
Ви відкриваєте сторінку GGUF популярної моделі на Hugging Face, і на вас дивиться п'ятнадцять файлів: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, плюс окремі папки для GPTQ, AWQ і EXL2 з півдюжиною бітових налаштувань. Ви робите прикидковий підрахунок для «4-бітного» файлу: 4 біти × 8 мільярдів параметрів ÷ 8 = 4 ГБ. Але файл показує 4,6 ГБ. А коли ви його завантажите, модель споживає ще більше пам'яті.
Назви файлів - це не шум. Вони кодують реальну, зрозумілу інформацію про бітову розрядність, середовище виконання, яке їх завантажує, і апаратне забезпечення, яке їм потрібне. Таблиці розмірів, які ви читали, кажуть, що моделі 70B потрібно приблизно 40 ГБ, це корисно, але вони ніколи не розшифровують сам формат і не пояснюють, чому запущена модель хоче більше пам'яті, ніж файл на диску.
Отже, ось план: розшифрувати конвенцію найменування GGUF (зі справжньою, а не номінальною бітовою розрядністю), з'ясувати, який з чотирьох форматів ваше апаратне забезпечення дійсно може запустити, і врахувати одну витрату пам'яті, невидиму в жодному розмірі файлу, KV-кеш. Наприкінці ви зможете прочитати репозиторій моделі та передбачити, як вона поведеться при завантаженні.
TL;DR
- Рівні квантизації GGUF - це ефективна бітова розрядність, а не точне число в назві. Q4_K_M становить приблизно 4,89 біта на вагу, тому «4-бітний» файл 8B виходить близько 4,6 ГіБ замість наївної 4-бітної оцінки.
- GGUF - найпереносніший варіант, оскільки llama.cpp може запускати його на CPU, GPU або в гібридній конфігурації. GPTQ, AWQ і EXL2 більш специфічні для GPU та середовища виконання, причому EXL2 особливо прив'язаний до робочих процесів NVIDIA/CUDA.
- KV-кеш окремий від ваг моделі, і він зростає з довжиною контексту. Саме тому модель, яка чисто завантажується, все одно може впасти через нестачу пам'яті, коли розмова стає довгою.
- Вище діапазону 5 біт втрата якості зазвичай невелика. Навколо Q4 компроміс усе ще практичний для багатьох локальних сценаріїв використання. Нижче 4 біт вартість якості стає набагато помітнішою. Q4_K_M залишається поширеним стандартним вибором спільноти, тоді як Q5_K_M і Q6_K безпечніші, якщо у вас є запас пам'яті.
Що означає Q4_K_M у назві файлу GGUF?

Назва квантизації GGUF відповідає шаблону Q[біти]_[K]_[S/M/L]. Число - це цільова значення бітів на вагу, K означає, що це «K-квант», який зберігає коефіцієнти масштабування для кожного малого блоку ваг, а завершальні S, M або L - рівень розміру/якості (малий, середній, великий). Оскільки K-кванти зберігають масштаб і мінімальне значення для кожного блоку поряд із вагами, ефективна бітова розрядність вища, ніж головна цифра. Q4_K_M виходить приблизно на 4,89 біта на вагу, а не 4.
Ця різниця - і є повна відповідь на питання «чому мій 4-бітний файл важить 4,6 ГБ?». Наївна оцінка припускає, що кожна вага коштує рівно 4 біти. Насправді K-кванти витрачають додаткові біти на блок на метадані, які роблять низькобітну квантизацію точною, масштаб і мінімум на блок, що дозволяють середовищу виконання відновити кожну вагу. Помножте 4,89 біта на 8 мільярдів ваг, і ви отримаєте близько 4,58 ГіБ, саме стільки й важить файл насправді.
Ось виміряні ефективні бітові розрядності та розміри файлів, взяті з llama.cpp quantize documentation , для Llama 3.1 8B як референсної моделі, поряд із вартістю перплексії для кожного рівня, виміряною в статті з оцінки квантизації llama.cpp (arXiv:2601.14277) на Llama-3.1-8B-Instruct:
| Рівень GGUF | Ефективний BPW | ~Розмір файлу (8B) | Перплексія проти F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 ГіБ | +22% |
| Q3_K_M | 3.95 | ~3,7 ГіБ | +8.7% |
| Q3_K_L | 4.30 | ~4,0 ГіБ | +6.7% |
| Q4_K_S | 4.67 | ~4,4 ГіБ | +4.1% |
| Q4_K_M | 4.89 | ~4,6 ГіБ | +3.3% |
| Q5_K_M | 5.70 | ~5,3 ГіБ | +1.1% |
| Q6_K | 6.56 | ~6,1 ГіБ | +0.4% |
| Q8_0 | 8.50 | ~8,0 ГіБ | +0.1% |
| F16 | 16.00 | ~15,0 ГіБ | базовий рівень |
*Значення перплексії стосуються конкретно Llama-3.1-8B-Instruct з arXiv:2601.14277. Стовпець BPW/розмір файлу і стовпець перплексії походять із двох різних джерел, виміряних окремо, тож читайте таблицю як практичний порівняльний довідник, а не як один окремий прогін бенчмарку. Деградація залежить від завдання, математичні міркування зазвичай страждають більше, ніж здоровий глузд, при низькій бітовій розрядності, але загальна картина зберігається: 5 біт і вище зазвичай безпечніше, Q4 - практична зона стиснення, а 3 біти - те місце, де втрату якості стає набагато важче ігнорувати.
Практично: Q4_K_M - стандартний вибір, до якого варто звертатися більшості людей, Q5_K_M і Q6_K - вибір на користь якості, коли у вас є запас пам'яті, а все на рівні Q3_K_S чи нижче - крайній засіб для апаратного забезпечення, яке справді не вміщує більше.
Який формат квантизації варто завантажити: GGUF, GPTQ, AWQ чи EXL2?

GGUF - найпереносніший з чотирьох форматів: він працює на CPU, GPU або гібридній комбінації обох через llama.cpp, тож це найбезпечніший вибір, коли ви не впевнені, що підтримує ваше апаратне забезпечення. GPTQ, AWQ і EXL2 більш специфічні для GPU та середовища виконання. На практиці вони найпоширеніші в конфігураціях NVIDIA/CUDA, але підтримка GPTQ і AWQ може відрізнятися залежно від завантажувача та стека обслуговування; vLLM, наприклад, розділяє підтримку квантизації за апаратним забезпеченням та реалізацією. Якщо ви працюєте локально на Mac, карті AMD або машині лише з CPU, GGUF залишається найбезпечнішою відповіддю. Якщо у вас GPU NVIDIA і ви хочете максимально швидких токенів, у гру вступають інші три.
| Формат | Апаратне забезпечення/середовище виконання | Швидкість (відносна) | VRAM порівняно з іншими | Найкраще для |
|---|---|---|---|---|
| GGUF Q4_K_M | Найширший, CPU, GPU або гібрид через llama.cpp | Помірний | Найнижча | Будь-яке апаратне забезпечення; локальний стандарт |
| GPTQ 4-bit | Зазвичай пріоритетно CUDA/GPU; залежить від середовища виконання | Швидкий (ExLlama) | Середнє | Пріоритетно GPU, застарілі інструменти |
| AWQ 4-bit | Зазвичай пріоритетно CUDA/GPU; залежить від середовища виконання | Швидко | Найвищий | Обслуговування через vLLM/TGI, швидке завантаження |
| EXL2 ~4,9 bpw | Пріоритетно NVIDIA/CUDA | Найшвидший | Низько-Середнє | Максимальна швидкість на NVIDIA |
Застереження щодо цієї таблиці: рейтинги швидкості та VRAM походять із бенчмарку oobabooga, який працював на апаратному забезпеченні 2023/2024 років. Сприймайте відносний порядок як стійкий. EXL2 створений для швидкості, AWQ обмінює VRAM на швидке завантаження, GGUF залишається компактним і переносним, але не сприймайте оригінальні абсолютні цифри токенів за секунду як актуальні. GPU 2026 року покаже зовсім іншу пропускну спроможність; саме порядок зберігається надалі.
З цього випливає правило прийняття рішення: якщо у вас карта NVIDIA і найбільше важлива швидкість, EXL2; якщо потрібен найбезпечніший локальний стандарт на різному апаратному забезпеченні, GGUF. AWQ і GPTQ мають значення переважно тоді, коли конкретний стек обслуговування (vLLM, TGI) або наявні інструменти підштовхують вас туди.
Чому локальна LLM споживає більше пам'яті, ніж її файл?
Розмір файлу - це лише ваги моделі. Під час виконання ви також платите за KV-кеш (стан уваги для кожного токена у вашому вікні контексту), активації (проміжні обчислення прямого проходу) та накладні витрати фреймворку й драйвера. Разом ці частини, що не є вагами, у конфігурації одного користувача зазвичай додають 10-20% понад ваги, а сам лише KV-кеш може затьмарити все інше, щойно контекст стане довгим. Файл на 4,6 ГБ може потребувати для роботи набагато більше ніж 4,6 ГБ пам'яті.
Уявіть пам'ять під час виконання як чотири компоненти, накладені один на одного:
- Ваги моделі. Файл, який ви завантажили. Це єдина частина, видима ще до завантаження.
- KV-кеш. Стан уваги для вікна контексту. Малий при короткому контексті, величезний при довгому контексті. Це тема наступного розділу, бо саме вона дивує людей.
- Активації. Робоча пам'ять прямого проходу. Для однопотокового локального інференсу (розмір батчу 1) вона мала, зазвичай кілька сотень мегабайт.
- Накладні витрати фреймворку. Власний слід середовища виконання плюс контекст драйвера GPU. Для легкого локального середовища виконання це може бути мало порівняно з вагами моделі та KV-кешем; важчі фреймворки обслуговування можуть резервувати набагато більше. Власне резервування пам'яті вашою операційною системою лежить поза цим і знову є окремим.
Ваги та накладні витрати фреймворку передбачувані. KV-кеш - це змінна, яка перетворює модель, що «вміщується», на модель, яка падає, тож варто пройтися по реальній математиці.
Скільки пам'яті споживає KV-кеш?
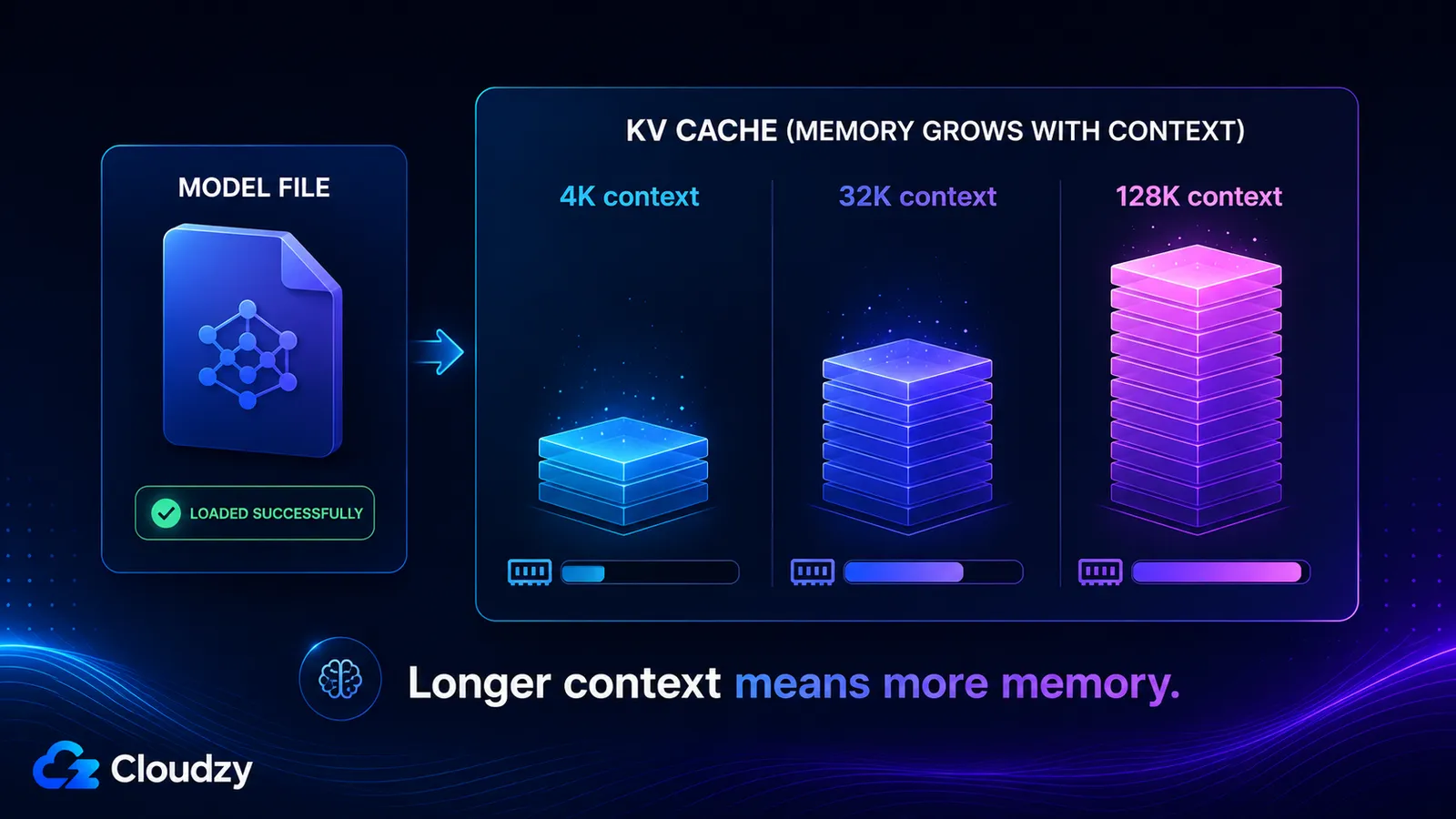
KV-кеш зберігає вектори ключів і значень для кожного токена у вашому вікні контексту, тож він росте приблизно лінійно з довжиною контексту і повністю відокремлений від ваг моделі. Його розмір визначається кількістю шарів моделі, кількістю KV-голів, розмірністю голови, довжиною контексту та точністю кешу. Увімкніть довгий контекст, і ви можете додати десятки гігабайт, про які модель, що благополучно завантажилась, вас так і не попередила.
Формула досить коротка, щоб тримати її в голові:
байти KV-кешу = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Провідна 2 - за два тензори, що зберігаються на токен, один для ключів, один для значень. bytes_per_element дорівнює 2 для кешу FP16. Решта - архітектурні константи, які можна прочитати з картки моделі.
Розрахуємо для Llama 3.1 8B, яка має 32 шари, 8 KV-голів і розмірність голови 128. При контексті 4096 токенів, розмірі батчу 1, кеші FP16:
2 × 32 × 8 × 128 × 4096 × 2 байти ≈ 536 МБ
Збільшуйте контекст, і число зростає разом з ним, оскільки кожен доданок, крім context_tokens, є фіксованим:
- Контекст 4K: ~536 МБ
- Контекст 32K: ~4,3 ГБ
- Контекст 128K: ~17 ГБ
Ці останні дві цифри пояснюють, чому модель може заявляти вікно контексту 128K, спокійно завантажуватися, а потім вичерпати пам'ять тієї миті, коли ви справді використаєте це вікно. KV-кеш при повному контексті більший за самі квантизовані ваги.
Ось частина, завдяки якій сучасні моделі з довгим контекстом взагалі можливі: Llama 3.1 8B використовує Grouped Query Attention (GQA)Вона має 32 голови запитів, але лише 8 KV-голів, кеш зберігає вектори ключ/значення лише для 8 голів, а не для 32. Запустіть ту саму формулу з 32 KV-головами (старіший дизайн Multi-Head Attention, де кількість KV-голів дорівнює кількості голів запитів), і кожне число вище множиться на 4. Ті 17 ГБ при 128K стають 68 ГБ. GQA - архітектурна причина, чому математика залишається стерпною в міру зростання вікон контексту.
Розмір файлу - не ваш бюджет пам'яті. Коли ваги чи KV-кеш більше не вміщуються у швидкий шлях пам'яті, і середовищу виконання доводиться повертатися до системної RAM через PCIe, пропускна здатність не деградує плавно. Вона різко обвалюється, щойно ви переміщуєте дані через PCIe для кожного токена. Плануйте пам'ять так, щоб вміщувалися і ваги, і KV-кеш за вашої реальної довжини контексту, а не лише ваги.
Як обрати квантизацію для своєї GPU чи Mac?
Почніть з вашого апаратного забезпечення та середовища виконання. Власники GPU NVIDIA мають найширше меню і мають зважити EXL2 заради чистої швидкості або GGUF заради переносності. Якщо у вас AMD, Apple Silicon, апаратне забезпечення лише з CPU або змішана конфігурація, GGUF через llama.cpp зазвичай є найбезпечнішою відправною точкою. Звідти оберіть найвищий рівень квантизації, який вміщується після того, як ви заклали бюджет на KV-кеш для довжини контексту, яку ви справді використовуєте, а не максимуму моделі.
Одна пастка Apple Silicon, про яку варто знати: GPU не отримує всю вашу уніфіковану пам'ять (повну картину того, як працює цей спільний пул, дивіться в нашій супутній статті про те, що таке уніфікована пам'ять насправді ). Спільнота self-hosting задокументувала обмеження близько 75% від загальної уніфікованої пам'яті, доступної GPU (це офіційно не підтверджено Apple і може змінюватися з оновленнями macOS). Тож «64 ГБ Mac» реалістично дає ~48 ГБ для моделі плюс її KV-кеш, плануйте, виходячи з меншого числа.
Ця стаття про те, як читати формат і передбачати його поведінку під час виконання: розшифрувати назву квантизації, обрати формат, який підтримує ваше апаратне забезпечення, і закласти бюджет на KV-кеш окремо від ваг. Зіставлення конкретної моделі з конкретним обсягом пам'яті, довідкова таблиця розмір-пам'ять, - це пов'язане, але окреме питання, яке ми розглянемо в майбутній супутній статті.
Прочитайте репозиторій
Тепер ви можете подивитися на сторінку моделі і прочитати її, а не вгадувати. Розшифруйте назву квантизації до її ефективної бітової розрядності, визнайте, що GGUF - найширший локальний формат, тоді як GPTQ, AWQ і EXL2 більш специфічні для середовища виконання, і пам'ятайте, що розмір файлу - лише підлога, KV-кеш накладається зверху і росте разом з вашим контекстом. Відкрийте файли для потрібної вам моделі, оберіть формат, який може запустити ваше апаратне забезпечення, виберіть найвищий рівень квантизації, який вміщується після того, як ви залишили запас для KV-кешу при вашій реальній довжині контексту, і ви уникнете аварії через нестачу пам'яті, з якої почалося все це питання.
Часті запитання
Що означає Q4_K_M?
Q4_K_M - це рівень квантизації GGUF: приблизно 4 біти на вагу (Q4), з використанням масштабування K-квант на блок (K), на середньому рівні розміру/якості (M). Його ефективна ефективна становить приблизно 4,89 біта на вагу, а не рівно 4, оскільки K-кванти зберігають масштаб і мінімальне значення для кожного блоку ваг. Ось чому файл «4-бітної» моделі 8B становить близько 4,6 ГБ, а не 3,5 ГБ.
Чи знижує квантизація якість LLM?
Так, але вартість сильно залежить від того, наскільки далеко ви це доведете. Для Llama-3.1-8B-Instruct, виміряного в arXiv:2601.14277, перплексія зростає лише приблизно на 0,4% при Q6_K і залишається близько 1% протягом усього діапазону Q5. Опустіться до Q4, і зростання все ще помірне (кілька відсотків); нижче Q3_K_M воно круто зростає, досягаючи +22% при Q3_K_S. Для більшості випадків використання Q4_K_M і вище практично безвтратний; крутий штраф починається на 3 бітах і нижче.
У чому різниця між GGUF, GPTQ, AWQ і EXL2?
GGUF (запускається через llama.cpp) - переносний формат, він працює на CPU, GPU або в гібридній конфігурації на широкому спектрі апаратного забезпечення. GPTQ, AWQ і EXL2 більш специфічні для GPU та середовища виконання. При 4 бітах усі чотири можуть потрапити у вузький діапазон якості, тож практична різниця - апаратне забезпечення, підтримка завантажувача, швидкість і використання VRAM: EXL2 - вибір, орієнтований на швидкість, для NVIDIA/CUDA, AWQ поширений у стеках обслуговування, GPTQ підходить старішим інструментам GPU та репозиторіям моделей, а GGUF залишається найпереноснішим локальним варіантом.
Чому моя локальна LLM споживає більше пам'яті, ніж файл?
Розмір файлу - це лише ваги моделі. Під час виконання ви також платите за KV-кеш (стан уваги для кожного токена у вікні контексту), активації та накладні витрати фреймворку плюс драйвера. KV-кеш - зазвичай винуватець, коли розрив великий, оскільки він росте з довжиною контексту і виділяється окремо від ваг, модель, файл якої важить кілька гігабайт, може потребувати набагато більше пам'яті, щойно ви встановите довгий контекст.
Як довжина контексту впливає на використання пам'яті?
KV-кеш зростає приблизно лінійно з довжиною контексту, тож подвоєння контексту приблизно подвоює кеш. Для Llama 3.1 8B кеш становить приблизно 536 МБ при 4K токенах, ~4,3 ГБ при 32K і ~17 ГБ при 128K (FP16, один потік). Це зростання повністю відокремлене від ваг моделі, тому декларування довгого вікна контексту може загнати модель у нестачу пам'яті, навіть якщо вона благополучно завантажилась.


