
A hurok negyvenszer futott tisztán a tesztelés során. A negyvenegyedik futásnál, éles környezetben, ugyanazt a broken lekérdezést ismételten ugyanazzal az SQL-eszközzel hívta, egészen addig, amíg felégette az aznapi API-keretet, és egy számlázási riasztás végre felébresztett valakit. Senki nem írt rossz modellt. Senki nem változtatta meg a promptot. Az ügynök egyszerűen sosem döntötte el, hogy kész.
Ez az a minta, amelyet újra és újra látok olyan csapatoknál, akik egy ügynököt prototípusból nonstop munkaterhelésre mozgatnak. Az AI-ügynök hurkok gyakran nem azért buknak meg éles környezetben, mert a modell hirtelen rosszabb lett, hanem mert a végrehajtási rétegből hiányzik a leállítási fegyelem, az érvényesített eszközszerződések, a korlátozott kontextus és a tartós állapot. Az ügynök-hurok egy sztochasztikus rendszer, amely egymás után hozza a döntéseket. Néhány konkrét korlát nélkül a ritka hiba garantálttá válik, ha elég sokáig futtatjuk. A felügyelt ügynökplatformok (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) néhány ilyen korlátot beépítve tartalmaznak; ez az útmutató azoknak szól, akik úgy döntöttek, hogy saját szerveren futtatják és maguk kezelik a hurkot.
A kockázat elég valós ahhoz, hogy a Gartner azt várja: az ügynöki AI-projektek több mint 40%-a 2027 végéig törlésre kerül, hivatkozva az emelkedő költségekre és a tisztázatlan értékre. Az alábbiakban hat konkrét módot mutatunk be, ahogyan a hurkok meghibásodnak éles környezetben, az egyes mechanizmusokat, és azt a keretrendszer-javítást, amely megoldja a problémát, a LangGraph és n8n részletekkel együtt, valamint azt, amit egy 24/7-es futtatáshoz valóban meg kell valósítani.
A rövid verzió
- Végtelen hurkok: Az ügynök sosem dönt arról, hogy kész. Kombináljon egy kemény lépéskorlátot (LangGraph
recursion_limit, alapértelmezés: 25) a haladás-figyeléssel, amely leállítja az ismétlődő eszköz+argumentum hívásokat. - Kontextus-túlcsordulás: A hurok feltölti a saját kontextusablakát a felhalmozott előzménnyel, amíg a hívások csonkítódnak vagy hibásodnak. Foglaljon össze előzményeket rögzített időközönként, hogy a munkakontextus korlátozott maradjon.
- Néma eszközhibák: Egy eszköz üres karakterláncot ad vissza, a modell érvényes eredményként értelmezi, és az ügynök "sikeresnek" tűnik anélkül, hogy bármit tett volna. Ellenőrizzen minden eszközeredményt, mielőtt a modell látná.
- Gondolkodási romlás: A minőség romlik a kontextus növekedésével, még a kemény korlát alatt is. Tömörítse a közbülső állapotot, de védje a rögzített biztonsági utasításokat.
- Állapotvesztés újraindításkor: Egy összeomlás nulláról kell kezdeni. Mentse az állapotot Postgres-be (LangGraph
PostgresSaver), ne SQLite-ba, éles üzemben. - Újrapróbálkozási viharok: Tíz ügynök, egyenként tíz újrapróbálkozással, száz kéréssel zúdul egy leállt szolgáltatásra. Adjon hozzá exponenciális visszalépést jitterrel és egy globális megszakítót.
Mit nem fed le ez az útmutató
Ez egy keretrendszer-útmutató, amely a hurok körüli mérnöki megoldásokra összpontosít, nem a benne lévő modellre. Néhány kapcsolódó téma szándékosan kívül esik a hatókörén:
- Többügynökes koordinációs hibák (elavult olvasások, árva állapot az ügynökök között): egy másik probléma, amely megérdemel egy saját leírást.
- Ügynöki biztonság (prompt-injekció, eszközmérgezés): külön hibakategória a saját fenyegetési modelljével.
- Modellválasztás és finomhangolás. Ez az útmutató azt feltételezi, hogy már választott egy modellt, és a körülötte lévő rendszert debuggolja.
- Felügyelt ügynökszolgáltatások, fentebb már megemlítve; az itt szereplő minták az önállóan futtatott megoldáshoz szólnak.
Végtelen hurkok: amikor az ügynök sosem dönt arról, hogy kész

Egy ügynök örökké fut, ha sem kemény lépéskorlátja, sem haladás-felismerési módszere nincs. A megoldás két részből áll: tartson fenn egy kemény korlátot mint költségvédőt, és adjon hozzá haladás-figyelést, amely kivonatolja az egyes eszköz-argumentum hívásokat, és leállítja a folyamatot, ha ugyanazt a hívást ismétlődni látja. A LangGraph-ban ez a korlát a recursion_limit, alapértelmezés 25 lépés; ha túllépi, a gráf kivált egy GraphRecursionError.
A LangGraph dokumentációja úgy írja le ezt a korlátot, mint "a megállási feltétel elérése előtti lépések maximális száma," és itt van a figyelemre méltó csapda: a recursion_limit nem hurok-védelem. Ez egy olyan védőhálló, amely akkor lép életbe, után miután a hurok már elvesztegetett huszonöt lépést és a velük járó API-kiadást. Az ügynök saját megtanult leállítási logikájának sokkal korábban kellene megállítania, és ez a logika önállóan is meghibásodhat. Egy bejelentett LangGraph-eset megmutat egy szöveg-SQL ügynököt, amely a recursion_limit-ig hurkolt, annak ellenére, hogy a promptban egyértelmű megállási feltételek szerepeltek. Folyamatosan ugyanazt a lekérdező eszközt hívta ugyanazzal a sikertelen SQL-lel, és a problémát "nem tervezett"-ként zárták le. Ezt egyértelmű jelzésnek értem: ne tekintse a korlátot megállási feltételnek. Ez a biztonsági öv, nem a fék.
A korlát emelése egyszerű; a config-on keresztül adja át, amikor meghívja a gráfot:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Ami valójában megállítja az elakadt hurkot, az a haladás-figyelés. A mechanizmus egyszerű: hash-elje az eszköz nevét és argumentumait minden lépésben, tartson fenn egy rövid ablakot a legutóbbi hash-ekből, és álljon le, ha ismétlést lát.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Ez elkapja azt az ügynököt, amely technikailag "fut" (eszközöket hív, tokeneket generál), de ugyanazon a sikertelen műveleten ciklik. Az itt megnevezett hibamód megfelel annak, amit a MAST-taxonómia (IBM Research és UC Berkeley) A leállítási feltételek figyelmen kívül hagyása (FM-1.5) névvel illet, és ez az egyik hibamód, amelyet az elemzésük a feladathiba teljes kudarcával társít.
Egy lépéskorlát megállítja az elszabadult költséget. A haladás-figyelés megállítja azt a hurkot, amely technikailag "halad", de önmagát ismétli. Produkcióban mindkettő szükséges.
Kontextusablak-túlcsordulás: amikor a hurok szeméttel tölti meg a saját kontextusát
Egy hosszan futó hurok felhalmoz minden eszközkimenetet, minden közbenső gondolatot és minden üzenetet, amelyet létrehozott, majd mindet visszatölti a kontextusablakba minden körben. Végül az ablak megtelik, és a hívások vagy csendesen csonkítódnak, vagy teljesen hibásodnak. A megoldás a kontextus tömörítése rögzített időközönként: minden N lépésnél tömörítse a felhalmozott előzményt egy futó összefoglalóba, hogy a munkakontextus korlátozott maradjon.
Képzeljen el egy kutatóügynököt, amely egy órája fut. A 60. lépésnél már hordozza az összes lekért oldal teljes szövegét, minden keresési eredményt, minden gondolkodási nyomot. Az előzmény egyik nyers darabja sem segít a 61. lépésnél, mégis mind beleszámít az ablakba, és a modell figyelmi keretet költ olyan tokenekre, amelyekre már nincs szüksége. Amikor az ablak megtelik, a szolgáltató az egyik végéről csonkítja, és az ügynök csendesen elveszíti a kezdeti utasítást.
A kiváltó küszöb hangolási döntés, és van rá egy hasznos referenciapont. A Mem0 egy valós produkciós rendszer leírásában megjegyzi, hogy a Hermes ügynök tömörítője "alapértelmezés szerint a modell kontextusablakának 50%-ánál lép életbe", egy másodlagos biztonsági hálóval 85%-nál olyan munkamenetekhez, amelyek fordulatok között megduzzadnak. Ötven százalék ésszerű kiindulópont: tömörítsen elég korán ahhoz, hogy egyetlen nagy eszközkimenet se léphesse át a korlátot a következő ütemezett tömörítés előtt.
Megjegyzés: Az overflow és a következtetési teljesítmény romlása különböző problémák, a következő szakasz a másodikkal foglalkozik. Az overflow egy kemény korlát: elfogy a tokens. A romlás fokozatos: a modell egyre rosszabbul teljesít. mielőtt elérné a falat. Mindkettőt kezelni kell, és a fenti kiváltó küszöb véd a kemény fal ellen.
A korlátozott kontextus a keretrendszer felelőssége, nem egy modellszolgáltatás. Tömörítsen időközönként, mielőtt az ablak egy néma csonkítást kényszerítene ki.
Néma eszközhívás-hibák: amikor az ügynök "sikeresen" nem tesz semmit
Egy eszközhívás üres karakterláncot vagy egy halvány "nincs találat" üzenetet ad vissza, a modell érvényes eredményként értelmezi, és az ügynök úgy folytatja, mintha a lépés működött volna, látszólag sikeresnek tűnve anélkül, hogy bármit tett volna. A megoldás egy ellenőrzési kapu minden eszközvisszatérésnél: séma-ellenőrzés vagy épszérű ellenőrzés a kimeneten, mielőtt a modell egyáltalán látná, és egy valódi hiba felszínre hozása, amellyel a huroknak foglalkoznia kell, egy üres siker helyett.
Ez azért alattomos, mert semmi sem omlik össze. Egy fejlesztő, aki leírta a néma hibamódokat éles ügynököknél , egyenesen fogalmazott: a modellek az általános üres karakterláncokat érvényes nullműveletként értelmezik, és a hiba tudatossága nélkül folytatják a végrehajtást. Az adatbázis-lekérdezés, amely a kapcsolat megszakadása miatt adott vissza nulla sort, pontosan ugyanúgy néz ki a modell számára, mint a lekérdezés, amely jogosan nem talált semmit. Tehát az ügynök "nincs megfelelő rekord" üzenetet jelent és továbblép, és egy héttel később derül ki, hogy a futások egyharmada csendben volt törött.
Az ellenőrzési kapu az eszköz és a modell közé kerül:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelA lényeg nem az pontos ellenőrzések; az Öné attól függ, mit ad vissza jogosan minden eszköz. A lényeg az, hogy egy ellenőrizetlen visszatérési érték egy sztochasztikus modellnek átadott döntés, és a modell alapértelmezett mozdulata a folytatás.
Egy ellenőrizetlen eszközvisszatérés néma hiba, amely csak idő kérdése. Ellenőrizze a kimenetet, ne bízzon csak a hívásban.
Gondolkodási romlás hosszú kontextusokban: amikor az ügynök minél tovább fut, annál rosszabbul teljesít
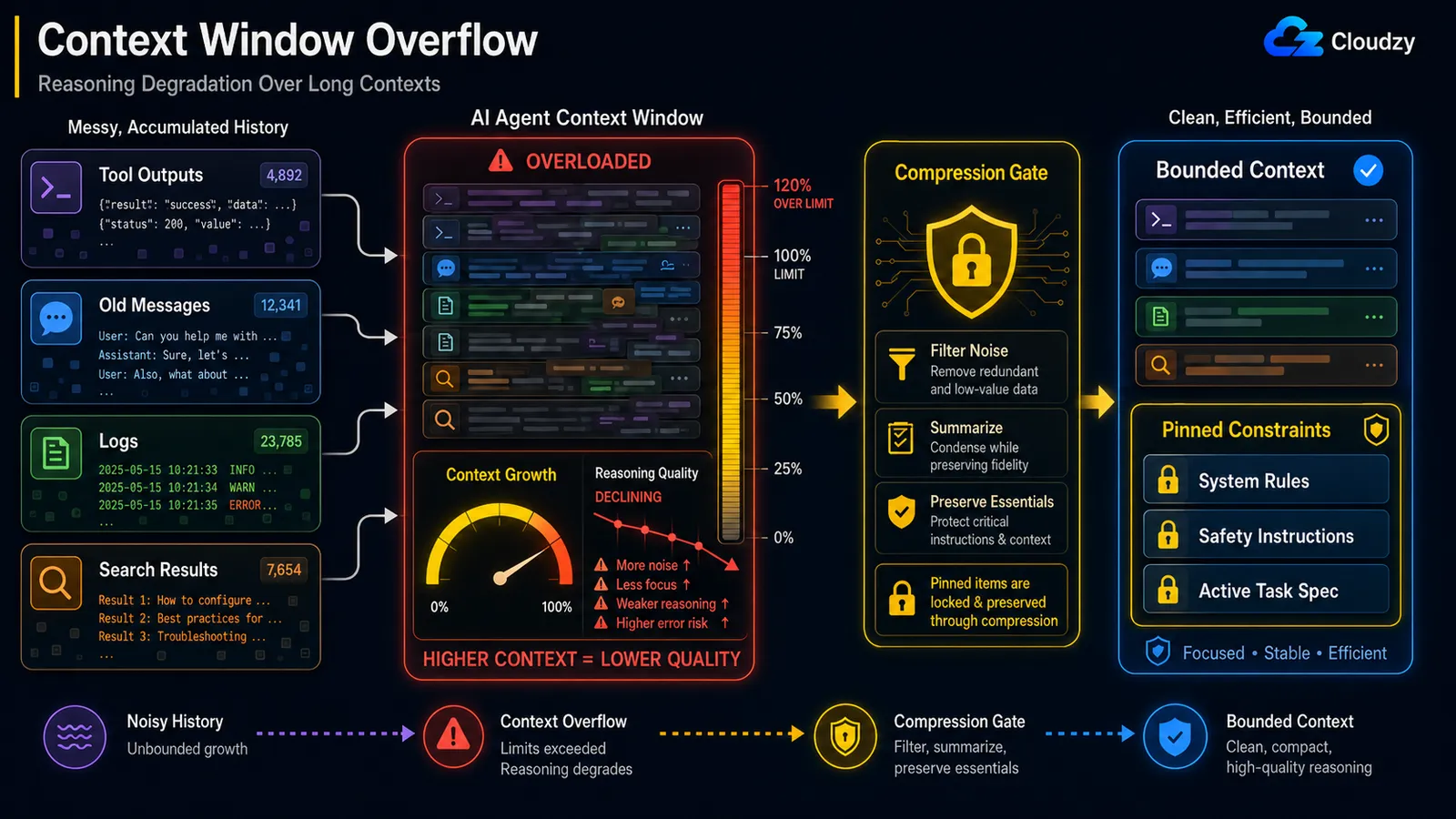
Még ha a kemény kontextuskorlát alatt is marad, a gondolkodási minőség romlik a kontextus növekedésével. Ez a "középen elveszett" hatás: a modell megbízhatóan figyel egy hosszú kontextus elejére és végére, de elveszíti a középső részt. A megoldás a közbülső tömörítés, amely megőrzi a rögzített megkötéseket: tömörítse a zajt, védje a teherhordozó utasításokat.
A mechanizmusnak neve van. Az Anthropic mérnöki blogja így hivatkozik rá: kontextusromlás: "mivel a kontextusablakban lévő tokenek száma növekszik, a modell képessége pontosan visszaidézni az adott kontextusból csökken." Mivel "minden token figyel minden más tokenre," n token esetén n² páros kapcsolatot kap, és a modell figyelme egyre vékonyabbra nyúlik, ahogy a kontextus hossza nő.
Ez a minősítő, védje a teherhordozó utasításokat, ez az egész játék lényege, és van egy dokumentált eset, amely megmutatja, miért. Egy bejelentett esetbenegy OpenClaw ügynök tömegesen törölte egy felhasználó postafiókját kontextustömörítés közben, mert a kapott biztonsági utasítást ("ne tegyél semmit, amíg nem szólok") kiesett az aktív kontextusból, amikor az előzményt tömörítették. A megkötés, amelynek az utolsónak kellett volna maradnia, közönséges előzményként kezelték és összefoglalták.
Tehát egy naiv "foglaljon össze mindent, ami N fordulónál régebbi" veszélyes. A tömörítőnek tudnia kell, mit nem szabad soha eldobnia:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactEz különbözik az előző szakaszban leírt túlcsordulási problémától. A túlcsordulás arról szól, hogy elfogy a hely; a romlás arról, hogy a modell rosszabbodik, miközben még van hely. Lehet az ablak 60%-ánál és már rosszul gondolkodhat.
Megjegyzés: A tömörítés, amely eldobja a biztonsági megkötést, más hibaosztály, mint a tömörítés, amely elveszít egy elavult keresési eredményt. Jelölje meg a megkötéseket, a feladatspecifikációt és minden "ne tedd X" utasítást rögzítettként, és zárja ki őket teljesen az összefoglalóból.
A tömörítés, amely eldobja a biztonsági utasítást, rosszabb a tömörítés hiányánál. Védje a rögzített megkötéseket tömörítéskor.
Állapotvesztés újraindításkor: amikor egy összeomlás nulláról kell kezdeni
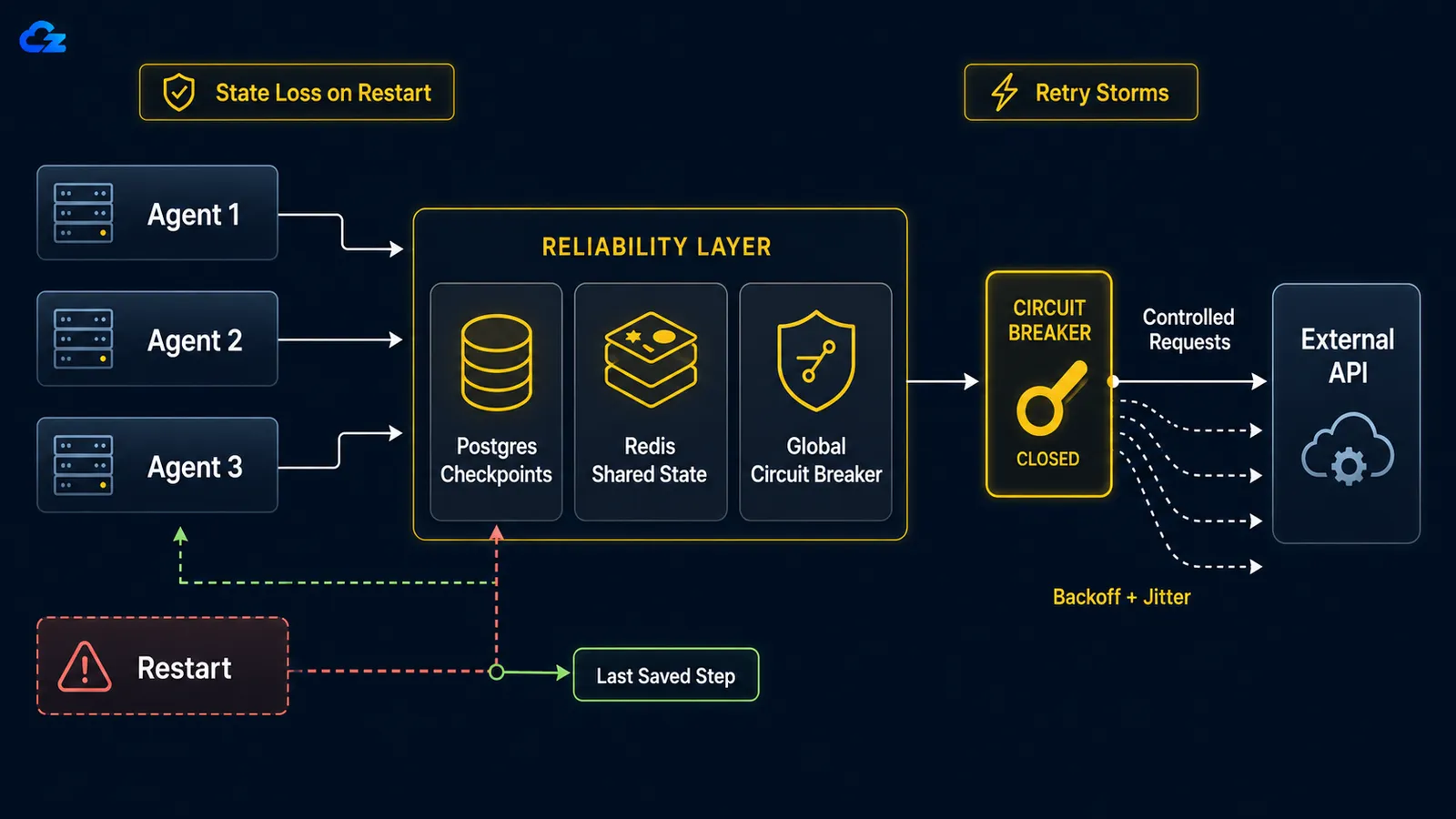
Ha egy hosszan futó ügynök összeomlik, legyen az újraindítás, OOM-leállítás vagy megszakadt hálózati kapcsolat, alapértelmezés szerint nincs ellenőrzőpontból való folytatás. A hurok nulláról indul: megismétli a már elvégzett munkát, és ami rosszabb, újra végrehajthatja a már megtett műveleteket, például kétszer küldi el ugyanazt az e-mailt vagy újra lefuttat egy fizetős API-hívást. A megoldás az ellenőrzőpontozás: mentse el a hurok állapotát minden lépés után, hogy egy újraindítás ott folytassa, ahol abbahagyta, nem nulláról.
A LangGraph-ban az ellenőrzőpont-háttér megválasztása a fejlesztési és a produkciós út közötti választás. A LangGraph perzisztencia-dokumentációja úgy írja le a SqliteSaver mint "kísérletezéshez és helyi munkafolyamatokhoz ideális", és a PostgresSaver mint "éles üzemhez ideális," és az utóbbit futtatja maga a LangSmith is. A kettő kódban szándékosan párhuzamos, ami könnyen láthatóvá teszi a különbséget:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverKét részlet, amely megcsíp embereket. Először is, az ellenőrzőpont-csomagok a LangGraph magtól külön telepítendők (langgraph-checkpoint-sqlite és langgraph-checkpoint-postgres saját függőségek), tehát egy friss szerveren nem lesz meg a Postgres-mentő, amíg hozzá nem adja. Másodszor, minden ellenőrzőpont-művelethez kell egy thread_id a config-ban. Ez az azonosító köti az adott futást a mentett állapothoz, és egy helytelen thread_id nélküli újraindítás semmit nem tölt vissza.
Profi tipp: A LangGraph ellenőrzőpont-csomagjai külön telepítendők.
langgraph-checkpoint-postgresnem kerül be az alaplanggraphcsomag telepítésekor, tehát rögzítse a produkciós requirements fájlban, mielőtt egy incidens során a nehezebb módon derül ki.
Az n8n-nek ugyanez a fejlesztési/produkciós megosztása van, csak más neveken. A beépített memóriaopciója szintén Simple Memory (vagy Buffer Window Memory) nevet visel, és a produkciós út a Postgres Chat Memory csomópont az újraindítást is túlélő állapothoz. A beépített memória a futó folyamatban tartja a beszélgetést, ami tesztelésre megfelelő, de 24/7-es munkaterhelésnél kockázat. Az n8n-ügynököket éles üzemben futtató szakemberek arról számolnak be, hogy Postgres-alapú tárolóra kellett átállniuk, miután a folyamaton belüli memória annyira megnőtt, hogy magával rántotta az egész példányt. Ha n8n-t használ, és az ügynöknek bármit is emlékeznie kell az újraindítások között, kezdettől fogva kösse a Postgres Chat Memory-hoz.
Az SQLite-ellenőrzőpontozás fejlesztési kényelmi megoldás. A produkciós újraindítás túléléséhez Postgres (LangGraph) vagy Postgres-alapú tároló (n8n) szükséges.
Újrapróbálkozási viharok: amikor saját ügynökei DDoS-olnak egy leállt szolgáltatást
Ha egy alsóbb szintű szolgáltatás leáll, a naiv futásonkénti újrapróbálkozások az ügynökflottáját önsugárzó szolgáltatásmegtagadássá változtatják. A megoldásnak két fele van: exponenciális visszalépés jitterrel minden ügynökön az újrapróbálkozások időbeli elosztásához, és egy globális megszakító, amely meghúzódik egy megosztott hibaszám után, és megakadályozza az egész csordát abban, hogy egy nyilvánvalóan leállt szolgáltatást ostromoljon.
A matematika könyörtelen. Ahogy egy újrapróbálkozási minták leírása fogalmaz: tíz párhuzamos ügynök, egyenként tíz újrapróbálkozással, száz kéréssel zúdul egy már padlón lévő szolgáltatásra, mert minden ügynök visszalépése futásonkénti, nem globális. Önmagában a per-ügynök visszalépés nem oldja meg. Tíz ügynök, amelyek egyenként szépen visszalépnek, mégis egyszerre lép vissza, ha mind egyszerre indultak, így szinkronizált hullámokban próbálnak újra. A jitter megszakítja a szinkronizációt az egyes ügynökök várakozási idejét véletlenszerűsítve; a megszakító megszakítja a csordát azáltal, hogy egy közös hibainformációt oszt meg köztük.
A visszalépés fele Pythonban megoldott probléma; a tenacity könyvtár tisztán kezeli az exponenciálist jitterrel:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)A megszakítónak globálisnakkell lennie: megosztottnak minden ügynök között, nem példányosítva minden futásnál. Ha a hibák átlépnek egy küszöböt, kinyílik, minden ügynök gyorsan kudarcot vall a hívás helyett, és egy lehűlési idő után beenged egyetlen szondát, hogy tesztelje, visszatért-e a szolgáltatás. Egy megszakító, amely minden ügynök saját folyamatában él, semmit nem véd, mert semmi nincs megosztva; a leállt szolgáltatás mégis megkapja a teljes száz kérést.
A futásonkénti visszalépés még mindig engedi, hogy tíz ügynök egyszerre verje a leállt szolgáltatást. A megszakítónak globálisnak kell lennie a csorda megállításához.
A hat hiba egy pillantásra
Az infrastrukturális rész előtt itt a teljes katalógus egy helyen: a hiba, az azt okozó mechanizmus, a keretrendszer-javítás és az, hogy az adott paraméter hol található az egyes keretrendszerekben.
| Meghibásodási mód | Mechanizmus | Keretrendszer-javítás | Keretrendszer-paraméter |
|---|---|---|---|
| Végtelen hurok | Nincs lépéskorlát vagy haladás-ellenőrzés | Kemény korlát + haladás-figyelés | LangGraph recursion_limit (25) / n8n Max Iterations |
| Kontextus-túlcsordulás | Az előzmény addig nő, amíg az ablak megtelik | Időközönkénti tömörítés | Alkalmazásszintű (tömörítés ~50%-nál) |
| Néma eszközhiba | Üres/halvány visszatérések érvényes nullműveletként olvasódnak | Ellenőrzési kapu minden eszközeredménynél | Alkalmazásszintű eszközburkoló |
| Gondolkodási romlás | A figyelem romlik a kontextus növekedésével ("kontextusromlás") | Közbülső tömörítés a rögzített megkötések védelmével | Alkalmazásszintű, megkötés-tudatos |
| Állapotvesztés újraindításkor | Nincs ellenőrzőpont; a hurok nulláról indul újra | Tartós ellenőrzőpontozás | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Újrapróbálkozási vihar | A futásonkénti újrapróbálkozások egy leállt szolgáltatásnál kaszkádba kapcsolódnak | Visszalépés + jitter + globális megszakító | tenacity + megosztott megszakító-állapot |
Megjegyzés CrewAI, AutoGen, Dify vagy saját Python-hurkot használó olvasóknak: a keretrendszer paraméterei változnak, de a hat minta nem. A deduplikáció, az időközönkénti tömörítés, a sémaellenőrzés, a megkötés-tudatos tömörítés, az ellenőrzőpontozás és a globális megszakító keretrendszer-agnosztikus fogalmak. Az itt szereplő LangGraph és n8n részletek konkrét kapaszkodók, nem a minták alkalmazhatóságának határa.
Egy produkciós ügynök-telepítés méretezése
A fenti minden minta azt feltételezi, hogy Ön kezeli a folyamatfelügyelőt, az adatbázist és az újraindítási viselkedést. Az ellenőrzőpontozás semmit nem ér, ha egy összeomlott hurok sosem indul újra, és a globális megszakítónak szüksége van egy helyre a megosztott állapot tárolásához. Ez a kontroll pontosan az, amit az önálló üzemeltetés ad, és egy felügyelt doboz nem ad, tehát az utolsó döntés az a szerver méretezése, amely ezt 24/7-ben futtatja.
A legtöbb egy ügynökes telepítésnél (egy ügynök, LLM-hívások külső API-ra mennek, alap Postgres-ellenőrzőpontozás) elegendő egy kis példány: 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. A nehéz számítás a modelszolgáltató oldalán van; az Ön szervere irányít, ellenőrzőpontoz és állapotot tart, nem futtat inferenciát. Lépjen fel nagyjából 4 GB RAM, 2 vCPU, and 120 GB NVMe ha az ügynök állapotalapú és többlépéses Postgres-ellenőrzőpontozással plusz Redis session-hidratáláshoz, vagy ha párhuzamos munkafolyamatokat futtat, amelyek megosztják a hostot.
Az ok, amiért ez önkezelt VPS-t igényel egy korlátozott platform helyett, ugyanaz, amiért a javítások egyáltalán működnek: root hozzáférés kell. Saját Postgres az ellenőrzőpontozáshoz, saját Redis a session-állapothoz, és egy valódi folyamatfelügyelő, mint például a systemd or pm2, hogy ha egy hurok meghal, a felügyelő újraindítsa, és az utolsó ellenőrzőpontjából töltse vissza, ahelyett, hogy elölről kezdené a feladatot. Ez a teljes helyreállítási történet azon alapul, hogy Ön tulajdonosa a folyamat életciklusának.
Mivel az n8n-t saját piacterünkön one-click alkalmazásként futtatjuk, a beállítás ez a részben a mi oldalunkon a legrövidebb út: telepítse az n8n-t egy Cloudzy VPS-re azzal a Postgres-alapú konfigurációval, amelyre a produkciós útnak szüksége van, egy olyan példányon, ahol rendelkezik root hozzáféréssel a saját Redis és folyamat-felügyelet hozzáadásához. Ez ugyanaz az önállóan futtatott lábnyom, amelyet fentebb leírtunk, ahol Ön tulajdonosa az adatbázisnak és az újraindítási viselkedésnek, ami az ellenőrzőpontozást és az automatikus helyreállítást ténylegesen működővé teszi.
A keretrendszer-minták csak annyira megbízhatók, mint az a szerver, amelyen futnak. Az ellenőrzőpontozás semmit nem ér, ha a folyamat sosem indul újra.
Gyakran ismételt kérdések
Hogyan akadályozom meg, hogy a LangGraph-ügynök örökké körözzön?
Használjon két mechanizmust egyszerre. Állítsa be a recursion_limit mint kemény lépéskorlátot (az alapértelmezett 25), hogy egy elszabadult hurok ne égethessen korlátlan keretet, és adjon hozzá haladás-figyelést, amely kivonatolja az egyes eszköz-argumentum hívásokat, és leáll, ha ugyanaz a hívás megismétlődik egy közeli ablakban. A korlát önmagában egy védőhálló, amely az elpazarolt lépések után lép életbe, nem valódi hurok-védelem. A haladás-figyelés az, ami ténylegesen megállítja az elakadt hurkot.
Mi a megfelelő recursion_limit a LangGraph-hoz éles üzemben?
Nincs univerzális szám. Méretezze az ügynök által valaha szükséges maximális jogos lépések számára, plusz egy margóra, és kezelje szigorúan csak mint költségvédőt. A korlát emelése nem konvergáltat egy köröző ügynököt. Ha az ügynök magas korlátot ér el, a megoldás a haladás-figyelés, nem a magasabb korlát.
Miért ütközik folyamatosan a Max Iterations-ba az n8n AI-ügynököm?
A Max Iterations korlát elérése azt jelenti, hogy az ügynök nem konvergál: a korlát által engedett lépéseknél többet tesz meg megállás nélkül. Emelje a korlátot csak akkor, ha a feladatnak jogosan több lépésre van szüksége; egyébként kezelje jelzésként, hogy az ügynök elakadt. Figyeljen egy konkrét csapdára: GitHub-issue #22771 arról számol be, hogy ha az iterációs korlát "On Error: Continue" beállítással éri el a maximumot, a végrehajtás a Hiba kimenet helyett a Siker kimenethez irányulhat, így egy határon elakadt, sikertelen futás sikernek tűnhet a munkafolyamatban.
Hogyan tarthatom meg az ügynök állapotát az újraindítások között?
A LangGraph-ban használja a PostgresSaver ellenőrzőpontozást a SqliteSaverhelyett, amely helyi fejlesztésre készült. Az n8n-ben használja a Postgres Chat Memory csomópontot a folyamaton belüli beépített memória helyett. Mindkettőhöz tartós adatbázis szükséges, és a LangGraph-ban minden ellenőrzőpont-művelethez kell egy thread_id amely az adott futást a mentett állapothoz köti.
Mi okoz gondolkodási romlást hosszú ügynök-futásoknál?
A gondolkodási minőség romlik a kontextus növekedésével, még a kemény tokenkorlát elérése előtt is. Ez a "középen elveszett" hatás, amelynél a modell figyel egy hosszú kontextus elejére és végére, de elveszíti a közepét. Az Anthropic mérnöki blogja az alatta lévő mechanizmust "kontextusromlásként" írja le: mivel minden token figyel minden más tokenre, n² páros kapcsolatot kap, és a modell figyelme egyre vékonyabbra nyúlik, ahogy a kontextus megnyúlik. A megoldás a közbülső tömörítés, amely összefoglalja az elavult előzményt, miközben a rögzített megkötéseket és biztonsági utasításokat érintetlenül hagyja.


