
NVIDIAがDLSS 4で 16ピクセルのうち15ピクセル をAIで生成する様子を見せたとき、観衆の大部分は進歩を見なかった。彼らが見たのは「偽のフレーム」と「AIスロップ」だった。それらしく見えても、ある瞬間に破綻する生成されたディテール、しかも置き場所を間違えたポリゴンをデバッグするようにはデバッグできない代物だ。あるコミュニティ投票についてのPCGuideの報道によると、回答の54%が単なる「ノー」だった。対象は DLSS 5の見た目で、批判の多くは顔の表現と「AIスロップ」反応に向けられていた。その反応は真剣に受け止める価値があり、後ほど立ち返る。
だが、それらの議論すべてに共通するより大きな問題は、「ニューラルレンダリング」という言葉が少なくとも5つの異なるものに使われていることだ。アップスケーリング、AI生成フレーム、写真からのシーン再構成、ソーシャルメディアで見かけるNeRFやGaussian Splattingのデモ、そして単一のネットワークで画像全体をレンダリングする研究システムである。人々は異なるレイヤーを指しながら同じ言葉を使うため、議論がかみ合わない。NVIDIAのジェンスン・フアンはこの転換を「グラフィックスのGPTモーメント」と呼んだ。それが主張だ。有用な問いは、その下で何が起きているかである。
全体を理解可能にする一本の筋はこれだ。 GPUは画像を計算する代わりに、ますますそれを予測するようになっている。 従来、GPUはジオメトリ、ライティング、マテリアルをシミュレートして全ピクセルを計算する(ラスタライズ、そして最近ではその上にレイトレーシングを重ねる)。ニューラルレンダリングは、何が 計算され 、何が学習済みネットワークによって 予測 されるかを変える。その一点の区別こそ本記事の背骨だ。読み終える頃には、どの技術もスペクトル上に位置づけられ、どれがリアルタイムで、どのハードウェアで動くかを知り、今日のゲームに実際に入っているものと、研究論文やGTCデモにすぎないものを見分けられるようになる。これは地図であって、ハウツーではない。個々の技術の深い仕組みは、それぞれ別の記事になる。
短いバージョン
- ニューラルレンダリングはスペクトルであって、DLSSの同義語ではない。 それはシーン再構成研究(NeRF、Gaussian Splatting)、レンダリングパイプラインの内部に位置するリアルタイム構成要素(DLSS、Ray Reconstruction、ニューラルラディアンスキャッシュ)、そしてフレームが一度も持たなかったディテールを生み出す生成手法までを網羅する。
- 一本の筋は「計算する代わりに予測する」だ。 各技術は、パイプラインの高価な計算ステージを、学習した結果を予測するネットワークで置き換える。
- 今日出荷されるものの大半はハイブリッドだ。 アップスケーリング、フレーム生成、AIデノイズは今やリアルタイムゲームで動いており、一方でニューラルテクスチャ圧縮やニューラルシェーダーは開発者向けツールキットを通じて登場しつつある。ネットワークで画像全体を描く完全なニューラルレンダラーは、いまだ研究段階だ。
- これはNVIDIAだけの話ではなく、ベンダーをまたぐ動きになりつつある。 シェーダーレベルのMLに関するMicrosoftのDirectXの取り組みは、Shader Model 6.9のCooperative Vectorsで始まり、Shader Model 6.10でのより広範な線形代数サポートへ向かっており、エンジンが一社のスタックを超えてニューラル方式のシェーダーワークロードを狙う道を開いている。
なぜ「ニューラルレンダリング」は5つの異なるものを意味するのか
ニューラルレンダリングとは、GPUが本来ならゼロから計算するはずの画像の一部(ピクセル、ライティング、マテリアル、さらにはフレーム全体)を、ニューラルネットワークで予測する一群の手法である。 Tewariらのサーベイ はこれを、フォトリアルな出力のために古典的コンピューターグラフィックスと深層生成モデルを組み合わせるものと定義している。この用語は広いスペクトルを覆い、「DLSS」はその上の一点だ。
議論が混乱している理由は、スペクトルに少なくとも3つの明確なレイヤーがあるのに、一般の人々がその全部に一つの言葉を使うからだ。
第一のレイヤーは 学術的 / 再構成ニューラルレンダリングだ。NeRF、3D Gaussian Splatting、そして微分可能レンダリングがここに入る。これらは実在のシーンの写真や計測値を取り込み、新しいカメラアングルからレンダリングできる表現を学習する。 オリジナルのNeRF論文 (Mildenhallら、2020)は、3D座標と視線方向を色と密度にマッピングする小さなネットワークを学習させ、それを問い合わせて新規視点をレンダリングする。このレイヤーはほぼオフラインだ。シーンを再構成するが、ゲームのフレームループを駆動しはしない。
第二のレイヤーは リアルタイムパイプラインニューラルレンダリングだ。通常のラスタライズされたフレームの内部、またはそれと並んで動くネットワークである。DLSSアップスケーリング、Ray Reconstruction、ニューラルラディアンスキャッシュがここに住む。パイプラインは依然としてラスタライズしレイトレースを行い、ネットワークはそのうちの高価な一ステージを担う。これが今日ゲームに入っているレイヤーだ。
第三のレイヤーは 生成ニューラルレンダリングだ。ネットワークが、フレームが一切計算しなかった画像コンテンツを生み出す。DLSS 4の生成フレームはこの縁に位置し、DLSS 5(NVIDIAが2026年秋と発表)は、レンダリング済みフレーム間を補間するだけでなく、ライティングやマテリアルのディテールを生成することで、ここへさらに深く踏み込む。
これら3つのレイヤーは振る舞いが異なり、異なる速度で動き、異なるハードウェアを必要とする。それらを一つのものとして扱うことこそ、二人がそれぞれ「ニューラルレンダリングは過大評価だ」と「ニューラルレンダリングは未来だ」と言い、どちらも部分的に正しくなりうる理由だ。
節のまとめ:この用語はDLSSより前から存在し、その同義語ではない。DLSSは、オフラインのシーン再構成から完全生成フレームまでにわたる、はるかに広いスペクトルの中の一つの応用(リアルタイム、パイプライン内)だ。
ニューラルレンダリングはいかにして総当たり式パイプラインの一部を置き換えているか
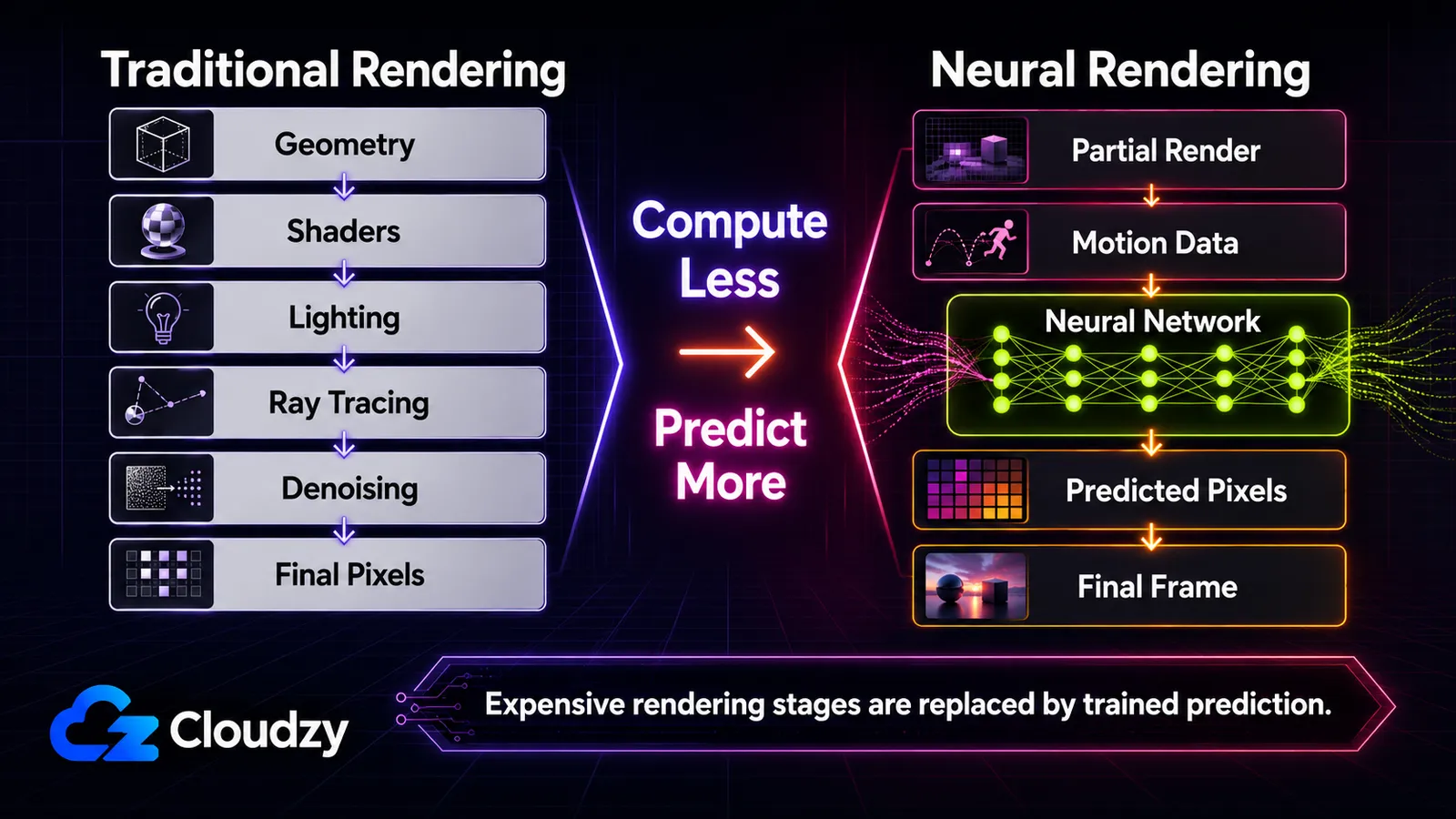
完全なDLSS 4のマルチフレーム生成では、画面上の16ピクセルのうちおよそ15ピクセルが、従来どおりレンダリングされたのではなくAIで生成される(NVIDIAのDLSS 4の数値による)。その数字は、変化全体を一つの統計に圧縮したものだ。レンダラーは画像の一部だけを計算し、残りを予測する。
従来のレンダリングは全ピクセルを一つずつ稼ぎ出す。GPUはジオメトリをラスタライズし、シェーダーを走らせてライティングとマテリアルを計算し、(レイトレーシングで)光がシーン内を跳ね回る様子をシミュレートする。とりわけレイトレーシングは残酷なほど高価だ。リアルな光は多くのバウンスとピクセルあたり多くのサンプルを必要とし、サンプリング不足から出るノイズは後で除去しなければならないからだ。シーンが野心的になるにつれ、最も高価なステージが当然の標的になった。それらを計算する代わりに、その出力を予測するようネットワークを学習させるのだ。
進展は突発的ではなく着実だった。
- 2018年、DLSS 1.0。 最初の商用ステップ。低解像度でレンダリングし、高解像度画像を予測する。アップスケールを「より多くのピクセルを計算する」から「より多くのピクセルを予測する」へ移した。
- 2020年、NeRF。 学習されたラディアンスフィールドによる画像からのシーン再構成。ジオメトリをモデリングしレンダリングする代わりに新規視点を予測する。
- 2021年、Neural Radiance Cache。 パストレーシング中の跳ね返り光を予測し、レンダラーが早めに追跡を止められるようにする。
- 2022年、DLSS 3 Frame Generation。 中間フレームをレンダリングする代わりに丸ごと生成する。
- 2023年、3D Gaussian Splatting。 再構成シーン向けの、NeRFより高速でリアルタイム寄りの代替手法。
- 2025年、DLSS 4 + RTX Kit。 マルチフレーム生成に加え、ニューラル構成要素(テクスチャ圧縮、ラディアンスキャッシュ、ニューラルシェーダー)のツールキット。
- 2025年、DirectX Cooperative Vectors(プレビュー)。 ニューラルシェーダーが必要とする行列演算のためのベンダー横断API(Shader Model 6.9の一部としてプレビュー導入)。
- 2026年、DLSS 4.5。 段階的な品質向上とRay Reconstructionの改善(NVIDIAがComputexで説明)。
- 2026年秋、DLSS 5(発表済み)。 生成ニューラルレンダリングへの次の一歩。
上から下へ読めば、各行は異なるステージに適用された同じ一手だ。パイプラインがかつて計算していた何かを取り上げ、代わりにネットワークに予測させる。
6つのレイヤー:パイプラインの各ステージでAIが何を置き換えるか
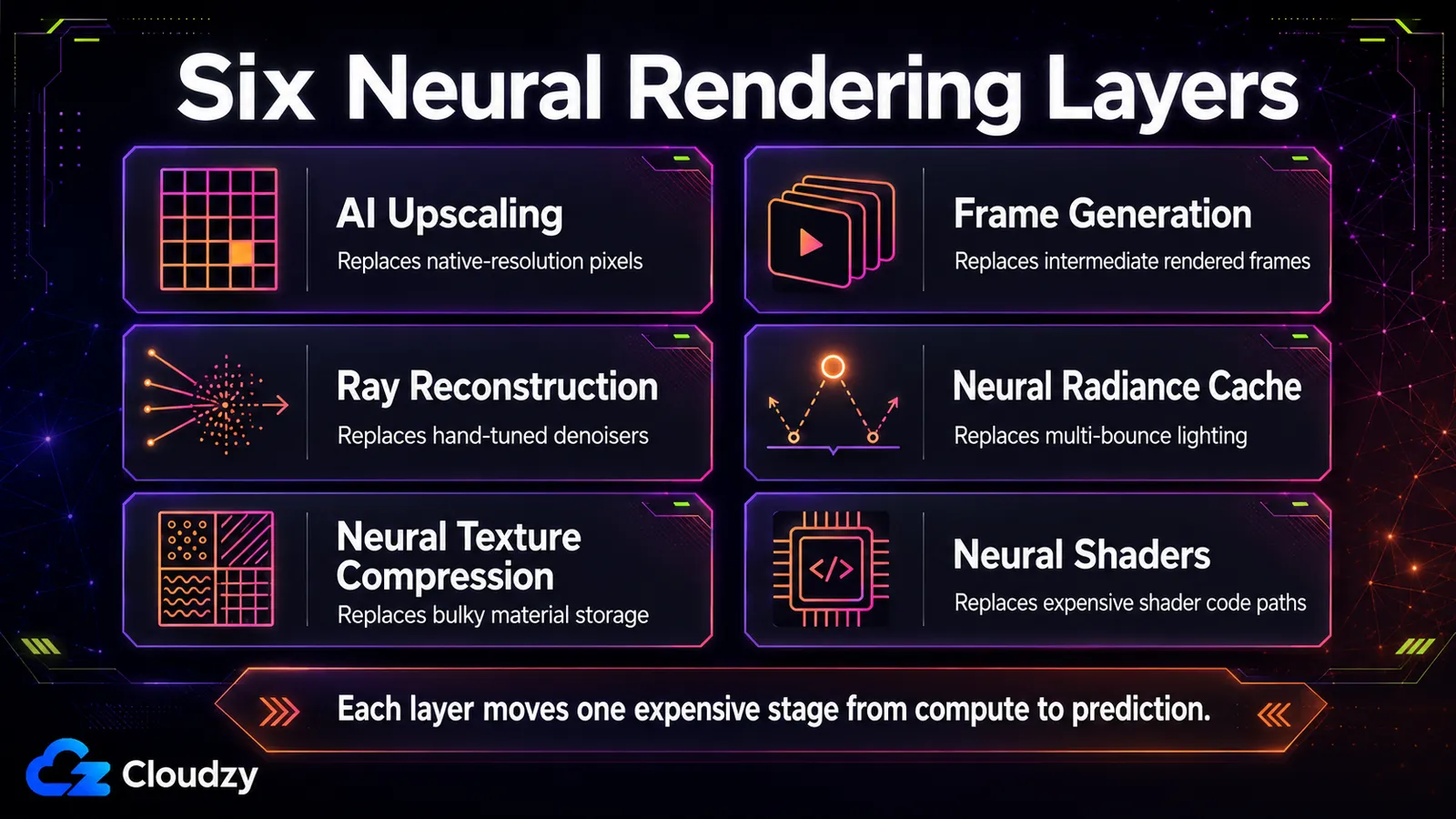
今日のリアルタイムニューラルレンダリングの大半を6つの技術が担い、それぞれが特定の計算ステージを置き換える。アップスケーリング(解像度)、フレーム生成(フレーム数)、レイリコンストラクション(デノイズ)、ニューラルラディアンスキャッシュ(グローバルイルミネーション)、ニューラルテクスチャ圧縮(マテリアル格納)、ニューラルシェーダー(シェーダー内演算)。それぞれがどのステージに触れるかを知ることが、戦いのほとんどだ。
これらは次の基準で分かれる。 ネットワークがパイプラインのどこで動くか。あるものは完成したフレームへのポストプロセスとして最後尾で動き、あるものはレイトレーシングと並んでパイプライン中盤で回り、あるものはシェーダー自体の内部に住む。その場所は些細なことではない。それが、技術がどれだけ速く動けるか、どのハードウェアを要するかを決める。表はその6つの技術を整理し、以下の小節は各セルにきれいに収まらない仕組みを説明する。
| 技術 | 何を置き換えるか | リアルタイム実現性 | 必要なハードウェア | ベンダー横断? |
|---|---|---|---|---|
| AIアップスケーリング(スーパーレゾリューション) | ネイティブ解像度ピクセルの計算 | リアルタイム、低オーバーヘッド | テンソル / 行列コア(RTX 20+、RDNA 4、Intel XMX) | カテゴリーとしてはイエス。実装はベンダー固有のまま(DLSS、FSR / FSR Upscaling、XeSS) |
| フレーム生成 | 中間フレームのレンダリング | リアルタイム。レイテンシを加える | RTX 40+(DLSS 3)、マルチフレームはRTX 50 | 部分的。ベンダー固有 |
| レイリコンストラクション | 手作業で調整されたデノイザースタック | リアルタイム | RTX 20+ | 現状NVIDIA |
| ニューラルラディアンスキャッシュ | 多重バウンス間接光の計算 | リアルタイム(約2.6 msと報告) | RTXクラスの行列コア | 現状NVIDIA(RTX Kit) |
| ニューラルテクスチャ圧縮 | ブロック圧縮されたマテリアル格納 | リアルタイムデコード | RTXクラスの行列コア | 現状NVIDIAのSDK/ツール。より広いシェーダーレベルMLサポートは別途標準化中 |
| ニューラルシェーダー | 計算されていたシェーダーコードパス | リアルタイム | シェーダーレベルML / 行列演算対応GPU | DirectX SM 6.9 / SM 6.10の経路を通じて登場中 |
AIアップスケーリング(スーパーレゾリューション)
AIアップスケーリングはフレームを低い解像度でレンダリングし、高解像度の結果を予測するので、GPUははるかに少ないピクセルを描き、ネットワークが構造を埋める。DLSS、AMDのFSR 4、IntelのXeSSはいずれもこれを 時間的(temporal) アップサンプリングで行う。連続するフレームにわたって異なるピクセルをサンプリングし、その履歴をモーションベクトルと組み合わせて、単一の低解像度フレームには含まれないディテールを再構成する。
これは最も成熟し、最も広く展開されたレイヤーであり、ベンダー横断の現実が最も明確な場所だ。DLSS 4は、ディテールの安定性を高めるため、アップスケーラーを畳み込みネットワークからトランスフォーマーへ移した。FSR 4はAMD初のMLベースのアップスケーラーで、以前のFSRバージョンの手書きヒューリスティックではなくFP8推論でRDNA 4上を動く。XeSSはIntelのXMX行列ユニットを使う。3つのベンダー、同じ根底のアイデア。レンダリングしなかったピクセルを予測することだ。
フレーム生成とマルチフレーム生成
フレーム生成は、モーションベクトルなどのゲームデータをオプティカルフロー推定とAIと組み合わせて、GPUが実際にレンダリングするフレームの間にフレーム全体を予測する。DLSS 3はRTX 40シリーズのOptical Flow Acceleratorを使い、レンダリング済みフレームの間に生成フレームを1枚挿入した。RTX 50シリーズハードウェア上のDLSS 4 Multi Frame Generationは、従来どおりレンダリングされたフレーム1枚につき最大3枚の追加フレームを生成でき、NVIDIAはDLSS 4がハードウェアのオプティカルフローステップをより効率的なAIモデルで置き換えると述べている。
これが「偽のフレーム」論が実際に対象とするレイヤーであり、ここでは言葉の枠組みが重要だ。生成フレームは、シーンがどこへ向かっていたかについてのもっともらしい補間だ。つまり使える視覚コンテンツを見せてくれる。だがそれは 予測されたのであって、ゲームの実際の状態からレンダリングされたものではなく、新しいゲームロジックや入力を運びはしない。決定的に、フレーム生成はフレームがレンダリングされた 後(after) に動くため、レイテンシを取り除くのではなく加える。NVIDIAのReflex 2は、まさにそのレイテンシを取り戻すために存在する。だから「フレーム生成はゲームを速くする」は半分の真実だ。ゲームが実際に更新され応答する速度を上げないまま、体感の滑らかさ(表示されるフレームの増加)だけを上げる。見えるものとゲームが知っていることの間のそのギャップが議論のすべてであり、入力レイテンシが勝敗を決める競技プレイでは、天秤にかける価値のあるトレードオフだ。
Ray Reconstruction(AIデノイズ)
Ray Reconstructionは、レイトレースレンダリングが頼る手作業調整のデノイズフィルター群を、ノイズの多いサンプル不足のレイトレース入力からクリーンな画像を再構成するよう学習させた単一のニューラルネットワークで置き換える。パストレーシングはリアルタイムではピクセルあたり数個の光サンプルしか賄えず、生の出力にはノイズが残る。それを見る前に何かがきれいにしなければならない。
従来のアプローチは、それぞれ特定の効果向けに手で調整された専用デノイザーの連鎖だった。それを学習済みネットワーク1つに置き換えると、手作業フィルターがにじませていたディテール、とりわけ反射や繊細なライティングを保ちやすくなり、しかも壊れやすいパイプラインの代わりに維持するネットワークは1つで済む。これは一本の筋のきれいな例だ。デノイズステージが「手書きヒューリスティックで計算」から「学習済みモデルで予測」へ移ったのだ。
Neural Radiance Cache(グローバルイルミネーション)
ニューラルラディアンスキャッシュ(NRC)は、光がシーン内をどう跳ね回るかを予測し、パストレーサーがすべてのバウンスを最後まで追う代わりに、大半のレイの追跡を早めに止められるようにする。グローバルイルミネーション(壁や床で跳ね返る柔らかな間接光)はリアルタイムグラフィックスで最も高価なものの一つであり、NRCを機能させる仕組みは平易な言葉で説明されることがまれなので、立ち止まって見る価値がある。
仕組みはこうだ。パストレーサーは通常、各光線を多くのバウンスにわたって追う。そこでコストが爆発する。NRCは小さなネットワークをレンダリング 中(during) (事前ではなく)に学習させ、さらなるバウンスの後にある点へ到達する光を予測する。そこでパストレーサーは光線を1、2バウンス追跡し、ネットワークに「ここの残りの光は何か?」と尋ねて経路を早めに終了する。 リアルタイムニューラルラディアンスキャッシングの論文 (Müllerら、2021)は、この方法で経路の大多数を終了させると報告している。これを、以前に見た正確な答えを保存するキャッシュではなく、シーンのライティングの パターン を、まだ見ていない問い合わせにも答えられるほど十分に学習し、シーンが変わるたびに学習し直し続けるキャッシュと考えてほしい。NVIDIAはNRCがおよそ2.6 msのオーバーヘッドで動くと報告しており、これこそがそれを研究上の好奇心ではなくリアルタイムで実現可能なものにしている。
ニューラルテクスチャ圧縮
ニューラルテクスチャ圧縮(NTC)は、あるマテリアルのすべてのテクスチャチャンネルをネットワークでまとめて圧縮し、同程度の視覚品質で従来のブロック圧縮に対して最大8倍のVRAM節約に達する(NVIDIAのRTX Kitドキュメントによる)。現代のマテリアルは1枚のテクスチャではない。それは複数の積み重ね(カラー、ノーマル、ラフネス、メタルネスなど)であり、それらのチャンネルは、各チャンネルを独立に絞り込むブロック圧縮が捨ててしまう形で相関している。
NTCはその相関を活用する。あるマテリアルの全チャンネルにわたる結合構造を一度に学習することで、同じマテリアルをはるかに少ないメモリに格納し、レンダー時にその場でデコードする。ゲームがテクスチャのディテールを押し進めるなかVRAMは恒常的な制約なので、「同じメモリに8倍多くのマテリアルを収める」は視覚的なギミックではなく、直接的で実用的な勝ちだ。
ニューラルシェーダーとDirectX Cooperative Vectors
ニューラルシェーダーは、小さなニューラルネットワークをプログラマブルシェーダー(GPUがすでに実行しているピクセルごと/頂点ごとのプログラム)の 中にある で走らせ、高価な計算効果が必要なまさにその場所でネットワークがそれを近似できるようにする。AIを別パスとして後付けする代わりに、MLPがGPUの行列ユニット(NVIDIAハードウェアのTensor Cores)上でシェーダーの一部として動く。
Tensor Coresは、これらのネットワークが動く行列演算を処理する。これは残りの作業を処理する汎用コアとは区別される。ニューラルシェーダーを単一ベンダーの機能から、より広い業界の能力へと変えるのは、その下にあるAPIレイヤーだ。 MicrosoftはDirectX Cooperative Vectorsを 2025年にShader Model 6.9とともにプレビューで導入し、HLSLシェーダー内のベクトル/行列演算を露出させた。2026年までにShader Model 6.9は製品版へ移行し、MicrosoftはCooperative VectorがShader Model 6.10で計画されるより広い線形代数設計を優先して非推奨化されつつあると述べた。安全な結論は、Cooperative Vectorsが最終的なAPIだということではなく、DirectXがベンダー横断のシェーダーレベルMLサポートへ向かっているということだ。
節のまとめ:6つの技術は、ネットワークがどこで動くかで分類される。フレーム末尾でのポストプロセス、レイトレーシングと並ぶパイプライン中盤、あるいはシェーダー自体の内部。その場所こそが、技術がリアルタイムで動けるか、どのハードウェアを要するかを決める。
何がリアルタイムで、どのハードウェアで動くか
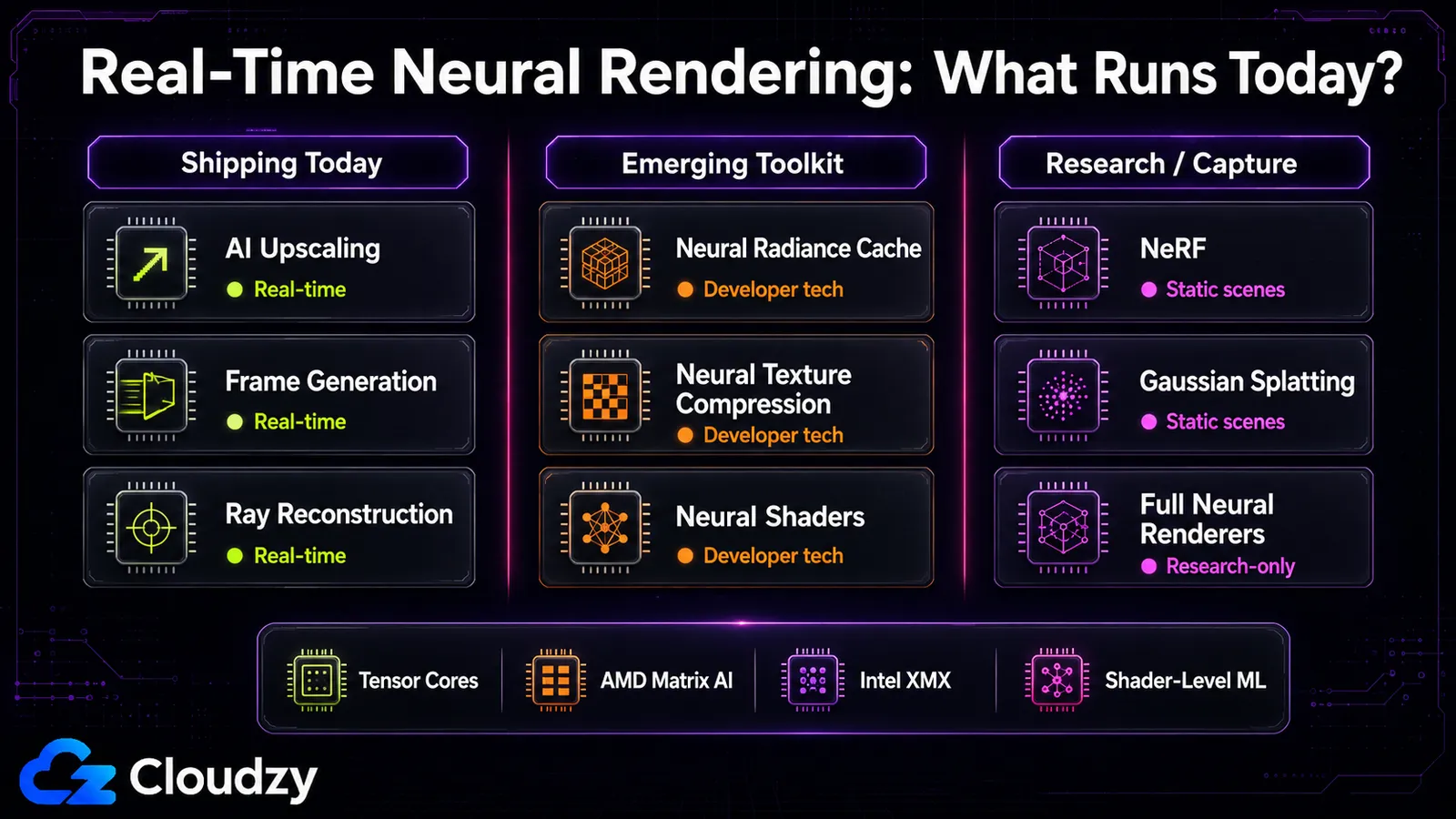
リアルタイムの線引きは誇大宣伝が示唆するより鮮明だ。AIアップスケーリングは通常低オーバーヘッドで動き、NRCは約2.6 msを加え、3D Gaussian Splattingは静的シーンでリアルタイムに近づく。オリジナルのNeRFやRenderFormerのような完全なニューラルレンダラーは確実に研究専用で、インタラクティブ用途にはフレームあたりの時間がかかりすぎる。「ニューラルレンダリングはリアルタイムだ」は、パイプライン内レイヤーには真で、再構成および完全レンダラーレイヤーには偽だ。
その分かれ方はスペクトルを正確に追う。一部のパイプライン内構成要素、とりわけアップスケーリング、フレーム生成、Ray Reconstructionは、すでに出荷済みのゲームで動いている。NRC、NTC、ニューラルシェーダーといった他のものは、一般的な量産機能というより、開発者向け技術や登場しつつあるツールキット機能と表現する方が適切だ。再構成レイヤーは玉石混交だ。オリジナルのNeRFは遅いが、3D Gaussian Splattingはリアルタイムへの意図的な後押しであり、静的シーンではそこに到達する。完全ニューラルレンダラーレイヤー(単一のネットワークが画像全体を生成する)は研究が住む場所で、フレーム時間はインタラクティブには程遠い。
ハードウェアは答えのもう半分であり、ここでベンダー横断の話が着地する。ここのあらゆる技術は、現代のGPUがAI推論のために搭載する行列演算ユニット上で動く。
- NVIDIA は20シリーズ以降のすべてのRTXカードにTensor Coresを持っており、だからこそこれらの技術の大半がそこでデビューした。
- AMDの MLベースのFSR Upscalingは、MLパスについて現状RDNA 4 / Radeon RX 9000シリーズGPUを対象とする。それ以前のハードウェアでは、AMDのSDKは解析的なFSR 3.1.5パスへフォールバックする。具体的なAMDの発表を引用しない限り、より広い旧GPUサポートは保証されたFSR 4の機能ではなく、流動的なロードマップ項目として扱うこと。
- Intel はXeSSのためにArc GPUでXMX行列エンジンを使う。
DLSS自体は世代ごとに機能がゲート制限されている。アップスケーリングはRTX 20シリーズまでさかのぼって動き、オリジナルのフレーム生成はRTX 40シリーズを要し、マルチフレーム生成はRTX 50シリーズ専用だ。あるカードが何をできるか推し量ろうとするなら、マーケティングのティアではなく、その世代によるゲート制限が実用的な答えだ。
今日使えるもの対これから来るもの:アップスケーリング、フレーム生成、Ray Reconstructionは今日ゲームで利用できる。 RTX Kitの構成要素 つまりNRC、NTC、ニューラルシェーダーといったものは開発者向け技術およびツールとして利用できるが、それらすべてが出荷済みゲームですでに一般的だと示唆すべきではない。Gaussian Splattingにはシーンキャプチャ向けの使えるオープンツールがある。まだここにないもの:単一のネットワークでフレーム全体を描く完全なニューラルレンダラー、成熟したベンダー横断のニューラルシェーダー(AMDのサポートは初期段階)、そしてDLSS 5の生成機能(2026年秋と発表)。再構成側を試したいなら(NeRFや推論ワークロードを自分で動かすこと)、それは GPUコンピュート の仕事であって、ゲームが代わりにやってくれるものではない。
ニューラルレンダリングではないもの:5つの誤解

ほとんどのニューラルレンダリング論は、その主張がスペクトルのどのレイヤーについてかを特定すれば、ぐっと扱いやすくなる。5つの誤解が何度も繰り返し現れる。
1. 「DLSSアップスケーリングはニューラルレンダリングだ。」 DLSSは an ニューラルレンダリングの応用、すなわちパイプライン内のリアルタイムレイヤーであって、分野全体ではない。この用語はDLSSより前から存在し、NeRF、Gaussian Splatting、そして生成手法を含む。両者を同一視するのは、「データベース」をたまたま使っている一製品の同義語と呼ぶようなものだ。
2. 「フレーム生成はゲームを速くする。」 それはあなたが見るフレーム数を上げ、動きをより滑らかに見せるが、レンダリングの後に動きレイテンシを加える。ゲームがあなたの入力に対して更新し応答する速度は上がらない。競技プレイにとってそのレイテンシは現実的なトレードオフであり、視覚的な滑らかさにとっては本物の勝ちだ。「速い」はその二つを混同している。
3. 「DLSS 5は3Dを認識する / 3Dシーンを読む。」 これは最も正しく理解する価値がある。技術報道が誤った特徴づけを繰り返しているからだ。NVIDIAの説明によれば、DLSS 5は各フレームのカラーデータとモーションベクトルを入力として受け取り、学習済みモデルを用いてキャラクター、髪、布、肌、ライティング条件といったシーンの意味を推論する。それはゲームのコンテンツに根ざしているが、NVIDIAはそれをゲームの完全な3Dシーンファイルを直接読むものとしては説明していない。「3Dガイド(3D-guided)」とは、推論がジオメトリと整合する(表面がどう動き関係し合うかを尊重する)という意味であって、ネットワークがシーンジオメトリを直接読むという意味ではない。この区別は、その技術が何を知りうるか・知りえないかを画定するため重要だ。
4. 「NeRFはもうリアルタイムだ。」 どの技術を指すかによる。これこそまさにスペクトルの問題だ。オリジナルのNeRFはリアルタイムではない。3D Gaussian Splattingは静的シーンでリアルタイムに近づく。単一のネットワークでフレーム全体をレンダリングする研究システム(RenderFormerや類似のもの)はまったくリアルタイムではない。「NeRF」は、速度が大きく異なる半ダースほどの手法をひとまとめにする総称になってしまった。
5. 「ニューラルレンダリングはまもなくラスタライズを置き換える。」 今日のシステムはハイブリッドだ。ニューラル構成要素は、ラスタライズとレイトレーシングのパイプラインの 中にある に位置し、それに取って代わるものではない。古典的パイプライン全体を単一の生成レンダラーで完全に置き換えるのは、長期的な研究目標であって、近い将来の製品の方向性ではない。「未来は完全にニューラルだ」は、日付の入った予測ではなく、進む方向として受け取ること。
節のまとめ:ほぼすべてのニューラルレンダリングの意見不一致の単一の根本原因は、人々がスペクトルの異なるレイヤーに同じ言葉を使うことだ。まず主張をスペクトル上に位置づければ、議論の大半は消える。
これがどこへ向かうか
軌道は上記すべてと整合している。今日はハイブリッドパイプライン、より多くのステージが計算から予測へ移行、ベンダー横断のニューラルシェーダーがこれを出荷できる主体を広げ、そして完全ニューラルレンダラーのフロンティアはまだ何年も先だ。次の消費者向けの一歩は2026年秋と発表されたDLSS 5で、レンダリング済みフレーム間を補間するだけでなく、ゲームが一切計算しなかったライティングやマテリアルのディテールを生成することで、生成ニューラルレンダリングへ踏み込む。NVIDIAはその技術をRTX 50シリーズの文脈で見せているが、最終的な消費者向けハードウェア要件は、NVIDIAが明確な互換性リストを公開するまで未確定として扱うべきだ。
将来展望には二つの側面がある。近い側で最も重要な一手は、どの単一技術でもない。標準化だ。MicrosoftのDirectXの経路はCooperative Vectorsからより広いシェーダーレベルの線形代数へ移りつつあり、これによりエンジンが一つのGPUブランドに賭けることなくニューラル方式のワークロードを狙えるようになりうる。遠い側では、NVIDIAの研究者が、ときに仮説的な「DLSS 10」として持ち出される、はるか将来の終着点を述べている。そこではレンダラーが完全にニューラルで、古典的パイプラインは消えている(Digital Foundryのラウンドテーブルから間接的に伝えられたものなので、ロードマップではなく表明された方向として扱うこと)。梯子の終着点は、世界を描くのではなく、一貫した世界を生成するシステムだ。
とはいえ懐疑は持ち続ける価値がある。生成されたディテールは芸術的意図から逸れることがあり、ネットワークは、デバッグすべき従来の対応物が存在しない、もっともらしいが誤ったビジュアルを幻覚しうる。これはGDC 2026で指摘されたQAの問題であり、「AIスロップ」反応の多くの実体だ。グラフィックスが向かう先に向けて作ることは、現在の出力が完成していると装うことを意味しない。それは、次にどのステージが計算から予測へ移るかを見守り、それぞれを、付けられた言葉ではなく、それが画像に何をするかで判断することを意味する。
よくある質問
DLSSはニューラルレンダリングか?
そうだ、ただし一種類にすぎない。DLSSはニューラルレンダリングの応用で、具体的にはAIアップスケーリングとフレーム生成を含む、リアルタイムのパイプライン内レイヤーだ。より広い用語はDLSSより前から存在し、NeRFやGaussian Splattingのようなシーン再構成手法や、新しい画像ディテールを生み出す生成手法も含む。だからあらゆるDLSS機能はニューラルレンダリングだが、ニューラルレンダリングの多くはDLSSではない。
ニューラルレンダリングとレイトレーシングの違いは何か?
レイトレーシングは シミュレートする 、光線がシーンをどう跳ねるかを計算して光を。ニューラルレンダリングは、それらを計算する代わりに、学習済みネットワークから結果を 予測します 。両者はライバルではない。組み合わさる。たとえばRay Reconstructionはニューラルネットワークを使ってノイズの多いレイトレース出力をデノイズし、ニューラルラディアンスキャッシュは跳ね返り光を予測してレイトレーサーが早めに止められるようにする。ニューラル技術はレイトレーシングをリアルタイムで賄えるものにする。
DLSSのフレーム生成はレイテンシを加えるか?
そうだ。フレーム生成はフレームがレンダリングされた後に動き、レンダリング済みフレームの間に予測フレームを挿入するので、レイテンシを取り除くのではなく加える。NVIDIAのReflex 2は、まさにこれを補償するために存在する。それはゲームが入力に対して更新し応答する速度を上げないまま、体感の滑らかさ(表示されるフレームの増加)を上げる。競技プレイにはトレードオフであり、シングルプレイヤーの滑らかさには通常ネットの勝ちだ。
NeRFはリアルタイムか?
どの技術を指すかによる。オリジナルのNeRFはリアルタイムではない。後発の手法である3D Gaussian Splattingは、静的シーンでリアルタイムに近づく。単一のネットワークでフレーム全体を描く完全なニューラルレンダラーは研究専用で、インタラクティブな速度には程遠い。「NeRF」は性能が大きく異なる複数の手法を覆う形でゆるく使われることが多く、それが混乱の大半の源だ。
ニューラルレンダリングはラスタライズを置き換えるか?
まもなくではない。今日のシステムはハイブリッドだ。ニューラル構成要素は、ラスタライズとレイトレーシングのパイプラインの内部で動き、それに取って代わるのではない。古典的パイプラインを単一の生成レンダラーで丸ごと置き換えるのは長期的な研究目標であって、近い将来の製品ではない。現実的な方向は、時間とともにより多くのパイプラインステージが計算から予測へ移ることで、ラスタライズは今後何年も実際の仕事を担い続ける。
ニューラルテクスチャ圧縮とは何か?
ニューラルテクスチャ圧縮(NTC)は、あるマテリアルのすべてのテクスチャチャンネル(カラー、ノーマル、ラフネスなど)をまとめて圧縮するニューラル手法で、同程度の視覚品質で従来のブロック圧縮に対して最大8倍のVRAM節約に達する(NVIDIAによる)。それは、各チャンネルを別々に絞り込むブロック圧縮が捨ててしまうチャンネル間の相関を学習することで機能する。圧縮されたマテリアルはレンダー時にその場でデコードされる。


