
Die Wahl einer GPU VPS kann sich überwältigend anfühlen, wenn man auf Datenblätter voller Zahlen starrt. Die Core-Anzahl reicht von 2.560 bis 21.760 – aber was bedeutet das konkret?
Ein CUDA-Kern ist eine Parallelverarbeitungseinheit in NVIDIA GPUs, die Tausende von Berechnungen gleichzeitig ausführt – von KI-Training bis zu 3D-Rendering. Dieser Leitfaden erklärt, wie sie funktionieren, wie sie sich von CPU- und Tensor-Kernen unterscheiden und welche Core-Anzahl wirklich zu Ihren Anforderungen passt.
Was sind CUDA-Kerne?

CUDA-Kerne sind einzelne Verarbeitungseinheiten in NVIDIA GPUs, die Anweisungen parallel ausführen. Im Kern funktioniert die CUDA-Technologie wie ein Team kleiner Arbeitseinheiten, die Teile derselben Aufgabe gleichzeitig bearbeiten.
NVIDIA hat CUDA (Compute Unified Device Architecture) 2006 eingeführt, um die Rechenleistung von GPUs über die Grafikverarbeitung hinaus für allgemeine Berechnungen nutzbar zu machen. Die offizielle CUDA-Dokumentation bietet umfassende technische Details. Jede Einheit führt grundlegende arithmetische Operationen auf Gleitkommazahlen aus – ideal für wiederkehrende Berechnungen.
Moderne NVIDIA GPUs vereinen Tausende dieser Einheiten auf einem einzigen Chip. GPUs der aktuellen Konsumentengeneration enthalten über 21.000 Kerne, während Rechenzentrums-GPUs auf Basis der Hopper-Architektur bis zu 16.896 bieten. Diese Einheiten arbeiten über Streaming Multiprocessors (SMs) zusammen.
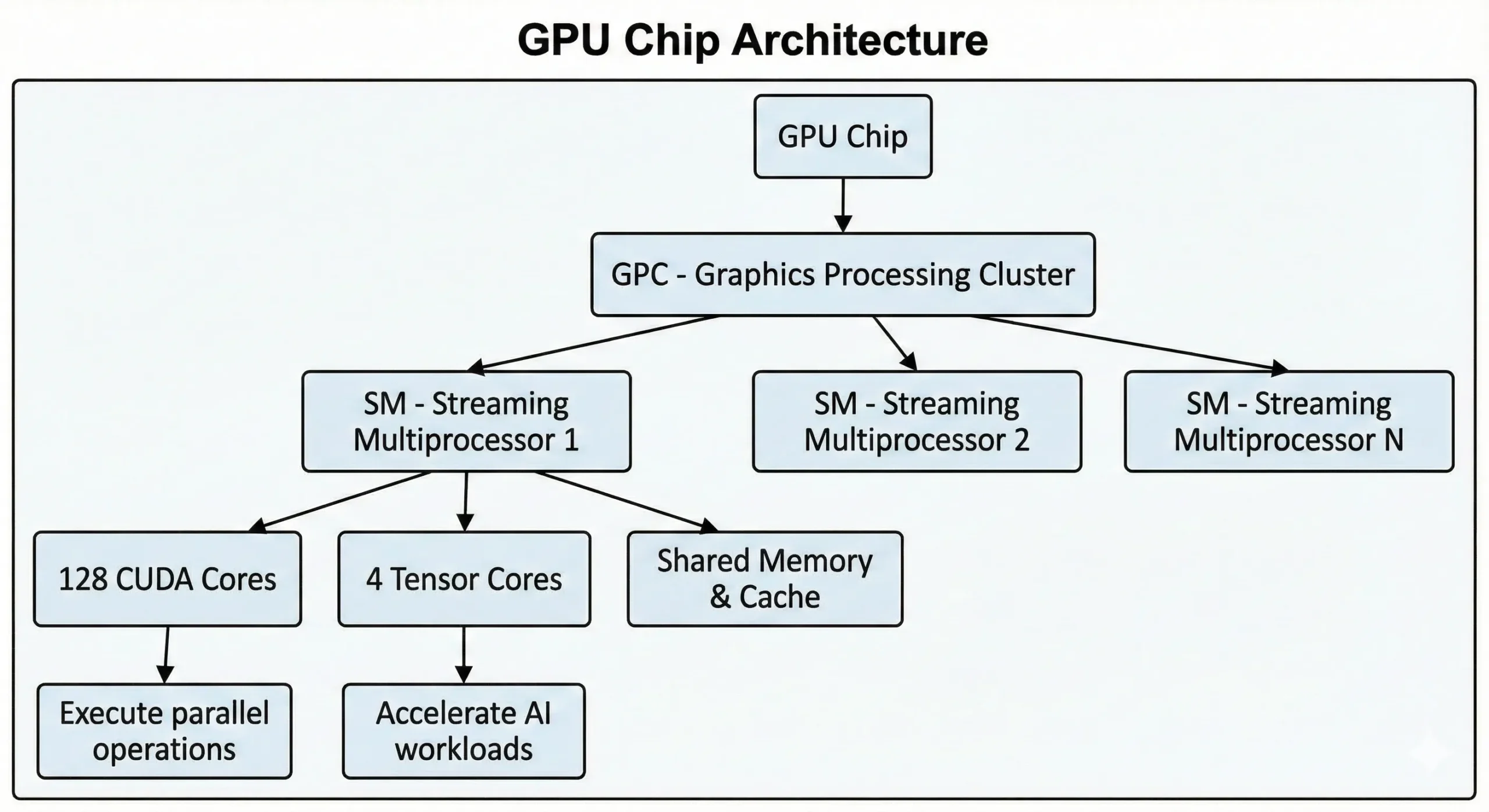
Die Einheiten führen SIMT-Operationen (Single Instruction, Multiple Threads) durch parallele Verarbeitungsmethoden aus. Eine Anweisung wird gleichzeitig auf viele Datenpunkte angewendet. Beim Training neuronaler Netze oder beim Rendern von 3D-Szenen laufen Tausende ähnlicher Operationen ab. Die Arbeit wird in parallele Streams aufgeteilt und gleichzeitig statt nacheinander ausgeführt.
CUDA-Kerne vs. CPU-Kerne: Was unterscheidet sie?

CPUs und GPUs lösen Probleme auf grundlegend unterschiedliche Weise. Ein moderner Server-CPU hat 8 bis über 128 Kerne mit hohen Taktfrequenzen. Diese Prozessoren sind auf sequenzielle Operationen ausgelegt, bei denen jeder Schritt vom vorherigen abhängt. Sie verarbeiten komplexe Logik und Verzweigungen effizient.
GPUs verfolgen einen anderen Ansatz. Sie vereinen Tausende einfacherer CUDA-Kerne mit niedrigeren Taktfrequenzen. Die geringere Einzelgeschwindigkeit wird durch Parallelverarbeitung ausgeglichen. Wenn 16.000 Kerne zusammenarbeiten, übertrifft der Gesamtdurchsatz die Leistung herkömmlicher CPUs.
CPUs führen Betriebssystem-Code und komplexe Anwendungslogik aus. GPUs priorisieren Durchsatz, haben aber durch Task-Start und Synchronisierung eine höhere Latenz. Parallele Grafikverarbeitung setzt auf Datendurchsatz. GPUs brauchen länger zum Starten, verarbeiten große Datensätze aber schneller als CPUs.
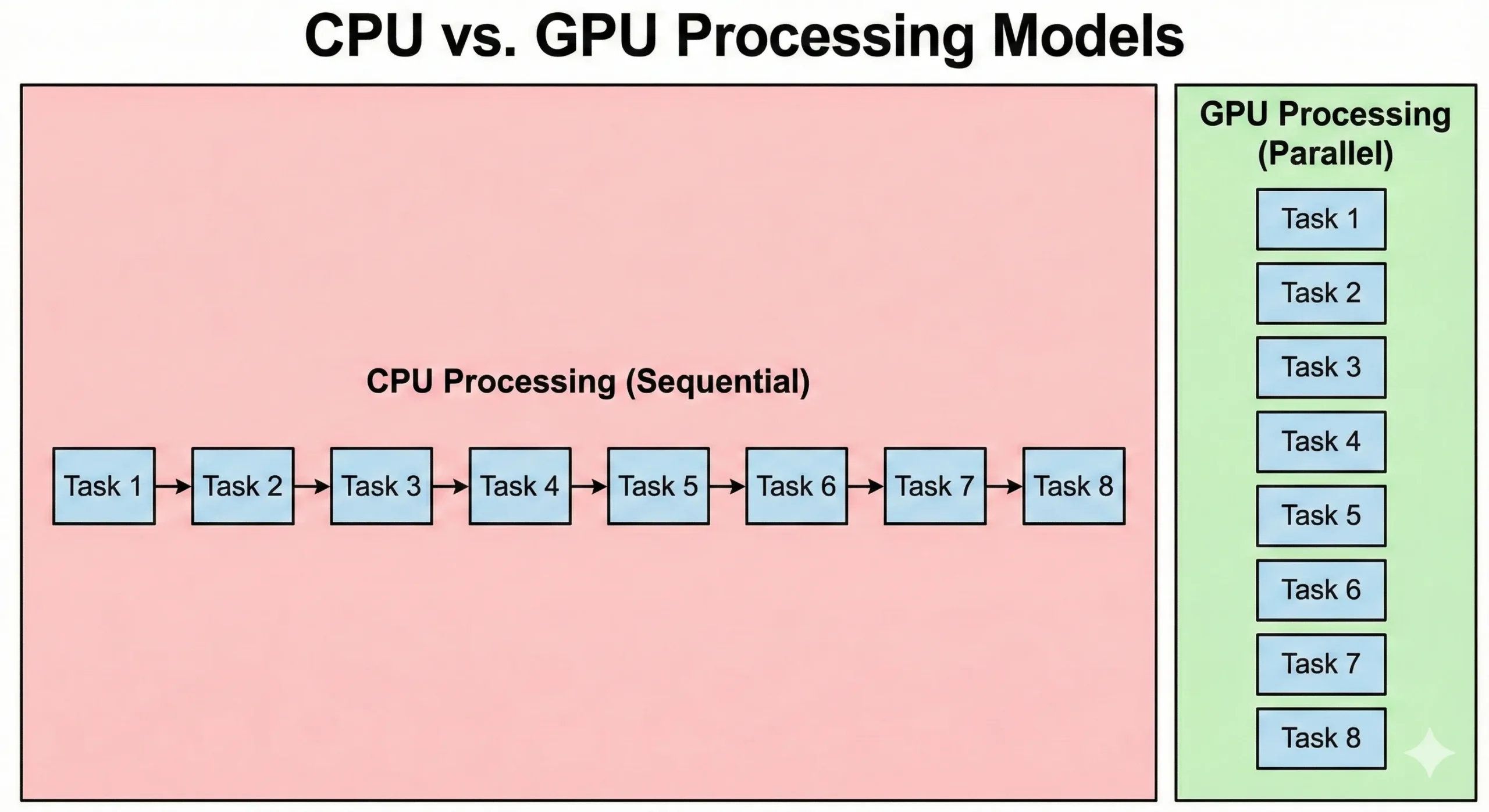
| Funktion | CPU-Kerne | CUDA-Kerne |
| Anzahl pro Chip | 4-128+ Kerne | 2.560–21.760 Kerne |
| Taktfrequenz | 3,0–5,5 GHz | 1,4–2,5 GHz |
| Verarbeitungsstil | Sequenziell, komplexe Anweisungen | Parallele, einfache Anweisungen |
| Am besten geeignet für | Betriebssysteme, Single-Threaded-Aufgaben | Matrizenrechnung, parallele Datenverarbeitung |
| Latenz | Niedrig (Mikrosekunden) | Höher (Startaufwand) |
| Architektur | Allzweck | Spezialisiert für repetitive Berechnungen |
Virtual GPU (vGPU) und Multi-Instance GPU (MIG) verwalten die Ressourcenaufteilung und Aufgabenplanung, um Prozessoren auf mehrere Nutzer zu verteilen. Diese Konfiguration erlaubt Teams, die Hardware-Auslastung zu maximieren - entweder durch zeitbasiertes Sharing oder dedizierte Hardware-Instanzen, je nach Einrichtung.
Das Training neuronaler Netze erfordert Milliarden von Matrixmultiplikationen. Ein GPU mit 10.000 Einheiten führt diese nicht einfach gleichzeitig aus, sondern verwaltet Tausende paralleler Threads, die in sogenannte "Warps" gruppiert sind, um den Durchsatz zu maximieren. Diese massive Parallelität macht diese Einheiten für KI-Entwickler unverzichtbar.
CUDA Cores vs. Tensor Cores: Der Unterschied erklärt

NVIDIA GPUs enthalten zwei spezialisierte Einheitentypen, die zusammenarbeiten: Standard-CUDA-Cores und Tensor-Cores. Es sind keine konkurrierenden Technologien - sie decken unterschiedliche Teile der Arbeitslast ab.
Standard-Einheiten sind universelle Parallelprozessoren, die FP32- und FP64-Berechnungen, ganzzahlige Arithmetik und Koordinatentransformationen übernehmen. Diese CUDA-Kerntechnologie bildet die Grundlage des GPU-Computings und führt alles aus - von Physiksimulationen bis zur Datenvorverarbeitung - ohne spezialisierte Hardwarebeschleunigung.
Tensor-Cores sind spezialisierte Einheiten, die ausschließlich für Matrixmultiplikation und KI-Aufgaben entwickelt wurden. Mit NVIDIAs Volta-Architektur (2017) eingeführt, liefern sie besonders bei FP16- und TF32-Präzisionsberechnungen starke Leistung. Die neueste Generation unterstützt zudem FP8 für noch schnellere KI-Inferenz.
| Funktion | CUDA-Kerne | Tensor-Kerne |
| Zweck | Allgemeines paralleles Computing | Matrixmultiplikation für KI |
| Präzision | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Geschwindigkeit für AI | 1x Basislinie | 2-10x schneller als CUDA-Cores |
| Anwendungsfälle | Datenvorverarbeitung, klassisches ML | Deep-Learning-Training und -Inferenz |
| Verfügbarkeit | Alle NVIDIA GPUs | RTX-20-Serie und neuer, Datacenter-GPUs |
Moderne GPUs kombinieren beide Typen. Der RTX 5090 bietet 21.760 Standard-Einheiten und 680 Tensor-Cores der fünften Generation. Der H100 kombiniert 16.896 Standard-Einheiten mit 528 Tensor-Cores der vierten Generation für Deep-Learning-Beschleunigung.
Beim Training neuronaler Netze übernehmen Tensor-Cores die rechenintensiven Aufgaben während der Vorwärts- und Rückwärtsdurchläufe durch das Modell. Standard-Einheiten kümmern sich um Datenladen, Vorverarbeitung, Verlustberechnungen und Optimierungs-Updates. Beide Typen arbeiten zusammen, wobei Tensor-Cores die besonders rechenintensiven Operationen beschleunigen.
Bei klassischen Machine-Learning-Algorithmen wie Random Forests oder Gradient Boosting übernehmen Standard-Einheiten die Arbeit, da diese keine Matrixmultiplikationsmuster verwenden, die Tensor-Cores beschleunigen. Bei Transformer-Modellen und konvolutionalen neuronalen Netzen hingegen sorgen Tensor-Cores für deutliche Geschwindigkeitssteigerungen.
Wofür werden CUDA-Cores eingesetzt?

CUDA-Cores eignen sich für Aufgaben, bei denen viele identische Berechnungen gleichzeitig ausgeführt werden müssen. Jede Arbeit mit Matrizenoperationen oder wiederkehrenden numerischen Berechnungen profitiert von ihrer Architektur.
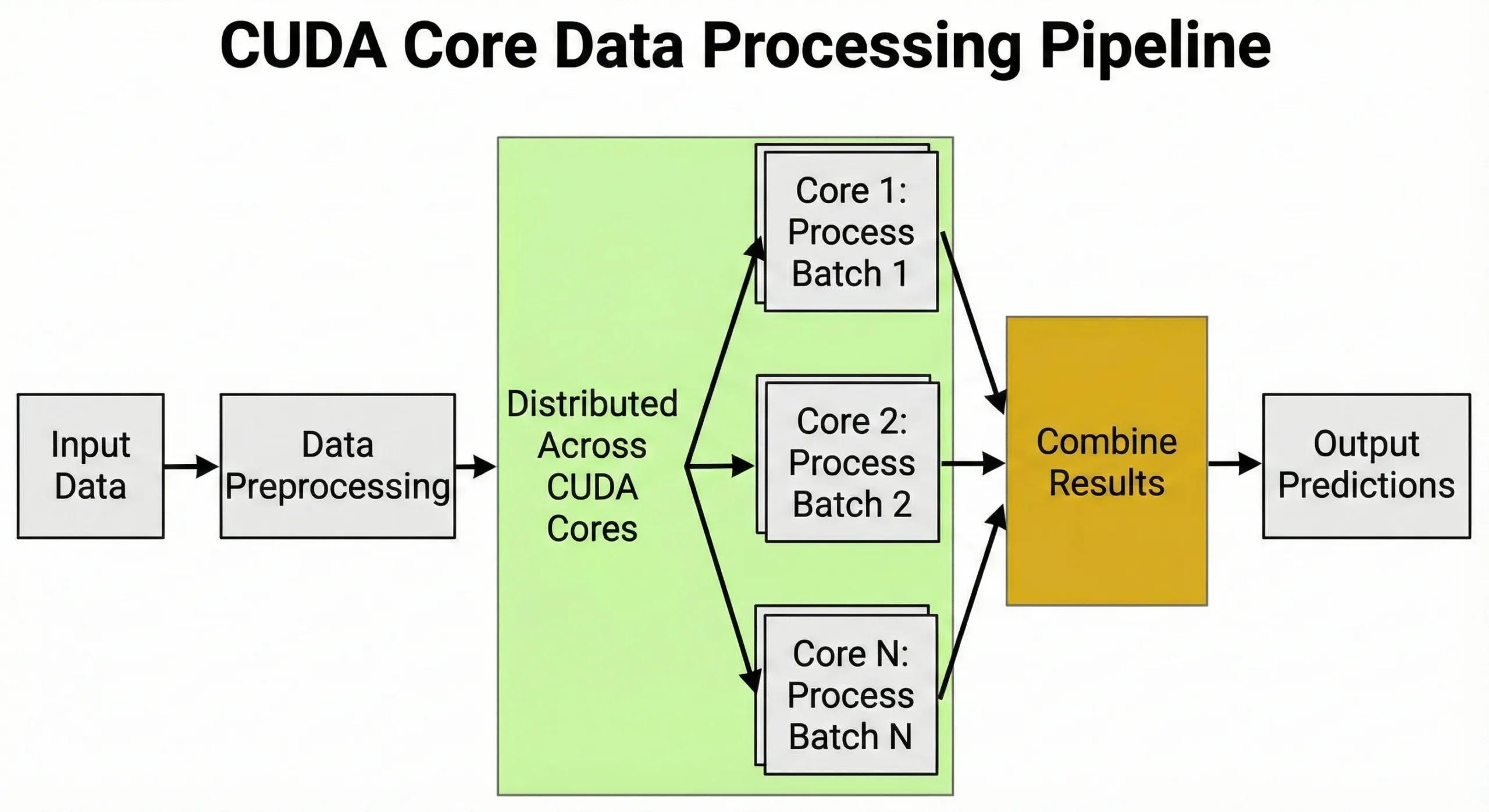
KI- und Machine-Learning-Anwendungen
Deep Learning basiert auf Matrizenmultiplikationen beim Training und bei der Inferenz. Bei jedem Forward Pass eines neuronalen Netzes werden Millionen von Multiply-Add-Operationen über Gewichtsmatrizen durchgeführt. Der Backpropagation-Schritt fügt während des Backward Pass noch einmal Millionen weiterer Operationen hinzu.
Die Einheiten übernehmen die Datenvorverarbeitung: Sie wandeln Bilder in Tensoren um, normalisieren Werte und wenden Augmentation-Transforms an. Genau diese Fähigkeit, Tausende von Aufgaben gleichzeitig zu verarbeiten, macht GPUs so wichtig für KI.
Während des Trainings steuern sie Learning-Rate-Schedules, Gradientenberechnungen und Optimizer-State-Updates.
Bei VPS für KI-Inferenzaufgaben, die Empfehlungssysteme oder Chatbots betreiben, werden Anfragen parallel verarbeitet und Hunderte von Vorhersagen gleichzeitig ausgeführt. Unser Leitfaden zu den besten GPU für KI 2025 zeigt, welche Konfigurationen für verschiedene Modellgrößen geeignet sind.
Die 16.896 Einheiten des H100 in Kombination mit Tensor Cores trainieren ein Modell mit 7 Milliarden Parametern in Wochen statt in Monaten. Echtzeit-Inferenz für Chatbots, die Tausende von Nutzern gleichzeitig bedienen, erfordert ähnliche parallele Rechenkapazität.
Wissenschaftliches Rechnen und Forschung
Forscher setzen diese Prozessoren für Molekulardynamiksimulationen, Klimamodellierung und Genomanalysen ein. Da jede Berechnung unabhängig ist, eignen sie sich ideal für die parallele Ausführung. Finanzinstitute führen Monte-Carlo-Simulationen mit Millionen von Szenarien gleichzeitig durch.
3D-Rendering und Videoproduktion
Ray Tracing berechnet die Lichtausbreitung in 3D-Szenen, indem es unabhängige Strahlen durch jeden Pixel verfolgt. Während dedizierte RT-Kerne die Traversierung übernehmen, verwalten Standardeinheiten Textur-Sampling und Beleuchtung. Diese Aufgabenteilung bestimmt die Rendergeschwindigkeit bei Szenen mit Millionen von Strahlen.
NVENC übernimmt die Kodierung für H.264 und H.265, während neuere Architekturen (Ada Lovelace und Hopper) Hardware-Unterstützung für AV1 einführen. CUDA unterstützt Effekte, Filter, Skalierung, Rauschunterdrückung, Farbtransformationen und die Verbindung der Pipeline-Stufen. Dadurch kann die Kodier-Engine parallel zu den Prozessorkernen arbeiten und die Videoproduktion beschleunigen.
3D-Rendering in Blender oder Maya verteilt Milliarden von Surface-Shader-Berechnungen auf verfügbare Einheiten. Partikelsysteme profitieren davon, da Tausende interagierender Partikel gleichzeitig simuliert werden. Diese Fähigkeiten sind entscheidend für hochwertige digitale Produktion.
Wie CUDA Cores die GPU-Leistung beeinflussen

Die Anzahl der Kerne gibt einen groben Anhaltspunkt für die parallele Rechenkapazität, aber bei CUDA Cores kommt es auf mehr als nur Zahlen an. Taktrate, Speicherbandbreite, Architektureffizienz und Software-Optimierung spielen alle eine wichtige Rolle.
Ein GPU mit 10.000 Einheiten bei 2,0 GHz liefert andere Ergebnisse als eines mit 10.000 Einheiten bei 1,5 GHz. Eine höhere Taktrate bedeutet, dass jede Einheit mehr Berechnungen pro Sekunde abschließt. Neuere Architekturen erledigen durch besseres Instruction Scheduling mehr Arbeit pro Taktzyklus.
Prüfen Sie, ob das Gerät ausgelastet ist, aber beachten Sie: Die nvidia-smi Auslastung ist eine grobe Kennzahl. Sie misst den prozentualen Anteil der Zeit, in der ein Kernel aktiv ist, nicht wie viele Kerne tatsächlich Arbeit verrichten.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderBeispielausgabe: 85 %, 92 % (85 % Zeit aktiv, 92 % Speichercontroller-Aktivität)
Zeigt Ihr GPU eine Auslastung von 60–70 %, liegen wahrscheinlich vorgelagerte Engpässe vor, etwa langsames CPU-Datenladen oder zu kleine Batch-Größen. Selbst eine Auslastung von 100 % kann jedoch irreführend sein, wenn Ihre Kernel speichergebunden oder single-threaded laufen. Für ein genaues Bild der Kernsättigung sollten Sie Profiler wie Nsight Systems verwenden und dort die Metriken "SM Efficiency" oder "SM Active" beobachten.
Die Speicherbandbreite wird häufig zum Engpass, bevor die Rechenkapazität ausgeschöpft ist. Verarbeitet Ihr GPU Daten schneller, als der Speicher sie liefern kann, stehen Einheiten ungenutzt. Das H100 SXM5-Modell bietet 3,35 TB/s Bandbreite um seine 16.896 Kerne zu versorgen. Die PCIe-Version reduziert dies jedoch auf 2 TB/s.
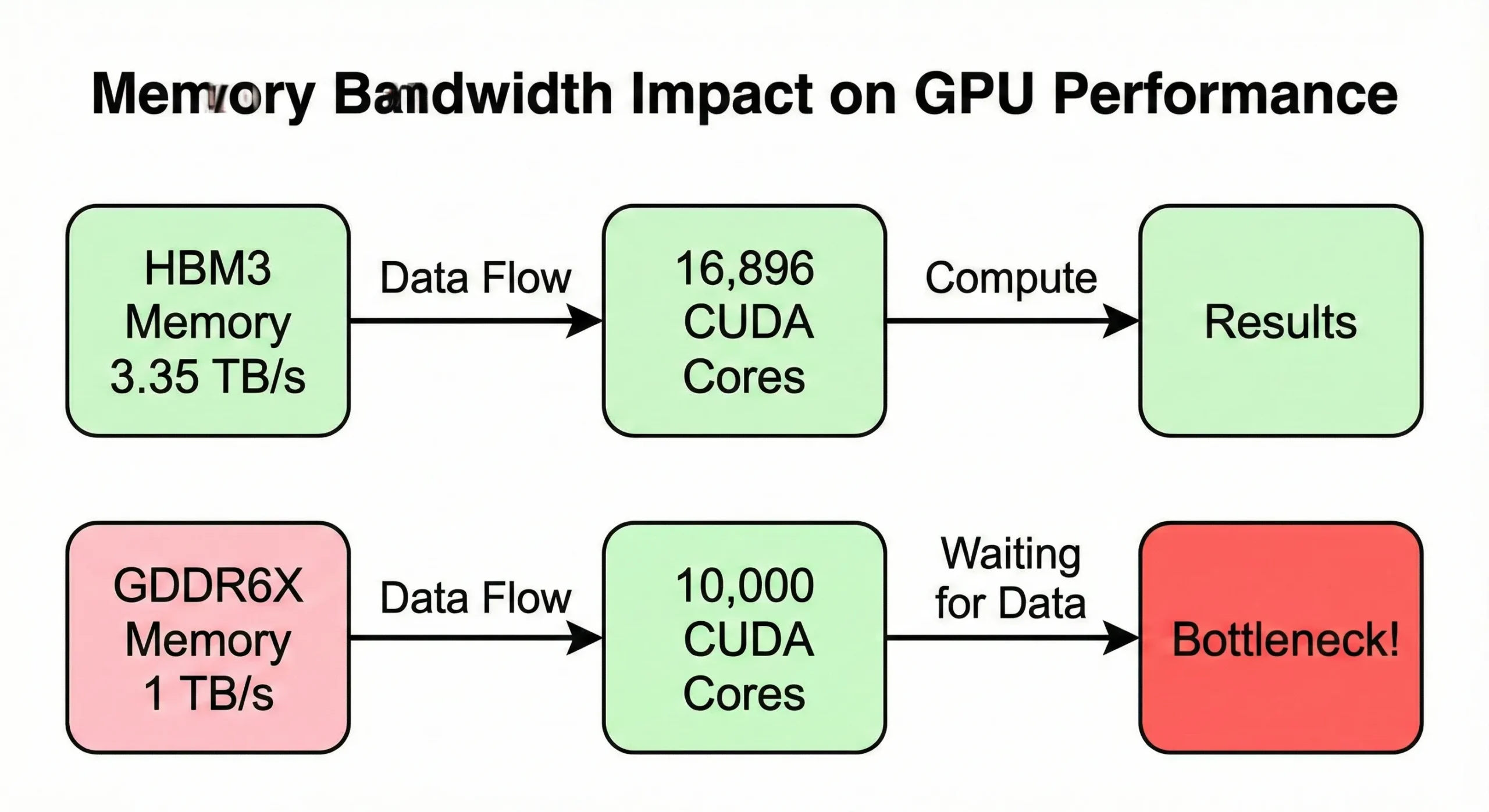
Consumer-GPUs mit ähnlicher Kernanzahl, aber geringerer Bandbreite (rund 1 TB/s) zeigen bei speicherintensiven Operationen spürbar niedrigere Geschwindigkeiten.
Die VRAM-Kapazität bestimmt, wie groß Ihre Aufgaben sein können. Ob FP16-Gewichte für ein 70B Modell, vollständiges Training erfordert mehr Speicher. Gradienten und Optimizer-Zustände müssen einkalkuliert werden. Diese Zustände verdreifachen den Speicherbedarf häufig, sofern keine Offload-Strategien eingesetzt werden.
Die A100 mit 80 GB ist auf hohen Inferenz-Durchsatz und Fine-Tuning ausgelegt. Die RTX 4090 mit 24 GB, oft als Wahl für 7B-Modelle genannt, kann mit modernen Quantisierungstechniken wie INT4 überraschenderweise auch Modelle mit 30B+ Parametern ausführen. Geht der VRAM jedoch zur Neige, erzwingen CPU-GPU-Datentransfers massive Einbußen beim Durchsatz.
Software-Optimierung entscheidet darüber, ob Ihr Code all diese Recheneinheiten tatsächlich nutzt. Schlecht geschriebene Kernel beanspruchen oft nur einen Bruchteil der verfügbaren Ressourcen. Bibliotheken wie cuDNN für Deep Learning und RAPIDS für Data Science sind stark auf maximale Auslastung optimiert.
Mehr CUDA-Kerne bedeuten nicht immer bessere Leistung

Eine GPU mit der höchsten Kernanzahl zu kaufen klingt logisch, ist aber Geldverschwendung, wenn die Recheneinheiten andere Systemkomponenten überlasten oder Ihre Aufgabe nicht mit der Kernanzahl skaliert.
Die Speicherbandbreite setzt die erste Grenze. Die 21.760 Einheiten der RTX 5090 werden mit 1.792 GB/s Speicherbandbreite versorgt. Ältere GPUs mit weniger Einheiten haben möglicherweise proportional mehr Bandbreite pro Einheit.
Architekturunterschiede spielen eine Rolle. Eine neuere GPU mit 14.000 Einheiten bei 2,2 GHz übertrifft eine ältere mit 16.000 Einheiten bei 1,8 GHz, weil sie mehr Instruktionen pro Takt ausführt. Damit 20.000 Einheiten effektiv genutzt werden, muss Ihr Code korrekt parallelisiert sein.
Warum CUDA-Kerne bei der Wahl einer GPU VPS eine Rolle spielen

Die richtige CUDA-Kern-Konfiguration der GPU für Ihre VPS zu wählen, verhindert, dass Sie Geld für ungenutzte Ressourcen verschwenden oder mitten im Projekt an Grenzen stoßen.
Der 80-GB-Speicher der H100 reicht für die Inferenz von 70B-Parameter-Modellen mit 4-Bit-Quantisierung. Für vollständiges Training sind jedoch selbst 80 GB bei einem 34B-Modell oft unzureichend, sobald Gradienten und Optimizer-Zustände berücksichtigt werden. Im FP16-Training wächst der Speicherbedarf erheblich und erfordert häufig Multi-GPU-Sharding.
Inferenz-Operationen für Echtzeit-Vorhersagen benötigen weniger Einheiten, profitieren aber von niedriger Latenz. Für Entwicklung und Prototyping reichen Mid-Range-GPUs zum Testen von Algorithmen und Debuggen von Code völlig aus.
Eine RTX 4060 Ti mit 4.352 Einheiten ermöglicht Tests ohne überdimensionierte Hardware. Sobald Ihr Ansatz validiert ist, skalieren Sie auf Produktions-GPUs für vollständige Trainingsdurchläufe.
Rendering und Videobearbeitung skalieren mit der Einheitenanzahl bis zu einem gewissen Punkt. Blenders Cycles-Renderer nutzt alle verfügbaren Ressourcen effizient. Eine GPU mit 8.000-10.000 Einheiten rendert Szenen 2-3x schneller als eine mit 4.000.
Bei Cloudzy bieten wir leistungsstarkes GPU-VPS Hosting für rechenintensive Aufgaben. Wählen Sie die RTX 5090 oder RTX 4090 für schnelles Rendering und kosteneffiziente KI-Inferenz, oder skalieren Sie auf A100s für umfangreiche Deep-Learning-Workloads. Alle Tarife laufen auf einem 40-Gbps-Netzwerk mit konsequentem Datenschutz und Kryptowährungs-Zahlungsoptionen - volle Rechenleistung ohne bürokratischen Aufwand.
Ob Sie KI-Modelle trainieren, 3D-Szenen rendern oder wissenschaftliche Simulationen ausführen - Sie wählen die Kernanzahl, die zu Ihren Anforderungen passt.
Das Budget spielt eine Rolle. Eine A100 mit 6.912 Einheiten kostet deutlich weniger als eine H100 mit 16.896. Für viele Aufgaben bieten zwei A100s ein besseres Preis-Leistungs-Verhältnis als eine H100. Der Break-even-Punkt hängt davon ab, ob Ihr Code über mehrere GPUs hinweg skaliert.
Wie Sie die richtige Anzahl an CUDA-Kernen wählen
Stimmen Sie Ihre Anforderungen auf die tatsächlichen Workload-Eigenschaften ab, statt nach den höchsten Zahlen auf dem Markt zu greifen.
Analysieren Sie zunächst Ihre aktuelle Arbeitslast. Wenn Sie Modelle auf lokaler Hardware oder Cloud-Instanzen trainieren, prüfen Sie die Auslastungsmetriken der GPU. Liegt die Auslastung Ihrer GPU konstant bei 60–70 %, schöpfen Sie die Einheiten nicht voll aus.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Dieser einfache Benchmark zeigt, ob Ihre GPU-Kerne den erwarteten Durchsatz liefern. Vergleichen Sie Ihre Ergebnisse mit veröffentlichten Benchmarks für Ihr GPU-Modell.
Ein Upgrade hilft hier nicht weiter. Beheben Sie zuerst Engpässe wie Speicher, Bandbreite oder CPU-Stalls. Berechnen Sie anschließend den Speicherbedarf: Modellgröße in Bytes plus Aktivierungsspeicher.
Addieren Sie Batch-Größe multipliziert mit Layer-Outputs und rechnen Sie Optimizer-Zustände hinzu. Dieses Gesamtvolumen muss in den VRAM passen. Wenn Sie den benötigten Speicher kennen, prüfen Sie, welche GPUs diesen Schwellenwert erfüllen.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Beachten Sie Ihren Zeitplan. Brauchen Sie Ergebnisse innerhalb weniger Stunden, zahlen Sie für mehr Einheiten. Trainingsläufe, die ohnehin mehrere Tage dauern können, laufen auch auf kleineren GPUs problemlos, brauchen dann eben entsprechend länger.
Kosten pro Stunde multipliziert mit der benötigten Stundenzahl ergibt die Gesamtkosten. Langsamere GPUs sind dadurch manchmal insgesamt günstiger. Testen Sie die Skalierungseffizienz mit den Benchmarking-Tools, die viele Frameworks mitbringen und den Durchsatz bei verschiedenen Konfigurationen anzeigen.
Wenn die doppelte Anzahl an Einheiten nur 1,5-fache Beschleunigung bringt, lohnen sich die zusätzlichen Kosten nicht. Suchen Sie den Punkt, an dem das Preis-Leistungs-Verhältnis am besten ist.
| Arbeitstyp | Empfohlene Kerne | Beispiel-GPUs | Hinweise |
| Modellentwicklung & Debugging | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Schnelle Iteration, niedrigere Kosten |
| KI-Training im kleinen Maßstab (< 7 Mrd. Parameter) | 6,000-10,000 | RTX 4090, L40S | Für Consumer- und kleine Unternehmensumgebungen |
| KI-Training im großen Maßstab (7–70 Mrd. Parameter) | 14,000+ | A100, H100 | Erfordert Rechenzentrum-GPUs |
| Echtzeit-Inferenz (hoher Durchsatz) | 10,000-16,000 | RTX 5080, L40 | Kosten und Leistung ausbalancieren |
| 3D-Rendering & Videokodierung | 8,000-12,000 | RTX 4080, RTX 4090 | Skaliert mit der Komplexität |
| Wissenschaftliches Rechnen & HPC | 10,000+ | A100, H100 | Benötigt FP64-Unterstützung |
Bekannte VPS GPUs und ihre CUDA-Core-Anzahl

Verschiedene GPU-Kategorien bedienen unterschiedliche Zielgruppen. Was ist GPUaaS? Es handelt sich um GPU-as-a-Service: Anbieter wie Cloudzy ermöglichen den bedarfsgesteuerten Zugriff auf leistungsstarke NVIDIA GPUs, ohne dass Sie die Hardware selbst kaufen und betreiben müssen.
| GPU-Modell | CUDA-Kerne | VRAM | Speicherbandbreite | Architektur | Am besten für |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Flaggschiff-Workstation, 8K-Rendering |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | High-End-KI, 4K-Rendering |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | KI-Training im großen Maßstab |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | Enterprise-AI, kosteneffizientes Rechenzentrum |
| A100 | 6,912 | 40/80 GB HBM2e | 1,555–2,039 GB/s | Ampere | Mid-Range-AI, bewährte Zuverlässigkeit |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming, Mid-Tier-AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Rechenzentrum für gemischte Workloads |
Consumer-RTX-Karten (4070, 4080, 4090, 5080, 5090) richten sich an Creator und Gamer, eignen sich aber gut für AI-Entwicklung. Sie bieten hohe Einzelkern-GPU-Leistung zu niedrigeren Preisen als Rechenzentrum-Karten.
VPS-Anbieter setzen diese Karten häufig für preissensible Nutzer ein. Rechenzentrum-Karten (A100, H100, L40) legen den Fokus auf Zuverlässigkeit, ECC-Speicher und Multi-GPU-Skalierung. Sie sind für den 24/7-Betrieb ausgelegt und unterstützen erweiterte Funktionen.
Multi-Instance GPU (MIG) ermöglicht es, eine GPU in mehrere isolierte Instanzen aufzuteilen. Die A100 bleibt trotz neuerer Alternativen beliebt, weil ihre Spezifikationen ausgewogen sind.
Das Verhältnis aus NVIDIA-Kernen, Speicher und Preis macht sie zur sicheren Wahl für die meisten produktiven AI-Workloads. Die H100 bietet 2,4-mal mehr Einheiten, kostet aber deutlich mehr.
Fazit
Parallelverarbeitungseinheiten machen modernes AI, Rendering und wissenschaftliche Berechnungen erst möglich. Wer versteht, wie sie mit Speicher, Taktfrequenzen und Software zusammenwirken, trifft bessere Entscheidungen bei der Wahl von GPU-VPS-Konfigurationen.
Mehr Einheiten helfen, wenn sich Ihre Arbeitslast gut parallelisieren lässt und Komponenten wie die Speicherbandbreite mithalten. Aber blindes Streben nach der höchsten Kernzahl verschwendet Geld, wenn Ihre Engpässe woanders liegen.
Analysieren Sie zunächst Ihre tatsächlichen Workloads, ermitteln Sie, wo Zeit verloren geht, und wählen Sie GPU-Spezifikationen, die genau diesen Anforderungen entsprechen, ohne unnötige Kapazität einzukaufen.
Für die meisten AI-Entwicklungsaufgaben bieten 6.000-10.000 Einheiten das beste Verhältnis aus Kosten und Leistung. Produktive Workloads beim Training großer Modelle oder bei hochvolumiger Inferenz profitieren von GPUs mit 14.000+ Einheiten wie der H100.
Rendering- und Videoarbeit skaliert effizient bis etwa 16.000 Einheiten. Darüber hinaus wird die Speicherbandbreite zum limitierenden Faktor.


