
Az GPU vagy VPS kiválasztása zavaróan hathat, ha csak a papíron szereplő számokra nézel. A magok száma 2560-ról 21760-ra ugrik, de mit is jelent ez valójában?
A CUDA mag egy párhuzamos feldolgozó egység az NVIDIA GPU-ben, amely egyszerre több ezer számítást hajt végre. Ez az alapja az AI-edzésnek, a 3D-megjelenítésnek és sok más munkának. Ez az útmutató elmagyarázza, hogyan működnek, miben különböznek az CPU és a Tensor magok, és hogy hány mag kellhet valójában az eddigi költségek nélkül.
Mik azok a CUDA magok?

A CUDA magok az NVIDIA GPU-k belsejében található egyedi feldolgozó egységek, amelyek párhuzamosan hajtják végre az utasításokat. Mi a CUDA mag technológia alapjában? Képzeld el ezeket az egységeket mint apró munkásokat, akik egy időben ugyanannak a feladatnak különböző részeivel foglalkoznak.
Az NVIDIA 2006-ban vezette be a CUDA-t (Compute Unified Device Architecture), hogy a GPU erejét általános számítási feladatokra használja a grafikafeldolgozáson túl. A hivatalos CUDA dokumentáció átfogó technikai részleteket biztosít. Minden egység alapvető aritmetikai műveletek végez lebegőpontos számokon, tökéletes az ismétlődő számítások kezelésére.
A modern NVIDIA GPU több ezer ilyen egységet pakol egyetlen chipbe. A legújabb generációs fogyasztói GPU-ek több mint 21 000 magot tartalmaznak, míg az GPUs adatközpont, amely a Hopper architekturán alapul, akár 16,896 GPU-val rendelkezikEzek az egységek a Streaming Multiprocessors (SMs) által együtt működnek.
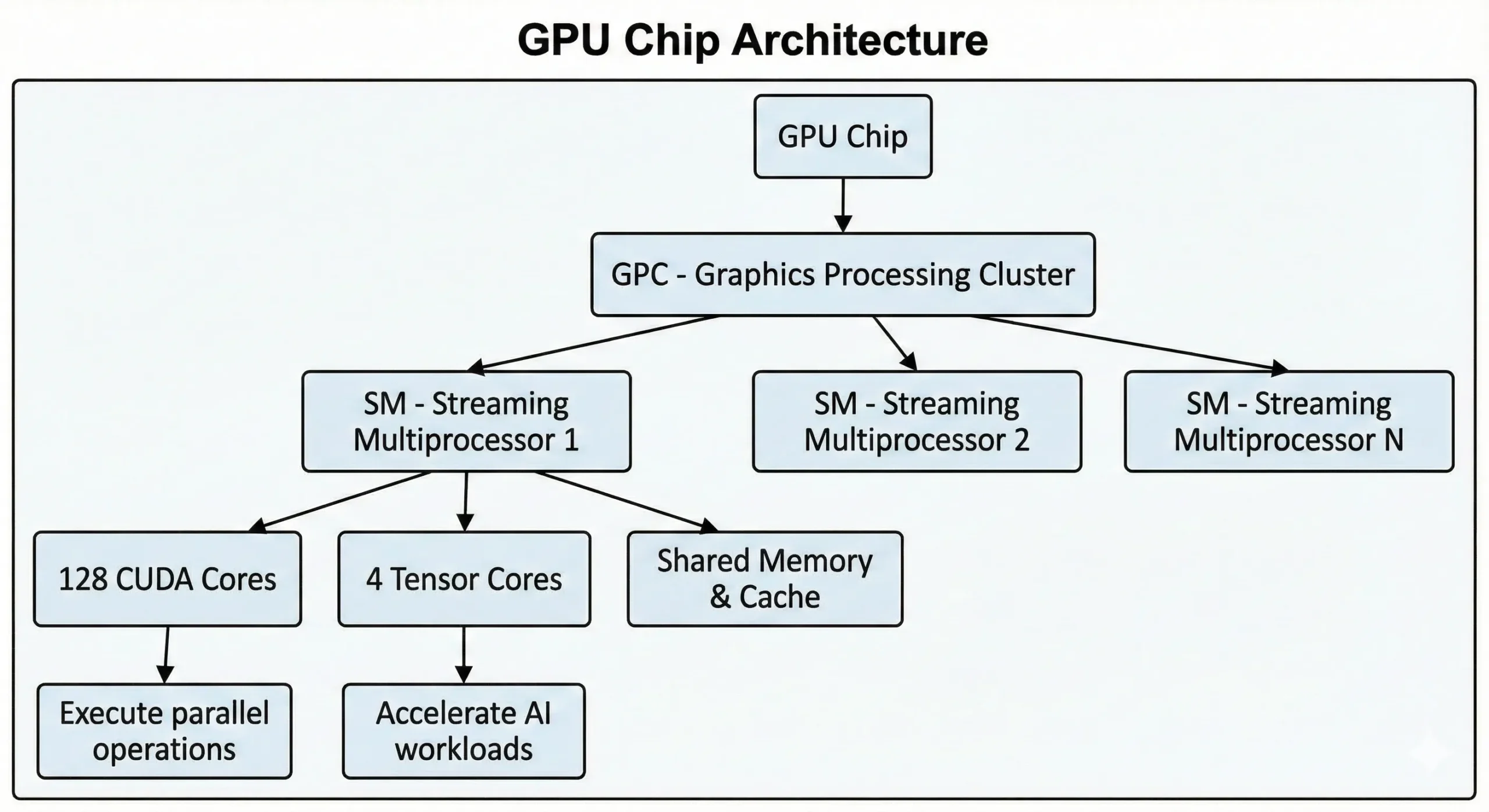
Az egységek SIMT (Single Instruction, Multiple Threads) műveleteket végeznek párhuzamos számítási módszerekkel. Egy utasítás egyszerre több adatponton kerül végrehajtásra. Neurális hálózatok betanításakor vagy 3D-s jelenetek megjelenítésekor több ezer hasonló művelet történik. Ezek egyidejű adatfolyamokra osztják fel a munkát, és egyszerre hajtják végre az egymást követő végrehajtás helyett.
CUDA magok vs CPU magok: Mi teszi őket különbözővé?

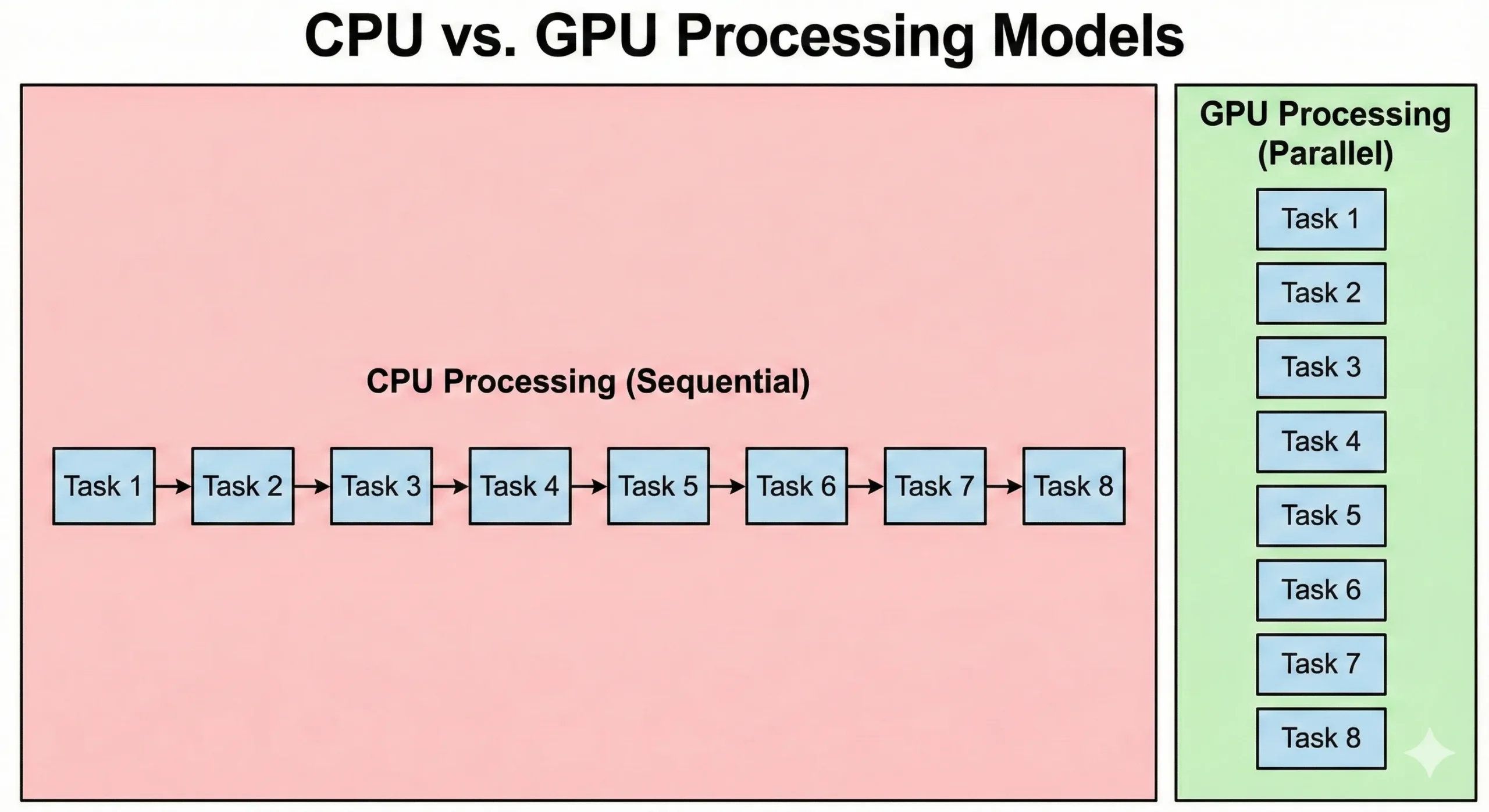
Az CPUs és GPUs gyökeresen eltérő módon oldja meg a problémákat. Egy modern CPU szerver 8-128+ maggal rendelkezhet, amelyek magas órajelen futnak. Ezek a processzok soros műveleteknél érnek el kiváló teljesítményt, ahol minden lépés az előzőtől függ. Hatékonyan kezelik az összetett logikát és az elágazásokat.
Az GPUs másik megközelítést követnek. Ezek az eszközök több ezer egyszerűbb CUDA magot tartalmaznak, amelyek alacsonyabb órajelen futnak. Az alacsonyabb sebesség mellett a párhuzamosság növeli az teljesítményt. Amikor 16 000 mag együtt dolgozik, az összes áteresztőképesség meghaladja a szabvány CPU lehetőségeit.
Az CPUs operációs rendszer kódot és összetett alkalmazáslogikát hajt végre. Míg az GPUs az áteresztőképességet helyezik előtérbe, a feladat inicializálásából és szinkronizálásából adódó terhelés magasabb latenciát eredményez. A párhuzamos grafikus feldolgozás az adatmozgatást helyezi előtérbe. Bár indításuk hosszabb ideig tart, nagyobb adatkészleteket dolgoznak fel gyorsabban, mint az CPUs.
| Funkció | CPU magok | CUDA magok |
| Számok chipenkénti alapon | 4-128+ mag | 2560–21760 magok |
| Órajel frekvencia | 3,0–5,5 GHz | 1,4–2,5 GHz |
| Feldolgozási stílus | Szekvenciális, összetett utasítások | Párhuzamos, egyszerű utasítások |
| A legjobb választás: | Operációs rendszerek, egyszálú feladatok | Matrix math, párhuzamos adatfeldolgozás |
| Késleltetés | Alacsony (mikroszekundum) | Magasabb (indítási terhelés) |
| Építészet | Általános célú | Repetitív számításokra optimalizálva |
A Virtual GPU (vGPU) és a Multi-Instance GPU (MIG) technológiák kezelik az erőforrások particionálását és ütemezését, hogy a processzorokat több felhasználó között osszák meg. Ez a konfiguráció lehetővé teszi a csapatoknak, hogy az időosztásos megosztás vagy dedikált hardverpéldányok segítségével maximalizálják a hardver kihasználtságát.
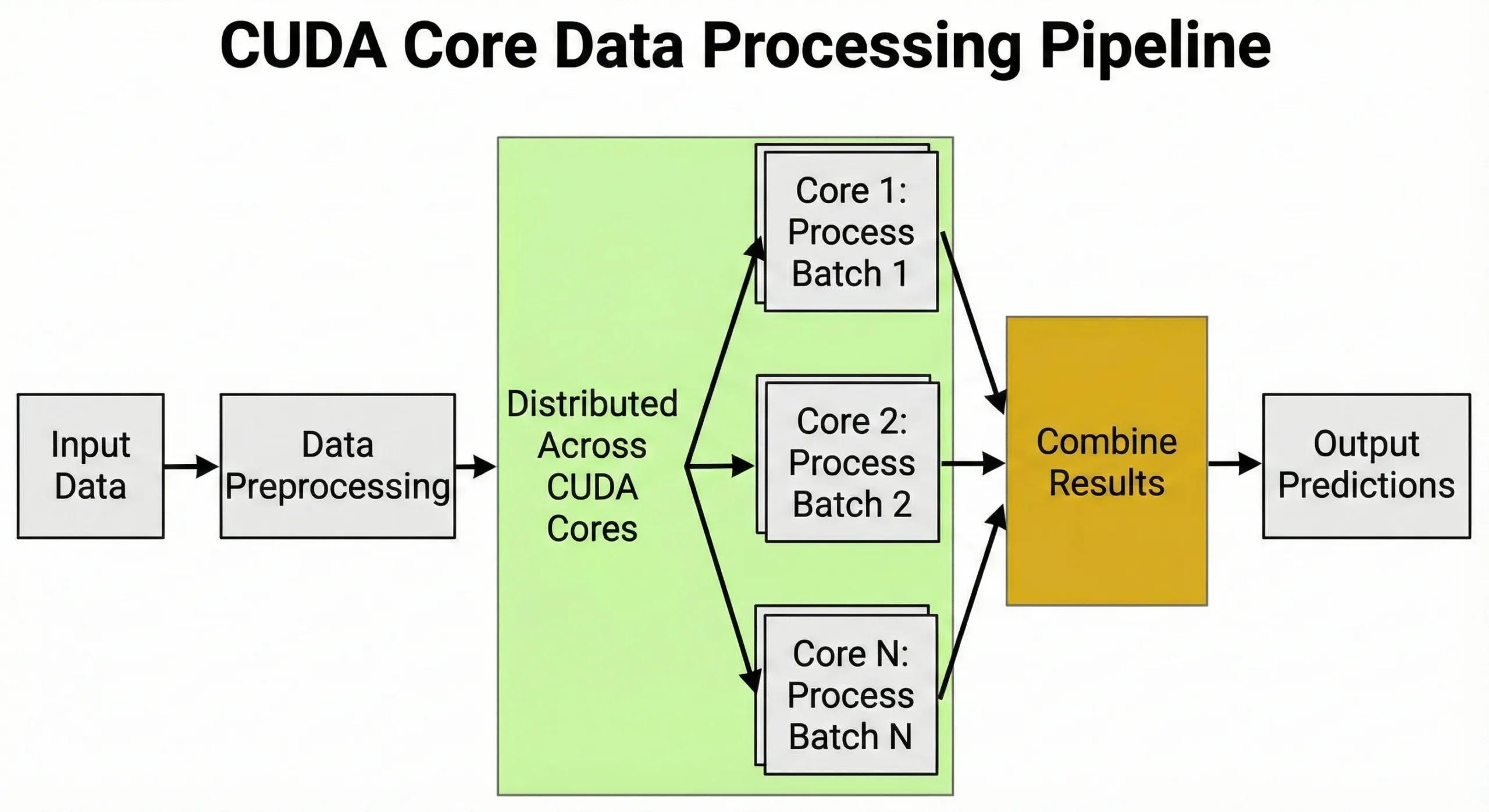
A neurális hálózatok tanítása milliárdnyi mátrixszorzást igényel. Az GPU 10 000 egységgel nem egyszerűen 10 000 műveletet hajt végre párhuzamosan – ezek helyett több ezer párhuzamos szálat kezel, melyeket "warp"-okba csoportosít a teljesítmény maximalizálása érdekében. Ez a hatalmas párhuzamosság az oka annak, hogy az AI fejlesztőknek ismerni kell ezeket az egységeket.
CUDA magok vs Tensor magok: A különbség megértése

Az NVIDIA GPU-k két típusú specializált egységet tartalmaznak, amelyek együtt működnek: szabványos CUDA magok és Tensor magok. Nem konkuráló technológiák; a munkaterhelés különböző részeit kezelik.
A Standard unitok általános célú párhuzamos processzorok, amelyek FP32 és FP64 számításokat, egész számok matematikáját és koordináta-transzformációkat kezelnek. Ez az alapvető CUDA-technológia az GPU számítások alapját képezi, és fizikai szimulációktól az adatelőfeldolgozásig mindenre képes speciális gyorsítás nélkül.
A Tensor magok olyan speciális egységek, amelyeket kizárólag mátrixszorzásra és AI feladatokra terveztek. Az NVIDIA Volta architektúrájában kerültek bevezetésre (2017), és az FP16 és TF32 pontosságú számításokra specializálódtak. A legújabb generáció az FP8-at is támogatja a még gyorsabb AI-következtetéshez.
| Funkció | CUDA magok | Tensor Magok |
| Célkitűzés | Általános párhuzamos számítástechnika | Mátrixszorzás AI-hoz |
| Pontosság | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Sebesség a mesterséges intelligenciához | 1x alapteljesítmény | 2-10x gyorsabb, mint a CUDA cores |
| Felhasználási esetek | Adatok előfeldolgozása, hagyományos ML | Mély tanulás képzése/következtetése |
| Elérhetőség | Az összes NVIDIA GPU | RTX 20 sorozat és újabb, adatközpont GPU-k |
A modern GPU mindkettőt egyesít. Az RTX 5090 21 760 standard egységet és 680 ötödik generációs Tensor magot kínál. Az H100 16 896 standard egységet párosít 528 negyedik generációs Tensor maggal a mélytanulás gyorsításához.
Neurális hálózatok tanítása során a Tensor magok végzik a nehéz számításokat az előre és visszafelé irányuló lépésekben. A standard magok az adatbetöltést, előfeldolgozást, veszteségszámítást és optimalizáló frissítéseket kezelik. Mindkét típus együtt működik, a Tensor magok felgyorsítva a számításigényes műveletek végrehajtását.
Hagyományos gépi tanulási algoritmusok, például véletlenerdők vagy gradiens növelés esetén a standard magok kezelik a munkát, mivel ezek nem használnak az olyan mátrixszorzási mintákat, amelyeket a Tensor magok felgyorsítanak. Azonban transzformátor modellek és konvolúciós neurális hálózatok esetén a Tensor magok drámai teljesítménynövekedést biztosítanak.
Mire Jó a CUDA Mag?

A CUDA magok olyan feladatokat hajtanak végre, amelyekhez nagyszámú azonos számítás párhuzamos végrehajtása szükséges. A mátrixműveleteket vagy ismétlődő numerikus számításokat magában foglaló bármely munka profitál ezekből az architektúrákból.
Mesterséges intelligencia és gépi tanulási alkalmazások
A mély tanulás mátrixszorzásokra támaszkodik tanítás és következtetés során. Neurális hálózatok tanítása közben minden előre irányuló lépés milliókat jelent szorzás-összeadás műveletek közül a súlymátrixokon. A visszaterjesztés még több milliókat adhoz hozzá a visszafelé irányuló lépés során.
A magok kezelik az adatok előfeldolgozását, képek tenzorrá alakítását, értékek normalizálását és kibővítési átalakítások alkalmazását. Az ezernyi feladat egyidejű kezelésének ez a képessége pontosan az, ami az GPUs fontos az AI-hoz.
A képzés során felügyelik a tanulási sebesség ütemezéseit, a gradiens számításokat és az optimalizáló állapot frissítéseit.
VPS esetén AI-beli következtetési műveleteknél ajánlási rendszerek vagy chatbotok futtatásakor egyidejűleg kezelik a kéréseket, több száz előrejelzést hajtanak végre egyidejűleg. Az útmutatónk az legjobb GPU mesterséges intelligenciához 2025 a különböző modellméretek számára működő konfigurációkat fedezi le.
Az H100 16 896 magja a Tensor magokkal kombinálva egy 7 milliárd paraméter modellt hetekben helyett hónapokban tud betanítani. Chatbotok valós idejű következtetéséhez, akik több ezer felhasználót szolgálnak ki, hasonló egyidejű végrehajtási teljesítményre van szükség.
Tudományos számítástechnika és kutatás
Kutatók ezeket a processzorokat molekuláris dinamika szimulációkhoz, klímamagyarázathoz és genomikai elemzéshez használják. Minden számítás független, ami ideálissá teszi őket az egyidejű végrehajtáshoz. Pénzintézetek Monte Carlo szimulációkat futtatnak milliós forgatókönyvekkel egyidejűleg.
3D renderelés és videógyártás
A sugárkövetés a 3D jelenetekben visszaverődő fényt számítja az egyes pixeleken keresztül független sugarak követésével. Míg a dedikált RT magok a traversálást kezelik, a standard magok a textúra mintavételezést és megvilágítást irányítják. Ez az elosztás a milliók sugár jelenetei sebességét határozza meg.
Az NVENC kezeli az H.264 és H.265 kódolást, míg a legújabb architektúrák (Ada Lovelace és Hopper) hardveres AV1-támogatást nyújtanak. A CUDA segítséget nyújt az effektusok, szűrők, méretezés, zajcsökkentés, színtranszformációk és pipeline-összeköttetés terén. Ez lehetővé teszi a kódolómotornak, hogy párhuzamos processzorokat használva gyorsabb videótermeléssel működjön.
3D renderelés a Blenderben vagy Mayában milliárdokat oszt fel felületi shader számítások között az elérhető magok között. A részecske rendszerek előnyösek, mivel ezer részecskét szimulálnak egyszerre kölcsönhatásban. Ezek a funkciók kulcsfontosságúak a csúcsszintű digitális kreatív munkához.
A CUDA Cores hogyan befolyásolják a GPU teljesítményét

A magszám nagyjából képet ad az egyidejű végrehajtási képességről, de a CUDA magok számokon túl való vizsgálatot igényelnek. Az órajel, memória sávszélesség, architektúra hatékonyság és szoftver optimalizálás mind fontos szerepet játszanak.
Az GPU 10 000 maggal 2,0 GHz sebességen más eredményeket nyújt, mint egy 10 000 1,5 GHz sebességűvel. Az alacsonyabb órajel azt jelenti, hogy minden mag másodpercenként több számítást végez el. Az újabb architektúrák jobban pakolnak munkát minden ciklus során jobb utasítás ütemezéssel.
Ellenőrizze, hogy az eszközt kihasználja-e, de ne feledje, hogy nvidia-smi a kihasználtság durva mutató. Az méri, hogy egy kernel mennyi ideig aktív, nem azt, hogy hány mag működik.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderPélda kimenet: 85%, 92% (85% aktív idő, 92% memóriavezérlő aktivitás)
Ha az GPU 60-70%-os kihasználtságot mutat, valószínűleg olyan felfelé irányuló szűk keresztmetszetek vannak, mint az CPU adatbetöltés vagy kis kötegméret. Azonban még 100%-os kihasználtság is megtévesztő lehet, ha kerneleid memória-kötöttek vagy egyszálúak. Az alapok teljes kihasználtságáról profilozók, például az Nsight Systems használatával követheti az "SM Efficiency" vagy az "SM Active" metrikákat.
A memória sávszélesség gyakran szűk keresztmetszet lesz, mielőtt a számítási képesség maximalizálódna. Ha az GPU gyorsabban dolgoz fel adatokat, mint amennyit a memória szolgáltat, a magok inaktívak maradnak. A H100 SXM5 modell 3,35 TB/s sávszélességet használ 16 896 magját táplálni. A PCIe verzió azonban ezt 2 TB/s-re csökkenti.
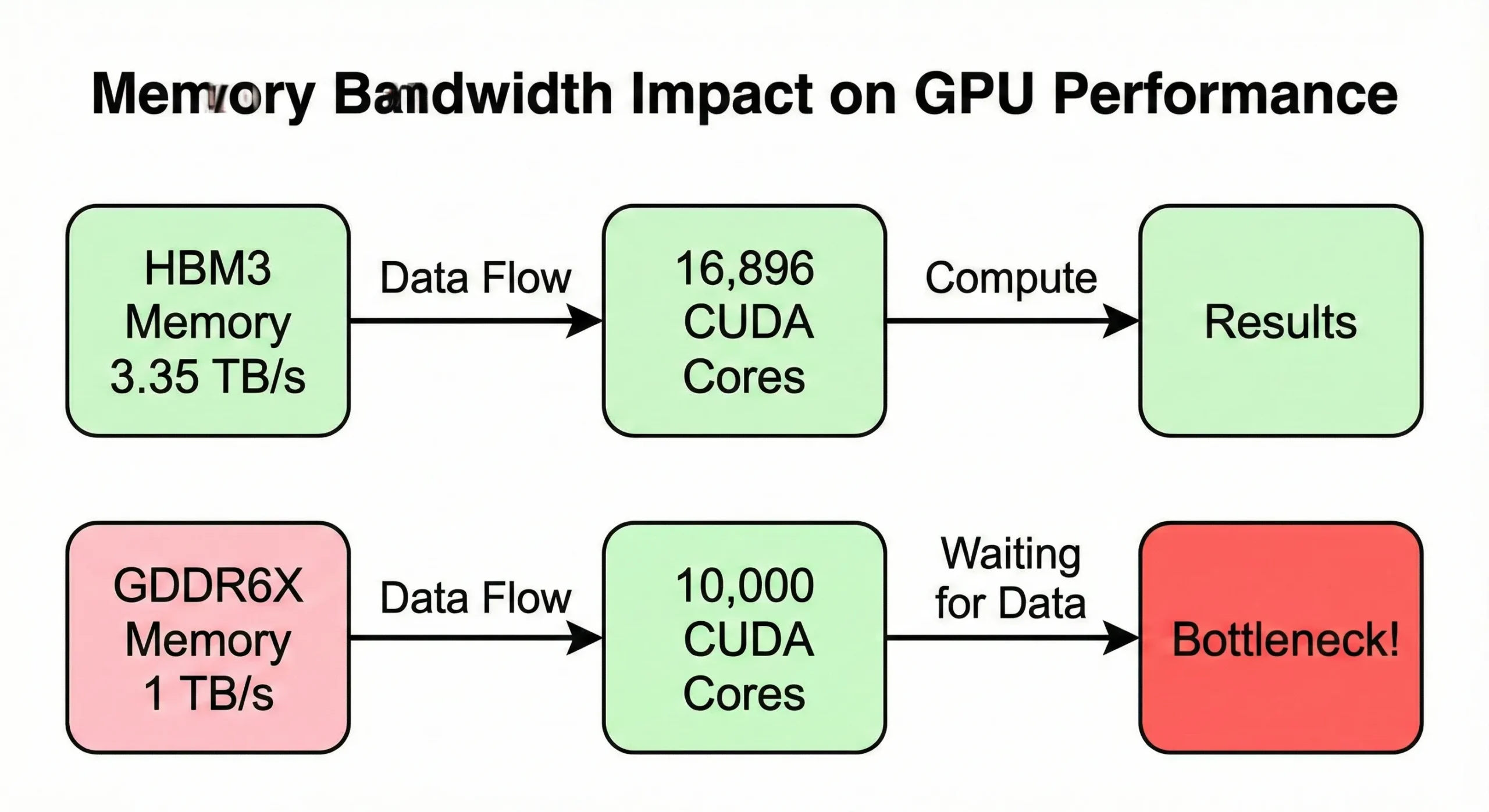
A fogyasztói GPU-k hasonló számokkal, de alacsonyabb sávszélességgel (körülbelül 1 TB/s) csökkent valós teljesítményt mutatnak memóriaigényes műveleteknél.
A VRAM kapacitása határozza meg a feladatok méretét. Legyenek azok FP16 súlyok egy 70B modell, a teljes tanítás több memóriát igényel. Figyelembe kell venni a gradienseket és optimalizáló állapotokat. Az ezek az állapotok gyakran meghározzák a lábnyomot, hacsak nem használsz kiszervezési stratégiákat
Az A100 80GB nagy átviteli sebességű következtetésre és finomhangolásra irányul. Közben az RTX 4090 24GB, gyakran 7B modellekhez megnevezve, meg tud lepően 30B+ paraméter modelleket futtatni, ha modern kvantálási technikákat, például INT4-et használsz. Azonban ha elfogy az VRAM, az CPU-GPU adattovábbítások letörik az átvitelt.
A szoftver optimalizálás határozza meg, hogy kódod valóban használja-e az összes maggal. A rosszul írt kernelek csak az elérhető erőforrások töredékét veszik igénybe. Az olyan könyvtárak, mint a cuDNN a mély tanuláshoz és az RAPIDS az adattudományhoz, nagymértékben vannak finomhangolva a kihasználtság maximalizálásához.
Több CUDA mag nem mindig jelent jobb teljesítményt

Az GPU beszerzése a legmagasabb magszámmal logikusnak tűnik, de pénzt pazarolsz, ha a magok túllépik más rendszerkomponenseket vagy a feladat nem skálázódik a magszámmal.
A memória sávszélessége jelenti az első korlátot. Az RTX 5090 21 760 egysége 1 792 GB/s memória sávszélességgel rendelkezik. A régebbi GPU-k kevesebb egységgel rendelkezhetnek, de arányosan magasabb sávszélességgel egységenként.
Az architektúra különbségei számítanak. Az újabb GPU 14 000 magra és 2,2 GHz-re 20 magra és 1,8 GHz-re felépített régebbi GPU-nél jobban teljesít, mivel óraciklus alatt több utasítást hajt végre. A kódodnak megfelelő párhuzamosítása szükséges ahhoz, hogy 20 000 magot hatékonyan kihasználj.
Miért Fontosak a CUDA Cores a GPU VPS Kiválasztásakor

A megfelelő CUDA core GPU konfiguráció kiválasztása az VPS-hez megelőzi az erőforrások pazarlását vagy projektközépen felmerülő szűk keresztmetszet problémákat.
Az H100 80GB memóriája képes 70B paraméteres modellek inferenciáját kezelni 4-bites kvantizációval. Teljes tanítás esetén azonban még a 80GB sem elég egy 34B modellhez, ha figyelembe vesszük a gradienseket és az optimizáló állapotokat. FP16 tanításnál a memóriaigény jelentősen megnő, gyakran több GPU közötti szétfejtésre lesz szükség.
A valós idejű előrejelzéseket végző inferencia-műveletek kevesebb egységet igényelnek, de a alacsony latencia előnyös számukra. A fejlesztési és prototipizálási munka jól működik középkategóriás GPUs-ekkel az algoritmusok teszteléséhez és a kód hibakereséséhez.
Az RTX 4060 Ti 4352 CUDA maggal tökéletes a prototípusozáshoz anélkül, hogy túlzottan drága hardverre költenél. Miután validáltad az ötleted, az GPUs szervereken futtathatsz teljes tanítási ciklusokat.
A renderelés és videomunka egy pontig skálázódik az egységekkel. A Blender Cycles renderere hatékonyan használja az összes elérhető erőforrást. Az GPU 8000-10000 egységgel 2-3x gyorsabban renderel jeleneteket, mint 4000-rel.
A Cloudzy-nál nagy teljesítményű megoldásokat kínálunk GPU VPS Hosting nehéz feladatokhoz. Válaszd az RTX 5090 vagy RTX 4090 konfigurációt gyors rendereléshez és költséghatékony AI inference futtatásához, vagy skálázz fel az A100s szerverre nagy méretű deep learning munkákhoz. Minden csomag 40 Gbps hálózaton működik adatvédelmi alapelvekkel és kriptovaluta-fizetési lehetőségekkel, azaz nyers teljesítményt kapsz a felesleges vállalati komplexitás nélkül.
Akár AI-modellek tanítása, 3D-jelenetekés renderelésevagy tudományos szimulációk futtatása – válassz olyan magszámot, amely az igényeidnek megfelelő.
Az ár számít. Az A100 6912 egységgel jóval olcsóbb, mint az H100 16896 egységgel. Sok alkalmazáshoz két A100 jobb ár-teljesítmény arányt nyújt, mint egy H100. A megtérülési pont attól függ, hogy a kódod több GPU-en skálázható-e.
Hogyan válasszuk meg a megfelelő CUDA magok számát
Válaszd meg a szervert a tényleges igényeid alapján, ne azt, amelyik a legjobb papíron néz ki.
Kezdje a jelenlegi munkájának profilozásával. Ha modelleket tanít helyi hardveren vagy felhő-instanciákon, ellenőrizze az GPU kihasználtság metrikáit. Ha az GPU aktuális értéke 60-70% kihasználtság körül mozog, nem használja ki teljesen az egységeket.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Ez az egyszerű teljesítménymérés megmutatja, hogy az GPU magok a várható átviteli sebességet nyújtják-e. Hasonlítsa össze az eredményeket az GPU modelljére vonatkozó közzétett referenciaértékekkel.
A frissítés nem segít. Előbb kezelned kell az olyan szűk keresztmetszeteket, mint a memória, a sávszélesség vagy az CPU szünetei. Ezután becsüld meg a memóriaigényt a modell méretének bájtban való kiszámításával és az aktivációs memória hozzáadásával.
Adja össze a batch méretét, a réteg kimeneteit és az optimizáló állapotait. Az összesen szükséges memóriának el kell férnie a VRAM-ben. Miután tudja, mennyi memória szükséges, ellenőrizze, mely GPU-k felelnek meg ennek a követelménynek.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Tekintsük az időkeretet. Ha órák alatt kell eredményt elérned, több egységre költs. Az olyan képzések, amelyek napokat vehetnek igénybe, kisebb GPU-eken is gond nélkül futnak, csak a befejezés arányosan tovább tart.
Az óradíj szorozva a szükséges órák számával adja meg a teljes költséget, így néha a lassabb GPU-k összességében olcsóbbak. A skálázási hatékonyságot számos keretrendszer segítségével tesztelje, amelyek teljesítménymérési eszközöket biztosítanak, amelyek az átviteli sebesség változásait mutatják.
Ha az egységek megduplázása csak 1,5-szeres gyorsulást hoz, az extra költség nem éri meg. Keress olyan konfigurációkat, ahol az ár-teljesítmény arány a legjobb.
| Terhelés típusa | Ajánlott magok | Például GPU-k | Megjegyzések |
| Modell fejlesztés és hibakeresés | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Gyors iteráció, alacsonyabb költségek |
| Kis léptékű AI képzés (<7B paraméter) | 6,000-10,000 | RTX 4090, L40S | Megfelel fogyasztóknak és kis vállalatoknak |
| Nagy léptékű mesterséges intelligencia képzés (7B-70B paraméter) | 14,000+ | A100, H100 | Adatközponti GPU szükséges |
| Valós idejű következtetés (nagy áteresztőképesség) | 10,000-16,000 | RTX 5080, L40 | Egyensúly a költség és a teljesítmény között |
| 3D renderelés és videó kódolás | 8,000-12,000 | RTX 4080, RTX 4090 | Skálázódik az összetettséggel |
| Tudományos számítás és HPC | 10,000+ | A100, H100 | FP64 támogatásra van szükség |
Népszerű VPS GPU-k és azok CUDA magok száma

A különböző GPU szintek különböző felhasználói csoportokat szolgálnak ki. Mi az GPUaaS? Ez GPU-as-a-Service, ahol az olyan szolgáltatók, mint az Cloudzy, igény szerinti hozzáférést biztosítanak ezekhez a nagy teljesítményű NVIDIA GPUokhoz anélkül, hogy saját maga kellene megvásárolnia és karbantartania a fizikai hardvert.
| GPU modell | CUDA magok | VRAM | Memória sávszélesség | Építészet | Legjobb a következőhöz |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1,792 GB/s | Blackwell | Zászlóshajó munkaállomás, 8K renderelés |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | Csúcsminőségű AI, 4K renderelés |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/s | Hopper | Nagyszabású MI-képzés |
| H100 PCIe | 14,592 | 80GB HBM2e | 2000 GB/s | Hopper | Vállalati AI, költséghatékony adatközpont |
| A100 | 6,912 | 40/80 GB HBM2e | 1,555–2,039 GB/s | Ampere | Közepes szintű mesterséges intelligencia, bizonyított megbízhatóság |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Játékok, középkategóriás AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Többfeladatos adatközpont |
A fogyasztói RTX kártyák (4070, 4080, 4090, 5080, 5090) kreatívoknak és játékosoknak készültek, de AI-fejlesztéshez is jól használhatók. Erős egymagos teljesítményt nyújtanak az adatközpont-kártyáknál jelentősen alacsonyabb áron.
A VPS szolgáltatók gyakran készleteznek ezeket a költségvetés-tudatos felhasználók számára. Az adatközpont kártyák (A100, H100, L40) a megbízhatóságot, az ECC memóriát és a többszörös GPU-skálázást helyezik előtérbe. A 24/7-es működésre és a fejlett funkciók támogatására vannak kialakítva.
A Multi-Instance GPU (MIG) lehetővé teszi, hogy egy GPU-t több izolált instanciára ossz fel. Az A100 továbbra is népszerű marad az újabb lehetőségek ellenére is, kiegyensúlyozott paraméterei miatt.
Az NVIDIA magok, a memória és az ár egyensúlya teszi ezt a biztonságos választássá a legtöbb éles AI-műveletnél. Az H100 2,4-szeresen több egységet kínál, de jelentősen drágább.
Összegzés
A párhuzamos feldolgozási motorok teszik lehetővé a modern mesterséges intelligenciát, a renderelést és a tudományos számítástechnikát. Ha megérted, hogyan működnek, és hogyan kapcsolódnak a memóriához, az órajel-sebességhez és a szoftverhez, könnyebben választhatsz GPU VPS konfigurációkat.
Több magot akkor érdemes használni, ha a munka jól párhuzamosítható és az olyan összetevők, mint a memória-sávszélesség, lépést tudnak tartani. De ha a szűk keresztmetszetek máshol vannak, az összes mag vadásza csak pénzt pazarol el.
Kezdje a tényleges műveletek profilozásával, azonosítsa, hol telik az idő, majd az GPU specifikációit az igényeihez igazítsa anélkül, hogy felesleges kapacitást vásárolna.
Az AI-fejlesztés nagy részéhez 6000-10000 egység adja a legjobb egyensúlyt a költség és teljesítmény között. Termelési rendszereknél, amelyek nagy modellek tanítására vagy magas áteresztőképességű következtetésre használnak, 14000+ egységes GPUs, például a H100 szükséges.
Renderelés és videómunkák hatékonyan skálázódnak körülbelül 16000 egységig, ezt követően az memóriasáv szélessége válik a korlátozó tényezővé.


