Artık bir model sayfasına bakıp tahmin etmek yerine onu okuyabilirsiniz. Kuantizasyon adını etkin bit genişliğine çözün, GGUF'un en geniş yerel format olduğunu, GPTQ, AWQ ve EXL2'nin ise daha çok çalışma zamanına özgü olduğunu kabul edin ve dosya boyutunun yalnızca taban olduğunu, KV önbelleğinin üzerine eklendiğini ve bağlamınızla birlikte büyüdüğünü unutmayın. İstediğiniz model için dosyaları açın, donanımınızın çalıştırabileceği formatı seçin, gerçek bağlam uzunluğunuzdaki KV önbelleği için pay bıraktıktan sonra sığan en yüksek kuantizasyon seviyesini seçin ve bu sorunun tamamını başlatan bellek yetersizliği çökmesinden kaçınacaksınız.
Sıkça Sorulan Sorular
Q4_K_M Ne Anlama Gelir?
Q4_K_M bir GGUF kuantizasyon seviyesidir: ağırlık başına kabaca 4 bit (Q4), blok başına K-kuant ölçeklendirme kullanır (K), orta boyut/kalite katmanında (M). Onun etkin bit genişliği ağırlık başına yaklaşık 4,89 bittir, tam olarak 4 değil, çünkü K-kuantlar her ağırlık bloğu için bir ölçek ve minimum değer depolar. Bu yüzden "4-bit" bir 8B model dosyası 3,5 GB yerine yaklaşık 4,6 GB'dır.
Kuantizasyon LLM Kalitesini Düşürür mü?
Evet, ancak maliyet, bunu ne kadar zorladığınıza büyük ölçüde bağlıdır. arXiv:2601.14277'de ölçülen Llama-3.1-8B-Instruct'ta, perplexity Q6_K'da yalnızca yaklaşık %0,4 artar ve Q5 bandı boyunca %1 civarında kalır. Q4'e düştüğünüzde artış hâlâ mütevazıdır (birkaç yüzde); Q3_K_M'nin altında dik bir şekilde tırmanır ve Q3_K_S'de +%22'ye ulaşır. Çoğu kullanım için Q4_K_M ve üzeri etkin biçimde kayıpsızdır; dik ceza 3 bit ve altında yaşar.
GGUF, GPTQ, AWQ ve EXL2 Arasındaki Fark Nedir?
GGUF (llama.cpp tarafından çalıştırılır) taşınabilir formattır; geniş bir donanım yelpazesinde CPU, GPU veya hibrit bir kurulumda çalışır. GPTQ, AWQ ve EXL2 daha çok GPU'ya ve çalışma zamanına özgüdür. 4-bit'te, dördü de dar bir kalite bandına düşebilir, bu yüzden pratik fark donanım, yükleyici desteği, hız ve VRAM kullanımıdır: EXL2 hıza odaklı NVIDIA/CUDA seçimidir, AWQ sunum yığınlarında yaygındır, GPTQ eski GPU araçlarına ve model depolarına uyar ve GGUF en taşınabilir yerel seçenek olarak kalır.
Yerel LLM'im Dosyadan Neden Daha Fazla Bellek Kullanıyor?
Dosya boyutu yalnızca model ağırlıklarıdır. Çalışma zamanında ayrıca KV önbelleği (bağlam penceresindeki her token için dikkat durumu), etkinleştirmeler ve çerçeve artı sürücü ek yükü için de bedel ödersiniz. Fark büyük olduğunda genellikle suçlu KV önbelleğidir, çünkü bağlam uzunluğuyla büyür ve ağırlıklardan ayrı olarak tahsis edilir; dosyası birkaç gigabayt olan bir model, uzun bir bağlam ayarladığınızda çok daha fazla belleğe ihtiyaç duyabilir.
Bağlam Uzunluğu Bellek Kullanımını Nasıl Etkiler?
KV önbelleği, bağlam uzunluğuyla kabaca doğrusal olarak büyür, bu yüzden bağlamınızı iki katına çıkarmak önbelleği de kabaca iki katına çıkarır. Llama 3.1 8B için önbellek, 4K token'da yaklaşık 536 MB, 32K'da ~4,3 GB ve 128K'da ~17 GB'dır (FP16, tek akış). Bu büyüme model ağırlıklarından tamamen ayrıdır, bu yüzden uzun bir bağlam penceresi ilan etmek, sorunsuz yüklenmiş olsa bile bir modeli bellek yetersizliğine itebilir.


