
Schnell loslegen, nur für das zahlen, was du nutzt, und das Patching auslagern: dieses Versprechen überzeugt nach wie vor. Die Euphorie verfliegt jedoch schnell, wenn unkontrollierte Speicherkosten auflaufen oder eine übersehene S3-Richtlinie einen Bucket offen stehen lässt. Aus langjähriger Erfahrung sehe ich dieselben zentralen Herausforderungen im Cloud Computing immer wieder, quer durch Stacks und Branchen. Wer sie früh kennt, vermeidet einen Großteil der Probleme und hält das Team darauf fokussiert, Features zu liefern, statt Brände zu löschen.
Warum diese Probleme hartnäckig Go bleiben
Cloud-Ausfälle entstehen selten durch einen einzelnen schwerwiegenden Fehler. Sie entstehen, wenn sich kleine Lücken in Architektur, Prozessen und beim Team aufschichten. Bevor wir uns die einzelnen Kategorien ansehen, hier ein kurzer Überblick über typische Warnsignale, die auf ein tieferliegendes Problem hindeuten:
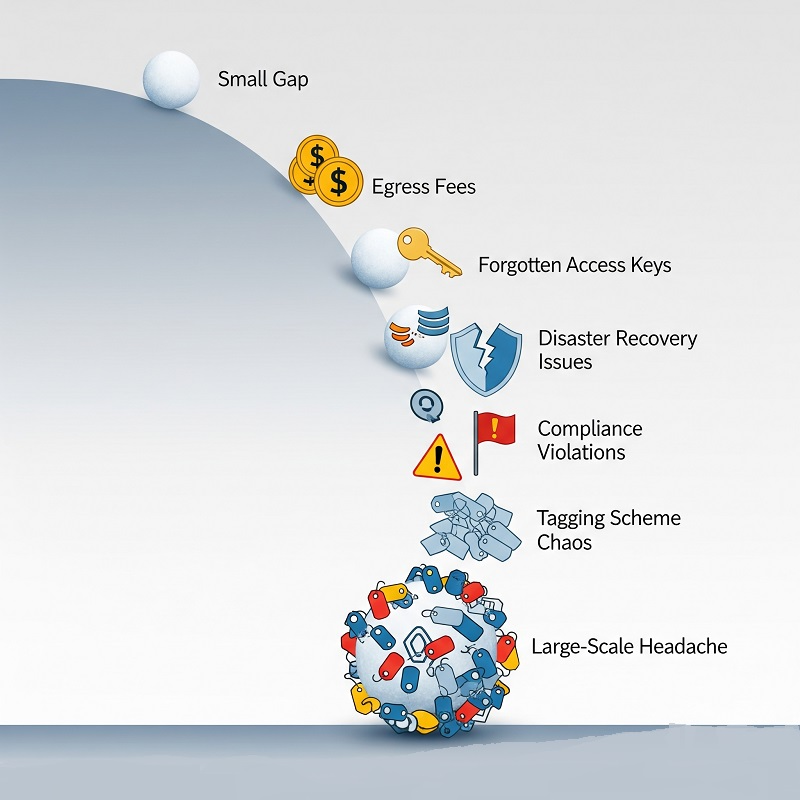
- Ein plötzlicher Anstieg der Egress-Gebühren frisst zwei Monate Marge auf.
- Ein vergessener Access Key befeuert über Nacht eine Crypto-Mining-Kampagne.
- Ein regionaler Ausfall setzt einen Disaster-Recovery-Plan auf die Probe, den niemand geprobt hat.
- Ein Compliance-Audit findet nicht klassifizierte sensible Daten im Object Storage.
- Zehn Teams nutzen zehn verschiedene Tagging-Schemata, sodass Chargeback-Berichte wie Hieroglyphen wirken.
Jedes dieser Symptome lässt sich auf eine oder mehrere zentrale Risikokategorien zurückführen. Behalte diese Übersicht im Blick, sie gibt die Richtung für alle weiteren Gegenmaßnahmen vor.
Risiken des Cloud-Computings
Branchenstudien zeigen konsistent sieben zentrale Risikokategorien, auf die der Großteil der Vorfälle in verschiedenen Branchen entfällt. Auch wenn diese Kategorien ineinandergreifen, bilden sie zusammen die Große Herausforderungen im Cloud-Computing Teams im Alltag begegnen, von explodierenden Kosten bis zur Datenexfiltration:
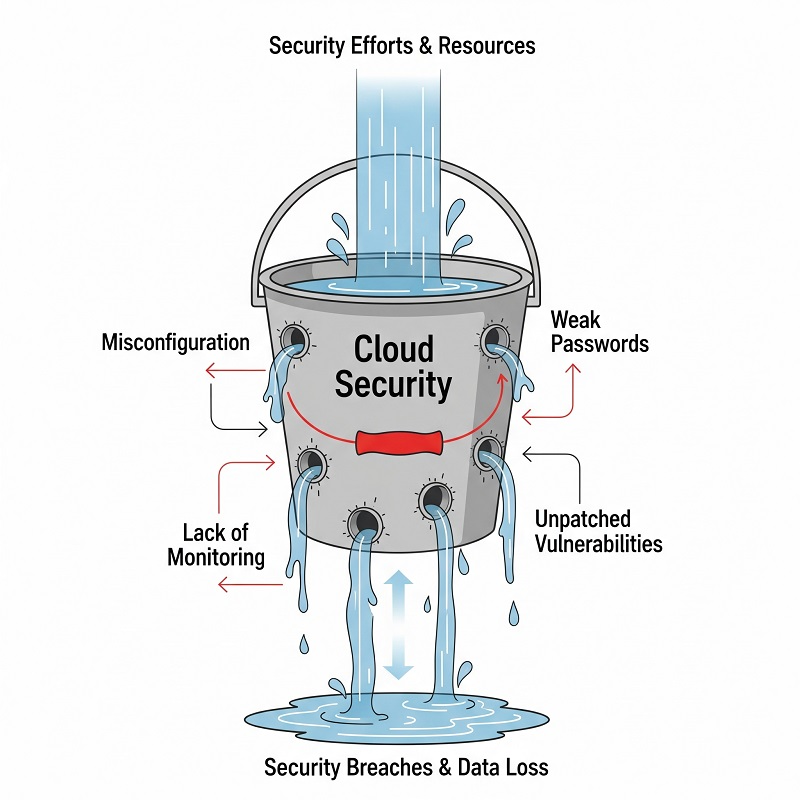
Fehlkonfiguration und übermäßige Berechtigungen
Selbst erfahrene Entwickler klicken im Admin-Panel gelegentlich daneben. Eine zu großzügige Security Group oder ein öffentlich zugänglicher Storage-Bucket verwandelt ein internes Tool in ein Einfallstor aus dem Internet.
Häufige Fehler
- Wildcard 0.0.0.0/0 Regeln für Admin-Ports.
- IAM-Rollen mit Vollzugriff, die lange nach Abschluss einer Migration noch aktiv sind.
Datenpannen und Datenlecks
Sobald Fehlkonfigurationen eine Lücke öffnen, verlassen Daten das System. Datenverletzungen sind ein wiederkehrendes Problem in der Cloud-Sicherheit, und sie beginnen selten mit ausgeklügelten Zero-Days. Sie entstehen durch offengelegte Endpunkte oder veraltete Zugangsdaten.
Insider-Bedrohungen und Schatten-Admins
Nicht jedes Risiko kommt von außen. Externe Mitarbeiter mit nicht widerrufenen Berechtigungen oder Beschäftigte, die nicht freigegebene Dienste starten, erzeugen blinde Flecken, die die übliche Überwachung nicht erfasst.
Unsichere APIs und Supply-Chain-Risiken
Jede Cloud-native Anwendung stützt sich auf Drittanbieter-SDKs und APIs. Fehlende Rate-Limits oder ungepatchte Bibliotheken laden zum Missbrauch ein und machen aus einer harmlosen Funktion eine Angriffsfläche.
Eingeschränkte Sichtbarkeit und Lücken in der Überwachung
Wenn Logs in einem Account liegen und Alerts in einem anderen, ziehen sich Incidents in die Länge, während Teams nach Kontext suchen. Blinde Flecken verbergen sowohl Performance-Drift als auch aktive Angriffe.
Sicherheitsbedenken, die Teams nachts wach halten
Die Grundsätze aus unserem Artikel über Was ist Cloud-Sicherheit bieten eine solide Ausgangsbasis, doch ausgeklügelte Angreifer kommen trotzdem durch, wenn Unternehmen Log-Auswertung, MFA und Least-Privilege-Design nicht automatisieren. Ohne diese Leitplanken werden die größten Sicherheitsprobleme im Cloud-Computing vom abstrakten Problem zum dringenden Handlungsbedarf. Moderne Cloud-Sicherheits-Tools helfen, Erkennungszeiten zu verkürzen, aber nur wenn Teams sie in den täglichen Arbeitsablauf integrieren.
Wichtigste Erkenntnisse:
- Alle externen Endpunkte erfassen und wöchentlich auf unbeabsichtigte Exposition prüfen.
- Schlüssel automatisch rotieren und langlebige Zugangsdaten als technischen Schulden behandeln.
- Audit-Logs in ein zentrales SIEM einspeisen und Anomalien statt roher Fehler melden.
Operative und finanzielle Überraschungen
Hohe Verfügbarkeit klingt einfach, bis ein Multi-AZ-Datenbankcluster die Rechnung verdoppelt. Unter den Große Herausforderungen im Cloud-Computing die offen zutage liegen, gehört Kostendrift zu den häufigsten Problemen. Support-Tickets häufen sich, wenn Instanzfamilien abgekündigt werden oder Kapazitätsgrenzen Scale-up-Ereignisse drosseln.
Teams, die eine detaillierte Kontrolle benötigen, verlagern latenzempfindliche Dienste manchmal in ein schlankes VPS Cloud Setup. Indem sie Workloads an garantierte vCPUs binden, umgehen sie Noisy-Neighbor-Effekte und behalten gleichzeitig die Flexibilität beim Anbieter.
Häufige Cloud-Probleme im operativen Betrieb
- Zu niedrig angesetzte Limits, die plötzliche Traffic-Spitzen blockieren.
- Vendor-Lock-in, der Änderungen auf der Datenebene langsam und teuer macht.
- Unerwartete regionsübergreifende Übertragungskosten bei Failover-Tests.
Goovernance und Compliance-Fallstricke
Prüfer haben ihre eigene Sprache, und die Cloud fügt noch mehr Fachbegriffe hinzu. Wenn Tagging-, Aufbewahrungs- und Verschlüsselungsrichtlinien auseinanderdriften, häufen sich die Befunde schnell. Die folgende Tabelle zeigt vier Lücken, auf die ich bei Bereitschaftsprüfungen regelmäßig stoße:
| Compliance-Lücke | Typischer Auslöser | Wahrscheinlichkeit | Geschäftliche Auswirkungen |
| Nicht klassifizierte personenbezogene Daten im Objektspeicher | Fehlende Dateninventarisierung | Mittel | Bußgelder, Reputationsschäden |
| Kein MFA auf privilegierten Konten | Geschwindigkeit vor Prozess | Hoch | Kontoübernahme |
| Disaster-Recovery-Plan wurde nie getestet | Ressourcenauslastung | Mittel | Längere Ausfallzeit |
| Proprietäre Funktionen tief eingebettet | Bequemlichkeit beim Aufbau | Niedrig | Teurer Ausstieg, verlangsamte Migration |
Jede Zeile lässt sich auf eine der oben genannten Computing-Herausforderungen zurückführen. Transparenz, minimale Rechtevergabe und wiederholbare Tests bilden das Fundament eines erfolgreichen Audit-Zyklus.
Die Schwachstellen angehen
Es gibt keine Patentlösung, aber ein mehrschichtiger Ansatz reduziert Risiken zügig. Ich unterteile Maßnahmen in drei Bereiche:
- Das Fundament härten
- Dokumentiere jede Umgebung als Infrastructure-as-Code. Drift-Alerts erkennen ungewollte Änderungen, bevor sie zum Problem werden.
- Setze MFA auf Ebene des Identity-Providers durch, nicht pro Anwendung.
- Erkennung und Reaktion automatisieren
- Logs zentral sammeln, dann nach Ressource-Tags aggregieren, damit Alerts erklären, was was kaputt ist, nicht nur wo Es ist kaputt.
- Starte wöchentlich Sandbox-Kopien, um Patches zu testen, bevor sie in die Produktion gehen.
- Auf den Ernstfall vorbereiten
- Simuliere Ausfälle im laufenden Betrieb: Trenn einen Dienst vom Netz und beobachte, wie die Dashboards reagieren. Solche Übungen hinterlassen mehr als jede Präsentation.
- Halte ein sauberes, portables Image bereit. Eine Ein-Klick- Cloud-Server kaufen Option wirkt als Sicherheitsventil, wenn eine Region ausfällt.
Fang mit den Bausteinen an, die zu deinem Stack passen, und weite die Abdeckung schrittweise aus. Kleine Erfolge wie automatisches Tagging oder tägliche Key-Rotation summieren sich mit der Zeit.
Fazit
Cloud-Nutzung wächst kontinuierlich, also ist es keine Option, die damit verbundenen Probleme zu ignorieren. Wenn du deine Umgebung gegen die Große Herausforderungen im Cloud-Computing hier beschriebenen Punkte abgleichst, erkennst du Schwachstellen früh, hältst die Kosten planbar und gibst Entwicklern die Sicherheit, Features ohne Risiko zu deployen. Die Arbeit hört nie wirklich auf, aber mit klarem Blick, solidem Tooling und regelmäßigen Reviews bleibt die Cloud ein Beschleuniger und kein Grund für Nachtschichten.
Geschwindigkeit, Konsistenz und zuverlässige Absicherung sind in Cloudzy's VPS Cloud-Portfoliobereits eingebaut. Jede Instanz läuft auf NVMe-Storage, hochfrequenten CPUs und redundanten Tier-1-Routen. Workloads starten schnell und bleiben auch unter Last reaktionsfähig. Firewalls auf Enterprise-Niveau, isolierte Tenants und kontinuierliches Patching sichern den Stack ab, ohne die Performance zu beeinträchtigen. Wer einen Cloud-Server sucht, der alle Anforderungen an Sicherheit und Zuverlässigkeit erfüllt, ist hier genau richtig.


