Mehr als 178.000 GitHub-Nutzer haben eine einzige Markdown-Datei mit einem Stern versehen. Die Datei sagt einer KI lediglich, wie sie sich verhalten soll.
Vier Regeln: Think Before Coding. Simplicity First. Surgical Changes. Goal-Driven Execution. Das war's. Keine Bibliothek. Kein Framework. Kein Installer. Forrest Chang verpackte Andrej Karpathys Beobachtungen über die Fehlermuster von LLMs beim Coden in eine einzige CLAUDE.md-Datei, und die Entwickler-Community trieb sie in den Folgemonaten über 178.000 GitHub-Sterne hinaus.
Wenn man genau hinschaut, was dort passiert ist, sieht es stark danach aus, was jede Engineering-Organisation irgendwann, nach genug Schmerz, als nötig erkannt hat: ein gemeinsames Set von Beschränkungen dafür, wie Code geschrieben wird. Eine Regelschicht. Die Art von Sache, die früher in einer Code-Review-Checkliste lebte, oder in einem Style Guide, oder im institutionellen Gedächtnis eines erfahrenen Entwicklers. Die Vibe-Coding-Community fand eine viel leichtere Version derselben Disziplin: die Regeln in Markdown aufschreiben und den Agenten sie lesen lassen, bevor er Code schreibt.
Das ist kein Einzelfall. Es ist ein Muster.
Kurzfassung
- Das Ökosystem der Agenten-Anweisungen (CLAUDE.md, AGENTS.md, geteilte Skills-Bibliotheken und Accessibility-Agenten) wird zu einer verteilten Schicht für die Qualitätsdurchsetzung beim KI-unterstützten Coden.
- Die Qualitätslücke, auf die es reagiert, ist real: Snyk scannte 3.984 Skills von ClawHub und skills.sh und fand, dass 1.467, also 36,82 %, mindestens einen Sicherheitsmangel hatten; 534, also 13,4 %, hatten mindestens ein kritisches Problem.
- Die Antwort der Community bestand darin, mehr Regeln zu bauen, nicht den Ansatz aufzugeben, und Institutionen von Vercel über OWASP bis zur Linux Foundation sind nun beteiligt.
Die Qualitätslücke ist real, und die Community weiß es

13,4 % der Community-Skills-Dateien enthalten kritische Sicherheitsmängel. Das stammt aus Snyks ToxicSkills-Bericht, veröffentlicht im Februar 2026 nach dem Scannen von 3.984 Skills von ClawHub und skills.sh. 36,82 % hatten mindestens eine Sicherheitslücke. 76 waren rundweg bösartig, wobei 91 % davon Prompt Injection als Liefermechanismus nutzten.
Die umfassendere Geschichte zur KI-Code-Qualität ist ähnlich. Laut CodeRabbits Analyse von Code-Review-Daten weist KI-unterstützter Code durchschnittlich 10,83 Probleme pro Pull Request auf, gegenüber 6,45 bei von Menschen geschriebenem Code, also ungefähr 1,7-mal mehr Probleme. GitClears jährliche Code-Studie berichtete von einem, wie sie es nennt, „4-fachen Wachstum" beim Klonen von Code: ein Anstieg von 8,3 % auf 12,3 % der geänderten Zeilen zwischen 2021 und 2024.
Das sind Anbieterzahlen, nehmen Sie die Präzision also mit angemessener Skepsis. Dennoch sind sie der Richtung nach nützlich: KI-unterstütztes Coden erzeugt genug Qualitätsdruck, dass Entwickler neue Leitplanken darum herum bauen.
Worauf es ankommt, ist, was die Community mit dieser Information gemacht hat. Die Antwort war nicht „Skills-Dateien sind gefährlich, hört auf, sie zu verwenden". Sie war: OWASP startete die Agentic Skills Top 10 (AST10), das Skills-Ökosystem-Äquivalent zur Web Application Security Top 10. Mehr Regeln. Mehr Struktur. Ein formales Sicherheits-Framework für ein informelles Ökosystem.
Das ist eine klassische Engineering-Antwort, selbst von einer Community, die oft versucht, schwergewichtige Prozesse zu vermeiden.
Das Ökosystem, das auftauchte

Über die erste Hälfte von 2026 begann das weniger wie eine Handvoll isolierter Markdown-Dateien auszusehen und mehr wie ein geschichtetes Ökosystem.
Beginnen Sie mit der Verhaltensschicht. Die von Karpathy inspirierte CLAUDE.md verpackt Forrest Changs Version von Andrej Karpathys Beobachtungen zu den Fehlermustern von LLMs beim Coden in eine einzige Anweisungsdatei, und sie steht jetzt bei mehr als 178.000 GitHub-Sternen, eines der am häufigsten mit Sternen versehenen Repositories der GitHub-Geschichte, für eine Datei, die um vier einfache Regeln herum gebaut ist. Was diese Regeln sind, ist weniger interessant als das, wofür sie stehen: ein Versuch, das Urteilsvermögen zu kodieren, das ein erfahrener Entwickler im Code-Review anwenden würde.
Darüber sitzt eine Community-Aggregationsschicht. Antigravity Awesome Skills hat 1.595+ agentische Skills überschritten und sammelt wiederverwendbare Playbooks für Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity und andere KI-Coding-Assistenten. Es funktioniert wie eine sich schnell bewegende geteilte Bibliothek für den Bereich: die Art von Sache, die ein Standardisierungsgremium produzieren könnte, wenn es sich durch GitHub statt durch PDFs bewegte.
Dann tauchten die Frameworks auf. Vercel machte vercel-labs/agent-skills zu einem offiziellen Organisations-Repository, jetzt bei 28.000 Sternen. Allein die React-Best-Practices-Skill enthält 40+ Regeln über acht performanceorientierte Kategorien, darunter Waterfalls, Bundle-Größe, serverseitige Performance, clientseitiges Daten-Fetching, Re-Render-Optimierung, Rendering-Performance und JavaScript-Mikro-Optimierungen. Wenn das Unternehmen, dem Ihre Deployment-Plattform gehört, offizielle Qualitätsregeln für KI-Agenten ausliefert, ist das Ökosystem vom Community-Experiment zur Produktionsinfrastruktur aufgestiegen.
Und ganz oben eine Standardschicht. OpenAI spendete die AGENTS.md-Spezifikation an die Agentic AI Foundation (AAIF) der Linux Foundation, neben MCP (Anthropic) und Goose (Block): toolübergreifend, agentenübergreifend, auf dem Standardisierungsweg. Die Richtung geht zur Portabilität: AGENTS.md gibt Teams einen gemeinsamen Ort für projektspezifische Agentenanleitung, auch wenn einzelne Tools sich noch darin unterscheiden mögen, wie sie diese Anweisungen laden und anwenden.
Diese Teile tauchten nicht als ein zentral geplanter Stack auf. Sie konvergierten, weil die Nachfrage real war.
Die Dimension, über die niemand spricht
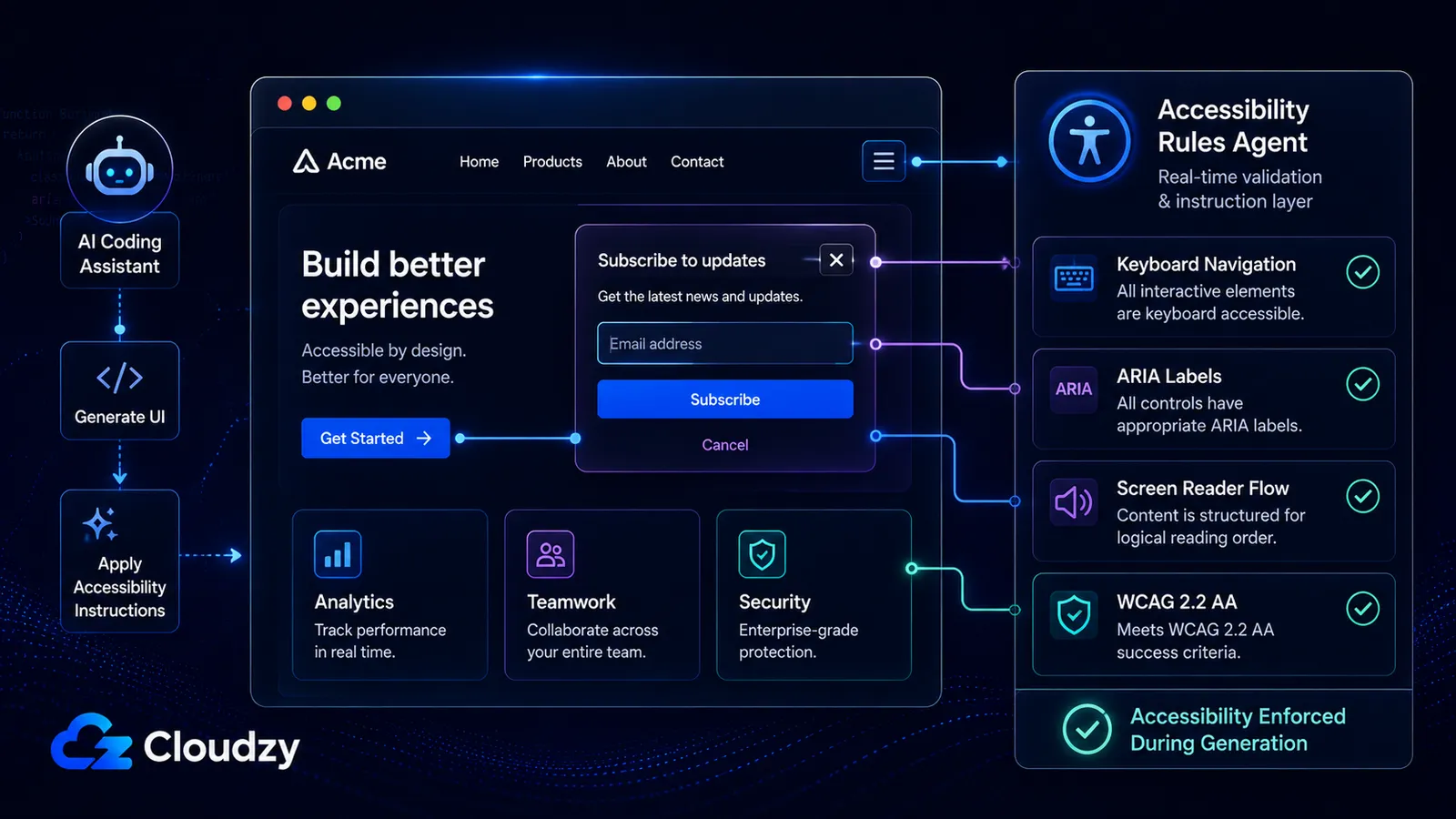
Die Daten zu Sicherheit und Code-Qualität bekommen Aufmerksamkeit. Die Accessibility-Dimension fast nie.
Community-Access/accessibility-agents startete am 21. Februar 2026 mit sechs Agenten. Stand Juni 2026: 79 spezialisierte Agenten über acht Teams, 18 wiederverwendbare Accessibility-Skills, Ausrichtung auf WCAG 2.2 AA und Unterstützung über fünf Plattformen: Claude Code, GitHub Copilot, Gemini CLI, Codex CLI und einen MCP Server, der MCP-kompatible Clients bedienen kann.
Was dieses Projekt im Klartext ist: eine Community von Entwicklern entschied, dass KI-Coding-Tools standardmäßig nicht barrierefreien Code erzeugen (sie überspringen ARIA-Regeln, ignorieren Tastaturnavigation, produzieren Modals, die Screenreader einsperren) und baute 79 spezialisierte Agenten, um die Regeln durchzusetzen, die die KI immer wieder vergisst.
Das ist eine bemerkenswerte Sache. Frontend-Entwickler haben bei Accessibility historisch zu wenig geliefert. Es ist das Erste, was unter Termindruck gestrichen wird. Das accessibility-agents-Projekt sind Vibe Coder, die die Regeln schreiben, für deren Durchsetzung sie sonst einen erfahrenen Entwickler bräuchten, und das öffentlich, kostenlos, über fünf unterstützte Integrationen hinweg.
Nach meiner Lesart ist das Projekt für eine ehrenamtliche Accessibility-Initiative ungewöhnlich gründlich, vor allem weil es Accessibility von einem späten QA-Anliegen in wiederverwendbare Agentenanweisungen verwandelt, die während der Code-Generierung laufen.
Warum das unvermeidlich war
Das Argument, dass „Skills-Dateien einfach READMEs für KI sind", ist fair, wenn man eine einzelne Datei betrachtet. Es hält nicht mehr stand, wenn man OWASP betrachtet, das ein Sicherheits-Framework für das Ökosystem startet, Vercel, das eine offizielle Qualitätsbibliothek ausliefert, oder ein ehrenamtliches Accessibility-Projekt, das zu 79 spezialisierten Agenten heranwächst.
Hier ist, was tatsächlich passiert: Qualitätsdurchsetzung verschwindet nicht, wenn man Prozesse entfernt. Sie taucht in einer anderen Form wieder auf, weil das Fehlen von Qualität schnell Schmerz erzeugt, und die Person, die diesem Schmerz am nächsten ist, behebt ihn an der Quelle.
Traditionelle Engineering-Disziplin (Code-Review, Style Guides, QA-Gates, architektonische Governance) existiert, um abzufangen, was einzelne Entwickler unter Zeitdruck überspringen. Sie funktioniert, wenn man ein Team und einen Prozess hat. Vibe Coder haben von Natur aus oft weder noch. Also haben sie das Review in den Anweisungen des Agenten vorkodiert.
CLAUDE.md ist vorkodiertes Code-Review. Awesome Skills ist ein verteilter Style Guide. AGENTS.md ist ein Governance-Standard. Die Worte änderten sich. Die Funktion nicht.
Interessant ist nicht, dass die Beschränkungen wieder auftauchten, das war unvermeidlich. Interessant ist, dass sie schneller wieder auftauchten als beim ersten Mal, und öffentlicher, und auf einem Qualitätsniveau, das manche Engineering-Organisationen mit ausgereiften Prozessen beschämt.
Die Vibe-Coding-Community hat Engineering-Disziplin nicht widerwillig neu erfunden, unter Druck des Managements. Sie hat sie gebaut, weil sie an eine Wand stießen und die Werkzeuge, um es zu beheben, nur eine Markdown-Datei entfernt waren.
Häufig gestellte Fragen
Was kommt in eine CLAUDE.md-Datei?
Verhaltensbeschränkungen für die KI: was zu vermeiden ist, was zu priorisieren ist, architektonische Regeln, Sicherheits-Warnsignale und projektspezifische Konventionen. Qualitätsorientierte Nutzung geht über Workflow-Abkürzungen hinaus: Regeln wie „niemals Fehlerbehandlung entfernen, um Tests bestehen zu lassen" stehen neben „immer TypeScript verwenden". Für echte, erprobte Beispiele beginnen Sie mit der Awesome-Skills-Community-Aggregation. Vercels agent-skills ist eine weitere starke Referenz.
Was ist AGENTS.md und wie unterscheidet es sich von CLAUDE.md?
AGENTS.md ist ein universeller Standard für projektspezifische Agentenanleitung, veröffentlicht von OpenAI und im Dezember 2025 an die Agentic AI Foundation der Linux Foundation beigesteuert. CLAUDE.md ist die Projektanleitungsdatei von Claude Code. Sie überschneiden sich im Zweck, aber sie sind nicht in jedem Tool identische Formate. Die praktische Erkenntnis ist, dass Teams Agentenanweisungen zunehmend einmal schreiben und über Tools wie Codex, Cursor, Copilot, Gemini CLI und Claude Code hinweg anpassen können.
Sind Skills-Dateien sicher zu verwenden?
Aus der Community stammende Skills sollten vor dem Importieren gelesen werden. Snyks ToxicSkills-Bericht fand, dass 36 % der gescannten Community-Skills mindestens einen Sicherheitsmangel hatten und 13,4 % kritische Mängel, mit Prompt Injection als primärem Angriffsmechanismus. Die OWASP Agentic Skills Top 10 ist das Referenz-Framework, um die Angriffsfläche zu verstehen. Skills-Dateien aus offiziellen Repositories oder etablierten Open-Source-Projekten tragen im Allgemeinen ein geringeres Lieferketten-Risiko als anonyme Community-Beiträge, sollten aber trotzdem vor dem Import geprüft werden.
Was ist die OWASP Agentic Skills Top 10 (AST10)?
OWASPs Sicherheits-Framework von 2026 für das Skills-Ökosystem, analog zur OWASP Web Application Security Top 10, aber speziell auf die Angriffsfläche ausgerichtet, die durch KI-Agenten-Anweisungsdateien entsteht. Es deckt die zehn kritischsten Sicherheitsrisiken über Plattformen hinweg ab, darunter Claude Code, Cursor/Codex und VS Code. Das Framework befindet sich Stand 2026 in aktiver Entwicklung, mit einem für Q4 2026 geplanten v1.0-Release.
Brauche ich Skills-Dateien, wenn ich ein privates Projekt baue?
Nur wenn Sie konsistentes KI-Verhalten wollen. Ohne Beschränkungen optimieren KI-Coding-Tools auf Aufgabenabschluss, nicht auf Code-Qualität, was gut funktioniert, bis es duplizierte Logik, fehlende Fehlerbehandlung oder nicht barrierefreie UI-Komponenten produziert. Der Aufwand ist gering: eine Datei pro Projekt, gepflegt, während Sie entdecken, was die KI immer wieder falsch macht. Die von Karpathy inspirierten Regeln sind ein vernünftiger Ausgangspunkt; die Community-Skills-Bibliotheken lassen Sie domänenspezifische Regeln (Sicherheit, Accessibility, Sprach-Idiome) einbinden, ohne sie von Grund auf zu schreiben.