
Als NVIDIA zeigte, wie DLSS 4 fünfzehn von je sechzehn Pixeln mit KI erzeugt, sah ein großer Teil des Publikums keinen Fortschritt. Sie sahen "Fake-Frames" und "KI-Müll": erzeugte Details, die richtig aussehen, bis sie es nicht mehr tun, und die man nicht so debuggen kann, wie man ein falsch platziertes Polygon debuggen würde. Ein PCGuide-Bericht über eine Community-Umfrage ergab, dass 54% der Antworten ein schlichtes "Nein" zum DLSS 5-Look waren, wobei sich viel der Kritik auf Gesichtszüge und die "KI-Müll"-Reaktion richtete. Diese Reaktion sollte man ernst nehmen, und wir kommen darauf zurück.
Aber das größere Problem in jedem dieser Argumente ist, dass "neuronales Rendering" für mindestens fünf verschiedene Dinge verwendet wird: Hochskalierung, KI-erzeugte Frames, Szenenrekonstruktion aus Fotos, die NeRF- und Gaussian-Splatting-Demos, die man in sozialen Medien gesehen hat, und die Forschungssysteme, die ein ganzes Bild mit einem einzigen Netzwerk rendern. Die Leute reden aneinander vorbei, weil jeder auf eine andere Ebene zeigt und dasselbe Wort benutzt. NVIDIAs Jensen Huang hat diesen Wandel einen "GPT-Moment für Grafik" genannt. Das ist die Behauptung. Die nützliche Frage ist, was darunter passiert.
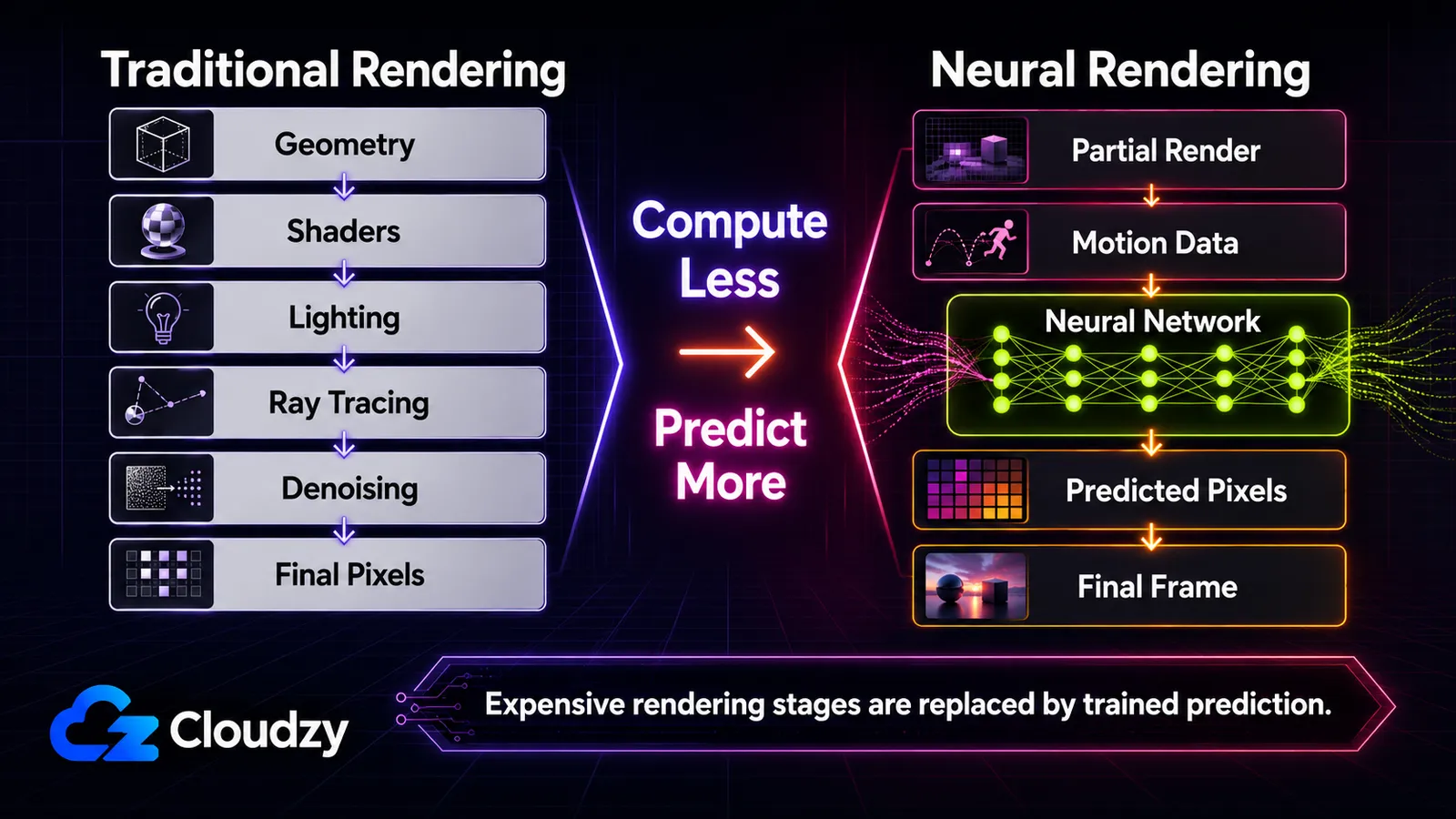
Hier ist der rote Faden, der das Ganze lesbar macht: die GPU sagt das Bild zunehmend vorher, statt es zu berechnen. Traditionell berechnet die GPU jedes Pixel, indem sie Geometrie, Beleuchtung und Materialien simuliert (Rasterisierung und in jüngerer Zeit Raytracing darüber). Neuronales Rendering ändert, was berechnet wird, gegenüber dem, was vorhergesagt wird, durch ein trainiertes Netzwerk. Diese eine Unterscheidung ist das Rückgrat dieses Artikels. Am Ende kannst du jede Technik auf einem Spektrum verorten, weißt, welche in Echtzeit und auf welcher Hardware laufen, und kannst unterscheiden, was heute in einem Spiel ausgeliefert wird, von dem, was ein Forschungspapier oder eine GTC-Demo ist. Das ist eine Karte, keine Anleitung. Die tiefe Mechanik jeder einzelnen Technik ist ein eigener Artikel.
Die Kurzfassung
- Neuronales Rendering ist ein Spektrum, kein Synonym für DLSS. Es umfasst die Forschung zur Szenenrekonstruktion (NeRF, Gaussian Splatting), Echtzeitkomponenten, die innerhalb der Rendering-Pipeline sitzen (DLSS, Ray Reconstruction, neuronaler Radiance-Cache), und generative Methoden, die Details erfinden, die der Frame nie hatte.
- Der rote Faden ist "vorhersagen statt berechnen." Jede Technik ersetzt eine teure berechnete Stufe der Pipeline durch ein Netzwerk, das das Ergebnis vorhersagt, auf das es trainiert wurde.
- Das meiste, was heute ausgeliefert wird, ist hybrid. Hochskalierung, Frame-Erzeugung und KI-Entrauschung laufen jetzt in Echtzeitspielen, während neuronale Texturkompression und neuronale Shader über Entwickler-Toolkits aufkommen. Vollständige neuronale Renderer, die das ganze Bild mit einem Netzwerk zeichnen, befinden sich noch im Forschungsstadium.
- Es wird herstellerübergreifend, nicht nur eine NVIDIA-Geschichte. Microsofts DirectX-Arbeit an ML auf Shader-Ebene begann mit Cooperative Vectors in Shader Model 6.9 und bewegt sich hin zu breiterer Unterstützung für lineare Algebra in Shader Model 6.10, was Engines einen Weg gibt, neuronale Shader-Workloads über den Stack eines einzelnen Herstellers hinaus anzusteuern.
Warum "neuronales Rendering" fünf verschiedene Dinge bedeutet
Neuronales Rendering ist eine Klasse von Methoden, die neuronale Netze nutzen, um Teile eines Bildes (Pixel, Beleuchtung, Materialien, sogar ganze Frames) vorherzusagen, die die GPU sonst von Grund auf berechnen würde. Der Übersichtsartikel von Tewari et al. definiert es als die Kombination klassischer Computergrafik mit tiefen generativen Modellen für fotorealistische Ausgabe. Der Begriff umfasst ein weites Spektrum, und "DLSS" ist ein Punkt darauf.
Der Grund, warum die Diskussion ein Durcheinander ist, liegt darin, dass das Spektrum mindestens drei verschiedene Ebenen hat und die Öffentlichkeit ein Wort für alle benutzt.
Die erste Ebene ist das akademische / rekonstruktive neuronale Rendering: NeRF, 3D Gaussian Splatting und differenzierbares Rendering. Diese nehmen Fotografien oder Messungen einer realen Szene und lernen eine Repräsentation, aus der man aus neuen Kamerawinkeln rendern kann. Das ursprüngliche NeRF-Papier (Mildenhall et al., 2020) trainiert ein kleines Netzwerk, um eine 3D-Koordinate und Blickrichtung auf Farbe und Dichte abzubilden, und rendert dann neue Ansichten, indem es es abfragt. Diese Ebene ist größtenteils offline. Sie rekonstruiert Szenen; sie treibt nicht die Frame-Schleife deines Spiels an.
Die zweite Ebene ist das neuronale Rendering in der Echtzeit-Pipeline: Netzwerke, die innerhalb oder neben einem normalen rasterisierten Frame laufen. DLSS-Hochskalierung, Ray Reconstruction und der neuronale Radiance-Cache leben hier. Die Pipeline rasterisiert und raytraced weiterhin; ein Netzwerk übernimmt eine teure Stufe davon. Das ist die Ebene, die heute in Spielen ausgeliefert wird.
Die dritte Ebene ist das generative neuronale Rendering: Das Netzwerk erzeugt Bildinhalt, den der Frame nie berechnet hat. Die erzeugten Frames von DLSS 4 sitzen am Rand davon, und DLSS 5 (das NVIDIA für Herbst 2026 angekündigt hat) treibt es weiter voran, indem es Beleuchtungs- und Materialdetails erzeugt, statt nur zwischen gerenderten Frames zu interpolieren.
Diese drei Ebenen verhalten sich unterschiedlich, laufen mit unterschiedlichen Geschwindigkeiten und brauchen unterschiedliche Hardware. Sie als eine Sache zu behandeln, ist der Grund, warum zwei Personen zugleich sagen können "neuronales Rendering ist überbewertet" und "neuronales Rendering ist die Zukunft" und beide teils recht haben.
Fazit des Abschnitts: Der Begriff ist älter als DLSS und kein Synonym dafür. DLSS ist eine Anwendung (Echtzeit, in der Pipeline) innerhalb eines viel breiteren Spektrums, das von der Offline-Szenenrekonstruktion bis zu vollständig erzeugten Frames reicht.
Wie neuronales Rendering Teile der Brute-Force-Pipeline ersetzt
Mit der vollständigen Multi-Frame-Erzeugung von DLSS 4 werden ungefähr fünfzehn von je sechzehn Pixeln auf dem Bildschirm KI-erzeugt statt traditionell gerendert (laut NVIDIAs DLSS-4-Zahlen). Diese Zahl ist der ganze Wandel, komprimiert in eine einzige Statistik: Der Renderer berechnet einen Bruchteil des Bildes und sagt den Rest vorher.
Traditionelles Rendering verdient sich jedes Pixel. Die GPU rasterisiert Geometrie, führt Shader aus, um Beleuchtung und Materialien zu berechnen, und (mit Raytracing) simuliert sie Licht, das durch die Szene springt. Raytracing ist besonders brutal teuer, weil realistisches Licht viele Sprünge und viele Samples pro Pixel braucht, und das Rauschen aus der Unterabtastung muss danach bereinigt werden. Als die Szenen ehrgeiziger wurden, wurden die teuersten Stufen zu den offensichtlichen Zielen: statt sie zu berechnen, ein Netzwerk trainieren, das ihre Ausgabe vorhersagt.
Der Fortschritt war stetig statt plötzlich:
- 2018, DLSS 1.0. Der erste kommerzielle Schritt: in niedriger Auflösung rendern, das hochauflösende Bild vorhersagen. Die Hochskalierung von "mehr Pixel berechnen" zu "mehr Pixel vorhersagen" verschieben.
- 2020, NeRF. Szenenrekonstruktion aus Bildern über ein gelerntes Radiance-Feld. Neue Ansichten vorhersagen, statt Geometrie zu modellieren und zu rendern.
- 2021, neuronaler Radiance-Cache. Gesprungenes Licht während des Path-Tracings vorhersagen, damit der Renderer früher mit dem Tracing aufhören kann.
- 2022, DLSS 3 Frame Generation. Ganze Zwischen-Frames erzeugen, statt sie zu rendern.
- 2023, 3D Gaussian Splatting. Eine schnellere, eher echtzeitorientierte Alternative zu NeRF für rekonstruierte Szenen.
- 2025, DLSS 4 + RTX Kit. Multi-Frame-Erzeugung plus ein Toolkit neuronaler Komponenten (Texturkompression, Radiance-Cache, neuronale Shader).
- 2025, DirectX Cooperative Vectors (Vorschau). Eine herstellerübergreifende API für die Matrixmathematik, die neuronale Shader brauchen (in der Vorschau als Teil von Shader Model 6.9 eingeführt).
- 2026, DLSS 4.5. Schrittweise Verbesserungen bei Qualität und Ray Reconstruction (von NVIDIA auf der Computex beschrieben).
- Herbst 2026, DLSS 5 (angekündigt). Der nächste Vorstoß hin zum generativen neuronalen Rendering.
Von oben nach unten gelesen, ist jede Zeile derselbe Schritt, angewandt auf eine andere Stufe: etwas nehmen, das die Pipeline früher berechnet hat, und es stattdessen von einem Netzwerk vorhersagen lassen.
Die sechs Ebenen: Was KI an jeder Stufe der Pipeline ersetzt
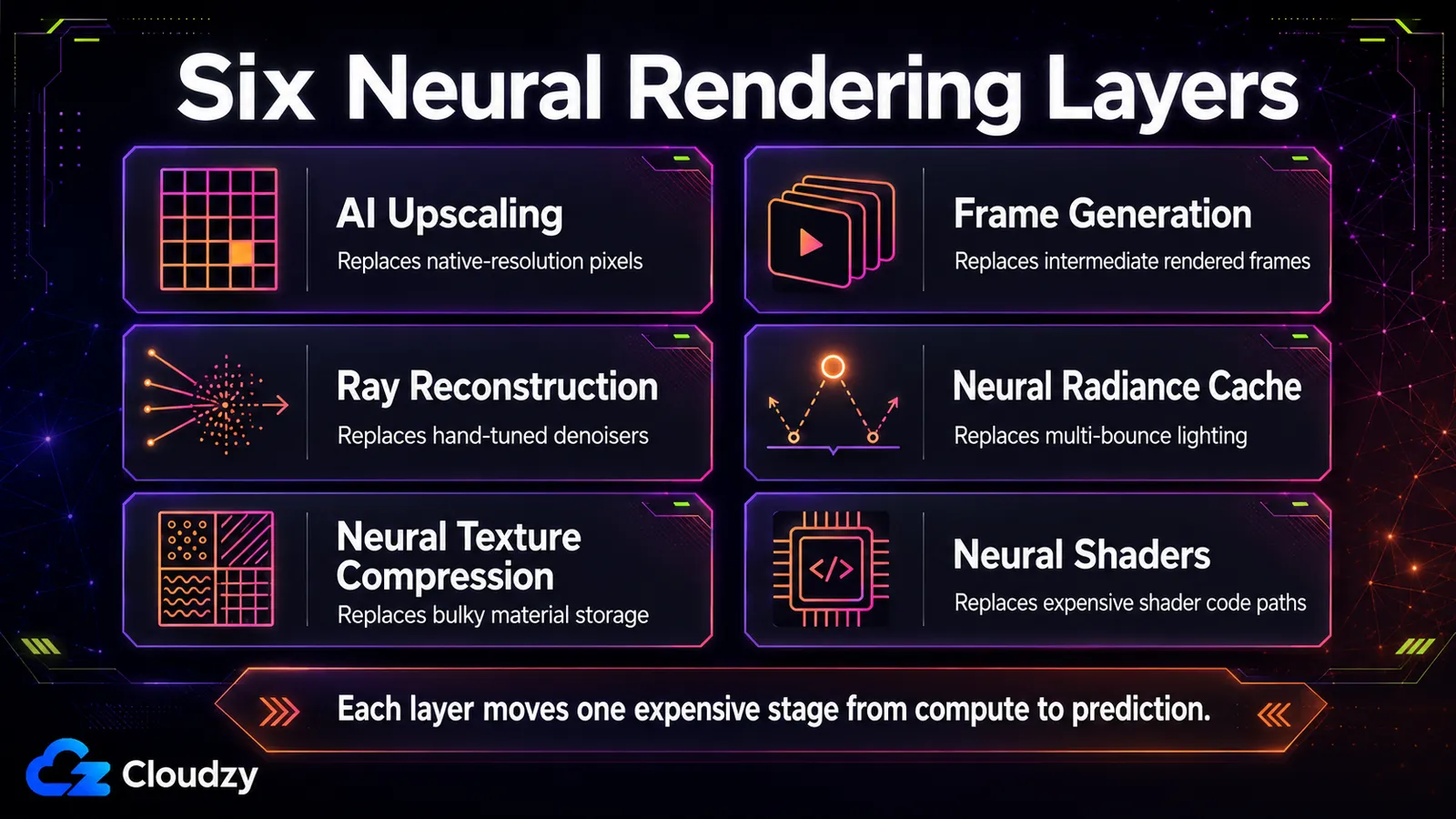
Sechs Techniken tragen den Großteil des heutigen Echtzeit-Neuronalrenderings, und jede ersetzt eine bestimmte berechnete Stufe: Hochskalierung (Auflösung), Frame-Erzeugung (Frame-Anzahl), Ray Reconstruction (Entrauschung), neuronaler Radiance-Cache (globale Beleuchtung), neuronale Texturkompression (Materialspeicherung) und neuronale Shader (Berechnung im Shader). Zu wissen, welche Stufe jede berührt, ist der größte Teil der Schlacht.
Diese unterscheiden sich danach, wo in der Pipeline das Netzwerk läuft. Manche arbeiten ganz am Ende als Nachbearbeitung eines fertigen Frames; manche laufen mitten in der Pipeline neben dem Raytracing; manche leben im Shader selbst. Dieser Ort ist kein Detail. Er bestimmt, wie schnell die Technik laufen kann und welche Hardware sie braucht. Die Tabelle bildet diese sechs Techniken ab; die Unterabschnitte darunter erklären den Mechanismus, der nicht sauber in jede Zelle passte.
| Technik | Was sie ersetzt | Echtzeit-Tauglichkeit | Erforderliche Hardware | Herstellerübergreifend? |
|---|---|---|---|---|
| KI-Hochskalierung (Super Resolution) | Pixel in nativer Auflösung berechnen | Echtzeit, geringer Overhead | Tensor- / Matrixkerne (RTX 20+, RDNA 4, Intel XMX) | Ja als Kategorie; Implementierungen bleiben herstellerspezifisch (DLSS, FSR / FSR Upscaling, XeSS) |
| Frame-Erzeugung | Zwischen-Frames rendern | Echtzeit; fügt Latenz hinzu | RTX 40+ (DLSS 3), RTX 50 für Multi-Frame | Teilweise; herstellerspezifisch |
| Ray Reconstruction | Der handabgestimmte Entrausch-Stack | Echtzeit | RTX 20+ | NVIDIA heute |
| Neuronaler Radiance-Cache | Indirektes Licht mit mehreren Sprüngen berechnen | Echtzeit (~2,6 ms berichtet) | Matrixkerne der RTX-Klasse | NVIDIA heute (RTX Kit) |
| Neuronale Texturkompression | Blockkomprimierte Materialspeicherung | Echtzeit-Dekodierung | Matrixkerne der RTX-Klasse | NVIDIA-SDK/-Tooling heute; breitere ML-Unterstützung auf Shader-Ebene wird separat standardisiert |
| Neuronale Shader | Berechnete Shader-Codepfade | Echtzeit | GPUs mit ML auf Shader-Ebene / matrixfähig | Aufkommend über den DirectX-SM-6.9- / SM-6.10-Pfad |
KI-Hochskalierung (Super Resolution)
KI-Hochskalierung rendert den Frame in niedrigerer Auflösung und sagt das hochauflösende Ergebnis vorher, sodass die GPU weit weniger Pixel zeichnet und ein Netzwerk die Struktur auffüllt. DLSS, AMDs FSR 4 und Intels XeSS tun dies alle über zeitliche Hochabtastung: Sie tasten über aufeinanderfolgende Frames hinweg unterschiedliche Pixel ab und kombinieren diese Historie mit Bewegungsvektoren, um Details zu rekonstruieren, die ein einzelner Frame in niedriger Auflösung nicht enthält.
Das ist die ausgereifteste und am weitesten verbreitete Ebene, und hier ist die herstellerübergreifende Realität am klarsten. DLSS 4 wechselte seinen Upscaler von einem Faltungsnetz zu einem Transformer für bessere Detailstabilität. FSR 4 ist AMDs erster ML-basierter Upscaler, der auf RDNA 4 mit FP8-Inferenz läuft statt mit den handgeschriebenen Heuristiken früherer FSR-Versionen. XeSS nutzt Intels XMX-Matrixeinheiten. Drei Hersteller, dieselbe zugrunde liegende Idee: die Pixel vorhersagen, die man nicht gerendert hat.
Frame-Erzeugung und Multi-Frame-Erzeugung
Die Frame-Erzeugung sagt ganze Frames zwischen denen vorher, die die GPU tatsächlich rendert, indem sie Spieldaten wie Bewegungsvektoren mit Schätzung des optischen Flusses und KI kombiniert. DLSS 3 nutzte den Optical Flow Accelerator der RTX-40-Serie, um einen erzeugten Frame zwischen gerenderte Frames einzufügen; die Multi Frame Generation von DLSS 4 auf Hardware der RTX-50-Serie kann bis zu drei zusätzliche Frames pro traditionell gerendertem Frame erzeugen, und NVIDIA sagt, DLSS 4 ersetze den Hardware-Schritt für optischen Fluss durch ein effizienteres KI-Modell.
Das ist die Ebene, um die es beim "Fake-Frames"-Argument wirklich geht, und die Rahmung ist hier wichtig. Ein erzeugter Frame ist eine plausible Interpolation davon, wohin sich die Szene entwickelte: Er zeigt dir nutzbaren visuellen Inhalt. Aber er ist vorhergesagt, nicht aus dem tatsächlichen Zustand des Spiels gerendert, und er trägt keine frische Spiellogik oder Eingabe. Entscheidend: Die Frame-Erzeugung läuft, nachdem ein Frame gerendert wurde, was Latenz hinzufügt, statt sie zu entfernen; NVIDIAs Reflex 2 existiert eigens dafür, diese Latenz zurückzuholen. Also ist "die Frame-Erzeugung macht das Spiel schneller" eine Teilwahrheit: Sie erhöht die wahrgenommene Geschmeidigkeit (mehr angezeigte Frames), ohne die Rate zu erhöhen, mit der das Spiel tatsächlich aktualisiert und reagiert. Diese Lücke zwischen dem, was du siehst, und dem, was das Spiel weiß, ist die ganze Debatte, und für den kompetitiven Spielbetrieb, wo die Eingabelatenz über Ergebnisse entscheidet, ist es ein abzuwägender Kompromiss.
Ray Reconstruction (KI-Entrauschung)
Ray Reconstruction ersetzt den Stapel handabgestimmter Entrausch-Filter, auf den sich das raygetracte Rendering stützt, durch ein einziges neuronales Netz, das darauf trainiert ist, ein sauberes Bild aus rauschiger, unterabgetasteter raygetracter Eingabe zu rekonstruieren. Path-Tracing kann sich in Echtzeit nur wenige Lichtsamples pro Pixel leisten, was die Rohausgabe rauschig lässt; etwas muss sie bereinigen, bevor du sie siehst.
Der traditionelle Ansatz war eine Kette spezialisierter Entrauscher, jeder von Hand für einen bestimmten Effekt abgestimmt. Das durch ein einziges trainiertes Netz zu ersetzen, neigt dazu, Details zu bewahren, die die handabgestimmten Filter verschmierten, besonders bei Reflexionen und feiner Beleuchtung, und es ist ein Netz zu pflegen statt einer brüchigen Pipeline davon. Das ist ein klares Beispiel für den roten Faden: Die Entrausch-Stufe wechselte von "mit handgeschriebenen Heuristiken berechnen" zu "mit einem trainierten Modell vorhersagen."
Neuronaler Radiance-Cache (globale Beleuchtung)
Der neuronale Radiance-Cache (NRC) sagt vorher, wie Licht durch eine Szene springt, damit der Path-Tracer die meisten Strahlen früher stoppen kann, statt jedem Sprung bis zum Ende zu folgen. Globale Beleuchtung (das weiche, indirekte Licht, das von Wänden und Böden abprallt) ist eines der teuersten Dinge in der Echtzeitgrafik, und der Mechanismus, der den NRC funktionieren lässt, wird selten in klarer Sprache erklärt, daher lohnt es sich, hier langsamer zu machen.
Hier ist der Mechanismus. Ein Path-Tracer folgt normalerweise jedem Lichtstrahl durch viele Sprünge, und dort explodieren die Kosten. Der NRC trainiert ein kleines Netzwerk während des Renderings (nicht vorab), um das Licht vorherzusagen, das nach weiteren Sprüngen an einem Punkt ankommt. Der Path-Tracer verfolgt also einen Strahl für ein, zwei Sprünge, fragt dann das Netzwerk "was ist der Rest des Lichts hier?" und beendet den Pfad früher; das Papier zum Echtzeit-Neuronal-Radiance-Caching (Müller et al., 2021) berichtet, auf diese Weise die große Mehrheit der Pfade zu beenden. Stell es dir als einen Cache vor, der keine exakten Antworten speichert, die er zuvor gesehen hat, sondern das Muster der Beleuchtung der Szene gut genug lernt, um Abfragen zu beantworten, die er nicht gesehen hat, und der weiter neu lernt, während sich die Szene ändert. NVIDIA berichtet, dass der NRC mit ungefähr 2,6 ms Overhead läuft, was ihn echtzeittauglich macht statt zu einer Forschungskuriosität.
Neuronale Texturkompression
Die neuronale Texturkompression (NTC) komprimiert alle Texturkanäle eines Materials gemeinsam mit einem Netzwerk und erreicht bis zu 8-fache VRAM-Einsparung gegenüber traditioneller Blockkompression bei ähnlicher visueller Qualität (laut NVIDIAs RTX-Kit-Dokumentation). Ein modernes Material ist nicht eine Textur. Es ist ein Stapel davon (Farbe, Normalen, Rauheit, Metallizität und mehr), und diese Kanäle sind auf Weisen korreliert, die die Blockkompression, die jeden Kanal unabhängig zusammendrückt, wegwirft.
Die NTC nutzt diese Korrelation aus. Indem sie die gemeinsame Struktur über alle Kanäle eines Materials auf einmal lernt, speichert sie dasselbe Material in weit weniger Speicher und dekodiert es zur Renderzeit im Vorbeigehen. VRAM ist eine anhaltende Beschränkung, während Spiele die Texturdetails hochtreiben, daher ist "8-mal mehr Material in denselben Speicher packen" ein direkter, praktischer Gewinn statt eines visuellen Tricks.
Neuronale Shader und DirectX Cooperative Vectors
Neuronale Shader führen kleine neuronale Netze innerhalb eines programmierbaren Shaders aus (die Programme pro Pixel/pro Vertex, die die GPU ohnehin ausführt), damit ein Netzwerk einen teuren berechneten Effekt genau dort annähern kann, wo dieser Effekt gebraucht wird. Statt KI als separaten Durchlauf anzuflanschen, läuft das MLP als Teil des Shaders auf den Matrixeinheiten der GPU (Tensor Cores auf NVIDIA-Hardware).
Tensor Cores übernehmen die Matrixmathematik, auf der diese Netze laufen, getrennt von den Allzweckkernen, die den Rest der Arbeit übernehmen. Das, was neuronale Shader von einer Einzelhersteller-Funktion in eine breitere Branchenfähigkeit verwandelt, ist die API-Schicht darunter. Microsoft führte DirectX Cooperative Vectors 2025 in der Vorschau mit Shader Model 6.9 ein, um Vektor-/Matrixoperationen innerhalb von HLSL-Shadern bereitzustellen. Bis 2026 war Shader Model 6.9 in die Verkaufsversion übergegangen, und Microsoft sagte, Cooperative Vector werde zugunsten eines breiteren Designs für lineare Algebra, das für Shader Model 6.10 geplant ist, verworfen. Die sichere Erkenntnis ist nicht, dass Cooperative Vectors die endgültige API sind, sondern dass DirectX sich hin zu herstellerübergreifender ML-Unterstützung auf Shader-Ebene bewegt.
Fazit des Abschnitts: Die sechs Techniken ordnen sich danach, wo das Netzwerk läuft: Nachbearbeitung am Ende des Frames, mitten in der Pipeline neben dem Raytracing oder im Shader selbst. Dieser Ort ist es, der bestimmt, ob eine Technik in Echtzeit laufen kann und welche Hardware sie braucht.
Was in Echtzeit läuft, und auf welcher Hardware
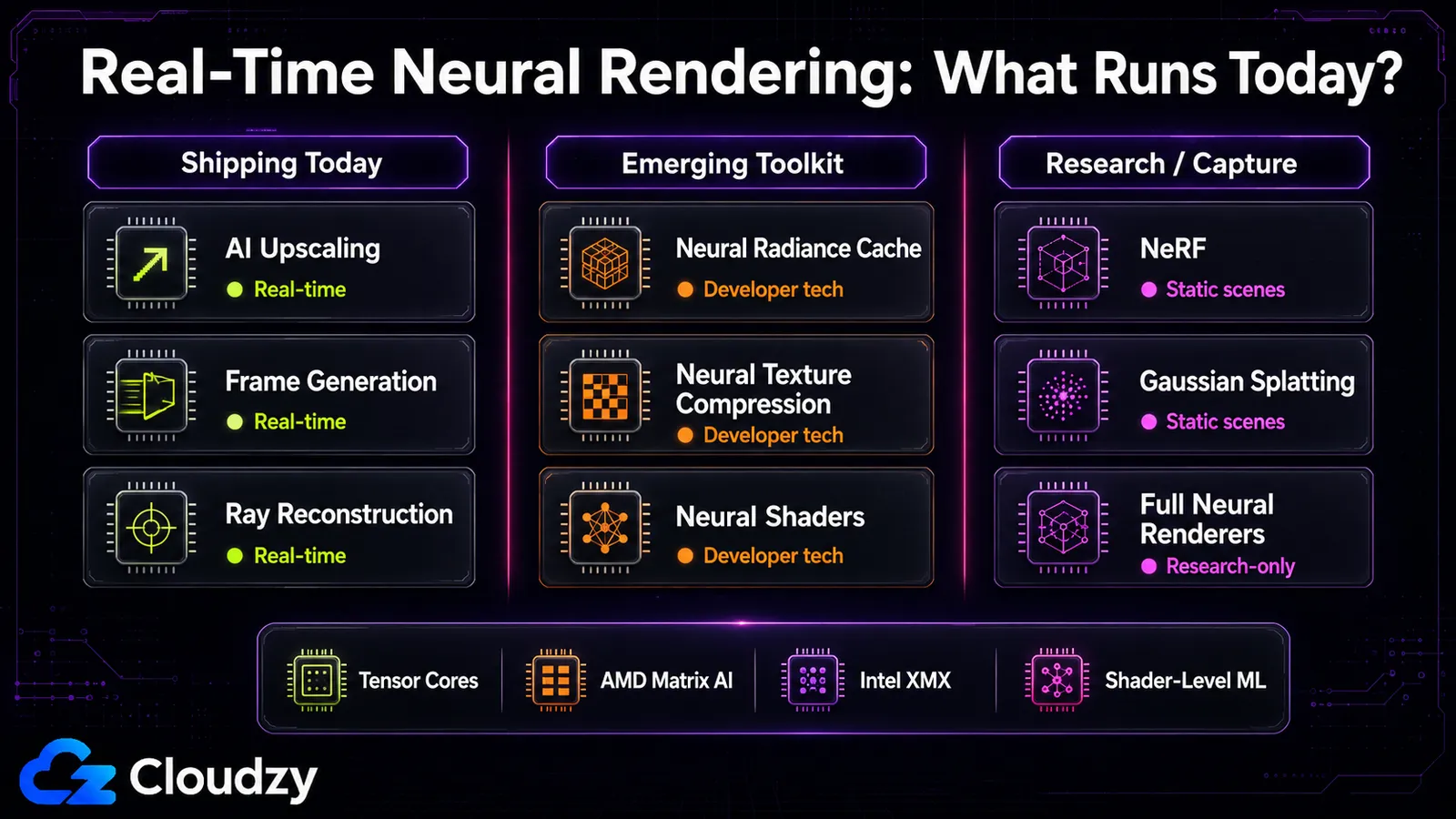
Die Echtzeit-Linie ist schärfer, als der Hype nahelegt: KI-Hochskalierung läuft meist mit geringem Overhead, der NRC fügt rund 2,6 ms hinzu, und 3D Gaussian Splatting nähert sich der Echtzeit für statische Szenen. Das ursprüngliche NeRF und vollständige neuronale Renderer wie RenderFormer sind klar nur für die Forschung und brauchen viel zu lange pro Frame für den interaktiven Einsatz. "Neuronales Rendering ist Echtzeit" stimmt für die Ebene in der Pipeline und ist falsch für die Rekonstruktions- und Vollrenderer-Ebenen.
Diese Trennung folgt dem Spektrum genau. Manche Komponenten in der Pipeline, besonders Hochskalierung, Frame-Erzeugung und Ray Reconstruction, laufen bereits in ausgelieferten Spielen. Andere, wie NRC, NTC und neuronale Shader, beschreibt man besser als Entwicklertechnologien und aufkommende Toolkit-Funktionen statt als gängige Produktionsfunktionen. Die Rekonstruktionsebene ist gemischt: Das ursprüngliche NeRF ist langsam, aber 3D Gaussian Splatting war ein bewusster Vorstoß zur Echtzeit und schafft sie für statische Szenen. Die Vollneuronalrenderer-Ebene (ein einziges Netzwerk, das das ganze Bild erzeugt) ist dort, wo die Forschung lebt, und die Frame-Zeiten sind bei Weitem nicht interaktiv.
Hardware ist die andere Hälfte der Antwort, und hier landet die herstellerübergreifende Geschichte. Jede Technik hier läuft auf den Matrixmathematik-Einheiten, die moderne GPUs für KI-Inferenz mitbringen:
- NVIDIA hat Tensor Cores auf jeder RTX-Karte ab der 20-Serie aufwärts, weshalb die meisten dieser Techniken dort debütierten.
- AMDs ML-basiertes FSR Upscaling zielt derzeit für den ML-Pfad auf RDNA-4- / Radeon-RX-9000-GPUs; auf älterer Hardware greift AMDs SDK auf analytische FSR-3.1.5-Pfade zurück. Behandle breitere Unterstützung älterer GPUs als ein sich bewegendes Roadmap-Element, nicht als garantierte FSR-4-Funktion, sofern du nicht eine konkrete AMD-Ankündigung zitierst.
- Intel nutzt XMX-Matrix-Engines auf Arc-GPUs für XeSS.
DLSS selbst ist nach Generation funktionsgebunden: Hochskalierung funktioniert bis zur RTX-20-Serie zurück, die ursprüngliche Frame-Erzeugung braucht die RTX-40-Serie, und Multi-Frame-Erzeugung gibt es nur bei der RTX-50-Serie. Wenn du herleiten willst, was eine bestimmte Karte kann, ist diese Generationsbindung die praktische Antwort, nicht die Marketing-Stufe.
Was du heute nutzen kannst gegenüber dem, was kommt: Hochskalierung, Frame-Erzeugung und Ray Reconstruction sind heute in Spielen verfügbar. RTX-Kit-Komponenten wie NRC, NTC und neuronale Shader sind als Entwicklertechnologien und Tooling verfügbar, aber du solltest nicht andeuten, dass sie alle bereits in ausgelieferten Spielen gängig sind. Gaussian Splatting hat brauchbares offenes Tooling für die Szenenerfassung. Was noch nicht da ist: vollständige neuronale Renderer, die einen ganzen Frame mit einem Netzwerk zeichnen, ausgereifte herstellerübergreifende neuronale Shader (die AMD-Unterstützung steckt in den Anfängen) und die generativen Funktionen von DLSS 5 (für Herbst 2026 angekündigt). Wenn du mit der Rekonstruktionsseite experimentieren willst (NeRF oder Inferenz-Workloads selbst ausführen), ist das eine Aufgabe für GPU-Berechnung , nicht etwas, das dein Spiel für dich erledigt.
Was neuronales Rendering nicht ist: fünf Missverständnisse

Die meisten Argumente zum neuronalen Rendering werden leichter, sobald du erkennst, von welcher Ebene des Spektrums die Behauptung handelt. Fünf Missverständnisse kommen immer wieder auf.
1. "DLSS-Hochskalierung ist neuronales Rendering." DLSS ist an Anwendung des neuronalen Renderings, die Echtzeitebene in der Pipeline, nicht das ganze Feld. Der Begriff ist älter als DLSS und umfasst NeRF, Gaussian Splatting und die generativen Methoden. Die beiden gleichzusetzen ist, als nenne man "Datenbanken" ein Synonym für ein Produkt, das man zufällig benutzt.
2. "Frame-Erzeugung macht Spiele schneller." Sie erhöht die Frame-Anzahl, die du siehst, was Bewegung geschmeidiger aussehen lässt, aber sie läuft nach dem Rendering und fügt Latenz hinzu. Die Rate, mit der das Spiel aktualisiert und auf deine Eingabe reagiert, steigt nicht. Für den kompetitiven Spielbetrieb ist diese Latenz ein echter Kompromiss; für visuelle Geschmeidigkeit ist sie ein echter Gewinn. "Schneller" vermischt die beiden.
3. "DLSS 5 ist 3D-bewusst / liest die 3D-Szene." Das ist das, was man am ehesten richtig verstehen sollte, weil die Tech-Berichterstattung es immer wieder falsch darstellt. So wie NVIDIA es beschreibt, nimmt DLSS 5 die Farbdaten und Bewegungsvektoren jedes Frames als Eingaben und nutzt dann sein trainiertes Modell, um die Szenensemantik abzuleiten, etwa Figuren, Haare, Stoff, Haut und Beleuchtungsbedingungen. Es ist im Inhalt des Spiels verankert, aber NVIDIA beschreibt es nicht als direktes Lesen der vollständigen 3D-Szenendatei des Spiels. "3D-geführt" bedeutet, dass die Inferenz geometriekonsistent ist (sie respektiert, wie sich Oberflächen bewegen und zueinander verhalten), nicht, dass das Netzwerk die Szenengeometrie direkt liest. Die Unterscheidung ist wichtig, weil sie begrenzt, was die Technik wissen kann und was nicht.
4. "NeRF ist jetzt Echtzeit." Kommt darauf an, welche Technik du meinst, was genau das Spektrumsproblem ist. Das ursprüngliche NeRF ist nicht Echtzeit. 3D Gaussian Splatting nähert sich der Echtzeit für statische Szenen. Forschungssysteme, die einen vollen Frame mit einem Netzwerk rendern (RenderFormer und ähnliche), sind überhaupt nicht Echtzeit. "NeRF" ist zu einem Sammelbegriff für ein halbes Dutzend Methoden mit völlig unterschiedlichen Geschwindigkeiten geworden.
5. "Neuronales Rendering wird die Rasterisierung bald ersetzen." Die heutigen Systeme sind hybrid: Neuronale Komponenten sitzen innerhalb einer Rasterisierungs- und Raytracing-Pipeline, nicht an deren Stelle. Die klassische Pipeline vollständig durch einen einzigen generativen Renderer zu ersetzen, ist ein Forschungsziel mit langem Horizont, keine kurzfristige Produktrichtung. Nimm "die Zukunft ist vollständig neuronal" als eine Bewegungsrichtung, nicht als datierte Vorhersage.
Fazit des Abschnitts: Die einzige Grundursache fast jeder Meinungsverschiedenheit zum neuronalen Rendering ist, dass Leute dasselbe Wort für verschiedene Ebenen des Spektrums benutzen. Verorte die Behauptung zuerst auf dem Spektrum, und der Großteil der Diskussion verschwindet.
Wohin das führt
Die Entwicklung ist mit allem oben Gesagten stimmig: heute hybride Pipelines, mehr Stufen, die von Berechnen zu Vorhersagen wechseln, herstellerübergreifende neuronale Shader, die erweitern, wer dies ausliefern kann, und die Vollneuronalrenderer-Grenze noch Jahre entfernt. Der nächste Schritt für Verbraucher ist DLSS 5, angekündigt für Herbst 2026, das in das generative neuronale Rendering vorstößt, indem es Beleuchtungs- und Materialdetails erzeugt, die das Spiel nie berechnet hat, statt nur zwischen gerenderten Frames zu interpolieren. NVIDIA hat die Technologie in Kontexten der RTX-50-Serie gezeigt, aber ihre endgültigen Verbraucher-Hardwareanforderungen sollten als unbestätigt behandelt werden, bis NVIDIA eine klare Kompatibilitätsliste veröffentlicht.
Der Ausblick hat zwei Hälften. Auf der nahen Seite ist der Schritt, der am meisten zählt, nicht irgendeine einzelne Technik. Es ist die Standardisierung. Microsofts DirectX-Pfad bewegt sich von Cooperative Vectors hin zu breiterer linearer Algebra auf Shader-Ebene, was es Engines erlauben könnte, neuronale Workloads anzusteuern, ohne auf eine GPU-Marke zu setzen. Auf der fernen Seite haben NVIDIA-Forscher einen Endpunkt in ferner Zukunft beschrieben, manchmal als hypothetisches "DLSS 10" ins Spiel gebracht, bei dem der Renderer vollständig neuronal ist und die klassische Pipeline verschwunden ist (aus zweiter Hand von einer Digital-Foundry-Runde berichtet; behandle es als eine genannte Richtung, nicht als Roadmap). Der Endpunkt der Leiter ist ein System, das eine kohärente Welt erzeugt, statt eine zu zeichnen.
Es lohnt sich aber, die Skepsis zu behalten. Erzeugte Details können von der künstlerischen Absicht abweichen, und ein Netzwerk kann plausible, aber falsche Bilder halluzinieren, die kein traditionelles Äquivalent zum Debuggen haben: ein auf der GDC 2026 markiertes QA-Problem und der Kern hinter viel der "KI-Müll"-Reaktion. Für die Richtung zu bauen, in die Grafik geht, heißt nicht, so zu tun, als sei die aktuelle Ausgabe fertig. Es heißt, zu beobachten, welche Stufen als Nächstes von Berechnen zu Vorhersagen wechseln, und jede danach zu beurteilen, was sie mit dem Bild macht, statt nach dem Wort, das daran haftet.
Häufig gestellte Fragen
Ist DLSS neuronales Rendering?
Ja, aber es ist nur eine Art. DLSS ist eine Anwendung des neuronalen Renderings: konkret die Echtzeitebene in der Pipeline, die KI-Hochskalierung und Frame-Erzeugung abdeckt. Der breitere Begriff ist älter als DLSS und umfasst auch Szenenrekonstruktionsmethoden wie NeRF und Gaussian Splatting sowie generative Methoden, die neues Bilddetail erfinden. Also ist jede DLSS-Funktion neuronales Rendering, aber viel neuronales Rendering ist nicht DLSS.
Was ist der Unterschied zwischen neuronalem Rendering und Raytracing?
Raytracing simuliert Licht, indem es berechnet, wie Strahlen durch eine Szene springen; neuronales Rendering sagt Ergebnisse aus einem trainierten Netzwerk vorher, statt sie zu berechnen. Sie sind keine Rivalen. Sie kombinieren sich. Ray Reconstruction nutzt zum Beispiel ein neuronales Netz, um rauschige raygetracte Ausgabe zu entrauschen, und der neuronale Radiance-Cache sagt gesprungenes Licht vorher, damit der Raytracer früher aufhören kann. Neuronale Techniken machen Raytracing in Echtzeit erschwinglich.
Fügt DLSS Frame Generation Latenz hinzu?
Ja. Die Frame-Erzeugung läuft, nachdem ein Frame gerendert wurde, und fügt zwischen gerenderten Frames vorhergesagte Frames ein, was Latenz hinzufügt, statt sie zu entfernen: NVIDIAs Reflex 2 existiert eigens zum Ausgleich. Sie erhöht die wahrgenommene Geschmeidigkeit (mehr angezeigte Frames), ohne zu erhöhen, wie schnell das Spiel aktualisiert und auf Eingaben reagiert. Für den kompetitiven Spielbetrieb ist das ein Kompromiss; für die Geschmeidigkeit im Einzelspieler ist es meist ein Nettogewinn.
Ist NeRF Echtzeit?
Es kommt darauf an, welche Technik du meinst. Das ursprüngliche NeRF ist nicht Echtzeit. 3D Gaussian Splatting, eine spätere Methode, nähert sich der Echtzeit für statische Szenen. Vollständige neuronale Renderer, die einen ganzen Frame mit einem Netzwerk zeichnen, sind nur für die Forschung und weit von interaktiven Geschwindigkeiten entfernt. "NeRF" wird oft locker verwendet, um mehrere Methoden mit sehr unterschiedlicher Leistung abzudecken, was die Quelle der meisten Verwirrung ist.
Wird neuronales Rendering die Rasterisierung ersetzen?
Nicht bald. Die heutigen Systeme sind hybrid: Neuronale Komponenten laufen innerhalb einer Rasterisierungs- und Raytracing-Pipeline, nicht an deren Stelle. Die klassische Pipeline vollständig durch einen einzigen generativen Renderer zu ersetzen, ist ein Forschungsziel mit langem Horizont, kein kurzfristiges Produkt. Die realistische Richtung ist, dass mit der Zeit mehr Pipeline-Stufen von berechnet zu vorhergesagt wechseln, wobei die Rasterisierung noch jahrelang echte Arbeit leistet.
Was ist neuronale Texturkompression?
Die neuronale Texturkompression (NTC) ist eine neuronale Methode, die alle Texturkanäle eines Materials gemeinsam komprimiert (Farbe, Normalen, Rauheit und den Rest) und bis zu 8-fache VRAM-Einsparung gegenüber traditioneller Blockkompression bei ähnlicher visueller Qualität erreicht, laut NVIDIA. Sie funktioniert, indem sie die Korrelationen über die Kanäle hinweg lernt, die die Blockkompression, die jeden Kanal separat zusammendrückt, verwirft. Das komprimierte Material wird zur Renderzeit im Vorbeigehen dekodiert.


