
In den 60ern und 70ern, monolithische Architektur war aufgrund begrenzter Rechenressourcen die bevorzugte Methode zur Anwendungsentwicklung – alle Funktionen wurden dabei in einer einzigen, zusammenhängenden Einheit gebündelt.
Das änderte sich ab den späten 1990ern und 2000ern, als die monolithische Struktur zu limitierend für die immer größer werdenden und komplexer werdenden Anwendungen wurde, besonders mit dem Aufstieg des Internets und verteilter Systeme.
Dies führte zur Entwicklung modularerer Ansätze, wie etwa serviceorientierte Architekturen (SOA) und später Microservices-Architektur (MSA), was Anfang der 2010er Jahre zunehmend an Bedeutung gewann.
Das war jedoch nur ein kurzer Überblick über das grundlegende Konzept und den Einsatz von Microservices. Im Folgenden gehen wir darauf ein, wie Microservices die monolithische Architektur abgelöst haben, wie sie funktionieren und welche konkreten Beispiele es gibt. Anschließend behandeln wir die wichtigsten Aspekte bei der Bereitstellung von Microservices und zeigen, wie du dabei vorgehst.
Was sind Microservices? Wie funktionieren sie?
Wie bereits erwähnt, entstanden Microservices als Antwort auf zunehmende Anwendungskomplexität und wachsende Codebases – sie ermöglichen es Unternehmen, Funktionen in unabhängig deploybare Services aufzuteilen.
Der Begriff "Microservices" wurde von Branchenexperten wie Martin Fowler und James Lewis populär gemacht, die ihn 2014 in einem Blog-Post formal einführten. Ihre Arbeit definierte Kernprinzipien und Merkmale, darunter unabhängig deploybare Services, dezentrales Datenmanagement und Technologie-Unabhängigkeit.
Seitdem haben sich Microservices zu einer weit verbreiteten Architekturentscheidung entwickelt, unterstützt durch Fortschritte in Containerisierungstechnologien wie Docker, Orchestrierungstools wie Kubernetes und serverlose Computing-Plattformen. Aber wie funktionieren Microservices?
Wie funktionieren Microservices?
Im Kern zerlegt eine Microservices-Architektur eine große Anwendung in kleinere, eigenständige Dienste, von denen jeder für eine bestimmte Geschäftsfunktion zuständig ist. Diese Dienste kommunizieren über ein Netzwerk miteinander, häufig über REST APIs, gRPC oder Message-Broker wie RabbitMQ oder Apache Kafka.
Laut der Definition von Martin Fowler und James Lewis weisen Microservices vier zentrale Merkmale auf:
- Einzelne Verantwortung: Jeder Microservice ist für eine spezifische Aufgabe oder Funktion ausgelegt, was Spezialisierung ermöglicht und Komplexität reduziert.
- Unabhängigkeit: Microservices können unabhängig voneinander entwickelt, bereitgestellt und skaliert werden, was Flexibilität und Ausfallsicherheit bietet.
- Dezentrales Datenmanagement: Microservices verfügen häufig über eigene Datenbanken, sodass keine zentrale Datenbank benötigt wird.
- Technologiefreiheit: Teams können für jeden Service die passende Technologie wählen, ohne an die Entscheidungen anderer Services gebunden zu sein.
Dieser Ansatz steht im Gegensatz zur klassischen monolithischen Architektur, bei der alle Anwendungskomponenten eng miteinander zu einer einzigen Einheit verknüpft sind.
Die wichtigsten Phasen der Microservices-Bereitstellung
Eine Microservices-Architektur bietet viele Vorteile - hohe Skalierbarkeit, Flexibilität, Effizienz, Fehlereingrenzung und mehr. Damit das Ganze funktioniert, braucht es jedoch ein solides Verständnis der Bereitstellung sowie sorgfältige Planung.
Deshalb ist es entscheidend, die wichtigsten Konzepte, Phasen und Best Practices für die Bereitstellung von Microservices zu kennen. Im Folgenden gehen wir die zentralen Phasen der Microservices-Bereitstellung durch und erläutern, was in jeder Phase zu beachten ist.
Planung und Vorbereitung der Microservices-Bereitstellung
Gute Ergebnisse erfordern Planung und Geduld. Für eine erfolgreiche Microservices-Bereitstellung gilt das besonders. Deshalb lohnt es sich, die Best Practices zu befolgen und alles Notwendige im Voraus zu planen und vorzubereiten.
Wie bereits erwähnt, ist eines der Kernprinzipien von Microservices das Prinzip der Einfachverantwortlichkeit. Wenn jeder Microservice konsequent auf genau eine Funktion und Verantwortlichkeit ausgerichtet ist, kann das Team Services unabhängig voneinander entwickeln, bereitstellen und skalieren.
Eine Erweiterung dieses Prinzips ist das Loose-Coupling-Designprinzip. Es besagt, dass jeder Service für seine Kommunikation eigenständig funktioniert und möglichst wenige Abhängigkeiten zu anderen Services hat. Änderungen an einem Service wirken sich dadurch nicht auf andere aus, was eine unabhängige Skalierung ermöglicht.
Das reduziert das Risiko von Kaskadenfehlern, bei denen ein Problem in einem Systemteil eine Kettenreaktion auslöst, die sich durch das gesamte System zieht und den Dienst vollständig zum Erliegen bringt.
Eine wichtige Best Practice ist es, jedem Service seinen eigenen Datenspeicher zuzuweisen. Das ist eine direkte Konsequenz des Loose-Coupling-Prinzips: Es verhindert Konflikte und verbessert die Skalierbarkeit der einzelnen Services.
Außerdem werden asynchrone Kommunikationsmuster wie Message Broker benötigt, damit Services miteinander kommunizieren können, ohne direkte Abhängigkeiten zu erzeugen.
Das letzte wichtige Element ist die Einrichtung von Continuous Integration und Continuous Delivery (CI/CD)-Pipelines für Microservices. Mit diesen Pipelines können Teams neue Features oder Fixes über CI/CD-Tools wie Jenkins und GitLab ausliefern und dabei die Systemstabilität aufrechterhalten, während regelmäßig neue Funktionen veröffentlicht werden.
Nachdem wir uns mit Planung und Vorbereitung der Microservices-Bereitstellung beschäftigt haben, geht es nun um die verschiedenen Bereitstellungsstrategien.
Microservices-Bereitstellungsstrategien
Bei der Bereitstellung von Microservices hängt die Wahl der Deployment-Strategie von der Servicefunktion, dem Datenverkehr, der Infrastruktur, dem Know-how des Teams und den Kosten ab. Grundsätzlich gibt es folgende Microservices-Deployment-Strategien:
- Eine Service-Instanz pro Container: Bei diesem Ansatz läuft jeder Microservice in einem eigenen Container, was eine bessere Isolation bietet als das Modell mit mehreren Instanzen pro Host. Container erleichtern die Skalierung und verbessern die Ressourcenverteilung.
- Eine Service-Instanz pro virtuelle Maschine: Jeder Service läuft in einer eigenen virtuellen Maschine (VM), was noch mehr Isolation bietet als Container. Das verbessert zwar Sicherheit und Stabilität, verursacht aber in der Regel mehr Overhead.
- Phasenweise Releases: Neue Microservice-Versionen werden zunächst an eine kleine Nutzergruppe ausgerollt und auf ihre Stabilität getestet, bevor sie vollständig veröffentlicht werden. Dieser Ansatz minimiert die Auswirkungen bei Problemen und ermöglicht schnelle Rollbacks, um die Systemintegrität zu wahren.
- Blau-Grün-Bereitstellung Diese Methode nutzt zwei identische Produktionsumgebungen: Eine bedient den Live-Traffic, während die andere für Tests des nächsten Releases verwendet wird. Blue-Green Deployment ermöglicht einfache Rollbacks und unterbrechungsfreie Updates, da der Traffic zwischen den beiden Umgebungen umgeschaltet werden kann.
- Stufenweise Releases: Bei dieser Strategie werden Updates schrittweise an verschiedene Nutzergruppen oder Umgebungen ausgerollt. Sie beginnt häufig mit internen Umgebungen, bevor sie die Produktion erreicht. Das begrenzt den Schadensradius bei möglichen Problemen und gibt Teams die Möglichkeit, Fehler in einzelnen Stufen zu beheben.
- Serverless-Bereitstellung: Dieser Ansatz nutzt serverlose Plattformen wie AWS Fargate und Google Cloud Run, die das Infrastrukturmanagement übernehmen, indem sie Skalierung und Ressourcenverteilung automatisch regeln. Beim Serverless Deployment müssen keine zugrundeliegenden Server verwaltet werden, sodass man sich vollständig auf die Microservices selbst konzentrieren kann.
Sobald man sich für eine der oben genannten Deployment-Strategien entschieden hat, wird ein Microservices-Orchestrierungswerkzeug benötigt.
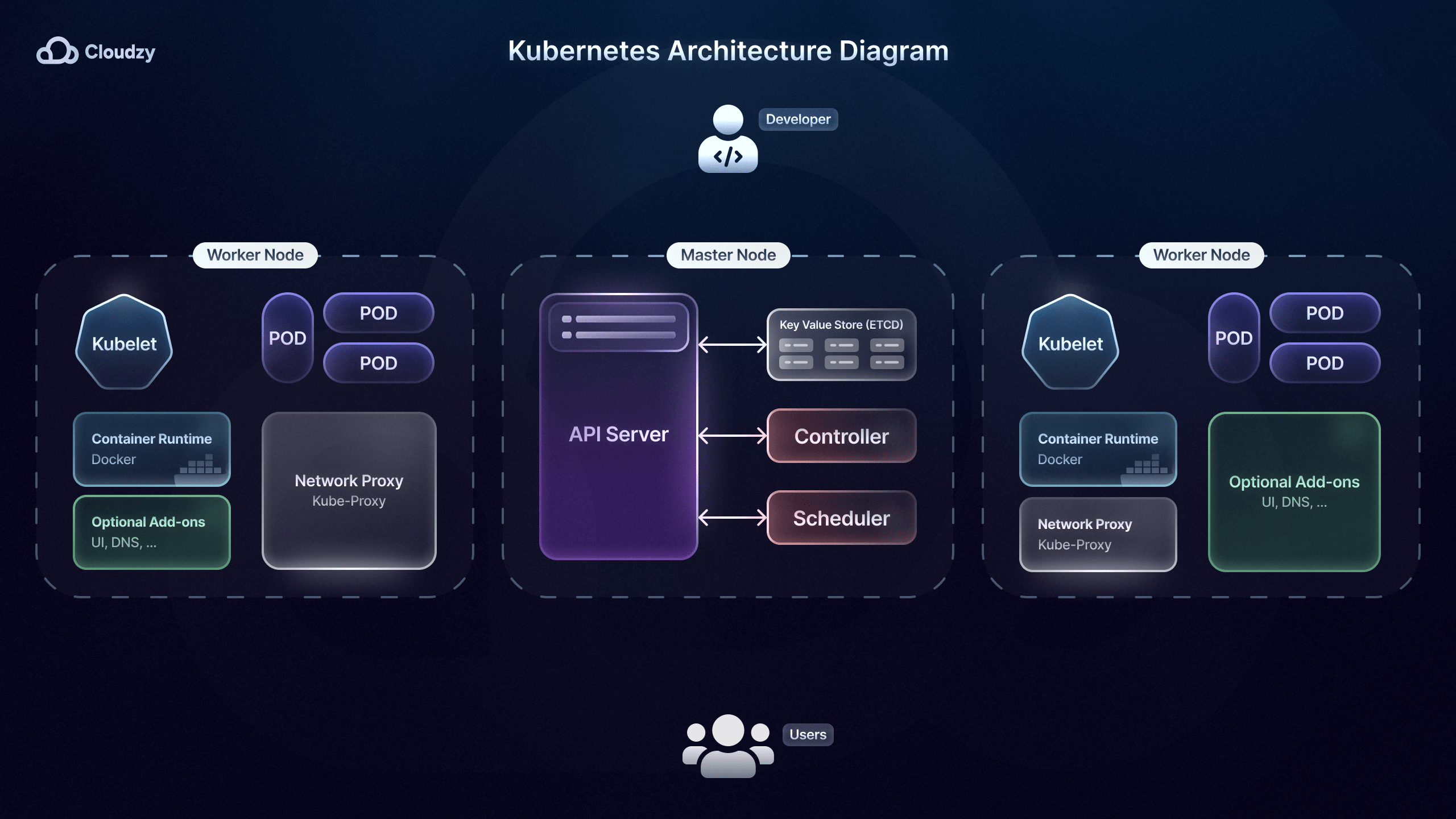
Microservices-Orchestrierung
Nach der Wahl einer der vielen Microservices-Deployment-Strategien braucht man eine Art Dirigenten für die Microservice-Orchestrierung. Orchestrierungswerkzeuge wie Kubernetesautomatisieren die Bereitstellung, Skalierung, Überwachung und Verwaltung containerisierter Microservices.
Airbnb setzt zum Beispiel auf Kubernetes, damit seine Entwickler Hunderte von Änderungen an Microservices ohne manuelle Aufsicht einzuspielen. Eine wichtige Funktion von Orchestrierungswerkzeugen wie Kubernetes ist der integrierte Load Balancing.
Eine leistungsfähige Load-Balancing-Funktion verteilt eingehenden Traffic auf mehrere Instanzen eines Microservice. Dadurch wird verhindert, dass eine einzelne Instanz zum Flaschenhals wird, und die Fähigkeit des Systems, Traffic-Spitzen zu bewältigen, wird verbessert.
Kubernetes spielt eine zentrale Rolle bei der Verwaltung von Microservices durch seine Self-Healing-Fähigkeiten: Ausgefallene Container werden automatisch ersetzt und neu gestartet. Die New York Times nutzt diese Funktion, um ihre Microservices ohne Beeinträchtigung der Nutzererfahrung und ohne Ausfallzeiten am Laufen zu halten.
Darüber hinaus verbessert Kubernetes auch die Sicherheit von Microservices, indem Konfigurationen und Geheimnisse wie Datenbank-Zugangsdaten oder API-Schlüssel über ConfigMaps und Secrets verwaltet werden. Das ist besonders wichtig für Unternehmen und Dienste wie Uber, die mit sensiblen Kunden- und Nutzerdaten arbeiten.
Orchestrierungswerkzeuge wie Kubernetes sind außerdem besonders nützlich für Microservice-Strategien mit Rolling Updates und Rollbacks, etwa bei stufenweisen Releases. Rolling Updates ermöglichen es, neue Microservice-Versionen ohne Unterbrechungen einzuspielen, indem einige Instanzen der alten Version weiter aktiv bleiben.
Sobald das Microservices-Orchestrierungswerkzeug eingerichtet ist, müssen CI/CD Pipelines für das Deployment von Microservices.
CI/CD Pipelines für Microservices-Deployments
Wie bereits erwähnt, sind CI/CD-Pipelines ein zentraler Bestandteil des Microservices-Deployments. Der CD-Teil der Pipeline sorgt dafür, dass Code-Änderungen automatisch in die Produktion überführt werden, sobald sie die Test- und Integrationsphasen durchlaufen haben.
Sobald Code-Änderungen die Test- und Integrationsphase bestehen, übernimmt der CD-Teil der CI/CD-Pipeline und stellt den Service in einem Microservices-Orchestrierungswerkzeug bereit, etwa in einem Kubernetes-Cluster.
Die Test- und Integrationsphasen laufen vollständig automatisiert ab: Unit-Tests, Integrationstests und End-to-End-Tests sind direkt in die Pipeline integriert.
So können Teams jede Änderung stufenweise validieren, ohne die Systemstabilität zu gefährden. Treten trotz der umfangreichen Tests Probleme auf, stellen automatisierte Rollbacks die letzte stabile Version wieder her.
CI/CD-Pipelines konsequent nach Best Practices für Microservices einzusetzen hilft Teams dabei, schneller zu entwickeln, manuelle Fehler zu reduzieren und gleichbleibend hohe Qualität zu sichern.
Unternehmen wie Spotify, Expedia, iRobot, Lufthansa und Pandora nutzen CI/CD-Pipelines für ihre Microservices - mit Tools wie CircleCI, AWS CodePipeline und GitLab. So automatisieren sie ihre Deployment-Prozesse, stellen konsistente Code-Qualität sicher und liefern neue Features schnell aus, ohne die Systemstabilität zu beeinträchtigen.
Kommunikationsmuster für Microservices
Wie Microservices miteinander kommunizieren, hängt von der jeweiligen Funktion, der Gesamtarchitektur sowie den gewünschten Skalierungs- und Zuverlässigkeitsanforderungen ab. Grundsätzlich kommen zwei Hauptarten von Kommunikationsmustern zum Einsatz: synchron und asynchron Kommunikationsmuster für Microservices.
Bei synchronen Kommunikationsmustern interagieren Services in Echtzeit: Ein Service sendet eine Anfrage und wartet auf die Antwort, bevor er weitermacht. Die am häufigsten eingesetzten synchronen Kommunikationsmuster sind REST (Representational State Transfer) APIs, gRPC (Google Remote Procedure Call), und GraphQL.
Diese Kommunikationsmuster werden vor allem in Branchen eingesetzt, die Echtzeit-Datenverarbeitung und sofortige Antworten erfordern. Finanzwesen, Gesundheitswesen und E-Commerce setzen häufig auf synchrone Kommunikation, um Transaktionen, Datenabrufe und Interaktionen ohne Verzögerung abzuwickeln und eine reaktionsschnelle Nutzererfahrung zu gewährleisten.
Synchrone Kommunikationsmuster bieten zwar Vorteile wie Echtzeit-Antworten und einfache Implementierung, bringen aber auch Nachteile mit sich: enge Kopplung kann zu Engpässen führen, die Skalierbarkeit unter Last ist begrenzt, und bei hohem Traffic steigen Antwortzeiten und Latenz.
Asynchrone Kommunikationsmuster hingegen eignen sich für Microservices meist besser, da sie auf dem Prinzip der losen Kopplung basieren, das wir bereits besprochen haben.
Dieses Kommunikationsmuster entkoppelt Services, indem es ihnen erlaubt, Nachrichten über einen Broker wie Kafka oder RabbitMQ auszutauschen. Nachrichten werden in eine Warteschlange gestellt, die als Puffer fungiert - Services kommunizieren dadurch unabhängig voneinander, ohne auf eine Antwort warten zu müssen. Der Sender kann seine Arbeit fortsetzen, während andere Services die Nachrichten in ihrem eigenen Tempo verarbeiten.
Das asynchrone Kommunikationsmuster bietet nicht nur eine lose gekoppelte Struktur für das Microservices-Deployment, sondern ermöglicht auch Echtzeit-Reaktionen, die synchronen Mustern in nichts nachstehen.
Das ist der ereignisgesteuerten Architektur asynchroner Kommunikationsmuster zu verdanken: Services kommunizieren, indem sie bei bestimmten Aktionen Ereignisse auslösen. Andere Services können diese Ereignisse abonnieren und entsprechend reagieren. So entstehen hochreaktive Systeme, die Änderungen in Echtzeit verarbeiten - ganz ohne direkte Kopplung zwischen den Services.
Darüber hinaus bietet das asynchrone Veröffentlichen-Abonnieren (Pub/Sub) Bei Microservices-Kommunikationsmustern senden die Dienste (Publisher) Nachrichten an ein Topic, und andere Dienste (Subscriber) lauschen auf dieses Topic, um Updates zu empfangen. Dieses Modell unterstützt mehrere Subscriber und überträgt Nachrichten gleichzeitig an viele Dienste.
Ähnlich wie ereignisgesteuerte Muster nutzen asynchrone Choreographie-basierte Saga Microservices-Kommunikationsmuster ebenfalls Ereignisse zur Kommunikation untereinander. In diesem Muster liegt jedoch eine bestimmte Reihenfolge vor: Ereignisse lösen den nächsten Schritt aus und aktivieren einen bestimmten Dienst.
Der Unterschied zu ereignisgesteuerten Mustern besteht darin, dass dort keine feste Abfolge oder kein festgelegter Workflow existiert und mehrere Dienste auf ein Ereignis reagieren können, anstatt einem spezifischen Prozess und einer bestimmten Reihenfolge wie im choreographie-basierten Saga-Muster zu folgen.
Welches asynchrone Microservices-Kommunikationsmuster Sie verwenden, hängt von der Aufgabe und dem Gesamtzweck Ihrer Microservices ab. Message Queues wie RabbitMQ und Amazon SQS werden typischerweise für Task Scheduling, Lastverteilung sowie E-Commerce-Bestellverarbeitung und Benachrichtigungssysteme eingesetzt.
Ereignisgesteuerte Message Broker wie Apache Kafka und AWS EventBridge werden typischerweise für die Verarbeitung großer Ereignisströme in Echtzeit und das Ereignis-Routing zwischen Microservices in Bereichen wie Finanzdienstleistungen und AWS-Umgebungen genutzt.
Publish-Subscribe-Message-Broker (Pub/Sub) wie Google Cloud Pub/Sub und Redis Streams werden in der Regel für skalierbare Nachrichtenübermittlung in verteilten Systemen eingesetzt, zum Beispiel für Echtzeit-Analysen, Event Ingestion sowie Echtzeit-Benachrichtigungen und Chat-Anwendungen.
Choreographie-basierte Saga-Message-Broker werden hauptsächlich für eCommerce-Bestellverarbeitung, Reisebuchungssysteme und Anwendungsfälle eingesetzt, bei denen komplexe, mehrstufige Transaktionen über mehrere Dienste hinweg ohne zentrale Steuerung koordiniert werden müssen.
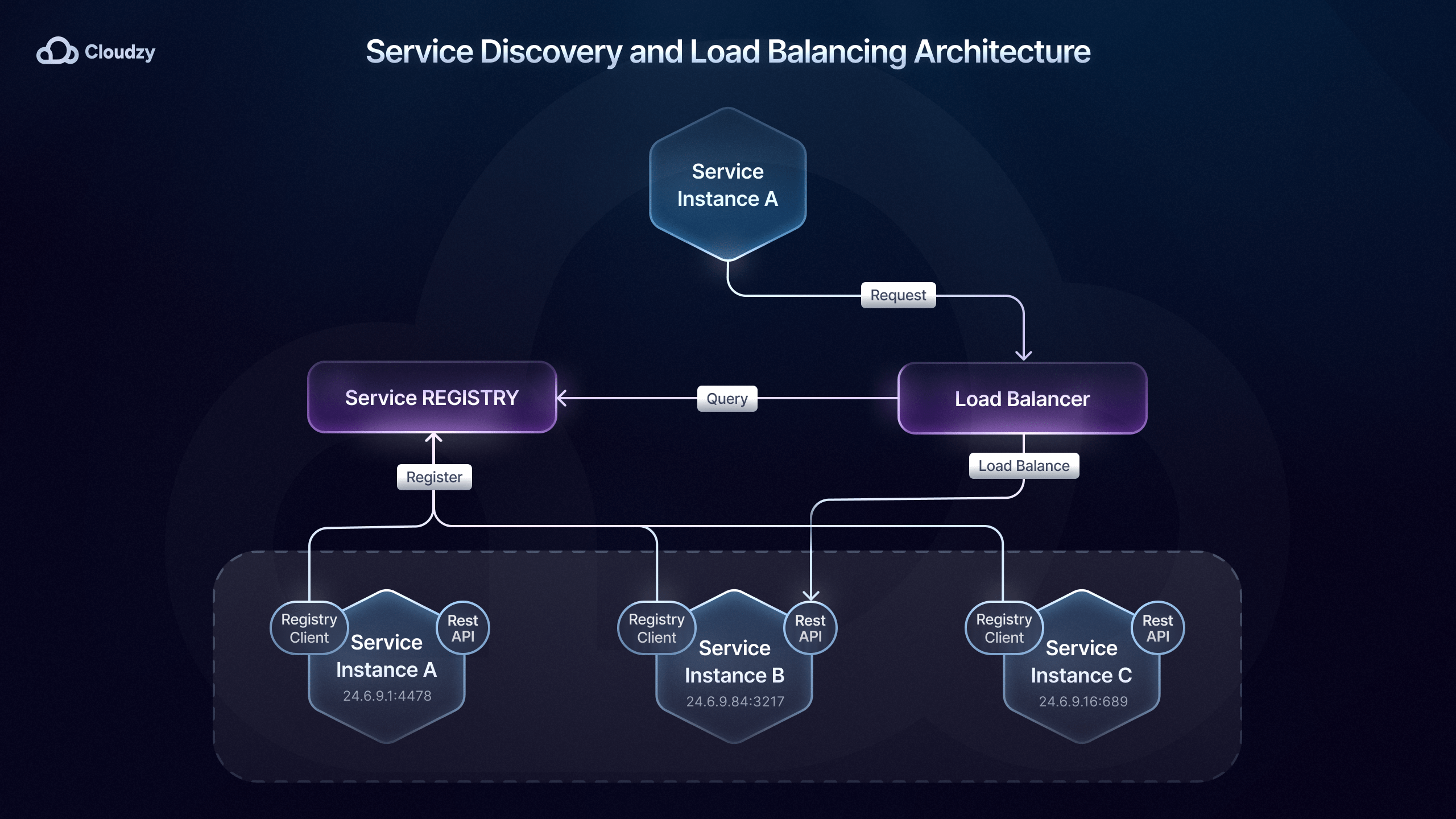
Microservice-Diensterkennung
Sobald Sie ein passendes Kommunikationsmuster eingerichtet und implementiert haben, müssen Sie sicherstellen, dass Ihre Dienste sich gegenseitig überhaupt auffinden können. Wie bereits erwähnt, spielen Microservices-Orchestrierungstools wie Kubernetes dabei eine wichtige Rolle bei der Microservice Service Discovery.
Dies geschieht über die integrierte Service Discovery von Kubernetes DNS, die IP-Adressen und DNS-Einträge dynamisch aktualisiert, wenn Dienste skalieren oder ihren Standort im Cluster wechseln.
Diese Methode der Microservices Service Discovery wird als serverseitige Discovery bezeichnet, da die Routing-Verantwortung an einen Load Balancer delegiert wird, der die Registry abfragt und den Traffic an die passende Instanz weiterleitet.
Daneben gibt es auch die clientseitige Discovery-Methode, bei der der Dienst oder das API-Gateway eine Service Registry wie Consul oder Eureka abfragt, um verfügbare Instanzen zu finden.
Welche Methode der Service Discovery für Ihr Microservices-Deployment am besten geeignet ist, hängt von den Anforderungen und dem Umfang Ihres Systems ab.
Bei der clientseitigen Microservice Service Discovery hat der Client die volle Kontrolle darüber, mit welcher Instanz er kommuniziert. Das ermöglicht mehr Anpassungsmöglichkeiten und reduziert die Komplexität, da kein zentraler Discovery-Dienst benötigt wird.
Netflix setzt beispielsweise bei seinem Microservices-Deployment auf clientseitige Service Discovery mit Eureka und Ribbon für das Load Balancing, sodass der Client die beste Instanz anhand von Kriterien wie Latenz und Serverlast auswählen kann.
Für größere Umgebungen ist die serverseitige Microservice Service Discovery besser geeignet, da ein zentraler Discovery-Dienst die Effizienz steigert und ein konsistentes Load Balancing in verteilten Systemen ermöglicht.
Serverseitige Microservice-Service-Discovery-Lösungen wie Kubernetes, AWS Elastic Load Balancing und API Gateways (Kong, NGINX usw.) leiten Traffic effizient weiter, gewährleisten hohe Verfügbarkeit und werden von Unternehmen wie Airbnb, Pinterest, Expedia und Lyft eingesetzt.
Microservice-Sicherheit
Auch wenn monolithische Architekturen der Microservice-Architektur (MSA) in den meisten Punkten unterlegen sind, hatte die monolithische Architektur bei der Sicherheit einen Vorteil. Da Microservices auf dem Prinzip der losen Kopplung basieren und von Natur aus verteilt sind, lässt sich keine einheitliche, übergreifende Sicherheitsmaßnahme umsetzen.
Da jeder Dienst eigenständig abgesichert werden muss und die Angriffsfläche bei Microservices deutlich größer ist, sind zusätzliche Schutzmaßnahmen erforderlich. Zu diesem Zweck werden Standards wie OAuth2 und JSON Web Tokens (JWT) häufig für Authentifizierung und Autorisierung eingesetzt.
Darüber hinaus wird oft ein API-Gateway eingesetzt, um die Sicherheit über alle Microservices hinweg zu verwalten, da es Authentifizierung und Autorisierung am Eintrittspunkt durchsetzt. Gateway-APIs können außerdem Rate Limiting, Logging und Monitoring implementieren, was zusätzliche Sicherheitsschichten für Microservices schafft.
Diese Maßnahmen sichern zwar den Haupteinstiegspunkt, aber für die Kommunikation zwischen den Diensten sind weitere Microservice-Sicherheitsmaßnahmen notwendig.
Genau hier kommen Service Meshes ins Spiel: Sie fügen eine zusätzliche Sicherheitsebene hinzu, verschlüsseln den Datenverkehr zwischen Services und setzen Richtlinien wie gegenseitiges TLS durch. Im Wesentlichen richten diese Service Meshes eine durchgängige Ende-zu-Ende-Verschlüsselung ein, die die Microservice-Sicherheit erheblich verbessert.
Microservice-Skalierung
Einer der größten Vorteile von MSA - und der Hauptgrund, warum es zur Ablösung monolithischer Architekturen entwickelt wurde - ist die hohe Skalierbarkeit. Grundsätzlich gibt es zwei Wege, Microservices zu skalieren: vertikal und horizontal.
Vertikale Microservice-Skalierung (Scale-up) bedeutet, einer bestehenden Instanz mehr Ressourcen hinzuzufügen, etwa mehr CPU oder Arbeitsspeicher. Horizontale Microservice-Skalierung (Scale-out) dagegen verteilt die Last und erhöht die Gesamtkapazität.
Was die Umsetzung betrifft, ist die vertikale Skalierung die einfachere der beiden Varianten: Man muss lediglich eine einzelne Instanz anpassen - zum Beispiel auf einen größeren Server migrieren, Arbeitsspeicher oder Rechenleistung in einer Cloud-Instanz erhöhen oder weiteren Speicherplatz hinzufügen.
Diese Skalierungsform kommt typischerweise dann zum Einsatz, wenn eine höhere RAM- oder CPU-Leistung die Abfrageverarbeitung und Datenverarbeitung verbessert, etwa bei Services, die für In-Memory-Caching zuständig sind.
Allerdings hat die vertikale Skalierung trotz ihrer Einfachheit und des sofortigen Leistungsgewinns auch Nachteile. Sie ist durch die Hardwarekapazität des Servers begrenzt, sodass man ab einem bestimmten Punkt auf horizontale Skalierung umsteigen muss, um weiter wachsen zu können.
Hinzu kommen die hohen Kosten: Leistungsstärkere Hardware und größere Instanzen sind in der Regel teuer. Außerdem bedeutet ein Ausfall der skalierten Instanz, dass der gesamte Service nicht mehr verfügbar ist - es gibt keine weiteren Instanzen, die die Last übernehmen könnten.
Bei der horizontalen Microservice-Skalierung werden statt der Ressourcen einer einzelnen Instanz neue Instanzen desselben Service gestartet. Diese Instanzen arbeiten zwar unabhängig voneinander, verarbeiten aber denselben Service und Teile derselben Arbeitslast.
Anders als bei der vertikalen Skalierung gibt es bei der horizontalen keine feste Obergrenze: Man kann beliebig viele Instanzen hinzufügen, um steigende Lasten und Traffic-Spitzen zu bewältigen, und gewinnt damit deutlich mehr Flexibilität.
Da mehrere Instanzen vorhanden sind, ist ein Ausfall einer einzelnen Instanz kein kritisches Problem - die anderen Instanzen übernehmen die Anfragen ohne Unterbrechung. Zudem ist horizontale Skalierung langfristig deutlich kosteneffizienter, weil mehrere kleinere und günstigere Instanzen gemeinsam eine zuverlässigere und leistungsfähigere Infrastruktur bilden.
Allerdings erfordert horizontale Skalierung mit jeder neuen Instanz auch mehr Load Balancer, Service-Discovery-Mechanismen und Orchestrierungswerkzeuge, was die Microservices-Architektur insgesamt erheblich komplexer macht.
Horizontale Skalierung eignet sich besonders für Web-Services und Anwendungen wie E-Commerce-Plattformen oder soziale Netzwerke, die häufig starken Schwankungen im Traffic und einem hohen Anfragevolumen ausgesetzt sind.
Es ist jedoch keine Entweder-oder-Entscheidung: Beide Skalierungsarten werden in Microservices-Umgebungen unterstützt und sind in vielen Fällen notwendig. Kleinere Organisationen setzen häufig zunächst auf vertikale Skalierung, da sie einfacher umzusetzen und zu verwalten ist. Mit der Zeit und dem Wachstum der Anwendung kommt dann horizontale Skalierung hinzu, um den steigenden Anforderungen gerecht zu werden.
Außerdem bieten Cloud-Plattformen Auto-Scaling-Dienste an, die Instanzen automatisch je nach aktuellem Bedarf hinzufügen oder entfernen. Das hilft Organisationen erheblich dabei, vertikale und horizontale Skalierung sinnvoll miteinander zu kombinieren.
Microservice-Monitoring
Zu diesem Zeitpunkt ist die Bereitstellung der Microservices weitgehend abgeschlossen - es bleibt nur noch sicherzustellen, dass alles zuverlässig und konsistent funktioniert. Genau hier kommen Microservice-Monitoring-Tools wie Prometheus und Grafana ins Spiel.
Diese Tools liefern Echtzeit-Einblicke in Service-Metriken, sodass Teams Ressourcennutzung, Latenz und Fehlerquoten im Blick behalten können. Darüber hinaus bieten sie Distributed Tracing (Jaeger, Zipkin usw.), das Request-Flows zwischen Services visualisiert und bei der Fehlerdiagnose erheblich helfen kann.
Da Fehler in Microservices-Architekturen aufgrund des verteilten Designs schnell auf andere Services übergreifen können, ist Log-Aggregation ein zentraler Bestandteil des Monitorings. Durch die Zusammenführung aller Logs in einer zentralen Plattform und die Einrichtung von Echtzeit-Alarmen bleiben Probleme stets im Blick - und können behoben werden, bevor sie Nutzer beeinträchtigen.
Fazit
Microservices sind zweifellos ein komplexes Thema, aber wer die Grundlagen und die wichtigsten Schritte der Bereitstellung versteht, macht den gesamten Prozess deutlich handhabbarer. Zudem stehen mit der Zeit immer mehr Tools mit umfangreicheren Funktionen zur Verfügung, die die Microservices-Bereitstellung zunehmend vereinfachen.
Häufig gestellte Fragen
Welche Deployment-Strategien werden üblicherweise für Microservices eingesetzt?
Es gibt viele verschiedene Strategien für Microservices-Deployments. Zu den am häufigsten eingesetzten gehören Service-Instanzen pro Container, schrittweise Releases, Blue-Green-Deployment und Serverless-Deployment - jede mit unterschiedlichem Grad an Isolation, Flexibilität und Skalierbarkeit.
Welche Rolle spielt Kubernetes bei der Orchestrierung von Microservices?
Microservices sind auf Orchestrierungstools wie Kubernetes angewiesen, um containerisierte Dienste automatisch bereitzustellen, zu skalieren und zu verwalten. Diese Tools übernehmen Load Balancing, Auto-Scaling und Self-Healing, damit die Microservices stabil und effizient laufen.
Wie stelle ich die Sicherheit in einer Microservices-Umgebung sicher?
Durch ihre verteilte Natur sind Microservices in Bezug auf Sicherheit deutlich anspruchsvoller als monolithische Architekturen. Sicherheit in Microservices umfasst die Authentifizierung und Autorisierung von Anfragen, die Verschlüsselung der Kommunikation zwischen Diensten sowie den Einsatz von API-Gateways und Service Meshes wie Istio für ein zentrales Sicherheitsmanagement.


