GPU monitoring software je nástroj, který změní "můj GPU nefunguje správně" v jasné vysvětlení, třeba "hotspot se zvýšil, takty klesly a VRAM je plný."
V tomto průvodci vás provedou nástroji, které můžete použít pro AI úlohy, herní overlaye a dlouhé pracovní relace, a ukážu vám GPU metriky, které vám pomohou diagnostikovat zpomalení, trhání a chyby.
Na konci budete mít GPU monitoring software nastavený tak, aby vyhovoval vašemu pracovnímu stylu. Dostanete také připravené konfigurace pro čtyři běžné případy použití, takže nebudete muset hledat články.
Rychlá odpověď: Top GPU Monitoring Software podle případu použití
Pokud chcete jen krátký seznam odpovídající tomu, jak lidé skutečně pracují, začněte s těmito. V praxi je nejlepší GPU monitoring software zásobník kombinace: jeden nástroj na rychlé kontroly, jeden na overlaye nebo logy a jeden na historii nebo výstrahy.
Tady je rychlý přehled:
| Případ použití | Doporučený základní zásobník | Co získáte |
| AI trénink, inference, HPC úlohy | nvidia-smi (NVIDIA) nebo AMD SMI (AMD) + logging/exporter | Rychlé kontroly, skriptovatelné logy, snadné upozorňování |
| Hraní her na Windows | MSI Afterburner + RTSS + nástroj na zachytávání frametime | Overlay a důkaz pro zasekávání vs. nízké FPS |
| Hraní her na Linuxu | MangoHud + terminálový kontroler (nvtop) | Odlehčená vrstva plus kontroly správnosti na úrovni procesu |
| Pracovní stanice (3D/video/CAD) | Logování HWiNFO + jednoduchý test zátěže | Dlouhé záznamy, které můžete sdílet, a reprodukovatelný případ |
| Sdílené stroje GPU | nvtop (Linux) + vývozce/dashboard | Viditelnost VRAM pro jednotlivý proces |
Odtud už jde jen o to, aby monitorovací software GPU odpovídal tomu, jak spotřebováváte data: na obrazovce, v logu nebo v dashboardu.
Pro koho je tento průvodce
Budu to psát jako někdo, kdo skutečně ladil servery. Vím totiž z vlastní zkušenosti, že různí čtenáři potřebují různé GPU nástroje, i když se dívají na stejný GPU.
Tady jsou čtyři konfigurace, na které se zaměřuji:
- Tvůrce modelů (AI/ML): zajímá vás, má VRAM dost rezervy, dokáží GPU udržet konstantní frekvenci, nedochází k throttlingu a hlavně - poběží úloha pres noc bez problémů?
- Konkurenční hráč/streamer: myslí na doby vykreslení, stabilitu overlay vrstev a odhalování regresí po aktualizacích ovladačů.
- Uživatel pracovní stanice (3D/video/CAD): zajímá se o logy, reprodukovatelné pády a přesné určení chování ohledně tepla, spotřeby a ovladačů.
- Správce serverů GPU: zajímá se o upozornění, trendové grafy, plánování kapacity a včasné odhalení problémů.
Jakmile víte, která kategorie vám vyhovuje, snadno si vyberete monitoring software GPU, který vám bude stačit.
Jak vybrat monitorovací software GPU
Spousta aplikací pro monitorování výkonu vypadá stejně, dokud je nezkusíš používat týden. Rozdíl je obvykle v tom, jak fungují a jak jsou spolehlivé, ne v těch atraktivních "funkcích", které každá zoufale propaguje.
Tři otázky vám pomůžou rychle vybrat monitoring software GPU:
- Potřebujete overlay, log, nebo obojí?
Hráči chtějí overlay. AI a práce na workstationech obvykle vyžadují logování. Správci chtějí logy plus upozornění. - Potřebujete viditelnost jednotlivých procesů?
Pokud si server sdílíte (lab, studio, vzdálený server), per-process VRAM je často první věc, kterou hledáte. - Potřebujete historii a upozornění?
Když běží úlohy přes noc, "zkontroluju to později" nestačí. Chcete graf a upozornění.
Aby to bylo praktické, zbytek návodu je organizovaný podle metriky GPU, pak toolkity, které se hodí pro každý use-case.
Metriky GPU, Na Kterých Záleží
Monitoring software GPU vám dá spoustu čísel. Opravdu užitečný monitoring software GPU vám dá tu specifickou hrstku, která vysvětlí chování. Metriky GPU dělím podle toho, jaké rozhodnutí vám pomohou udělat.
Metriky Teploty a Throttlingu
Toto jsou metriky GPU, které vysvětlují "bylo to rychlé 10 minut, pak to už nebylo":
- Teplota GPU
- Teplota hotspotu (často první věc, která vzroste)
- Teplota paměti/junction (důležitější při dlouhých AI bězích a renderech)
- Rychlost ventilátoru (pomáhá odhalit laptop profily nebo špatné fan curves)
Pokud chcete zlepšit stabilitu, logujte to, protože jednotlivé snímky zřídka dávají dost informací.
Výkon, Frekvence a Limity
Tyto metriky GPU vysvětlují downclocking a nekonzistentní výkon:
- Spotřeba desky
- Frekvence jádra a paměti
- Limit výkonu/performance state (pokud to váš tool zobrazuje)
V mnoha reálných debuggingy jsou výkon a frekvence jasnějším obrázkem než prostá "GPU usage %".
VRAM a Zatížení Paměti
Tyto metriky GPU vysvětlují zaseky, chyby nedostatku paměti a typické "náhodné" zpomalení:
- VRAM použitá vs celkem
- Aktivita řadiče paměti (pomáhá odhalit omezení šířky pásma)
- Tlak na systém RAM (protože přetečení VRAM může stáhnout i celý systém)
Pro AI je VRAM často pevný strop. Pro hry se tlak VRAM obvykle projevuje nejdřív jako skokové změny v čase snímku.
Metriky času snímku a vyvážení snímků
Pro hraní a streamování může být samotný počet FPS zavádějící. Čas snímku je metrika, na kterou se chcete zaměřit, protože ukazuje hladkost přehrávání nebo její absenci:
- Doba snímku (ms)
- 1% nízko / 0.1% nízko (dobré pro porovnání)
- GPU vytížení vs CPU vytížení (pomáhá odlišit úzká místa GPU od úzkých míst CPU)
Proto aplikace pro sledování výkonu zaměřené na hraní často obsahují cestu pro zaznamenávání času snímku. Teď když máte základy metrik, můžeme si povědět o nejlepších softwarových sadách pro sledování GPU v jednotlivých pracovních postupech.
Software pro sledování GPU pro AI, trénink a servery

Sledování AI má jednoduché nastavení s rychlými kontrolami v terminálu, plus logy a upozornění pro dlouhé běhy. K tomu chcete software pro sledování GPU, který mluví CLI a exportuje metriky.
NVIDIA: nvidia-smi pro rychlé kontroly a logovatelné skripty
Na systémech NVIDIA, nvidia-smi je obvykle první příkaz, který lidé spustí, protože se dodává s ovladačem a je určen pro sledování a správu přes NVML.
Oficiální dokumentace je zde: Rozhraní správy systému NVIDIA (nvidia-smi).
Pokud chcete jednoduchý přístup "zaznamenat a podívat se později" (a budete překvapeni, jak často to problém vyřeší), tento vzor je dost spolehlivý:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Toto je základní chování software pro sledování GPU s časovými razítky, základními metrikami GPU a výstupem, který dobře funguje se skripty.
AMD: AMD SMI pro ROCm a HPC uzly
Na výpočetních uzlech AMD a Linux je AMD SMI moderní rozhraní pro monitorování a správu. AMD jej dokumentuje jako jednotný nástroj pro monitorování a řízení v HPC prostředích.
Oficiální dokumentace je zde: Dokumentace AMD SMI.
Pokud vaše prostředí silně využívá AMD, AMD SMI je základem monitorovacího softwaru GPU, na kterém obvykle staví další nástroje.
Viditelnost jednotlivých procesů: nvtop pro sdílené GPU
Pokud jste kdy řešili sdílený server, kde VRAM "záhadně" zůstává plná, viditelnost na úrovni procesů vám ušetří čas. Na Linux nvtop je populární právě proto, že jasně ukazuje "kdo VRAM používá". Na AMD/Intel možná budete potřebovat novější kernel pro statistiky jednotlivých procesů.
V smíšených týmech často vidím lidi spouštět nvtop vedle sebe s nvidia-smi nebo AMD SMI. Je to jednoduchá kombinace, která se vyhne spoustě hádání, takže ji důrazně doporučuji.
Nepodceňujte volbu hardwaru!
Monitorování neodstraní strop VRAM; pouze jej zviditelní. Pokud stále mapujete úlohy na úrovně GPU, naše průvodce Nejlepší GPU pro strojové učení v roce 2025 je užitečný doplněk, protože VRAM a šířku pásma vysvětluje stejně jako je později uvidíte v lozích a řídicích panelech.
Jakmile máte server-style monitorování GPU pod kontrolou, dalším krokem jsou overlay a frametime, protože interaktivní úlohy se chování jinak.
Monitorovací software GPU pro hraní a streaming

U hraní mají lidé nejsilnější názory na nástroje GPU, hlavně proto, že overlay selhají v nejhorší chvíli. Na hraní chcete jednoduché overlay a opakovatelné záznamy frametime.
MSI Afterburner + RTSS pro overlay na Windows
Tato kombinace je populární, protože si můžete vytvořit čistý overlay přesně s metrikami GPU, které vás zajímají: zatížením, frekvencemi, VRAM, teplotami, frametime a třeba otáčkami ventilátoru.
Jedno vážné varování, které se často objevuje v diskuzích komunity, se týká podvodných stránek ke stažení. Sám Afterburner na stránkách MSI zdůrazňuje, že legitimní stažení by mělo pocházet z msi.com a Guru3D, a také tam naleznete aktuální verzi (4.6.6 final, vydána říjen 2025).
Dalším problémem jsou chyby overlay. Například RTSS funguje v některých hrách a v jiných selže, zejména s moderními render pipeline. Lidé hlásí případy, kdy se overlay zobrazuje ve Vulkanu, ale ne v DX12 u stejné hry, nebo zmizí po aktualizacích.
To ale není chyba z vaší strany, jen to, co se děje, když se overlay napojují na neustále se měnící herní a ovladačové stacky.
Pokud chcete stabilní základní overlay, uchyťte jej krátký:
- čas snímku
- Používání GPU
- VRAM použitá
- Teplota GPU
Přidej power a clocks pouze, pokud aktivně debuguješ throttling.
Zachycení frametime pro "Zasekávání"
Tady se hodí aplikace pro monitorování výkonu, které umí zachycovat grafy frametime. Průměrný počet FPS může vypadat dobře, ale časování snímků může být katastrofální. Grafy frametime tu zmatek vyřeší rychle.
Mnoho herních benchmark workflowů používá PresentMon v pozadí, a Dokumentace NVIDIA jeho analýza FrameView také používá PresentMon pro zachycení obnovovací frekvence a času snímků.
Nemusíte benchmarkovat každou hru. Zachycení frametime se nejlépe hodí na srovnání, třeba před a po aktualizaci driveru, před a po změně limiteru, před a po změně nastavení, a tak dál.
MangoHud pro Linux Overlay
Na Linux se MangoHud často doporučuje, protože je lehký a čistě se integruje se setupy Steam/Proton. Nejčastější stížnosti jsou na chybějící senzory nebo zvláštní hodnoty na hybridních laptopu.
V praxi můžete MangoHud snadno spárovat s terminálním checkerem jako nvtop. Je to také pěkný příklad toho, jak software pro monitorování GPU funguje výrazně lépe jako malý stack, místo jedné obrovské aplikace.
Od her je přirozený další krok monitoring workstationu, protože tam jsou prioritou logy a opakovatelné řešení problémů.
Hostujte herní servery bez lagů s vysokorychlostním NVMe VPS hostingem.
VPS pro hraní
Software pro monitorování GPU na workstationech a profesionálních aplikacích
Monitoring workstationu není tolik práce bezpečnostního důstojníka, který sleduje živý overlay, ale spíš odpovídání na otázku "Co se stalo v čase a umím to zopakovat?"
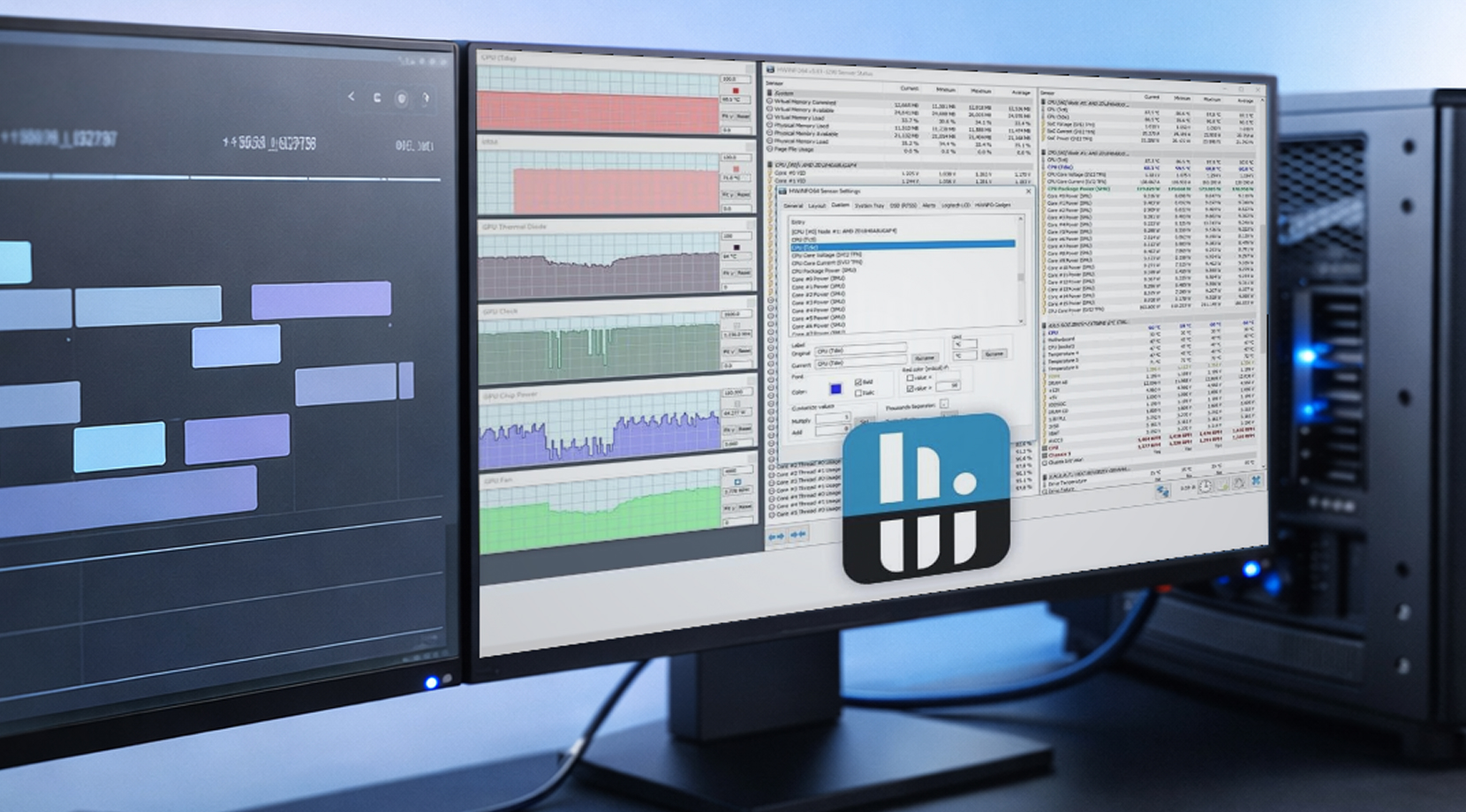
HWiNFO pro logování na Windows
HWiNFO je populární v kruzích workstationů, protože má hluboké pokrytí senzorů a logování, které se snadno sdílí. Jednoduchý CSV log s časovými razítky snadno změní vágní zprávu na něco, co můžete aktivně používat k opravě problémů.
Pokud stavíte log workstationu pro stabilitu GPU, začněte s těmito metrikami GPU:
- Teplota GPU a hotspot
- VRAM použitá
- Napájení desky
- základní frekvence
- Napájení balíčku CPU (protože limity napájení platformy vás mohou kousnout)
Toto je sada "dost dat na vysvětlení". Je to proto, že logování každého senzoru jen ztěžuje čitelnost souboru.
GPU-Z pro rychlé kontroly "Jaký je to GPU?"
GPU-Z je stále užitečné, protože je rychlé a zaměřené. V týmech se smíšeným hardwarem je to nejrychlejší způsob, jak potvrdit model GPU, základy driveru a živé senzory bez proklikávání menu.
Stress testing: Užitečný pouze s logováním
Stress testy mohou pomoct reprodukovat selhání, ale pouze pokud váš software pro monitorování GPU loguje během jejich spuštění. Bez těch logů vám zbývá jen "to zase selhalo" a prakticky žádná osa času.
V tomto bodě lidé narazí na stejné problémy, třeba na overlay, které se nezobrazují, na chybné hodnoty výkonu a na nečitelné logy. Pojďme se s tím vypořádat přímo.
Běžné problémy s GPU monitorovacím softwarem a rychlá řešení

Většina problémů se dá svést na pár základních příčin. Tady je co zkouším první, protože to vyřeší nudné věci rychle.
Chybějící overlay ve hře
Když overlay zmizí v moderní hře, jde často o problém s per-game hookem nebo konflikt s anti-cheat či anti-tamper vrstvami.
Co můžeš zkusit, co často pomáhá:
- Aktualizuj RTSS a resetuj per-game profil
- Nastav vyšší "úroveň detekce aplikace" pro profil hry
- Zkus jiný API, pokud hra to podporuje
- Vrátíš se k zabudovaným overlayům, když hra blokuje overlaye třetích stran
Ne každá hra bude spolupracovat a nestojí to za to trávit hodinami jedinou tvrdohlavou hrou.
Podivné hodnoty napájení (0W, plochá linka, chybějící senzory)
Toto se často objevuje u notebooků a hybridních sestav, kde se aktivní GPU může měnit. V těchto případech si to ověř druhým nástrojem, třeba nvidia-smi (NVIDIA) nebo AMD SMI (AMD), jsou to dobré testy na "je GPU vůbec aktivní?".
Logy jsou příliš hlučné
Příčinou je obvykle oversampling. Na většinu diagnostiky stačí 1 až 5 sekund. Na dlouhé AI úlohy je 5 sekund v pořádku. Kratší intervaly zvyšují velikost souboru a zhoršují čitelnost grafů.
Jakmile jsou základy vyřešeny, vzdálený monitoring je logickým dalším krokem, protože spoustu GPU workflowů se dnes spouští mimo stroj.
Vzdálený GPU monitoring a praktická cloudová volba
Vzdálená práce mění, co znamená "dobrý software pro monitoring GPU". Nepřihlížíš stroji neustále, takže potřebuješ kontroly, které si můžeš spustit rychle, plus historii, kterou si můžeš později prohlédnout.
Čisté vzdálené nastavení obvykle vypadá takto:
- Kontroly CLI (nvidia-smi nebo AMD SMI)
- soubor logu, který si můžeš později stáhnout
- exporter či dashboard, když potřebuješ upozornění
Pokud jsi v bodě, kde se místní hardware stává překážkou pokroku (VRAM limity, sdílení jednoho GPU, potřeba čistého prostředí na projekt), spouštění workloadů na GPU VPS je často nejjednoduší cesta jak se posouvat dál.
Cloudzy GPU VPS

Pokud chceš vzdálený GPU čas, který vyhovuje AI, hrám a renderování, náš Cloudzy GPU VPS nabízí NVIDIA varianty jako RTX 5090, A100 a RTX 4090, plus NVMe úložiště, plný root přístup, připojení až do 40 Gbps, DDoS ochranu a deklarovaný cíl 99,95% dostupnosti.
Z pohledu monitoringu se chová jako normální stroj, protože si můžeš spustit software GPU pro monitoring přes SSH, logovat GPU metriky na dlouhé úlohy a přidat dashbordy, chceš-li historii a upozornění.
Pokud si stále nejste jistí, zda zvolit instanci GPU nebo se spolehnout jen na CPU, přečtěte si naše články o Co je GPU VPS? a GPU vs CPU VPS které popisují praktické rozdíly podle typu úlohy.
Jakmile je monitorování na dálku vyřešeno, zbývá jen vložit vše dohromady v podobě připravených konfigurací.
Připravené konfigurace pro každý typ uživatele
Tady jsou jednoduché konfigurace, které si můžete vzít a používat beze změny svého celého workflow. Jsou to skvělé výchozí body, které si později přizpůsobíte svým konkrétním potřebám.
- Tvůrce modelů (AI/ML): GPU monitoring software přes nvidia-smi nebo AMD SMI, plus jednoduchý CSV log a plus exportér/dashboard, pokud úlohy běží bez dozoru.
- Soutěžní hráč / Streamer: GPU monitoring software overlay přes Afterburner + RTSS, plus nástroj na zachycení doba snímku pro srovnání, plus minimální sada metrik na obrazovce.
- Uživatel pracovní stanice: GPU monitoring software přes HWiNFO logging, plus GPU-Z pro rychlé ověření identity, plus stress test jen když si zaznamenáte běh.
- Admin spravující stroje GPU: GPU monitoring software jako služba: exportér + dashboardy + upozornění, plus viditelnost jednotlivých procesů (nvtop) pro sdílené stroje.
Pokud si z tohoto průvodce vezmeš jen jednu věc, nech to být tohle: vyber GPU monitoring software podle toho, kde potřebuješ data (overlay, log, dashboard), a pak si udržuj sadu metrik dost malou, aby ses jí opravdu používal.