
Die Schleife lief in Tests vierzig Mal fehlerfrei. Beim einundvierzigsten Durchlauf in der Produktion rief sie dasselbe SQL-Tool immer wieder mit derselben fehlerhaften Abfrage auf, bis das API-Budget des Tages aufgebraucht war und ein Abrechnungsalarm jemanden weckte. Niemand hatte ein schlechtes Modell geschrieben. Niemand hatte den Prompt geändert. Der Agent hatte schlicht nie entschieden, dass er fertig war.
Das ist das Muster, das ich immer wieder bei Teams beobachte, die einen Agenten von einem Prototyp auf eine 24/7-Arbeitslast umstellen. KI-Agenten-Schleifen scheitern in der Produktion oft nicht, weil das Modell plötzlich schlechter geworden ist, sondern weil der Ausführungs-Layer keine Terminierungsdisziplin, validierte Tool-Verträge, begrenzten Kontext und dauerhaften Zustand besitzt. Eine Agenten-Schleife ist ein stochastisches System, das eine sequenzielle Entscheidung nach der anderen trifft. Ohne ein paar spezifische Leitplanken wird aus dem seltenen Fehler ein garantierter, sobald man sie lange genug laufen lässt. Verwaltete Agenten-Plattformen (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) integrieren einige dieser Leitplanken bereits. Dieser Leitfaden richtet sich an alle, die sich für Self-Hosting entschieden haben und die Schleife selbst steuern.
Die Risiken sind real genug, dass Gartner erwartet, dass über 40 % der agentischen KI-Projekte bis Ende 2027 eingestellt werden, da die Kosten steigen und der Nutzen unklar bleibt. Im Folgenden werden sechs konkrete Wege beschrieben, auf denen Schleifen in der Produktion versagen, der jeweilige Mechanismus dahinter und das Harness-Muster, das das Problem behebt, einschließlich der LangGraph- und n8n-Details sowie der Anforderungen für einen echten 24/7-Betrieb.
Die Kurzfassung
- Infinite Loops: Der Agent entscheidet nie, dass er fertig ist. Kombinieren Sie eine harte Schritt-Obergrenze (LangGraph's
recursion_limit, Standardwert 25) mit einer Fortschrittsüberwachung, die wiederholte Tool-Aufrufe mit denselben Argumenten abbricht. - Context Overflow: Die Schleife füllt ihr eigenes Kontextfenster mit angesammeltem Verlauf, bis Aufrufe abgeschnitten werden oder scheitern. Fassen Sie den Verlauf in festen Intervallen zusammen, damit der Arbeitskontext begrenzt bleibt.
- Silent Tool Failures: Ein Tool gibt einen leeren String zurück, das Modell interpretiert das als gültige No-Op, und der Agent "schlägt fehl" beim Nichtstun. Validieren Sie jedes Tool-Ergebnis, bevor das Modell es sieht.
- Reasoning Degradation: Die Qualität nimmt ab, wenn der Kontext wächst, selbst unterhalb des harten Limits. Komprimieren Sie in der Schleife, schützen Sie dabei aber fixierte Sicherheitsanweisungen.
- State Loss on Restart: Ein Absturz bedeutet, von vorne zu beginnen. Checkpointing in Postgres (LangGraph
PostgresSaver), nicht SQLite, für die Produktion. - Retry Storms: Zehn Agenten, die jeweils zehn Mal wiederholen, treffen einen ausgefallenen Dienst mit hundert Anfragen. Fügen Sie exponentielles Backoff mit Jitter und einen globalen Circuit Breaker hinzu.
Was dieser Leitfaden nicht abdeckt
Dies ist ein Harness-Leitfaden, der sich auf die Technik um die Schleife herum konzentriert, nicht auf das Modell darin. Einige verwandte Themen werden bewusst ausgeklammert:
- Multi-Agenten-Koordinationsfehler (veraltete Lesevorgänge, verwaister Zustand zwischen Agenten): ein anderes Problem, das einen eigenen Beitrag verdient.
- Agentensicherheit (Prompt Injection, Tool Poisoning): eine separate Fehlerkategorie mit einem eigenen Bedrohungsmodell.
- Modellauswahl und Fine-Tuning. Dieser Leitfaden geht davon aus, dass Sie bereits ein Modell gewählt haben und das System darum herum debuggen.
- Verwaltete Agenten-Dienste, die oben erwähnt wurden. Die Muster hier gelten für den Self-Hosted-Pfad.
Infinite Loops: Wenn der Agent nie entscheidet, dass er fertig ist

Ein Agent läuft ewig in einer Schleife, wenn er weder eine harte Schritt-Obergrenze noch eine Möglichkeit hat, zu erkennen, dass er keinen Fortschritt mehr macht. Die Lösung besteht aus zwei Teilen: eine harte Obergrenze als Kosten-Backstop beibehalten und eine Fortschrittserkennung hinzufügen, die jeden Tool-Aufruf mit seinen Argumenten hasht und abbricht, wenn derselbe Aufruf erneut erscheint. In LangGraph ist diese Obergrenze der recursion_limit, Standardwert 25 Schritte. Wird dieser überschritten, wirft der Graph einen Fehler, GraphRecursionError.
LangGraph's Docs beschreiben dieses Limit als das Erreichen der "maximalen Anzahl von Schritten vor dem Eintreten einer Stopp-Bedingung", und hier liegt die Falle: Das recursion_limit ist kein Schleifenschutz. Es ist ein Backstop, der nachdem auslöst, nachdem die Schleife bereits fünfundzwanzig Schritte und die damit verbundenen API-Kosten verbraucht hat. Die eigene erlernte Terminierungslogik des Agenten soll ihn lange vorher stoppen, und diese Logik kann unabhängig versagen. Ein gemeldeter LangGraph-Fall zeigt einen Text-to-SQL-Agenten, der bis zum recursion_limit schleift, obwohl klare Stopp-Bedingungen im Prompt vorhanden waren. Er rief immer wieder dasselbe Query-Tool mit demselben fehlerhaften SQL auf, und das Problem wurde als "not planned" geschlossen. Das ist für mich ein klares Signal: Behandeln Sie die Obergrenze nicht als Stopp-Bedingung. Sie ist Ihr Sicherheitsgurt, nicht Ihre Bremse.
Die Obergrenze anzuheben ist einfach; Sie übergeben sie über die Konfiguration beim Aufruf des Graphen:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Was eine feststeckende Schleife tatsächlich stoppt, ist die Fortschrittserkennung. Der Mechanismus ist einfach: Hash den Tool-Namen plus seine Argumente bei jedem Schritt, führe ein kurzes Fenster mit jüngsten Hashes und breche ab, wenn eine Wiederholung erkannt wird.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Das erfasst den Agenten, der technisch "läuft" (Tools aufruft, Tokens generiert), aber bei derselben fehlgeschlagenen Aktion kreist. Der hier benannte Fehlermodus entspricht dem, was die MAST-Taxonomie (IBM Research und UC Berkeley) Unaware of Termination Conditions (FM-1.5) nennt, einen der Fehlermodi, den ihre Analyse mit vollständigem Aufgabenversagen in Verbindung bringt.
Eine Schritt-Obergrenze stoppt unkontrollierte Kosten. Die Fortschrittserkennung stoppt die Schleife, die technisch "voranschreitet", aber sich wiederholt. Die Produktion braucht beides.
Context Window Overflow: Wenn die Schleife ihr eigenes Kontextfenster mit unnötigen Daten füllt
Eine lang laufende Schleife sammelt jeden Tool-Output, jeden Zwischengedanken und jede erzeugte Nachricht an und steckt all das bei jedem Durchlauf zurück ins Kontextfenster. Irgendwann ist das Fenster voll, und Aufrufe werden entweder stillschweigend abgeschnitten oder schlagen ganz fehl. Die Lösung ist Kontextzusammenfassung in festen Intervallen: Alle N Schritte wird der angesammelte Verlauf zu einer laufenden Zusammenfassung komprimiert, damit der Arbeitskontext begrenzt bleibt.
Stellen Sie sich einen Rechercheagenten vor, der seit einer Stunde läuft. Bei Schritt 60 trägt er den vollständigen Text jeder abgerufenen Seite, jedes Suchergebnisses und jeder Reasoning-Spur mit sich. Nichts davon hilft ihm bei Schritt 61, und trotzdem verbraucht alles Platz im Fenster - das Modell zahlt Attention-Budget für Tokens, die es nicht mehr benötigt. Wenn das Fenster voll ist, kürzt der Anbieter von einem Ende ab, und der Agent verliert stillschweigend die Anweisung, die er zu Beginn erhalten hatte.
Der Auslöser ist eine Abstimmungsentscheidung, und es gibt einen nützlichen Referenzpunkt dafür. Mem0's Beschreibung eines echten Produktionssystems stellt fest, dass der Compressor des Hermes-Agenten "standardmäßig bei 50 % des Kontextfensters des Modells auslöst", mit einem sekundären Sicherheitsnetz bei 85 % für Sitzungen, die zwischen den Durchläufen stark anwachsen. Fünfzig Prozent ist ein sinnvoller Ausgangspunkt: früh genug komprimieren, damit ein einziger großer Tool-Output nicht über das Limit hinausschießt, bevor die nächste geplante Komprimierung stattfindet.
Hinweis: Overflow und Reasoning-Degradation sind unterschiedliche Probleme, und der nächste Abschnitt befasst sich mit dem zweiten. Overflow ist eine harte Grenze: Ihnen gehen die tokens aus. Degradation ist weich: Das Modell wird schlechter. bevor die Grenze erreicht ist. Beide müssen behandelt werden, und der obige Auslöseschwellenwert schützt vor der harten Grenze.
Begrenzter Kontext ist eine Harness-Verantwortung, kein Modell-Feature. Fassen Sie in Intervallen zusammen, bevor das Fenster eine stille Kürzung erzwingt.
Silent Tool Call Failures: Wenn der Agent "erfolgreich" nichts tut
Ein Tool-Aufruf gibt einen leeren String oder eine sanfte "no results found"-Meldung zurück, das Modell interpretiert das als gültiges Ergebnis, und der Agent fährt fort, als ob der Schritt funktioniert hätte, scheinbar erfolgreich, während er tatsächlich nichts tut. Die Lösung ist ein Validierungs-Gate bei jedem Tool-Rückgabewert: Schema-Prüfung oder Plausibilitätsprüfung des Outputs, bevor das Modell ihn sieht, und ein echter Fehler, den die Schleife verarbeiten muss, anstelle eines leeren Erfolgs.
Das ist tückisch, weil nichts abstürzt. Ein Entwickler, der stille Fehlermodi in Produktionsagenten beschreibt, bringt es auf den Punkt: Modelle interpretieren generische leere Strings als gültige No-Ops und fahren ohne Fehlerkenntnis fort. Die Datenbankabfrage, die null Zeilen zurückgab, weil die Verbindung unterbrochen wurde, sieht für das Modell identisch aus wie die Abfrage, die legitim nichts gefunden hat. Also meldet der Agent "keine passenden Einträge" und macht weiter, und man merkt eine Woche später, dass ein Drittel seiner Durchläufe still gebrochen war.
Das Validierungs-Gate sitzt zwischen dem Tool und dem Modell:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelEs geht nicht um die genauen Prüfungen; diese hängen davon ab, was jedes Tool legitim zurückgibt. Der Punkt ist, dass ein unvalidierter Rückgabewert eine Entscheidung ist, die Sie einem stochastischen Modell überlassen, und das Modell macht standardmäßig weiter.
Ein unvalidierter Tool-Rückgabewert ist ein stiller Fehler, der darauf wartet zu passieren. Validieren Sie den Output, vertrauen Sie nicht blind dem Aufruf.
Reasoning Degradation bei langen Kontexten: Wenn der Agent mit zunehmender Laufzeit schlechter wird
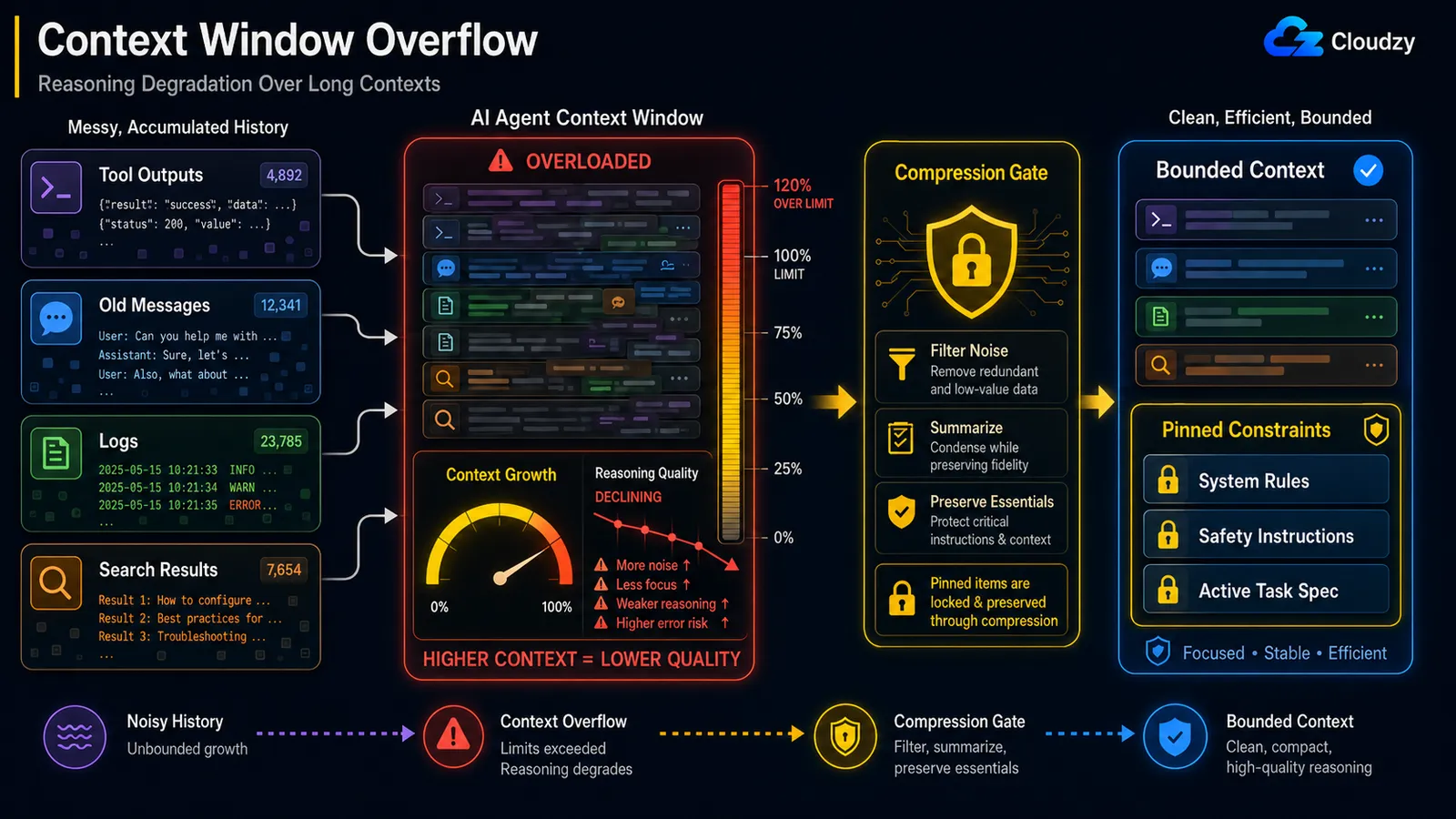
Selbst wenn man unter dem harten Kontextlimit bleibt, nimmt die Reasoning-Qualität ab, wenn der Kontext wächst. Das ist der "Lost in the Middle"-Effekt, bei dem das Modell zuverlässig Anfang und Ende eines langen Kontexts beachtet, aber die Mitte verliert. Die Lösung ist Mid-Loop-Komprimierung mit Schutz fixierter Constraints: Das Rauschen komprimieren, die tragenden Anweisungen schützen.
Der Mechanismus hat einen Namen. Anthropics Engineering-Blog bezeichnet ihn als Context Rot: "mit zunehmender Anzahl von Tokens im Kontextfenster nimmt die Fähigkeit des Modells ab, Informationen aus diesem Kontext korrekt abzurufen." Weil "jeder Token jeden anderen Token beachtet," erhält man n² paarweise Beziehungen für n Tokens, und die Aufmerksamkeit des Modells streckt sich dünner, je länger der Kontext wird.
Dieser Zusatz, die tragenden Anweisungen schützen, ist entscheidend - und ein dokumentierter Vorfall zeigt warum. In einem berichteten Fallhat ein OpenClaw-Agent den Posteingang eines Nutzers massenweise gelöscht, weil die Sicherheitsanweisung ("keine Aktion ausführen, bis ich es sage") beim Komprimieren des Verlaufs aus dem aktiven Kontext entfernt wurde. Die Constraint, die zuletzt hätte wegfallen sollen, wurde wie normaler Verlauf behandelt und wegzusammengefasst.
Ein naives "Alles zusammenfassen, was älter als N Durchläufe ist" ist also gefährlich. Die Komprimierung muss wissen, was sie niemals verwerfen darf:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactDas unterscheidet sich vom Overflow-Problem im vorherigen Abschnitt. Overflow bedeutet, dass der Platz ausgeht; Degradation bedeutet, dass das Modell schlechter wird, während noch Platz vorhanden ist. Man kann bei 60 % des Fensters sein und bereits schlecht reasoning betreiben.
Hinweis: Komprimierung, die eine Sicherheits-Constraint verwirft, ist ein anderer Fehlertyp als Komprimierung, die ein veraltetes Suchergebnis verliert. Markieren Sie Constraints, die Task-Spezifikation und alle "Tu X nicht"-Anweisungen als fixiert, und schließen Sie diese vollständig vom Komprimierer aus.
Komprimierung, die eine Sicherheitsanweisung verwirft, ist schlimmer als keine Komprimierung. Schützen Sie fixierte Constraints beim Komprimieren.
State Loss on Restart: Wenn ein Absturz bedeutet, von vorne zu beginnen
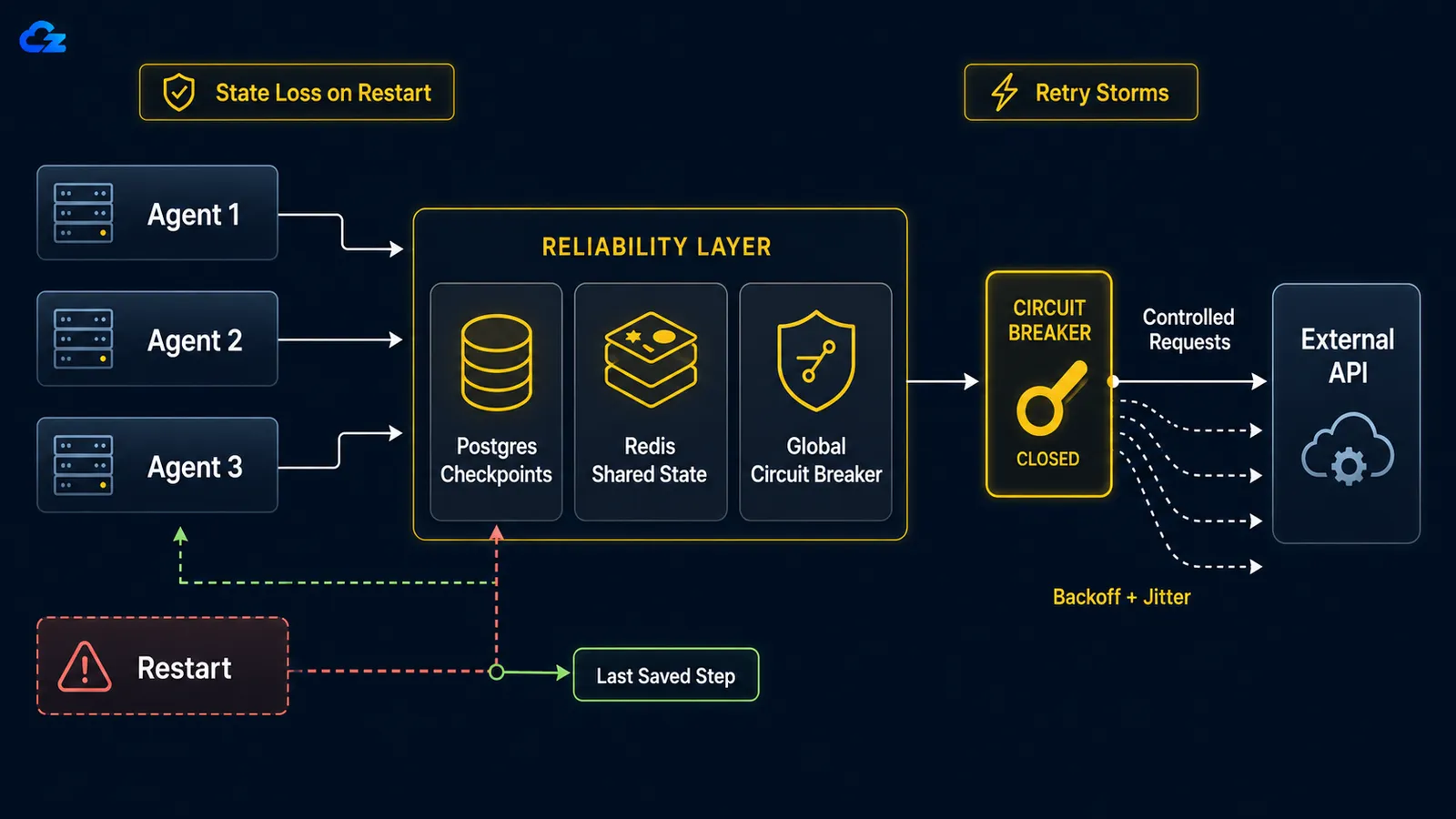
Wenn ein lang laufender Agent abstürzt, sei es durch einen Neustart, einen OOM-Kill oder eine unterbrochene Netzwerkverbindung, gibt es standardmäßig kein Resume-from-Checkpoint. Die Schleife beginnt von vorne: Sie wiederholt bereits abgeschlossene Arbeit und kann, schlimmer noch, bereits ausgeführte Aktionen erneut ausführen, wie dieselbe E-Mail zweimal senden oder einen bezahlten API-Aufruf wiederholen. Die Lösung ist Checkpointing: Den Zustand der Schleife nach jedem Schritt persistieren, damit ein Neustart vom letzten gespeicherten Punkt statt von null weitermacht.
In LangGraph ist die Wahl des Checkpoint-Backends die Wahl zwischen Entwicklung und Produktion. LangGraph's Persistence-Docs beschreiben SqliteSaver als "ideal für Experimente und lokale Workflows" und PostgresSaver als "ideal für den Produktionseinsatz", und LangSmith selbst läuft auf letzterem. Beide sind im Code bewusst parallel aufgebaut, was den Unterschied leicht erkennbar macht:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverZwei Details, über die man stolpern kann. Erstens installieren sich die Checkpoint-Pakete getrennt vom LangGraph-Kern (langgraph-checkpoint-sqlite und langgraph-checkpoint-postgres sind eigene Abhängigkeiten), sodass eine frische Umgebung den Postgres Saver nicht enthält, bis man ihn hinzufügt. Zweitens benötigt jeder Checkpoint-Vorgang eine thread_id in der Konfiguration. Diese ID verknüpft einen bestimmten Lauf mit seinem gespeicherten Zustand, und ein Neustart ohne die richtige thread_id lädt nichts nach.
Profi-Tipp: Die LangGraph Checkpoint-Pakete sind separate Installationen.
langgraph-checkpoint-postgreswird nicht durch das Basis-langgraphPaket eingezogen, also bitte in der Produktions-Requirements-Datei eintragen, bevor man es bei einem Incident auf die harte Tour lernt.
n8n hat dieselbe Entwicklungs-Produktions-Aufspaltung, nur unter anderen Namen. Die integrierte Memory-Option heißt ebenfalls Simple Memory (oder Buffer Window Memory), und der Produktionspfad ist der Postgres Chat Memory-Node für Zustand, der einen Neustart überleben muss. Der integrierte Speicher hält die Konversation im laufenden Prozess, was für Tests in Ordnung ist, aber für eine 24/7-Arbeitslast ein Risiko darstellt. Praktiker, die n8n-Agenten produktiv betreiben, berichten, dass sie zu einem Postgres-gestützten Store migrieren mussten, nachdem der In-Process-Speicher so stark anwuchs, dass er die Instanz zum Absturz brachte. Wer n8n verwendet und möchte, dass der Agent über einen Neustart hinaus etwas merkt, sollte von Anfang an Postgres Chat Memory einbinden.
SQLite-Checkpointing ist eine Entwicklungs-Bequemlichkeit. Einen Produktions-Neustart zu überstehen bedeutet Postgres (LangGraph) oder einen Postgres-gestützten Store (n8n).
Retry Storms: Wenn die eigenen Agenten einen ausgefallenen Dienst DDoSen
Wenn ein nachgelagerter Dienst ausfällt, verwandeln naive, pro-Ausführung gesteuerte Wiederholungsversuche die Agenten-Flotte in einen selbst verursachten Denial-of-Service. Die Lösung hat zwei Hälften: exponentielles Backoff mit Jitter bei jedem Agenten, um die Wiederholungen zeitlich zu verteilen, und ein globaler Circuit Breaker, der auslöst, sobald ein gemeinsamer Fehlerschwellenwert überschritten wird, und die gesamte Herde davon abhält, einen Dienst zu hammern, der offensichtlich ausgefallen ist.
Die Mathematik ist gnadenlos. Wie ein Retry-Patterns-Artikel es formuliert: Mit zehn parallelen Agenten, die jeweils zehn Mal wiederholen, werden hundert Anfragen an einen Dienst gesendet, der bereits am Boden liegt, weil das Backoff jedes Agenten pro Ausführung gilt, nicht global. Pro-Agent-Backoff allein löst das nicht. Zehn Agenten, die höflich zurückweichen, weichen trotzdem synchron zurück, wenn sie alle zur gleichen Zeit gestartet sind - sie wiederholen in synchronisierten Wellen. Jitter bricht die Synchronisierung auf, indem er die Wartezeit jedes Agenten zufällig variiert; der Circuit Breaker bricht die Herde auf, indem er einen Fehlerzustand über alle Agenten hinweg teilt.
Das Backoff-Problem ist in Python gelöst; die tenacity Bibliothek handhabt exponentielles Backoff mit Jitter sauber:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)Der Circuit Breaker ist die Hälfte, die globalsein muss: über jeden Agenten hinweg geteilt, nicht pro Ausführung neu instanziiert. Wenn Fehler einen Schwellenwert überschreiten, öffnet er, jeder Agent schlägt sofort fehl, anstatt einen Aufruf zu machen, und nach einer Abklingzeit lässt er eine einzelne Sonde durch, um zu prüfen, ob der Dienst wieder verfügbar ist. Ein Breaker, der im Prozess jedes Agenten lebt, schützt nichts, weil nichts geteilt wird; der ausgefallene Dienst erhält trotzdem die vollen hundert Anfragen.
Pro-Ausführungs-Backoff lässt zehn Agenten trotzdem synchron einen ausgefallenen Dienst hammern. Der Circuit Breaker muss global sein, um die Herde zu stoppen.
Die sechs Fehler auf einen Blick
Vor dem Infrastrukturabschnitt folgt der gesamte Katalog auf einen Blick: der Fehler, der Mechanismus dahinter, der Harness-Fix und wo der relevante Parameter in jedem Framework zu finden ist.
| Fehlerfall | Mechanismus | Harness-Fix | Framework-Parameter |
|---|---|---|---|
| Infinite Loop | Keine Schritt-Obergrenze oder Fortschrittsprüfung | Harte Obergrenze + Fortschrittserkennung | LangGraph recursion_limit (25) / n8n Max Iterations |
| Context Overflow | Verlauf wächst, bis das Fenster voll ist | Intervallbasierte Zusammenfassung | App-Ebene (komprimieren bei ca. 50 % des Fensters) |
| Silent Tool Failure | Leere/weiche Rückgaben werden als gültige No-Ops gelesen | Validierungs-Gate bei jedem Tool-Ergebnis | App-Level Tool Wrapper |
| Reasoning Degradation | Aufmerksamkeit nimmt ab, wenn Kontext wächst ("Context Rot") | Mid-Loop-Komprimierung mit Schutz fixierter Constraints | App-Ebene, constraint-bewusst |
| State Loss on Restart | Kein Checkpoint; Schleife startet von null | Persistentes Checkpointing | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Retry Storm | Pro-Ausführungs-Retries eskalieren bei einem ausgefallenen Dienst | Backoff + Jitter + globaler Circuit Breaker | tenacity + geteilter Breaker-Zustand |
Ein Hinweis für alle, die CrewAI, AutoGen, Dify oder eine handgeschriebene Python-Schleife verwenden: Die Framework-Parameter ändern sich, aber die sechs Muster nicht. Deduplizierung, Intervallzusammenfassung, Schema-Validierung, constraint-bewusste Komprimierung, Checkpointing und ein globaler Circuit Breaker sind framework-agnostische Konzepte. Die LangGraph- und n8n-Details hier sind konkrete Anhaltspunkte, nicht die Grenze, wo die Muster gelten.
Sizing eines Produktions-Agenten-Deployments
Jedes der obigen Muster setzt voraus, dass Sie den Prozessmanager, die Datenbank und das Neustart-Verhalten kontrollieren. Checkpointing nützt nichts, wenn eine abgestürzte Schleife nie wieder hochkommt, und ein globaler Circuit Breaker braucht einen Ort, an dem sein gemeinsamer Zustand gehalten wird. Genau diese Kontrolle gibt Ihnen Self-Hosting, und eine verwaltete Black Box nicht, daher ist die letzte Entscheidung die Dimensionierung des Servers, der es 24/7 betreibt.
Für die meisten Single-Agent-Deployments (ein Agent, LLM-Aufrufe an eine externe API, grundlegendes Postgres-Checkpointing) reicht eine kleine Instanz: 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. Die schwere Rechenarbeit liegt auf der Seite des Modell-Anbieters; Ihr Server orchestriert, macht Checkpointing und hält den Zustand, führt keine Inferenz aus. Wechseln Sie zu etwa 4 GB RAM, 2 vCPU, and 120 GB NVMe wenn der Agent zustandsbehaftet und mehrstufig mit Postgres-Checkpointing plus Redis für Session-Hydration ist, oder wenn parallele Workflows den Host gemeinsam nutzen.
Der Grund, warum dafür ein selbstverwalteter VPS besser geeignet ist als eine eingeschränkte Plattform, ist derselbe, warum die Fixes überhaupt funktionieren: sie brauchen Root-Zugriff. Eigenes Postgres für Checkpointing, eigenes Redis für Session-Zustand und ein echter Prozessmanager wie systemd or pm2, damit wenn eine Schleife abstürzt, der Supervisor sie neustartet und sie aus ihrem letzten Checkpoint wiederherstellt, anstatt den Job von vorne zu beginnen. Diese gesamte Recovery-Geschichte setzt voraus, dass Sie den Prozess-Lebenszyklus besitzen.
Da wir n8n als One-Click-App in unserem eigenen Marketplace betreiben, ist dieser Teil des Setups auf unserer Seite der kürzeste Weg: Sie können n8n auf einem Cloudzy VPS deployen mit der Postgres-gestützten Konfiguration, die der Produktionspfad benötigt, auf einer Instanz, bei der Sie Root-Zugriff haben, um eigenes Redis und Prozess-Supervision hinzuzufügen. Das ist derselbe Self-Hosted-Footprint wie oben beschrieben, bei dem Sie die Datenbank und das Neustart-Verhalten besitzen, was Checkpointing und Auto-Recovery überhaupt erst ermöglicht.
Die Harness-Muster sind nur so zuverlässig wie der Server, auf dem sie laufen. Checkpointing nützt nichts, wenn der Prozess nie neustartet.
Häufig gestellte Fragen
Wie verhindere ich, dass mein LangGraph-Agent ewig in einer Schleife läuft?
Verwenden Sie zwei Mechanismen zusammen. Setzen Sie recursion_limit als harte Schritt-Obergrenze (der Standardwert ist 25), damit eine unkontrollierte Schleife kein unlimitiertes Budget verbrennen kann, und fügen Sie eine Fortschrittserkennung hinzu, die jeden Tool-Aufruf mit seinen Argumenten hasht und abbricht, wenn derselbe Aufruf innerhalb eines kurzen Fensters wiederholt wird. Die Obergrenze allein ist ein Backstop, der erst auslöst, wenn die Verschwendung bereits passiert ist, kein echter Schleifenschutz. Die Fortschrittserkennung ist es, was eine feststeckende Schleife tatsächlich stoppt.
Was ist das richtige recursion_limit für LangGraph in der Produktion?
Es gibt keine universelle Zahl. Dimensionieren Sie es auf die maximale Anzahl legitimer Schritte, die Ihr Agent jemals benötigen sollte, plus einen Puffer, und behandeln Sie es streng als Kosten-Backstop. Das Limit anzuheben lässt einen schleifenden Agenten nicht konvergieren. Wenn Ihr Agent ein hohes Limit erreicht, ist die Lösung eine Fortschrittserkennung, nicht eine höhere Obergrenze.
Warum erreicht mein n8n KI-Agent immer wieder Max Iterations?
Das Erreichen der Max Iterations-Grenze bedeutet, dass der Agent nicht konvergiert: Er macht mehr Schritte als das Limit erlaubt, ohne einen Stopp zu erreichen. Erhöhen Sie das Limit nur, wenn die Aufgabe legitim mehr Schritte benötigt; andernfalls ist es ein Signal, dass der Agent feststeckt. Achten Sie auf eine spezifische Falle: GitHub Issue #22771 berichtet, dass wenn das Iterationslimit mit "On Error: Continue" gesetzt erreicht wird, die Ausführung zum Success-Output statt zum Error-Output geroutet werden kann - ein gedeckelter, fehlgeschlagener Lauf kann also im Workflow wie ein Erfolg aussehen.
Wie persistiere ich den Agenten-Zustand über Neustarts hinweg?
In LangGraph verwenden Sie PostgresSaver Checkpointing statt SqliteSaver, das für die lokale Entwicklung gedacht ist. In n8n verwenden Sie den Postgres Chat Memory-Node statt des In-Process-integrierten Speichers. Beides erfordert eine persistente Datenbank, und in LangGraph benötigt jeder Checkpoint-Vorgang eine thread_id die einen bestimmten Lauf mit seinem gespeicherten Zustand verknüpft.
Was verursacht Reasoning Degradation bei langen Agenten-Läufen?
Die Reasoning-Qualität sinkt, wenn der Kontext wächst, selbst bevor das harte Token-Limit erreicht ist. Das ist der "Lost in the Middle"-Effekt, bei dem das Modell Anfang und Ende eines langen Kontexts beachtet, aber die Mitte verliert. Anthropics Engineering-Blog bezeichnet den zugrundeliegenden Mechanismus als "Context Rot": Weil jeder Token jeden anderen Token beachtet, entstehen n² paarweise Beziehungen, und die Aufmerksamkeit des Modells streckt sich dünner, je länger der Kontext wird. Die Lösung ist Mid-Loop-Komprimierung, die veralteten Verlauf zusammenfasst, während fixierte Constraints und Sicherheitsanweisungen intakt bleiben.


