Oprogramowanie do monitorowania GPU to narzędzie, które zmienia "mój GPU działa dziwnie" w bezpośrednie wyjaśnienie, na przykład "hotspot wzrósł, taktowanie spadło, a VRAM się zapełnił".
W tym przewodniku pokażę ci narzędzia, które możesz wykorzystać do pracy z sztuczną inteligencją, nakładek do gier i długich sesji na stacjach roboczych. Pokażę ci także metryki GPU, które pomagają diagnozować spowolnienia, zacinanie się i awarie.
Na koniec będziesz mieć konfigurację oprogramowania do monitorowania GPU dostosowaną do twojego sposobu pracy. Otrzymasz też gotowe stosy dla czterech typowych przypadków użycia, więc nie będziesz musiał szukać artykułów.
Szybka odpowiedź: najlepsze wybory oprogramowania do monitorowania GPU wg przypadku użycia
Jeśli chcesz krótką listę dopasowaną do tego, jak naprawdę pracują ludzie, zacznij od poniższych. W praktyce najlepszy stos oprogramowania do monitorowania GPU to zwykle kombinacja: jedno narzędzie do szybkich kontroli, jedno do nakładek lub logów i jedno do historii lub alertów.
Oto szybka mapa:
| Przypadek użycia | Zestaw początkowy | Co otrzymujesz |
| Trenowanie AI, wnioskowanie, zadania HPC | nvidia-smi (NVIDIA) lub AMD SMI (AMD) + logowanie/eksporter | Szybkie kontrole, logi można skryptować, łatwe alerty |
| Gry na Windows | MSI Afterburner + RTSS + narzędzie do pomiaru czasu klatki | Nakładka z potwierdzeniem dla zacinania vs niskie FPS |
| Gry na Linuxie | MangoHud + sprawdzenie w terminalu (nvtop) | Lekka nakładka plus kontrole dla każdego procesu |
| Stacje robocze (3D/wideo/CAD) | Logowanie HWiNFO + prosty test obciążenia | Długie logi do udostępnienia, powtarzalne scenariusze |
| Współdzielone maszyny GPU | nvtop (Linux) + eksporter/dashboard | Widoczność VRAM dla każdego procesu |
Z tego punktu głównym zadaniem jest dostosowanie oprogramowania monitorującego GPU do sposobu, w jaki konsumują dane: na ekranie, w logu lub w dashboardzie.
Dla kogo jest ten przewodnik
Napiszę to jak ktoś, kto musiał debugować prawdziwe maszyny. Bo z doświadczenia wiem, że różni czytelnicy potrzebują różnych narzędzi GPU, nawet jeśli patrzą na to samo GPU.
Oto cztery scenariusze, które omawiam:
- Model Builder (AI/ML): zależy mu na zapasie VRAM, stabilnych taktach, throttlingu i na tym, czy zadanie będzie działać całą noc bez przerwy.
- Gracz konkurencyjny/streamer: zależy mu na czasach klatek, stabilności nakładki i wychwytywaniu regresji po aktualizacjach sterownika.
- Użytkownik stacji roboczej (3D/wideo/CAD): zależy mu na logach, powtarzalnych błędach i wskazaniu, czy to temperatura, zasilanie czy sterownik.
- Administrator maszyn GPU: zależy mu na alertach, wykresach trendów, planowaniu pojemności i wczesnym wychwytywaniu błędów.
Jak już wiesz, w której jesteś grupie, możesz łatwo wybrać oprogramowanie monitorujące GPU, które do ciebie pasuje.
Jak wybrać oprogramowanie monitorujące GPU
Wiele aplikacji do monitorowania wydajności wygląda podobnie, aż spróbujesz ich używać przez tydzień. Główną różnicą jest zwykle sposób przedstawiania danych i niezawodność, a nie te atrakcyjne funkcje, które każda z nich intensywnie reklamuje.
Mam dla ciebie trzy pytania, które pomogą ci szybko wybrać oprogramowanie do monitorowania GPU:
- Potrzebujesz nakładki, logów, czy obu?
Gracze chcą nakładkę. Praca z AI i na stacjach roboczych zwykle wymaga logów. Administratorzy chcą logi plus powiadomienia. - Potrzebujesz widoczności dla poszczególnych procesów?
Jeśli udostępniasz maszynę (lab, studio, serwer zdalny), widoczność per-proces VRAM to często pierwsza rzecz, którą chcesz sprawdzić. - Potrzebujesz historii i powiadomień?
Jeśli zadania uruchamiają się w nocy, "sprawdzę to później" to za mało. Potrzebujesz wykresu i powiadomienia.
Żeby to było praktyczne, reszta przewodnika jest zorganizowana wokół metryk GPU, a potem stosów narzędzi pasujących do każdego przypadku użycia.
Metryki GPU, którym powinieneś się priorityzować
Oprogramowanie do monitorowania Go GPU daje ci mnóstwo liczb. Naprawdę użyteczne oprogramowanie do monitorowania GPU daje ci tę konkretną garść wartości, która wyjaśnia zachowanie. Grupuję metryki GPU wokół decyzji, którą pomagają ci podjąć.
Metryki temperatury i throttlingu
To metryki GPU, które wyjaśniają "było szybko przez 10 minut, potem już nie":
- Temperatura GPU
- Temperatura hotspotu (często pierwsza rzecz, która wzrasta)
- Temperatura pamięci/złącze (bardziej istotne przy długich uruchomieniach AI i renderach)
- Prędkość wentylatora (pomaga dostrzec profile laptopa lub źle skalibrowane krzywe wentylatorów)
Jeśli chcesz poprawić stabilność, loguj te wartości, bo pojedyncze migawki rzadko dają wystarczająco dużo informacji.
Moc, taktowanie i limity
Te metryki GPU wyjaśniają obniżanie taktowania i niespójną wydajność:
- Pobór mocy płyty
- Taktowanie rdzenia i pamięci
- Limit mocy/stan wydajności (jeśli twoje narzędzie to ujawnia)
W wielu rzeczywistych debugowaniach, moc i taktowanie dają znacznie jaśniejszy obraz niż podstawowe "użycie GPU %".
Ciśnienie VRAM i pamięci
Te metryki GPU wyjaśniają spowolnienia, błędy braku pamięci i typowe "losowe" spadki wydajności:
- VRAM użyte vs razem
- Aktywność kontrolera pamięci (pomaga zidentyfikować limity przepustowości)
- Ciśnienie systemu RAM (bo wyciek VRAM może też spowolnić cały system)
W przypadku AI VRAM to często praktyczny limit. W grach objawy braku dostępności VRAM pojawiają się najpierw jako skoki czasu klatki.
Metryki czasu klatki i synchronizacji klatek
W grach i streamingu sama liczba FPS może być myląca. Liczy się frametime - to wskaźnik, który naprawdę ma znaczenie, bo pokazuje płynność obrazu:
- Czas ramki (ms)
- 1% niskie / 0.1% niskie (przydatne do porównań)
- GPU zajęty vs CPU zajęty (pomaga rozdzielić wąskie gardła GPU od wąskich gardeł CPU)
Dlatego aplikacje do monitorowania wydajności ukierunkowane na gaming często zawierają ścieżkę przechwytywania czasu klatki. Po omówieniu podstawowych metryk możemy poruszyć temat najlepszych stosów oprogramowania monitorującego GPU dla każdego przepływu pracy.
GPU Oprogramowanie monitorujące do AI, szkolenia i serwerów

Monitoring AI to proste - szybkie testy w terminalu, logi i alerty dla długotrwałych procesów. Potrzebujesz oprogramowania monitoringu GPU, które działa z CLI i eksportuje metryki.
NVIDIA: Użyj nvidia-smi do Szybkich Sprawdzeń i Logów Dostępnych dla Skryptów
Na systemach NVIDIA, nvidia-smi to zwykle pierwsza komenda, którą uruchamiają użytkownicy, ponieważ jest dołączona do sterownika i zaprojektowana do monitorowania i zarządzania poprzez NVML.
Oficjalna dokumentacja jest tutaj: Interfejs zarządzania systemem NVIDIA (nvidia-smi).
Jeśli wolisz podejście "zaloguj i sprawdź później" (a zaskoczysz się, jak często to rozwiązuje problem), ten wzorzec się sprawdza:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
To podstawowe oprogramowanie do monitorowania GPU ze znacznikami czasu, metrykami jądra GPU i wyjściem kompatybilnym ze skryptami.
AMD: AMD SMI dla węzłów ROCm i HPC
Na węzłach obliczeniowych AMD i Linux interfejs AMD SMI to nowoczesne narzędzie do monitorowania i zarządzania. AMD dokumentuje je jako ujednolicony zestaw narzędzi do monitorowania i kontroli w kontekstach HPC.
Oficjalna dokumentacja jest tutaj: Dokumentacja AMD SMI.
Jeśli Twoje środowisko intensywnie wykorzystuje AMD, AMD SMI stanowi fundament oprogramowania do monitorowania GPU, na którym budują się inne narzędzia.
Widoczność na poziomie procesu: nvtop dla współdzielonych GPU
Jeśli miałeś kiedyś współdzielony serwer, na którym VRAM "tajemniczo" zawsze jest zapełniony, widoczność na poziomie procesu zaoszczędzi Ci czasu. Na Linux, nvtop cieszy się popularnością właśnie dlatego, że od razu widać "kto korzysta z VRAM?". Na AMD/Intel możesz potrzebować nowszego kernela do statystyk na poziomie procesu.
W zespołach mieszanych często widzę, że ludzie uruchamiają nvtop równolegle z nvidia-smi lub AMD SMI. To proste połączenie, które eliminuje wiele zgadywania, dlatego gorąco to polecam.
Nie lekceważ wyboru sprzętu!
Monitorowanie nie rozwiąże problemu pułapu VRAM, tylko go ujawni. Jeśli nadal mapujesz obciążenia na poziomy GPU, nasz przewodnik na temat Najlepsze GPU do Machine Learning w 2025 roku to pomocny materiał towarzyszący, bo wyjaśnia VRAM i przepustowość w ten sam sposób, w jaki będziesz je czytać później w logach i dashboardach.
Gdy opanujesz oprogramowanie do monitorowania GPU na poziomie serwera, następny krok to nakładki i czasy renderowania, ponieważ interaktywne obciążenia zachowują się inaczej.
Oprogramowanie do monitorowania GPU dla gier i streamingu

Gry to dziedzina, gdzie ludzie mają najsilniej ukształtowane opinie na temat narzędzi GPU, głównie dlatego że nakładki zawodzą w najgorszych momentach. Do gier potrzebujesz prostych nakładek i powtarzalnego pomiaru czasów renderowania.
MSI Afterburner + RTSS do nakładek na Windows
Ta kombinacja cieszy się popularnością, bo możesz zbudować czystą nakładkę z dokładnie tymi metrykami GPU, które Cię interesują: obciążenie, taktowania, VRAM, temperatury, czas renderowania, a może i prędkość wentylatora.
Jedno poważne ostrzeżenie, które pojawia się w wątkach społeczności, to oszukańcze strony pobierania. Sama strona Afterburnera od MSI zwraca uwagę, że prawidłowe pobrania powinny pochodzić z msi.com oraz Guru3D, a także podaje aktualną linię wydań (4.6.6 final, wydane w październiku 2025).
Problemy z nakładkami to kolejna rzecz, na którą warto zwrócić uwagę. Na przykład RTSS działa w niektórych grach, a w innych zawodzi, szczególnie w nowoczesnych ścieżkach renderowania. Ludzie zgłaszają przypadki, gdy nakładka pokazuje się w Vulkanie, ale nie w DX12 dla tej samej gry, albo znika po aktualizacjach.
Jednak nie dlatego, że coś źle zrobiłeś, tylko dlatego, że tak się dzieje, gdy nakładki haczyują się w zmieniające się stosy gier i sterowników.
Jeśli chcesz stabilną nakładkę, trzymaj ją krótko:
- czas klatki
- Użycie GPU
- Używana VRAM
- Temperatura GPU
Dodawaj zasilanie i taktowanie tylko, gdy aktywnie debugujesz throttling.
Frametime Capture dla problemu "Stuttering"
Tu przydają się aplikacje do monitorowania wydajności, które potrafią zachwytywać wykresy frametime. Średnie FPS mogą wyglądać dobrze, a równomierność wyświetlania klatek może być okropna. Wykresy frametime szybko to wyjaśniają.
Wiele workflow'ów benchmarkowania gier opiera się na PresentMon pod spodem, i Dokumenty NVIDIA że ich analityka FrameView używa PresentMon do pomiaru szybkości klatek i czasu ich wyświetlania.
Nie musisz testować każdej gry. Frametime capture przydaje się głównie do porównań, takich jak przed i po aktualizacji sterownika, przed i po zmianie limitera, przed i po zmianzie ustawień, i tak dalej.
MangoHud dla nakładek Linux
Na Linux MangoHud jest polecany, bo jest lekki i czysto się integruje z zestawami Steam/Proton. Najczęściej skarżą się na brakujące czujniki lub dziwne odczyty na hybrydowych laptopach.
W praktyce możesz łatwo połączyć MangoHud z terminalowym checkerem takim jak nvtop. To też dobry przykład tego, jak oprogramowanie do monitorowania GPU działa zdecydowanie lepiej jako mały stos narzędzi, zamiast jednej ogromnej aplikacji.
Od gier naturalnym krokiem dalej jest monitorowanie stanowiska roboczego, bo tam liczą się logi i powtarzalne diagnostykowanie.
Hostuj serwery gier bez lagów dzięki szybkiemu hostingowi VPS NVMe.
VPS do gier
Oprogramowanie do monitorowania GPU dla stanowisk roboczych i aplikacji profesjonalnych
Monitorowanie stanowiska roboczego to znacznie mniej praca pracownika ds. bezpieczeństwa patrzącego na żywy overlay, a bardziej o odpowiadaniu na pytanie "Co się stało w czasie, i czy mogę to powtórzyć?"
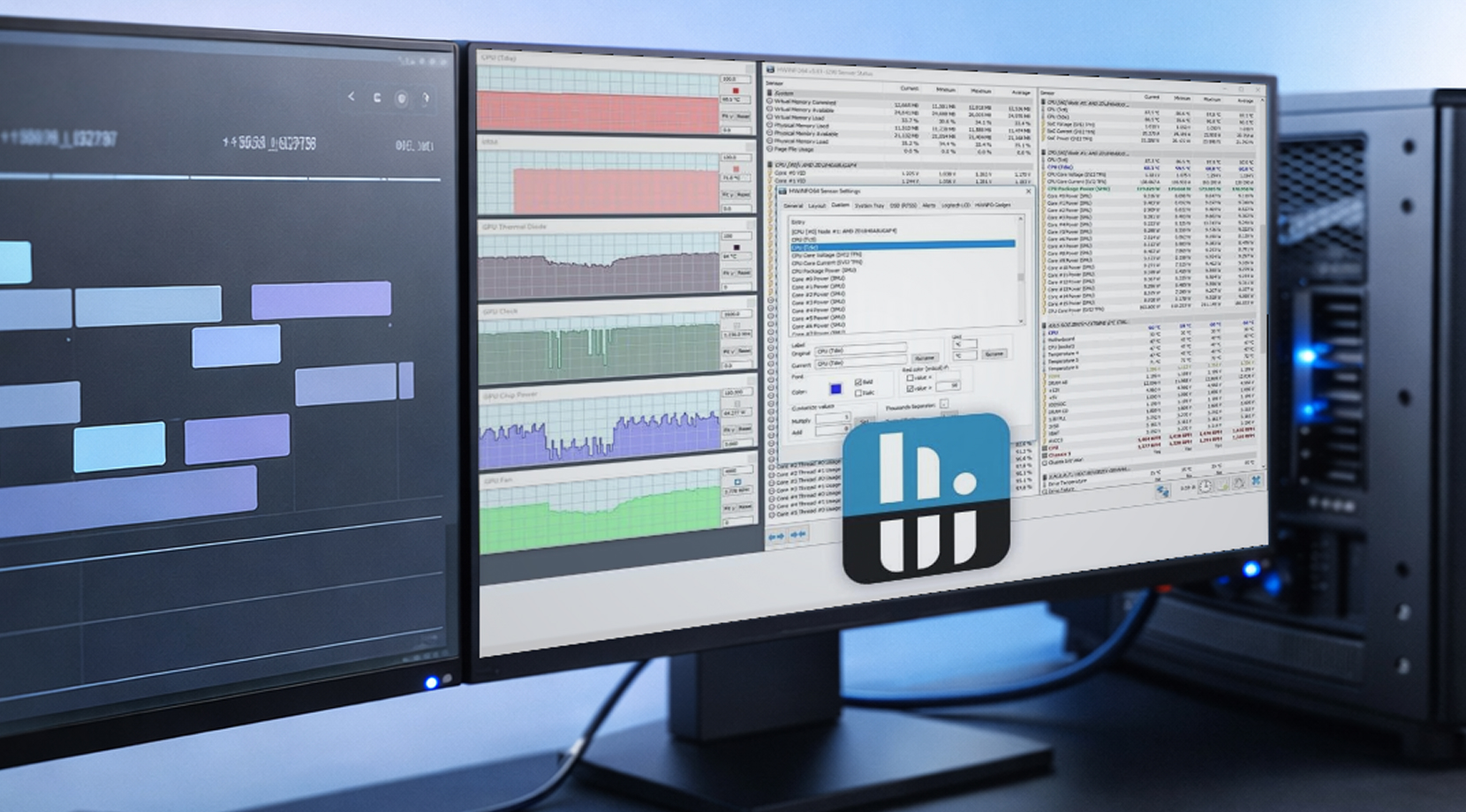
HWiNFO dla logowania na Windows
HWiNFO jest popularne w kręgach stanowisk roboczych, bo ma głębokie pokrycie czujników i logowanie, które łatwo się udostępnia. Prosty log CSV z czasami może łatwo zmienić niejasny raport w coś, czego możesz aktywnie używać do naprawy problemów.
Jeśli budujesz log stabilności stanowiska roboczego dla GPU, zacznij od tych metryk GPU:
- Temperatura GPU i hotspot
- Używana VRAM
- zasilanie płyty głównej
- takt rdzenia
- Moc pakietu CPU (bo limity mocy platformy mogą cię ugryźć)
To jest zestaw "wystarczającej ilości danych do wyjaśnienia". Logowanie każdego czujnika po prostu utrudnia czytanie pliku.
GPU-Z do szybkich sprawdzeń "Jaki to GPU?"
GPU-Z wciąż przydaje się, bo jest szybki i skoncentrowany. W zespołach z mieszanym sprzętem to najszybszy sposób na potwierdzenie modelu GPU, podstaw sterownika i czujników na żywo bez przeszukiwania menu.
Stress Testing: Przydaje się tylko z logowaniem
Testy obciążeniowe mogą pomóc w reprodukowaniu awarii, ale tylko jeśli twoje oprogramowanie do monitorowania GPU loguje dane podczas ich uruchamiania. Bez tych logów zostaje ci tylko "awaria się powtórzyła" i praktycznie żadna oś czasowa.
W tym momencie większość ludzi trafia na te same problemy, takie jak niewidoczne overlaye, błędne odczyty mocy i nieczytelne logi. Zajmijmy się nimi bezpośrednio.
Częste problemy z oprogramowaniem do monitorowania GPU i szybkie poprawki

Większość problemów sprowadza się do kilku schematów. Poniżej znajdują się rozwiązania, które sprawdzam w pierwszej kolejności, bo szybko eliminują nudne sprawy.
Brakujący overlay w grze
Jeśli overlay znika w nowoczesnej grze, zwykle chodzi o problem z hookami per-grę lub konflikt z warstwami anti-cheat lub anti-tamper.
Co możesz spróbować:
- Zaktualizuj RTSS i zresetuj profil per-grę
- Ustaw wyższy "poziom detekcji aplikacji" dla profilu gry
- Spróbuj innego API, jeśli gra to obsługuje
- Wróć do wbudowanych overlayów, gdy gra blokuje overlaye firm trzecich
Nie każda gra będzie współpracować, a nie warto tracić godzin na jedną upartą produkcję.
Dziwne odczyty mocy (0W, linie płaskie, brakujące czujniki)
To się często zdarza na laptopach i hybrydowych konfiguracjach, gdzie aktywne GPU się zmienia. W takich przypadkach sprawdź narzędziem dodatkowym, takim jak nvidia-smi (NVIDIA) lub AMD SMI (AMD), żeby potwierdzić, czy GPU jest faktycznie aktywny.
Zbyt hałaśliwe logi
Przyczyna zwykle to oversampling. Do większości diagnostyki wystarczy 1-5 sekund. Do długich zadań AI 5 sekund jest ok. Krótsze przedziały rozjeżdżają rozmiar pliku i utrudniają czytanie wykresów.
Gdy te podstawy są załatwione, monitorowanie zdalne staje się naturalnym następnym krokiem, bo wiele przepływów pracy GPU teraz uruchamia się poza maszyną.
Zdalne monitorowanie GPU i praktyczna opcja w chmurze
Praca zdalna zmienia to, co oznacza "dobre oprogramowanie do monitorowania GPU". Nie zawsze patrzysz na maszynę, więc potrzebujesz kontroli, którą można uruchomić szybko, plus historii, którą można przejrzeć później.
Czysty setup zdalny zwykle wygląda tak:
- Kontrole CLI (nvidia-smi lub AMD SMI)
- plik dziennika, który możesz pobrać później
- eksporter/dashboard, jeśli potrzebujesz alertów
Jeśli sprzęt lokalny zaczyna blokować postęp (limity VRAM, dzielenie się jednym GPU, potrzeba czystego środowiska dla każdego projektu), uruchamianie obciążeń na chmurowym GPU VPS może być najprostszym sposobem na utrzymanie tempa.
Cloudzy GPU VPS

Jeśli szukasz zdalnego czasu GPU dostosowanego do przepływów pracy AI, gier i renderingu, nasze Cloudzy GPU VPS obejmuje opcje NVIDIA takie jak RTX 5090, A100 i RTX 4090, plus pamięć NVMe, pełny dostęp root, połączenia do 40 Gbps, ochronę DDoS i deklarowany czas dostępności 99,95%.
Z perspektywy monitorowania zachowuje się jak zwykła maszyna, ponieważ możesz uruchamiać oprogramowanie do monitorowania GPU przez SSH, logować metryki GPU dla długich zadań i dodawać dashboardy, jeśli chcesz historię i alerty.
Jeśli wciąż wahasz się między konfiguracją GPU a ustawieniem CPU-only, nasze artykuły na temat Czym jest GPU VPS? oraz VPS GPU vs CPU wyjaśniają praktyczne różnice w zależności od zastosowania.
Skoro monitoring zdalny jest już skonfigurowany, ostatni krok to złożenie wszystkiego w gotowe do skopiowania stosy konfiguracji.
Gotowe stosy konfiguracji dla każdego scenariusza
Oto łatwe w wdrożeniu stosy, które możesz zastosować bez przepisywania całego workflow. To świetne punkty wyjścia dla twoich konfiguracji, które później dostosowujesz do swoich konkretnych potrzeb.
- Konstruktor modeli (AI/ML): Oprogramowanie do monitorowania GPU przez nvidia-smi lub AMD SMI, plus prosty plik CSV, plus eksporter/dashboard do zadań uruchamianych bez nadzoru.
- Gracz konkurencyjny/Streamer: GPU monitoring software overlay via Afterburner + RTSS, plus narzędzie do pomiaru czasu klatek do porównań, plus minimalny zestaw metryk ekranowych.
- Użytkownik Stacji Roboczej GPU monitoring software via HWiNFO logging, plus GPU-Z do szybkich sprawdzeń identyfikacji, plus test obciążenia tylko gdy logujesz przebieg.
- Admin zarządzający maszynami GPU: GPU monitoring software jako usługa: eksporter + dashboards + alerty, plus widoczność poszczególnych procesów (nvtop) dla współdzielonych maszyn.
Jeśli weźmiesz jedno z tego poradnika, niech to będzie: wybierz GPU monitoring software na podstawie tego, gdzie potrzebujesz danych (overlay, log, dashboard), a następnie utrzymuj swój zestaw metryk na tyle mały, że będziesz go naprawdę używać.