GPU 監視ソフトウェアは、「GPU の調子が悪い」という曖昧な表現を、「ホットスポットが急上昇し、クロックが低下し、VRAM が満杯になった」という直接的で明確な説明に変換することができるツールです。
このガイドでは、AI タスク、ゲーミングオーバーレイ、長時間のワークステーションセッション用に使用できるツールを紹介し、遅延、スタッター、クラッシュを診断するのに役立つ GPU メトリクスを示します。
最後に、自分の作業方法に合った GPU 監視ソフトウェアのセットアップが完成します。一般的な 4 つのユースケース用にコピー可能なスタックも得られるので、記事を何度も検索する必要がなくなります。
クイックアンサー: ユースケース別トップ GPU 監視ソフトウェア
実際の作業方法に合った短いリストが必要なだけなら、これらから始めましょう。実際には、最適な GPU 監視ソフトウェアスタックは通常、複数のツールを組み合わせたものです。迅速なチェック用に 1 つ、オーバーレイやログ用に 1 つ、履歴またはアラート用に 1 つです。
高速マップはこちらです:
| ユースケース | 推奨スターティングスタック | 内容 |
| AI トレーニング、推論、HPC ジョブ | nvidia-smi (NVIDIA) または AMD SMI (AMD) + ログ記録/エクスポーター | 高速チェック、スクリプト可能なログ、簡単なアラート |
| Windowsでのゲーミング | MSI Afterburner + RTSS + フレームタイムキャプチャツール | オーバーレイとスタッター対低 FPS の証拠 |
| Linux上のゲーミング | MangoHud + ターミナルチェッカー (nvtop) | 軽量オーバーレイと プロセス別サニティチェック |
| ワークステーション (3D / ビデオ / CAD) | HWiNFO ログ + シンプルなストレステスト | 共有可能な長期ログ、再現可能な再現環境 |
| 共有 GPU マシン | nvtop (Linux) + エクスポーター/ダッシュボード | プロセス別 VRAM 可視性 |
ここからは、GPU モニタリングソフトウェアをあなたのデータ消費方法に合わせることが主な作業になります。画面表示、ログ、またはダッシュボードのいずれかです。
このガイドの対象者
実際にマシンをデバッグした経験のある人のように書きます。というのも、経験上、読者によって必要な GPU ツールは異なることを知っているからです。たとえ同じ GPU を見ていても。
対象とする4つのセットアップをここに挙げます。
- Model Builder (AI/ML) VRAM の余裕、安定したクロック、スロットリング、「ジョブが一晩中止まらずに実行されたか」に関心があります。
- 競技ゲーマー/ストリーマー フレームタイム、オーバーレイの安定性、ドライバ更新後の性能低下に関心があります。
- ワークステーションユーザー (3D/ビデオ/CAD) ログ、再現可能なクラッシュ、熱対電源対ドライバの動作の特定に関心があります。
- GPU マシンを運用する管理者 アラート、トレンドグラフ、キャパシティプランニング、障害の早期検出に関心があります。
自分がどのグループに該当するかわかれば、あなたに合った GPU モニタリングソフトウェアを簡単に選べます。
GPU モニタリングソフトウェアの選び方
パフォーマンスモニタリングアプリの多くは、実際に1週間使ってみるまで似ているように見えます。主な違いは、各アプリが必死に宣伝する魅力的な「機能」ではなく、通常は出力と信頼性にあります。
GPU モニタリングソフトウェアをすばやく選ぶのに役立つ3つの質問を提示します。
- オーバーレイ、ログ、またはその両方が必要ですか。
ゲーマーはオーバーレイを望みます。AI およびワークステーション作業は通常ロギングが必要です。管理者はログとアラートを望みます。 - プロセス単位の可視性が必要ですか。
マシンを共有している場合 (ラボ、スタジオ、リモートサーバー)、プロセス単位の VRAM がしばしば最初に確認することです。 - 履歴とアラートが必要ですか。
ジョブが夜間に実行される場合、「後で確認します」では不十分です。グラフとアラートが必要です。
実践的に保つため、ガイドの残りは GPU メトリクスを最初に整理し、次に各ユースケースに適したツールスタックで構成されています。
優先すべき GPU メトリクス
多くの GPU モニタリングソフトウェアは、たくさんの数値を提供します。本当に役立つ GPU モニタリングソフトウェアは、動作を説明する特定の少数の数値を提供します。GPU メトリクスを、その判断に役立つもので分類します。
熱と スロットリング メトリクス
これらの GPU メトリクスは「10分は高速だったが、その後は遅くなった」という状況を説明します:
- GPU温度
- ホットスポット温度 (最初にスパイクすることが多い)
- メモリ温度/ジャンクション温度 (長時間のAI実行やレンダリングで特に重要)
- ファン速度 (ラップトップ設定の問題や不適切なファンカーブを見つけるのに役立つ)
安定性を改善しようとしているなら、これらをログに記録してください。単一のスナップショットではほぼ情報が足りません。
電力、クロック、リミット
これらの GPU メトリクスはダウンクロックと不安定なパフォーマンスを説明します:
- ボード電力消費
- コアクロックとメモリクロック
- 電力リミット/パフォーマンス状態 (ツールが公開している場合)
実際のデバッグでは、電力とクロックは基本的な「GPU 使用率 %」よりはるかに明確な全体像を示します。
VRAM とメモリプレッシャー
これらの GPU メトリクスはスタッター、OOM エラー、典型的な「ランダムな」速度低下を説明します:
- VRAM 使用量/合計
- メモリコントローラアクティビティ (帯域幅リミットを見つけるのに役立つ)
- システム RAM プレッシャー (VRAM がシステム全体を引きずり下ろすことがあるため)
AI では VRAM がハードリミットになることが多いです。ゲームでは VRAM プレッシャーがフレームタイムのスパイクとして最初に現れることがよくあります。
フレームタイムとフレームペーシング メトリクス
ゲームとストリーミングでは、FPS だけでは信頼できません。フレームタイムが重要なメトリクスです。滑らかさ、または滑らかさの欠如を追跡するからです:
- フレームタイム (ms)
- 1% 低 / 0.1% 低 (比較に便利)
- GPU の負荷 vs CPU の負荷 (GPU のボトルネックと CPU のボトルネックを区別するのに役立ちます)
ゲーミング向けのパフォーマンスモニタリングアプリがフレームタイムキャプチャパスを含めることが多いのはそのためです。基本的なメトリクスを押さえたところで、各ワークフロー向けの最適な GPU モニタリングソフトウェアスタックについて話を進めることができます。
AI、トレーニング、サーバー向け GPU モニタリングソフトウェア

AI モニタリングはターミナルでの簡単なセットアップと迅速なチェック、長時間実行のログとアラート機能で構成されています。このようなケースでは、CLI に対応してメトリクスをエクスポートできる GPU モニタリングソフトウェアが必要です。
NVIDIA: 迅速なチェックとスクリプト可能なログのための nvidia-smi
NVIDIA システムでは、 nvidia-smi は通常、最初に実行されるコマンドです。ドライバーに付属しており、NVML 経由のモニタリングと管理用に設計されています。
公式ドキュメントはこちら: NVIDIA システム管理インターフェース (nvidia-smi).
シンプルな「ログして後で確認」のアプローチを望む場合(実際のところ、これで問題が解決することは珍しくありません)、このパターンはかなり信頼できます:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
これは基本的な GPU モニタリングソフトウェアの動作で、タイムスタンプ、主要な GPU メトリクス、スクリプトと相性の良い出力が含まれています。
AMD: ROCm と HPC ノード向け AMD SMI
AMD Linux コンピュートノードでは、AMD SMI は最新のモニタリング・管理インターフェースであり、AMD は HPC コンテキストでの統一されたモニタリング・制御ツールセットとしてドキュメント化しています。
公式ドキュメントはこちら: AMD SMI ドキュメント.
環境が AMD 中心の場合、AMD SMI は他のツールが通常構築する基礎となる GPU モニタリングソフトウェアです。
プロセス単位の可視性: 共有 GPU 向け nvtop
共有マシンで VRAM が「謎のまま」いっぱいになってしまう経験があれば、プロセス単位の可視性は時間の短縮につながります。Linux では、 nvtop 正確にそのためにポピュラーです。「VRAM を使用しているのは誰か?」が明確になるからです。AMD/Intel では、プロセス単位のスタッツのために最新のカーネルが必要な場合があります。
混在したチームでは、多くの場合、 nvtop を並行して実行する人を見かけます。 nvidia-smi または AMD SMI と一緒に。シンプルな組み合わせで多くの推測を避けられるため、強くお勧めします。
ハードウェア選択を見落とさないでください!
モニタリングはVRAMの上限を解決するわけではありません。上限を可視化するだけです。GPUティアにワークロードをマッピングしている場合は、こちらのガイドが役立ちます。 2025年の機械学習に最適なGPU VRAMと帯域幅を、後でログやダッシュボードで読む方法と同じ視点でフレーミングするため、有用なリファレンスになります。
サーバー形式のGPUモニタリングソフトウェアを制御下に置いたら、次のステップはオーバーレイとフレームタイムです。理由は インタラクティブなワークロードは異なる動作をするためです。.
ゲームとストリーミング向けのGPUモニタリングソフトウェア

ゲーミングは、GPUツールに関して最も強い意見が出る領域です。主な理由は、オーバーレイが最悪のタイミングで機能しなくなるからです。ゲーミング向けには、シンプルなオーバーレイと再現可能なフレームタイム キャプチャが必要です。
Windowsのオーバーレイ用MSI Afterburner + RTSS
このコンビネーションは人気があります。なぜなら、使用率、クロック、VRAM、温度、フレームタイム、ファン速度など、あなたが気にするGPUメトリクスで構成した、クリーンなオーバーレイを作成できるからです。
コミュニティスレッドで繰り返し指摘される重大な警告は、偽のダウンロードサイトです。MSI公式のAfterburnnerページでは、正規のダウンロードは msi.com と Guru3Dから入手する必要があることが明記されており、現在のリリース情報(4.6.6 final、2025年10月リリース)も記載されています。
オーバーレイの問題も注意が必要です。例えば、RTSSはゲームによって動作したり失敗したりします。特に最新のレンダリングパスでは、オーバーレイが Vulkanでは表示されるがDX12では表示されない ケースが報告されており、アップデート後に消える場合もあります。
ただし、これはあなたのエラーではなく、オーバーレイがゲームとドライバスタックの変更にフックするときに起こることです。
安定したベースラインオーバーレイが必要な場合は、シンプルに保ってください。
- フレームタイム
- GPU使用率
- 使用済みVRAM
- GPU温度
スロットリングを積極的にデバッグしている場合のみ、電力とクロックを追加してください。
フレームタイムキャプチャと「スタッター」
フレームタイムグラフをキャプチャできるパフォーマンスモニタリングアプリが大きく役立ちます。平均FPSは良好に見えても、フレームペーシングは最悪の場合があります。フレームタイムグラフはその混乱をすぐに解決します。
多くのゲーミングベンチマークワークフローはPresentMonに依存しており、 NVIDIA ドキュメント そのFrameViewアナリティクスはフレームレートとフレームタイムのキャプチャにPresentMonを使用しています。
すべてのゲームをベンチマークする必要はありません。フレームタイムキャプチャは比較に最も有用です。例えば、ドライバアップデート前後、リミッター変更前後、設定変更前後など。
Linux向けMangoHud
Linuxでは、MangoHudは軽量でSteam/Protonセットアップとクリーンに統合されるため、よく推奨されます。最も一般的な不満は、ハイブリッドラップトップセットアップでセンサーが不足しているか、読み値が奇妙な場合です。
実際には、MangoHudを nvtopのようなターミナルチェッカーと簡単にペアリングできます。また、GPUモニタリングソフトウェアが、1つの巨大なアプリではなく、小さなスタックとしてはるかに効果的に機能する良い例です。
ゲーミングから次の段階は、ワークステーション監視です。ログと再現可能なトラブルシューティングが最優先だからです。
高速NVMe VPSホスティングでラグのないゲームサーバーを。
ゲーミング用VPS
GPU ワークステーションと プロ向けアプリケーション用 監視ソフトウェア
ワークステーション監視はセキュリティ担当者のような、ライブオーバーレイを見張る仕事ではなく、「どうなったのか、再現できるのか」に答える作業です。
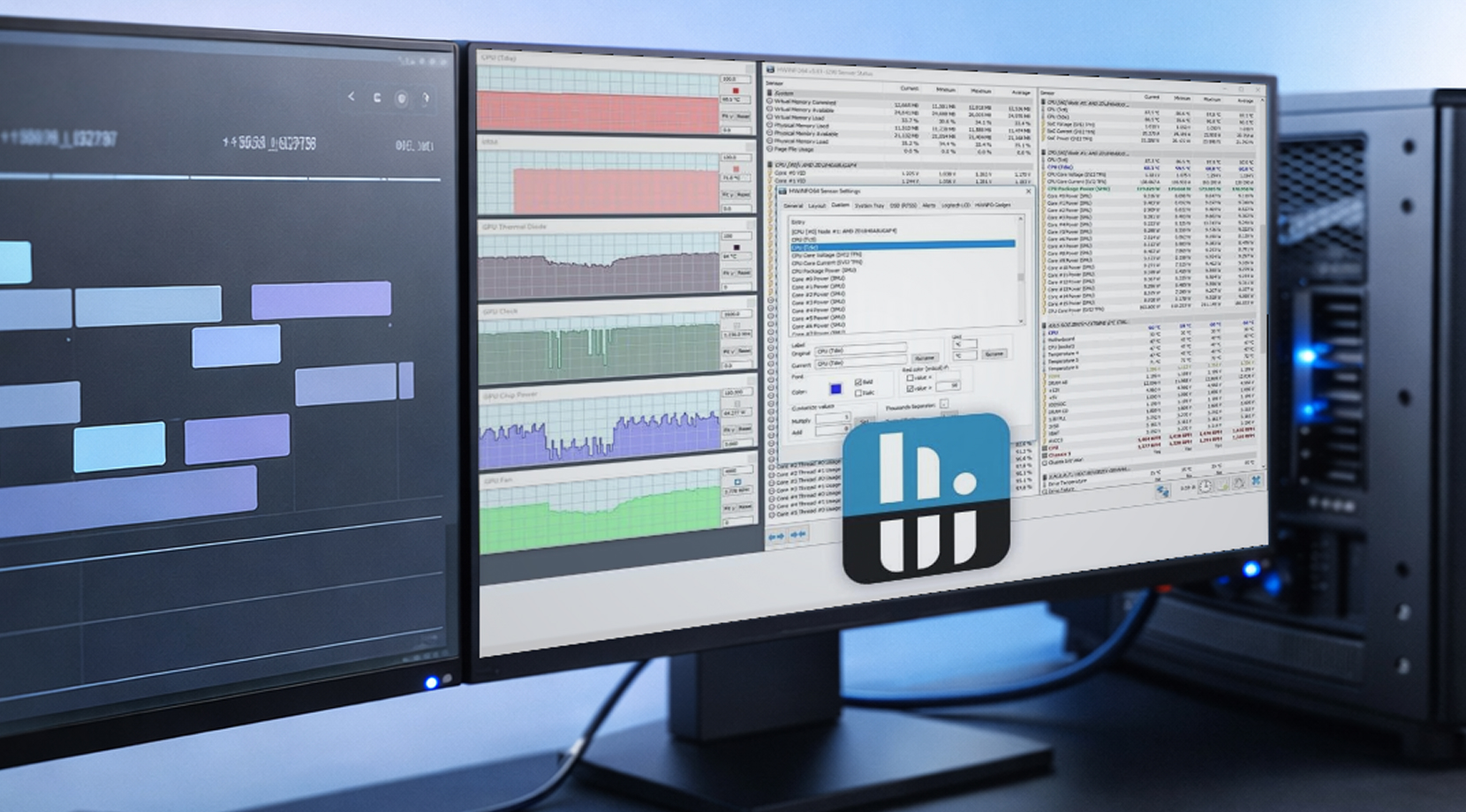
Windows での HWiNFO ログ記録
HWiNFO はワークステーション業界で人気です。センサーカバレッジが深く、ログが共有しやすいからです。タイムスタンプ付きのシンプルな CSV ログなら、曖昧なレポートを実際に問題解決に使える情報に変えられます。
GPU の安定性ログを構築するなら、まずこれらの GPU メトリクスから始めてください。
- GPU 温度とホットスポット
- 使用済みVRAM
- ボード電力
- コアクロック
- CPU パッケージパワー (プラットフォームパワーリミットが問題になることがあるため)
「説明に十分なデータ」セットです。すべてのセンサーをログすると、ファイルが読みづらくなるからです。
GPU-Z で素早く「これ何の GPU?」確認
GPU-Z は高速で的を絞っているため有用です。混合ハードウェアのチームでは、メニューを掘り下げずに GPU モデル、ドライバーの基本、ライブセンサーを確認する最速の方法です。
ストレステスト : ログ記録がなければ意味がない
ストレステストはクラッシュの再現に役立ちますが、実行中に GPU 監視ソフトウェアがログを記録している場合だけです。ログがなければ「また落ちた」という記録だけで、タイムラインはほぼありません。
ここまでくると、ほとんどの人が同じ問題にぶつかります。オーバーレイが表示されない、電力読み取りがおかしい、ログが読みづらいなど。これらに直接対処しましょう。
GPU 監視ソフトウェアでよくある問題とその簡単な解決策

ほとんどの問題は少数のパターンに分かれます。つまらない部分を素早く解決するため、私がまず試す修正方法です。
ゲームでオーバーレイが表示されない
モダンなゲームではオーバーレイが消えるのは、ゲーム固有のフック問題や、アンチチート・アンチタンパー機構との衝突が原因であることがよくあります。
よく効く対策。
- RTSS を更新してゲーム固有のプロファイルをリセット
- ゲームプロファイルの「アプリケーション検出レベル」を上げる
- ゲームがサポートしていれば別の API を試す
- タイトルがサードパーティ製オーバーレイをブロックする場合は、組み込みオーバーレイにフォールバック
すべてのゲームが対応するわけではなく、1つの頑固なタイトルに何時間も費やす価値はありません。
奇妙な電力測定値(0W、フラットライン、センサー欠落)
ノートパソコンやハイブリッド構成で、アクティブな GPU が変わる場合に頻繁に発生します。その場合は、別のツールで検証してください。例えば nvidia-smi (NVIDIA)または AMD SMI(AMD)は、「GPU が実際にアクティブか」を確認するのに適しています。
ログが多すぎる
オーバーサンプリングが通常の原因です。ほとんどのトラブルシューティングでは、1~5秒の間隔で十分です。長時間の AI ジョブの場合でも 5 秒で問題ありません。間隔を短くするとファイルサイズが膨らみ、グラフが見づらくなります。
基本的な部分が済めば、次は遠隔監視が論理的な次のステップです。多くの GPU ワークフローが今、マシン外で実行されているからです。
遠隔 GPU 監視と実用的なクラウドオプション
リモートワークは「良い GPU 監視ソフトウェア」の意味を変えます。常にマシンを見ているわけではないので、素早く実行できるチェックと、後で確認できる履歴が必要です。
クリーンな遠隔セットアップは通常、このようになります。
- CLIチェック(nvidia-smi またはAMD SMI)
- 後でプルできるログファイル
- アラートが必要な場合はエクスポーター、ダッシュボード
ローカルハードウェアが進捗を妨げている場合(VRAM の制限、単一の GPU を時間共有している、プロジェクトごとにクリーンな環境が必要)、GPU VPS でワークロードを実行することが、最もシンプルな前に進む方法になります。
Cloudzy GPU VPS

AI、ゲーム、レンダリングのワークフローに対応する遠隔 GPU 時間が必要な場合は、当社の Cloudzy GPU VPS は RTX 5090、A100、RTX 4090 などの NVIDIA オプション、NVMe ストレージ、フルルートアクセス、最大 40 Gbps 接続、DDoS 保護、および 99.95% のアップタイム目標を含みます。
監視の観点からは、GPU 監視ソフトウェアを SSH で実行したり、長時間のジョブ用に GPU メトリクスを記録したり、履歴とアラーティングが必要な場合はダッシュボードを追加したりできるため、通常のマシンのように動作します。
GPU インスタンスと CPU のみのセットアップのどちらかで迷っている場合は、当社の GPU VPSとは と GPU対CPU VPS ワークロード別に実用的な違いを説明しています。
遠隔監視に対応できたら、最後のステップはそれらすべてをコピー可能なスタックにまとめることです。
ペルソナ別のコピー可能なスタック
ワークフロー全体を書き直すことなく導入できる、分かりやすいスタックです。これらは素晴らしい出発点となり、後で特定のニーズに合わせてカスタマイズできます。
- モデルビルダー (AI/ML): GPU 監視ソフトウェア(経由 nvidia-smi または AMD SMI)、シンプルな CSV ログ、およびジョブが無人で実行される場合はエクスポーター、ダッシュボード。
- 競技ゲーマー、ストリーマー: GPU 監視ソフトウェアオーバーレイ(Afterburner + RTSS 経由)、フレームタイムキャプチャツール(比較用)、最小限のオンスクリーンメトリクスセット。
- ワークステーション ユーザー HWiNFO ログを使用した GPU 監視ソフトウェア、高速な識別チェック用 GPU-Z、および実行をログに記録できる場合のストレステストのみ。
- GPU マシンの管理: GPU 監視ソフトウェアサービス: エクスポーター + ダッシュボード + アラート、共有ボックス用のプロセスごとの可視性 (nvtop) 対応。
このガイドから 1 つだけ取り上げるなら、これです: データが必要な場所 (オーバーレイ、ログ、ダッシュボード) に基づいて GPU 監視ソフトウェアを選択し、実際に使用できる十分な大きさのメトリクスセットを保つこと。