
At vælge en GPU VPS kan føles overvældende, når du stirrer på specifikationsark fyldt med tal. Kernetal springer fra 2.560 til 21.760, men hvad betyder det?
En CUDA-kerne er en parallel processeringsenhed inden i NVIDIA GPUs, som udfører tusindvis af beregninger samtidigt og dyrker alt fra AI-træning til 3D-rendering. Denne vejledning nedbryder, hvordan de fungerer, hvordan de adskiller sig fra CPU og Tensor-kerner, og hvilke kernetal der passer til dine behov uden at overbetale.
Hvad er CUDA-kerner?

CUDA-kerner er individuelle processeringsenheder inden i NVIDIA GPUs, som udfører instruktioner parallelt. Hvad er CUDA-kerneteknologi i sit grundlag? Tænk på disse enheder som små arbejdere, der tackler stykker af det samme job samtidigt.
NVIDIA introducerede CUDA (Compute Unified Device Architecture) i 2006 for at bruge GPU-kraft til generel computing ud over grafik. Den officielle CUDA-dokumentation giver omfattende tekniske detaljer. Hver enhed udfører grundlæggende aritmetiske operationer på decimaltal, perfekt til gentagne beregninger.
Moderne NVIDIA GPUs pakker tusindvis af disse enheder på en enkelt chip. Forbruger-GPUs fra den seneste generation indeholder over 21.000 kerner, mens datacenter GPUs baseret på Hopper-arkitekturen har op til 16.896. Disse enheder arbejder sammen gennem Streaming Multiprocessors (SMs).
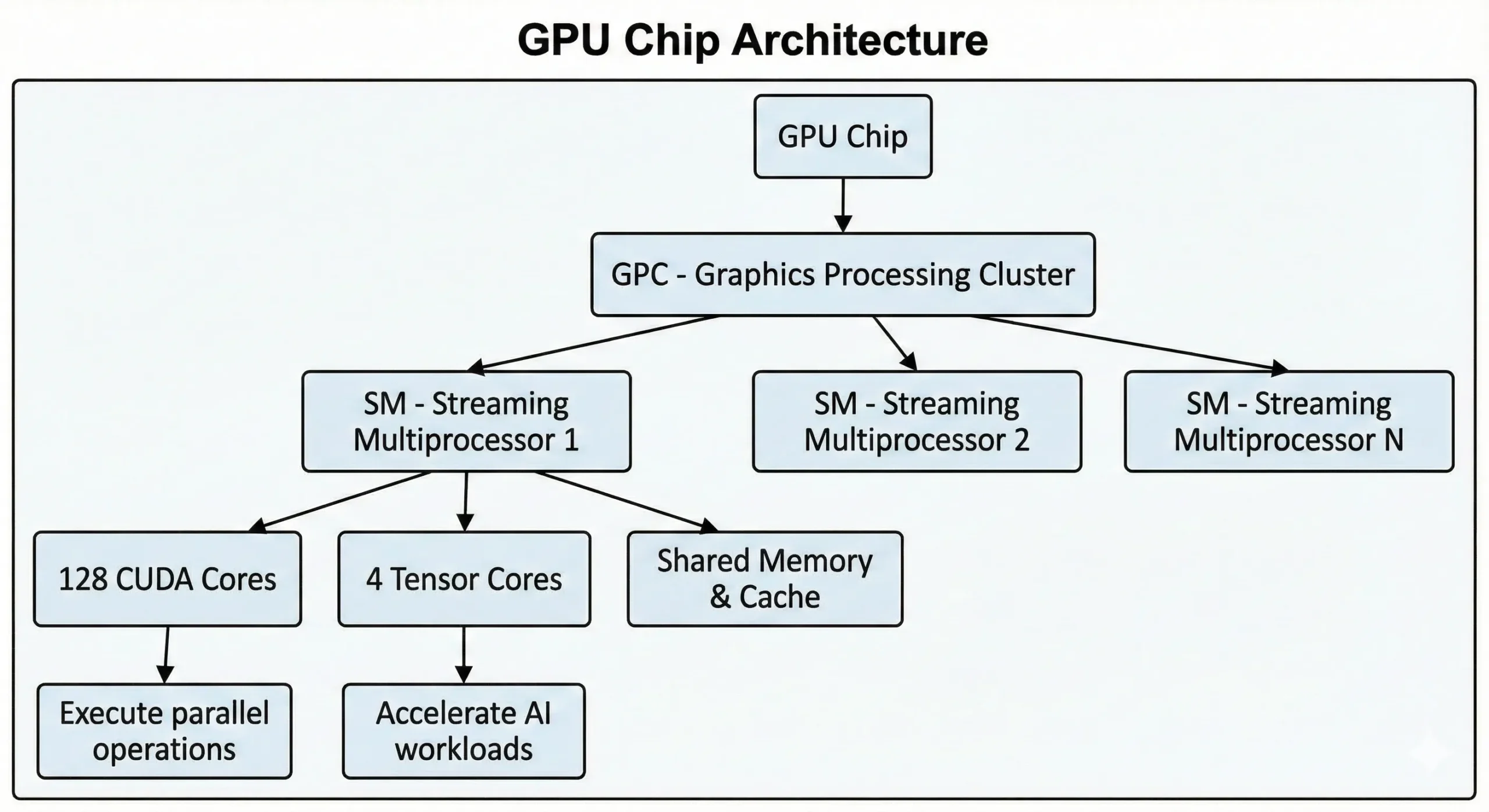
Enhederne udfører SIMT (Single Instruction, Multiple Threads)-operationer gennem parallelle computemetoder. En instruktion udføres på tværs af mange datapunkter på én gang. Når du træner neurale netværk eller rendrer 3D-scener, sker tusindvis af lignende operationer. De deler dette arbejde op i samtidige strømme og udfører det samtidigt i stedet for sekventielt.
CUDA-kerner vs CPU-kerner: Hvad gør dem forskellige?

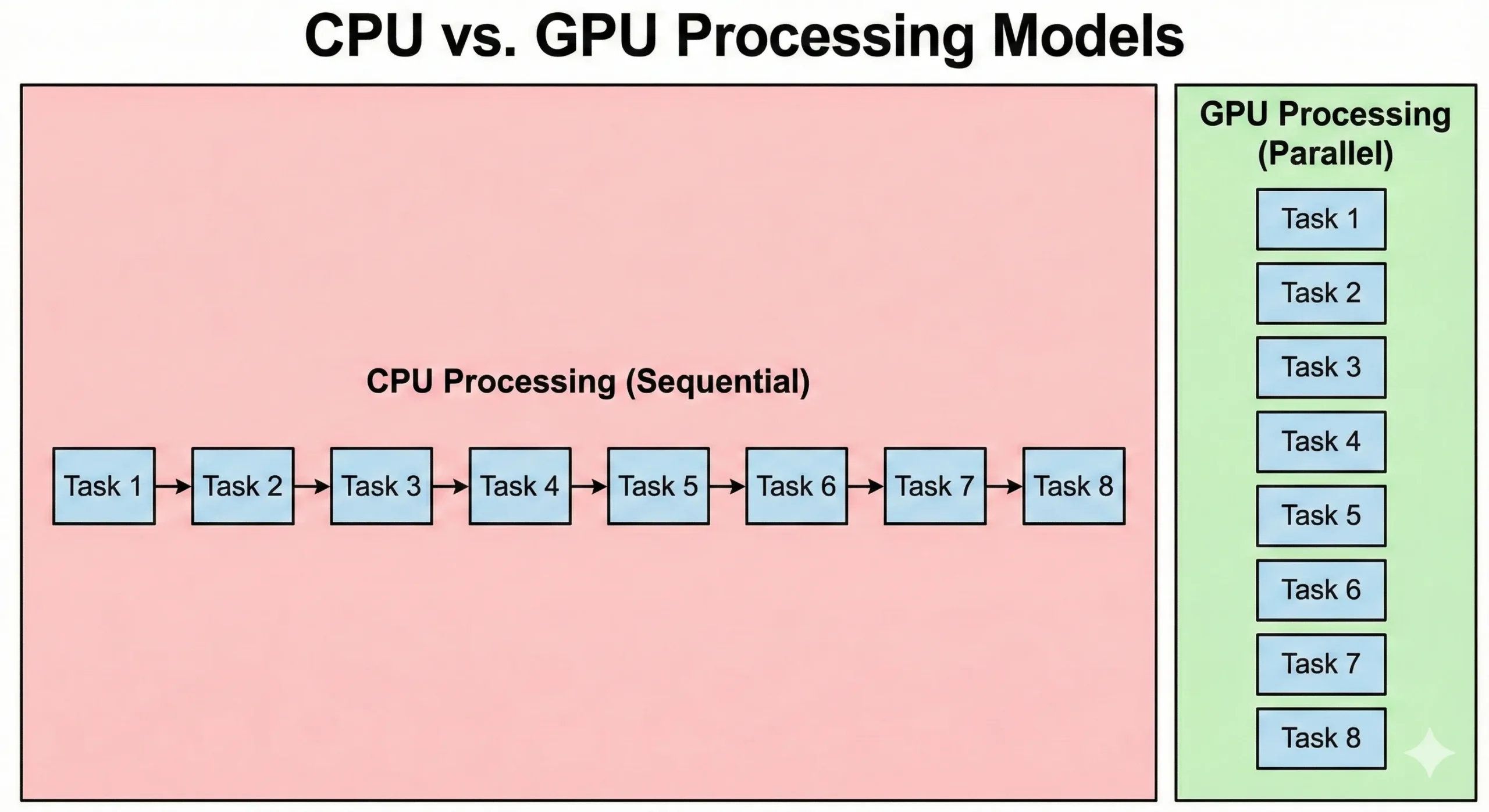
CPUs og GPUs løser problemer på fundamentalt forskellige måder. En moderne server CPU kan have 8-128+ kerner, der kører ved høje klokfrekvenser. Disse processorer er særligt gode til sekventielle operationer, hvor hvert trin afhænger af det tidligere resultat. De håndterer kompleks logik og forgrening effektivt.
GPUs vender denne tilgang om. De pakker tusindvis af enklere CUDA-kerner, der kører ved lavere klokfrekvenser. Disse enheder kompenserer for lavere hastigheder gennem parallelisme. Når 16.000 arbejder sammen, overstiger det samlede gennemløb standardkapaciteten for CPU.
CPUs udfører operativsystemkode og kompleks applikationslogik. Mens GPUs prioriterer gennemløb, resulterer overhead fra taskinitiering og synkronisering i højere latens. Parallel grafikbehandling prioriterer dataflytning. Selvom de tager længere tid at starte, behandler de store datasæt hurtigere end CPUs.
| Funktion | CPU-kerner | CUDA-kerner |
| Antal pr. chip | 4-128+ kerner | 2.560-21.760 kerner |
| Klokfrekvens | 3,0-5,5 GHz | 1,4-2,5 GHz |
| Behandlingsstil | Sekventielle, komplekse instruktioner | Parallelle, simple instruktioner |
| Bedst til | Operativsystemer, single-threaded opgaver | Matrixmatematik, parallel databehandling |
| Latency | Lav (mikrosekunder) | Højere (opstartsomkostninger) |
| Arkitektur | Generelt formål | Specialiseret til gentagne beregninger |
Virtual GPU (vGPU) og Multi-Instance GPU (MIG) teknologier håndterer ressourcepartitionering og planlægning for at distribuere processorer på tværs af flere brugere. Dette setup gør det muligt for teams at maksimere hardwareuudnyttelsen gennem enten tidsdelt deling eller dedikerede hardwareinstanser, afhængigt af konfigurationen.
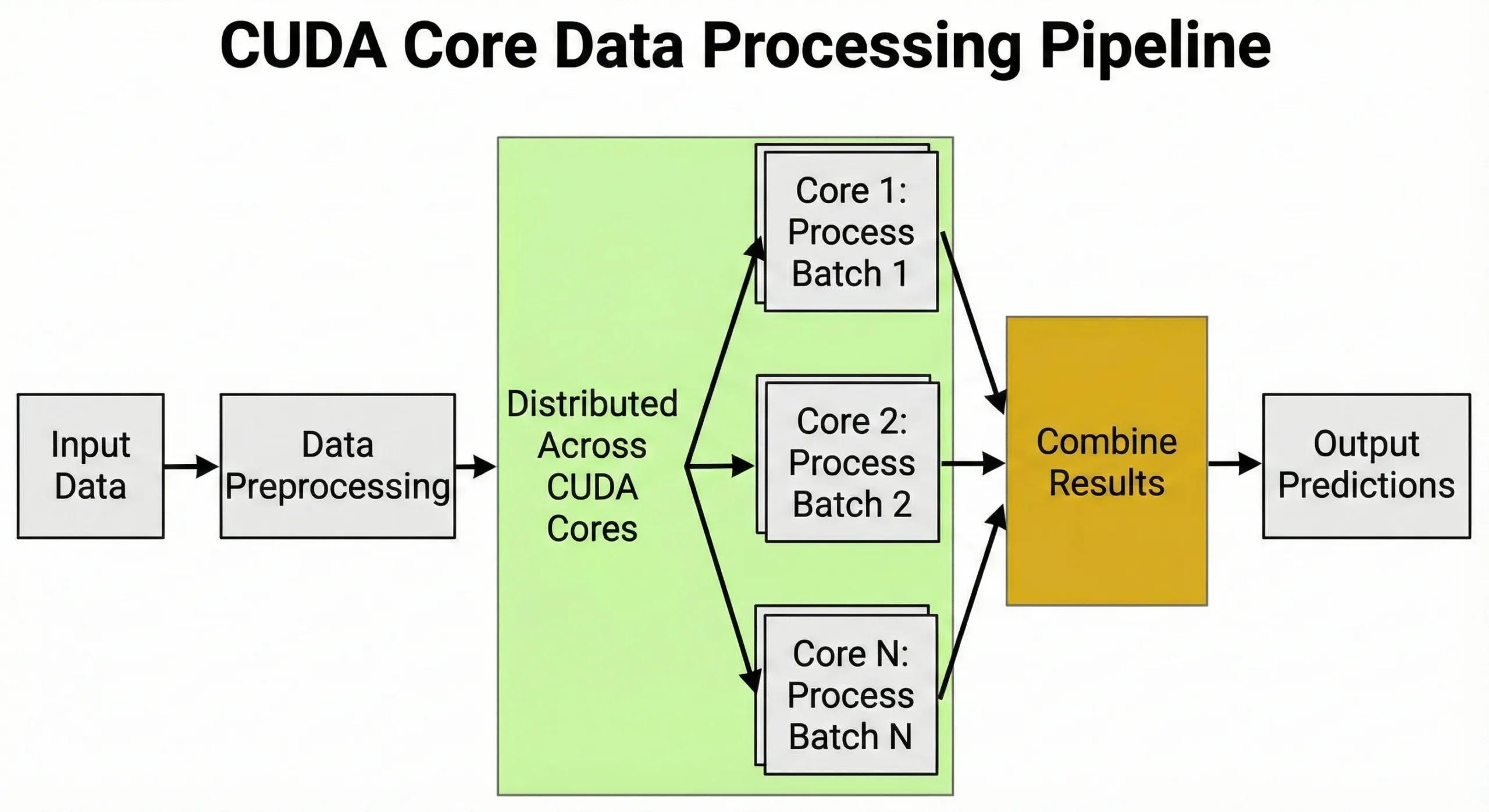
Træning af neurale netværk involverer milliarder af matrixmultiplikationer. En GPU med 10.000 enheder udfører ikke blot 10.000 operationer samtidigt; i stedet administrerer den tusinder af parallelle tråde grupperet i "warps" for at maksimere gennemstrømningen. Denne massive parallelisme er grunden til, at disse enheder er vigtige at forstå for AI-udviklere.
CUDA Cores vs Tensor Cores: Forstå forskellen

NVIDIA GPUs indeholder to specialiserede enhetstyper, der arbejder sammen: standard CUDA cores og Tensor cores. De er ikke konkurrerende teknologier; de adresserer forskellige dele af arbejdsbelastningen.
Standard enheder er almenpurpose-parallelle processorer, der håndterer FP32 og FP64-beregninger, heltalmatematik og koordinattransformationer. Denne grundlæggende CUDA-teknologi danner grundlaget for GPU-computing og kører alt fra fysiksimulatorer til dataforbehandling uden specialiseret acceleration.
Tensor cores er specialiserede enheder designet udelukkende til matrixmultiplikation og AI-opgaver. De blev introduceret i NVIDIAs Volta-arkitektur (2017) og glimrer ved FP16 og TF32-præcisionsberegninger. Den seneste generation understøtter FP8 for endnu hurtigere AI-slutning.
| Funktion | CUDA-kerner | Tensor-kerner |
| Formål | Generel parallel computing | Matrixmultiplikation til AI |
| Præcision | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Hastighed for AI | 1x baseline | 2-10x hurtigere end CUDA cores |
| Brugsscenarier | Dataforbehandling, traditionel ML | Deep learning træning/slutning |
| Tilgængelighed | Alle NVIDIA GPUs | RTX 20 serie og nyere, datacenter GPUs |
Moderne GPUs kombinerer begge. RTX 5090 har 21.760 standard enheder plus 680 femte-generations Tensor cores. H100 parrer 16.896 standard enheder med 528 fjerde-generations Tensor cores til deep learning acceleration.
Under træning af neurale netværk udfører Tensor cores det tunge arbejde under fremad- og tilbagegangspas gennem modellen. Standard enheder administrerer dataloading, dataforbehandling, tabbedberegninger og optimizer-opdateringer. Begge typer arbejder sammen, hvor Tensor cores accelererer beregningsmæssigt intensive operationer.
For traditionelle machine learning-algoritmer som random forests eller gradient boosting håndterer standard enheder arbejdet, da disse ikke bruger matrixmultiplikationsmønstre, som Tensor cores accelererer. Men for transformer-modeller og convolutional neural networks giver Tensor cores dramatiske hastighedsforbedringer.
Hvad bruges CUDA Cores til?

CUDA-kerner driver opgaver, der kræver mange identiske beregninger udført samtidigt. Alt arbejde, der involverer matrixoperationer eller gentagne numeriske beregninger, drager fordel af deres arkitektur.
AI og Machine Learning-applikationer
Deep learning baserer sig på matrixmultiplikationer under træning og inferens. Når du træner neurale netværk, kræver hvert fremadgående pass millioner af multiply-add-operationer på tværs af vægtmatricer. Backpropagation tilføjer millioner mere under det bagudgående pass.
Enheder håndterer dataforbehandling, konverterer billeder til tensorer, normaliserer værdier og anvender augmentationstransformationer. Denne evne til at håndtere tusindvis af opgaver samtidigt er præcis grunden til, at GPUs er vigtige for AI.
Under træning håndterer de indlæringshastigheder, gradientberegninger og optimizer-tilstandsopdateringer.
For VPS til AI-inferensoperationer, der kører anbefalingssystemer eller chatbots, behandler de anmodninger samtidigt og udfører hundredvis af forudsigelser på én gang. Vores guide om bedste GPU til AI 2025 dækker hvilke konfigurationer, der fungerer for forskellige modelstørrelser.
H100s 16.896 enheder kombineret med Tensor-kerner træner en 7-milliard-parameters-model på få uger i stedet for måneder. Realtidsinferen til chatbots, der betjener tusindvis af brugere, kræver tilsvarende samtid udførelsesstyrke.
Videnskabelig databehandling og forskning
Forskere bruger disse processorer til molekylær dynamik-simuleringer, klimamodellering og genomik-analyse. Hver beregning er uafhængig, hvilket gør dem ideelle til samtidig udførelse. Finansielle institutioner kører Monte Carlo-simuleringer med millioner af scenarier samtidigt.
3D-rendering og videoproduktion
Ray tracing beregner lys, der hopper gennem 3D-scener ved at spore uafhængige stråler gennem hver pixel. Mens dedikerede RT-kerner håndterer traversering, administrerer standard-enheder tekstursampling og belysning. Denne opdeling bestemmer hastigheden af scener med millioner af stråler.
NVENC håndterer kodning til H.264 og H.265, mens de seneste arkitekturer (Ada Lovelace og Hopper) introducerer hardwaresupport til AV1. CUDA hjælper med effekter, filtre, skalering, denoising, farvetransformationer og pipeline-klæbemiddel. Dette giver kodningsmotoren mulighed for at arbejde sammen med parallelle processorer til hurtigere videoproduktion.
3D-rendering i Blender eller Maya fordeler milliarder af overfladeshadingberegninger på tværs af tilgængelige enheder. Partikelsystemer drager fordel, da de simulerer tusindvis af partikler, der interagerer på én gang. Disse funktioner er nøglen til avanceret digital kreativitet.
Hvordan CUDA-kerner påvirker GPU-ydeevne

Kernetal giver dig et groft billede af samtid udførelsesevne, men CUDA-kerner kræver, at man kigger ud over tallene. Klokfrekvens, hukommelsesbredde, arkitekturefektivitet og softwareoptimering spiller alle vigtige roller.
En GPU med 10.000 enheder, der kører ved 2,0 GHz, leverer forskellige resultater end en med 10.000 ved 1,5 GHz. Højere klokfrekvens betyder, at hver enhed fuldfører flere beregninger pr. sekund. Nyere arkitekturer packer mere arbejde ind i hver cyklus gennem bedre instruksplanificering.
Kontrollér, om du holder enheden travl, men husk på at nvidia-smi udnyttelse er en grov metrik. Den måler den procentdel tid, en kernel er aktiv, ikke hvor mange kerner, der udfører arbejde.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderEksempel på output: 85 %, 92 % (85 % tidspunkt aktivt, 92 % hukommelseskontrolleraktivitet)
Hvis din GPU viser 60-70 % udnyttelse, har du sandsynligvis opstemmeflaskehalse som CPU-dataloading eller små batchstørrelser. Men selv 100 % udnyttelse kan være vildledende, hvis dine kernels er hukommelsesbound eller enkelttrået. For et sandt billede af kernemetning skal du bruge profilers som Nsight Systems til at spore "SM Efficiency" eller "SM Active" metrikker.
Hukommelsesbåndbredde bliver ofte flaskehals før beregningskapaciteten makseres. Hvis din GPU behandler data hurtigere, end hukommelsen forsyner det, sidder enhederne uvirksomme. H100 SXM5-modellen bruger 3,35 TB/s båndbredde til at forsyningsstrømme sine 16.896 kerner. PCIe-versionen reducerer dette til 2 TB/s.
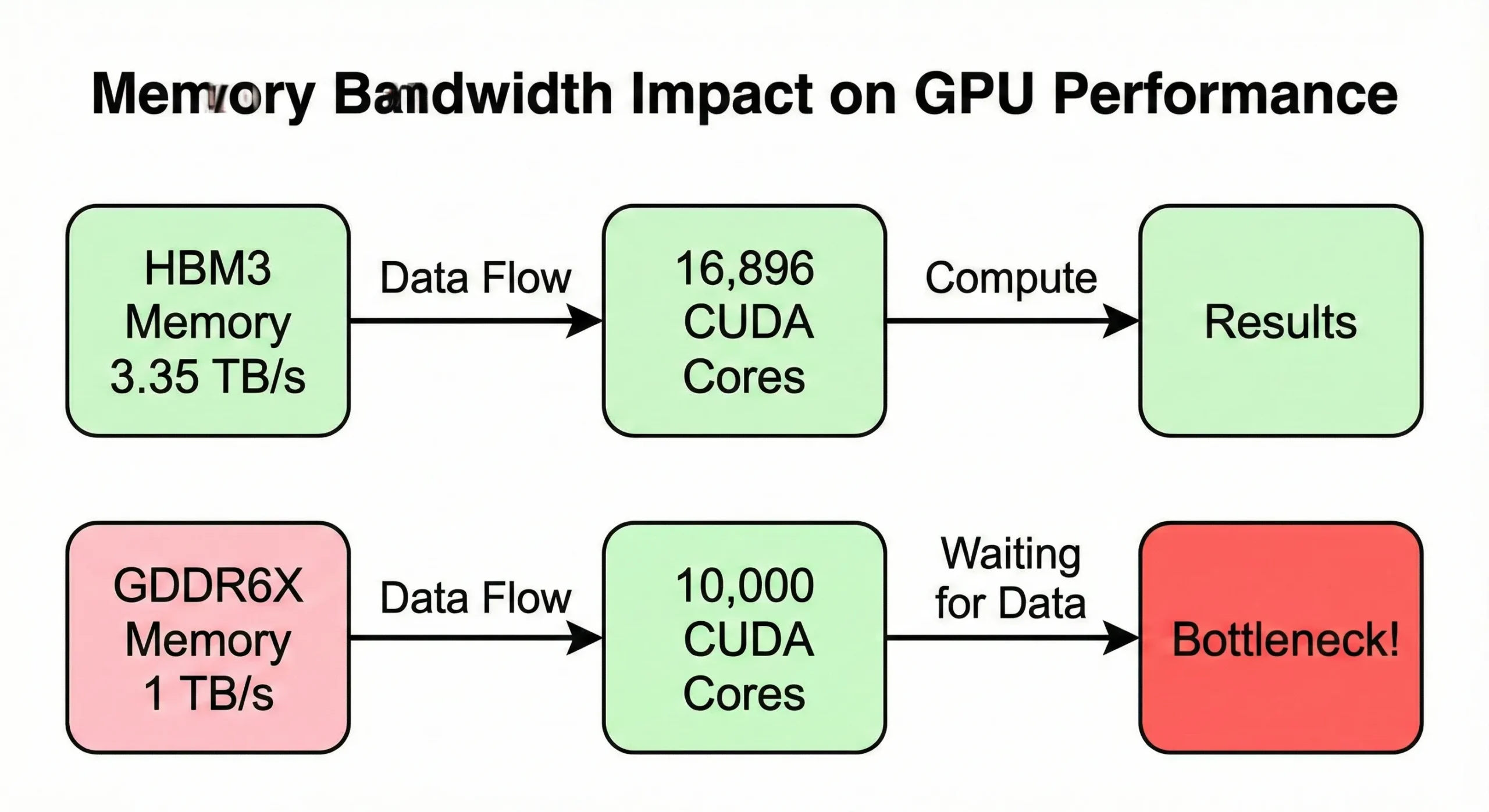
Consumer GPUs med lignende kernetal, men lavere båndbredde (omkring 1 TB/s), viser reduceret real-world hastighed ved hukommelseskrævende operationer.
VRAM-kapacitet bestemmer størrelsen på dine opgaver. Hvad enten det er FP16-vægte for en 70B modelkræver fuld træning mere hukommelse. Du skal tage højde for gradienter og optimizer-states. Disse states tredobler ofte pladsforbruget, medmindre du bruger offload-strategier
A100 med 80GB sigter mod høj-throughput-inferens og fine-tuning. Samtidig kan 24GB RTX 4090, som ofte nævnes til 7B-modeller, overraskende nok køre 30B+ parameter-modeller, hvis du bruger moderne kvantiseringsteknikker som INT4. Men når VRAM løber tør, tvinger det CPU-GPU dataoverførsler, der ødelægger throughput.
Softwareoptimering afgør, om din kode faktisk bruger alle disse enheder. Dårligt skrevne kernels engagerer måske kun en brøkdel af de tilgængelige ressourcer. Biblioteker som cuDNN til deep learning og RAPIDS til datascience er tuneret kraftigt for at maksimere udnyttelsen.
Flere CUDA-kerner betyder ikke altid bedre performance

At købe en GPU med det højeste kernetal virker logisk, men du spilder penge, hvis enhederne overtager andre systemkomponenter, eller hvis din opgave ikke skaleres med kernetal.
Hukommelsesbåndbredde skaber den første grænse. RTX 5090's 21.760 enheder forsynes af 1.792 GB/s hukommelsesbåndbredde. Ældre GPUs med færre enheder har måske forholdsmæssigt højere båndbredde pr. enhed.
Arkitekturforskelle betyder noget. En nyere GPU med 14.000 enheder ved 2,2 GHz ydermere en ældre GPU med 16.000 ved 1,8 GHz takket være bedre instruktioner pr. ur. Din kode skal have ordentlig parallelisering for at bruge 20.000 enheder effektivt.
Hvorfor CUDA-kerner betyder noget når du vælger GPU VPS

At vælge den rigtige CUDA-kernel GPU-konfiguration til din VPS forhindrer spild af penge på ubrugte ressourcer eller at ramme flaskehalse midt i projektet.
H100's 80GB hukommelse håndterer inferens for 70B parameter-modeller ved 4-bit kvantisering. Til fuld træning er 80GB dog ofte utilstrækkeligt til en 34B-model, når du tager højde for gradienter og optimizer-states. Ved FP16-træning udvides hukommelsesforbruget markant, hvilket ofte kræver multi-GPU sharding.
Inferensoperationer, der udfører real-time forudsigelser, har brug for færre enheder, men drager fordel af lav latency. Udviklings- og prototypingsarbejde fungerer fint med mellemklasse GPUs til at teste algoritmer og fejlsøge kode.
En RTX 4060 Ti med 4.352 enheder lader dig teste uden at betale for overkill-hardware. Når du validerer din tilgang, skaler op til production GPUs for fuld træningskørsler.
Rendering og videoarbejde skaleres med enheder op til et vist punkt. Blender's Cycles-renderer bruger alle tilgængelige ressourcer effektivt. En GPU med 8.000-10.000 enheder renderer scener 2-3 gange hurtigere end en med 4.000.
På Cloudzy tilbyder vi højtydende GPU-VPS hosting bygget til tungt arbejde. Vælg RTX 5090 eller RTX 4090 til hurtig rendering og omkostningseffektiv AI-inferens, eller skaler op til A100s til massive deep learning-arbejdsbelastninger. Alle planer kører på et 40 Gbps netværk med privacy-first-politikker og cryptocurrency-betalingsmuligheder, der giver dig råkraft uden bypasset.
Det være sig træning af AI-modeller, rendering af 3D-scener eller køring af videnskabelige simuleringer, du vælger kernetal, der passer til dine behov.
Budgetovervejelser betyder noget. En A100 med 6.912 enheder koster markant mindre end en H100 med 16.896. For mange operationer giver to A100s et bedre pris-til-hastighed forhold end en H100. Break-even-punktet afhænger af, om din kode skaleres på tværs af flere GPUs.
Sådan vælger du det rigtige antal CUDA-kerner
Tilpas dine krav til faktiske arbejdsbelastningskarakteristika i stedet for at jage de højeste tal på markedet.
Start med at profilere dit nuværende arbejde. Hvis du træner modeller på lokal hardware eller cloud-instanser, skal du tjekke GPU-udnyttelsesmålinger. Hvis din nuværende GPU viser 60-70% udnyttelse konsistent, maksimerer du ikke enhederne.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Dette simple benchmarktest viser, om dine GPU-kerner leverer den forventede gennemstrømning. Sammenlign dine resultater med offentliggjorte benchmarks for din GPU-model.
En opgradering hjælper ikke. Du skal først håndtere flaskehalse som hukommelse, båndbredde eller CPU-ventetid. Estimér hukommelseskrav efterfølgende ved at beregne modelstørrelse i bytes plus aktiveringshukommelse.
Læg batch-størrelse gange lag-output til og inkluder optimeringstilstande. Denne sum skal passe i VRAM. Når du ved, hvilken hukommelse der skal til, kan du kontrollere, hvilke GPU'er der opfylder den grænse.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Overhold din tidslinje. Hvis du har brug for resultater på timer, betaler du for flere enheder. Træningskørsler, der kan tage dage, fungerer fint på mindre GPU'er med proportionalt længere gennemførelsestider.
Omkostning pr. time gange timer nødvendig giver samlede omkostninger, hvilket nogle gange gør langsommere GPU'er billigere samlet set. Test skaleringseffektivitet ved hjælp af mange frameworks, som giver benchmarkværktøjer, der viser gennemstrømningsændringer.
Hvis fordobling af enheder kun giver 1,5x hastighedsforbedring, er de ekstra udgifter ikke værd. Find de optimale punkter, hvor pris-til-hastighed-forholdet er bedst.
| Arbejdsbelastningstype | Anbefalede Kerner | Eksempel-GPU'er | Bemærkninger |
| Modeludvikling og fejlfinding | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Hurtig iteration, lavere omkostninger |
| Småskalatræning af AI (<7B parametre) | 6,000-10,000 | RTX 4090, L40S | Passer til forbruger- og små virksomheder |
| Storstilettræning af AI (7B-70B parametre) | 14,000+ | A100, H100 | Kræver datacenter GPU'er |
| Realtidskonklusion (høj gennemstrømning) | 10,000-16,000 | RTX 5080, L40 | Balance omkostninger og ydeevne |
| 3D-gengivelse og videoenkodning | 8,000-12,000 | RTX 4080, RTX 4090 | Skaleres med kompleksitet |
| Videnskabeligt computing og HPC | 10,000+ | A100, H100 | Kræver FP64-understøttelse |
Populære VPS GPU-modeller og deres CUDA-kernetal

Forskellige GPU-niveauer tjener forskellige brugersegmenter. Hvad er GPUaaS? Det er GPU-as-a-Service, hvor udbydere som Cloudzy tilbyder on-demand-adgang til disse kraftfulde NVIDIA GPU'er uden at du skal købe og vedligeholde fysisk hardware selv.
| GPU-model | CUDA-kerner | VRAM | Hukommelsesbåndbredde | Arkitektur | Bedst til |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Avanceret arbejdsstation, 8K-gengivelse |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | Avanceret AI, 4K-gengivelse |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/s | Hopper | Storskalapraktisk AI-træning |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | Enterprise AI, omkostningseffektivt datacenter |
| A100 | 6,912 | 40/80GB HBM2e | 1.555–2.039 GB/s | Ampere | Mid-range AI, pålidelig ydeevne |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming, mid-range AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Multi-arbejdsbelastning datacenter |
Consumer RTX-kort (4070, 4080, 4090, 5080, 5090) henvender sig til kreative og gamere, men fungerer godt til AI-udvikling. De leverer stærk enkeltenkerne-ydeevne til lavere priser end datacenterkort.
VPS-udbydere har ofte disse på lager til omkostningsbevidste brugere. Datacenterkort (A100, H100, L40) prioriterer pålidelighed, ECC-hukommelse og multi-enkeltenkerne-skalering. De håndterer 24/7-drift og understøtter avancerede funktioner.
Multi-Instance GPU (MIG) lader dig partitionere ét GPU i flere isolerede instanser. A100 forbliver populær på trods af nyere alternativer på grund af dets velafbalancerede specifikationer.
Kombinationen af NVIDIA-kerner, hukommelse og pris gør det til det sikre valg for de fleste produktions-AI-operationer. H100 tilbyder 2,4 gange flere enheder, men koster betydeligt mere.
Konklusion
Parallelle processormotorer muliggør moderne AI, rendering og videnskabelig computing. Hvordan de virker og interagerer med hukommelse, klokkefrekvens og software hjælper dig med at vælge GPU VPS-konfigurationer.
Flere enheder hjælper når dit arbejde paralleliseres effektivt, og komponenter som hukommelsesbåndbredde holder trit. Men at jage det højeste kerneantal uden grund spilder penge, hvis dine flaskehalse ligger andre steder.
Start med at profilere dine faktiske operationer, identificere hvor tiden går hen, og matches GPU-specifikationer til disse krav uden at købe unødvendig kapacitet.
For det meste AI-udvikling giver 6.000-10.000 enheder det bedste forhold mellem omkostning og muligheder. Produktionsdrift med træning af store modeller eller højtgennemstrøms-inferens drager fordel af 14.000+ enheder i GPU som H100.
Rendering og videoarbejde skaleres effektivt med enheder op til omkring 16.000, hvorefter hukommelsesbåndbredde bliver den begrænsende faktor.


