
Ersetze GPT-5 durch Claude in einem funktionierenden Agenten und meistens ändert sich kaum etwas. Ändere, wie er mit Wiederholungsversuchen umgeht, was du in sein Kontextfenster einspeist oder wann er entscheidet aufzuhören, und der gesamte Agent verhält sich anders. Diese Lücke ist das Zeichen: Das Modell ist der kleinste und am leichtesten austauschbare Teil eines funktionierenden Agenten. Die interessante Technik steckt in allem, was darum herum gebaut ist.
Dieser Wrapper hat jetzt einen Namen. Praktiker einigten sich auf "Harness" für die Schicht, die einen Textgenerator in etwas verwandelt, das im Laufe der Zeit Aktionen ausführt, anstatt ein festes Skript abzuarbeiten. Der Begriff verbreitete sich Anfang 2026 schnell auf Twitter und in Engineering-Blogs, was auch bedeutet, dass er unpräzise verwendet wurde, wobei dasselbe Wort in jedem Beitrag eine leicht andere Bedeutung hatte. Dieser Artikel klärt es: Was ein Harness ist, woraus er besteht, wie er sich von einem "Framework" und einem "Scaffold" unterscheidet, und warum die meiste Qualität deines Agenten im Harness steckt, nicht im Modell.
Die Kurzfassung
- Ein Agent-Harness ist die Software um ein LLM herum, die die Ausführungsschleife, Werkzeuge, Speicher, Kontext, Zustand, Fehlerbehandlung und Leitplanken verwaltet. Das Modell generiert Text; das Harness entscheidet, was das Modell sieht, was es tun kann, wann es stoppt und was passiert, wenn etwas schiefläuft.
- Im Produktionseinsatz ist der Modellaufruf oft der kleinste sichtbare Teil der Systemoberfläche. Ein schwächeres Modell in einem gut aufgebauten Harness kann ein stärkeres Modell in einem schlampigen übertreffen, besonders bei langen, werkzeugintensiven Aufgaben.
- Ein Harness hat grob neun bis elf wiederkehrende Komponenten. Die meisten davon sind Dinge, die das Modell nie direkt berührt.
- "Harness" ist nicht dasselbe wie "Framework". Ein Framework (LangGraph, ein Agents SDK) ist die Bibliothek, mit der du baust; das Harness ist die laufende Schicht, die dir diese Bibliothek hilft zusammenzustellen.
Was ist ein Agent-Harness?
Ein Agent-Harness ist die Software-Infrastruktur rund um ein Sprachmodell, die die Ausführungsschleife, den Werkzeugzugriff, Speicher, Kontext, Zustandspersistenz, Fehlerbehandlung und Leitplanken verwaltet. Das Modell generiert Text. Das Harness entscheidet, was das Modell in jedem Schritt sieht, welche Aktionen es ausführen kann, wann es stoppt und was passiert, wenn ein Schritt fehlschlägt.
Die klarste Formulierung kommt von LangChain, die es auf eine Gleichung reduzieren: Agent = Model + Harness. Das Modell liefert die Intelligenz. Der Harness ist das, was diese Intelligenz im echten Umfeld handlungsfähig macht.
"Ein Harness ist jeder Code, jede Konfiguration und jede Ausführungslogik, die nicht das Modell selbst ist."
— LangChain, Die Anatomie eines Agent-Harness
Die Grenze lässt sich am besten durch eine Frage erfassen: Wenn dein Agent etwas Falsches tut, war dann das eigene Denken des Modells falsch, oder hat das System um es herum dem Modell den falschen Kontext, die falschen Tools oder keine Möglichkeit zur Wiederherstellung gegeben? Meistens ist es in einem echten System das Zweite. Das Modell hat über fehlerhafte Eingaben korrekt nachgedacht. Der Harness kontrolliert die Eingaben.
Wichtigste Erkenntnis: Das Modell generiert; der Harness regiert. Diese Trennung ist das gesamte Konzept.
Was sind die Komponenten eines Agent-Harness?
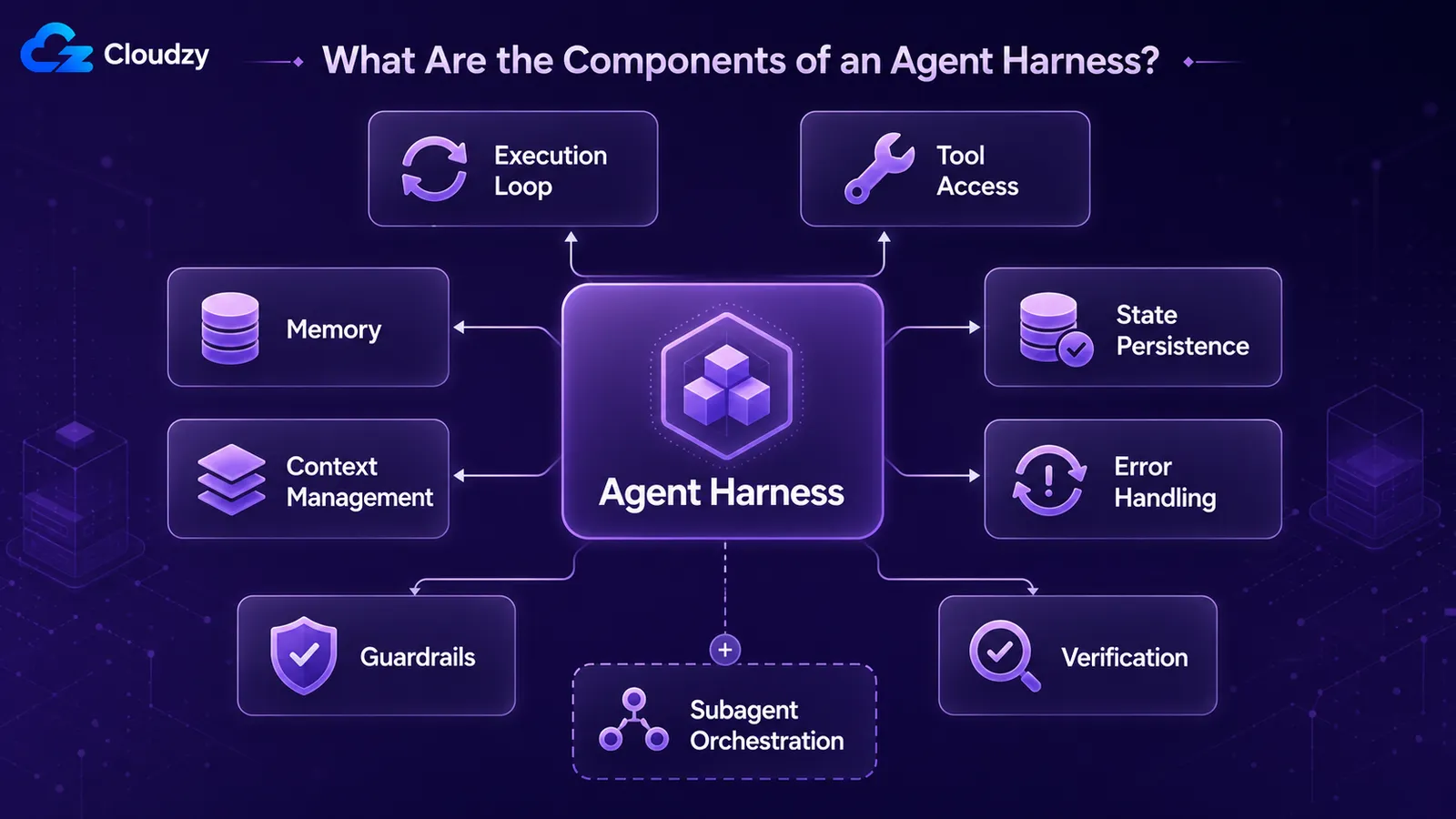
Jeder Production-Harness setzt dieselben wiederkehrenden Teile zusammen: eine Ausführungsschleife, die das Modell Zug für Zug steuert, Tool-Zugriff, der es handeln lässt, Speicher über Züge hinweg, Kontextverwaltung für das, was es gerade sieht, Zustandspersistenz, damit die Arbeit über Sitzungen hinweg erhalten bleibt, Fehlerbehandlung für fehlgeschlagene Schritte und Leitplanken, die einschränken, was es tun kann. Production-Systeme fügen Verifikationsschleifen und Subagenten-Orchestrierung hinzu.
Ein nützliches Inventar, abgeleitet aus der Art und Weise, wie Praktiker reale Systeme beschreiben:
- Ausführungs- / Steuerungsschleife: das, was den Agenten Schritt für Schritt antreibt. Das Modell aufrufen, seine Ausgabe lesen, jedes angeforderte Tool ausführen, das Ergebnis zurückgeben, wiederholen bis zur Abbruchbedingung.
- Tool-Zugriff: die Funktionen, APIs, die Codeausführung und das Dateisystem, auf die das Modell zugreifen kann.
- Memory: was der Agent über Turns und Sessions hinweg behält.
- Kontextverwaltung: was bei jedem Turn in das Fenster des Modells gepackt wird und was herausgedrängt wird, wenn es überläuft.
- Statuspersistenz / Checkpointing: den Zustand des Agenten speichern, damit ein abgestürzter oder pausierter Lauf fortgesetzt werden kann.
- Fehlerbehandlung: Wiederholungsversuche, Fallbacks und Wiederherstellung bei Fehlern in Tool- oder Modellaufrufen.
- Leitplanken: Einschränkungen für das, was der Agent tun kann, z. B. erlaubte Tools, Schrittlimits und Ausgabevalidierung.
- Verifikationsschleifen: der Agent (oder der Harness) prüft seine eigene Arbeit, bevor er sie als abgeschlossen deklariert.
- Subagenten-Orchestrierung: Subagenten starten, delegieren und deren Ergebnisse bei größeren Aufgaben einsammeln.
Nicht alle davon sind universell. Die Ausführungsschleife, Tools, Kontextverarbeitung und Fehlerbehandlung tauchen selbst in einem Wochenend-Prototyp auf. Zustandspersistenz, Verifikation und Subagenten-Orchestrierung sind der Punkt, an dem sich Prototypen und Produktionssysteme trennen. Ein Prototyp kann sie überspringen; ein langläufiger Produktionsagent nicht. Anthropics Beschreibung zu langläufige Agenten ist ein Überblick über die produktionsexklusiven Teile: wie ein Agent sein Verständnis aus einer Fortschrittsdatei nach dem Zurücksetzen seines Kontextfensters wiederherstellt und wie Tests in die Schleife eingebunden werden.
Für alle, die die akademische Brücke möchten, eine aktuelle Überblick über Agentenarchitekturen fasst dieselbe Mechanik in einem kleineren formalen Tupel von Kernkomponenten zusammen. Die Praktikerliste und das Rahmenwerk der Studie sind zwei Zoomstufen auf dieselbe Struktur: die Studie komprimiert, das obige Inventar expandiert. Behandeln Sie die Neun-bis-elf-Zahl als die Komponenten, die die meisten Produktions-Harnesses teilen, nicht als ratifizierten Standard; das Feld hat noch nichts ratifiziert.
Wichtigste Erkenntnis: Die meisten beweglichen Teile eines Agenten befinden sich im Harness, nicht im Modell. Das Modell ist eine Komponente unter vielen.
Warum ist das Harness wichtiger als das Modell?
Ein schwächeres Modell in einem gut konstruierten Harness übertrifft häufig ein stärkeres Modell in einem schlecht konstruierten. Der Grund ist mechanisch, nicht magisch: Die End-to-End-Zuverlässigkeit eines Agenten ist das Produkt der Zuverlässigkeit jedes einzelnen Schritts, und die meisten dieser Schritte (Werkzeugauswahl, Kontextzusammenstellung, Fehlerwiederherstellung) sind Aufgabe des Harness, nicht des Modells. Verbessert man sie, wird die gesamte Kette zuverlässiger, unabhängig davon, welches Modell darin steckt.
Die Arithmetik macht es greifbar. Angenommen, jeder Schritt in einer Zehnschrittaufgabe gelingt 99% der Zeit. Der End-to-End-Erfolg ist nicht 99%. Es ist 0,99 hoch zehn, also etwa 90%. Drückt man jeden Schritt auf 99,9%, springt der End-to-End-Wert auf etwa 99%. Die Zuverlässigkeit pro Schritt multipliziert sich, und die Zuverlässigkeit pro Schritt ist überwiegend eine Harness-Eigenschaft. Deshalb zahlt sich das Optimieren von Fehlerbehandlung und Kontextverwaltung mehr aus als der Austausch gegen ein Modell, das auf einem Benchmark einen halben Punkt besser abschneidet.
Es gibt Produktionssignale, die in dieselbe Richtung zeigen. MongoDB, unter Berufung auf die Fallstudie von Vercel, berichtet, dass Vercel den Großteil der Tools ihres Agenten gestrichen hat und dessen Erfolgsquote beim gleichen Modell deutlich gestiegen ist, mit einem kleineren und saubereren Harness. Lesen Sie es als konvergierendes Indiz und nicht als Beweis: Es ist ein Produktionsfall, kein kontrolliertes Experiment, aber es zeigt in dieselbe Richtung wie die kumulierende Arithmetik und die Umfragearbeiten oben.
Das ist die Heuristik, zu der ich als Plattform-Ingenieur immer wieder zurückkomme: Der Kontext ist der Engpass, nicht die rohe Modellkapazität, und Gerüste, die gebaut werden, um heutige Modelllücken zu überbrücken, werden tendenziell von sich verbessernden Modellen überholt. Bauen Sie die dauerhaften Teile des Harness (die Schleife, den Zustand, die Wiederherstellung) und lassen Sie das darunterliegende Modell nach seinem eigenen Zeitplan besser werden.
Wichtigste Erkenntnis: Wenn Ihr Agent versagt, verdächtigen Sie das Harness, bevor Sie das Modell verdächtigen. Die Wahrscheinlichkeit spricht dafür.
Was ist der Unterschied zwischen einem Harness, einem Scaffold und einem Framework?
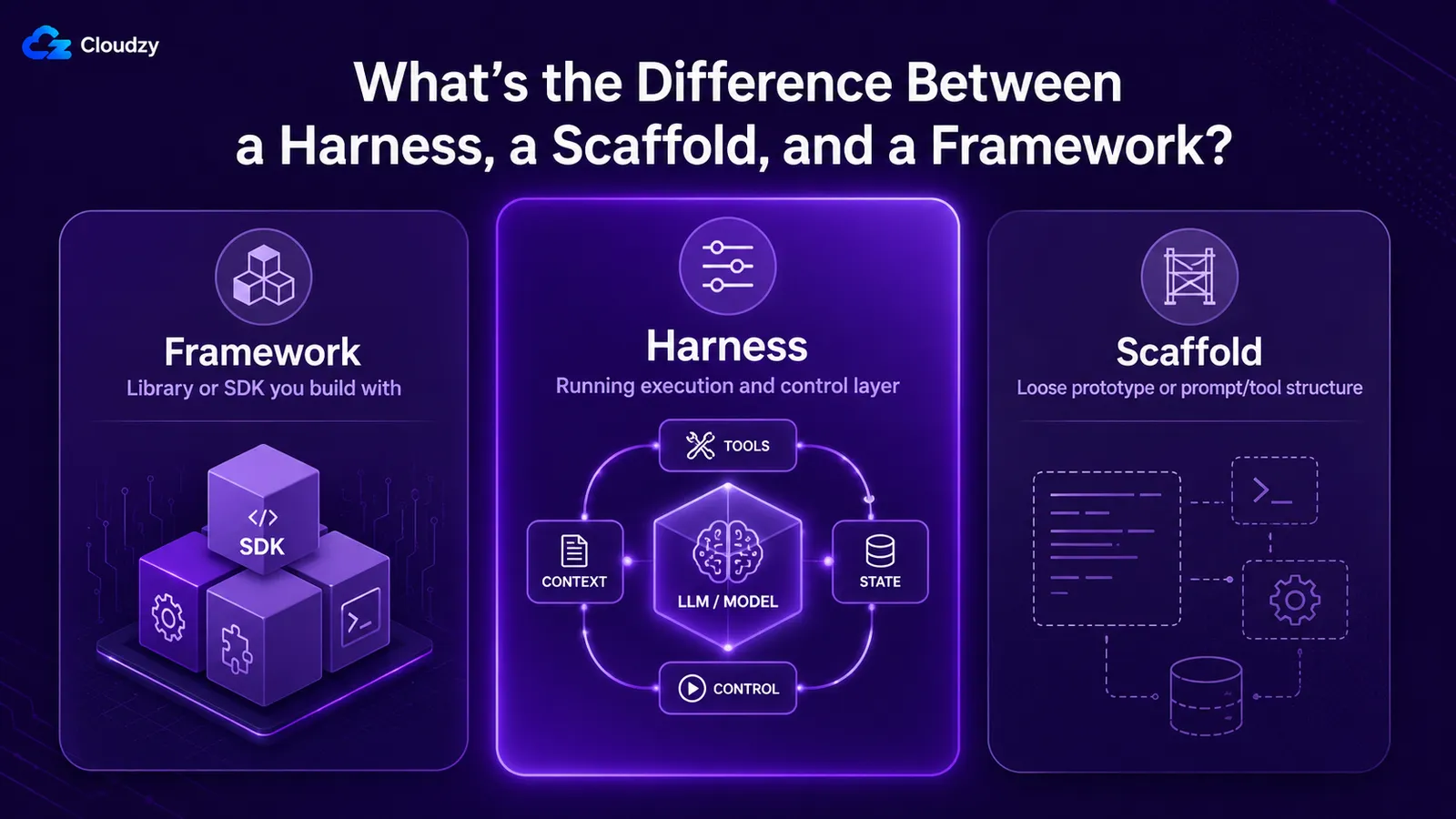
Diese drei werden oft synonym verwendet, obwohl sie es nicht sein sollten. A Framework ist die Bibliothek oder das SDK, mit dem Sie bauen, z. B. LangGraph oder ein Agents SDK. Ein Harness ist die laufende Ausführungs- und Governance-Schicht um das Modell, die ein Framework Ihnen beim Zusammenstellen hilft. Ein Scaffold ist das lockerste der drei: manchmal ein Fast-Synonym für das Harness, manchmal die Prototyp-Version davon, manchmal speziell die Prompt-und-Tool-Beschreibungs-Schicht.
Das Vokabular ist tatsächlich ungeregelt, und das Sauberste ist es, die Verwendungen zu kartieren, anstatt eine festzulegen. Das von HuggingFace Agenten-Glossar sagt dies direkt:
"Viele dieser Begriffe haben noch keine allgemein akzeptierten Definitionen, und verschiedene Frameworks verwenden dasselbe Wort unterschiedlich."
— HuggingFace, Agenten-Glossar
| Begriff | Wofür es steht | Beziehung |
|---|---|---|
| Framework | Die Bibliothek oder das SDK, mit dem Sie bauen (LangGraph, ein Agenten-SDK) | Ein Werkzeug zum Zusammenbauen eines Harness |
| Harness | Die laufende Schicht um das Modell: Loop, Tools, Kontext, Zustand, Guardrails | Was Sie ausliefern und betreiben |
| Scaffold | Weit gefasst verwendet: ein Quasi-Synonym für Harness, oder die Prototyp-Variante / Prompt-Schicht | Überschneidet sich mit Harness; weniger präzise |
| Loop | Der Ausführungszyklus innerhalb des Harness | Eine Komponente des Harness |
Die praktische Schlussfolgerung für das Denken über das eigene System: Wenn jemand "Framework" sagt, frage, ob er die Bibliothek oder das laufende Ding meint. Wenn jemand "Scaffold" sagt, frage, ob er den gesamten Harness oder nur die Prompt-und-Tool-Schicht meint. Die Disambiguierung ist der Wert hier, kein Anspruch auf das letzte Wort.
Wie implementiert LangGraph das Harness-Muster?
LangGraph ist eine beliebte Open-Source-Python-Implementierung des Harness-Musters. Es modelliert die Agent-Ausführung als gerichteten Graphen aus Knoten und Kanten, mit typisiertem Zustand, der zwischen ihnen fließt, und jedem Übergang, der checkpointfähig ist. Wenn sich die abstrakten Komponenten oben schwer greifen lassen, ist LangGraph ein Ort, um sie in einem echten Tool konkrete Gestalt annehmen zu sehen.
Die Zuordnung ist nahezu eins-zu-eins. Die Knoten und Kanten sind die Ausführungsschleife: jeder Knoten leistet Arbeit, jede Kante entscheidet, wohin die Kontrolle als nächstes geht. Das typierte Zustandsobjekt, das zwischen Knoten übergeben wird, ist die Kontext-und-Zustand-Komponente explizit gemacht. Das Checkpointing (LangGraph persistiert den Zustand durch Savers wie seine Postgres-basierte Implementierung) ist die Zustandspersistenz-Komponente. Ein konfigurierbares Schrittelimit ist ein Stopbedingung-Guardrail, das verhindert, dass ein fehlerhafter Agent endlos schleift. Gleiche Komponenten, benannt und verdrahtet von einer spezifischen Bibliothek.
Wenn Sie einen LangGraph-Agenten rund um die Uhr auf Ihrem eigenen Server betreiben möchten, ist das eine Deployment-Frage und keine konzeptionelle. Siehe unseren Linux VPS-Leitfaden für diesen Weg. Hier ist LangGraph nur das ausgearbeitete Beispiel: Beweis dafür, dass "Ausführungsschleife", "Zustandspersistenz" und "Guardrail" keine Abstraktionen sind, sondern Dinge, auf die man im echten Code zeigen kann.
Häufig gestellte Fragen
Was ist ein Agent-Harness?
Ein Agent-Harness ist die Software um ein Sprachmodell herum, die es in einen Agenten verwandelt. Er verwaltet den Ausführungsloop, den Werkzeugzugriff, den Speicher, den Kontext, die Zustandspersistenz, die Fehlerbehandlung und die Guardrails. Das Modell generiert Text; der Harness entscheidet, was das Modell sieht, was es tun kann, wann es aufhören soll und was passiert, wenn etwas fehlschlägt.
Ist ein Agent Harness dasselbe wie ein Agent Framework?
Nein. Ein Framework ist die Bibliothek oder das SDK, mit dem Sie bauen, wie LangGraph oder ein Agents-SDK. Der Harness ist die laufende Ausführungs- und Governance-Schicht um das Modell (die Schleife, Tools, Kontext, Zustand und Guardrails), die ein Framework Ihnen hilft zusammenzustellen. Sie verwenden ein Framework, um einen Harness zu bauen.
Welche Komponenten hat jeder Agent Harness?
Die meisten Harnesses teilen einen wiederkehrenden Kern: eine Ausführungsschleife, Tool-Zugriff, Speicher, Kontextverwaltung, Zustandspersistenz, Fehlerbehandlung und Guardrails. Produktions-Harnesses fügen Verifizierungsschleifen und Subagenten-Orchestrierung hinzu. Prototypen können die produktionsspezifischen Teile weglassen, aber die Schleife, Tools, Kontextverarbeitung und Fehlerbehandlung tauchen fast überall auf.
Was bedeutet "Das LLM ist der kleinste Teil Ihres Agentensystems"?
Es bedeutet, dass der Großteil des Verhaltens und der Zuverlässigkeit eines Agenten aus dem Harness kommt, nicht aus dem Modell. Die End-to-End-Zuverlässigkeit ist das Produkt der Erfolgsrate jedes Schritts, und die meisten Schritte sind Harness-Arbeit. MongoDB berichtet, unter Berufung auf Vercels Fallstudie, von einem Erfolgsraten-Sprung allein durch Harness-Änderungen, beim selben Modell. Das ist Beleg dafür, dass das Beheben des Harness das Beheben des Modells übertrifft.
Wo die Qualität Ihres Agenten wohnt
Der Harness ist der Ort, an dem der Großteil der Qualität eines Agenten liegt, und Sie haben jetzt das Vokabular, um Probleme in Ihrem eigenen System zu lokalisieren. Sie können einen Harness definieren, seine Komponenten benennen, ihn von einem Framework und einem Scaffold unterscheiden und darüber nachdenken, ob ein bestimmter Fehler ein Modellproblem oder ein Harness-Problem ist.
Wenn Ihr Agent sich also das nächste Mal daneben verhält, prüfen Sie zuerst die Harness-Schicht: den Kontext, den Sie ihm zuführen, die Tools, die Sie freigegeben haben, die Stop-Bedingungen, die Sie gesetzt haben, die Art, wie er sich von einem fehlgeschlagenen Schritt erholt. Greifen Sie erst dann auf ein größeres Modell zurück, wenn diese Schicht überprüft ist. In den meisten Fällen wird das nicht nötig sein.


