
การเลือก GPU VPS อาจรู้สึกยากเมื่อเจอ spec sheet เต็มไปด้วยตัวเลข จำนวน core กระโดดจาก 2,560 ถึง 21,760 แต่ตัวเลขเหล่านั้นหมายความว่าอะไรกันแน่?
CUDA core คือหน่วยประมวลผลแบบขนานภายใน NVIDIA GPU ที่รันการคำนวณหลายพันรายการพร้อมกัน รองรับทุกอย่างตั้งแต่การเทรน AI ไปจนถึงการเรนเดอร์ 3D คู่มือนี้อธิบายการทำงานของ CUDA core ความแตกต่างจาก CPU core และ Tensor core รวมถึงจำนวน core ที่เหมาะกับการใช้งานของคุณโดยไม่ต้องจ่ายเกินความจำเป็น
CUDA Cores คืออะไร

CUDA cores คือหน่วยประมวลผลย่อยภายใน GPU ของ NVIDIA ที่ทำงานแบบขนานกัน แก่นแท้ของเทคโนโลยี CUDA core คืออะไร? ให้นึกภาพหน่วยเหล่านี้เป็นผู้ช่วยหลายคนที่รับงานชิ้นเดียวกันไปทำพร้อมกัน
NVIDIA เปิดตัว CUDA (Compute Unified Device Architecture) ในปี 2006 เพื่อนำพลังของ GPU มาใช้กับการคำนวณทั่วไปที่นอกเหนือจากงานกราฟิก ดู เอกสาร CUDA อย่างเป็นทางการ สำหรับรายละเอียดทางเทคนิคที่ครบถ้วน แต่ละหน่วยทำการคำนวณเลขคณิตพื้นฐานบนตัวเลขทศนิยม ซึ่งเหมาะอย่างยิ่งสำหรับการคำนวณที่ต้องทำซ้ำจำนวนมาก
GPU รุ่นใหม่ของ NVIDIA บรรจุหน่วยเหล่านี้ไว้หลายพันหน่วยในชิปเดียว GPU สำหรับผู้บริโภครุ่นล่าสุดมีมากกว่า 21,000 cores ในขณะที่ GPU สำหรับ data center ที่ใช้สถาปัตยกรรม Hopper มีสูงสุดถึง 16,896หน่วยเหล่านี้ทำงานร่วมกันผ่าน Streaming Multiprocessors (SMs)
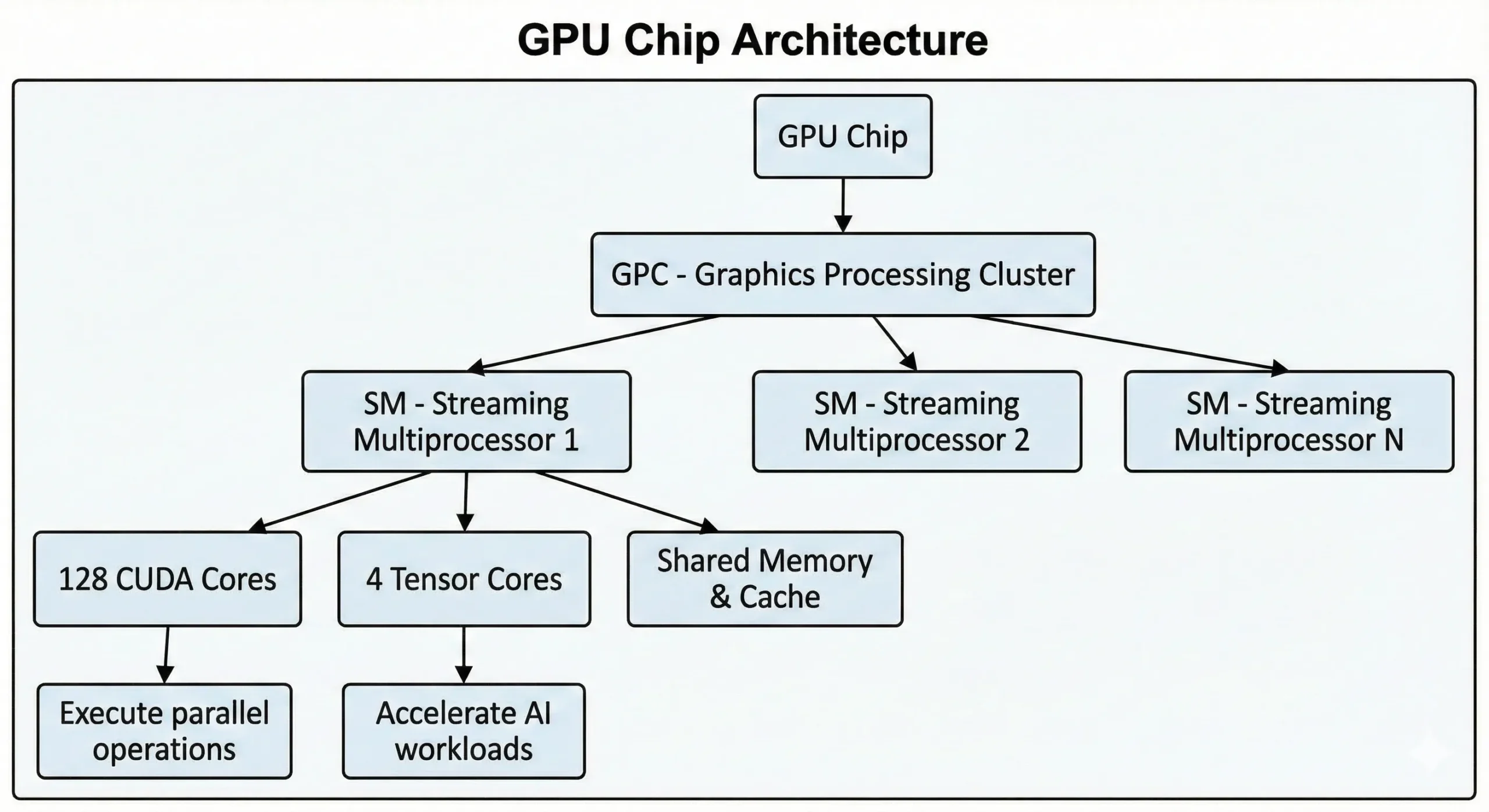
หน่วยเหล่านี้รันคำสั่งแบบ SIMT (Single Instruction, Multiple Threads) ผ่านการประมวลผลแบบขนาน คำสั่งเดียวถูกนำไปใช้กับข้อมูลหลายจุดพร้อมกัน เมื่อต้องเทรน neural network หรือเรนเดอร์ฉาก 3 มิติ การดำเนินการซ้ำๆ หลายพันรายการเกิดขึ้นพร้อมกัน งานเหล่านี้ถูกแบ่งออกเป็น stream ที่ทำงานพร้อมกัน แทนที่จะรันทีละขั้นตอน
CUDA Cores กับ CPU Cores: ต่างกันอย่างไร?

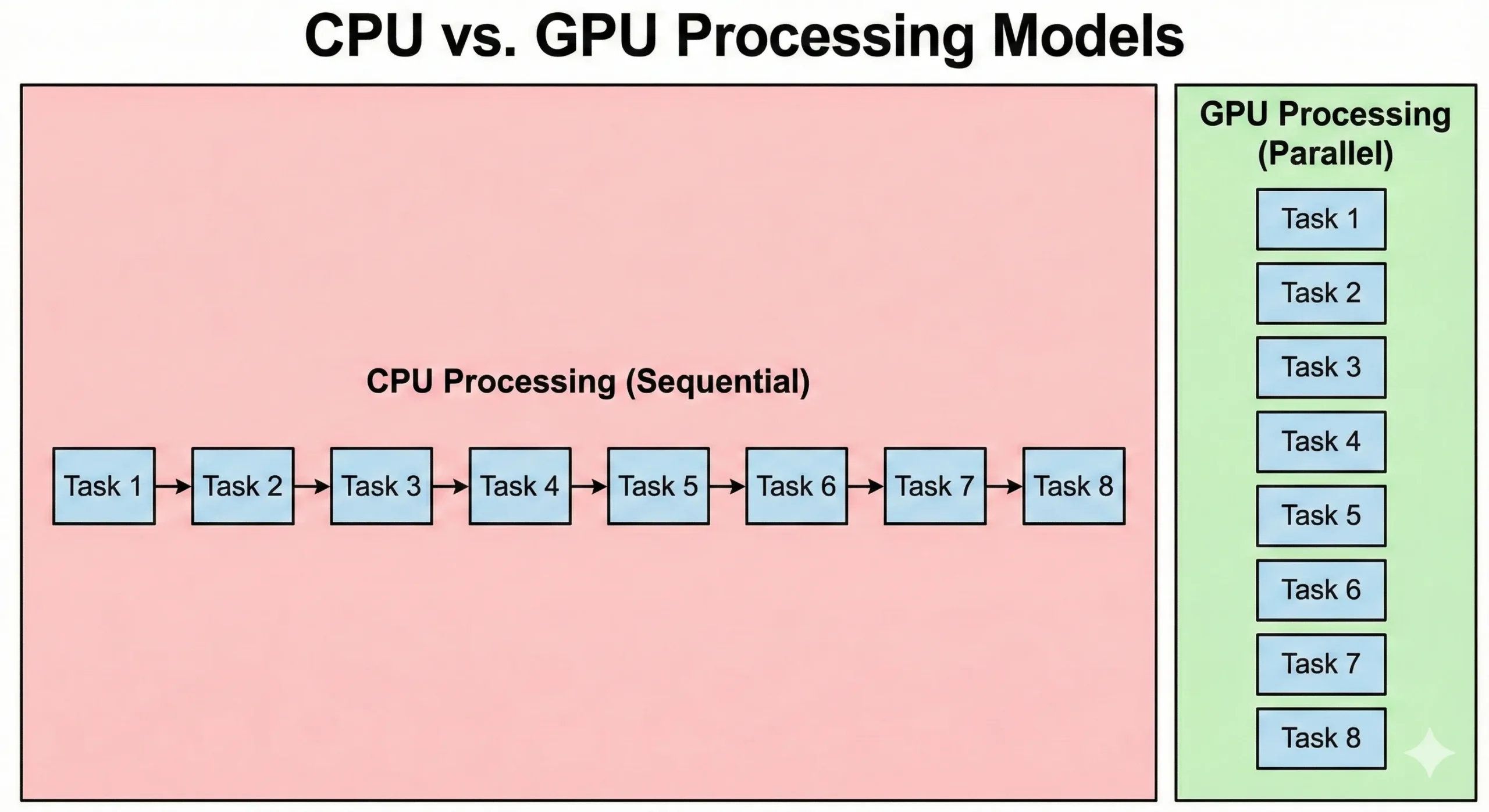
CPU และ GPU แก้ปัญหาด้วยวิธีที่แตกต่างกันโดยพื้นฐาน CPU เซิร์ฟเวอร์รุ่นใหม่อาจมี 8-128+ cores ที่ทำงานด้วยความเร็วสัญญาณนาฬิกาสูง ตัวประมวลผลเหล่านี้เก่งในงานที่ต้องทำตามลำดับ ซึ่งแต่ละขั้นตอนขึ้นอยู่กับผลลัพธ์ก่อนหน้า และจัดการ logic ที่ซับซ้อนและการแตกสาขาได้อย่างมีประสิทธิภาพ
GPU ใช้แนวทางตรงกันข้าม บรรจุ CUDA cores ที่เรียบง่ายกว่าหลายพันหน่วยซึ่งทำงานด้วยความเร็วสัญญาณนาฬิกาที่ต่ำกว่า หน่วยเหล่านี้ชดเชยความเร็วที่ต่ำกว่าด้วยการประมวลผลแบบขนาน เมื่อทำงานพร้อมกัน 16,000 หน่วย throughput รวมจะสูงกว่าความสามารถของ CPU ทั่วไป
CPU รันโค้ดระบบปฏิบัติการและ logic ของแอปพลิเคชันที่ซับซ้อน ในขณะที่ GPU เน้น throughput เป็นหลัก overhead จากการเริ่มงานและการ synchronize ส่งผลให้ latency สูงกว่า การประมวลผลกราฟิกแบบขนานให้ความสำคัญกับการเคลื่อนย้ายข้อมูล แม้จะใช้เวลาเริ่มต้นนานกว่า แต่ประมวลผล dataset ขนาดใหญ่ได้เร็วกว่า CPU
| ฟีเจอร์ | แกนประมวลผล CPU | CUDA Cores |
| จำนวนต่อชิป | 4-128+ แกน | 2,560-21,760 แกน |
| ความเร็วนาฬิกา | 3.0-5.5 GHz | ١٫٤ ถึง ٢٫٥ GHz |
| รูปแบบการประมวลผล | คำสั่งแบบลำดับ ซับซ้อน | คำสั่งแบบขนาน เรียบง่าย |
| เหมาะสำหรับ | ระบบปฏิบัติการ งาน single-threaded | การคำนวณเมทริกซ์ การประมวลผลข้อมูลแบบขนาน |
| ความล่าช้า | Low (ไมโครวินาที) | สูงกว่า (overhead จากการเริ่มงาน) |
| สถาปัตยกรรม | วัตถุประสงค์ทั่วไป | เหมาะสำหรับการคำนวณซ้ำๆ โดยเฉพาะ |
เทคโนโลยี Virtual GPU (vGPU) และ Multi-Instance GPU (MIG) จัดการการแบ่งทรัพยากรและการกำหนดเวลาเพื่อกระจาย GPU ให้ผู้ใช้หลายคน การตั้งค่านี้ช่วยให้ทีมใช้งานฮาร์ดแวร์ได้อย่างเต็มประสิทธิภาพ ไม่ว่าจะเป็นแบบ time-sliced sharing หรือ dedicated hardware instance ขึ้นอยู่กับการกำหนดค่า
การเทรน neural network ต้องใช้การคูณเมทริกซ์นับพันล้านครั้ง GPU ที่มี 10,000 หน่วยไม่ได้แค่รัน 10,000 การดำเนินการพร้อมกัน แต่จัดการ thread แบบขนานหลายพันรายการที่จัดกลุ่มเป็น "warps" เพื่อเพิ่ม throughput ให้สูงสุด parallelism ขนาดนี้คือเหตุผลที่นักพัฒนา AI ต้องรู้จัก GPU เป็นอย่างดี
CUDA Cores กับ Tensor Cores: ความแตกต่างที่ควรรู้

NVIDIA GPU ประกอบด้วยหน่วยเฉพาะทางสองประเภทที่ทำงานร่วมกัน ได้แก่ CUDA cores มาตรฐาน และ Tensor cores ทั้งสองไม่ได้แข่งขันกัน แต่ถูกออกแบบมาเพื่อรองรับงานคนละส่วน
CUDA cores มาตรฐานเป็นหน่วยประมวลผลแบบขนานทั่วไป รองรับการคำนวณ FP32 และ FP64 การคำนวณเลขจำนวนเต็ม และการแปลงพิกัด เทคโนโลยี CUDA พื้นฐานนี้คือรากฐานของการประมวลผล GPU ครอบคลุมทุกอย่างตั้งแต่การจำลองฟิสิกส์ไปจนถึงการเตรียมข้อมูล โดยไม่ต้องพึ่งการเร่งความเร็วแบบเฉพาะทาง
Tensor cores เป็นหน่วยเฉพาะทางที่ออกแบบมาสำหรับการคูณเมทริกซ์และงาน AI โดยเฉพาะ เปิดตัวครั้งแรกใน Volta architecture ของ NVIDIA (2017) และทำงานได้ดีเป็นพิเศษกับการคำนวณความแม่นยำ FP16 และ TF32 รุ่นล่าสุดรองรับ FP8 เพื่อให้ AI inference เร็วยิ่งขึ้น
| ฟีเจอร์ | CUDA Cores | Tensor Cores |
| วัตถุประสงค์ | การประมวลผลแบบขนานทั่วไป | การคูณเมทริกซ์สำหรับ AI |
| ความแม่นยำ | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| ความเร็วสำหรับ AI | 1x พื้นฐาน | เร็วกว่า CUDA cores 2-10 เท่า |
| กรณีการใช้งาน | การเตรียมข้อมูล, ML แบบดั้งเดิม | การเทรนและ inference สำหรับ Deep learning |
| ความพร้อมใช้งาน | NVIDIA GPU ทุกรุ่น | RTX ซีรีส์ 20 ขึ้นไป และ GPU สำหรับ datacenter |
GPU รุ่นใหม่รวมทั้งสองประเภทไว้ด้วยกัน RTX 5090 มี CUDA cores มาตรฐาน 21,760 หน่วย พร้อม Tensor cores รุ่นที่ 5 จำนวน 680 หน่วย ส่วน H100 จับคู่ CUDA cores มาตรฐาน 16,896 หน่วยกับ Tensor cores รุ่นที่ 4 จำนวน 528 หน่วยสำหรับการเร่งความเร็ว deep learning
เมื่อเทรน neural network Tensor cores รับหน้าที่หนักในช่วง forward pass และ backward pass ผ่านโมเดล ส่วน CUDA cores มาตรฐานดูแลการโหลดข้อมูล การเตรียมข้อมูล การคำนวณ loss และการอัปเดต optimizer ทั้งสองประเภททำงานร่วมกัน โดย Tensor cores เร่งความเร็วในส่วนที่ใช้การคำนวณสูง
สำหรับอัลกอริทึม machine learning แบบดั้งเดิม เช่น random forests หรือ gradient boosting CUDA cores มาตรฐานจะรับหน้าที่ทั้งหมด เพราะงานเหล่านี้ไม่ได้ใช้รูปแบบการคูณเมทริกซ์ที่ Tensor cores ถนัด แต่สำหรับ transformer models และ convolutional neural networks Tensor cores ช่วยเพิ่มความเร็วได้อย่างเห็นได้ชัด
CUDA Cores ใช้ทำอะไรได้บ้าง?

CUDA cores เหมาะกับงานที่ต้องการการคำนวณแบบเดิมซ้ำกันจำนวนมากพร้อมกัน งานใดก็ตามที่เกี่ยวข้องกับการดำเนินการเมทริกซ์หรือการคำนวณตัวเลขซ้ำ ๆ ล้วนได้ประโยชน์จากสถาปัตยกรรมนี้
AI และการประยุกต์ใช้ Machine Learning
Deep learning พึ่งพาการคูณเมทริกซ์ทั้งในขั้นตอนการเทรนและ inference เมื่อเทรน neural network แต่ละ forward pass ต้องการการดำเนินการ multiply-add นับล้านครั้งผ่าน weight matrices และ backpropagation ยังเพิ่มการดำเนินการอีกนับล้านครั้งใน backward pass
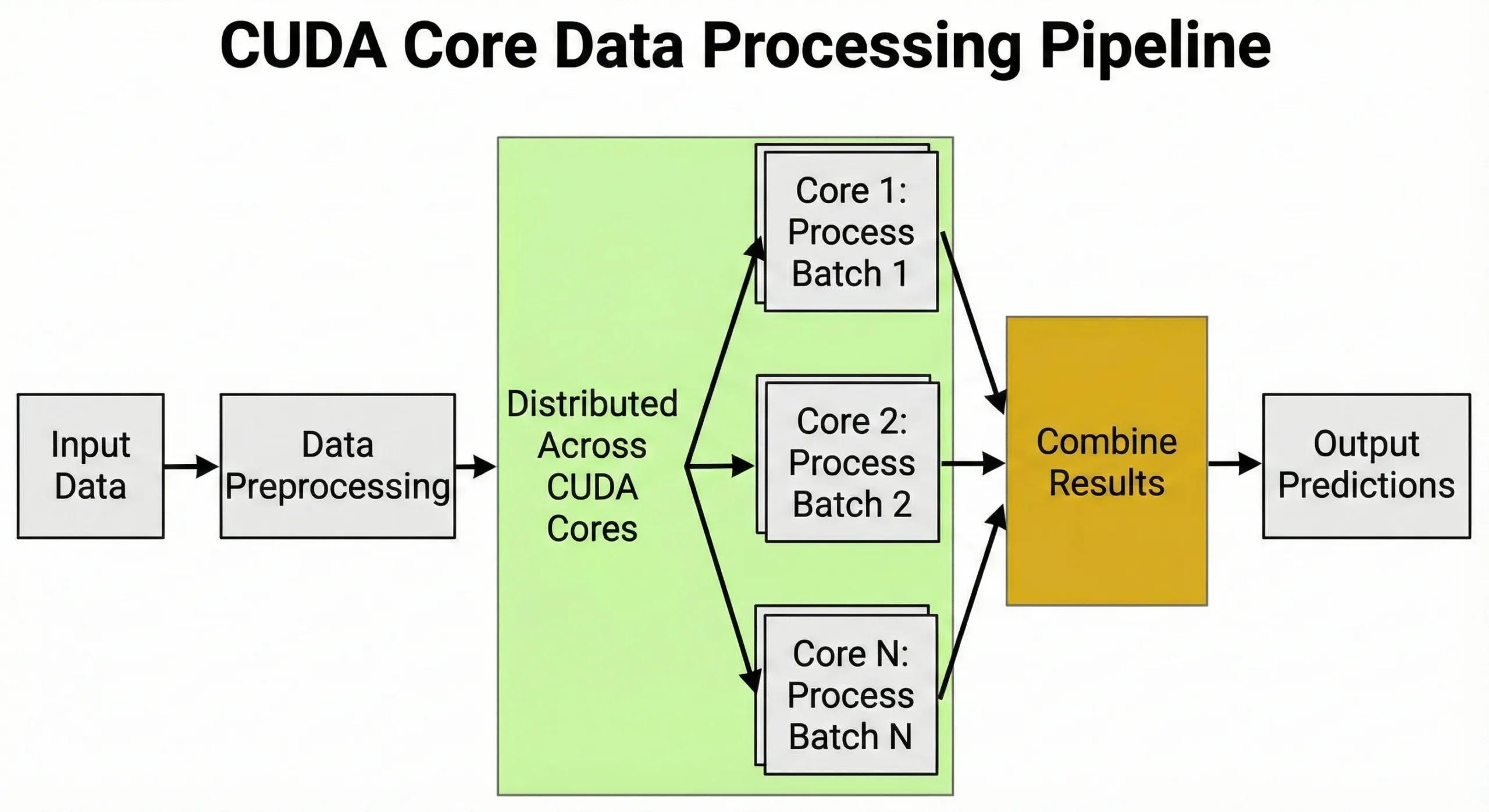
CUDA cores ดูแลการเตรียมข้อมูล แปลงภาพเป็น tensor ปรับค่า normalization และใช้ augmentation transforms ความสามารถในการจัดการงานหลายพันรายการพร้อมกันนี้คือสาเหตุที่ GPU มีความสำคัญต่องาน AI
ระหว่างการเทรน CUDA cores ควบคุม learning rate schedules การคำนวณ gradient และการอัปเดตสถานะ optimizer
สำหรับ VPS ที่ใช้งาน AI inference เช่น ระบบแนะนำสินค้าหรือ chatbot CUDA cores ประมวลผลคำขอพร้อมกัน รันการทำนายได้หลายร้อยรายการในเวลาเดียวกัน คู่มือของเราเรื่อง GPU ที่ดีที่สุดสำหรับ AI 2025 อธิบายว่าการกำหนดค่าแบบไหนเหมาะกับโมเดลขนาดต่าง ๆ
หน่วยประมวลผล 16,896 หน่วยของ H100 ร่วมกับ Tensor cores ช่วยให้เทรนโมเดลขนาด 7 พันล้านพารามิเตอร์ได้ภายในสัปดาห์แทนที่จะเป็นเดือน การอินเฟอเรนซ์แบบเรียลไทม์สำหรับแชทบอตที่รองรับผู้ใช้หลายพันคนพร้อมกันก็ต้องการพลังการประมวลผลแบบขนานในระดับเดียวกัน
การคำนวณทางวิทยาศาสตร์และการวิจัย
นักวิจัยใช้โปรเซสเซอร์เหล่านี้สำหรับการจำลองพลศาสตร์ของโมเลกุล การสร้างแบบจำลองสภาพอากาศ และการวิเคราะห์จีโนมิกส์ การคำนวณแต่ละรายการทำงานอิสระจากกัน จึงเหมาะอย่างยิ่งสำหรับการประมวลผลแบบขนาน สถาบันการเงินใช้รันการจำลอง Monte Carlo ที่มีสถานการณ์นับล้านไปพร้อมกัน
การเรนเดอร์ 3D และการผลิตวิดีโอ
Ray tracing คำนวณการสะท้อนของแสงในฉาก 3D ด้วยการติดตามรังสีอิสระผ่านแต่ละพิกเซล แม้ว่า RT cores เฉพาะทางจะจัดการการตรวจสอบทิศทางรังสี แต่หน่วยมาตรฐานจะดูแลการสุ่มตัวอย่างพื้นผิวและการคำนวณแสง การแบ่งหน้าที่นี้เป็นตัวกำหนดความเร็วในการเรนเดอร์ฉากที่มีรังสีนับล้านเส้น
NVENC จัดการการเข้ารหัสสำหรับ H.264 และ H.265 ส่วนสถาปัตยกรรมล่าสุดอย่าง Ada Lovelace และ Hopper รองรับ AV1 ในระดับฮาร์ดแวร์ CUDA ช่วยด้านเอฟเฟกต์ ฟิลเตอร์ การปรับขนาด การลดสัญญาณรบกวน การแปลงสี และการเชื่อมต่อในไปป์ไลน์ ด้วยการทำงานร่วมกันระหว่างเอนจินเข้ารหัสและโปรเซสเซอร์แบบขนาน จึงช่วยเร่งความเร็วในการผลิตวิดีโอได้อย่างมีนัยสำคัญ
การเรนเดอร์ 3D ใน Blender หรือ Maya กระจายการคำนวณ surface shader นับพันล้านรายการไปยังหน่วยประมวลผลที่มีอยู่ทั้งหมด ระบบอนุภาคได้ประโยชน์จากสิ่งนี้เช่นกัน เนื่องจากสามารถจำลองอนุภาคหลายพันตัวที่โต้ตอบกันได้พร้อมกัน ฟีเจอร์เหล่านี้คือหัวใจสำคัญของงานสร้างสรรค์ดิจิทัลระดับสูง
CUDA Cores ส่งผลต่อประสิทธิภาพของ GPU อย่างไร

จำนวน core บอกแนวโน้มความสามารถในการประมวลผลแบบขนานได้คร่าวๆ แต่การประเมิน CUDA cores ต้องพิจารณาให้มากกว่าแค่ตัวเลข clock speed แบนด์วิดท์หน่วยความจำ ประสิทธิภาพสถาปัตยกรรม และการปรับแต่งซอฟต์แวร์ ล้วนมีบทบาทสำคัญ
GPU ที่มี 10,000 หน่วยรันที่ 2.0 GHz ให้ผลลัพธ์ต่างจากรุ่นที่มี 10,000 หน่วยเช่นกันแต่รันที่ 1.5 GHz clock speed ที่สูงกว่าหมายความว่าแต่ละหน่วยทำการคำนวณได้มากกว่าต่อวินาที สถาปัตยกรรมรุ่นใหม่ยังทำงานได้มากขึ้นในแต่ละรอบสัญญาณนาฬิกาผ่านการจัดตารางคำสั่งที่ดีขึ้น
ตรวจสอบว่าอุปกรณ์ทำงานอยู่ตลอดเวลาหรือไม่ แต่ควรทราบว่า nvidia-smi utilization เป็นเมตริกแบบหยาบ โดยวัดเป็นเปอร์เซ็นต์ของเวลาที่ kernel ทำงานอยู่ ไม่ใช่จำนวน core ที่ประมวลผลจริง
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderตัวอย่างผลลัพธ์: 85%, 92% (เวลาที่ active 85%, activity ของ memory controller 92%)
หาก GPU แสดง utilization ที่ 60-70% มักหมายความว่ามีปัญหาคอขวดต้นน้ำ เช่น การโหลดข้อมูลของ CPU หรือ batch size ที่เล็กเกินไป อย่างไรก็ตาม แม้แต่ utilization 100% ก็อาจให้ภาพที่คลาดเคลื่อนได้ หาก kernel ของคุณถูกจำกัดด้วย memory หรือทำงานแบบ single-threaded สำหรับภาพที่แม่นยำของการใช้งาน core ให้ใช้ตัววิเคราะห์อย่าง Nsight Systems เพื่อติดตามเมตริก "SM Efficiency" หรือ "SM Active"
แบนด์วิดท์หน่วยความจำมักกลายเป็นคอขวดก่อนที่จะถึงขีดจำกัดของ compute capacity หาก GPU ประมวลผลข้อมูลได้เร็วกว่าที่หน่วยความจำส่งให้ หน่วยประมวลผลก็จะต้องรอโดยเปล่าประโยชน์ รุ่น H100 SXM5 มีแบนด์วิดท์ 3.35 TB/s เพื่อป้อนข้อมูลให้กับ 16,896 core อย่างไรก็ตาม รุ่น PCIe ลดลงมาเหลือ 2 TB/s
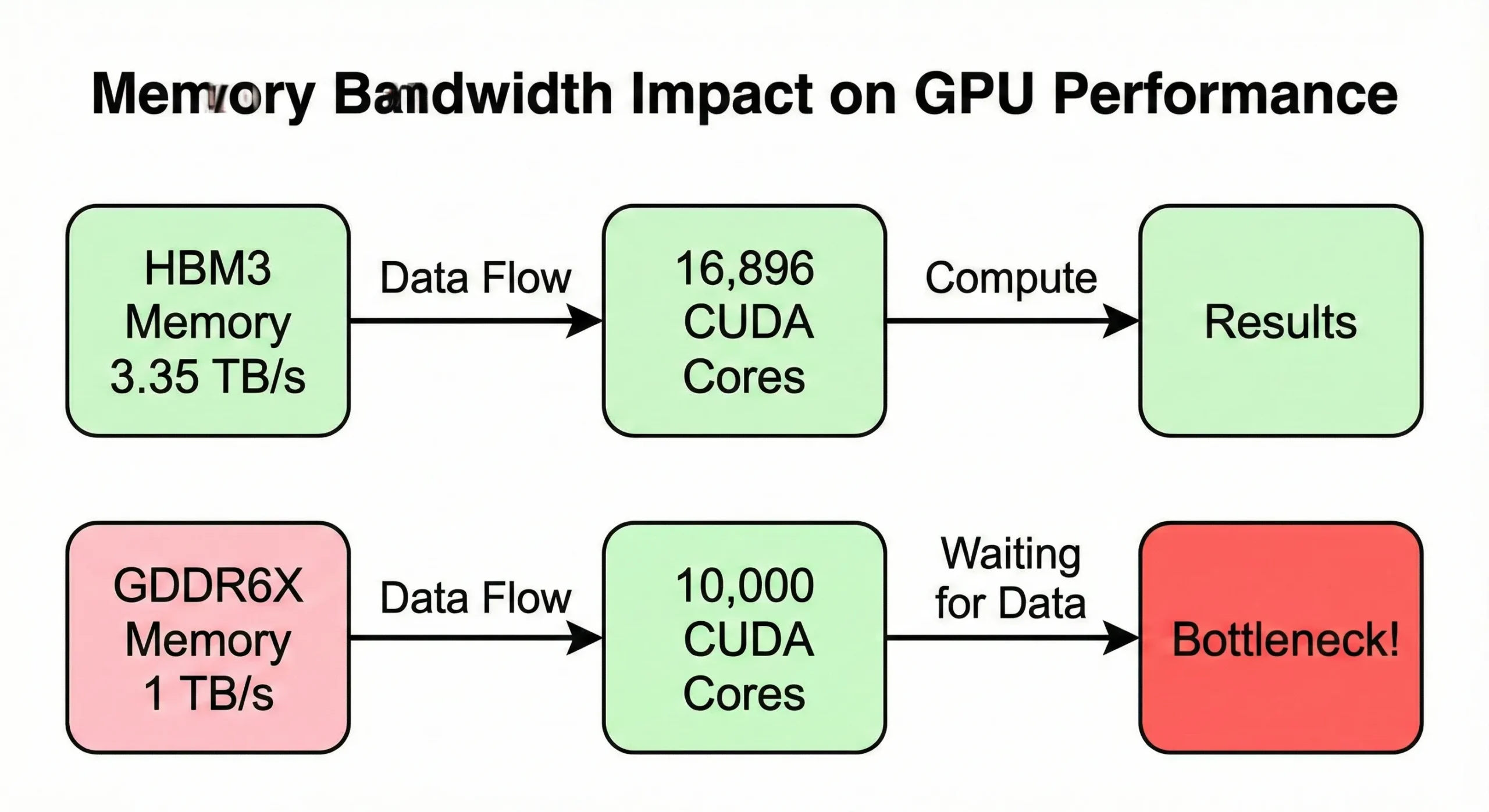
GPU สำหรับผู้บริโภคที่มีจำนวน core ใกล้เคียงกันแต่แบนด์วิดท์ต่ำกว่า (ประมาณ 1 TB/s) แสดงความเร็วในการใช้งานจริงที่ลดลงสำหรับงานที่ต้องใช้ memory มาก
ความจุ VRAM กำหนดขนาดของงานที่รองรับได้ ไม่ว่าจะเป็น FP16 weights สำหรับ โมเดล 70Bการเทรนแบบเต็มรูปแบบต้องการหน่วยความจำมากกว่านั้น คุณต้องคำนึงถึง gradient และ optimizer state ด้วย ซึ่ง state เหล่านี้มักเพิ่ม footprint ขึ้นสามเท่า เว้นแต่จะใช้กลยุทธ์ offload
A100 80GB เหมาะสำหรับ inference throughput สูงและการ fine-tuning ส่วน RTX 4090 ขนาด 24GB ที่มักถูกอ้างถึงสำหรับโมเดล 7B นั้น สามารถรันโมเดลที่มีพารามิเตอร์ 30B+ ได้อย่างน่าประหลาดใจหากใช้เทคนิค quantization สมัยใหม่อย่าง INT4 อย่างไรก็ตาม หาก VRAM เต็ม จะถูกบังคับให้ถ่ายโอนข้อมูลระหว่าง CPU กับ GPU ซึ่งทำลาย throughput อย่างรุนแรง
การปรับแต่งซอฟต์แวร์เป็นตัวกำหนดว่าโค้ดของคุณจะใช้ประโยชน์จากหน่วยประมวลผลเหล่านั้นได้จริงหรือไม่ kernel ที่เขียนไม่ดีอาจใช้ทรัพยากรได้เพียงส่วนเดียวเท่านั้น ไลบรารีอย่าง cuDNN สำหรับ deep learning และ RAPIDS สำหรับ data science ได้รับการปรับแต่งอย่างละเอียดเพื่อเพิ่ม utilization ให้สูงสุด
CUDA Cores ที่มากกว่าไม่ได้หมายความว่าประสิทธิภาพดีกว่าเสมอไป

การซื้อ GPU ที่มีจำนวนคอร์สูงสุดดูสมเหตุสมผล แต่ถ้าจำนวนหน่วยประมวลผลเกินกว่าที่องค์ประกอบอื่นในระบบจะรองรับได้ หรืองานของคุณไม่ได้ขยายตามจำนวนคอร์ คุณก็แค่จ่ายเงินฟรี
Memory bandwidth คือข้อจำกัดแรก RTX 5090 มี 21,760 หน่วยและรองรับด้วย memory bandwidth 1,792 GB/s แต่ GPU รุ่นเก่าที่มีหน่วยน้อยกว่าอาจมี bandwidth ต่อหน่วยสูงกว่าในสัดส่วนที่ดีกว่า
ความแตกต่างด้านสถาปัตยกรรมมีผล GPU รุ่นใหม่ที่มี 14,000 หน่วยที่ 2.2 GHz ให้ประสิทธิภาพสูงกว่า GPU รุ่นเก่าที่มี 16,000 หน่วยที่ 1.8 GHz เพราะรันคำสั่งต่อรอบนาฬิกาได้มากกว่า และโค้ดของคุณต้องรองรับการทำงานแบบขนานจริง ๆ จึงจะใช้ประโยชน์จาก 20,000 หน่วยได้เต็มที่
ทำไม CUDA Cores ถึงสำคัญเมื่อเลือก GPU VPS

การเลือก CUDA core และการกำหนดค่า GPU ที่เหมาะกับ VPS ของคุณช่วยให้ไม่ต้องจ่ายเงินสำหรับทรัพยากรที่ไม่ได้ใช้ หรือเจอคอขวดกลางโปรเจกต์
H100 ที่มี RAM 80GB รองรับการ inference โมเดลขนาด 70B parameter ด้วย 4-bit quantization ได้ แต่สำหรับการเทรนแบบเต็มรูปแบบ แม้แต่ 80GB ก็มักไม่พอสำหรับโมเดล 34B เมื่อรวม gradient และ optimizer state เข้าไปด้วย การเทรนแบบ FP16 ใช้หน่วยความจำมากกว่าอย่างเห็นได้ชัด และมักต้องใช้การ sharding ข้าม GPU หลายตัว
งาน inference สำหรับการทำนายแบบ real-time ใช้หน่วยประมวลผลน้อยกว่า แต่ต้องการ latency ต่ำ ส่วนงานพัฒนาและทดสอบต้นแบบนั้น GPU ระดับกลางก็เพียงพอสำหรับการทดสอบ algorithm และดีบักโค้ด
RTX 4060 Ti ที่มี 4,352 หน่วยช่วยให้คุณทดสอบได้โดยไม่ต้องจ่ายสำหรับฮาร์ดแวร์ที่เกินความจำเป็น เมื่อตรวจสอบแนวทางของคุณแล้ว ค่อยขยับขึ้นไปใช้ GPU สำหรับ production เพื่อเทรนจริง
งาน rendering และวิดีโอขยายตามจำนวนหน่วยได้จนถึงจุดหนึ่ง Cycles renderer ของ Blender ใช้ทรัพยากรที่มีอยู่ได้อย่างมีประสิทธิภาพ GPU ที่มี 8,000-10,000 หน่วย render ฉากได้เร็วกว่าตัวที่มี 4,000 หน่วย ประมาณ 2-3 เท่า
ที่ Cloudzy เราให้บริการ GPU VPS hosting ประสิทธิภาพสูงสำหรับงานหนัก เลือก RTX 5090 หรือ RTX 4090 สำหรับ rendering ที่รวดเร็วและ AI inference ที่คุ้มค่า หรืออัปเกรดไปใช้ A100 สำหรับ workload deep learning ขนาดใหญ่ ทุกแพ็กเกจรันบนเครือข่าย 40 Gbps พร้อมนโยบายความเป็นส่วนตัวและรองรับการชำระด้วยสกุลเงินดิจิทัล ได้พลังงานที่ต้องการโดยไม่ต้องผ่านขั้นตอนยุ่งยากแบบองค์กรใหญ่
ไม่ว่าจะเป็นการเทรน AI model, rendering ฉาก 3D หรือรัน simulation ทางวิทยาศาสตร์ คุณเลือกจำนวนคอร์ที่ตรงกับความต้องการได้เลย
งบประมาณเป็นเรื่องสำคัญ A100 ที่มี 6,912 หน่วยราคาถูกกว่า H100 ที่มี 16,896 หน่วยอย่างเห็นได้ชัด สำหรับงานหลายประเภท การใช้ A100 สองตัวให้อัตราส่วนราคาต่อประสิทธิภาพที่ดีกว่า H100 หนึ่งตัว จุดคุ้มทุนขึ้นอยู่กับว่าโค้ดของคุณขยายข้าม GPU หลายตัวได้ดีแค่ไหน
วิธีเลือกจำนวน CUDA Cores ที่เหมาะสม
จับคู่ความต้องการกับลักษณะจริงของ workload แทนที่จะไล่ตามตัวเลขสูงสุดในตลาด
เริ่มต้นด้วยการ profile งานปัจจุบันของคุณ ถ้าคุณกำลังเทรนโมเดลบนฮาร์ดแวร์ local หรือ cloud instance ให้ตรวจสอบค่า utilization ของ GPU ถ้า GPU ตัวปัจจุบันของคุณแสดง utilization ที่ 60-70% อย่างสม่ำเสมอ แสดงว่าคุณยังไม่ได้ใช้หน่วยประมวลผลเต็มที่
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")benchmark เบื้องต้นนี้บอกได้ว่า core ของ GPU ส่ง throughput ตามที่คาดหวังหรือไม่ เปรียบเทียบผลลัพธ์กับ benchmark ที่เผยแพร่สำหรับรุ่น GPU ของคุณ
การอัปเกรดจะไม่ช่วยอะไร คุณต้องแก้ปัญหาคอขวดก่อน ไม่ว่าจะเป็น memory, bandwidth หรือการหยุดชะงักของ CPU จากนั้นประเมินความต้องการ memory โดยคำนวณขนาดโมเดลเป็น byte บวกกับ activation memory
บวก batch size คูณ layer output และรวม optimizer state เข้าไปด้วย ผลรวมทั้งหมดต้องพอดีกับ VRAM เมื่อรู้ขนาด memory ที่ต้องการแล้ว ให้ตรวจสอบว่า GPU ตัวใดตรงตาม threshold นั้น
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)คำนึงถึงระยะเวลาด้วย ถ้าต้องการผลลัพธ์ภายในไม่กี่ชั่วโมง ก็จ่ายสำหรับหน่วยประมวลผลเพิ่ม แต่ถ้า training run ที่ใช้เวลาหลายวันเป็นที่ยอมรับได้ GPU ขนาดเล็กกว่าพร้อมเวลาทำงานที่นานขึ้นก็ทำงานได้ดีเช่นกัน
ค่าใช้จ่ายต่อชั่วโมงคูณจำนวนชั่วโมงที่ใช้คือต้นทุนรวม ซึ่งบางครั้ง GPU ที่ช้ากว่ากลับถูกกว่าโดยรวม ทดสอบประสิทธิภาพการขยายตัวโดยใช้ framework หลาย ๆ ตัวที่มีเครื่องมือ benchmark แสดงการเปลี่ยนแปลง throughput
ถ้าการเพิ่มหน่วยเป็นสองเท่าให้ความเร็วแค่ 1.5 เท่า ส่วนที่เพิ่มมาไม่คุ้มค่า มองหาจุดที่อัตราส่วนราคาต่อประสิทธิภาพดีที่สุด
| ประเภทโหลดงาน | คอร์ที่แนะนำ | ตัวอย่าง GPU | หมายเหตุ |
| การพัฒนาและดีบักโมเดล | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | วนซ้ำได้เร็ว ต้นทุนต่ำกว่า |
| การเทรน AI ขนาดเล็ก (น้อยกว่า 7B พารามิเตอร์) | 6,000-10,000 | RTX 4090, L40S | เหมาะสำหรับผู้ใช้ทั่วไปและธุรกิจขนาดเล็ก |
| การเทรน AI ขนาดใหญ่ (พารามิเตอร์ 7B–70B) | 14,000+ | A100, H100 | ต้องการ data center GPUs |
| การประมวลผล Inference แบบเรียลไทม์ (ปริมาณงานสูง) | 10,000-16,000 | RTX 5080, L40 | สมดุลระหว่างต้นทุนและประสิทธิภาพ |
| การเรนเดอร์ 3D และการเข้ารหัสวิดีโอ | 8,000-12,000 | RTX 4080, RTX 4090 | ขยายตามความซับซ้อนได้ |
| การคำนวณเชิงวิทยาศาสตร์และ HPC | 10,000+ | A100, H100 | ต้องการการสนับสนุน FP64 |
GPU ยอดนิยมและจำนวน CUDA Core ของแต่ละรุ่น

ระดับบริการ GPU แต่ละระดับรองรับกลุ่มผู้ใช้ที่แตกต่างกัน แล้ว GPUaaS คืออะไร? คือบริการ GPU-as-a-Service ที่ผู้ให้บริการอย่าง Cloudzy เปิดให้เข้าถึง NVIDIA GPU ประสิทธิภาพสูงแบบ on-demand โดยไม่ต้องซื้อหรือดูแลฮาร์ดแวร์จริงด้วยตัวเอง
| รุ่น GPU | CUDA Cores | VRAM | ความกว้างแบนด์วิดท์หน่วยความจำ | สถาปัตยกรรม | เหมาะที่สุดสำหรับ |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1,792 GB/s | Blackwell | เวิร์กสเตชันระดับสูงสุด สำหรับการเรนเดอร์ 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | อาดา เลิฟเลซ | AI ระดับสูง, เรนเดอร์ 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/s | Hopper | การเทรน AI ขนาดใหญ่ |
| H100 PCIe | 14,592 | 80GB HBM2e | 2,000 GB/s | Hopper | AI ระดับองค์กร ดาต้าเซ็นเตอร์ประหยัดต้นทุน |
| A100 | 6,912 | 40/80GB HBM2e | 1,555-2,039 GB/s | Ampere | AI ระดับกลาง ความน่าเชื่อถือที่พิสูจน์แล้ว |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | อาดา เลิฟเลซ | เกมและ AI ระดับกลาง |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | อาดา เลิฟเลซ | ดาต้าเซ็นเตอร์รองรับหลายประเภทงาน |
การ์ด RTX สำหรับผู้บริโภค (4070, 4080, 4090, 5080, 5090) ออกแบบมาสำหรับนักสร้างคอนเทนต์และเกมเมอร์ แต่ก็ใช้งานได้ดีสำหรับการพัฒนา AI ให้ความเร็วในการประมวลผลแบบเธรดเดียวที่แรง ในราคาที่ต่ำกว่าการ์ดระดับ datacenter
ผู้ให้บริการ VPS มักเลือกใช้การ์ดเหล่านี้สำหรับผู้ใช้ที่คำนึงถึงต้นทุน ส่วนการ์ดระดับ Datacenter (A100, H100, L40) เน้นความเสถียร หน่วยความจำ ECC และการขยายระบบแบบหลาย GPU รองรับการทำงานตลอด 24/7 และฟีเจอร์ขั้นสูง
Multi-Instance GPU (MIG) ช่วยให้คุณแบ่ง GPU หนึ่งตัวออกเป็นหลาย instance ที่แยกจากกันได้อย่างอิสระ ส่วน A100 ยังคงได้รับความนิยมแม้จะมีตัวเลือกใหม่กว่า เพราะสเปกที่สมดุลลงตัว
ความสมดุลระหว่าง NVIDIA cores หน่วยความจำ และราคา ทำให้เป็นตัวเลือกที่เหมาะสมสำหรับงาน AI บน production ส่วนใหญ่ ส่วน H100 มี units มากกว่าถึง 2.4 เท่า แต่มีราคาสูงกว่าอย่างเห็นได้ชัด
บทสรุป
เอนจินประมวลผลแบบขนานเป็นพื้นฐานของงาน AI การเรนเดอร์ และการคำนวณทางวิทยาศาสตร์ยุคใหม่ การเข้าใจวิธีทำงานและการโต้ตอบกับหน่วยความจำ ความเร็วสัญญาณนาฬิกา และซอฟต์แวร์ จะช่วยให้คุณเลือก GPU VPS ได้ตรงกับความต้องการมากขึ้น
จำนวนยูนิตที่มากขึ้นช่วยได้จริง เมื่องานของคุณรองรับการประมวลผลแบบขนานได้ดี และองค์ประกอบอื่นอย่าง memory bandwidth ตามทัน แต่ถ้าคอขวดอยู่ที่จุดอื่น การไล่ตามจำนวนคอร์สูงสุดโดยไม่วิเคราะห์ก็แค่เสียเงินเปล่า
เริ่มต้นด้วยการโปรไฟล์งานจริงของคุณ ระบุว่าเวลาหมดไปกับส่วนไหน แล้วจับคู่ข้อมูลจำเพาะของ GPU ให้ตรงกับความต้องการนั้น โดยไม่ซื้อความจุเกินที่จำเป็น
สำหรับงาน AI development ส่วนใหญ่ 6,000-10,000 ยูนิตให้ความสมดุลระหว่างราคาและประสิทธิภาพได้ดีที่สุด งาน production ที่ต้องเทรนโมเดลขนาดใหญ่หรือรัน inference throughput สูง จะได้ประโยชน์จาก GPU ที่มี 14,000+ ยูนิต อย่าง H100
งานเรนเดอร์และวิดีโอสเกลได้ดีกับยูนิตถึงประมาณ 16,000 หลังจากนั้น memory bandwidth จะกลายเป็นปัจจัยจำกัดแทน


