
Salah satu aspek terpenting dalam machine learning adalah menghasilkan prediksi yang akurat dan andal. Satu pendekatan inovatif yang semakin banyak digunakan untuk tujuan ini adalah Bootstrap Aggregating, yang lebih dikenal sebagai bagging dalam machine learning. Artikel ini akan membahas apa itu bagging dalam machine learning, membandingkan bagging dan boosting dalam machine learning, memberikan contoh bagging classifier, menjelaskan cara kerja bagging, serta mengulas kelebihan dan kekurangan bagging dalam machine learning.
Apa Itu Bagging dalam Machine Learning?
Dua gambar ini adalah satu-satunya yang relevan dan digunakan dalam artikel populer. Satu atau keduanya bisa dipakai (satu di sini, satunya di tempat lain) jika tim Desain membuat versi Cloudzy dari gambar-gambar tersebut.
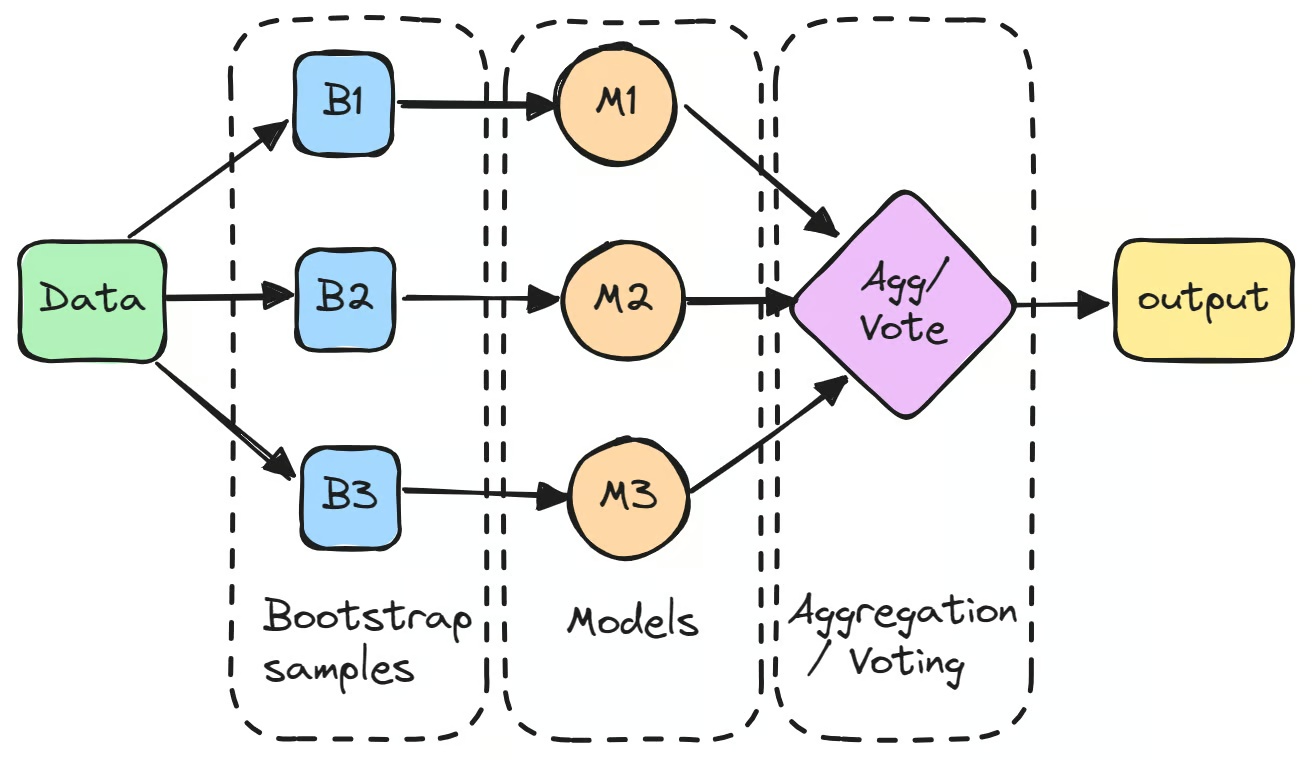
Apa itu Bagging?
Bayangkan Anda mencoba menebak berat suatu benda dengan meminta perkiraan dari banyak orang. Secara individual, tebakan mereka mungkin sangat beragam, tetapi dengan merata-ratakan semua perkiraan tersebut, Anda bisa mendapatkan angka yang jauh lebih akurat. Inilah inti dari bagging: menggabungkan output beberapa model untuk menghasilkan prediksi yang lebih tepat dan konsisten.
Prosesnya dimulai dengan membuat beberapa subset dari dataset asli melalui bootstrapping, yaitu pengambilan sampel acak dengan pengembalian. Setiap subset digunakan untuk melatih model terpisah secara independen.
Model-model individual ini, yang sering disebut sebagai "weak learner", mungkin tidak berkinerja terlalu baik secara sendiri karena variansi yang tinggi. Namun, ketika prediksi mereka digabungkan, umumnya dengan cara rata-rata untuk tugas regresi atau voting mayoritas untuk tugas klasifikasi, hasilnya sering kali melampaui performa model mana pun yang berdiri sendiri.
Salah satu contoh klasifikator bagging yang terkenal adalah algoritma Random Forest, yang membangun ensemble dari pohon keputusan untuk meningkatkan akurasi prediksi. Perlu dicatat, bagging tidak sama dengan boosting dalam machine learning. Boosting melatih model secara berurutan untuk mengurangi bias, sedangkan bagging melatih model secara paralel untuk mengurangi variansi.
Baik bagging maupun boosting dalam machine learning bertujuan meningkatkan performa model, tetapi keduanya menyasar aspek yang berbeda dari perilaku model.
Kenapa Bagging Berguna?
Salah satu keunggulan utama bagging dalam machine learning adalah kemampuannya mengurangi variansi, sehingga model dapat menggeneralisasi data baru dengan lebih baik. Bagging sangat bermanfaat saat bekerja dengan algoritma yang sensitif terhadap fluktuasi data pelatihan, seperti pohon keputusan.
Dengan mencegah overfitting, bagging menghasilkan model yang lebih stabil dan dapat diandalkan. Jika dibandingkan dengan boosting dalam machine learning, bagging berfokus pada pengurangan variansi dengan melatih banyak model secara paralel, sedangkan boosting bertujuan mengurangi bias dengan melatih model secara berurutan.
Contoh penerapan bagging dalam machine learning dapat dilihat pada prediksi risiko keuangan, di mana beberapa pohon keputusan dilatih pada subset data historis pasar yang berbeda. Dengan menggabungkan prediksi dari setiap model, bagging menghasilkan model prediksi yang lebih andal dan meminimalkan dampak kesalahan dari model individual.
Pada dasarnya, bagging dalam machine learning memanfaatkan kecerdasan kolektif dari banyak model untuk menghasilkan prediksi yang lebih akurat dan dapat diandalkan dibandingkan model individual mana pun.
Cara Kerja Bagging dalam Machine Learning: Langkah demi Langkah
Untuk memahami sepenuhnya bagaimana bagging meningkatkan performa model, mari kita uraikan prosesnya langkah demi langkah.
Ambil Beberapa Bootstrap Sample dari Dataset
Langkah pertama dalam bagging pada machine learning adalah membuat beberapa subset baru dari dataset asli menggunakan teknik bootstrapping. Teknik ini melibatkan pengambilan sampel data secara acak dengan pengembalian, sehingga beberapa titik data bisa muncul lebih dari sekali dalam subset yang sama, sementara yang lain mungkin tidak muncul sama sekali. Proses ini memastikan setiap model dilatih pada versi data yang sedikit berbeda.
Latih Model Terpisah pada Setiap Sample
Setiap bootstrap sample kemudian digunakan untuk melatih model tersendiri, biasanya bertipe sama, seperti pohon keputusan. Model-model ini, yang sering disebut "base learner" atau "weak learner", dilatih secara independen pada subset masing-masing. Contoh klasifikator bagging adalah pohon keputusan yang digunakan dalam algoritma Random Forest, yang menjadi tulang punggung banyak model berbasis bagging. Meski setiap model individual mungkin tidak bekerja optimal sendiri, masing-masing memberikan wawasan unik berdasarkan data pelatihan spesifiknya.
Gabungkan Prediksi
Setelah model dilatih, prediksi dari semua model digabungkan untuk membentuk output akhir.
- Untuk tugas regresi, prediksi dirata-ratakan untuk mengurangi variansi model.
- Untuk tugas klasifikasi, prediksi akhir ditentukan melalui majority voting, di mana kelas yang diprediksi oleh sebagian besar model yang dipilih. Metode ini menghasilkan prediksi yang lebih stabil dibandingkan output dari satu model saja.
Prediksi Akhir
Dengan menggabungkan prediksi dari banyak model, bagging mengurangi dampak kesalahan dari model mana pun dan meningkatkan akurasi secara keseluruhan. Proses agregasi inilah yang menjadikan bagging teknik yang sangat efektif, terutama dalam tugas machine learning yang menggunakan model bervariansi tinggi seperti pohon keputusan. Bagging secara efektif meratakan inkonsistensi dalam prediksi model individual, menghasilkan model akhir yang lebih kuat.
Meski bagging efektif untuk menstabilkan prediksi, ada beberapa hal yang perlu diperhatikan: risiko overfitting tetap ada jika model dasar terlalu kompleks, meskipun tujuan utama bagging adalah menguranginya.
Bagging juga membutuhkan sumber daya komputasi yang cukup besar, jadi menyesuaikan jumlah base learner atau mempertimbangkan metode ensemble yang lebih efisien bisa membantu, dan memilih GPU yang tepat untuk ML dan DL selalu penting.
Pastikan ada keberagaman model di antara base learner untuk hasil yang lebih baik. Jika bekerja dengan data yang tidak seimbang, teknik seperti SMOTE dapat membantu sebelum menerapkan bagging agar performa pada kelas minoritas tidak buruk.
Penerapan Bagging
Setelah memahami cara kerja bagging, saatnya melihat penerapannya di dunia nyata. Bagging telah digunakan di berbagai industri untuk meningkatkan akurasi dan stabilitas prediksi dalam skenario yang kompleks. Mari kita lihat beberapa aplikasi paling berdampak:
- Klasifikasi dan Regresi: Bagging banyak digunakan untuk meningkatkan performa klasifikator dan regresor dengan mengurangi variansi dan mencegah overfitting. Misalnya, Random Forest yang menggunakan bagging terbukti efektif dalam tugas seperti klasifikasi gambar dan pemodelan prediktif.
- Deteksi Anomali: Dalam bidang seperti deteksi penipuan dan deteksi intrusi jaringan, algoritma bagging menawarkan performa yang lebih unggul dengan cara mengidentifikasi outlier dan anomali dalam data secara efektif.
- Penilaian Risiko Keuangan: Teknik bagging digunakan di perbankan untuk meningkatkan model credit scoring, memperbaiki akurasi proses persetujuan pinjaman dan evaluasi risiko keuangan.
- Diagnostik Medis: Di bidang kesehatan, bagging telah diterapkan untuk mendeteksi gangguan neurokognitif seperti penyakit Alzheimer dengan menganalisis dataset MRI, membantu dalam diagnosis dini dan perencanaan pengobatan.
- Pemrosesan Bahasa Alami (NLP): Bagging berkontribusi pada tugas-tugas seperti klasifikasi teks dan analisis sentimen dengan menggabungkan prediksi dari beberapa model, menghasilkan pemahaman bahasa yang lebih akurat.
Kelebihan dan Kekurangan Bagging
Seperti teknik machine learning lainnya, bagging memiliki kelebihan dan kekurangannya sendiri. Memahami keduanya dapat membantu menentukan kapan dan bagaimana menggunakan bagging dalam model Anda.
Keuntungan Bagging:
- Mengurangi Variansi dan Overfitting: Salah satu keunggulan terbesar bagging dalam machine learning adalah kemampuannya mengurangi variansi, yang membantu mencegah overfitting. Dengan melatih beberapa model pada subset data yang berbeda, bagging memastikan model tidak terlalu sensitif terhadap fluktuasi dalam data pelatihan, sehingga menghasilkan model yang lebih stabil dan mampu digeneralisasi.
- Efektif untuk Model Bervariansi Tinggi: Bagging sangat efektif ketika digunakan bersama model bervariansi tinggi seperti decision tree. Model-model ini cenderung overfit terhadap data dan memiliki variansi yang tinggi, tetapi bagging mengatasi hal ini dengan merata-ratakan atau melakukan voting dari beberapa model. Ini membuat prediksi lebih andal dan tidak mudah terpengaruh oleh noise dalam data.
- Meningkatkan Stabilitas dan Performa Model: Dengan menggabungkan beberapa model yang dilatih pada subset data berbeda, bagging sering menghasilkan performa keseluruhan yang lebih baik. Teknik ini membantu meningkatkan akurasi prediksi sekaligus mengurangi sensitivitas model terhadap perubahan kecil dalam dataset, yang pada akhirnya membuat model lebih andal.
Kelemahan Bagging:
- Meningkatkan Biaya Komputasi: Karena bagging mengharuskan pelatihan beberapa model sekaligus, biaya komputasinya pun meningkat secara alami. Melatih dan menggabungkan prediksi dari banyak model bisa memakan waktu, terutama saat menggunakan dataset berukuran besar atau model kompleks seperti decision tree.
- Kurang Efektif untuk Model Bervariansi Rendah: Meskipun bagging sangat efektif untuk model bervariansi tinggi, teknik ini tidak memberikan banyak manfaat ketika diterapkan pada model bervariansi rendah seperti regresi linear. Dalam kasus ini, model individual sudah memiliki tingkat kesalahan yang rendah, sehingga menggabungkan prediksi tidak banyak meningkatkan hasilnya.
- Hilang Interpretabilitas Dengan menggabungkan beberapa model, bagging dapat mengurangi keterbacaan model akhir. Misalnya, dalam Random Forest, proses pengambilan keputusan didasarkan pada banyak decision tree, sehingga lebih sulit untuk melacak alasan di balik prediksi tertentu.
Kapan Sebaiknya Menggunakan Bagging?
Mengetahui kapan harus menerapkan bagging dalam proyek machine learning adalah kunci untuk mendapatkan hasil yang optimal. Teknik ini bekerja baik dalam situasi tertentu, tetapi tidak selalu menjadi pilihan terbaik untuk setiap masalah.
Ketika Model Rentan terhadap Overfitting
Salah satu kasus penggunaan utama bagging adalah ketika model Anda rentan terhadap overfitting, terutama pada model bervariansi tinggi seperti decision tree. Model-model ini mungkin bekerja baik pada data pelatihan, tetapi sering gagal digeneralisasi ke data baru karena terlalu menyesuaikan diri dengan pola spesifik dari data pelatihan.
Bagging membantu mengatasi masalah ini dengan melatih beberapa model pada subset data yang berbeda, lalu menggabungkan hasilnya melalui rata-rata atau voting untuk menghasilkan prediksi yang lebih stabil. Ini mengurangi risiko overfitting dan membuat model lebih mampu menangani data baru yang belum pernah dilihat sebelumnya.
Saat Anda Ingin Meningkatkan Stabilitas dan Akurasi
Jika Anda ingin meningkatkan stabilitas dan akurasi model tanpa terlalu mengorbankan interpretabilitas, bagging adalah pilihan yang tepat. Dengan menggabungkan prediksi dari beberapa model, hasil akhirnya menjadi lebih andal, yang sangat berguna saat menangani data yang banyak mengandung noise.
Baik untuk masalah klasifikasi maupun regresi, bagging dapat menghasilkan hasil yang lebih konsisten, meningkatkan akurasi sekaligus menjaga efisiensi.
Saat Anda Memiliki Sumber Daya Komputasi yang Cukup
Faktor penting lainnya dalam memutuskan apakah akan menggunakan bagging adalah ketersediaan sumber daya komputasi. Karena bagging memerlukan pelatihan beberapa model secara bersamaan, biaya komputasinya bisa cukup besar, terutama dengan dataset berukuran besar atau model yang kompleks.
Jika Anda memiliki daya komputasi yang memadai, manfaat bagging jauh lebih besar daripada biayanya. Namun, jika sumber daya terbatas, Anda mungkin perlu mempertimbangkan teknik alternatif atau membatasi jumlah model dalam ensemble Anda.
Saat Anda Bekerja dengan Model Bervariansi Tinggi
Bagging sangat berguna saat bekerja dengan model yang memiliki variansi tinggi dan sensitif terhadap fluktuasi dalam data pelatihan. Decision tree, misalnya, sering digunakan bersama bagging dalam bentuk Random Forest karena performanya cenderung sangat bervariasi tergantung pada data pelatihan.
Dengan melatih beberapa model pada subset data yang berbeda lalu menggabungkan prediksinya, bagging meredam variansi tersebut dan menghasilkan model yang lebih konsisten.
Saat Anda Membutuhkan Classifier yang Andal
Jika Anda mengerjakan masalah klasifikasi dan membutuhkan classifier yang andal, bagging dapat meningkatkan stabilitas prediksi secara signifikan. Contohnya, Random Forest, yang merupakan salah satu contoh bagging classifier, dapat memberikan prediksi yang lebih akurat dengan menggabungkan hasil dari banyak decision tree individual.
Pendekatan ini bekerja dengan baik ketika model-model individual mungkin lemah secara sendiri-sendiri, tetapi kekuatan gabungannya menghasilkan model keseluruhan yang jauh lebih kuat.
Selain itu, jika Anda mencari platform yang tepat untuk mengimplementasikan teknik bagging secara efisien, tools seperti Databricks dan Snowflake menyediakan platform analitik terpadu yang sangat berguna untuk mengelola dataset besar dan menjalankan metode ensemble seperti bagging.
Jika Anda mencari pendekatan machine learning yang tidak terlalu teknis, alat AI tanpa kode bisa menjadi pilihan. Meskipun tidak berfokus langsung pada teknik lanjutan seperti bagging, banyak platform no-code yang memungkinkan pengguna bereksperimen dengan metode ensemble learning, termasuk bagging, tanpa memerlukan keahlian coding yang mendalam.
Ini memungkinkan Anda menerapkan teknik yang lebih canggih dan tetap menghasilkan prediksi yang akurat, dengan fokus pada performa model daripada kode di baliknya.
Pemikiran Akhir
Bagging dalam machine learning adalah teknik yang efektif untuk meningkatkan performa model dengan mengurangi variansi dan meningkatkan stabilitas. Dengan menggabungkan prediksi dari beberapa model yang dilatih pada subset data berbeda, bagging menghasilkan hasil yang lebih akurat dan dapat diandalkan. Teknik ini sangat efektif untuk model bervariansi tinggi seperti decision tree, di mana ia membantu mencegah overfitting dan memastikan model dapat digeneralisasi dengan lebih baik ke data yang belum pernah dilihat.
Meski bagging memiliki keunggulan yang signifikan, seperti mengurangi overfitting dan meningkatkan akurasi, ada beberapa trade-off yang perlu dipertimbangkan. Bagging meningkatkan biaya komputasi karena melatih beberapa model sekaligus dan dapat mengurangi interpretabilitas. Terlepas dari kekurangan ini, kemampuannya meningkatkan performa menjadikannya teknik yang berharga dalam ensemble learning, berdampingan dengan metode lain seperti boosting dan stacking.
Pernahkah Anda menggunakan bagging dalam proyek machine learning? Bagikan pengalaman Anda dan ceritakan bagaimana hasilnya!


