
Одним із найважливіших завдань у машинному навчанні є отримання точних і надійних прогнозів. Один із підходів, що набув широкого визнання, — Bootstrap Aggregating, або bagging у машинному навчанні. У цій статті ми розберемо, що таке bagging у машинному навчанні, порівняємо bagging і boosting, розглянемо приклад bagging-класифікатора, пояснимо принцип роботи методу та проаналізуємо його переваги й недоліки.
Що таке bagging у машинному навчанні?
Це єдині два релевантні зображення, що використовуються в популярних статтях. Одне або обидва можна задіяти (одне тут, інше деінде), якщо Design створить їх у стилі Cloudzy.
Що таке Bagging?
Уявіть, що ви намагаєтеся визначити вагу предмета, запитуючи кількох людей про їхні оцінки. Окремі відповіді можуть суттєво різнитися, але якщо усереднити всі оцінки, результат виявиться значно точнішим. Саме в цьому і полягає суть bagging: поєднати результати кількох моделей, щоб отримати точніший і стійкіший прогноз.
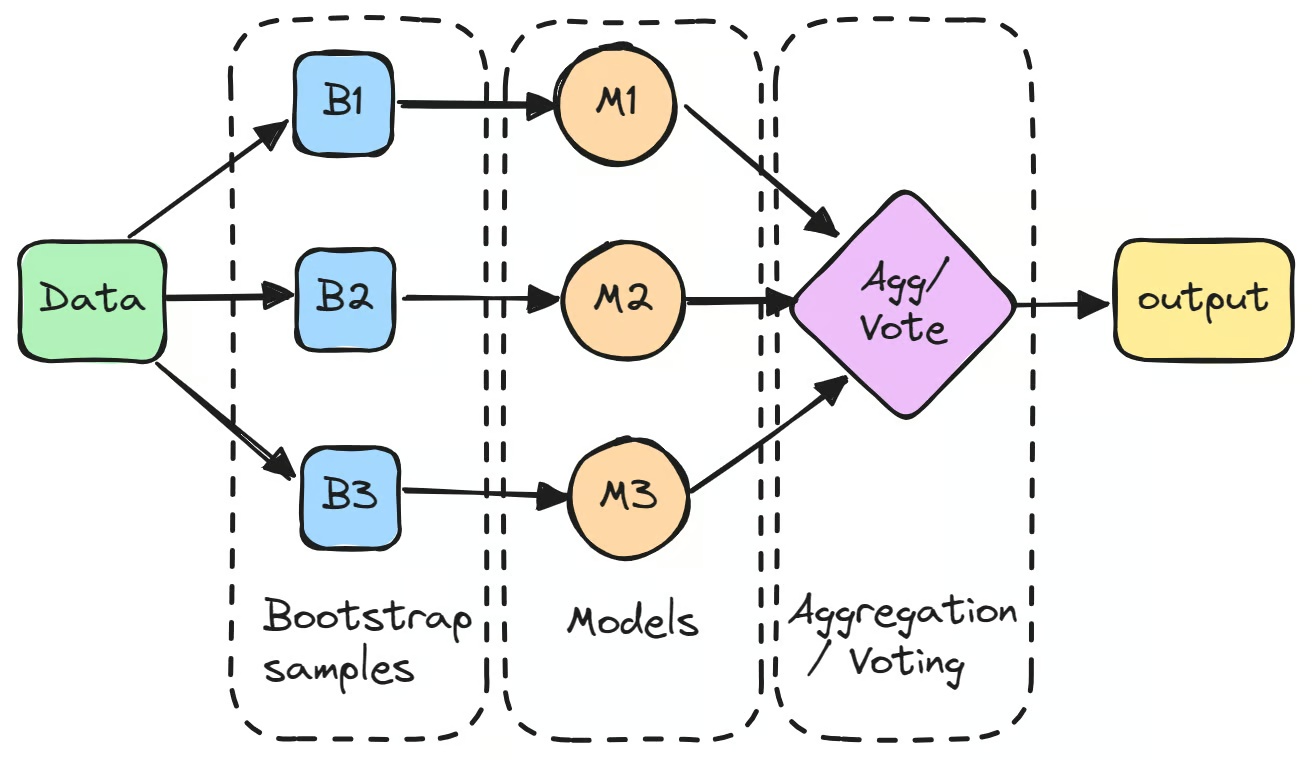
Процес починається зі створення кількох підвибірок вихідного датасету методом bootstrapping — випадковою вибіркою з поверненням. На основі кожної підвибірки незалежно навчається окрема модель.
Окремі моделі, які часто називають «слабкими учнями», можуть не показувати видатних результатів самостійно через високу дисперсію. Однак після агрегування їхніх прогнозів — як правило, усередненням для задач регресії або голосуванням більшості для задач класифікації — сукупний результат нерідко перевершує будь-яку окрему модель.
Відомий приклад бегінг-класифікатора — алгоритм Random Forest, який будує ансамбль дерев рішень для підвищення точності прогнозів. Втім, бегінг не слід плутати з бустингом у машинному навчанні: бустинг навчає моделі послідовно, щоб зменшити зміщення, тоді як бегінг навчає їх паралельно, щоб зменшити дисперсію.
І бегінг, і бустинг у машинному навчанні спрямовані на покращення якості моделі, але кожен з них впливає на різні аспекти її поведінки.
Чому Bagging корисний?
Одна з головних переваг бегінгу в машинному навчанні — здатність зменшувати дисперсію, що допомагає моделям краще узагальнювати дані, яких вони раніше не бачили. Бегінг особливо корисний при роботі з алгоритмами, чутливими до змін у навчальних даних, — наприклад, з деревами рішень.
Запобігаючи перенавчанню, бегінг забезпечує стабільнішу та надійнішу модель. Якщо порівнювати бегінг і бустинг у машинному навчанні: бегінг зменшує дисперсію, навчаючи кілька моделей паралельно, тоді як бустинг зменшує зміщення, навчаючи їх послідовно.
Практичний приклад бегінгу в машинному навчанні — прогнозування фінансових ризиків, де кілька дерев рішень навчаються на різних підвибірках історичних ринкових даних. Агрегуючи їхні прогнози, бегінг формує надійнішу прогностичну модель і знижує вплив помилок окремих моделей.
По суті, бегінг у машинному навчанні спирається на колективні результати кількох моделей, даючи точніші та надійніші прогнози, ніж будь-яка окрема модель.
Як працює бегінг у машинному навчанні: покроково
Щоб зрозуміти, як бегінг покращує якість моделі, розберемо процес крок за кроком.
Формування кількох бутстреп-вибірок із датасету
Перший крок бегінгу в машинному навчанні — створення кількох нових підвибірок вихідного датасету за допомогою бутстреп-вибірки. Ця техніка передбачає випадкове вибирання даних із поверненням: деякі точки даних можуть зустрічатися в одній підвибірці кілька разів, інші не потраплять до неї взагалі. Таким чином кожна модель навчається на дещо відмінній версії даних.
Навчання окремої моделі на кожній вибірці
Кожна бутстреп-вибірка використовується для навчання окремої моделі, зазвичай одного типу, наприклад дерева рішень. Ці моделі, які часто називають «базовими учнями» або «слабкими учнями», навчаються незалежно одна від одної на своїх підвибірках. Приклад бегінг-класифікатора — дерево рішень в алгоритмі Random Forest, яке лежить в основі багатьох бегінг-моделей. Хоча кожна окрема модель може давати посередні результати, кожна вносить унікальні знання зі своїх навчальних даних.
Агрегація прогнозів
Після навчання моделей їхні прогнози агрегуються у фінальний результат.
- Для задач регресії прогнози усереднюються, що зменшує дисперсію моделі.
- Для задач класифікації фінальний прогноз визначається голосуванням більшості: обирається клас, який передбачила найбільша кількість моделей. Цей підхід дає стабільніший результат порівняно з виходом єдиної моделі.
Остаточний прогноз
Комбінування прогнозів кількох моделей знижує вплив помилок будь-якої однієї моделі та підвищує загальну точність. Саме агрегація робить бегінг настільки ефективною технікою, особливо в задачах машинного навчання, де використовуються моделі з високою дисперсією, як-от дерева рішень. Вона згладжує розбіжності в прогнозах окремих моделей і в результаті дає сильнішу фінальну модель.
Хоча бегінг добре стабілізує прогнози, варто враховувати кілька моментів: базові моделі надто складної структури можуть спричинити перенавчання, попри те що бегінг загалом покликаний його уникати.
Метод також є обчислювально затратним, тому варто регулювати кількість базових учнів або розглянути ефективніші ансамблеві методи. вибір правильного GPU для ML та DL завжди важливо.
Подбайте про різноманітність базових учнів — це покращить результати. Якщо ви працюєте з незбалансованими даними, перед застосуванням бегінгу можна скористатися такими техніками, як SMOTE, щоб уникнути низької якості прогнозів для міноритарних класів.
Застосування Bagging
Тепер, розібравшись із принципами роботи бегінгу, подивімося, де він застосовується на практиці. Бегінг знайшов застосування в різних галузях і допомагає підвищити точність та стабільність прогнозів у складних сценаріях. Розглянемо найбільш показові приклади:
- Класифікація та регресія: Бегінг широко використовується для підвищення якості класифікаторів і регресорів завдяки зменшенню дисперсії та запобіганню перенавчанню. Наприклад, Random Forests, побудовані на основі бегінгу, ефективно вирішують задачі класифікації зображень і предиктивного моделювання.
- Виявлення аномалій: У таких сферах, як виявлення шахрайства та мережевих вторгнень, алгоритми беґінгу демонструють вищу ефективність завдяки точному виявленню викидів і аномалій у даних.
- Оцінка фінансових ризиків: У банківській сфері техніки беґінгу застосовуються для вдосконалення моделей кредитного скорингу, підвищуючи точність прийняття рішень щодо позик і оцінки фінансових ризиків.
- Медична діагностика: У медицині беґінг використовується для виявлення нейрокогнітивних розладів, зокрема хвороби Альцгеймера, шляхом аналізу наборів даних МРТ, що сприяє ранній діагностиці та плануванню лікування.
- Обробка природної мови (NLP): Беґінг покращує результати задач класифікації тексту та аналізу тональності, агрегуючи прогнози кількох моделей і забезпечуючи глибше розуміння мови.
Переваги та недоліки беґінгу
Як і будь-яка техніка машинного навчання, беґінг має свої переваги та недоліки. Розуміння цих аспектів допоможе визначити, коли і як застосовувати його у своїх моделях.
Переваги Bagging:
- Зменшення дисперсії та перенавчання: Одна з головних переваг беґінгу в машинному навчанні - здатність знижувати дисперсію, що запобігає перенавчанню. Навчаючи кілька моделей на різних підмножинах даних, беґінг гарантує, що модель не стає надто чутливою до коливань у навчальних даних. Результат - більш стабільна модель, яка добре узагальнює.
- Ефективний для моделей із високою дисперсією: Беґінг особливо корисний у поєднанні з моделями, схильними до високої дисперсії, наприклад деревами рішень. Такі моделі мають тенденцію до перенавчання, але беґінг нейтралізує це, усереднюючи або агрегуючи результати кількох моделей голосуванням. Це робить прогнози надійнішими і менш чутливими до шуму в даних.
- Підвищення стабільності та якості моделі: Поєднання кількох моделей, навчених на різних підмножинах даних, зазвичай покращує загальну ефективність. Беґінг підвищує точність прогнозів і знижує чутливість моделі до незначних змін у наборі даних, що в підсумку робить її надійнішою.
Недоліки Bagging:
- Збільшення обчислювальних витрат: Оскільки беґінг потребує навчання кількох моделей, це закономірно збільшує обчислювальні витрати. Навчання і агрегація прогнозів від багатьох моделей може займати багато часу, особливо на великих наборах даних або складних моделях, як-от дерева рішень.
- Невисока ефективність для моделей із низькою дисперсією: При всій ефективності для моделей із високою дисперсією, беґінг майже не дає переваг для моделей із низькою дисперсією, наприклад лінійної регресії. У таких випадках окремі моделі вже мають невисокий рівень помилок, тому агрегація прогнозів практично не покращує результат.
- Втрата інтерпретованості: Поєднання кількох моделей знижує інтерпретованість кінцевої моделі. Наприклад, у Random Forest процес прийняття рішень ґрунтується на множині дерев рішень, що ускладнює відстеження логіки за конкретним прогнозом.
Коли варто використовувати беґінг?
Розуміння того, коли застосовувати беґінг у проєктах машинного навчання, є ключем до досягнення оптимальних результатів. Ця техніка добре працює в певних ситуаціях, але підходить не для кожної задачі.
Коли модель схильна до перенавчання
Беґінг передусім варто використовувати, коли модель схильна до перенавчання, особливо у випадку моделей із високою дисперсією, як-от дерева рішень. Такі моделі можуть добре працювати на навчальних даних, але часто погано узагальнюються на нових даних, надмірно підлаштовуючись під конкретні закономірності навчальної вибірки.
Беггінг допомагає вирішити цю проблему, навчаючи кілька моделей на різних підмножинах даних і усереднюючи або голосуючи для отримання стабільнішого прогнозу. Це знижує ймовірність перенавчання, завдяки чому модель краще справляється з новими, раніше не баченими даними.
Коли потрібно підвищити стабільність і точність
Якщо ви хочете підвищити стабільність і точність моделі, не жертвуючи надто інтерпретованістю, беггінг — чудовий вибір. Агрегація прогнозів кількох моделей робить кінцевий результат надійнішим, що особливо корисно при роботі з зашумленими даними.
Незалежно від того, чи вирішуєте ви задачі класифікації, чи задачі регресії, беггінг допомагає отримувати стабільніші результати, підвищуючи точність без втрати ефективності.
Коли є достатньо обчислювальних ресурсів
Ще один важливий фактор при виборі беггінгу — наявність обчислювальних ресурсів. Оскільки беггінг потребує одночасного навчання кількох моделей, обчислювальні витрати можуть бути значними, особливо з великими наборами даних або складними моделями.
Якщо у вас є необхідні обчислювальні потужності, переваги беггінгу з лишком перекривають витрати. Якщо ж ресурси обмежені, варто розглянути альтернативні методи або зменшити кількість моделей в ансамблі.
Коли ви працюєте з моделями з високою дисперсією
Беггінг особливо корисний при роботі з моделями, що мають високу дисперсію і чутливі до коливань у навчальних даних. Дерева рішень, наприклад, часто використовуються з беггінгом у вигляді Random Forests, оскільки їхня продуктивність суттєво залежить від навчальних даних.
Навчаючи кілька моделей на різних підмножинах даних і об'єднуючи їхні прогнози, беггінг згладжує дисперсію, формуючи надійнішу модель.
Коли потрібен стійкий класифікатор
Якщо ви вирішуєте задачі класифікації і потребуєте стійкого класифікатора, беггінг може значно підвищити стабільність прогнозів. Наприклад, Random Forest, який є класичним прикладом беггінг-класифікатора, забезпечує точніший прогноз завдяки агрегації результатів багатьох окремих дерев рішень.
Цей підхід добре працює, коли окремі моделі слабкі, але в сукупності вони формують сильну загальну модель.
Крім того, якщо ви шукаєте відповідну платформу для ефективної реалізації беггінгу, такі інструменти, як Databricks і Snowflake надають єдину аналітичну платформу, яка може бути дуже корисною для роботи з великими наборами даних і запуску ансамблевих методів, зокрема беггінгу.
Якщо ви шукаєте менш технічний підхід до машинного навчання, інструменти AI без коду також можуть стати варіантом. Хоча такі платформи безпосередньо не зосереджені на просунутих методах на кшталт беггінгу, багато no-code рішень дозволяють експериментувати з методами ансамблевого навчання, включно з беггінгом, без глибоких знань програмування.
Це дає змогу застосовувати складніші техніки й отримувати точні прогнози, зосереджуючись на продуктивності моделі, а не на коді.
Підсумкові думки
Беггінг у машинному навчанні — це дієвий метод, що покращує продуктивність моделі, знижуючи дисперсію і підвищуючи стабільність. Агрегуючи прогнози кількох моделей, навчених на різних підмножинах даних, беггінг допомагає отримувати точніші й надійніші результати. Він особливо ефективний для моделей з високою дисперсією, зокрема дерев рішень, де запобігає перенавчанню і забезпечує краще узагальнення на нових даних.
Незважаючи на суттєві переваги — зниження перенавчання і підвищення точності — беггінг має певні компроміси. Він збільшує обчислювальні витрати через навчання кількох моделей і може ускладнити інтерпретацію результатів. Попри ці недоліки, здатність беггінгу покращувати продуктивність робить його цінним методом в ансамблевому навчанні поряд з іншими підходами, такими як бустинг і стекінг.
Чи використовували ви беггінг у проєктах з машинного навчання? Розкажіть про свій досвід і результати!


