
Gdy NVIDIA pokazała, jak DLSS 4 generuje piętnaście z każdych szesnastu pikseli za pomocą AI, duża część odbiorców nie dostrzegła postępu. Zobaczyli „fałszywe klatki” i „bełkot AI”: wygenerowane szczegóły, które wyglądają poprawnie, dopóki nie przestaną, i których nie da się debugować tak, jak debugowałbyś źle umieszczony wielokąt. Raport PCGuide z ankiety społeczności wykazał, że 54% odpowiedzi to było zwykłe „Nie” wobec DLSS 5 i jego wyglądu, przy czym znaczna część krytyki dotyczyła rysów twarzy oraz reakcji „bełkot AI”. Tę reakcję warto potraktować poważnie i jeszcze do niej wrócimy.
Ale większym problemem w każdym z tych sporów jest to, że termin „rendering neuronowy” bywa używany do co najmniej pięciu różnych rzeczy: skalowania w górę, klatek generowanych przez AI, rekonstrukcji sceny ze zdjęć, demonstracji NeRF i Gaussian Splatting, które widziałeś w mediach społecznościowych, oraz systemów badawczych renderujących całe obrazy jedną siecią. Ludzie rozmawiają obok siebie, bo każdy wskazuje na inną warstwę, używając tego samego słowa. Jensen Huang z NVIDIA nazwał ten przełom „momentem GPT dla grafiki”. Takie jest twierdzenie. Użyteczne pytanie brzmi: co dzieje się pod nim.
Oto myśl przewodnia, która czyni całość zrozumiałą: GPU coraz częściej przewiduje obraz, zamiast go obliczać. Tradycyjnie GPU oblicza każdy piksel, symulując geometrię, oświetlenie i materiały (rasteryzacja, a ostatnio śledzenie promieni na jej szczycie). Rendering neuronowy zmienia to, co jest obliczane , w porównaniu z tym, co jest przewidywane przez wytrenowaną sieć. To jedno rozróżnienie jest osią tego artykułu. Pod jego koniec będziesz w stanie umieścić dowolną technikę na spektrum, wiedzieć, które działają w czasie rzeczywistym i na jakim sprzęcie, oraz odróżnić to, co trafia dziś do gier, od tego, co jest pracą badawczą lub demem z GTC. To mapa, a nie poradnik. Głęboka mechanika każdej pojedynczej techniki to temat na osobne artykuły.
Krótka wersja
- Rendering neuronowy to spektrum, a nie synonim DLSS. Obejmuje badania nad rekonstrukcją scen (NeRF, Gaussian Splatting), komponenty czasu rzeczywistego wewnątrz potoku renderowania (DLSS, Ray Reconstruction, neuronowy bufor radiancji) oraz metody generatywne, które wymyślają szczegóły, których klatka nigdy nie miała.
- Myśl przewodnia to „przewiduj zamiast obliczać”. Każda technika zastępuje kosztowny obliczany etap potoku siecią, która przewiduje wynik, na którym ją wytrenowano.
- Większość tego, co trafia dziś na rynek, jest hybrydowa. Skalowanie w górę, generowanie klatek i odszumianie AI działają już w grach czasu rzeczywistego, podczas gdy neuronowa kompresja tekstur i neuronowe shadery pojawiają się przez zestawy narzędzi dla deweloperów. Pełne renderery neuronowe, które rysują cały obraz siecią, są wciąż na etapie badań.
- Staje się to międzyproducencie, a nie tylko historią NVIDIA. Prace Microsoftu nad ML na poziomie shaderów w DirectX zaczęły się od Cooperative Vectors w Shader Model 6.9 i zmierzają ku szerszemu wsparciu algebry liniowej w Shader Model 6.10, dając silnikom drogę do neuronowych obciążeń shaderowych poza stosem jednego producenta.
Dlaczego „rendering neuronowy” oznacza pięć różnych rzeczy
Rendering neuronowy to klasa metod, które używają sieci neuronowych do przewidywania części obrazu (pikseli, oświetlenia, materiałów, a nawet całych klatek), które GPU musiałoby inaczej obliczyć od zera. Przegląd Tewari i in. definiuje go jako połączenie klasycznej grafiki komputerowej z głębokimi modelami generatywnymi dla fotorealistycznego wyniku. Termin obejmuje szerokie spektrum, a „DLSS” to jeden punkt na nim.
Powodem, dla którego rozmowa jest bałaganem, jest to, że spektrum ma co najmniej trzy odrębne warstwy, a opinia publiczna używa jednego słowa do wszystkich.
Pierwsza warstwa to akademicki / rekonstrukcyjny rendering neuronowy: NeRF, 3D Gaussian Splatting i rendering różniczkowalny. Biorą one zdjęcia lub pomiary rzeczywistej sceny i uczą się reprezentacji, którą można renderować z nowych ujęć kamery. oryginalny artykuł o NeRF (Mildenhall i in., 2020) trenuje małą sieć, aby odwzorować współrzędną 3D i kierunek patrzenia na kolor i gęstość, a następnie renderuje nowe widoki, odpytując ją. Ta warstwa jest głównie offline. Rekonstruuje sceny; nie napędza pętli klatek twojej gry.
Druga warstwa to rendering neuronowy potoku czasu rzeczywistego: sieci, które działają wewnątrz lub obok normalnej rasteryzowanej klatki. Skalowanie DLSS, Ray Reconstruction i neuronowy bufor radiancji żyją tutaj. Potok wciąż rasteryzuje i śledzi promienie; sieć obsługuje jeden kosztowny jego etap. To warstwa obecna w grach dzisiaj.
Trzecia warstwa to generatywny rendering neuronowy: sieć tworzy zawartość obrazu, której klatka w ogóle nigdy nie obliczyła. Generowane klatki DLSS 4 znajdują się na skraju tego, a DLSS 5 (który NVIDIA ogłosiła na jesień 2026 roku) idzie dalej w tę stronę, generując szczegóły oświetlenia i materiałów, zamiast tylko interpolować między renderowanymi klatkami.
Te trzy warstwy zachowują się różnie, działają z różną prędkością i potrzebują różnego sprzętu. Traktowanie ich jako jednej rzeczy jest powodem, dla którego dwie osoby mogą jednocześnie powiedzieć „rendering neuronowy jest przereklamowany” i „rendering neuronowy to przyszłość”, i obie mieć częściowo rację.
Wniosek z sekcji: Termin powstał przed DLSS i nie jest jego synonimem. DLSS to jedno zastosowanie (czas rzeczywisty, w potoku) wewnątrz znacznie szerszego spektrum, które sięga od offlinowej rekonstrukcji scen po w pełni generowane klatki.
Jak rendering neuronowy zastępuje części potoku siłowego
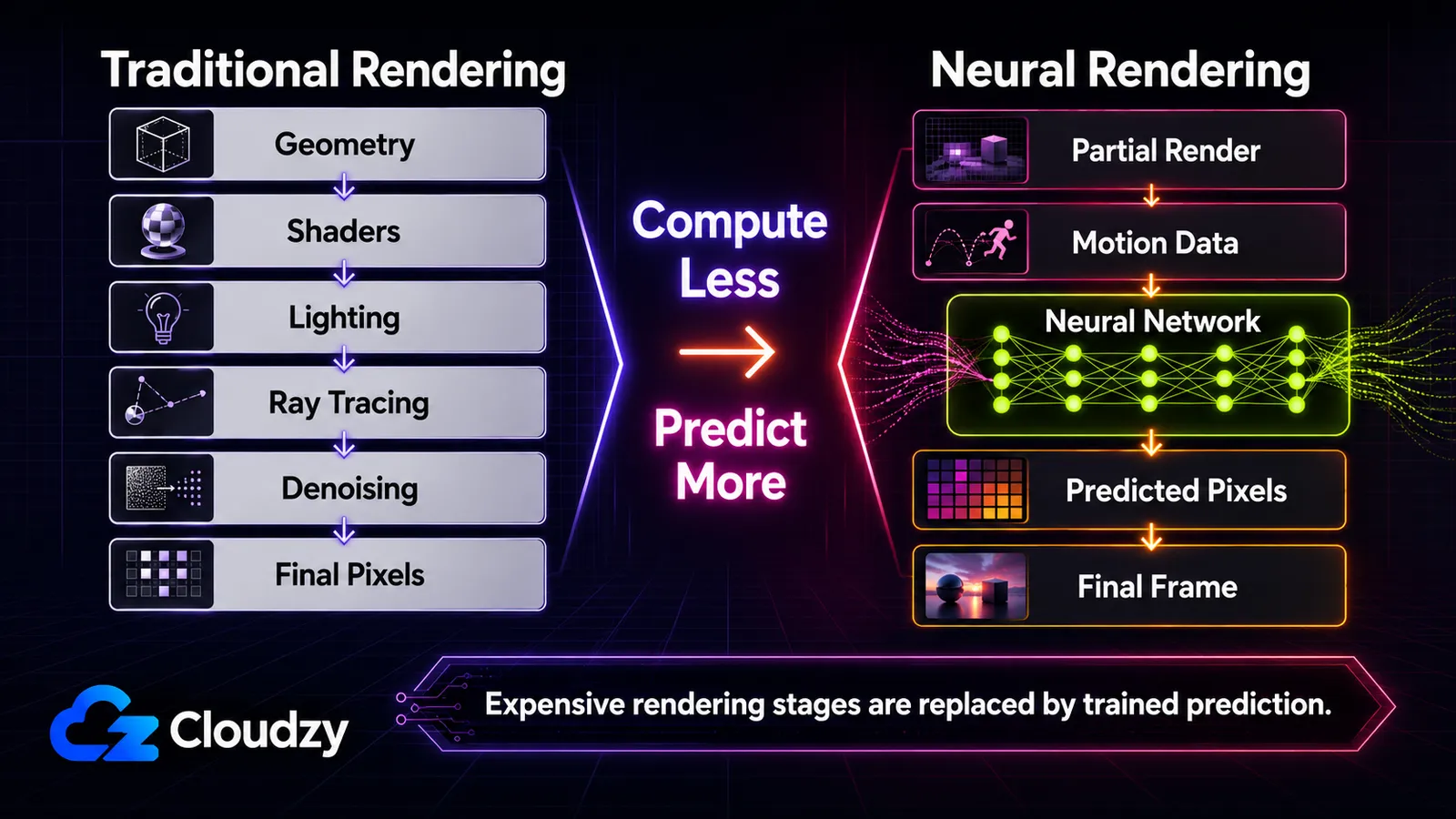
Przy pełnym wielokrotnym generowaniu klatek DLSS 4 mniej więcej piętnaście z każdych szesnastu pikseli na ekranie jest wytwarzanych przez AI, a nie renderowanych tradycyjnie (według danych NVIDIA o DLSS 4). Ta liczba to cały przełom skompresowany w jedną statystykę: renderer oblicza ułamek obrazu i przewiduje resztę.
Tradycyjny rendering zapracowuje na każdy piksel. GPU rasteryzuje geometrię, uruchamia shadery, aby obliczyć oświetlenie i materiały, oraz (przy śledzeniu promieni) symuluje odbijanie się światła po scenie. Śledzenie promieni jest w szczególności brutalnie kosztowne, bo realistyczne światło potrzebuje wielu odbić i wielu próbek na piksel, a szum z niedopróbkowania trzeba potem oczyścić. W miarę jak sceny stawały się bardziej ambitne, najdroższe etapy stały się oczywistymi celami: zamiast je obliczać, wytrenuj sieć, by przewidywała ich wynik.
Postęp był raczej stały niż nagły:
- 2018, DLSS 1.0. Pierwszy krok komercyjny: renderuj w niskiej rozdzielczości, przewiduj obraz w wysokiej rozdzielczości. Przejdź ze skalowania od „obliczaj więcej pikseli” do „przewiduj więcej pikseli”.
- 2020, NeRF. Rekonstrukcja sceny z obrazów przez wyuczone pole radiancji. Przewiduj nowe widoki zamiast modelować i renderować geometrię.
- 2021, Neural Radiance Cache. Przewiduj odbite światło podczas śledzenia ścieżek, aby renderer mógł wcześnie przerwać śledzenie.
- 2022, DLSS 3 Frame Generation. Generuj całe klatki pośrednie zamiast je renderować.
- 2023, 3D Gaussian Splatting. Szybsza, skłaniająca się ku czasowi rzeczywistemu alternatywa dla NeRF dla rekonstruowanych scen.
- 2025, DLSS 4 + RTX Kit. Wielokrotne generowanie klatek plus zestaw komponentów neuronowych (kompresja tekstur, bufor radiancji, neuronowe shadery).
- 2025, DirectX Cooperative Vectors (wersja zapoznawcza). Międzyproducencie API dla matematyki macierzowej, której potrzebują neuronowe shadery (wprowadzone w wersji zapoznawczej jako część Shader Model 6.9).
- 2026, DLSS 4.5. Stopniowe usprawnienia jakości i Ray Reconstruction (opisane przez NVIDIA na Computex).
- Jesień 2026, DLSS 5 (zapowiedziany). Kolejny krok ku generatywnemu renderingowi neuronowemu.
Czytając od góry do dołu, każdy wiersz to ten sam ruch zastosowany do innego etapu: weź coś, co potok kiedyś obliczał, i niech sieć to zamiast tego przewiduje.
Sześć warstw: co AI zastępuje na każdym etapie potoku
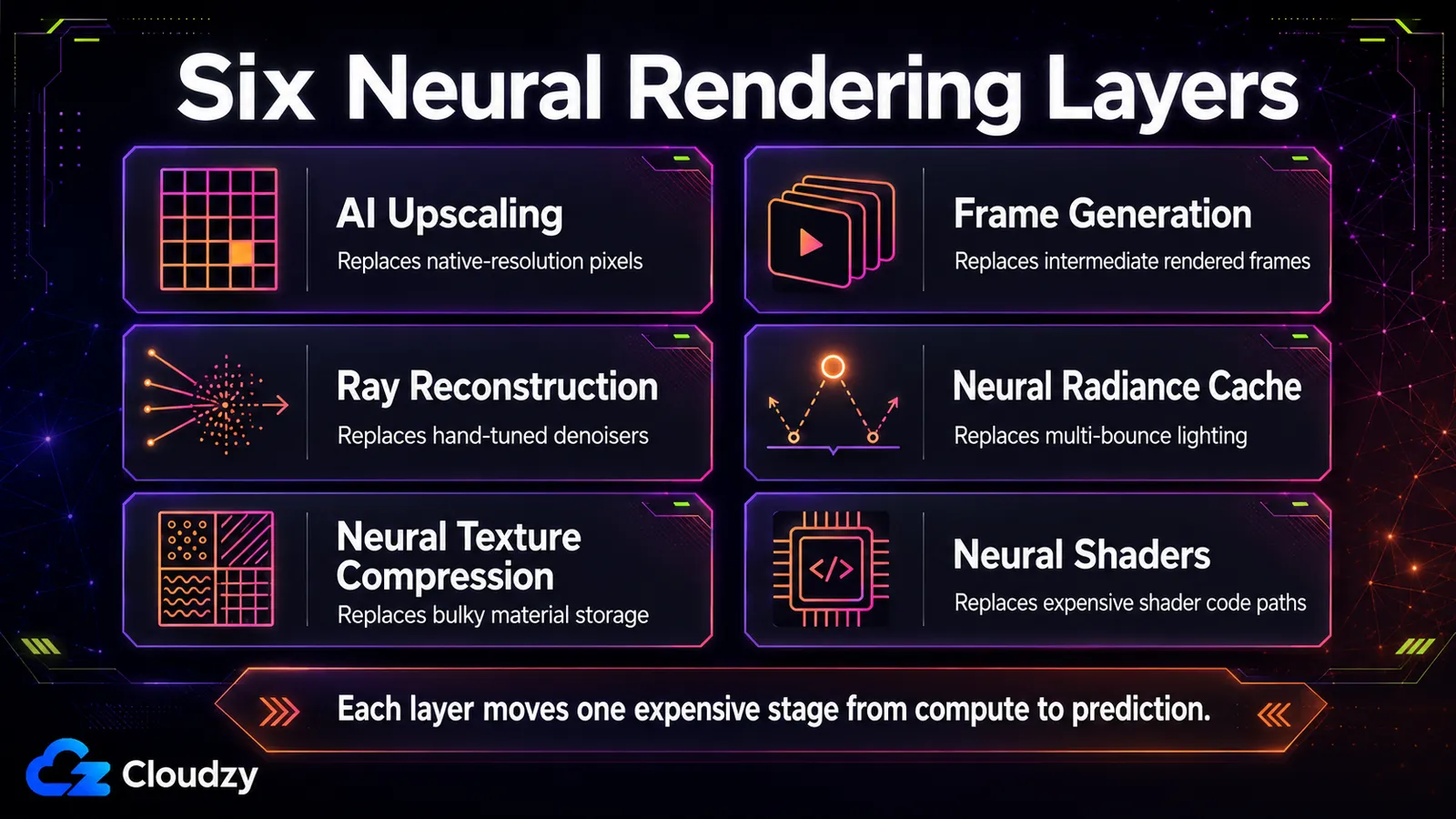
Sześć technik dźwiga większość dzisiejszego renderingu neuronowego czasu rzeczywistego, a każda z nich zastępuje konkretny obliczany etap: skalowanie w górę (rozdzielczość), generowanie klatek (liczba klatek), ray reconstruction (odszumianie), neuronowy bufor radiancji (oświetlenie globalne), neuronowa kompresja tekstur (przechowywanie materiałów) i neuronowe shadery (obliczenia wewnątrz shadera). Wiedza o tym, którego etapu dotyka każda, to większość sukcesu.
Dzielą się one według tego, gdzie w potoku działa sieć. Niektóre działają na samym końcu jako przetwarzanie końcowe gotowej klatki; niektóre działają w środku potoku obok śledzenia promieni; niektóre żyją wewnątrz samego shadera. To umiejscowienie nie jest szczegółem. Określa ono, jak szybko technika może działać i jakiego sprzętu potrzebuje. Tabela mapuje tych sześć technik; podrozdziały poniżej wyjaśniają mechanizm, który nie zmieściłby się czysto w każdej komórce.
| Technika | Co zastępuje | Przydatność w czasie rzeczywistym | Wymagany sprzęt | Międzyproducencie? |
|---|---|---|---|---|
| Skalowanie AI (super rozdzielczość) | Obliczanie pikseli natywnej rozdzielczości | Czas rzeczywisty, niski narzut | Rdzenie tensorowe / macierzowe (RTX 20+, RDNA 4, Intel XMX) | Tak jako kategoria; implementacje pozostają specyficzne dla producenta (DLSS, FSR / FSR Upscaling, XeSS) |
| Generowanie klatek | Renderowanie klatek pośrednich | Czas rzeczywisty; dodaje opóźnienie | RTX 40+ (DLSS 3), RTX 50 dla wielokrotnej | Częściowo; specyficzna dla producenta |
| Ray reconstruction | Stos ręcznie dostrojonych odszumiaczy | Czas rzeczywisty | RTX 20+ | NVIDIA dzisiaj |
| Neuronowy bufor radiancji | Obliczanie wielokrotnie odbitego światła pośredniego | Czas rzeczywisty (zgłaszane ~2,6 ms) | Rdzenie macierzowe klasy RTX | NVIDIA dzisiaj (RTX Kit) |
| Neuronowa kompresja tekstur | Przechowywanie materiałów z kompresją blokową | Dekodowanie w czasie rzeczywistym | Rdzenie macierzowe klasy RTX | NVIDIA SDK/narzędzia dzisiaj; szersze wsparcie ML na poziomie shaderów jest standaryzowane osobno |
| Neuronowe shadery | Obliczane ścieżki kodu shadera | Czas rzeczywisty | ML na poziomie shaderów / GPU z obsługą macierzy | Pojawia się przez ścieżkę DirectX SM 6.9 / SM 6.10 |
Skalowanie AI (super rozdzielczość)
Skalowanie AI renderuje klatkę w niższej rozdzielczości i przewiduje wynik wysokiej rozdzielczości, więc GPU rysuje znacznie mniej pikseli, a sieć uzupełnia strukturę. DLSS, FSR 4 od AMD oraz XeSS od Intela robią to wszystkie przez czasowe nadpróbkowanie: próbkują różne piksele w kolejnych klatkach i łączą tę historię z wektorami ruchu, aby zrekonstruować szczegóły, których pojedyncza klatka o niskiej rozdzielczości nie zawiera.
To najbardziej dojrzała i najszerzej wdrożona warstwa, i to tutaj rzeczywistość międzyproducencia jest najjaśniejsza. DLSS 4 przeniósł swój skaler z sieci konwolucyjnej na transformer dla lepszej stabilności szczegółów. FSR 4 to pierwszy skaler AMD oparty na ML, działający na RDNA 4 z inferencją FP8, a nie na ręcznie pisanych heurystykach wcześniejszych wersji FSR. XeSS używa jednostek macierzowych XMX firmy Intel. Trzech producentów, ta sama podstawowa idea: przewiduj piksele, których nie wyrenderowałeś.
Generowanie klatek i wielokrotne generowanie klatek
Generowanie klatek przewiduje całe klatki między tymi, które GPU faktycznie renderuje, łącząc dane gry, takie jak wektory ruchu, z estymacją przepływu optycznego i AI. DLSS 3 używał akceleratora przepływu optycznego serii RTX 40 do wstawienia jednej wygenerowanej klatki między renderowanymi; DLSS 4 Multi Frame Generation na sprzęcie serii RTX 50 może wygenerować do trzech dodatkowych klatek na każdą tradycyjnie renderowaną, a NVIDIA mówi, że DLSS 4 zastępuje sprzętowy etap przepływu optycznego wydajniejszym modelem AI.
To warstwa, o którą tak naprawdę chodzi w sporze o „fałszywe klatki”, i ujęcie ma tu znaczenie. Wygenerowana klatka to wiarygodna interpolacja tego, dokąd zmierzała scena: pokazuje ci użyteczną zawartość wizualną. Ale jest przewidywane, a nie wyrenderowana z faktycznego stanu gry, i nie niesie świeżej logiki gry ani wejścia. Co kluczowe, generowanie klatek działa po wyrenderowaniu klatki, co dodaje opóźnienie, zamiast je usuwać; Reflex 2 od NVIDIA istnieje właśnie po to, by odzyskać to opóźnienie. Więc „generowanie klatek przyspiesza grę” to częściowa prawda: podnosi postrzeganą płynność (wyświetla się więcej klatek), nie podnosząc tempa, z jakim gra faktycznie się aktualizuje i reaguje. Ta przepaść między tym, co widzisz, a tym, co gra wie, to cała debata, a dla gry rywalizacyjnej, gdzie opóźnienie wejścia decyduje o wynikach, to kompromis wart rozważenia.
Ray Reconstruction (odszumianie AI)
Ray Reconstruction zastępuje stos ręcznie dostrojonych filtrów odszumiania, na których opiera się rendering ze śledzeniem promieni, pojedynczą siecią neuronową wytrenowaną do rekonstrukcji czystego obrazu z zaszumionego, niedopróbkowanego wejścia ze śledzenia promieni. Śledzenie ścieżek w czasie rzeczywistym może pozwolić sobie tylko na kilka próbek światła na piksel, co pozostawia surowy wynik zaszumiony; coś musi go oczyścić, zanim go zobaczysz.
Tradycyjnym podejściem był łańcuch wyspecjalizowanych odszumiaczy, każdy dostrojony ręcznie do konkretnego efektu. Zamiana tego na jedną wytrenowaną sieć zwykle zachowuje szczegóły, które ręcznie dostrojone filtry rozmazywały, zwłaszcza na odbiciach i delikatnym oświetleniu, i jest to jedna sieć do utrzymania zamiast kruchego potoku z nich. To czysty przykład myśli przewodniej: etap odszumiania przeszedł od „obliczaj ręcznie pisanymi heurystykami” do „przewiduj wytrenowanym modelem”.
Neuronowy bufor radiancji (oświetlenie globalne)
Neuronowy bufor radiancji (NRC) przewiduje, jak światło odbija się po scenie, aby tracer ścieżek mógł wcześnie przerwać śledzenie większości promieni, zamiast śledzić każde odbicie do końca. Oświetlenie globalne (miękkie, pośrednie światło odbijające się od ścian i podłóg) to jedna z najdroższych rzeczy w grafice czasu rzeczywistego, a mechanizm, dzięki któremu NRC działa, rzadko jest wyjaśniany prostym językiem, więc warto przy nim zwolnić.
Oto mechanizm. Tracer ścieżek normalnie śledzi każdy promień światła przez wiele odbić, i właśnie tam koszt eksploduje. NRC trenuje małą sieć podczas renderowania (a nie z wyprzedzeniem), aby przewidzieć światło docierające do punktu po dalszych odbiciach. Więc tracer ścieżek śledzi promień przez jedno lub dwa odbicia, potem pyta sieć „jakie jest tu reszta światła?” i wcześnie kończy ścieżkę; artykuł o neuronowym buforowaniu radiancji w czasie rzeczywistym (Müller i in., 2021) raportuje kończenie znacznej większości ścieżek w ten sposób. Pomyśl o tym jak o buforze, który nie przechowuje dokładnych odpowiedzi widzianych wcześniej, lecz uczy się wzorca oświetlenia sceny na tyle dobrze, by odpowiadać na zapytania, których nie widział, i wciąż się douczać w miarę zmian sceny. NVIDIA raportuje, że NRC działa z narzutem mniej więcej 2,6 ms, co czyni go przydatnym w czasie rzeczywistym, a nie badawczą ciekawostką.
Neuronowa kompresja tekstur
Neuronowa kompresja tekstur (NTC) kompresuje wszystkie kanały tekstur materiału razem za pomocą sieci, osiągając do 8-krotnej oszczędności VRAM w porównaniu z tradycyjną kompresją blokową przy podobnej jakości wizualnej (według dokumentacji NVIDIA RTX Kit). Nowoczesny materiał to nie jedna tekstura. To stos ich (kolor, normalne, chropowatość, metaliczność i więcej), a te kanały są skorelowane w sposób, który kompresja blokowa, ściskająca każdy kanał niezależnie, odrzuca.
NTC wykorzystuje tę korelację. Ucząc się wspólnej struktury wszystkich kanałów materiału naraz, przechowuje ten sam materiał w znacznie mniejszej pamięci i dekoduje go w locie podczas renderowania. VRAM pozostaje stałym ograniczeniem, w miarę jak gry zwiększają szczegółowość tekstur, więc „zmieść 8x więcej materiału w tej samej pamięci” to bezpośrednia, praktyczna wygrana, a nie wizualna sztuczka.
Neuronowe shadery i DirectX Cooperative Vectors
Neuronowe shadery uruchamiają małe sieci neuronowe wewnątrz programowalnego shadera (programy na piksel/na wierzchołek, które GPU już wykonuje), aby sieć mogła przybliżyć kosztowny obliczany efekt dokładnie tam, gdzie ten efekt jest potrzebny. Zamiast doczepiać AI jako osobny przebieg, MLP działa jako część shadera na jednostkach macierzowych GPU (Tensor Cores na sprzęcie NVIDIA).
Tensor Cores obsługują matematykę macierzową, na której działają te sieci, odrębne od rdzeni ogólnego przeznaczenia, które obsługują resztę pracy. Tym, co zmienia neuronowe shadery z funkcji jednego producenta w szerszą zdolność branżową, jest warstwa API pod nimi. Microsoft wprowadził DirectX Cooperative Vectors w wersji zapoznawczej z Shader Model 6.9 w 2025 roku, aby udostępnić operacje wektorowe/macierzowe wewnątrz shaderów HLSL. Do 2026 roku Shader Model 6.9 przeszedł do wersji finalnej, a Microsoft poinformował, że Cooperative Vector jest wycofywany na rzecz szerszego projektu algebry liniowej planowanego dla Shader Model 6.10. Bezpieczny wniosek nie jest taki, że Cooperative Vectors to ostateczne API, lecz taki, że DirectX zmierza ku międzyproducencie wsparciu ML na poziomie shaderów.
Wniosek z sekcji: Sześć technik porządkuje się według tego, gdzie działa sieć: przetwarzanie końcowe na końcu klatki, w środku potoku obok śledzenia promieni lub wewnątrz samego shadera. To umiejscowienie decyduje o tym, czy technika może działać w czasie rzeczywistym i jakiego sprzętu potrzebuje.
Co działa w czasie rzeczywistym i na jakim sprzęcie
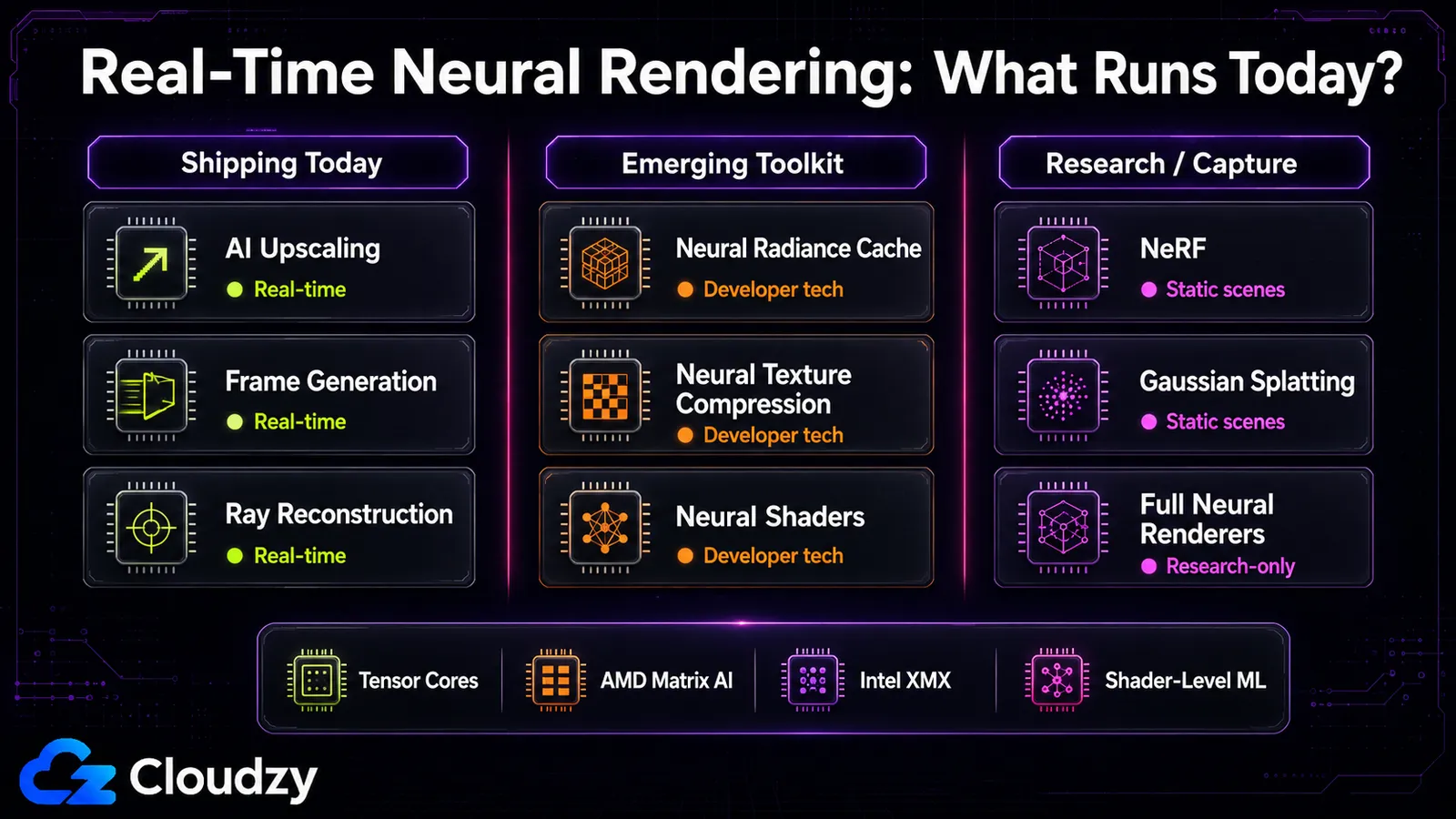
Granica czasu rzeczywistego jest ostrzejsza, niż sugeruje szum: skalowanie AI zwykle działa z niskim narzutem, NRC dodaje mniej więcej 2,6 ms, a 3D Gaussian Splatting zbliża się do czasu rzeczywistego dla scen statycznych. Oryginalny NeRF i pełne renderery neuronowe, takie jak RenderFormer, pozostają zdecydowanie wyłącznie badawcze, zajmując zdecydowanie za długo na klatkę do użytku interaktywnego. „Rendering neuronowy działa w czasie rzeczywistym” jest prawdą dla warstwy w potoku, a fałszem dla warstw rekonstrukcji i pełnego renderera.
Ten podział dokładnie odwzorowuje spektrum. Niektóre komponenty w potoku, zwłaszcza skalowanie, generowanie klatek i Ray Reconstruction, już działają w wydawanych grach. Inne, takie jak NRC, NTC i neuronowe shadery, lepiej opisać jako technologie dla deweloperów i pojawiające się funkcje zestawów narzędzi, a nie powszechne funkcje produkcyjne. Warstwa rekonstrukcji jest mieszana: oryginalny NeRF jest powolny, ale 3D Gaussian Splatting był świadomym dążeniem ku czasowi rzeczywistemu i osiąga go dla scen statycznych. Warstwa pełnego renderera neuronowego (jedna sieć tworząca cały obraz) to miejsce, gdzie żyją badania, a czasy klatek są dalekie od interaktywnych.
Sprzęt to druga połowa odpowiedzi i właśnie tutaj ląduje historia międzyproducencia. Każda technika tutaj działa na jednostkach matematyki macierzowej, które nowoczesne GPU dostarczają do inferencji AI:
- NVIDIA ma Tensor Cores na każdej karcie RTX od serii 20 wzwyż, dlatego większość tych technik zadebiutowała właśnie tam.
- AMD FSR Upscaling oparte na ML obecnie celuje w GPU RDNA 4 / Radeon RX serii 9000 dla ścieżki ML; na wcześniejszym sprzęcie SDK od AMD wraca do analitycznych ścieżek FSR 3.1.5. Traktuj szersze wsparcie starszych GPU jako ruchomy element planu działania, a nie gwarantowaną funkcję FSR 4, chyba że powołasz się na konkretne ogłoszenie AMD.
- Intel używa silników macierzowych XMX na GPU Arc dla XeSS.
Sam DLSS jest ograniczony funkcjami zależnie od generacji: skalowanie działa wstecz aż do serii RTX 20, oryginalne generowanie klatek wymaga serii RTX 40, a wielokrotne generowanie klatek dotyczy wyłącznie serii RTX 50. Jeśli próbujesz rozważyć, co dana karta potrafi, to ograniczenie generacyjne jest praktyczną odpowiedzią, a nie poziom marketingowy.
Czego możesz użyć dzisiaj a co nadchodzi: Skalowanie, generowanie klatek i Ray Reconstruction są dostępne w grach już dzisiaj. Komponenty RTX Kit takie jak NRC, NTC i neuronowe shadery są dostępne jako technologie i narzędzia dla deweloperów, ale nie powinieneś sugerować, że wszystkie z nich są już powszechne w wydawanych grach. Gaussian Splatting ma użyteczne otwarte narzędzia do przechwytywania scen. Czego jeszcze tu nie ma: pełnych rendererów neuronowych rysujących całą klatkę jedną siecią, dojrzałych międzyproducencich neuronowych shaderów (wsparcie AMD jest wczesne) oraz funkcji generatywnych DLSS 5 (zapowiedzianych na jesień 2026 roku). Jeśli chcesz eksperymentować ze stroną rekonstrukcji (samodzielnie uruchamiając NeRF lub obciążenia inferencji), to zadanie dla obliczeń GPU , a nie coś, co gra robi za ciebie.
Czym rendering neuronowy nie jest: pięć błędnych przekonań

Większość sporów o rendering neuronowy staje się łatwiejsza, gdy zidentyfikujesz, której warstwy spektrum dotyczy twierdzenie. Pięć błędnych przekonań pojawia się raz za razem.
1. „Skalowanie DLSS to rendering neuronowy”. DLSS to an zastosowanie renderingu neuronowego, warstwa czasu rzeczywistego w potoku, a nie cała dziedzina. Termin powstał przed DLSS i obejmuje NeRF, Gaussian Splatting oraz metody generatywne. Zrównywanie ich to jak nazywanie „baz danych” synonimem jednego produktu, którego akurat używasz.
2. „Generowanie klatek przyspiesza gry”. Podnosi liczbę klatek, które widzisz, przez co ruch wygląda płynniej, ale działa po renderowaniu i dodaje opóźnienie. Tempo, z jakim gra się aktualizuje i reaguje na twoje wejście, nie wzrasta. Dla gry rywalizacyjnej to opóźnienie jest realnym kompromisem; dla wizualnej płynności to autentyczna wygrana. „Szybciej” miesza te dwie rzeczy.
3. „DLSS 5 rozumie 3D / czyta scenę 3D”. To jest to, co najbardziej warto zrozumieć właściwie, bo publikacje techniczne wciąż to błędnie przedstawiają. Jak opisuje to NVIDIA, DLSS 5 bierze na wejściu dane o kolorze każdej klatki i wektory ruchu, a następnie używa swojego wytrenowanego modelu, aby wywnioskować semantykę sceny, taką jak postacie, włosy, tkanina, skóra i warunki oświetlenia. Jest osadzony w zawartości gry, ale NVIDIA nie opisuje go jako bezpośredniego czytania pełnego pliku sceny 3D gry. „Sterowany 3D” oznacza, że wnioskowanie jest spójne geometrycznie (respektuje, jak powierzchnie się poruszają i odnoszą), a nie że sieć czyta geometrię sceny bezpośrednio. Rozróżnienie ma znaczenie, bo wyznacza granice tego, co technika może i czego nie może wiedzieć.
4. „NeRF działa teraz w czasie rzeczywistym”. Zależy, którą technikę masz na myśli, co jest dokładnie problemem spektrum. Oryginalny NeRF nie działa w czasie rzeczywistym. 3D Gaussian Splatting zbliża się do czasu rzeczywistego dla scen statycznych. Systemy badawcze renderujące pełną klatkę jedną siecią (RenderFormer i podobne) wcale nie działają w czasie rzeczywistym. „NeRF” stał się workiem na pół tuzina metod o skrajnie różnych prędkościach.
5. „Rendering neuronowy wkrótce zastąpi rasteryzację”. Dzisiejsze systemy są hybrydowe: komponenty neuronowe siedzą wewnątrz potoku rasteryzacji i śledzenia promieni, a nie w jego miejsce. Pełne zastąpienie klasycznego potoku jednym generatywnym rendererem to cel badawczy o długim horyzoncie, a nie bliski kierunek produktowy. Potraktuj „przyszłość jest w pełni neuronowa” jako kierunek podróży, a nie datowaną prognozę.
Wniosek z sekcji: Jedyną pierwotną przyczyną niemal każdego sporu o rendering neuronowy są ludzie używający tego samego słowa do różnych warstw spektrum. Najpierw umieść twierdzenie na spektrum, a większość sporu zniknie.
Dokąd to zmierza
Trajektoria jest spójna ze wszystkim powyżej: hybrydowe potoki dzisiaj, coraz więcej etapów przechodzących z obliczania na przewidywanie, międzyproducencie neuronowe shadery poszerzające grono tych, którzy mogą to wydawać, a granica pełnego renderera neuronowego wciąż oddalona o lata. Kolejny krok konsumencki to DLSS 5, zapowiedziany na jesień 2026 roku, który wkracza w generatywny rendering neuronowy, tworząc szczegóły oświetlenia i materiałów, których gra nigdy nie obliczyła, zamiast tylko interpolować między renderowanymi klatkami. NVIDIA pokazała tę technologię w kontekstach serii RTX 50, ale jej ostateczne wymagania sprzętowe dla konsumentów należy traktować jako niepotwierdzone, dopóki NVIDIA nie opublikuje jasnej listy zgodności.
Spojrzenie w przód ma dwie połowy. Po bliższej stronie ruch, który liczy się najbardziej, to nie żadna pojedyncza technika. To standaryzacja. Ścieżka Microsoftu w DirectX przesuwa się od Cooperative Vectors ku szerszej algebrze liniowej na poziomie shaderów, co mogłoby pozwolić silnikom celować w neuronowe obciążenia bez stawiania na jedną markę GPU. Po dalszej stronie badacze NVIDIA opisali punkt końcowy odległej przyszłości, niekiedy wspominany jako hipotetyczny „DLSS 10”, w którym renderer jest w pełni neuronowy, a klasyczny potok zniknął (relacjonowane z drugiej ręki z okrągłego stołu Digital Foundry; traktuj to jako deklarowany kierunek, a nie plan działania). Punktem końcowym tej drabiny jest system, który generuje spójny świat, zamiast go rysować.
Warto jednak zachować sceptycyzm. Wygenerowane szczegóły mogą rozmijać się z zamysłem artystycznym, a sieć może halucynować wiarygodne, lecz błędne obrazy, które nie mają tradycyjnego odpowiednika do debugowania: problem kontroli jakości zgłoszony na GDC 2026 i istota znacznej części reakcji „bełkot AI”. Budowanie pod to, dokąd zmierza grafika, nie oznacza udawania, że obecny wynik jest skończony. Oznacza obserwowanie, które etapy przejdą z obliczania na przewidywanie jako następne, i ocenianie każdego po tym, co robi z obrazem, a nie po słowie do niego przyczepionym.
Często zadawane pytania
Czy DLSS to rendering neuronowy?
Tak, ale to tylko jeden rodzaj. DLSS to zastosowanie renderingu neuronowego: konkretnie warstwa czasu rzeczywistego w potoku, obejmująca skalowanie AI i generowanie klatek. Szerszy termin powstał przed DLSS i obejmuje także metody rekonstrukcji scen, takie jak NeRF i Gaussian Splatting, oraz metody generatywne, które wymyślają nowe szczegóły obrazu. Więc każda funkcja DLSS to rendering neuronowy, ale spora część renderingu neuronowego to nie DLSS.
Jaka jest różnica między renderingiem neuronowym a śledzeniem promieni?
Śledzenie promieni symuluje światło, obliczając, jak promienie odbijają się po scenie; rendering neuronowy przewiduje wyniki z wytrenowanej sieci, zamiast je obliczać. Nie są rywalami. Łączą się. Ray Reconstruction na przykład używa sieci neuronowej do odszumiania zaszumionego wyniku śledzenia promieni, a neuronowy bufor radiancji przewiduje odbite światło, aby tracer promieni mógł wcześnie się zatrzymać. Techniki neuronowe sprawiają, że śledzenie promieni jest dostępne w czasie rzeczywistym.
Czy generowanie klatek DLSS dodaje opóźnienie?
Tak. Generowanie klatek działa po wyrenderowaniu klatki i wstawia przewidziane klatki między renderowane, co dodaje opóźnienie, a nie je usuwa: Reflex 2 od NVIDIA istnieje właśnie po to, by je kompensować. Zwiększa postrzeganą płynność (wyświetla się więcej klatek), nie zwiększając tego, jak szybko gra się aktualizuje i reaguje na wejście. Dla gry rywalizacyjnej to kompromis; dla płynności w grze jednoosobowej to zwykle wygrana netto.
Czy NeRF działa w czasie rzeczywistym?
To zależy, którą technikę masz na myśli. Oryginalny NeRF nie działa w czasie rzeczywistym. 3D Gaussian Splatting, późniejsza metoda, zbliża się do czasu rzeczywistego dla scen statycznych. Pełne renderery neuronowe rysujące całą klatkę jedną siecią są wyłącznie badawcze i dalekie od interaktywnych prędkości. „NeRF” bywa używany luźno, by objąć kilka metod o bardzo różnej wydajności, co jest źródłem większości zamieszania.
Czy rendering neuronowy zastąpi rasteryzację?
Nieprędko. Dzisiejsze systemy są hybrydowe: komponenty neuronowe działają wewnątrz potoku rasteryzacji i śledzenia promieni, a nie zamiast niego. Całkowite zastąpienie klasycznego potoku jednym generatywnym rendererem to cel badawczy o długim horyzoncie, a nie bliski produkt. Realistyczny kierunek to coraz więcej etapów potoku przechodzących z obliczanych na przewidywane z czasem, przy czym rasteryzacja wciąż wykonuje realną pracę przez lata.
Czym jest neuronowa kompresja tekstur?
Neuronowa kompresja tekstur (NTC) to metoda neuronowa, która kompresuje wszystkie kanały tekstur materiału razem (kolor, normalne, chropowatość i resztę), osiągając do 8-krotnej oszczędności VRAM w porównaniu z tradycyjną kompresją blokową przy podobnej jakości wizualnej, według NVIDIA. Działa, ucząc się korelacji między kanałami, które kompresja blokowa, ściskająca każdy kanał osobno, odrzuca. Skompresowany materiał jest dekodowany w locie podczas renderowania.


